


如何使用8G以下显卡训练Stable diffusion可用的Lora模型


Lora,跃跃欲试!
最近,很多网友都在体验从 Civitai 网站下载的各种模型(权重参数),这些模型都是全球各地网友贡献的,图片效果很惊艳,而且类型丰富多样。
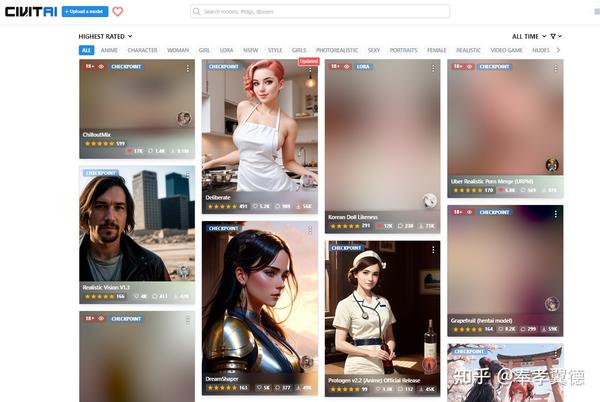

更重要的是,每张图片还都清楚地附带了生成图片所需的各种配置,根据提示下载相关模型和推理参数,就可以用 Stable Diffusion Webui 在本地个人电脑上用显卡生成图片。
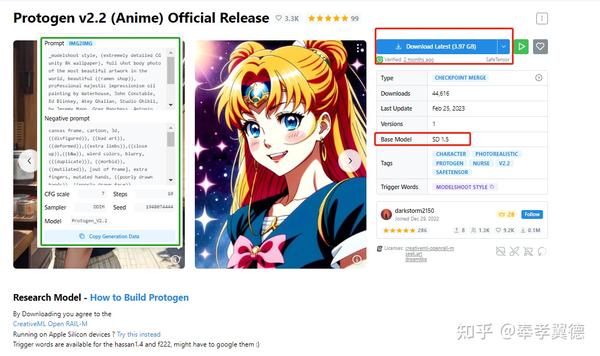
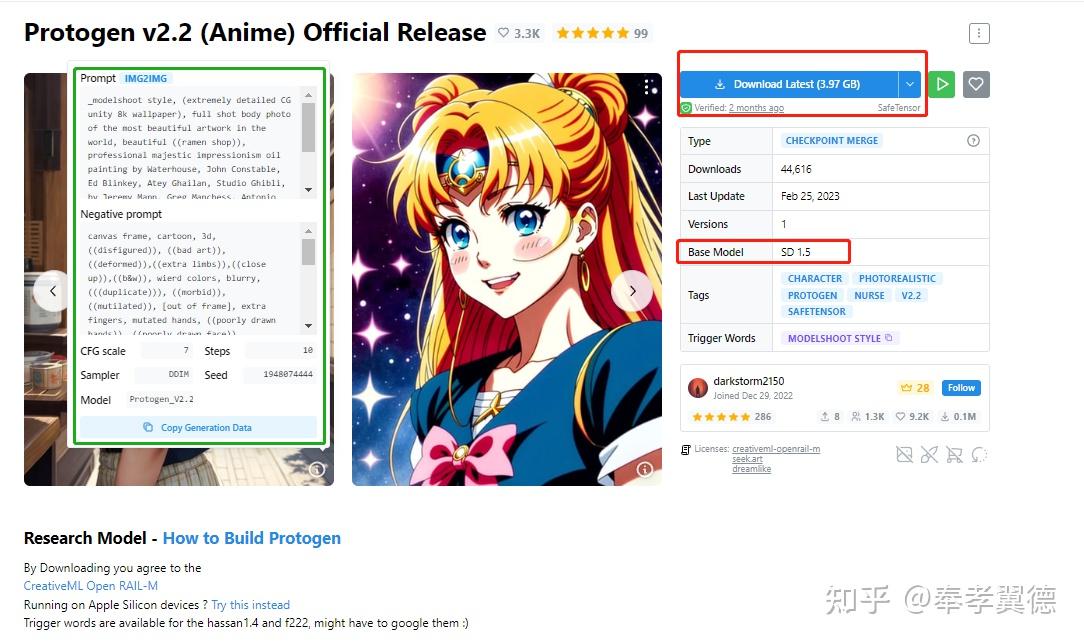
上图是用checkpoint(理解为Stable diffusion模型的格式)融合而来的一个checkpoint merge模型,右侧介绍的是它的类型,使用的底模型Stable Diffusion1.5,左侧是提示词、负面词和CFG、采样器、步数、seed等主要参数,用它就可以基本复现原图。
网站上的模型除了有大量的Stable Diffusion最原始的checkpoint模型,另外最常见的就是LoRa模型,另外还也有少部分Textual Inversion模型。
checkpoint模型大部分都是用基于精简版(prund)的Stable Diffusion1.5模型训练而来,所以,整体个头都比较大,下载下来比较占硬盘空间。
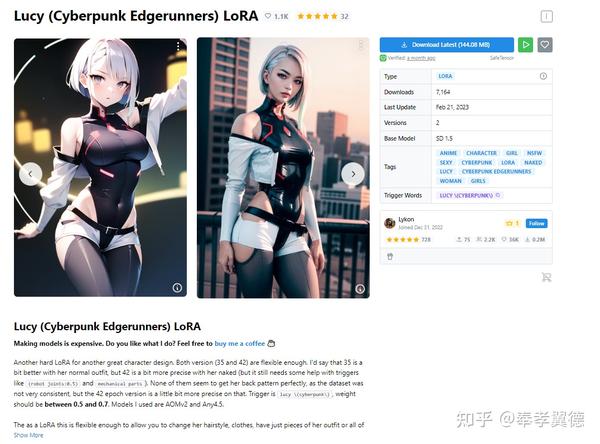

而LoRa模型的个头都比较小,常见的都是144MB左右,使用的时候要与精简版(prund)的Stable Diffusion1.5模型配合使用。
LoRa虽然个头小,但效果也非常不错,更重要的是,用它做训练占用的显存非常小,我实际用RTX 3070做训练时,显存占用维持在7GB左右。


我跟着油管博主 Aitrepreneur 的视频成功训练了一个七龙珠孙悟空的LoRa模型,明显能看出来是少儿时期的孙悟空,但是还有不少问题,从训练样本到训练参数,需要优化的空间比较多。
这里简要分享一下我学习的训练过程和需要踩的坑(就是改了个参数)。
为了降低训练门槛,这里选用的是基于Gradio做的一个WebGui图形化界面,该项目在GitHub上叫 Kohya's GUI 。

懂行的大神可以自行摸索,跳过后续的安装使用教程,不太熟悉的朋友可以接着往下看,看着参考一下。
安装Kohya's GUI
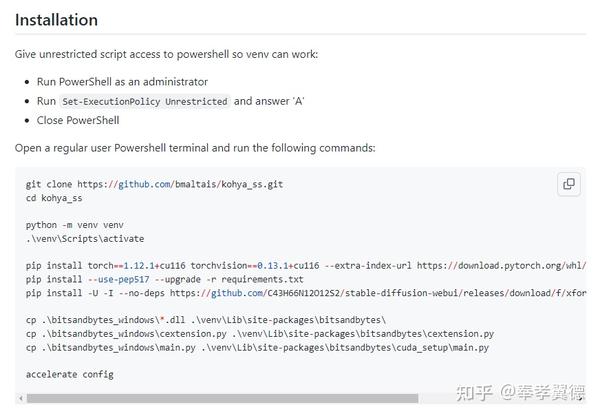
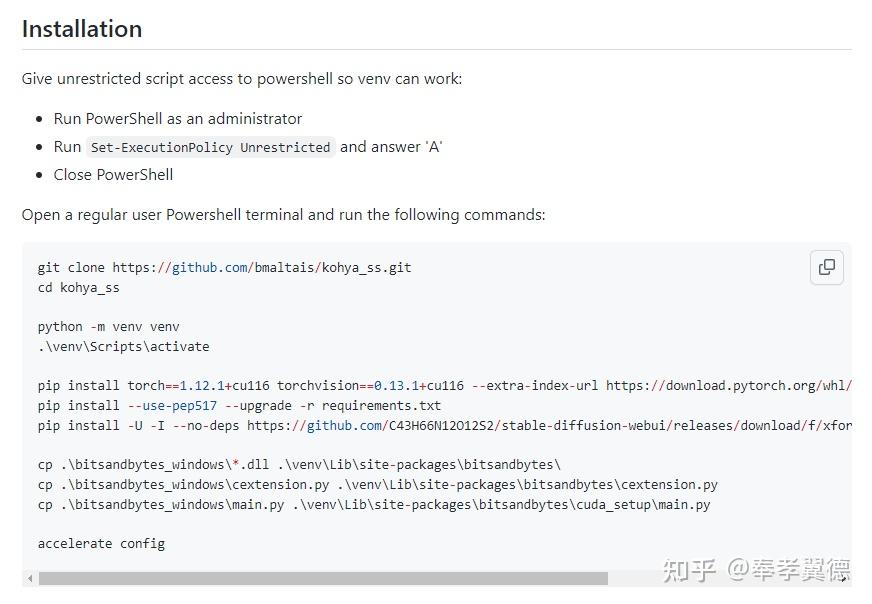
安装过程比较简单,安装环境需要Python 3.10.X版本和最新版本的Git。
1,以管理员身份打开Windows的PowerShell,输入“Set-ExecutionPolicy Unrestricted”,然后,选择“A”;
2,用git clone下载安装包,创建名为“venv”的Python虚拟环境,并激活虚拟环境;
3,此后的命令都是机器学习训练所需的环境了,按照文档提示,用pip逐个安装,逐个用cp命令复制一下即可;(需要网络代理才能正常安装)
4,最后输入:“accelerate config”命令来完成最后的配置,需要你作出几个选择:
- 选在本地运行还是在Amazon Sagemaker上运行,这里自然选本地“The Machine”了;
- 第二个选是否有分布式训练,是否多CPU训练,多GPU训练,用TPU还是MPS;
- 第三个选的是“是否只用CPU训练”,我们选NO;
- 第四个也是选NO,不用torch dynamo来优化脚本;
- DeepSpeed,也是选NO;
- 第六个选择所有GPU来做训练;
- 最后,训练精度选择FP16就行了;
至此,安装完毕了。
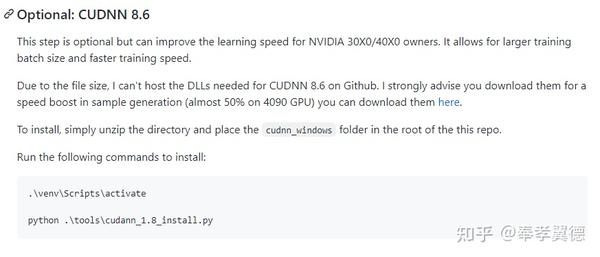

另外,对于英伟达30系和40系显卡,可以安装CUDNN 8.6来加速,下载安装包放到目录下,在PowerShell里复制上面的命令即可完成安装。
启动Kohya's GUI
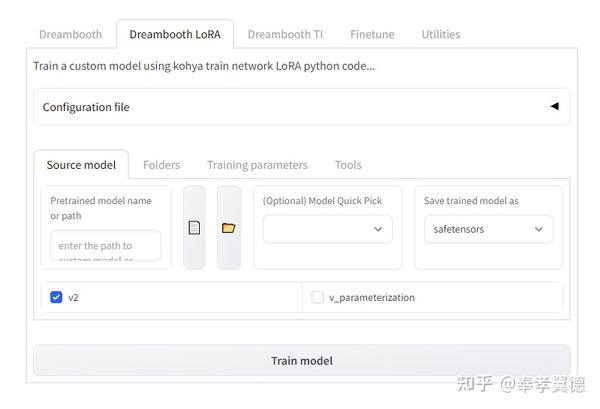
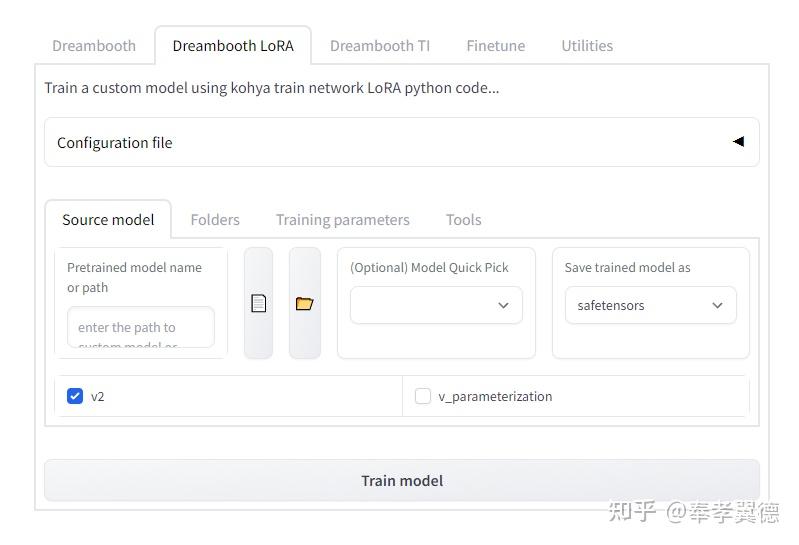
在双击安装目录里的gui.bat即可在浏览器里打开WebUI,上图是新打开的页面,我选择了LoRa标签栏,Source model我选的是stable-diffusion-v1-5,这是比较常用的模型,模型的存储格式选择默认的“safetensors”。
接下来要开始训练,要做两件事:
第一:数据预处理,准备用于训练的数据,也就是图片切割和图片标注;
第二:设置训练参数。
1,数据预处理
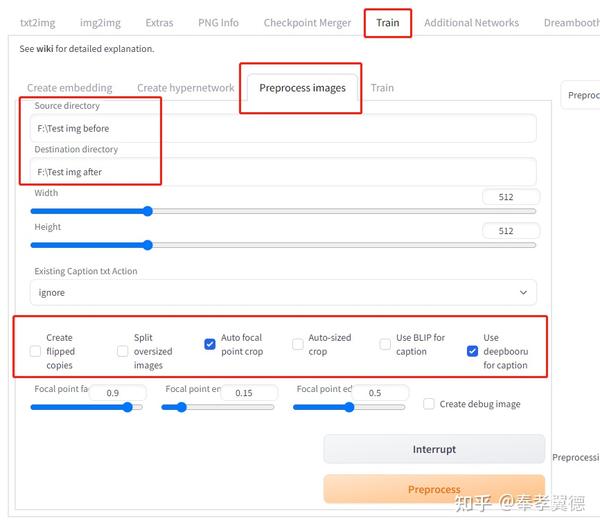

我习惯用Stable Diffusion WebUI自带的工具来做,基本设置如上图,在“Train训练”标签找到“Preprocess Image图片预处理”。
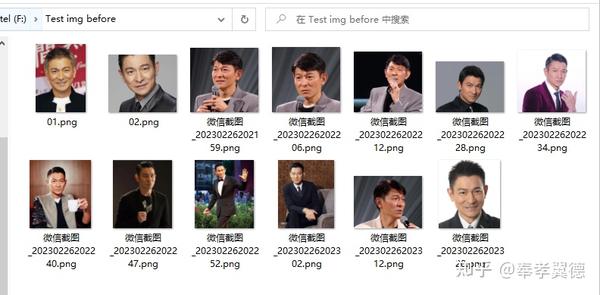

在文件夹里放入用于训练的图片,我找了几张老刘的照片,记住并在WebUI填写该文件夹路径,同时,填写一个输出路径。
然后,在WebUI的四个选项里选择一种处理图片的方法。
最后,选择BLIP或者deepbooru来生成标注数据。
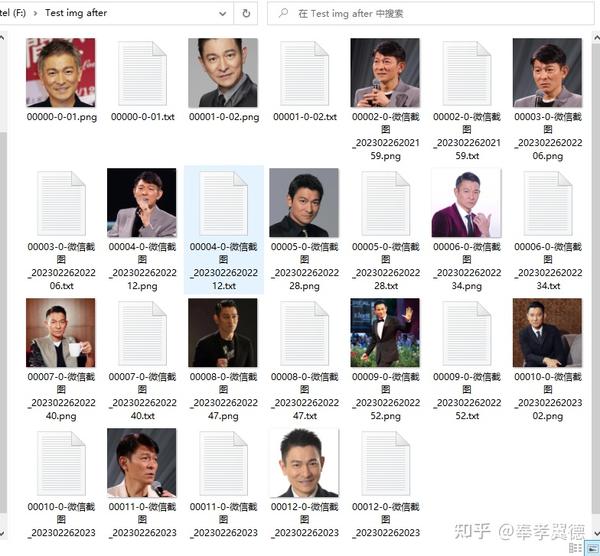

处理完后的数据,切成了512x512的正方形图片,带有自动生成的标注文件。
2,配置训练参数。
这里是重点,显存少的用户强烈推荐使用以下配置,否则很可能爆显存。
既可以用 原博主分享的配置文件 ,下载完点击载入。
也可以使用我的配置参数:
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"v2": false,
"v_parameterization": false,
"logging_dir": "F:\Test-Train-img\log",
"train_data_dir": "F:\Test-Train-img\image",
"reg_data_dir": "",
"output_dir": "F:\Test-Train-img\model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 1,
"epoch": "1",
"save_every_n_epochs": "1",
"mixed_precision": "fp16",
"save_precision": "fp16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": true,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": false,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "5e-5",
"unet_lr": "0.0001",
"network_dim": 128,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"gradient_accumulation_steps": 1.0,
"mem_eff_attn": true,
"output_name": "YunTiYanSHi",
"model_list": "runwayml/stable-diffusion-v1-5",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",
"network_alpha": 128,
"training_comment": "",
"keep_tokens": "0",
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": ""
}载入配置后,记得修改训练参数,如果使用原博主的配置,需要额外修改use_8bit_adam为False,或者在UI界面里取消勾选这一项。
另外需要修改的就是训练目录,这里也比较重要。
建议新建立文件夹,比如我这里叫Test-Train-img,在文件夹里创建image、log和model三个文件夹,其中,image里存放的图片就是预处理生成的图片。
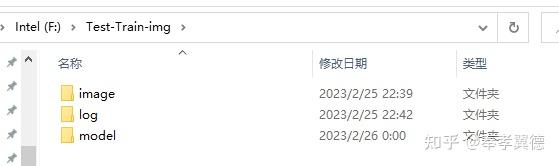

其中,image里的预处理图片不能直接放在里面,需要在里面创建一个文件夹, 文件夹的命名非常有讲究 。
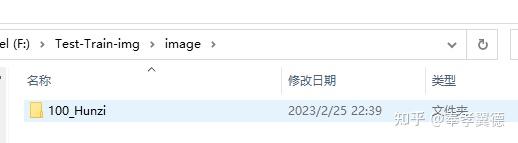

已知,LoRa的训练需要至少1500步,而每张图片至少需要训练100步。
如果我们有15张或者15张以上张图片,文件夹就需要写上100_Hunzi。
如果训练的图片不够15张,比如10张,就需要改为150_Hunzi,以此类推。
这部分很重要,一定要算清楚。
当然,这也正是LoRa强大的地方,用这么少的图片即可完成训练。
开始使用Lora模型训练
配置完成后,即可开始训练。
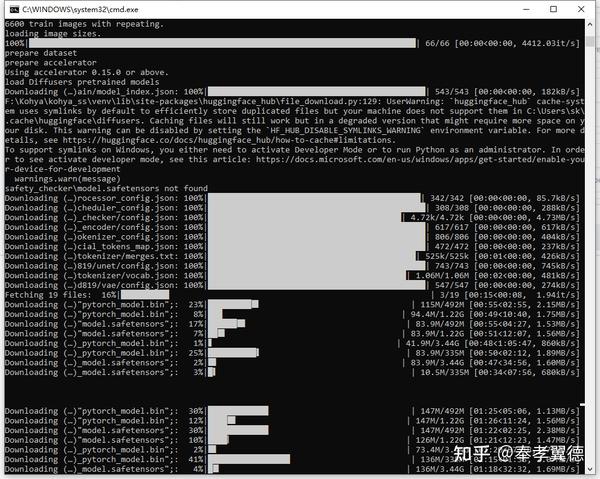

正式开始训练之前,还需要下载很多东西,这里建议设置好代理,否则可能会有别的问题。我自己没碰到,就不说了。
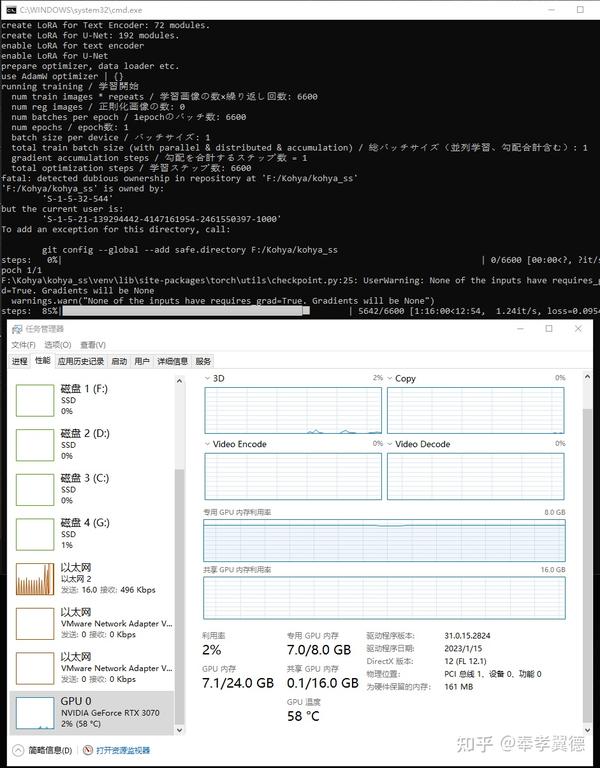

如何使用LoRa模型
训练完成后的模型放到模型文件夹里的Lora文件夹,然后在新版的Stable Diffusion WeuUI里点击“Show Extra Network”按钮。
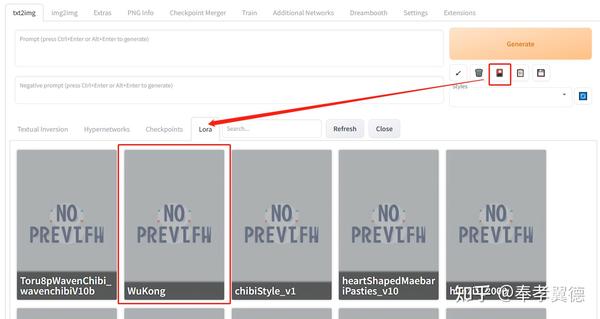

在Lora标签里选择刚生成的Lora模型,然后就会在上方Prompt提示符里显示Lora模型已经使用,通常是以尖括号的形式引入的。
其他提示词按照你自己的需要填写进去即可开始生成图片。






有小伙伴问3090大显存用户用什么配置,本来,没用过大显存的我无话可说。
但是,视频博主还分享了一组基础配置,对显存没什么困扰的朋友可以点 这个链接 。
或者用我原封不动复制过来的配置参数:
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"v2": false,
"v_parameterization": false,
"logging_dir": "C:/Users/ohmni/AI/SAMPLE IMAGES/ADAMS/LORA OUTPUT/log",
"train_data_dir": "C:/Users/ohmni/AI/SAMPLE IMAGES/ADAMS/LORA OUTPUT/img",
"reg_data_dir": "",
"output_dir": "C:/Users/ohmni/AI/SAMPLE IMAGES/ADAMS/LORA OUTPUT/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 2,
"epoch": "1",
"save_every_n_epochs": "1",
"mixed_precision": "bf16",
"save_precision": "bf16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": false,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "5e-5",
"unet_lr": "0.0001",
"network_dim": 128,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"gradient_accumulation_steps": 1.0,
"mem_eff_attn": false,
"output_name": "Addams",
"model_list": "runwayml/stable-diffusion-v1-5",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",