

分区表是指拥有分区空间的表,即在创建表时指定表内的一个或者某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立的文件夹,一个分区对应一个文件夹,文件夹下是对应分区所有的数据文件。
概述
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。
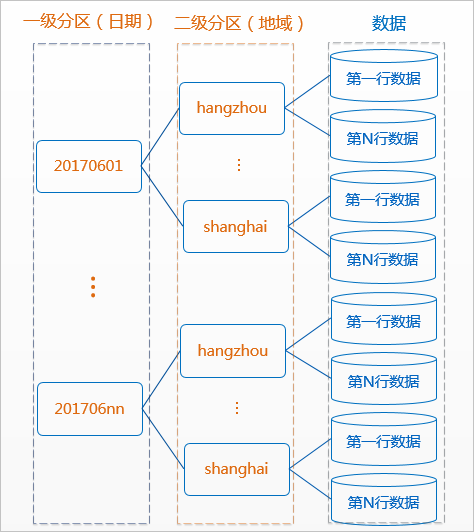
MaxCompute将分区列的每个值作为一个分区(目录),您可以指定多级分区,即将表的多个字段作为表的分区,分区之间类似多级目录的关系。
分区表的意义在于优化查询。查询表时通过WHERE子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。使用数据时,如果指定需要访问的分区名称,则只会读取相应的分区。
部分对分区操作的SQL的运行效率较低,会给您带来较高的费用,例如 插入或覆写动态分区数据(DYNAMIC PARTITION) 。
使用限制
- 单表分区层级最多为6级。
- 单表分区数最大值为60000个。
- 单次查询允许查询最多的分区个数为10000个。
- STRING分区类型的分区值不支持使用中文。
使用说明
分区数据不宜过小,如果创建很多过小分区,会导致计算查询性能下降。建议单分区数据不要小于一万行。
分区列的数据类型
MaxCompute 2.0数据类型版本支持的分区字段为TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING。
MaxCompute 1.0数据类型版本支持的分区字段仅有STRING。虽然可以指定分区列的类型为BIGINT,但是除了表的字段显示为BIGINT类型,任何其他情况(例如,字段的计算和比较)下都当作STRING类型处理。执行如下语句后,返回的结果只有一行。
---创建表parttest。
create table parttest (a bigint) partitioned by (pt bigint);
---向表中插入数据。
insert into parttest partition(pt)(a,pt) values (1, 1);
insert into parttest partition(pt)(a,pt) values (1, 10);
---查询表中字段pt大于等于2的行。
select * from parttest where pt >= '2';示例
-
创建分区。
--创建一个二级分区表,以日期为一级分区,地域为二级分区 CREATE TABLE src (shop_name string, customer_id bigint) PARTITIONED BY (pt string,region string); -
使用分区列作为过滤条件查询数据。
--正确使用方式。MaxCompute在生成查询计划时只会将'20170601'分区下region为'hangzhou'二级分区的数据纳入输入中。 select * from src where pt='20170601'and region='hangzhou'; --错误的使用方式。在这样的使用方式下,MaxCompute并不能保障分区过滤机制的有效性。pt是STRING类型,当STRING类型与BIGINT(20170601)比较时,MaxCompute会将二者转换为DOUBLE类型,此时有可能会有精度损失。 select * from src where pt = 20170601;