利用自己的数据集训练MobileNetSSD建立模型,并基于caffe-ssd实现

折腾了一段时间,终于将自己的数据集成功建立了MobileNetSSD模型,并在caffe-ssd下成功实现,下面和大家一起分享下我实现的过程,并欢迎大家一起讨论。
一、前提
1、在ubuntu系统下安装caffe-ssd,这一过程不清楚的地方可以参考我之前的一篇文章,也可以参考下面链接的文章:
https:// blog.csdn.net/qq_334313 68/article/details/84866166
2、用自己的数据集制作图像VOC数据集,用下面链接的工具:
https://github.com/imistyrain/MRLabeler.git下载好后,里面有详细的操作说明。
二、下载MobileNetSSD,测试demo
1、输入
git clone
https://
github.com/chuanqi305/M
obileNet-SSD.git
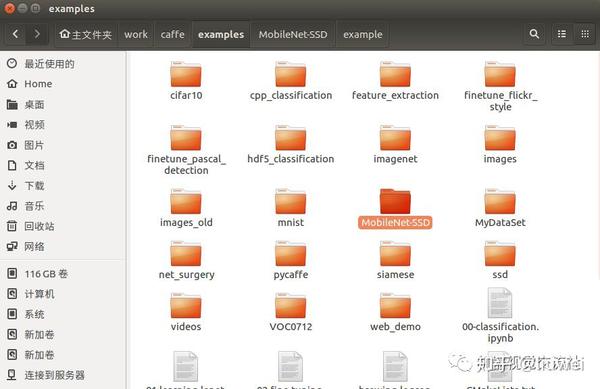
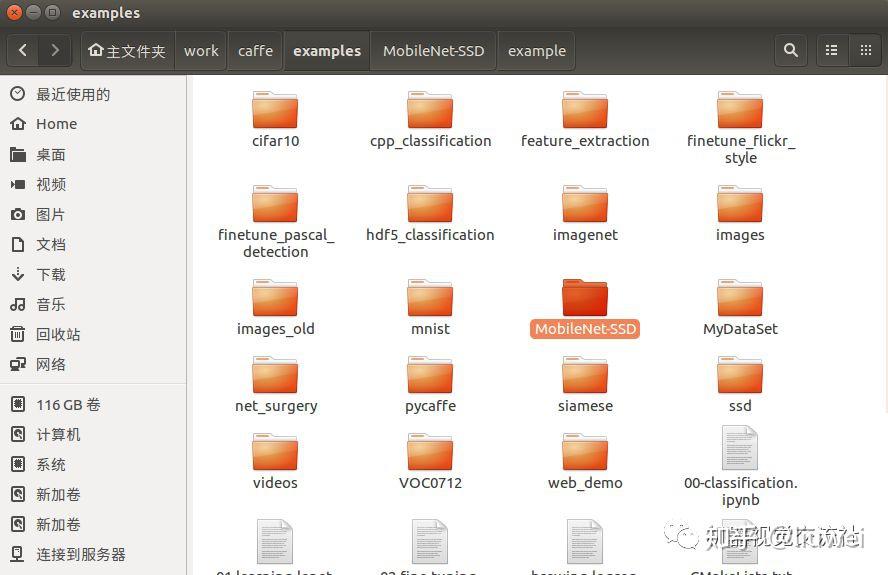
下载MobileNetSSD,并把它包放在caffe/examples/中,如下图:
2、MobileNet-SSD文件夹中文件简要说明
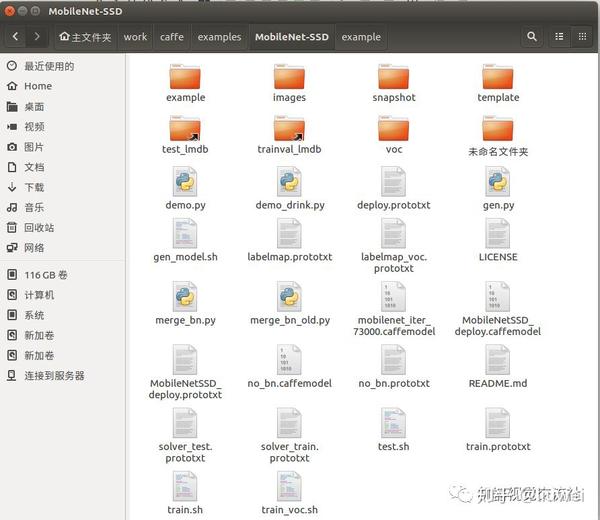
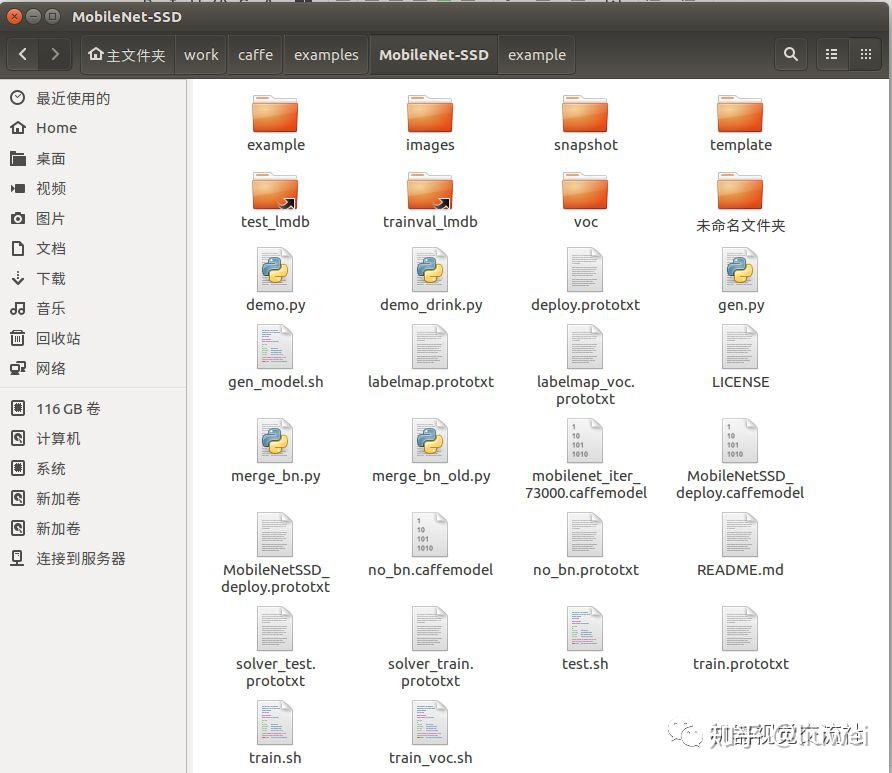
1)、images 测试图片所存放位置
2)、template 存放网络定义的公用模板train/test/deploy.protoxt,由gen.py脚本修改并生成,主要是因为label个数不一样所以这里的网络结构的前面几层和后面几层少许不同,这个需要我们后续训练自己数据集的时候利用gen_model.sh脚本生成。
3)、voc 存有三个根据VOC数据集生成的网络文件和一个网络超参数train文件
demo.py 实际检测脚本(图片存于images文件夹)只针对单张图片,做成视频就是一帧帧图片遍历
4)、deploy.prototxt 运行网络定义文件,demo.py中调用.
-(和template/MobileNetSSD_deploy_template.prototxt相似)
5)、gen.py 生成公用模板脚本(没有用到)
6)、gen_model.sh 生成自定义网络脚本---生成template中类似的文件(训练自己的数据集时需要用到)
7)、merge_bn.py 合并bn层脚本,用于生成最终的caffemodel(因为mobilenet有两个层最后需要合并才能得到deploy.caffemodel)
8)、mobilenet_iter_73000.caffemodel 预训练模型
9)、solver_test.prototxt 网络测试超参数定义文件
10)、solver_train.prototxt 网络训练超参数定义文件
11)、test.sh 网络测试脚本
12)、train.sh 网络训练脚本
13)、train.prototxt 训练网络定义文件 和template中的train定义网络文件相似
14)、train_voc.sh 针对voc文件里的超参数文件和网络文件的训练脚本
3、测试demo
1)、测试之前要下载MobileNetSSD_deploy.caffemodel和MobileNetSSD_deploy.prototxt,第一个文件需要翻墙下载,第二个需要CSDN积分下载,如果大家怕麻烦,可以联系我。
2)、修改demo.py里面的路径
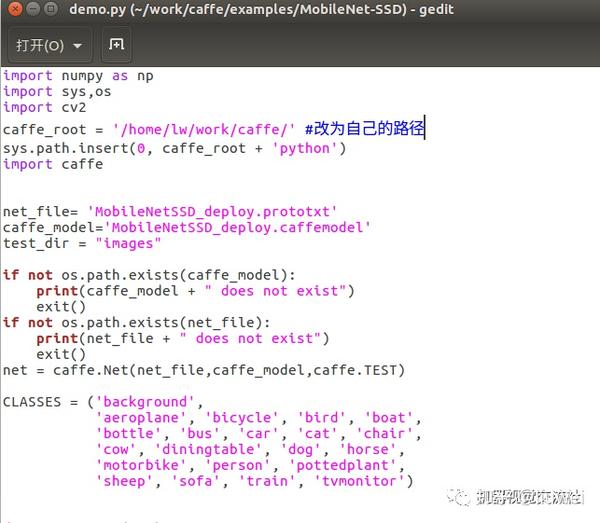
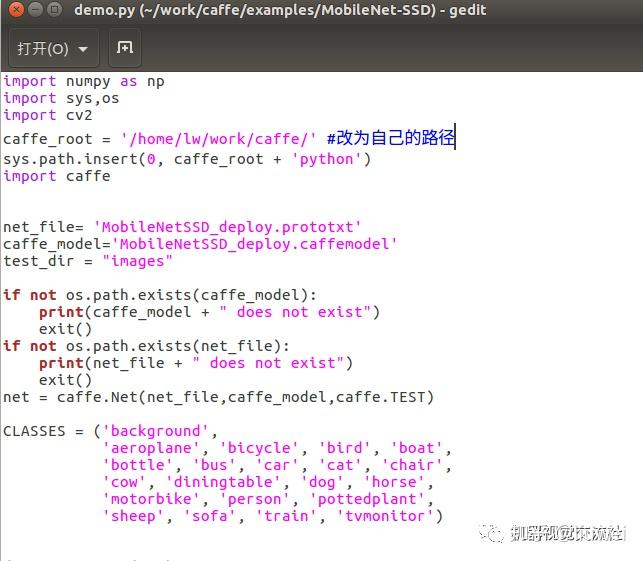
3)、按照下图,输入命令测试


结果:

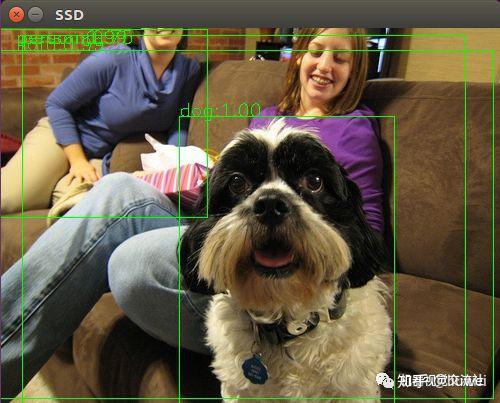
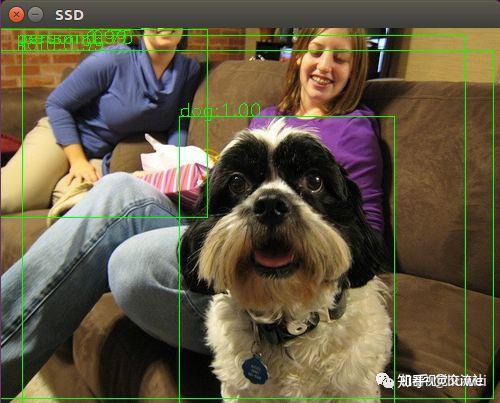
三、利用自己的数据集训练自己的MobileNetSSD model
1、在caffe/data中新建一个MyDataSet文件夹,将前面标注好的数据集中两个文件夹Annotations (利用标注软件生成对应的xml文件)和JPEGImages (原始图片)拷入MyDataSet文件夹。
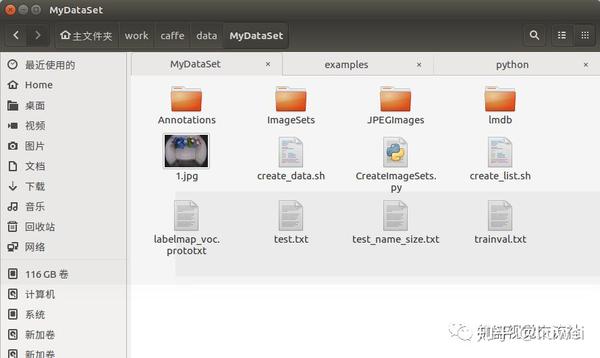
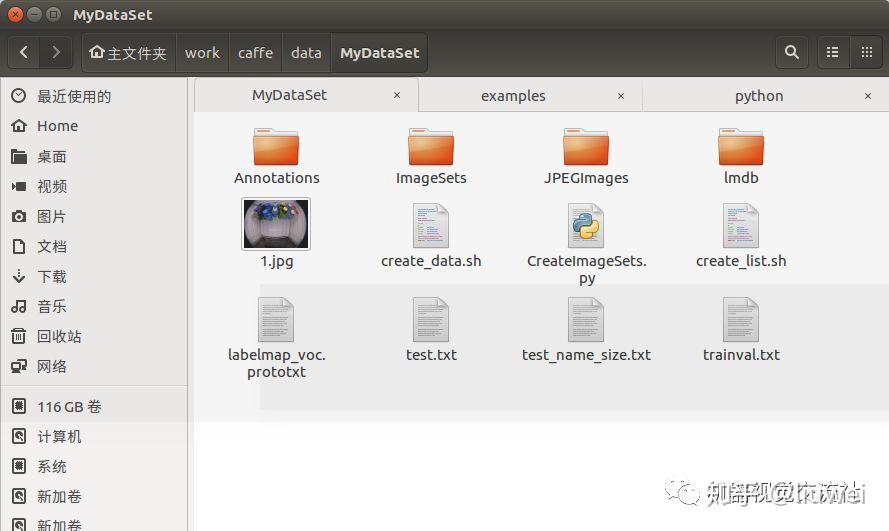
2、生成索引txt文件
利用以下代码,生成ImageSet文件夹,此文件夹目录下包含Main文件下,在ImageSets\Main里有四个txt文件:test.txt train.txt trainval.txt val.txt;分别是测试数据集索引(也就是各个测试图片的名称,相对路径)、训练数据集、训练验证数据集、验证数据集
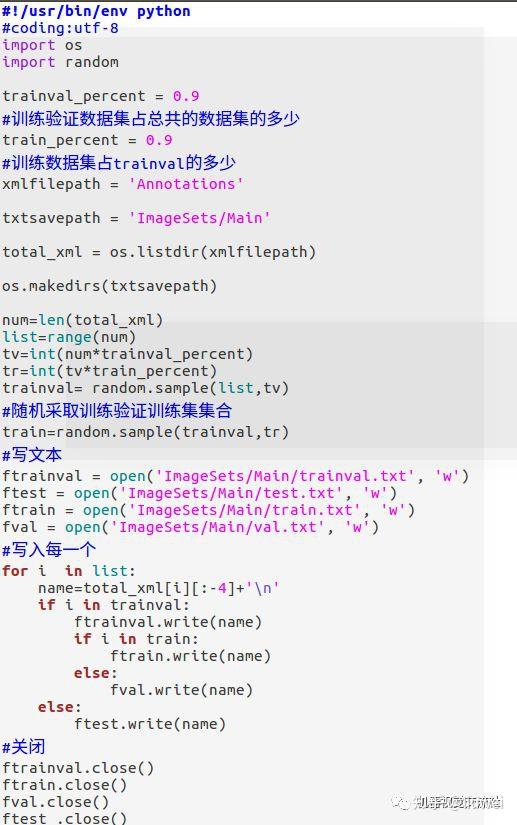
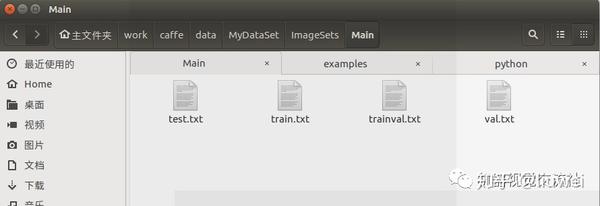
执行文件得到四个txt文件,结果如下:


3.生成lmdb格式文件(caffe输入格式)
在VOC0712文件夹中把以下几个文件拷贝到MyDataSet中
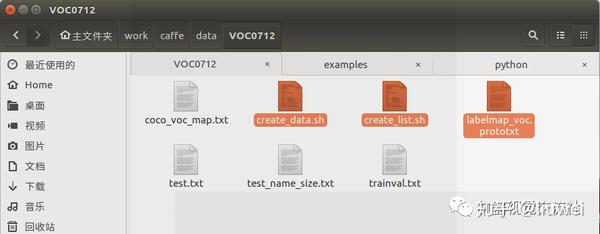
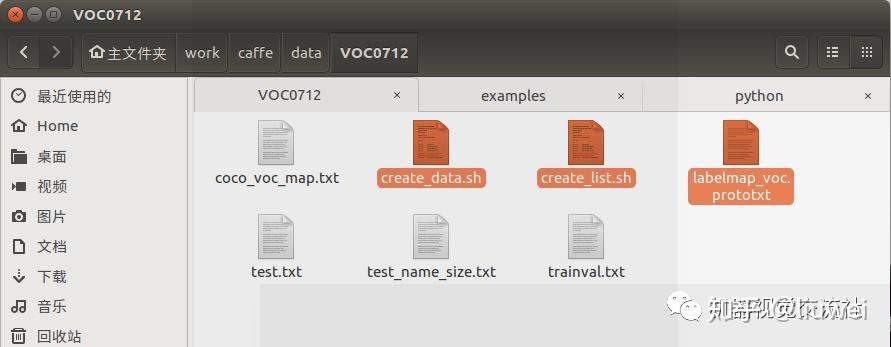
此时MyDataSet文件中情况为:
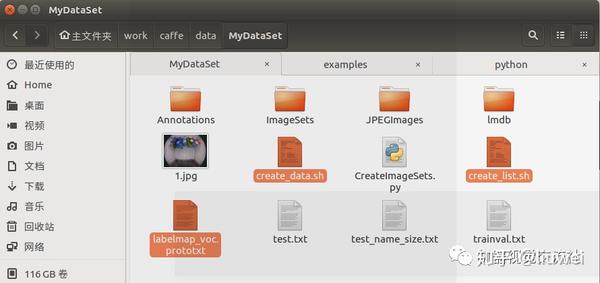
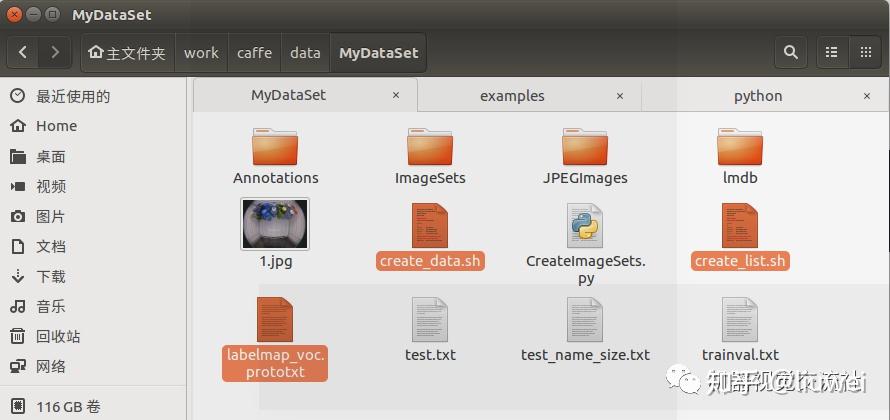
更改这三个文件(更改后的如下):
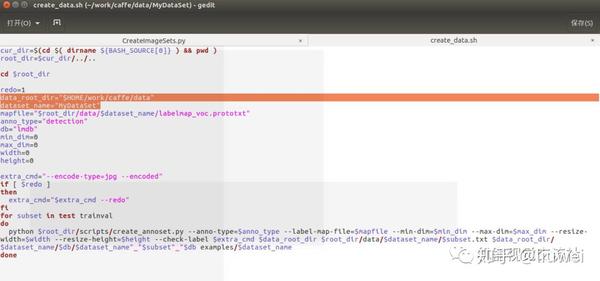
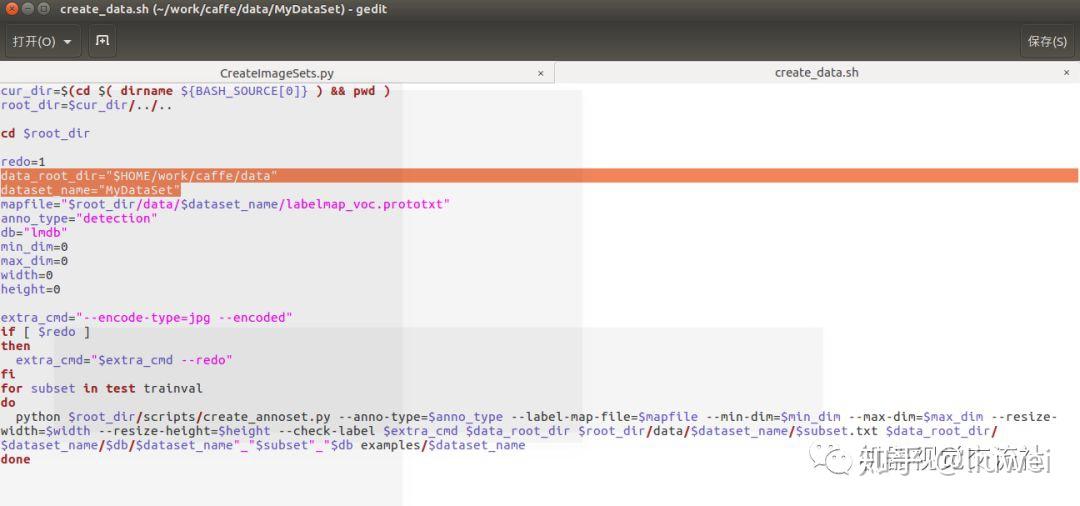
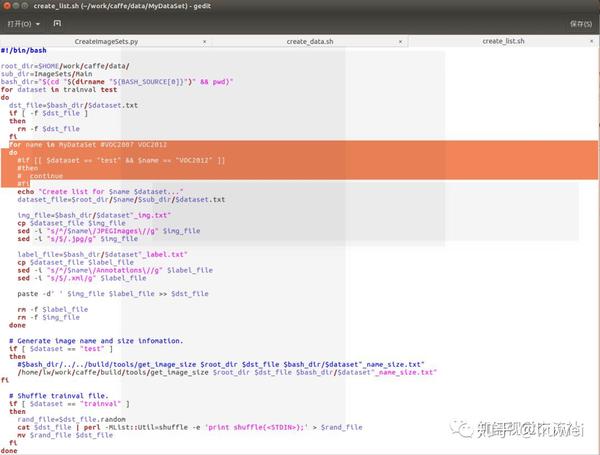
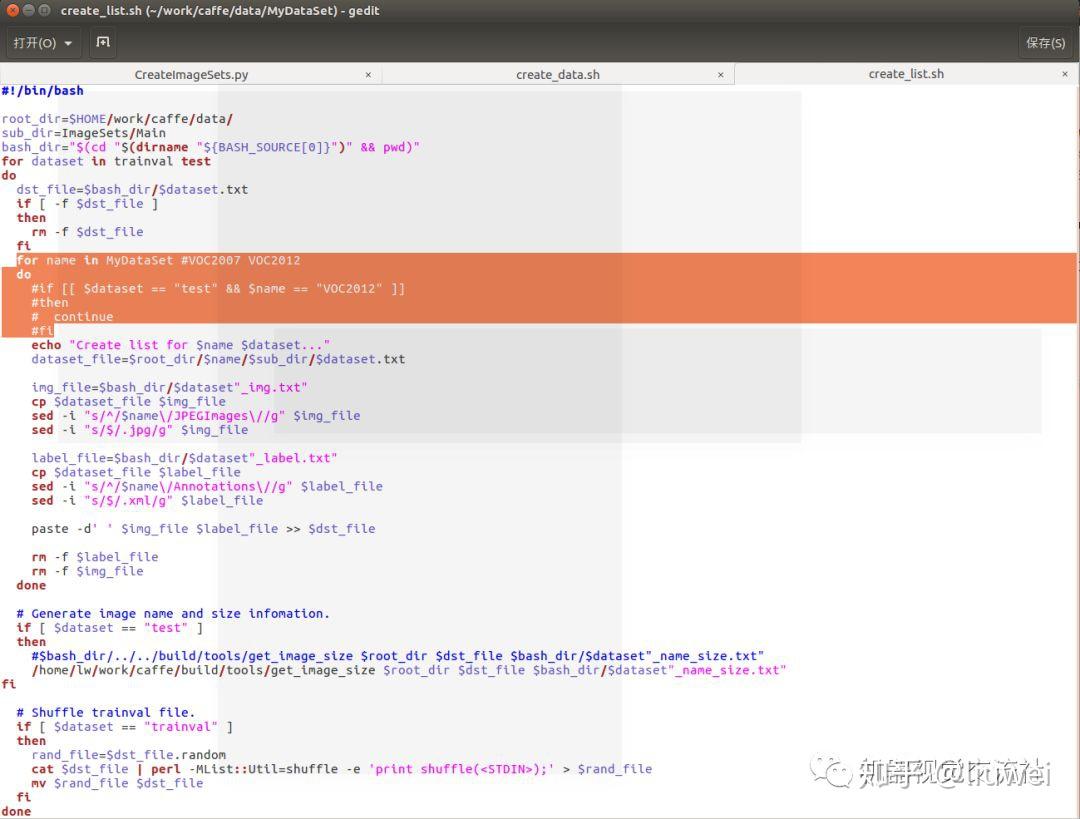
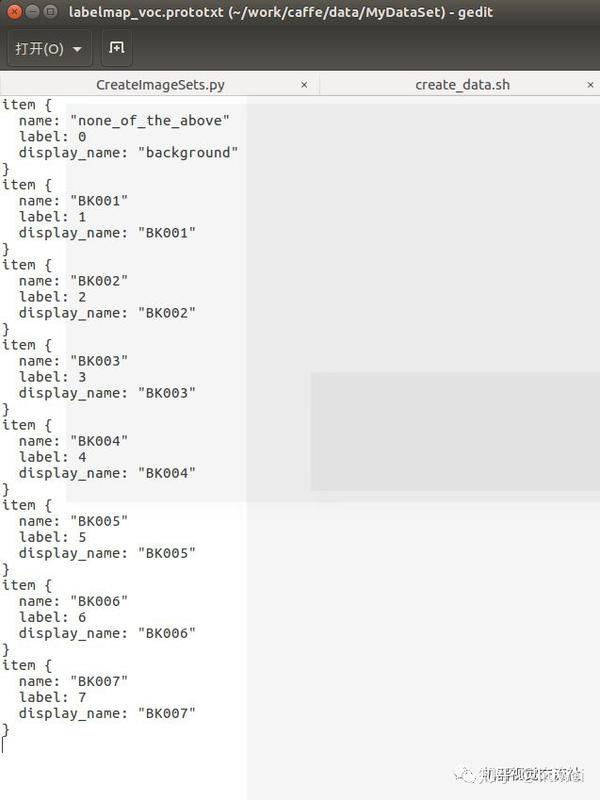
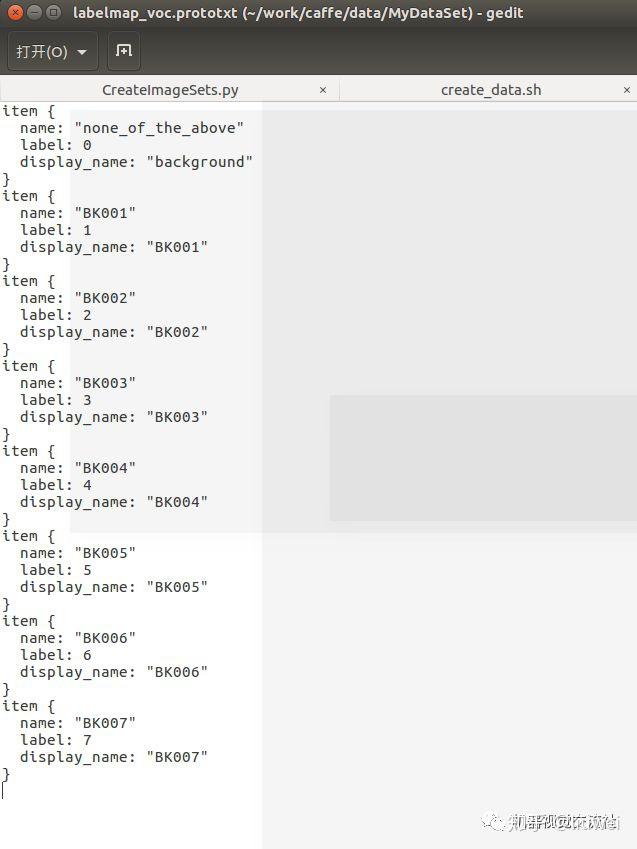
更改好后依次执行
cd caffe/data/MyDataSet
create_list.sh
create_data.sh
得到结果:
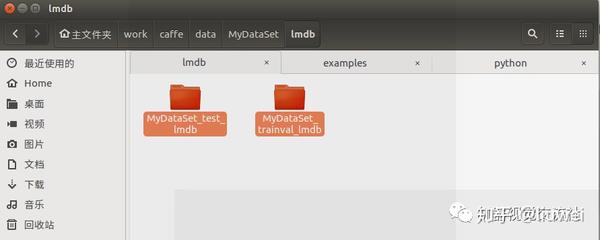
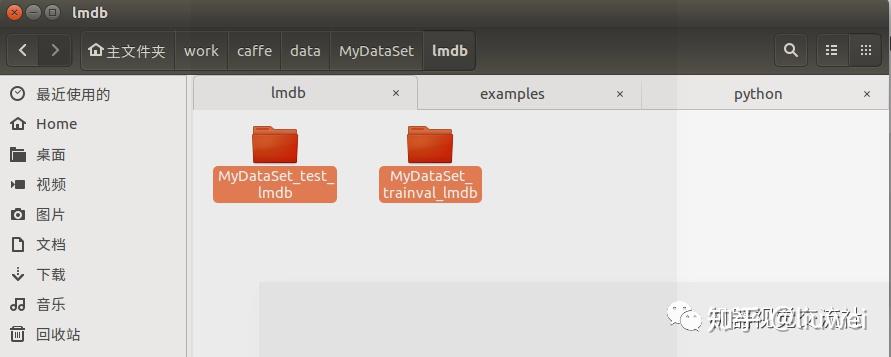
在caffe/examples中有个与MobileNetSSD平级的目录MyDataSet
里面为lmdb文件夹的超链接文件,后续训练使用。
4.利用MobileNetSSD进行训练
1)、在MobileNetSSD文件中建立自己的labelmap.prototxt, 内容和之前 labelmap_voc.prototxt一样)
2)、建立自己对应label个数的train/test/deploy网络文件,执行下面的命令:
gen_model.sh 7 #7对应label 的个数,加上backgroud 就8个label
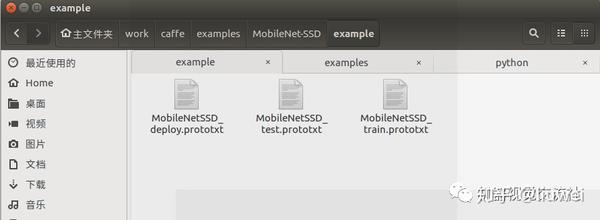
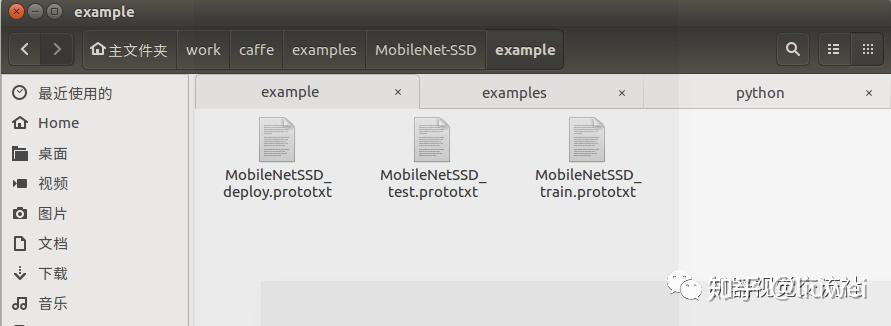
这里一定要注意自己数据集中的类别数。文件中生成一个example文件,里面就是所生成的网络定义文件。
3)、利用下面的命令建立数据集的超链接
ln -s PATH_TO_YOUR_TRAIN_LMDB trainval_lmdb
ln -s PATH_TO_YOUR_TEST_LMDB test_lmdb


结果MobileNetSSD下出现两个超链接文件:
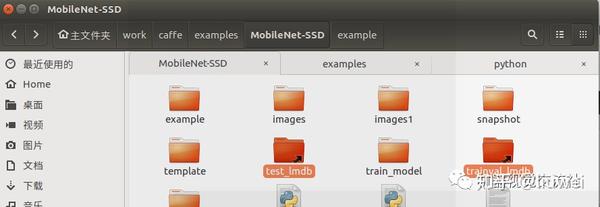
5、执行train.sh 进行训练,得到结果:
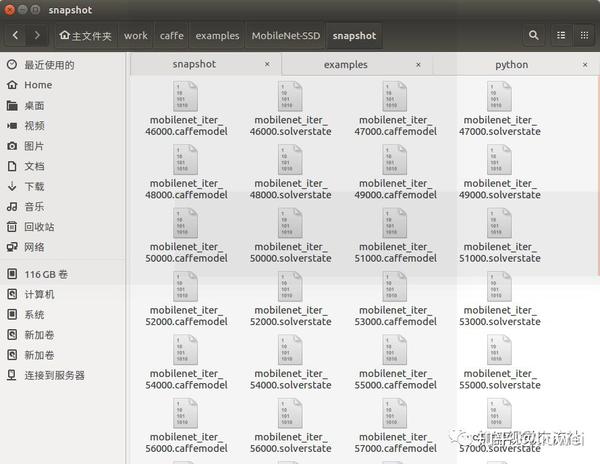
6、合并成最终的model,以及测试
因为MobileNet中有bn和scale层,最后生成deploy需要进行一步操作,此处运用merge_bn.py文件。
这里使用的是迭代训练50000次得到的模型来进行bn层的合并,以获得最终的模型。
python merge_bn.py --model ./example/MobileNetSSD_deploy.prototxt --weights ./snapshot/mobilenet_iter_50000.caffemodel
此时会发现,MobileNet-SSD中多出了一个no_bn.prototxt文件和一个no_bn.caffemodel文件,这就是我们想要获得模型文件和参数文件了。
修改demo.py,进行测试
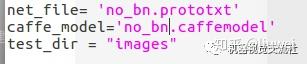
结果如下:


欢迎大家一起交流。