


驱雷掣电——深度强化学习在电网调度任务中应用浅析

什么是电网调度任务?
众所周知,国家电网公司一共拥有五级调度机构——国调、网调、省调、地调、县调。这五级调度机构由于管辖的范围和权限不同,在实际的工作中的职责重点也会不同。不过总体而言,他们负责的工作就是指挥电网各部门,保证电网的安全稳定运行。层级较低的调度机构更关注具体的设备和对象(比如指挥倒闸操作),层级较高的调度机构则倾向于进行某些宏观的操作与判断(比如分析某省的弃风率为何居高不下)。
关于调度员的日常工作,有很多知乎文章进行过分享:
这个同学写的情况都很还原,电网调度员是一个相当辛苦的工作。需要承担电网的各种指挥、各种文牍工作,甚至在某些时候还要与其他单位勾心斗角……不过在这篇回答我们主要关注调度员需要应对的某些突发的紧急事件。
电网是一个极端重要、极端需要保证安全性的复杂系统。每个人都离不开夏天的空调、冬天的电暖器、房子中的WIFI……这一切都需要稳定的电力供应。像军队、医院这种有重大意义的特殊机构对电网稳定供应的要求就更高了。电网可能遇到各种各样、有意无意的冲击,比如网络攻击、异常负荷、人员失误、天灾等……我们每个人能吃到夏天的冰西瓜,背后都有无数个电网工作者通过默默的付出把这些安全隐患消弭于无形。
在这样的突发情况下,电网调度员要承担的,在危机时刻做出正确判断的压力是很大的,我举一个栗子。


2015年,广东电网遭遇台风“彩虹”袭击,许多输电线路跳闸,无法把电能从供给端输送到负荷端。
据南方电网全资子公司广东电网通报,截至10月4日15时,受台风“彩虹”影响,广东电网500kV线路跳闸2条,220kV线路跳闸12条,110kV线路跳闸6条,10kV线路跳闸359条。
在这种情况下,在事前计算出的电网运行方式都已经不再可行了,调度员需要综合多个目标(保证重要用户供电、保证电网不解列、尽量少切负荷、尽快恢复到正常的网架结构),做出最优的判断。
打个比方,电网调度员是一名火车司机,日常的工作是把火车从A地开到B地,所有的路线都是已经规定好,重复走过无数次的成熟路线。


突然某天,很多铁轨被龙卷风卷到了天上。调度员现在需要依靠对火车的手感和一些理论计算,来找出一条之前不太采用的新路来,稳稳当当地把火车依旧开到B地。
据我所听说,某位在某省会调度认知的学长就曾经遇到过不得不依靠个人经验挺身而出拯救世界的情况。当时该省会城市的电网遭遇了某种冲击,由于这种冲击刚好击中了电网的薄弱点。整个城市的电网变得极其不稳定,电压的波动尤为剧烈,甚至当时城市中某些区域的路灯都开始按照某种频率发生忽明忽暗的亮度变化。这种波动沿着输电线路传导,让整个城市的路灯都产生了某种奇妙的明暗共振。当然,路灯明暗变化只是一种现象,背后体现的是整个城市的电压都在失稳的边缘,传统的一些电压和频率稳定的手段已经不足以保护电网安全了。
在这个紧要时刻,这位调度员学长依靠学校的理论积累+长期调度上值的工作经验,做出了准确判断,切除了某些机组和某些负荷,维持住了整个城市能源供应命脉的大体稳定。这位学长也依靠其临危不乱的操作被领导看重,走上了升职加薪的巅峰道路。
为什么电网调度任务需要强化学习
尽管我很爱讲段子,但是上文的故事不仅仅是个段子。我希望表达的是,尽管我国的电网技术独步全球,但是在某些情况下,依然还有不能够,或者来不及,依靠某些固定化的计算工具来解决的问题。这种情况下,能够依靠的只有调度人员的知识、经验、智慧、反应力、领导力甚至孤勇。而在电网调度领域推某些AI工具的初心就是让调度员们可以不用再去面对这样让人肾上腺素爆发的紧急情况。要知道,如果做出了正确的调度命令固然皆大欢喜,可是如果出现了什么差池,城市会因为停电而受到巨大损失,调度员自身也会失去自己的职业生命。
举一个不是100%恰当的例子。
汶川地震时,为了进行通信,需要空降兵冒死跳伞进入灾区建立通信链路。而这次河南的洪灾,利用翼龙无人机就可以稳定的保障通信了——技术进步让我们不再需要依靠英雄们的付出来保障集体利益。


在实际的电网调度任务中,其实调度员有非常多的仿真工具和计算工具可以利用。他们在做出判断时,会在非常大的程度上依赖这些工具。
不过,尽管电网的仿真准确成熟,但是很难解决随机性/突发性的问题。老调度员在进行操作的时候,往往也会依靠自己的直觉(intuition)与经验。这让某些科研人员陷入了沉思——既然电网的操作本身有靠“直觉”的成本,而AI技术其实某种意义上说,就是通过天量的训练,在特定的任务上还原这种直觉。而建立这种直觉的工具——深度神经网络,其实很多读者都已经在其他的任务,比如图像识别中,了解过了。
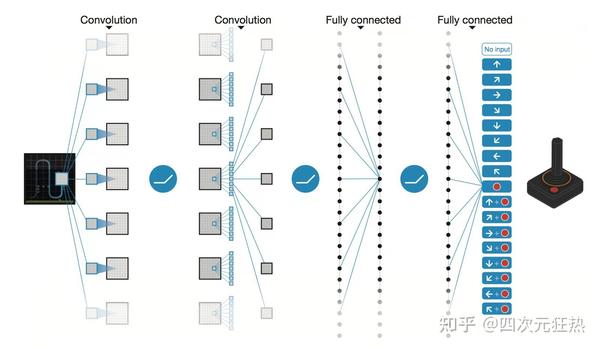
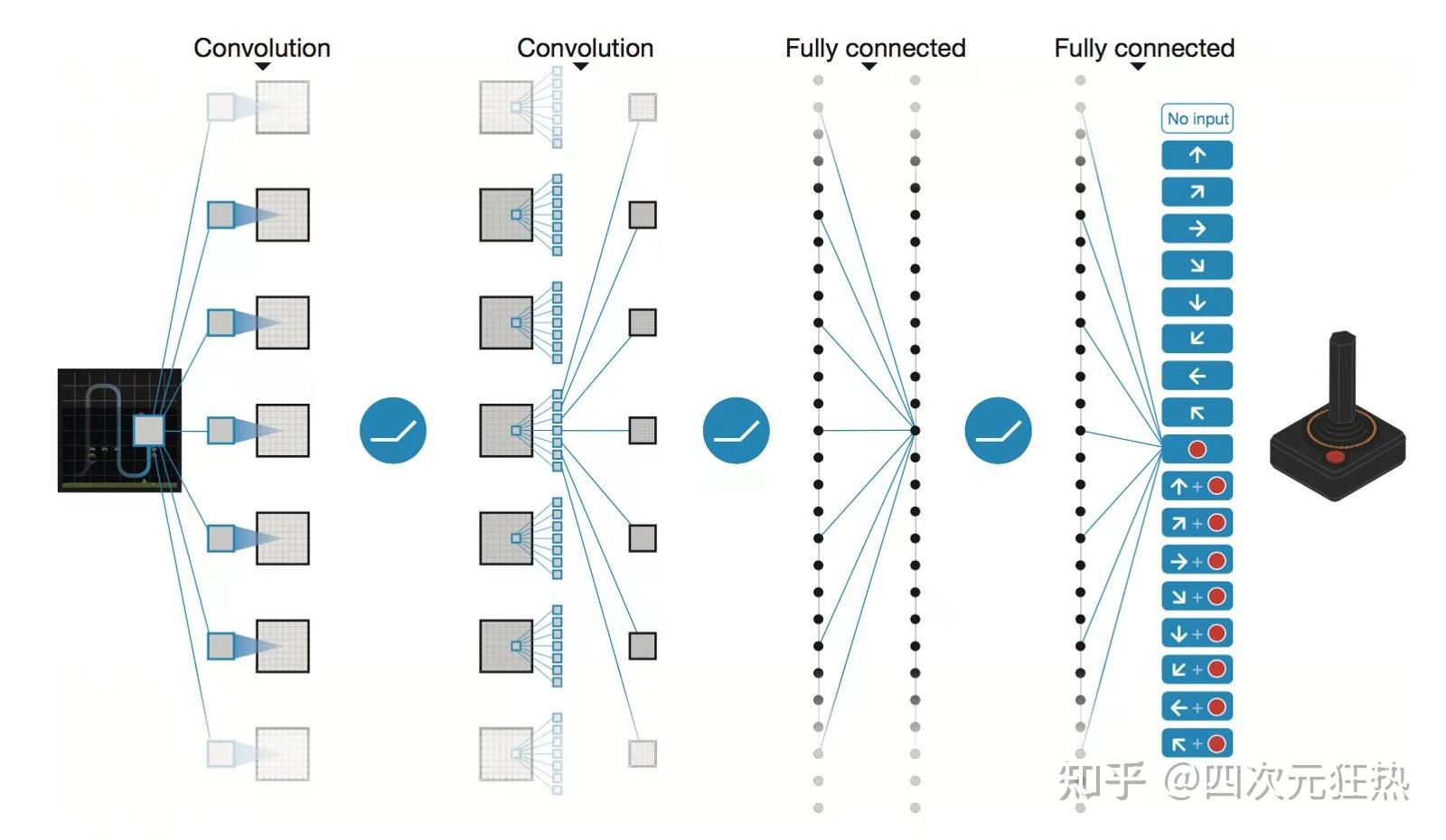
那我们能否借助已经成熟的仿真工具,投入大量算力,不断地从各种情境中学到这种“直觉”,进而把电网的调度员从某些繁琐or紧急的任务中解放出来?
另外一个对更智能更强大算法有强烈需求的点,是碳达峰和碳中和的新任务。在习近平主席提出了2030年碳达峰和2060年碳中和之后,电力系统的工作者做了非常多的讨论。
主要的感觉是——太难了。
碳中和意味着构建一个全新的,以非碳能源(风电光伏光热核电水电)为主体的全新电力系统。这和我们传统的以火电为主体,其他能源为辅助的现状有着天壤之别。
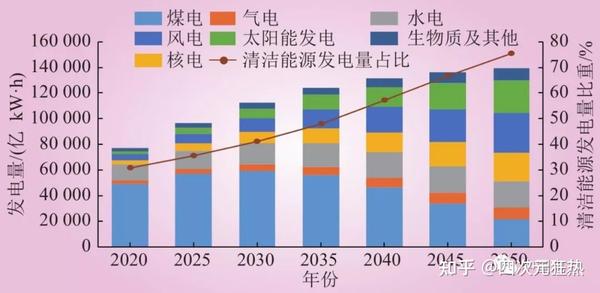
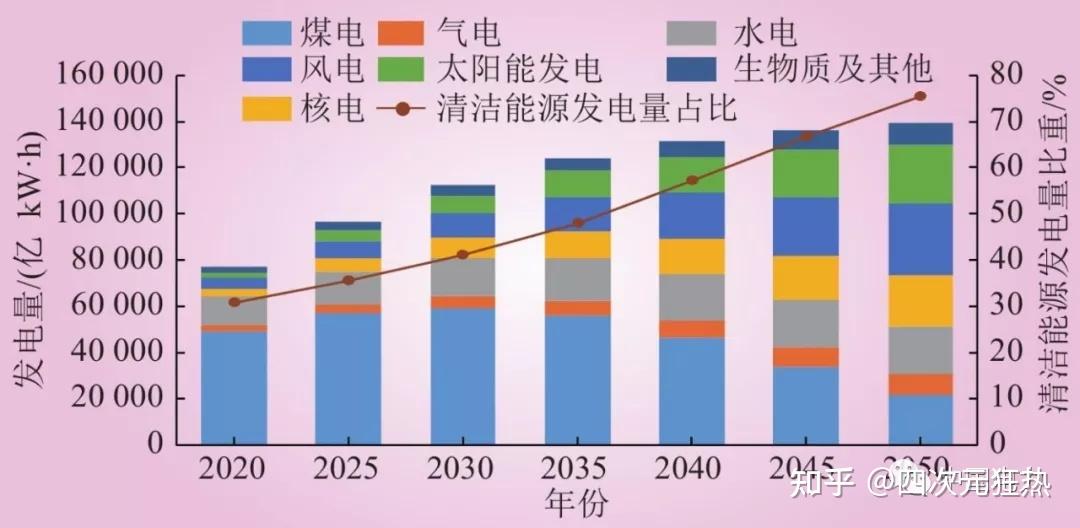
火电意味着安全、稳定和可操控。和火电比起来,核电站出现过几个令全世界侧目的安全事故;水电站的建设有生态影响,同时水库除了发电还要承担防洪、灌溉等任务;风电和光伏都是看天吃饭,不确定性很高;潮汐、地热、生物质能还看不到大规模应用的希望。目前看来,最有可能成为碳中和主体的能源形式是光伏和风电。
要注意的是,风电和光伏的引入不仅仅带来了不确定的发电出力,同时还会给电力系统带来大量的直流输电和电力电子设备。怎么样处理好一个更不确定、稳定性和惯量更低、直流和交流混合、大量电力电子设备和储能设备接入、甚至还有相当程度的可控负荷存在,并且受电力市场影响极深的新型电力系统?尽管还没有一个一定的答案,但是更智能、更强大的调度算法一定是这个系统中不可或缺的一环。深度强化学习有希望成为这个环节中的key。
深度强化学习
深度强化学习想要解决的本质问题是马尔可夫决策问题(Markov Decision Process, MDP):基于状态通过动作与环境交互,最大化累计奖励。
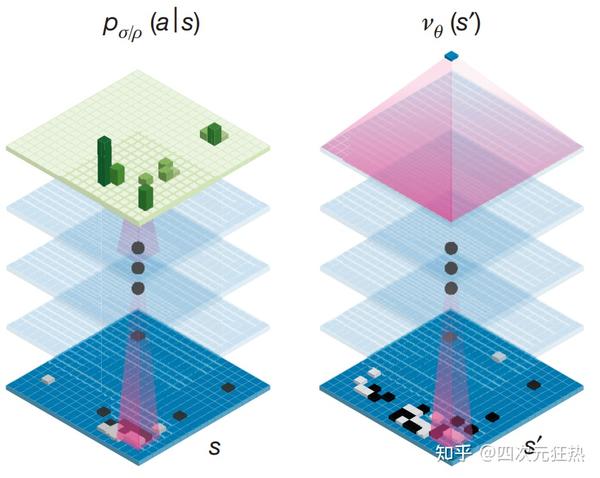
深度强化学习在近些年取得的最出名的成果应当是AlphaGo。
围棋问题的最大难点在于其爆炸庞大的状态空间——我们无法通过穷举局面来得到一个特定回答。而AlphaGo通过极大数量的训练,建立了一种基于当前局面,对不同位置落子进行价值判断的方法,加上有限步数的模拟,把穷举问题缩小为可以通过贪心算法(或者蒙特卡洛搜索树)求解的,计算资源要求可以接受的新问题。[2]


从最原始的AlphaGo到最终版本的AlphaGo Zero,AlphaGo家族的架构与算法一直在发生变迁。然而其中最核心的思路始终保持未变:通过大量的比赛模拟,建立一种对于当前棋盘局面与不同落子位置的价值判断,从而迭代地把棋局进行下去。
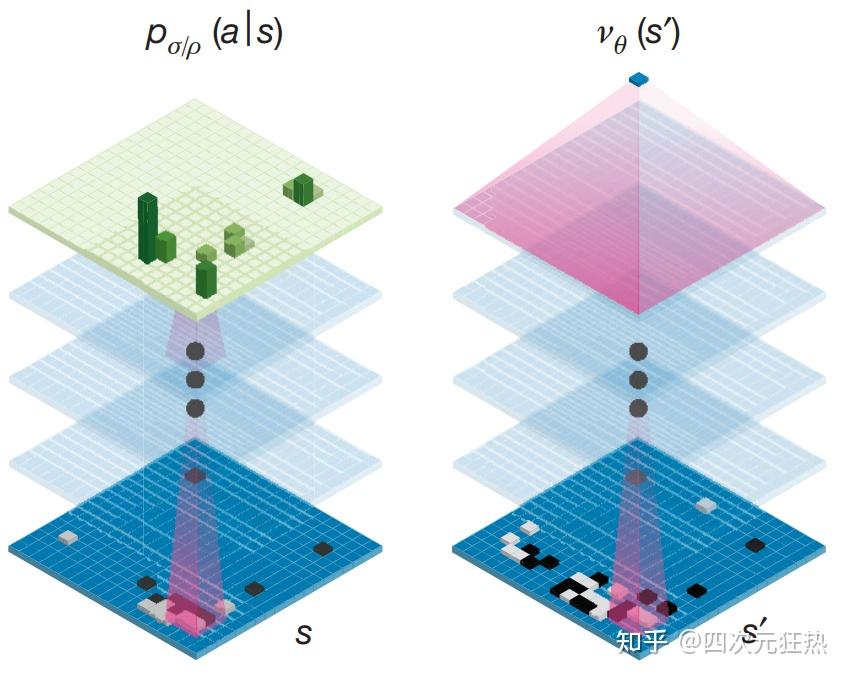
虽然围棋拥有极大的复杂度,但是在强化学习角度,围棋是个相对比较好处理的问题。这是因为围棋可以被抽象为纯粹的数学问题,同时每一个动作的结果是确定的。(举个例子,如果在机器人上应用强化学习算法,可能出现模拟环境中没有见到的突发情况,比如有路人把机器人抱走了。但是围棋环境下,在空的天元位置落子的动作一定会导致棋盘的天元位置多出一个棋子,不会出现落到棋盘之外的情况来。)因为这样的真实-模拟代沟(reality-simulation gap),强化学习在工业领域的推广受到了很多阻碍。不过实际上,因为其独特优势,深度强化学习近年来还是在在很多实际的工业track上取得了相当好的效果。
譬如在规划相关的任务上,滴滴的AI Lab在KDD 2018上提出了一种考虑时空因素的强化学习派单方法,通过深度强化学习,评估不同时间与空间位置的司机\乘客的价值,从而优化派单模型(是不是有点像AlphaGo评估不同落子位置价值的风格?不同的任务中,强化学习的“价值”有不同的定义)。优化后的派单模型在某些城市市场给滴滴带来了0.5%-5%的收益提升。对于滴滴这个体量的公司,应用深度强化学习算法的收益十分惊人。[3]
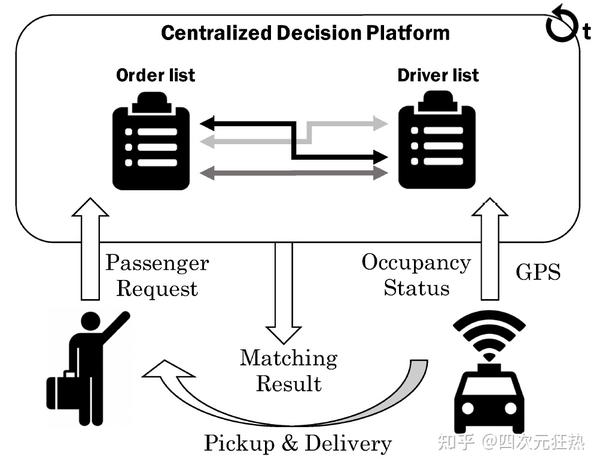
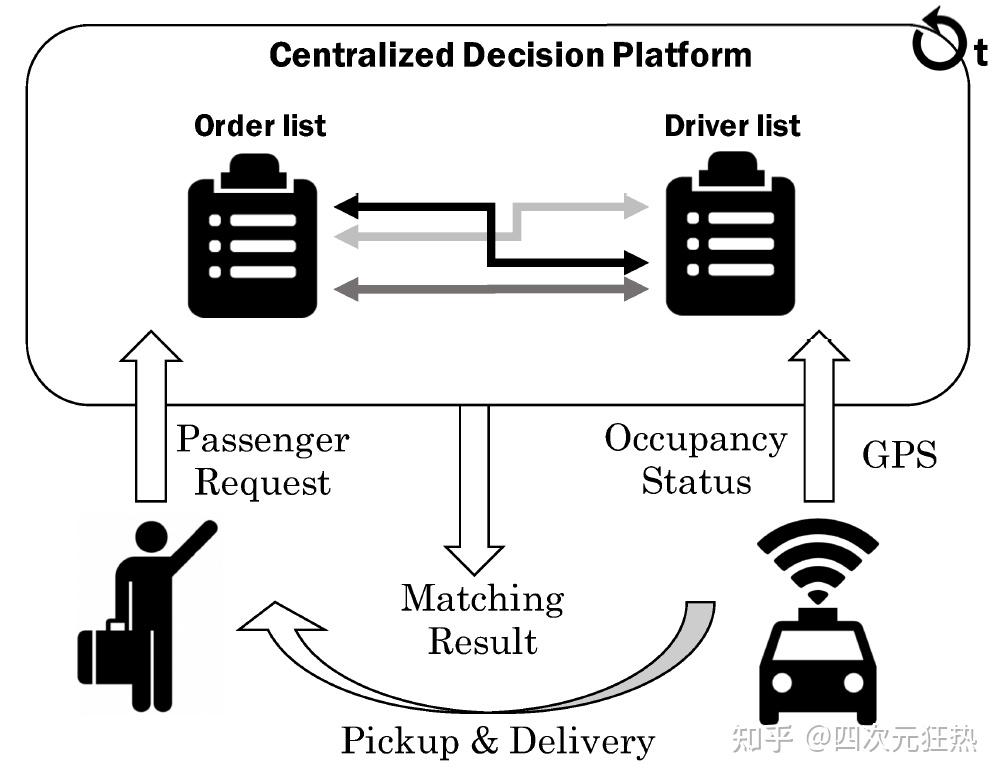
强化学习在各个领域的成功给电网工作者带来了相当的冲击——基于当前复杂局面,做出价值判断从而给出最有策略的能力,在不断追求更安全更经济的电网调度领域应用前景很大。
电网调度+深度强化学习进展
电网调度问题和围棋问题相似,尽管理论上是可以通过穷举获得最佳结果的,但是极大的动作空间、极长的决策步数、太过复杂的拓扑情况、随机发生的各种突发事件,让问题的规模不可能通过穷举来求解。大家自然而然地想到了通过深度学习(深度强化学习)来解决问题。
AI领域通过竞赛来推动对应问题研究。法国输电网公司(RTE)举办的L2RPN(Learning to Run a Power Network)比赛在业内的认知度不低。[4,5]
L2RPN比赛的初衷:
Grid operators are still responsible for ensuring that a reliable supply of electricity is provided everywhere, at all times. With the advent of renewable energy, electric mobility, and limitations placed on engaging in new grid infrastructure projects, the task of controlling existing grids is becoming increasingly difficult, forcing grid operators to do “more with less”. This challenge aims at testing the potential of AI to address this important real-world problem for our future.
电网公司有责任确保随时随地提供可靠的电力供应。随着可再生能源、电动汽车的出现以及对新的电网基础设施建设的限制,现有电网的控制任务变得越来越有挑战性,迫使电网运营商用更少的操作实现更多的目的。这项挑战旨在测试人工智能在解决这一重要现实问题方面的潜力。
可能是中国的电网技术与电网规模更发达的原因,中国人在这个比赛拿到了非常好的名次。到目前为止,L2RPN比赛一共举办了四届,具体情况见如下表格。
| 比赛名 | 赢家 | 备注 |
| L2RPN 2019 | 全球能源互联网研究院 | |
| L2RPN 2020 WCCI | KAIST | |
| L2RPN 2020 NIPS | 百度 PARL | 共两个赛道,赢家相同 |
| L2RPN 2021 ICAPS | ? | 正在进行 |
L2RPN比赛的主要任务可以归纳为:在正常的负荷波动以及随机发生的事故影响下,通过改变电网的拓扑结构、母线连接方式与发电机出力等设置,维持电网的安全稳定运行,并取得最优的经济效益。
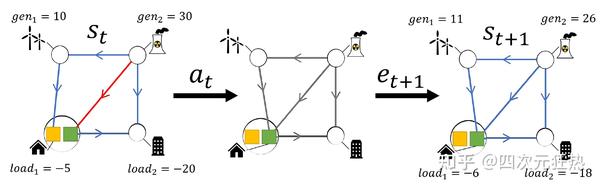
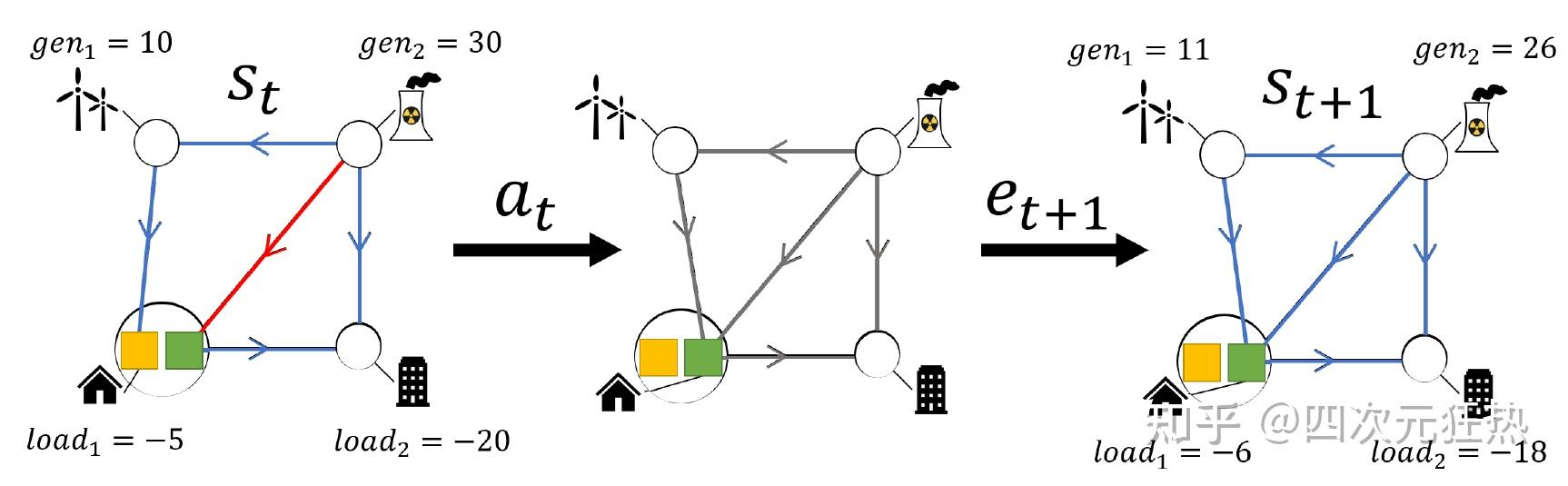
通过KAIST论文中的配图来对任务做讲解会更清晰:这个例子中,我们的电网一共有4个变电站、2个发电机、2个负荷和5条输电线路。从左侧开始,首先改变左下角的负荷的母线连接方式,从母线A(黄色方块)转移到母线B(绿色方块)。这个母线切换的操作通过a(action)表示。之后,电网会经历一个外部事件e(exogenous event)。e包含多种多样的情况,比如负荷改变或者突然的断线。这里可以看出负荷发生了变化。
最终,电网下一个状态量是由a与e两者共同确定。其中,a是我们可以控制的动作,而e是外来的,我们不可控制的随机量。在这个例子中,对角线所处的输电线路本来正在经历较为严重的过载(实际电流值超过其额定电流),在操作后,过载的情况消失了。
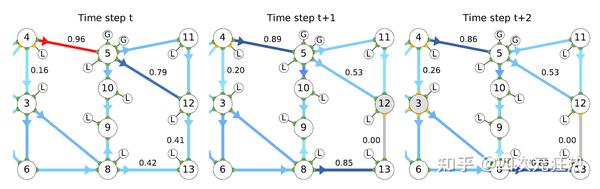
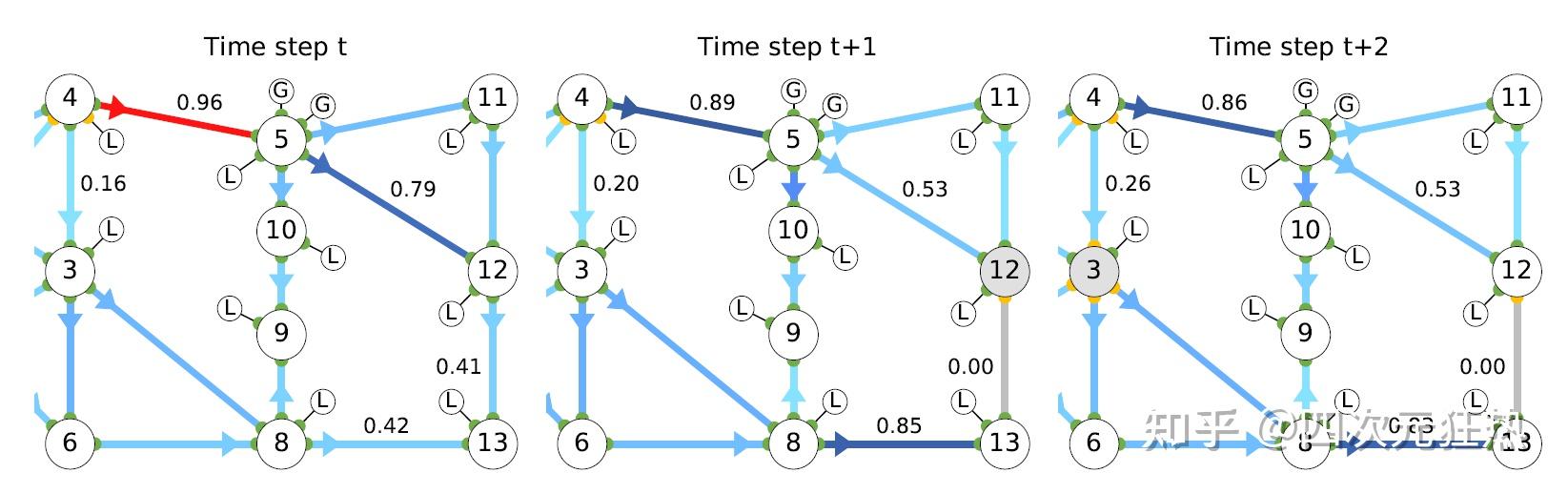
再来一个稍微复杂些的IEEE 14节点的控制作为例子。图中,大圆圈表示变电站,带G或L的小圆圈表示发电机或负载,变电站上的绿色或黄色圆点表示母线A或母线B。线旁边的数字是电流与线路容量的比值,即线路使用率。线路颜色越深表示线路使用率越大,线路越危险。如果超过1,那么线路便进入了过载状态。这是我们所不希望见到的。
线路的具体情况按照时间顺序自左向右排列。在t时刻(左图),可以看出线路4-5的负载率达到了96%,处于危险状态之中。在t+1时刻(中图),强化学习的agent做出动作,将变电站12上的线路12-13转移到了黄色母线上。这样的动作导致的结果是,线路12-13上不再有电流经过(因为线路两端不在同一母线上)。这样做的后果是,变电站13上的所有负荷供电都要从线路8-13来。这样一来,一些原本在线路4-5上的电流被转移到了线路4-3上。(我们不能直接的命令电流有怎样的流向,只能通过接线方式来引导它们)在t+2时刻(右图),线路4-5在部分电流被转移之后,负载率不再处于危险的情况之中。
虽然离实际的电网调度任务还有一定差异,但是RTE做的工作已经非常有借鉴意义了:基于他们开发的潮流计算软件搭建了强化学习的操作平台,提取出一个足够抽象的接口给需要使用的工作者们。同时,他们问题的难度也恰到好处——既没有难到超越现实的技术发展步伐,又没有简单到可以通过调包传统算法轻松求解。
在去年的L2RPN NIPS比赛中,百度的PARL团队获得了两条赛道的双冠军。
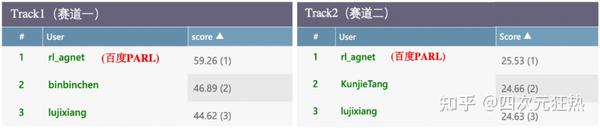
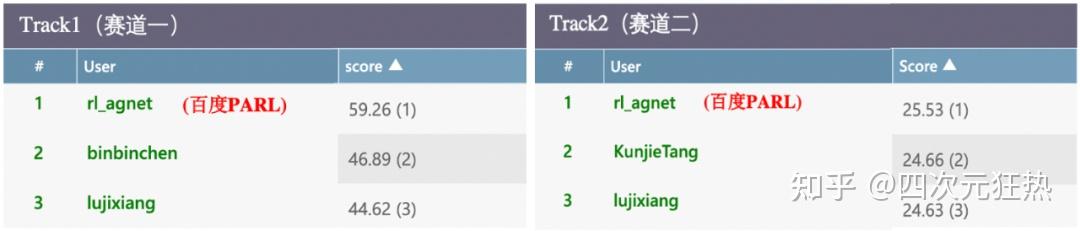
虽然他们没有开源他们的代码,但是根据赛后的视频介绍,以及机器之心的报道,我们可以大概还原出他们的工作思路。[6]
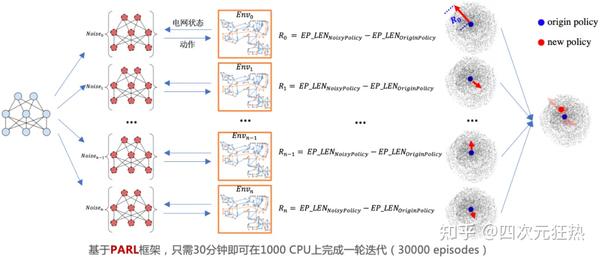
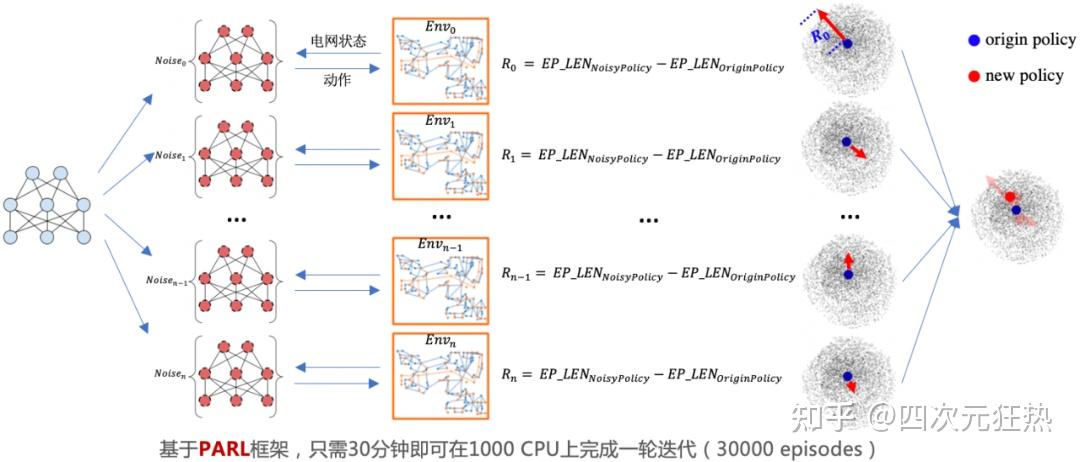
在大规模进化训练过程中,百度利用 PARL 高性能并行框架同时在上千 CPU 上对近 500 万参数的较大规模神经网络进行进化学习。在此过程中,需要先对网络参数进行不同的高斯噪声扰动,然后将扰动后网络作为专家系统新的动作打分模型,分别和电网系统进行交互,并计算噪声扰动后网络相比原始网络在电网系统中的平稳运行时长增益,作为该采样噪声的奖励;最后,整合不同噪声方向的奖励来决定下一轮网络参数的进化方向。据悉,一个这样的电网调度打分模型需要进行 60 万个 episode 迭代, 合计总的电网模拟时长一万多年,包含 10 亿多步探索。而这些仅仅需要 10 个小时左右的时间就能完成。
首先做一个简单的说明,电网的调度问题和大家比较熟知的CV任务不同,主要的资源瓶颈在于CPU(用来做潮流仿真生成数据)而非GPU(用来更新深度学习模型)。
这句话的我的理解是,百度在上千个CPU上建立了上千个电网仿真平台,每个平台可以独立的承担电网计算任务。针对不同的场景,每次生成一个动作之后,都给这个动作上附加一个噪声值,再发送给某个CPU(加噪声的目的是为了对状态空间的探索程度)。CPU针对这个附加了噪声的动作,运行电网仿真程序,计算出这个动作所对应的奖励得分。一千个CPU可以同时处理一千个case,考虑一千种动作,也就是探索一千种可能性。通过同步或异步的将这一千个奖励综合到一起,进行反向传播改变模型,再输出下一个动作,做出下一步决策。
PS. 我司和PARL的团队比较熟络,他们技术很强。飞桨算是国产AI框架里当之无愧的No.1了。非常遗憾的是这次的工作他们没有开源= =
RTE对百度的工作非常满意,他们很高地评价了百度的工作,评价的原话是,这次训练的agent在特定的任务上取得了“super human performance”(超越人类的控制表现)。
结合RTE的解释,介绍一下“super human performance”的具体情况。
Over this 4-hour short period of time, RL agent execute lots of actions (20), through sometimes impressive complex 3 to 5 combined action sequences. It successfully adapts to new overloads appearing because of a continuously increasing consumption up to 10am. As combined-action depth superior to 3 is hard to study for human operators, some sequences showcased by the agent can be today considered super-human.
在四个小时的短暂时间窗口中,百度开发的智能体进行了大量的动作,有时会进行三到五个动作的复杂集合。他成功适应了在早上10点钟持续的需求增长而带来的线路过载情况。由于人类很难考虑到超过3个的动作集合,智能体的某些操作序列可以被认为是超越人类水平的。
这个“super human performance”恰恰是我们希望获得的,让agent取代电网调度员的任务中最核心的需求。
展望
归纳一下,RTE的比赛初步还原了电网调度的某些核心数学问题,并取得了相当好的效果。但是想要纳入实用化,我认为还有三个点需要关注:
1. L2RPN比赛还原的是基于“法国国情的电网控制问题”而非考虑中国国情。譬如,L2RPN比赛中,给调整发电机出力加了一个很大的惩罚项。这是因为在电力市场改革程度较深的欧洲地区,RTE作为输电运营商,是没有权力去直接命令发电商改变发电计划的,需要付出相当大的经济成本。故而在之前提到的比赛中,参赛选手更多的是依靠切换母线操作来维持电网平衡的。
在国内,恰恰相反的是,调度机构更倾向于通过改变发电计划而非切换母线来维持系统的稳定运行。
2. 现实中要顾忌的因素远远多于L2RPN中数学模型所描述出来的,而调度员往往是在和这些琐碎但决不能忽略的问题打交道。
据悉,锡泰工程送端风电送出能力受限于两方面技术因素:一是送端高比例风电经直流送出,风电出力越大需要通过直流送出的功率越大,而此时如果交、直流系统发生故障导致直流送出短时中断(换相失败),风电机组机端会出现超过1.3倍额定电压的暂态过电压,就出现了“跷跷板效应”:风电出力越大,需要的直流外送功率越大,风电机组机端电压升高越显著,为避免暂态过电压则需要限制新能源出力;
像这样的问题实在太多太多,很难完全的描述出来。而想要实现大比例的调度人员替代,这些细节问题又是必须逾越过去的难关。
3. 可信&可解释性——和游戏等基于虚拟环境的强化学习任务不同,省市电网如果一旦出问题就是影响万人级别,损失亿元级别的大事件
为了解决这些问题,业界也有一些对应的举措:
1.2021年的新比赛L2RPN Trust,就加入了预警机制,来模仿在强化学习智能体取代调度员工作后,在面对极为危险问题时发出预警,呼唤人类调度员接手的环节。在国内,国家电网的调度中心也举办了更加符合中国电网情况的电网智能运行安排比赛。和L2RPN比赛相比,国内的比赛对解决国内实际的电网问题启发更大。
2. 第二个问题需要靠时间解决。目前的技术进步,仍然还聚焦于电力系统的主干问题。对于各种各样的分支问题与细节,还没有到去解决他们的时候。不过这对于AI的算法工作者来讲并不是一个陌生的工作——改造任何一个领域,都应该是从主体的问题开始着手,以各种各样的corner case收尾的。
3. 第三个问题提到的深度学习模型的可解释性是一个非常晦涩的话题。
要研究深度学习的可解释性(Interpretability),应从哪几个方面着手? - superbrother的回答 - 知乎
我不是这个方面的专家,但是就我看到的资料感觉,通过模型的参数直接理解其动作的逻辑是一个不可能完成的任务。和随机森林这种有明显的逻辑展示的方法不同,深度学习的模型内核很难用逻辑直接的归纳出来。在CV、NLP这些领域的可解释性也是更多从feature的角度去分析的。
我个人认为比较靠谱的路线,是通过大量的符合实际场景的测试,验证强化学习模型的结果可行。这个思路也非常好理解,我们知道官媒在评论某些英雄人物的时候,经常给出“久经考验的共产主义战士”的评价。这代表着尽管人心隔肚皮,我们不能知道一个人内心的真实想法(就好比不能通过看模型的参数来理解这个模型),但是只要他能在长期的残酷斗争中坚持下来(经历了实际的调度任务的模拟考验),我们就可以认为这位工作者是真正的自己人(强化学习模型给出的调度指令是可信的)。
国内的电网工作者在强化学习智能体的可解释性上也一直在努力。在江苏的常州,就有基于深度强化学习的“电网脑”系统的试运行。[7]


这是一个非常有意义的验证工作,但对于证明深度强化学习能被用于电网调度任务的宏伟目标,这还只是刚刚迈出的一小步。
虽然还有一段很长的距离,但是由于优化电网运行的潜在经济效益实在太大——回避一个可能发生的事故,承受住可能的天灾or人祸打击,整个系统的运行效率提升一个百分点,都会带来百亿级别的社会效益。所以全球与我们国家的电力工作者在这个方面的努力是不会停止的。当然这个领域也需要更多更优秀的电力&AI工作者参与。
本文中,为了避免涉密,我尽量全部使用公开资料来介绍。同时也尽可能让没有电力甚至AI背景的同学也能看懂。因为我不是调度方面的专业工作者,如果有不专业甚至错误的地方,也欢迎专业的研究者批评指正。
Reference
[2] D Silver, Huang A , Maddison C J , et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature.
[3] Zhe X , Li Z , Guan Q , et al. Large-Scale Order Dispatch in On-Demand Ride-Hailing Platforms: A Learning and Planning Approach[C]// the 24th ACM SIGKDD International Conference. ACM, 2018.
[4] https:// l2rpn.chalearn.org/
[5]Marot A , Donnot B , Dulac-Arnold G , et al. Learning to run a Power Network Challenge: a Retrospective Analysis[J]. 2021.
[6] https://www. jiqizhixin.com/articles /2020-11-17-6
[7] http://www. js.sgcc.com.cn/html/czd lj/col238/2019-12/24/20191224090825093872798_1.html
