|
|
|


GitHub 上有哪些优秀的 Java 爬虫项目?
关注者
4,784
被浏览
1,041,335
33 个回答


1、Gecco
github地址:
xtuhcy/geccoGecco是一款用java语言开发的轻量化的易用的网络爬虫。整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。
2、WebCollector
github地址:
CrawlScript/WebCollectorWebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
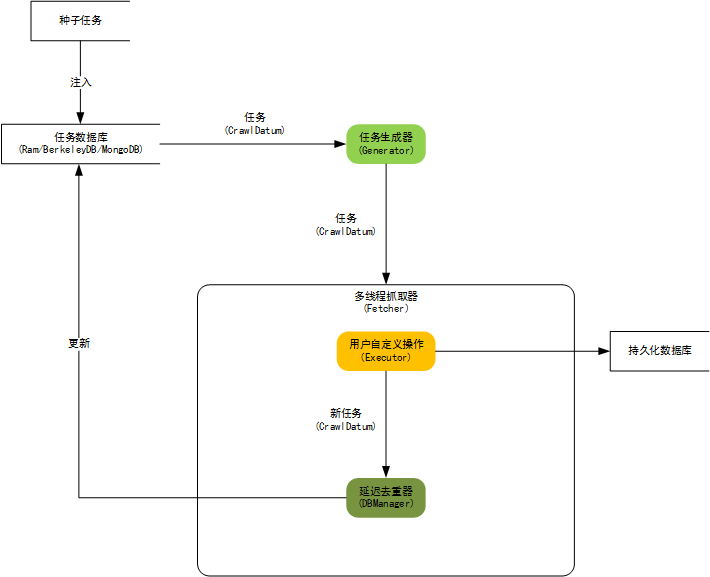
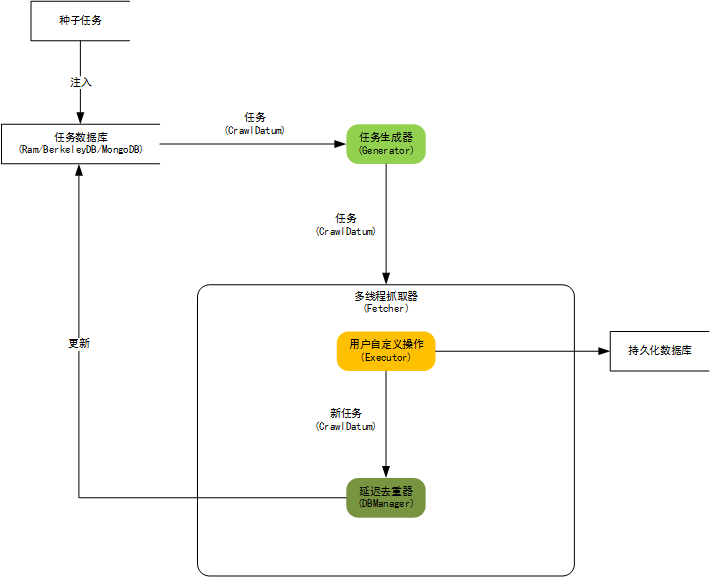
3、Spiderman
码云地址:
l-weiwei/Spiderman2 - 码云 - 开源中国使用案例:
展现垂直爬虫的能力 - 像风一样自由Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
4、WebMagic
码云地址:
flashsword20/webmagic - 码云 - 开源中国webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
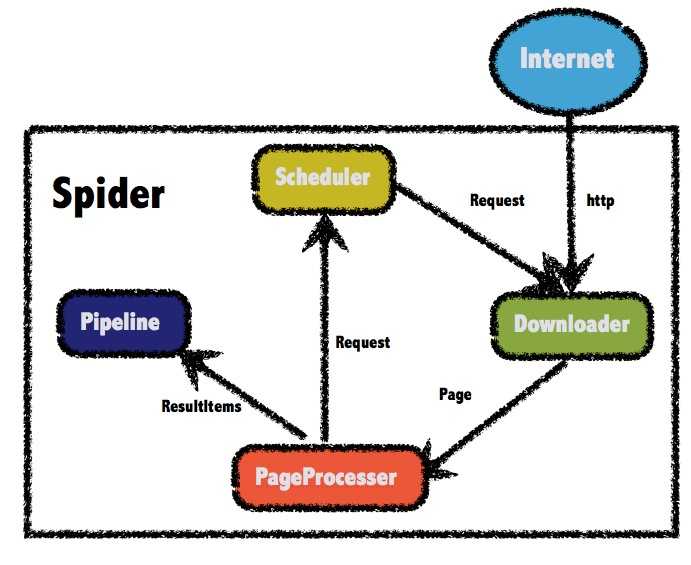
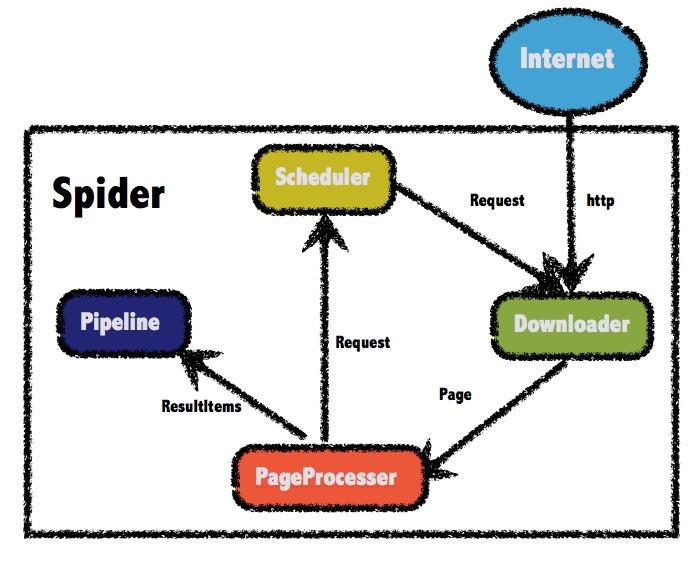
5、Heritrix
github地址:
internetarchive/heritrix3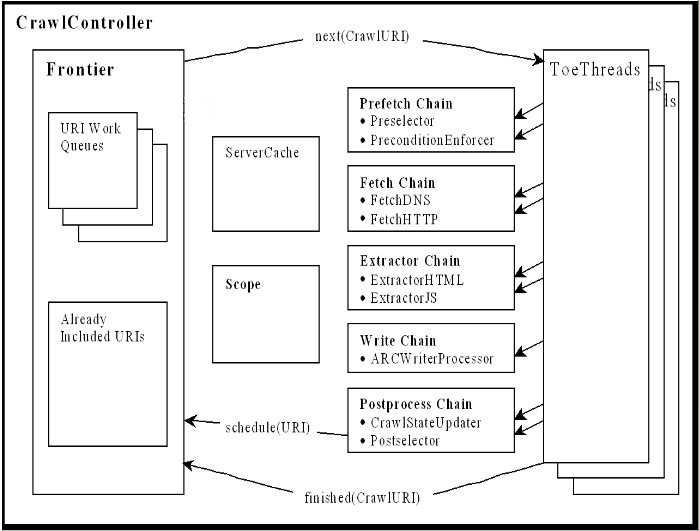
6、crawler4j
github地址:
yasserg/crawler4j · GitHubcrawler4j是Java实现的开源网络爬虫。提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫。

1.nutch
地址:
apache/nutch · GitHub
apache下的开源爬虫程序,功能丰富,文档完整。有数据抓取解析以及存储的模块。而且这玩意儿还包括了一个开箱即用的搜索引擎,安装好就可以搜索了。
2.Heritrix
地址:
internetarchive/heritrix3 · GitHub
很早就有了,经历过很多次更新,使用的人比较多,功能齐全,文档完整,网上的资料也多。有自己的web管理控制台,包含了一个HTTP 服务器。操作者可以通过选择Crawler命令来操作控制台。
3.crawler4j
地址:
yasserg/crawler4j · GitHub
因为只拥有爬虫的核心功能,所以上手极为简单,几分钟就可以写一个多线程爬虫程序。
当然,上面说的nutch有的功能比如数据存储不代表Heritrix没有,反之亦然。具体使用哪个合适还需要仔细阅读文档并配合实验才能下结论啊~
还有比如 JSpider , WebEater , Java Web Crawler , WebLech , Ex-Crawler , JoBo 等等,这些没用过,不知道。。。
ps:来 前任网 骂一骂前任