

SQL CASE WHEN实战大全

在现在的大数据统计中,我们经常会在sql中看到或者自己使用case when语法,它的地位也随着统计指标的多样性变得越来越重要,今天就来对case when做一个总结。
case when相当于if else语法,是一个表达式,表示对某些条件的判断并返回对应的结果,完整的语法如下:
CASE
WHEN col1=${value1} [AND | OR col2=${value2}] THEN ...
WHEN col1=${value3} [AND | OR col2=${value3}] THEN ...
ELSE ...
END例如:
CASE WHEN score>=90 THEN 'A' WHEN score>=80 THEN 'B' WHEN score>=70 THEN 'C' ELSE 'D' END表达的是当score>=90时返回A,A可以代表等级。score>=80返回B,这里隐含的完整条件是90>score>=80,当score>=70时返回C,其他的都返回D。
为了展示case when的使用,我们首先创建一个student表,只有name和score两个字段。数据如下:
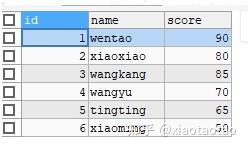
在维度中使用
1、根据学生的成绩来给学生划分等级,等级的划分和上述示例一致,score>=90为A,80=<score<90为B,70=<score<80为C,score<70为D。
sql如下:
SELECT
name,
score,
CASE WHEN score>=90 THEN 'A' WHEN score>=80 THEN 'B' WHEN score>=70 THEN 'C' ELSE 'D' END AS grade
FROM student结果:
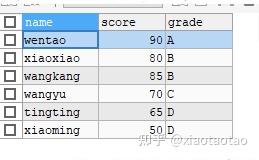
2、按照等级统计每个等级有多少人。一种方式是将1)中的结果当做子查询来按照grade进行group by。另一种方式是在维度列直接使用case when将分数转换为等级,然后group by操作时也是用同样的case when语句来进行聚合,这时就是按照等级来聚合,计算的逻辑是首先根据分数来确定等级,相同等级的数据进行count聚合。如下:
SELECT
CASE WHEN score>=90 THEN 'A' WHEN score>=80 THEN 'B' WHEN score>=70 THEN 'C' ELSE 'D' END AS grade,
COUNT(name) AS num
FROM student
GROUP BY
CASE WHEN score>=90 THEN 'A' WHEN score>=80 THEN 'B' WHEN score>=70 THEN 'C' ELSE 'D' END结果:
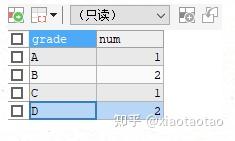
在指标列使用
case when在指标列中的使用功能要远远大于在维度列的使用,在维度列使用的时候只是当做一个函数来使用。而在指标列却是可以通过不同的判断表达式来统计各种各样的指标。
例如:统计各个分数等级的人数,结果都在指标列展示,指标列形如:A B C D,数据为人数。
sql如下:
SELECT
COUNT(CASE WHEN score>=90 THEN `name` ELSE NULL END) AS A,
COUNT(CASE WHEN score>=80 AND score<90 THEN `name` ELSE NULL END) AS B,
COUNT(CASE WHEN score>=70 AND score<80 THEN `name` ELSE NULL END) AS C,
COUNT(CASE WHEN score<70 THEN `name` ELSE NULL END) AS D
FROM student结果:

- CASE WHEN和WHERE的关系
在以上的统计的4个指标,每个指标都可以单独的进行统计,例如要统计B等级的人数,我们可以用如下的sql:
SELECT
COUNT(`name`) AS B
FROM student
WHERE score>=80
AND score<90同样也可以用case when来统计:
SELECT
COUNT(CASE WHEN score>=80 AND score<90 THEN `name` ELSE NULL END) AS B
FROM student以上两个sql统计出来的结果是一样的。那么这两个有什么异同呢?
通过观察我们知道,case when语句是将原来在where后的条件移到了case when后面,在逻辑上,都是满足score>=80 AND score<90这个条件的人才会被统计为B等级。
既然我们知道等级为B的肯定score<90,因此我们再来看以下这个sql:
SELECT
COUNT(CASE WHEN score>=80 THEN `name` ELSE NULL END) AS B
FROM student
WHERE score<90它的执行结果和上面两个sql是一致的。但是这个score>=80 AND score<90的条件一个case when后面,一个在where后面。where和case when的条件共同组成为score>=80 AND score<90这个条件,最后的结果也是一致的。
因此,我们可以得出结论,case when的条件和where的条件共同确定了要统计指标的计算逻辑(或者计算条件)
那么,这种case when和where有不同点吗?答案是肯定的,虽然这两种sql结果是一样的,但是统计的基数,或者说数据集不同。
首先我们来看where,条件表达式放在where后面,sql在运算时只会筛选where后符合条件的这部分数据进行运算,这样可以提高性能,但是同时也限制了其他维度指标的计算,比如我们计算A等级的人数时候就无法同时再统计B的指标了,因为这两个指标的条件是互斥的。
我们再来看case when,因为条件或者部分条件从where移到了case when后面,那么sql的计算数据集就会变大,where条件后的全部数据都要参与case when的指标计算,然后再从这部分的数据集中判断出符合case when条件的数据进行聚合。虽然sql运算的数据量大了,但同时也允许我们进行更多case when条件判断,也就可以进行更多指标计算。例如同时计算等级B、C、D的人数:
SELECT
COUNT(CASE WHEN score>=80 THEN `name` ELSE NULL END) AS B,
COUNT(CASE WHEN score>=70 AND score<80 THEN `name` ELSE NULL END) AS C,
COUNT(CASE WHEN score<70 THEN `name` ELSE NULL END) AS D
FROM student
WHERE score<90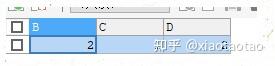
这样sql运算的数据都是score<90的数据,B、C、D等级都属于这部分数据集,他们的计算逻辑都满足score<90这个条件,因此可以同时进行计算。
可以总结出case when和where的关系和异同点:
1、case when的条件和where的条件共同确定了要统计指标的计算逻辑(或者计算条件)
2、统计的基数,或者说数据集不同。where后条件或者部分条件移到了case when后面,那么sql的计算数据集就会变大,where条件后的全部数据都要参与case when的指标计算,这就会造成不满足条件的数据也会进行计算,如果有group by的情况,可能某一个分组的指标数据都是0
3、条件表达式放在where后面,这样可以提高性能,但是同时也限制了其他维度指标的计算;条件或者部分条件从where移到了case when后面,虽然sql运算的数据量大了,但同时也允许我们进行更多case when条件判断,也就可以进行更多指标计算。
- CASE WHEN的计算过程
下面再来分析case when的计算过程,用上述开始的sql举例:
SELECT
COUNT(CASE WHEN score>=90 THEN `name` ELSE NULL END) AS A,
COUNT(CASE WHEN score>=80 AND score<90 THEN `name` ELSE NULL END) AS B,
COUNT(CASE WHEN score>=70 AND score<80 THEN `name` ELSE NULL END) AS C,
COUNT(CASE WHEN score<70 THEN `name` ELSE NULL END) AS D
FROM studentsql运算的是全表数据,计算的过程和数据转换大致如下:
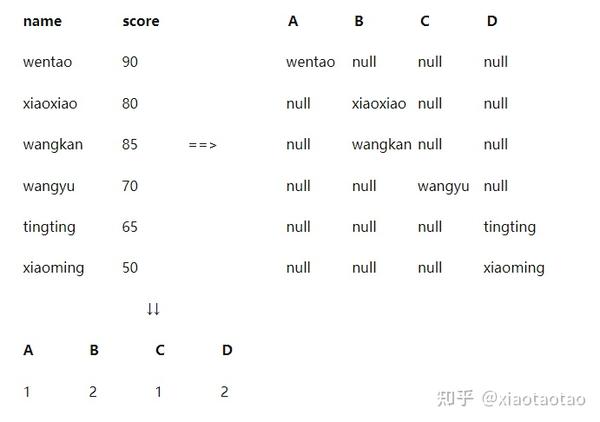
对于count的统计,只有空和非空的区别,所以在case when里else必须是null。对于这个统计我们也可以换成sum函数,如下:
SELECT
SUM(CASE WHEN score>=90 THEN 1 ELSE 0 END) AS A,
SUM(CASE WHEN score>=80 AND score<90 THEN 1 ELSE 0 END) AS B,
SUM(CASE WHEN score>=70 AND score<80 THEN 1 ELSE 0 END) AS C,
SUM(CASE WHEN score<70 THEN 1 ELSE 0 END) AS D
FROM student它的执行结果跟count是一样的,但是计算过程就变成了如下:
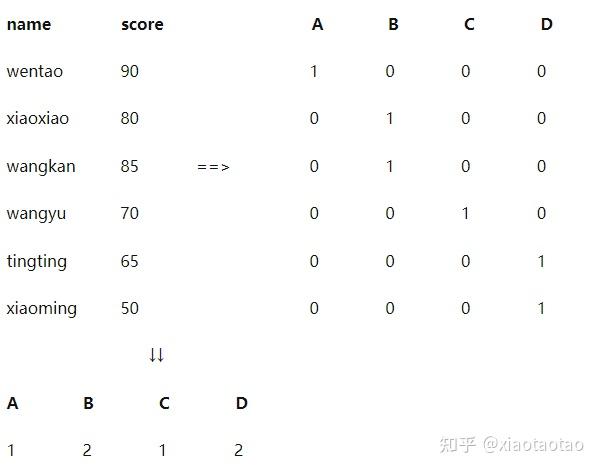
count和sum的选择可以根据自己的喜好决定,但是如果有需要对数据去重的话,就必须要用count了,形如count(distinct case when ...),可以对满足case when条件的结果进行去重计算。
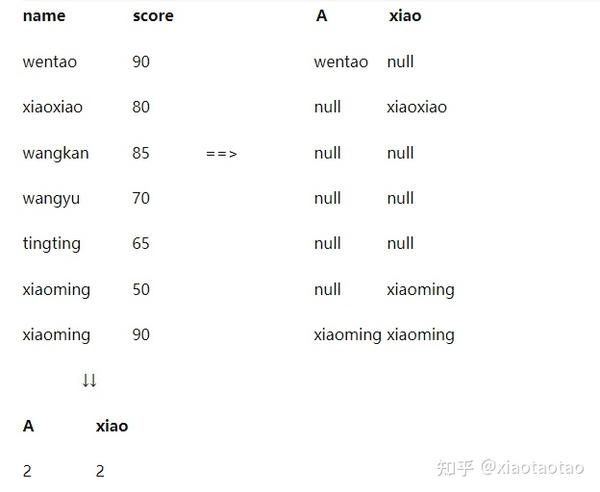
在上面的例子中,我们都是对score这个条件进行判断,不过在指标统计中,我们可以不同的条件进行不同的统计,比如我们要同时统计等级为A的人数和名字中带‘xiao’的人数,尽管这两个指标并没什么关系,这次我们增加一个重复名字的的student数据(xiaoming 90),这样就要使用count(distinct )来统计了。如下:
SELECT
COUNT(DISTINCT CASE WHEN score>=90 THEN `name` ELSE NULL END) AS A,
COUNT(DISTINCT CASE WHEN `name` LIKE '%xiao%' THEN `name` ELSE NULL END) AS xiao
FROM student结果:
这次它的计算过程如下:
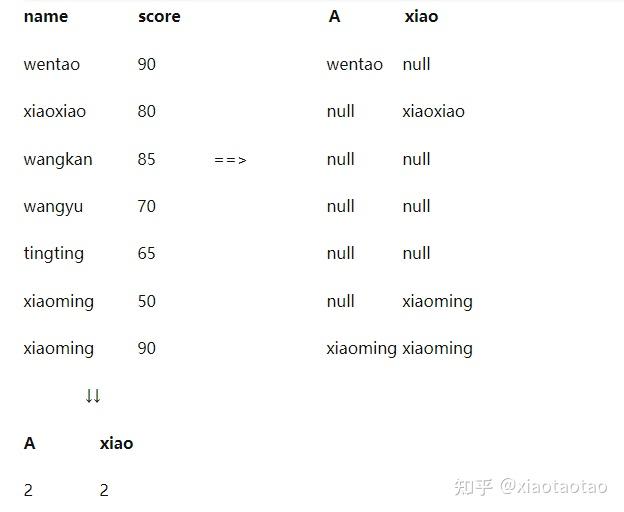
- 无数值意义的统计指标
上述我们统计的指标基本都有具体的数值意义,比如各个等级的人数,名字带xiao的人数,这个数值都代表了具体的人数是多少,是有实际意义的。但是我们有时候会统计一些指标,它没有实际的数值意义,只有0和非0的区别。
比如我们想要知道一个用户在今天是否出现过,我们可以用如下统计:
SELECT
COUNT(*)
FROM t_app_cc
WHERE p_day=20201029
AND uid='12345'如果结果是0,说明t_app_cc表里p_day=20201029这一天没有uid='12345'的数据,那就代表着12345这个用户没有在20201029这一天出现过。如果结果>0,说明这个用户出现过,但是这个count到底是多少,我们并不关心。因此,在这种情况下,这个结果我们认为它是无实际数值意义的。
但是如果换个情形,如果这个用户数据是一个购物行为,而我们想了解的是他的购物次数,那么这个结果对于我们就是有数值意义的了。
上面我们分析了case when和where的关系,那么这个统计值我们换做case when来统计就是:
SELECT
SUM(CASE WHEN p_day=20201029 THEN 1 ELSE 0 END) AS 20201029
FROM t_app_cc
WHERE uid='12345'指标20201029和上面的count指标是一样的,如果指标20201029>0,表明用户12345有p_day=20201029的数据,那就说明这个用户在20201029这天出现过。(需要注意的是,这样参与运算的是整个表的uid数据,数据量可能会很大。一般我们都会在where后面加一个时间限制,case when的条件需要包含在这个时间内)。
基于此,我们可以进一步统计这个用户在20201028和20201029这两天出现的情况:
SELECT
SUM(CASE WHEN p_day=20201028 THEN 1 ELSE 0 END) AS 20201028,
SUM(CASE WHEN p_day=20201029 THEN 1 ELSE 0 END) AS 20201029
FROM t_app_cc
WHERE p_day in (20201028, 20201029)
AND uid='12345'20201028和20201029两个指标值就可以判断出该用户是否在这两天出现过。比如20201028>0,20201029=0,说明这个用户在20201028这天出现过,没在20201029这天出现。
再进一步,我们可以对所有的用户进行统计,统计出所有用户在这两天内的出现情况。而不仅限于对某一个用户的统计,如下:
SELECT
SUM(CASE WHEN p_day=20201028 THEN 1 ELSE 0 END) AS 20201028,
SUM(CASE WHEN p_day=20201029 THEN 1 ELSE 0 END) AS 20201029
FROM t_app_cc
WHERE p_day in (20201028, 20201029)
GROUP BY uid
那么这个结果我们可以用来做什么呢?这当然也跟也无需求有关,比如可以用来计算用户的留存,也就是20201028的用户在20201029这天的留存情况,首先20201028>0的用户说明这个用户在20201028这天出现过,它属于20201028,同时如果20201029>0说明这个用户在20201029这天也出现过,那么它就算一个20201028在20201029这天的留存用户。统计如下:
SELECT
COUNT(CASE WHEN 20201028>0 THEN uid ELSE NULL END) AS 20201028_user_num,
COUNT(CASE WHEN 20201028>0 AND 20201029>0 THEN uid ELSE NULL END) AS 20201028_user_retain
FROM(
SELECT
SUM(CASE WHEN p_day=20201028 THEN 1 ELSE 0 END) AS 20201028,
SUM(CASE WHEN p_day=20201029 THEN 1 ELSE 0 END) AS 20201029
FROM t_app_cc
WHERE p_day in (20201028, 20201029)
GROUP BY uid
) a因为在子查询中已经对uid进行了group by操作,每个uid都是唯一的,那我们在这个结果集上就可以直接使用count或者sum,而不是count(distinct),可以提高计算性能。
在上面的sql中我们还观察到外层case when的两个条件有相同的部分,就是20201028>0,那么我们就可以将这个公共的条件提取到where后,减少参与运算的数据,提高性能:
SELECT
COUNT(uid) AS 20201028_user_num,
COUNT(CASE WHEN 20201029>0 THEN uid ELSE NULL END) AS 20201028_user_retain
FROM(
WHERE 20201028>0
上述的例子只是列举了一种无数值意义的指标,即在某天是否有数据或者出现过,还有很多其他种类的指标,在业务的理解上,他们只有0和非0的区别,各自代表不同的含义。这样的指标我称之为非数值指标,而有数值意义的指标我称之为为数值指标。
- 数值指标和非数值指标混合使用
在统计中,经常会出现过各种各样的指标,这些指标可能是数值指标,也可能是非数值指标,也可能是两种指标的混合。例如我们想要对用户打标签,或者要筛选出一批符合某种条件的用户,那就首先要统计一下这些用户的各种指标,然后再筛选出满足条件的用户。
例如,在t_app_cc表中,newuser=1代表是新用户,0代表老用户;url=29022代表用户点赞,68023代表上传视频。我们想要筛选出上传过视频、点赞超过10次的新用户,那怎么来统计呢?
首先看到这些用户满足3个条件,我们可以将这些条件都作为指标统计出来,然后再根据指标来确定条件。上传过视频这个条件可以通过上传视频次数这个指标来确定,指标>0即可以确定这个用户上传过视频,这里这个次数指标对我们而言是无数值意义的,我们不关心它的值到底是多少;新用户这个指标可以统计newuser=1的数据出现的次数指标来确定,指标>0即这个用户存在newuser=1的数据,代表他是一个新用户,它也是一个无数值意义的质保;点赞次数的指标比较明确,通过统计点赞次数来确定,因为我们要选点赞>10的用户,那么这个指标就是有数值意义的指标。
确定了统计指标之后我们就可以写sql如下:
SELECT
SUM(CASE WHEN newuser=1 THEN 1 ELSE 0 END) AS new,
SUM(CASE WHEN url=68023 THEN 1 ELSE 0 END) AS upload,
SUM(CASE WHEN url=29022 THEN 1 ELSE 0 END) AS praise
FROM t_app_cc
WHERE p_day=20201030
GROUP BY uid
HAVING new>0 AND upload>0 AND praise>10
如果我们只是想给用户打个标签,将满足上传过视频、点赞超过10次的新用户打标签为A,其他为B,那么可以如下:
SELECT
CASE WHEN NEW>0 AND upload>0 AND praise>10 THEN 'A' ELSE 'B' END AS tag
FROM(
SELECT
SUM(CASE WHEN newuser=1 THEN 1 ELSE 0 END) AS NEW,
SUM(CASE WHEN url=68023 THEN 1 ELSE 0 END) AS upload,
SUM(CASE WHEN url=29022 THEN 1 ELSE 0 END) AS praise
FROM t_app_cc
WHERE p_day=20201030
GROUP BY uid
) a
- 多表UNION查询
上述我们都是在一个表里进行不同指标的查询,但是有时候我们需要统计的指标并不在一个表里,比如一个新用户表t_app_bd_stat,一个行为表t_app_cc,一个视频vv表t_app_vv,我们想找到那些观看超过10次视频、上传超过5个视频的新用户。这应该怎么统计筛选呢?
在这种条件下我们首先想到的仍然是要统计每个用户的各个指标来筛选用户。统计用户的vv数确定观看超过10次这个条件,统计上传视频指标来确定上传超过5个视频这个条件,统计新增指标来确定是新用户,新增这个指标属于无数值意义的指标。
1、原始JOIN方式
不在同一个表的情况下,我们通常想到的办法就是join,将几个表进行join来看用户的指标,在t_app_cc里统计用户的上传视频数,在t_app_vv表里统计用户观看视频数,再和t_app_bd_stat表里的新用户进行关联,这样就可以得到每个用户的vv,上传指标以及是否是新用户,这样就可以来筛选用户了。
join统计的形式如下:
SELECT
a.uid
FROM(
SELECT
FROM t_app_bd_stat
WHERE p_day=20201030
AND newuser=1
AND pro=1
AND mtype=6
GROUP BY uid
LEFT JOIN
( SELECT
COUNT(*) vv
FROM t_app_vv
WHERE p_day=20201030
AND msg='playCount'
AND pro=1
AND mtype=6
GROUP BY uid
) b ON a.uid = b.uid
LEFT JOIN
( SELECT
COUNT(*) upload
FROM t_app_cc
WHERE p_day=20201030
AND url=68023
AND pro=1
AND mtype=6
GROUP BY uid
) c ON a.uid = c.uid
WHERE b.vv > 10
AND c.upload > 5结果:
用panther平台的sparksql进行sql测试,最后有24个uid。
上述的join过程大致如下例子所示:
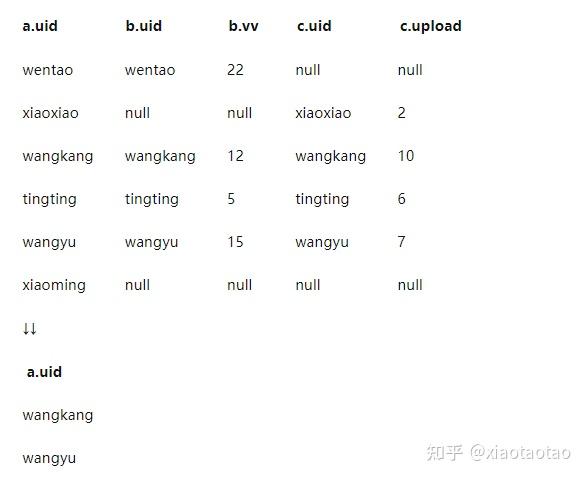
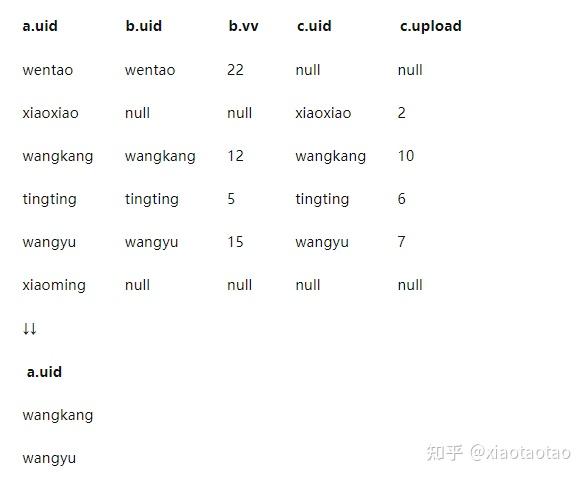
根据上述的join结果我们分析:
wentao这个新用户跟b表join上了,他有20个vv,但是却没有跟c表join上,因为c表是所有上传行为的用户,没跟c表join上说明wentao这个用户没有上传视频,也即上传视频次数等于0;
同理xiaoxiao这个用户没有跟vv的用户join上,也就没有vv,即vv=0,但他有2次上传。
xiaoming这个用户则既没有vv,没有上传。
既有上传又有vv的只有wangkang、wangyu、tingting三个用户,那么根据条件我们就知道了满足条件的只有wangkang、wangyu两个用户。
2、将JOIN改成UNION
上面的sql统计我们都是按照uid进行group by和join的,那么这个我们能不能把uid放在一起进行统计呢?将好几种的数据放在一起,同时统计出uid的上传、vv、新增指标。这样就可以减少计算的步骤、聚合的过程、join的过程,提高计算的性能。
仔细想想上述的要求是可以实现的:
1)、将数据放在一起,可以用union all操作;
2)、为了区分不同的统计指标,我们需要对不同类型的数据进行区分,可以新增一个type字段解决;
3)、union all需要所有的数据字段一致,那么每种类型数据所需要的统计字段都需要出现在最终字段中,也就是union all的字段是所有类型数据字段的并集,因此对于某一个类型数据,它的其他类型字段的数据可以用默认值代替。如‘’或者0等。
用union all改写为:
SELECT
FROM(
SELECT
SUM(CASE WHEN TYPE='new' THEN 1 ELSE 0 END) AS NEW,
SUM(CASE WHEN TYPE='vv' THEN 1 ELSE 0 END) AS vv,
SUM(CASE WHEN TYPE='upload' THEN 1 ELSE 0 END) AS upload
FROM(
SELECT uid, 'new' AS TYPE FROM t_app_bd_stat WHERE p_day=20201030 AND newuser=1 AND pro=1 AND mtype=6
UNION ALL
SELECT uid, 'vv' AS TYPE FROM t_app_vv WHERE p_day=20201030 AND msg='playCount' AND pro=1 AND mtype=6
UNION ALL
SELECT uid, 'upload' AS TYPE FROM t_app_cc WHERE p_day=20201030 AND url=68023 AND pro=1 AND mtype=6
GROUP BY uid
HAVING NEW>0 AND vv>10 AND upload>5
) b结果:
经过sparksql执行后,同样是24个uid,并且uid和join的结果集一致。
统计逻辑的区别
- join的方式是求几个数据集之间的交集,需要先求出各个数据集中对应的指标,再进行uid的关联,从而得到每个uid的各个指标。然后我们再从结果集中去筛选出符合条件的uid。这种方式的有点是逻辑简单易理解,但是需要进行计算的步骤比较多。应用的是left join,这里的基准表是新增表,同样也可以改成vv表或者行为表
- union all的方式是对所有数据集进行了一个聚合,把新增、vv、行为的全部数据当做一个整体进行各个指标的聚合,最后通过指标来筛选出uid。该计算的优点是步骤少,一次计算就能得出结果,节省io。但是所有的数据都会参与各个指标的计算,计算量比较大。
- 结果的稍微区别,join没关联上的指标会是null,而union是0
性能对比:
spark
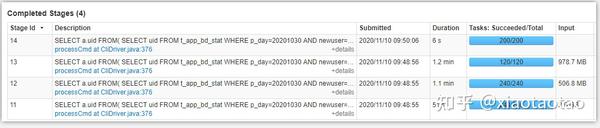
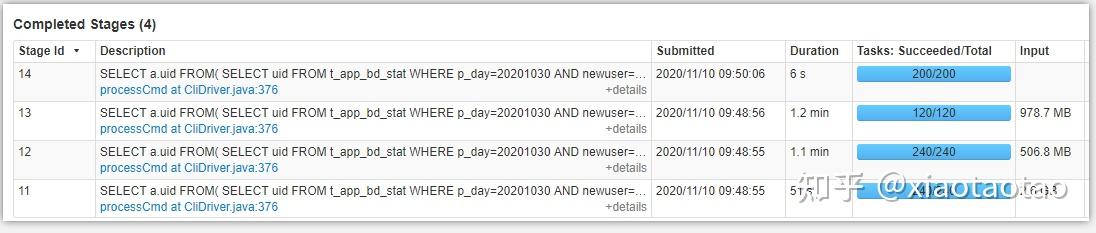
相同资源下,两种计算的性能相差无几,job3、4组成一个union查询,job5是一个join查询,两者耗时差不多。主要可以对比job3和job5,可以看到两者的任务数是一致的,都是800个


union过程只有2个stage,从各个表查数据到union在一起的过程属于一个stage,即stage6,数据聚合的过程属于一个stage,即stage7,stage6有600个任务,stage7有200个任务。
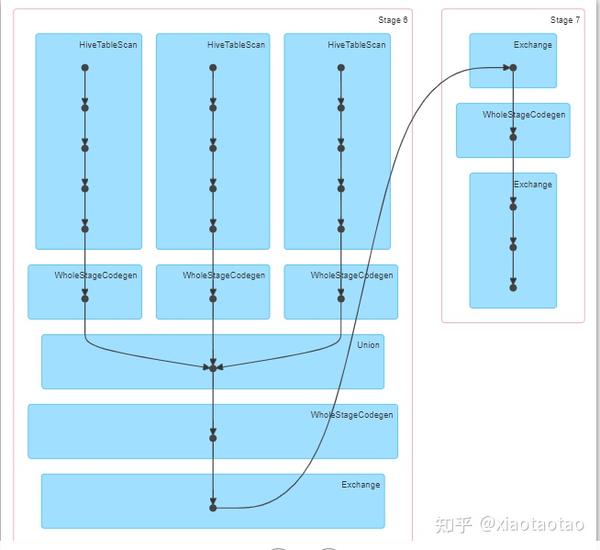
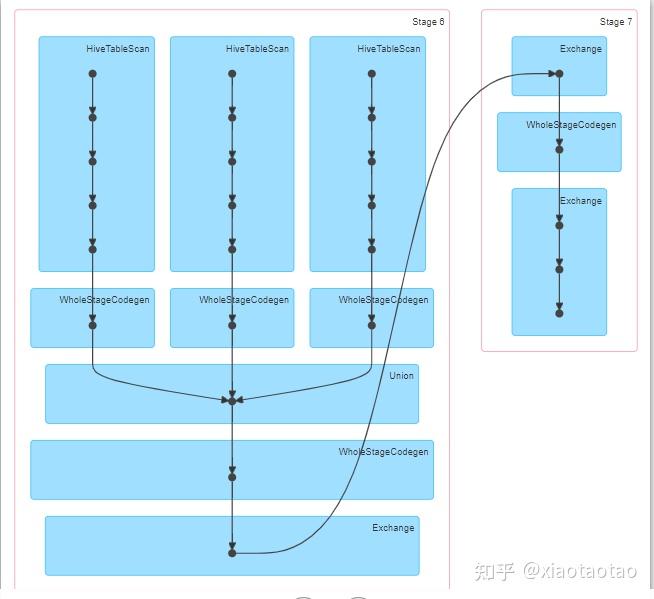
stage6耗费了1.2min,stage7耗费了1s的时间


join方式的计算stage比较多,每个子查询组成一个stage,但是子查询可以并行执行,例如图中的stage11、12、13可以并行执行,三个stage一共有600个任务,这跟union的任务是一致的,主要取决于数据量的大小。不过也可以看到每个子查询的数据聚合都在最后一个stage里进行,即stage14,而且join的过程也在stage14进行。也就是数据的聚合和join都在一个stage里进行。
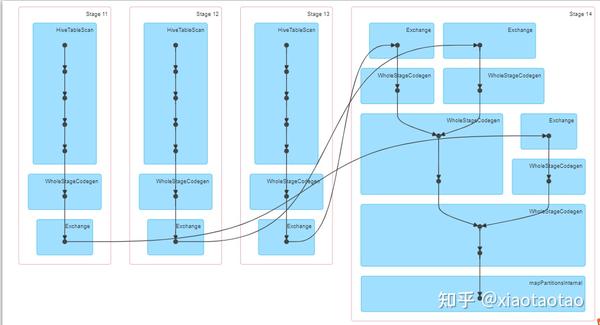
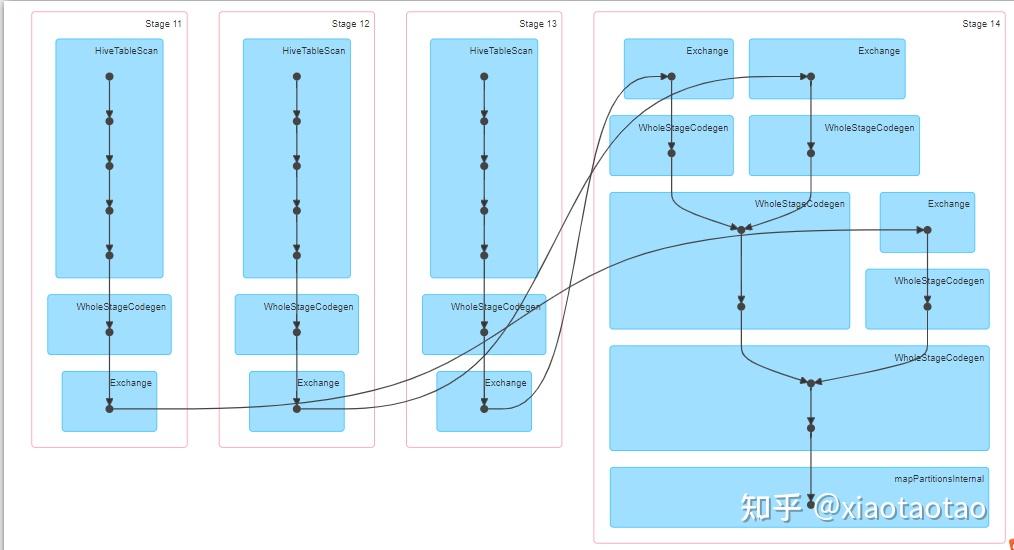
可以看到join下stage11、12、13共耗费了1.2min,stage14耗费了6s的时间
经过分析可以发现在sparksql下两者计算性能相当的原因是大部分的时间都耗费在了数据的读取过程,也就是io上,join下的stage14确实比union下的stage7要耗时,因为stage14不仅要进行数据聚合还要进行join。stage7仅进行数据聚合就可以。但是多耗费的几秒钟时间对于整体而言无可厚非。join过程能够这么快的执行也得益于spark优秀的DAG结构。
hive
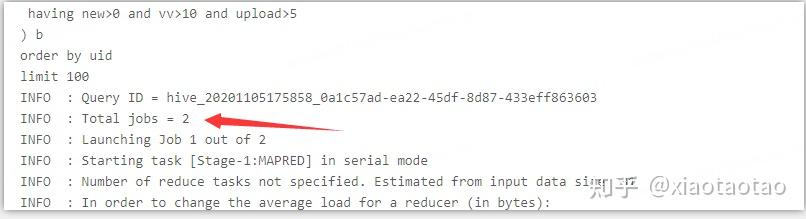
在hive下,union的计算在2min左右,join的计算在4min左右。union的算法性能要高于join。
union情况下的stage有2个:
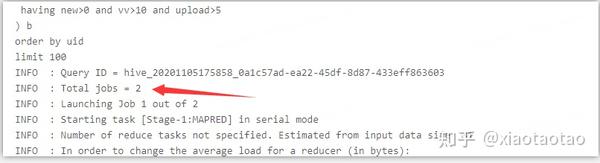
join的stage有6个:
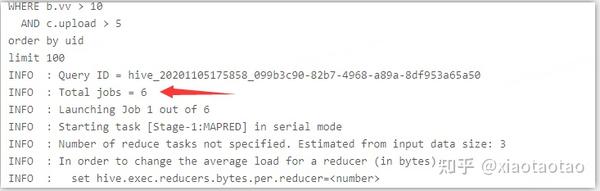
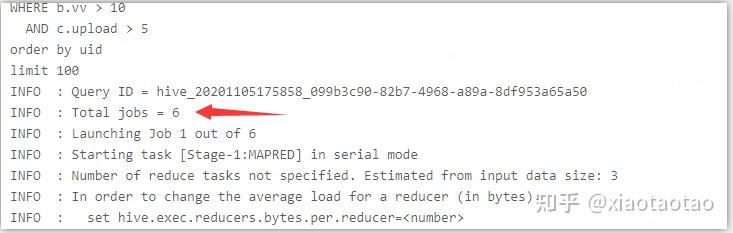
union的job1有470个mapper


join的job1、2、3加起来也是470个mapper,跟union一样,也是由数据的大小所决定的。
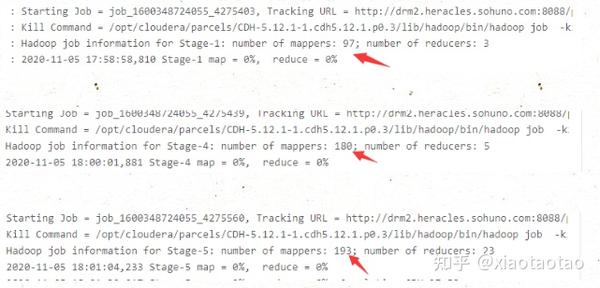
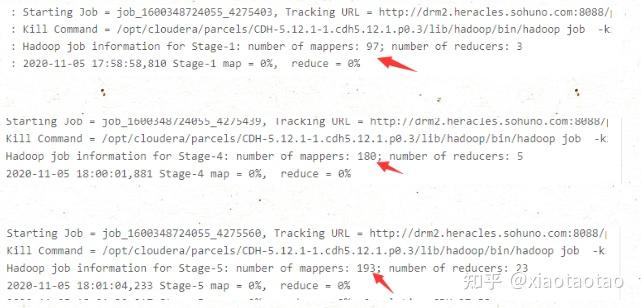
此外,join的方式还要进行一个job4来进行三个表的join操作
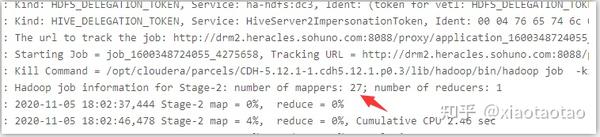
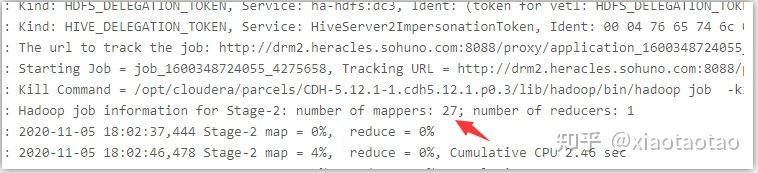
由此可以分析出,hive join要比union慢的原因是因为stage较多,而且stage是串行执行的,也就是说子查询即使互不相关也要进行串行查询,每个job都有map和reduce。还需要一个job来进行join操作,本例中这个join操作耗时了36s。union快的原因就是因为减少了stage数,减少了io,提高了资源利用率。
3、什么情况可以用UNION代替JOIN?
1)、条件要求:join各个数据集的维度相同,join的key等于各个数据集的维度,并且结果要求按照该维度进行去重。如下(d=dimension, m=metric, c=column):
SELECT
a.d1,
a.d2,
a.m1,
(SELECT d1, d2, SUM(m1) m1 FROM table1 WHERE c1=X GROUP BY d1, d2) a
(SELECT d1, d2, SUM(m2) m2 FROM table2 WHERE c2=Y GROUP BY d1, d2) b
ON a.d1=b.d1
AND a.d2=b.d2
这种情况下a、b的维度都是d1、d2,并且以此为join的key。最后的结果是根据d1、d2去重的。
那么就可以改成union all如下:
SELECT
SUM(CASE WHEN tp='a' THEN 1 ELSE 0 END) AS a,
SUM(CASE WHEN tp='b' THEN 1 ELSE 0 END) AS b,
SUM(m1) m1,
SUM(m2) m2
FROM(
SELECT d1, d2, m1, 0 AS m2, 'a' AS tp FROM table1 WHERE c1=X
UNION ALL
SELECT d1, d2, 0 AS m1, m2, 'b' AS tp FROM table2 WHERE c2=Y
GROUP BY d1, d2
HAVING a>0 AND b>0
统计a和b指标是为了看维度d1、d2在table1和table2中是否出现,这属于无数值意义的统计指标,HAVING用来展示哪个表的结果,这跟join方式有关:
JOIN => a>0 AND b>0
LEFT JOIN => a>0
RIGHT JOIN => b>0
FULL JOIN => a>0 OR b>0 或者 无条件限制
2)、性能要求:在满足1的条件要求下,如果union的性能要明显高于join,那么推荐使用union。在hive执行模式下,一般union性能都要高于join,如果数据量越大,差距也越明显
- 嵌套的CASE WHEN统计
有时候要计算某些指标的时候无法直接通过一个case when来得出结果,需要嵌套一个case when的中间结果集来计算。比如,我们要筛选过去一个月内超过20天每天vv(观看视频次数)大于10个,超过15天每天上传视频大于5个,超过10天每天点赞大于10个的用户。
针对这个需求,我们有如下思路:
1、我们最终是通过计算用户的各个指标对应的天数来确定用户,而统计天数首先还需要统计用户每一天的vv、上传、点赞的指标,所以这就构成了一个嵌套的case when指标统计。
2、除此之外,计算的指标还包含在两个表里,计算vv的指标需要t_app_vv表,计算上传和点赞的指标需要t_app_cc表,所以还涉及到多表union的计算。
最终的统计sql如下:
SELECT
COUNT(CASE WHEN vv>20 THEN p_day ELSE NULL END) AS vv_day,
COUNT(CASE WHEN upload>5 THEN p_day ELSE NULL END) AS upload_day,
COUNT(CASE WHEN praise>10 THEN p_day ELSE NULL END) AS praise_day
FROM (
SELECT
p_day,
SUM(CASE WHEN TYPE='vv' THEN 1 ELSE 0 END) AS vv,
SUM(CASE WHEN TYPE='cc' AND url=68023 THEN 1 ELSE 0 END) AS upload,
SUM(CASE WHEN TYPE='cc' AND url=29022 THEN 1 ELSE 0 END) AS praise
FROM (
SELECT uid, p_day, '' AS url, 'vv' AS TYPE FROM t_app_vv WHERE p_day BETWEEN 20201101 AND 20201130 AND msg='playCount' AND pro=1 AND mtype=6
UNION ALL
SELECT uid, p_day, url, 'cc' AS TYPE FROM t_app_cc WHERE p_day BETWEEN 20201101 AND 20201130 AND url IN (68023, 29022) AND pro=1 AND mtype=6
GROUP BY uid, p_day
GROUP BY uid
HAVING vv_day>20 AND upload_day>15 AND praise_day>10经spark sql查询,一共有71个用户
观察这个sql,其实在上述《无数值意义的统计指标》就已经体现出来了,都是在一个结果之上进行另一个结果的查询,我称之为嵌套的指标查询。
实际应用举例
dm4要开发一个分层月报看板,要计算主动用户的活跃度分层,看每个级别的用户数。
分层的级别有:
新增用户:t_app_bd_stat中newuser=1的用户;
高活用户:过去30天内使用app大于8天的用户,url=1002 | 2002的为使用用户;
中活用户:过去30天内使用app大于4天,小于等于8天的用户;
低活用户:过去30天内使用app大于等于1天,小于等于4天的用户;
回流用户:过去30天内没有使用过app的老用户,即使用天数为0并且newuser=0;
对于新增用户还需要知道渠道来源,以计算每个渠道的新增用户。
这个需求其实是分为两个计算的,一个计算分层用户数,一个是计算渠道的新增数。我们需要建立一个中间模型,对主动用户进行标记,标记用户是否为新增、活跃级别、新用户的渠道几个字段。把模型建立好了,计算就统计了。
建模思路
1、计算涉及到三个表:
主动用户表initiative_user,包含mtype、uid两个字段,已经去重;
新增表t_app_bd_stat,newuser=1代表新增用户;
行为表t_app_action,url in (1002,2002)代表使用dau;
为了提升hive的计算性能,采用union的方式统计用户的各个指标:渠道、主动用户、新增用户、过去30天内的使用天数;
1)、主动用户、新增用户这两个指标是无数值意义的,只有0和非0之分。通过sum或者count计算;
2)、过去30天内的使用天数这个指标是有数值意义的。通过count distinct计算;
3)、渠道这个指标严格来说不是一个指标,而是用户的一个属性,需要从新增表来获取。将主动用户数据和行为数据的渠道设置为空值,新增表的渠道为原始值,通过max计算,那么主动用户和新增用户的交集用户(即主动用户中的新增用户)就可以获取到新增表中的渠道id;
2、根据1中的统计结果对用户进行标签化处理,因为我们要求主动用户的数据,所以只需要1中主动用户指标>0的用户。用户有3个标签字段:channelid、newuser、actvie_type。通过case when语句来进行标记,这就是一个嵌套的case when统计,但这个case when只是相当于一个维度列的普通函数。
- 建模
建模sql如下:
INSERT overwrite TABLE initiative_user_active PARTITION(p_day=$idate)
SELECT
mtype,
(CASE WHEN newuser>0 THEN 1 ELSE 0 END) AS newuser,
(CASE
WHEN use_days>8 THEN 'high'
WHEN use_days>4 AND use_days<=8 THEN 'middle'
WHEN use_days>0 AND use_days<=4 THEN 'low'
WHEN use_days=0 AND newuser=0 THEN 'callback'
ELSE 'other'
END) AS active_type,
channelid
FROM (
SELECT
mtype,
MAX(channelid) AS channelid,
SUM(CASE WHEN TYPE='initiative' THEN 1 ELSE 0 END) AS initiative,
SUM(CASE WHEN TYPE='newuser' THEN 1 ELSE 0 END) AS newuser,
COUNT(DISTINCT CASE WHEN TYPE='dau' THEN p_day ELSE NULL END) AS use_days
FROM(
SELECT mtype, uid, p_day, '' AS channelid, 'initiative' AS TYPE FROM initiative_user WHERE p_day=$idate
UNION ALL
SELECT mtype, uid, p_day, channelid, 'newuser' AS TYPE FROM t_app_bd_stat WHERE p_day=$idate AND newuser=1 AND pro=1
UNION ALL
SELECT mtype, uid, p_day, '' AS channelid, 'dau' AS TYPE FROM t_app_action WHERE p_day BETWEEN $day_30_ago AND $day_1_ago AND url IN (1002, 2002) AND pro=1
GROUP BY mtype, uid
WHERE b.initiative > 0
- 计算
建完模型之后,计算就变得简单了,计算也是通过case when来进行。
计算各个活跃分层用户:
SELECT
'$idate',
mtype,
COUNT(uid) AS dau,
COUNT(CASE WHEN newuser=1 THEN uid ELSE NULL END) AS new_users,
COUNT(CASE WHEN active_type='high' THEN uid ELSE NULL END) AS high_active_users,
COUNT(CASE WHEN active_type='middle' THEN uid ELSE NULL END) AS middle_active_users,
COUNT(CASE WHEN active_type='low' THEN uid ELSE NULL END) AS low_active_users,
COUNT(CASE WHEN active_type='callback' THEN uid ELSE NULL END) AS callback_user
FROM initiative_user_active
WHERE p_day=$idate
AND mtype IN (0,1,3,6)
GROUP BY mtype可以看到这两个计算的聚合函数都没有使用count distinct,而是直接使用的count,这是因为在模型表initiative_user_active中mtype和uid是去重的,再对mtype进行维度统计时,uid都是唯一的,不存在重复记录,所以直接使用count或者sum即可。
计算各个渠道的新增用户:
SELECT
'$idate',
channel,
COUNT(uid) AS newuser
FROM(
SELECT
WHEN channelid = '1' THEN 'app_store'
WHEN channelid = '315' THEN 'vivo'
WHEN channelid = '6581' THEN 'huawei'
WHEN channelid = '6562' THEN 'xiaomi'
WHEN channelid = '281' THEN 'oppo'
WHEN channelid IN ('6580','1006034683') THEN '360'
WHEN channelid IN ('1006033201','6787') THEN 'myapp'
ELSE 'other'
END AS channel,
FROM initiative_user_active
WHERE p_day=$idate