

RWKV语言模型从入门到放弃,保姆级Training、Fine-tuning、Lora入坑教程



环境
1、安装 CUDA 11.7,Python 3.10
2、安装一些 pip 库和 pytorch 1.13.1+cu117
pip install numpy tokenizers prompt_toolkit
pip install torch --extra-index-url https://download.pytorch.org/whl/cu117 --upgrade
pip install rwkv --upgradeChatRWKV
模型下载地址 https:// huggingface.co/BlinkDL


补充:Pile模型是指基础模型,仅做了Pile的语料训练,相对比较干净,更适合有自己语料的高手在垂直领域中训练自己的大语言模型。
详情介绍可查阅RWKV作者的文章 https:// zhuanlan.zhihu.com/p/61 8011122
仓库地址 https:// github.com/BlinkDL/Chat RWKV
git clone https://github.com/BlinkDL/ChatRWKV.git切换到 cd v2 目录下
执行chat.py脚本
python chat.pychat.py 脚本的部分参数说明
可根据自身需求调整以下对应的参数:
1、确定中英文等语言模式
CHAT_LANG = 'English' # English // Chinese // more to come
2、 修改对应模式下的 args.MODEL_NAME 模型路径值,注意不需要 .pth 后缀结尾
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v9x-Eng49%-Chn50%-Other1%-20230418-ctx4096'
3、 根据自身设备需求来调整运行策略
args.strategy = 'cuda fp16'
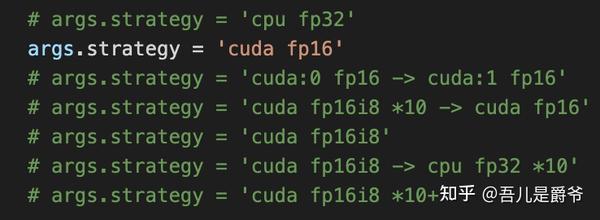

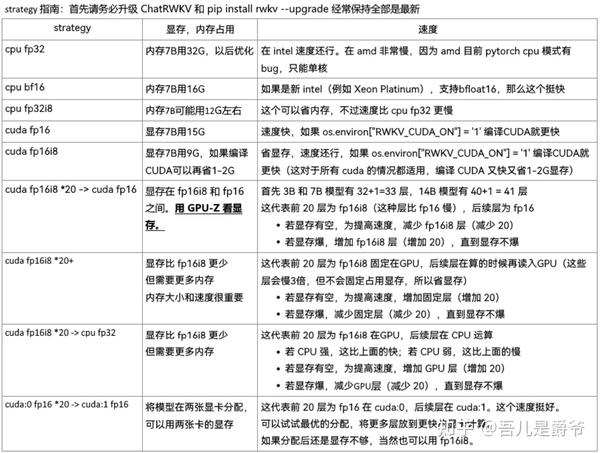
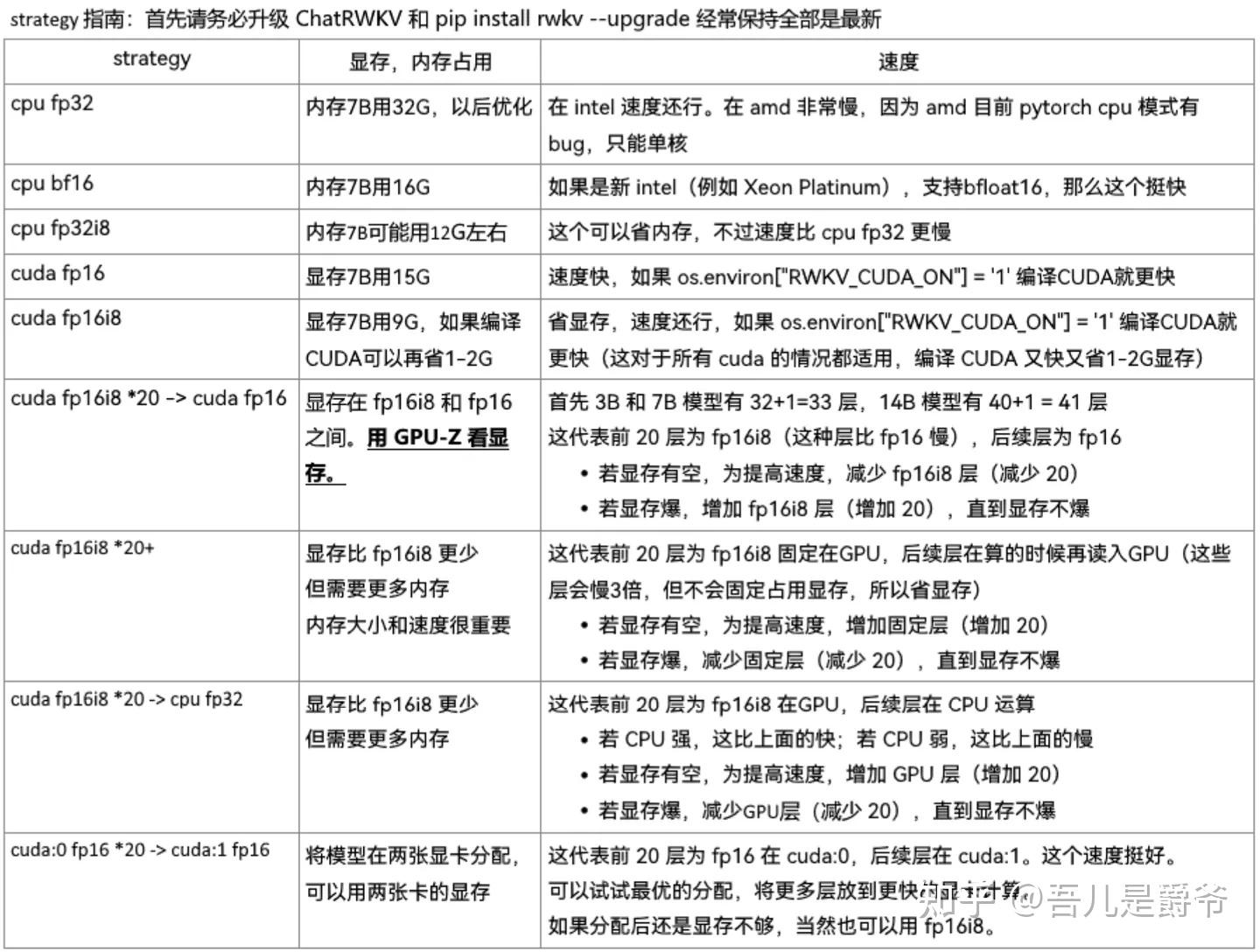
详情介绍可查阅RWKV作者的文章 https:// zhuanlan.zhihu.com/p/61 8011122
4、 采样参数阐释
GEN_TEMP = 1.1 # It could be a good idea to increase temp when top_p is low
GEN_TOP_P = 0.7 # Reduce top_p (to 0.5, 0.2, 0.1 etc.) for better Q&A accuracy (and less diversity)
GEN_alpha_presence = 0.2 # Presence Penalty
GEN_alpha_frequency = 0.2 # Frequency Penalty
- top_p(默认0.7):在采样时截取前p%可能出现token采样。更小的top_p → 更准确的答案,但会增加输出重复内容的概率;
- temp(默认1.1):改变模型输出分布的随机性,温度越高 → 输出随机性越大,文采斐然,但更容易偏题、脱轨;
- alpha_presence(默认0.2):为避免复读,惩罚出现过的token,某token首次出现,后续得分扣除 alpha_presence;
- alpha_frequency(默认0.2):为避免复读,惩罚重复出现的token,出现N次得分扣 alpha_frequency x N;
注意:过大的alpha值可能导致输出文不对题、脱轨、乱码等。
可以尝试的组合:
回答问题
- top_p = 0.2(或者0.0)
- temp = 1.0
- alpha_presence= 0.1
- alpha_frequency = 0.1
写故事
- top_p = 0.5
- temp = 1.5
- alpha_presence= 0.3
- alpha_frequency = 0.3
总之,top_p大,temp就必须小
5、 输出内容的长度,让回答的字符更长一些
CHAT_LEN_LONG = 150
FREE_GEN_LEN = 256
Training / Fine-tuning
官方教程地址 https:// github.com/BlinkDL/RWKV -LM/#training--fine-tuning
git clone https://github.com/BlinkDL/RWKV-LM.git切换到 cd RWKV-v4neo 目录下
执行train.py脚本
python train.py \
--load_model "/cfs/cfs-307cx1ch/wbx/Pth/RWKV-4-Raven-3B-v10x-Eng49-Chn50-Other1-20230423-ctx4096.pth" \
--proj_dir "/cfs/cfs-307cx1ch/wbx/OutBinIdx" \
--data_file "/workspace/team_code_tegcdcai/wbx/rwkv/Datasets/CoDesign_text_document" \
--data_type binidx \
--vocab_size 50277 \
--ctx_len 1024 \
--accumulate_grad_batches 8 \
--epoch_steps 10 \
--epoch_count 10 \
--epoch_begin 0 \
--epoch_save 2 \
--micro_bsz 1 \
--n_layer 32 \
--n_embd 2560 \
--pre_ffn 0 \
--head_qk 0 \
--lr_init 1e-5 \
--lr_final 1e-5 \
--warmup_steps 0 \
--beta1 0.9 \
--beta2 0.999 \
--adam_eps 1e-8 \
--accelerator gpu \
--devices 8 \
--precision fp16 \
--strategy deepspeed_stage_2 \
--grad_cp 1train.py 脚本的参数详解
python train.py
--load_model RWKV预训练的底模型.pth (需要带上.pth后缀)
--proj_dir /path/save_pth 最后训练好的pth保存的路径,注意不要以 / 结尾,否则会出现找不到目录
--data_file /path/file 预处理语料数据(如果是binidx语料,不需要加bin或idx,只要文件名)
--data_type binidx 语料的格式,目前支持"utf-8", "utf-16le", "numpy", "binidx", "dummy", "wds_img", "uint16"
--vocab_size 50277 词表大小,格式转换的时候,最后返回的一个数值,txt数据的时候可以设置为0表示自动计算
--ctx_len 1024(看显存,越大越好,模型文件名有最大ctx_len)
--accumulate_grad_batches 8 (貌似已废用)
--epoch_steps 1000 指每个epoch跑1000步
--epoch_count 20 指跑20个epoch,但是在rwkv中不会自动停止训练,需要人工停止,所以这个参数没什么大作用
--epoch_begin 0 epoch开始值,表示从第N个epoch开始加载
--epoch_save 5 训练第几轮开始自动保存,5表示每5轮epoch自动保存一个pth模型文件
--micro_bsz 1 微型批次大小(每个GPU的批次大小)(改大应该会更好些,显存占用更大)
--n_layer 32(看模型,Pile上有介绍)
--n_embd 2560(看模型,Pile上有介绍)
--pre_ffn 0 用ffn替换第一个att层(有时更好)
--head_qk 0 headQK技巧
--lr_init 6e-4 6e-4表示L12-D768,4e-4表示L24-D1024,3e-4表示L24-D2048
--lr_final 1e-5
--warmup_steps 0 预热步骤,如果你加载了一个模型,就试试50
--beta1 0.9
--beta2 0.999 当你的模型接近收敛时使用0.999
--adam_eps 1e-8
--accelerator gpu 目前有gpu、cpu,但是正常情况下cpu是无法支持training的
--devices 1 (单卡为1,多卡就按照对应的卡数来填写,比如8卡就填写8)
--precision fp16 策略精度,目前支持"fp32", "tf32", "fp16", "bf16"
--strategy deepspeed_stage_2 这是lightning吃的策略参数,顾名思义是deepspeed的stage 2
--grad_cp 1(开启加速) 配置这个显存量,0应该可以直接全量
更多参数介绍可以看train.py脚本中的代码train.py脚本中的--precision参数参考以下,fp16是训练最快
train.py脚本中的--n_layer、--n_embd参数值,参考以下:
3B模型 https:// huggingface.co/BlinkDL/ rwkv-4-pile-3b


7B模型 https:// huggingface.co/BlinkDL/ rwkv-4-pile-7b


14B模型 https:// huggingface.co/BlinkDL/ rwkv-4-pile-14b


正常来说训练了10~20个epoch就好,然后采取二分测试法,选择中间的pth来进行测试,比如一共训练了20epoch,那就先测试rwkv_10 先,如果有问题就再试试rwkv_5,以此类推
运行已Training好的模型
切换train.py同级目录下, 运行 chat.py 或者 在Chat RWKV的v2中运行 chat.py
python chat.py脚本的参数与ChatRWKV差不多,主要就修改下MODEL_NAME 模型路径值,就是以上--proj_dir 的路径
语料格式
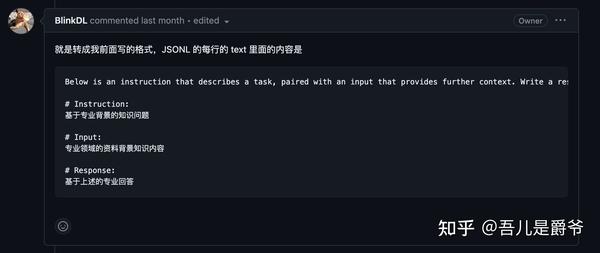
基于Pile基础模型,jsonl格式建议如下
{"text": "Instruction:基于专业背景的知识问题\n\nInput:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答"}
{"text": "\nInstruction:基于专业背景的知识问题\n\nInput:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答\n"}
{"text": "\n\nInstruction:基于专业背景的知识问题\n\nInput:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答\n\n"}
{"text": "\n\nInstruction:基于专业背景的知识问题\n\nInput:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答\n基于上述的专业回答\n\n"}Instruction 是指示,Input 是需要操作的数据,Response是答案
{"text": "Instruction:基于专业背景的知识问题\n\nContext:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答"}
{"text": "\nInstruction:基于专业背景的知识问题\n\nContext:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答\n"}
{"text": "\n\nInstruction:基于专业背景的知识问题\n\nContext:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答\n\n"}
{"text": "\n\nInstruction:基于专业背景的知识问题\n\nContext:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答\n基于上述的专业回答\n\n"}目前支持 Context ! 而Context相当于上述的Input,是用于补充材料,不是回答!!!
可参考官方说法
关于训练数据集 · Issue #102 · BlinkDL/ChatRWKV

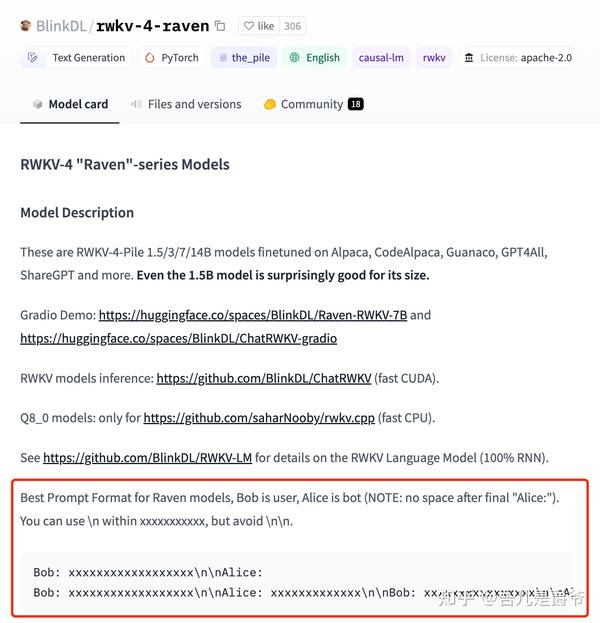
基于Raven对话模型,jsonl格式建议如下(Instruction - Response的格式也可以)
Bob是指用户提问方,Alice是指机器人回答方
{"text": "Bob: 提问\n\nAlice: 回答"}
{"text": "\nBob: 提问\n\nAlice: 回答\n"}
{"text": "\n\nBob: 提问\n\nAlice: 回答\n\n"}
{"text": "\n\nBob: 提问\n\nAlice: 回答\n回答\n\n"}如果是FAQ问答式可以试试以下的jsonl格式
{"text": "Q: 问题\n\nA: 答案"}
{"text": "\nQ: 问题\n\nA: 答案\n"}
{"text": "\n\nQ: 问题\n\nA: 答案\n\n"}
{"text": "\nQ: 问题\n\nA: 答案\n答案\n"}可参考官方的说法
最终还是根据自身的需求来定制语料就好,需要怎么使用,就怎么写语料格式。
开源语料
数据集 https:// huggingface.co/datasets
基础数据 https:// huggingface.co/datasets /JeanKaddour/minipile
WuDaoCorpora Text文本预训练数据 https:// data.baai.ac.cn/details /WuDaoCorporaText
jsonl转binidx文件
对于大语料来说,把jsonl文件格式转换成binidx文件格式,会更有利于训练
仓库地址 https:// github.com/Abel2076/jso n2binidx_tool
git clone https://github.com/Abel2076/json2binidx_tool.git切换到根目录
执行 preprocess_data.py 脚本
python ./tools/preprocess_data.py
--input /dataset/CoDesign.jsonl
--output-prefix /dataset/CoDesign
--vocab 20B_tokenizer.json
--dataset-impl mmap
--tokenizer-type HFTokenizer
--append-eodpreprocess_data.py 脚本部分的参数说明
python ./tools/preprocess_data.py
--input /path/CoDesign.jsonl jsonl文件的位置
--output-prefix /path/CoDesign文件名前缀 用于存储生成bin和idx文件的路径,并且CoDesign是输出的文件名前缀而已,注意并不是目录路径,代码中会自动拼接文件的名字和后缀
--vocab 20B_tokenizer.json 项目中的根目录下就有
--dataset-impl mmap 数据集实现方式,默认使用mmap。目前支持"lazy", "cached", "mmap"
--tokenizer-type HFTokenizer 类型的标记器,目前支持 "HFGPT2Tokenizer","HFTokenizer","GPT2BPETokenizer","CharLevelTokenizer", "TiktokenTokenizer"
--append-eod 开启将<eod>标记附加到文档的末尾最终生成的文件,可直接用于做模型的Training


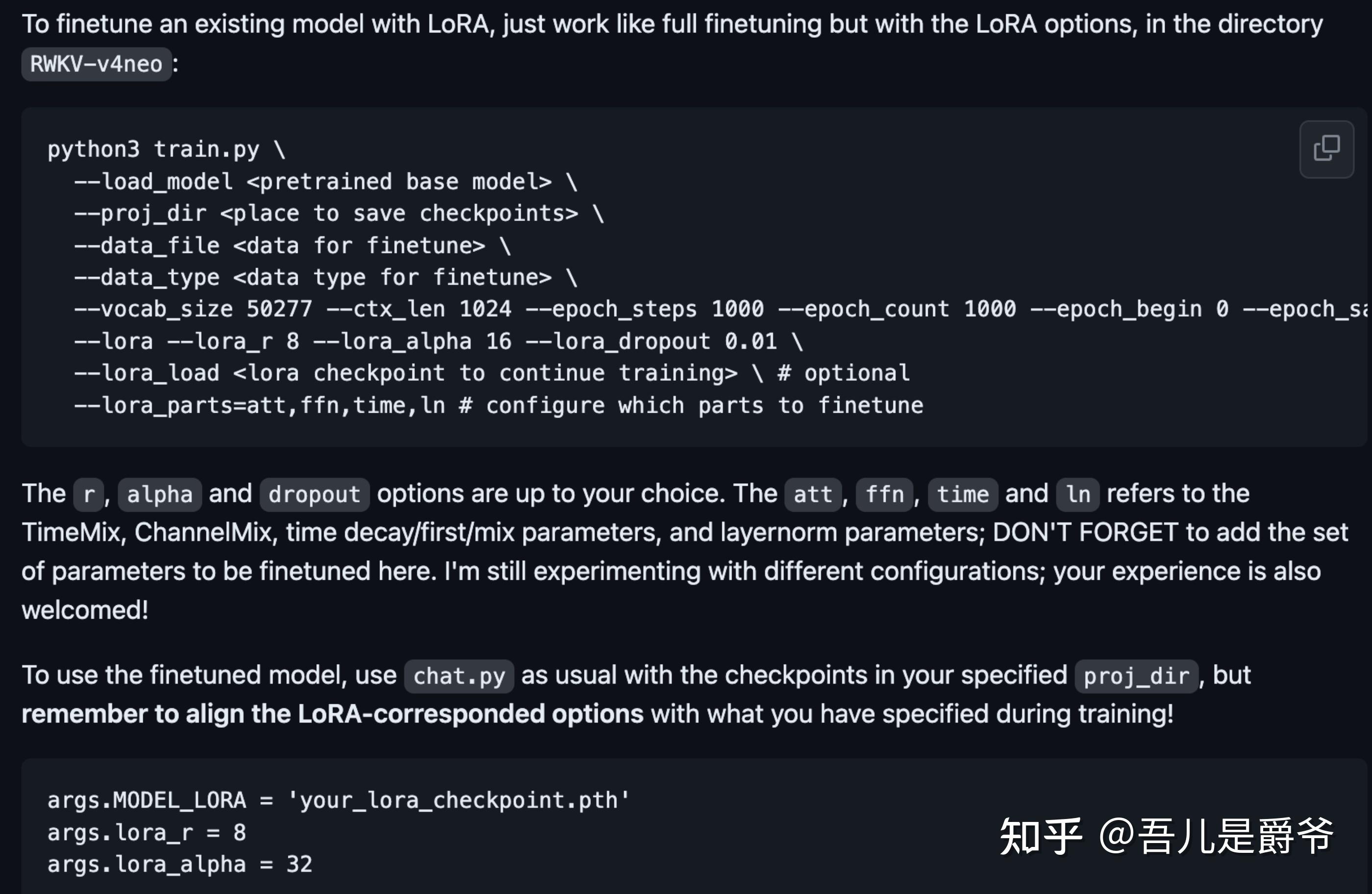
LoRA微调
使用LoRA的方式进行微调,先对Training来说设备要求会低很多
仓库地址 https:// github.com/Blealtan/RWK V-LM-LoRA
git clone https://github.com/Blealtan
/RWKV-LM-LoRA.gitLoRA微调只是比上述的Training / Fine-tuning步骤一样的,只是多几个参数而已
切换到 cd RWKV-v4neo 目录下
执行train.py脚本
python train.py \
--load_model "/cfs/cfs-307cx1ch/wbx/Pth/RWKV-4-Raven-3B-v10x-Eng49-Chn50-Other1-20230423-ctx4096.pth" \
--proj_dir "/cfs/cfs-307cx1ch/wbx/OutBinIdx" \
--data_file "/workspace/team_code_tegcdcai/wbx/rwkv/Datasets/CoDesign_text_document" \
--data_type binidx \
--vocab_size 50277 \
--ctx_len 1024 \
--accumulate_grad_batches 8 \
--epoch_steps 10 \
--epoch_count 10 \
--epoch_begin 0 \
--epoch_save 2 \
--micro_bsz 1 \
--n_layer 32 \
--n_embd 2560 \
--pre_ffn 0 \
--head_qk 0 \
--lr_init 1e-5 \
--lr_final 1e-5 \
--warmup_steps 0 \
--beta1 0.9 \
--beta2 0.999 \
--adam_eps 1e-8 \
--accelerator gpu \
--devices 8 \
--precision fp16 \
--strategy deepspeed_stage_2 \
--grad_cp 1 \
--lora \
--lora_r 8 \
--lora_alpha 32 \
--lora_dropout 0.01 \
--lora_parts=att,ffn,time,ln \
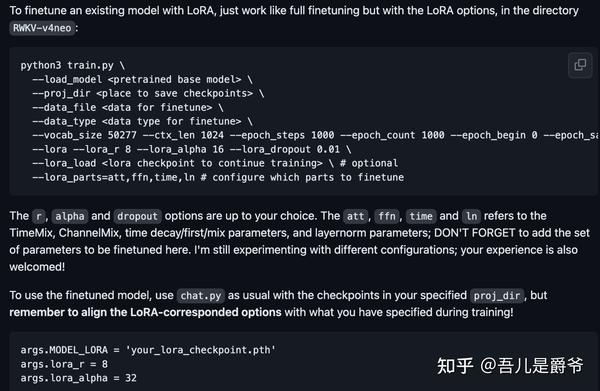
--lora_load /path/lora.pth train.py 脚本的Lora相关参数详解
python train.py
--load_model RWKV预训练的底模型.pth (需要带上.pth后缀)
--proj_dir /path/save_pth 最后训练好的pth保存的路径,注意不要以 / 结尾,否则会出现找不到目录
--data_file /path/file 预处理语料数据(如果是binidx语料,不需要加bin或idx,只要文件名)
--data_type binidx 语料的格式,目前支持"utf-8", "utf-16le", "numpy", "binidx", "dummy", "wds_img", "uint16"
--vocab_size 50277 词表大小,格式转换的时候,最后返回的一个数值,txt数据的时候可以设置为0表示自动计算
--ctx_len 1024(看显存,越大越好,模型文件名有最大ctx_len)
--accumulate_grad_batches 8 (貌似已废用)
--epoch_steps 1000 指每个epoch跑1000步
--epoch_count 20 指跑20个epoch,但是在rwkv中不会自动停止训练,需要人工停止,所以这个参数没什么大作用
--epoch_begin 0 epoch开始值,表示从第N个epoch开始加载
--epoch_save 5 训练第几轮开始自动保存,5表示每5轮epoch自动保存一个pth模型文件
--micro_bsz 1 微型批次大小(每个GPU的批次大小)(改大应该会更好些,显存占用更大)
--n_layer 32(看模型,Pile上有介绍)
--n_embd 2560(看模型,Pile上有介绍)
--pre_ffn 0 用ffn替换第一个att层(有时更好)
--head_qk 0 headQK技巧
--lr_init 6e-4 6e-4表示L12-D768,4e-4表示L24-D1024,3e-4表示L24-D2048
--lr_final 1e-5
--warmup_steps 0 预热步骤,如果你加载了一个模型,就试试50
--beta1 0.9
--beta2 0.999 当你的模型接近收敛时使用0.999
--adam_eps 1e-8
--accelerator gpu 目前有gpu、cpu,但是正常情况下cpu是无法支持training的
--devices 1 (单卡为1,多卡就按照对应的卡数来填写,比如8卡就填写8)
--precision fp16 策略精度,目前支持"fp32", "tf32", "fp16", "bf16"
--strategy deepspeed_stage_2 这是lightning吃的策略参数,顾名思义是deepspeed的stage 2
--grad_cp 1 (开启加速) 配置这个显存量,0应该可以直接全量
--lora 开启lora训练
--lora_r 8 r 越多,可训练参数越多
--lora_alpha 32 alpha 越大,可以看作等效学习率越大
--lora_dropout 0.01 dropout用来防过拟合
--lora_parts=att,ffn,time,ln 这里att, ffn, time 和 ln指的是TimeMix, ChannelMix, time decay/first/mix参数, layernorm参数;
--lora_load /path/lora.pth 是指你已lora训练好的pth文件,如果想继续之前已lora训练好的pth上继续Lora训练,那么这里就填写pth对应的路径即可。如果没有则删除这个参数即可。更多参数介绍可以看train.py脚本中的代码,以及Lora仓库的介绍
运行已lora训练好的模型
切换到根目录下, 运行 chat.py
python chat.py脚本的参数与ChatRWKV差不多,就增多了Lora相关的参数配置
主要就调整以下参数即可
args.MODEL_NAME = '/home/blealtancao/rwkv-models/RWKV-4-Pile-14B-20230227-ctx4096-test503'
args.MODEL_LORA = '/home/blealtancao/rwkv-models/lora-full-1e-4/rwkv-33'
MODEL_NAME 指预训练的Pth文件路径,注意不需要 .pth 后缀
MODEL_LORA 指已Lora训练好的Pth文件路径,注意不需要 .pth 后缀。也就是上述--proj_dir 的路径中
args.lora_r 、args.lora_alpha 、n_layer、n_embd 就根据训练时的传值来调整即可如果运行中提示RWKV_JIT_ON,可改成执行RWKV_JIT_ON=1 python chat.py 来运行(包含前面的RWKV_JIT_ON=1)
RWKV_JIT_ON=1 python chat.py正常来说训练了10~20个epoch就好,然后采取二分测试法,选择中间的pth来进行测试,比如一共训练了20epoch,那就先测试rwkv_10 先,如果有问题就再试试rwkv_5,以此类推
合并Pth模型
把预训练的基础模型和Lora微调好的模型合并成一个模型
执行merge_lora.py脚本
python merge_lora.py --use-gpu 32 /cfs/cfs-307cx1ch/wbx/Pth/RWKV-4-Raven-7B-v10-Eng49-Chn50-Other1-20230420-ctx4096.pth /cfs/cfs-307cx1ch/wbx/Lora/rwkv-50.pth /cfs/cfs-307cx1ch/wbx/Lora/rwkv-50-merge.pth
参数说明:
python merge_lora.py [--use-gpu] <lora_alpha> <base_model.pth> <lora_checkpoint.pth> <output.pth>
--use-gpu 开启gpu加速
lora_alpha 是指lora训练的时候的lora_alpha值,正常是32
base_model.pth RWKV预训练的底模型.pth (需要带上.pth后缀)
lora_checkpoint.pth 已Lora训练好的pth文件(需要带上.pth后缀)
output.pth 合并的pth文件的存储路径(需要带上.pth后缀)合成后的pth模型,就可以直接在ChatRWKV上运行了,就不需要在依赖RWKV- LM-LORA项目中的chat.py了
RWKV World模型
常规问题
1、官方教程:
https://
zhuanlan.zhihu.com/p/63
8326262
2、环境务必保证 rwkv 0.7.4+ ,可执行 pip install rwkv --upgrade 进行升级
语料上特别注意事项
1、 注意Raven模型和World模型的词表不同,数据转换方法不同
2、 所以,在jsonl转binidx文件的时候特别需要注意词表是使用 rwkv_vocab_v20230424.txt,具体可以更新最新的
https://
github.com/Abel2076/jso
n2binidx_tool
Git项目查阅。
3、 在准备Rwkv World模型的binidx文件的时候,--vocab、--tokenizer-type参数都需要注意有变化的,和Raven模型略有所不同。
4、 执行 preprocess_data.py 脚本
python ./tools/preprocess_data.py \
--input /dataset/CoDesign.jsonl \
--output-prefix /dataset/CoDesign \
--vocab rwkv_vocab_v20230424.txt \
--dataset-impl mmap \
--tokenizer-type RWKVTokenizer \
--append-eod
5、 语料格式,在World模型中就不建议再使用
Bob/Alice 或 Q/A
了,为了防止污染正常人名,所以在World模型中推荐使用
Question/Answer
这样的预料格式。


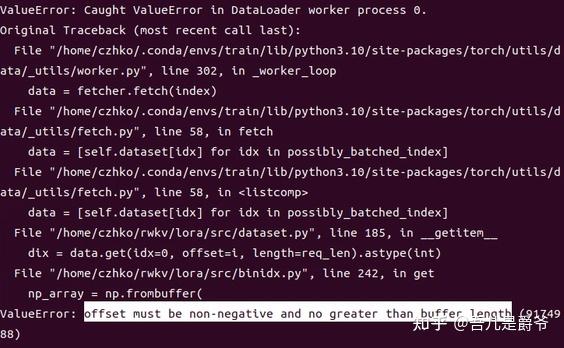
Training/Lora的时候需要注意事项
整体来说,训练微调的时候并没有太大变化,参照上面的教程执行即可。
倘如遇到以下错误提示:

请务必更新最新的Git代码
https://
github.com/Blealtan/RWK
V-LM-LoRA
和
https://
github.com/BlinkDL/RWKV
-LM/
在Tarining的时候遇到上面的提示,说明你的代码还是旧的。因为dataset.py有一些小问题需要修复一下。




ChatRwkv的时候需要注意事项
1、 运行World模型,可参考:
https://
github.com/BlinkDL/Chat
RWKV/blob/main/v2/benchmark_world.py
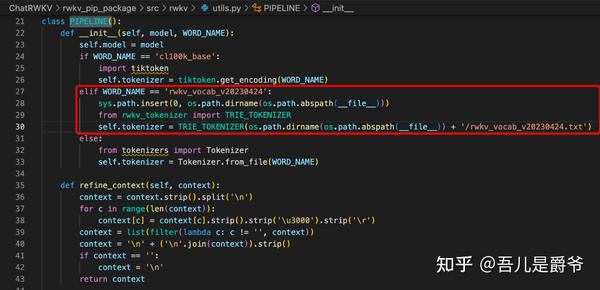
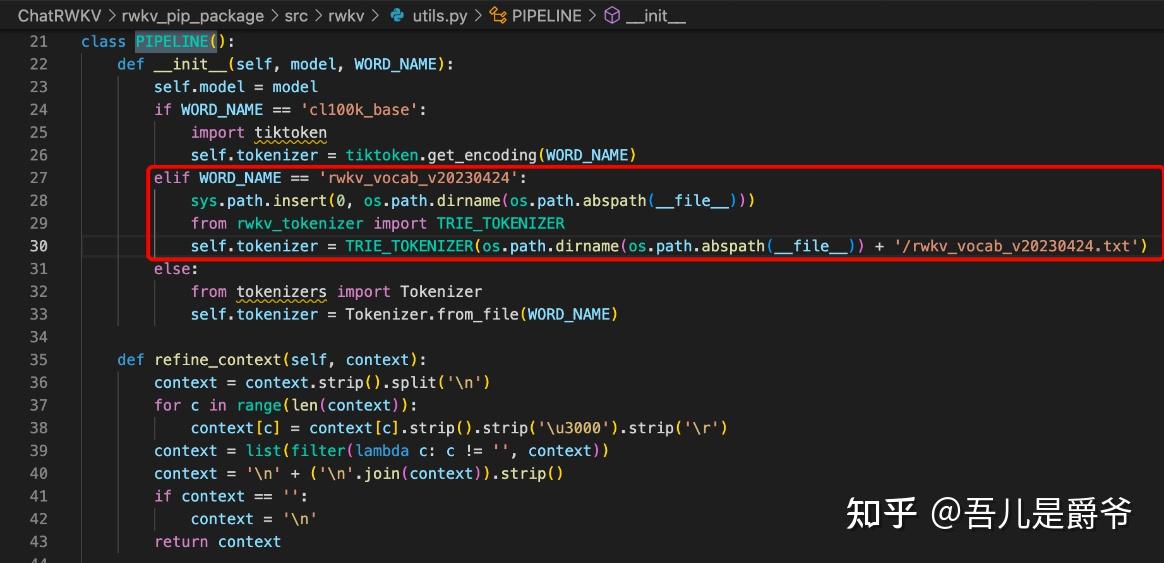
2、 需要特别注意的有两个地方,在World模型中 pipeline = PIPELINE(model, "rwkv_vocab_v20230424") ,这里不再是使用20B_tokenizer.json 而是 rwkv_vocab_v20230424,另外ctx = f'Bob: {q.strip()}\n\nAlice:' 这一句也是需要按照World模型的预料格式调整成 ctx = f'Question: {q.strip()}\n\nAnswer:'
注意:rwkv_vocab_v20230424在ChatRwkv项目中tokenizer目录下
https://
github.com/BlinkDL/Chat
RWKV/blob/main/tokenizer/rwkv_vocab_v20230424.txt
在ChatRwkv项目中只需要填写rwkv_vocab_v20230424就好,也不需要路径和.txt结尾,因为src/utils.py中的PIPELINE类已经帮忙处理好了
3、 RWKV-LM/RWKV-v4neo/chat.py 以及 RWKV-LM-LoRA/RWKV-v4neo/chat.py 项目中运行World模型也是参考上面来修改就好,但是需要注意就是rwkv_vocab_v20230424.txt文件记得Copy过来。
4、 如果不想经常在文件中改来改去这些参数的话,这里在ChatRWKV/v2/chat.py脚本的基础上稍微做了些调整,有需要就直接拿去使用。
在v2目录下创建一个chat_neo.py脚本文件, vim chat_neo.py
########################################################################################################
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
########################################################################################################
from argparse import ArgumentParser
import os, copy, types, gc, sys
current_path = os.path.dirname(os.path.abspath(__file__))
sys.path.append(f'{current_path}/../rwkv_pip_package/src')
import numpy as np
from prompt_toolkit import prompt
os.environ["CUDA_VISIBLE_DEVICES"] = sys.argv[1]
except:
np.set_printoptions(precision=4, suppress=True, linewidth=200)
args = types.SimpleNamespace()
print('\n\nChatRWKV v2 https://github.com/BlinkDL/ChatRWKV')
import torch
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
# Tune these below (test True/False for all of them) to find the fastest setting:
# torch._C._jit_set_profiling_executor(True)
# torch._C._jit_set_profiling_mode(True)
# torch._C._jit_override_can_fuse_on_cpu(True)
# torch._C._jit_override_can_fuse_on_gpu(True)
# torch._C._jit_set_texpr_fuser_enabled(False)
# torch._C._jit_set_nvfuser_enabled(False)
########################################################################################################
# fp16 = good for GPU (!!! DOES NOT support CPU !!!)
# fp32 = good for CPU
# bf16 = less accuracy, supports some CPUs
# xxxi8 (example: fp16i8) = xxx with int8 quantization to save 50% VRAM/RAM, slightly less accuracy
# Read https://pypi.org/project/rwkv/ for Strategy Guide
########################################################################################################
# args.strategy = 'cpu fp32'
# args.strategy = 'cuda fp16'
# args.strategy = 'cuda:0 fp16 -> cuda:1 fp16'
# args.strategy = 'cuda fp16i8 *10 -> cuda fp16'
# args.strategy = 'cuda fp16i8'
# args.strategy = 'cuda fp16i8 -> cpu fp32 *10'
# args.strategy = 'cuda fp16i8 *10+'
os.environ["RWKV_JIT_ON"] = '1' # '1' or '0', please use torch 1.13+ and benchmark speed
os.environ["RWKV_CUDA_ON"] = '0' # '1' to compile CUDA kernel (10x faster), requires c++ compiler & cuda libraries
parser = ArgumentParser()
parser.add_argument("--strategy", default="cpu fp32", type=str)
# parser.add_argument("--strategy", default="cuda fp16", type=str)
parser.add_argument("--MODEL_NAME", default="", type=str)
parser.add_argument("--CHAT_LANG", default="Chinese", type=str) # English Chinese
parser.add_argument("--tokenizer", default="{current_path}/20B_tokenizer.json", type=str) # 词表
parser.add_argument("--user", default="Bob", type=str) # 提问者
parser.add_argument("--bot", default="Alice", type=str) # 机器人回答
args = parser.parse_args()
if not args.MODEL_NAME:
raise Exception('请录入MODEL_NAME参数')
if '.pth' in args.MODEL_NAME:
raise Exception('MODEL_NAME参数请不要带.pth结尾')
print(f'参数:{args.CHAT_LANG} - {args.MODEL_NAME} - {args.strategy}')
# CHAT_LANG = 'Chinese' # English // Chinese // more to come
# Download RWKV models from https://huggingface.co/BlinkDL
# Use '/' in model path, instead of '\'
# Use convert_model.py to convert a model for a strategy, for faster loading & saves CPU RAM
# if CHAT_LANG == 'English':
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v9-Eng99%-Other1%-20230412-ctx8192'
# # args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v10-Eng99%-Other1%-20230418-ctx8192'
# # args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-14b/RWKV-4-Pile-14B-20230313-ctx8192-test1050'
# elif CHAT_LANG == 'Chinese': # Raven系列可以对话和 +i 问答。Novel系列是小说模型,请只用 +gen 指令续写。
# args.MODEL_NAME = '/cfs/cfs-307cx1ch/wbx/OutPth/rwkv-20'
# # args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-novel/RWKV-4-Novel-7B-v1-ChnEng-20230409-ctx4096'
# elif CHAT_LANG == 'Japanese':
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v8-EngAndMore-20230408-ctx4096'
# # args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v9-Eng86%-Chn10%-JpnEspKor2%-Other2%-20230414-ctx4096'
# -1.py for [User & Bot] (Q&A) prompt
# -2.py for [Bob & Alice] (chat) prompt
PROMPT_FILE = f'{current_path}/prompt/default/{args.CHAT_LANG}-2.py'
CHAT_LEN_SHORT = 40
CHAT_LEN_LONG = 2500
FREE_GEN_LEN = 256
# For better chat & QA quality: reduce temp, reduce top-p, increase repetition penalties
# Explanation: https://platform.openai.com/docs/api-reference/parameter-details
GEN_TEMP = 1.1 # It could be a good idea to increase temp when top_p is low
GEN_TOP_P = 0.7 # Reduce top_p (to 0.5, 0.2, 0.1 etc.) for better Q&A accuracy (and less diversity)
GEN_alpha_presence = 0.2 # Presence Penalty
GEN_alpha_frequency = 0.2 # Frequency Penalty
AVOID_REPEAT = ',:?!'
CHUNK_LEN = 256 # split input into chunks to save VRAM (shorter -> slower)
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v9-Eng86%-Chn10%-JpnEspKor2%-Other2%-20230414-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-3B-v9x-Eng49%-Chn50%-Other1%-20230417-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/CODE/_PUBLIC_/RWKV-LM/RWKV-v4neo/7-ENZH/rwkv-88'
# args.MODEL_NAME = '/fsx/BlinkDL/CODE/_PUBLIC_/RWKV-LM/RWKV-v4neo/7-JP/rwkv-5'
########################################################################################################
print(f'\n{args.CHAT_LANG} - {args.strategy} - {PROMPT_FILE}')
from rwkv.model import RWKV
from rwkv.utils import PIPELINE
def load_prompt(PROMPT_FILE):
variables = {}
with open(PROMPT_FILE, 'rb') as file:
exec(compile(file.read(), PROMPT_FILE, 'exec'), variables)
user, bot, interface, init_prompt = variables['user'], variables['bot'], variables['interface'], variables['init_prompt']
init_prompt = init_prompt.strip().split('\n')
for c in range(len(init_prompt)):
init_prompt[c] = init_prompt[c].strip().strip('\u3000').strip('\r')
init_prompt = '\n' + ('\n'.join(init_prompt)).strip() + '\n\n'
return user, bot, interface, init_prompt
# Load Model
print(f'Loading model - {args.MODEL_NAME}')
model = RWKV(model=args.MODEL_NAME, strategy=args.strategy)
pipeline = PIPELINE(model, f"{args.tokenizer}")
END_OF_TEXT = 0
END_OF_LINE = 187
END_OF_LINE_DOUBLE = 535
# pipeline = PIPELINE(model, "cl100k_base")
# END_OF_TEXT = 100257
# END_OF_LINE = 198
model_tokens = []
model_state = None
AVOID_REPEAT_TOKENS = []
for i in AVOID_REPEAT:
dd = pipeline.encode(i)
assert len(dd) == 1
AVOID_REPEAT_TOKENS += dd
########################################################################################################
def run_rnn(tokens, newline_adj = 0):
global model_tokens, model_state
tokens = [int(x) for x in tokens]
model_tokens += tokens
# print(f'### model ###\n{tokens}\n[{pipeline.decode(model_tokens)}]')
while len(tokens) > 0:
out, model_state = model.forward(tokens[:CHUNK_LEN], model_state)
tokens = tokens[CHUNK_LEN:]
out[END_OF_LINE] += newline_adj # adjust \n probability
if model_tokens[-1] in AVOID_REPEAT_TOKENS:
out[model_tokens[-1]] = -999999999
return out
all_state = {}
def save_all_stat(srv, name, last_out):
n = f'{name}_{srv}'
all_state[n] = {}
all_state[n]['out'] = last_out
all_state[n]['rnn'] = copy.deepcopy(model_state)
all_state[n]['token'] = copy.deepcopy(model_tokens)
def load_all_stat(srv, name):
global model_tokens, model_state
n = f'{name}_{srv}'
model_state = copy.deepcopy(all_state[n]['rnn'])
model_tokens = copy.deepcopy(all_state[n]['token'])
return all_state[n]['out']
# Model only saw '\n\n' as [187, 187] before, but the tokenizer outputs [535] for it at the end
def fix_tokens(tokens):
if len(tokens) > 0 and tokens[-1] == END_OF_LINE_DOUBLE:
tokens = tokens[:-1] + [END_OF_LINE, END_OF_LINE]
return tokens
########################################################################################################
# Run inference
print(f'\nRun prompt...')
user, bot, interface, init_prompt = load_prompt(PROMPT_FILE)
if user != args.user:
user = args.user
if bot != args.bot:
bot = args.bot
out = run_rnn(fix_tokens(pipeline.encode(init_prompt)))
save_all_stat('', 'chat_init', out)
gc.collect()
torch.cuda.empty_cache()
srv_list = ['dummy_server']
for s in srv_list:
save_all_stat(s, 'chat', out)
def reply_msg(msg):
print(f'{bot}{interface} {msg}\n')
def on_message(message):
global model_tokens, model_state, user, bot, interface, init_prompt
srv = 'dummy_server'
msg = message.replace('\\n','\n').strip()
x_temp = GEN_TEMP
x_top_p = GEN_TOP_P
if ("-temp=" in msg):
x_temp = float(msg.split("-temp=")[1].split(" ")[0])
msg = msg.replace("-temp="+f'{x_temp:g}', "")
# print(f"temp: {x_temp}")
if ("-top_p=" in msg):
x_top_p = float(msg.split("-top_p=")[1].split(" ")[0])
msg = msg.replace("-top_p="+f'{x_top_p:g}', "")
# print(f"top_p: {x_top_p}")
if x_temp <= 0.2:
x_temp = 0.2
if x_temp >= 5:
x_temp = 5
if x_top_p <= 0:
x_top_p = 0
msg = msg.strip()
if msg == '+reset':
out = load_all_stat('', 'chat_init')
save_all_stat(srv, 'chat', out)
reply_msg("Chat reset.")
return
# use '+prompt {path}' to load a new prompt
elif msg[:8].lower() == '+prompt ':
print("Loading prompt...")
PROMPT_FILE = msg[8:].strip()
user, bot, interface, init_prompt = load_prompt(PROMPT_FILE)
if user != args.user:
user = args.user
if bot != args.bot:
bot = args.bot
out = run_rnn(fix_tokens(pipeline.encode(init_prompt)))
save_all_stat(srv, 'chat', out)
print("Prompt set up.")
gc.collect()
torch.cuda.empty_cache()
except:
print("Path error.")
elif msg[:5].lower() == '+gen ' or msg[:3].lower() == '+i ' or msg[:4].lower() == '+qa ' or msg[:4].lower() == '+qq ' or msg.lower() == '+++' or msg.lower() == '++':
if msg[:5].lower() == '+gen ':
new = '\n' + msg[5:].strip()
# print(f'### prompt ###\n[{new}]')
model_state = None
model_tokens = []
out = run_rnn(pipeline.encode(new))
save_all_stat(srv, 'gen_0', out)
elif msg[:3].lower() == '+i ':
msg = msg[3:].strip().replace('\r\n','\n').replace('\n\n','\n')
new = f'''
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
{msg}
# Response:
# print(f'### prompt ###\n[{new}]')
model_state = None
model_tokens = []
out = run_rnn(pipeline.encode(new))
save_all_stat(srv, 'gen_0', out)
elif msg[:4].lower() == '+qq ':
new = '\nQ: ' + msg[4:].strip() + '\nA:'
# print(f'### prompt ###\n[{new}]')
model_state = None
model_tokens = []
out = run_rnn(pipeline.encode(new))
save_all_stat(srv, 'gen_0', out)
elif msg[:4].lower() == '+qa ':
out = load_all_stat('', 'chat_init')
real_msg = msg[4:].strip()
new = f"{user}{interface} {real_msg}\n\n{bot}{interface}"
# print(f'### qa ###\n[{new}]')
out = run_rnn(pipeline.encode(new))
save_all_stat(srv, 'gen_0', out)
elif msg.lower() == '+++':
out = load_all_stat(srv, 'gen_1')
save_all_stat(srv, 'gen_0', out)
except:
return
elif msg.lower() == '++':
out = load_all_stat(srv, 'gen_0')
except:
return
begin = len(model_tokens)
out_last = begin
occurrence = {}
for i in range(FREE_GEN_LEN+100):
for n in occurrence:
out[n] -= (GEN_alpha_presence + occurrence[n] * GEN_alpha_frequency)
token = pipeline.sample_logits(
temperature=x_temp,
top_p=x_top_p,
if token == END_OF_TEXT:
break
if token not in occurrence:
occurrence[token] = 1
else:
occurrence[token] += 1
if msg[:4].lower() == '+qa ':# or msg[:4].lower() == '+qq ':
out = run_rnn([token], newline_adj=-2)
else:
out = run_rnn([token])
xxx = pipeline.decode(model_tokens[out_last:])
if '\ufffd' not in xxx: # avoid utf-8 display issues
print(xxx, end='', flush=True)
out_last = begin + i + 1
if i >= FREE_GEN_LEN:
break
print('\n')
# send_msg = pipeline.decode(model_tokens[begin:]).strip()
# print(f'### send ###\n[{send_msg}]')
# reply_msg(send_msg)
save_all_stat(srv, 'gen_1', out)
else:
if msg.lower() == '+':
out = load_all_stat(srv, 'chat_pre')
except:
return
else:
out = load_all_stat(srv, 'chat')
msg = msg.strip().replace('\r\n','\n').replace('\n\n','\n')
new = f"{user}{interface} {msg}\n\n{bot}{interface}"
# print(f'### add ###\n[{new}]')
out = run_rnn(pipeline.encode(new), newline_adj=-999999999)
save_all_stat(srv, 'chat_pre', out)
begin = len(model_tokens)
out_last = begin
print(f'{bot}{interface}', end='', flush=True)
occurrence = {}
for i in range(999):
if i <= 0:
newline_adj = -999999999
elif i <= CHAT_LEN_SHORT:
newline_adj = (i - CHAT_LEN_SHORT) / 10
elif i <= CHAT_LEN_LONG:
newline_adj = 0
else:
newline_adj = min(3, (i - CHAT_LEN_LONG) * 0.25) # MUST END THE GENERATION
for n in occurrence:
out[n] -= (GEN_alpha_presence + occurrence[n] * GEN_alpha_frequency)
token = pipeline.sample_logits(
temperature=x_temp,
top_p=x_top_p,
# if token == END_OF_TEXT:
# break
if token not in occurrence:
occurrence[token] = 1
else:
occurrence[token] += 1
out = run_rnn([token], newline_adj=newline_adj)
out[END_OF_TEXT] = -999999999 # disable <|endoftext|>
xxx = pipeline.decode(model_tokens[out_last:])
if '\ufffd' not in xxx: # avoid utf-8 display issues
print(xxx, end='', flush=True)
out_last = begin + i + 1
send_msg = pipeline.decode(model_tokens[begin:])
if '\n\n' in send_msg:
send_msg = send_msg.strip()
break
# send_msg = pipeline.decode(model_tokens[begin:]).strip()
# if send_msg.endswith(f'{user}{interface}'): # warning: needs to fix state too !!!
# send_msg = send_msg[:-len(f'{user}{interface}')].strip()
# break
# if send_msg.endswith(f'{bot}{interface}'):
# send_msg = send_msg[:-len(f'{bot}{interface}')].strip()
# break
# print(f'{model_tokens}')
# print(f'[{pipeline.decode(model_tokens)}]')
# print(f'### send ###\n[{send_msg}]')
# reply_msg(send_msg)
save_all_stat(srv, 'chat', out)
########################################################################################################
if args.CHAT_LANG == 'English':
HELP_MSG = '''Commands:
say something --> chat with bot. use \\n for new line.
+ --> alternate chat reply
+reset --> reset chat
+gen YOUR PROMPT --> free single-round generation with any prompt. use \\n for new line.
+i YOUR INSTRUCT --> free single-round generation with any instruct. use \\n for new line.
+++ --> continue last free generation (only for +gen / +i)
++ --> retry last free generation (only for +gen / +i)
Now talk with the bot and enjoy. Remember to +reset periodically to clean up the bot's memory. Use RWKV-4 14B (especially https://huggingface.co/BlinkDL/rwkv-4-raven) for best results.
elif args.CHAT_LANG == 'Chinese':
HELP_MSG = f'''指令:
直接输入内容 --> 和机器人聊天(建议问机器人问题),用\\n代表换行,必须用 Raven 模型
+ --> 让机器人换个回答
+reset --> 重置对话,请经常使用 +reset 重置机器人记忆
+i 某某指令 --> 问独立的问题(忽略聊天上下文),用\\n代表换行,必须用 Raven 模型
+gen 某某内容 --> 续写内容(忽略聊天上下文),用\\n代表换行,写小说用 testNovel 模型
+++ --> 继续 +gen / +i 的回答
++ --> 换个 +gen / +i 的回答
作者:彭博 请关注我的知乎: https://zhuanlan.zhihu.com/p/603840957
如果喜欢,请看我们的优质护眼灯: https://withablink.taobao.com
中文 Novel 模型,可以试这些续写例子(不适合 Raven 模型):
+gen “区区
+gen 以下是不朽的科幻史诗长篇巨著,描写细腻,刻画了数百位个性鲜明的英雄和宏大的星际文明战争。\\n第一章
+gen 这是一个修真世界,详细世界设定如下:\\n1.
elif args.CHAT_LANG == 'Japanese':
HELP_MSG = f'''コマンド:
直接入力 --> ボットとチャットする.改行には\\nを使用してください.
+ --> ボットに前回のチャットの内容を変更させる.
+reset --> 対話のリセット.メモリをリセットするために,+resetを定期的に実行してください.
+i インストラクトの入力 --> チャットの文脈を無視して独立した質問を行う.改行には\\nを使用してください.
+gen プロンプトの生成 --> チャットの文脈を無視して入力したプロンプトに続く文章を出力する.改行には\\nを使用してください.
+++ --> +gen / +i の出力の回答を続ける.
++ --> +gen / +i の出力の再生成を行う.
ボットとの会話を楽しんでください。また、定期的に+resetして、ボットのメモリをリセットすることを忘れないようにしてください。
print(HELP_MSG)
print(f'{args.CHAT_LANG} - {args.MODEL_NAME} - {args.strategy}')
print(f'{pipeline.decode(model_tokens)}'.replace(f'\n\n{bot}',f'\n{bot}'), end='')
########################################################################################################
while True:
msg = prompt(f'{user}{interface} ')
if len(msg.strip()) > 0:
on_message(msg)
else:
print('Error: please say something')执行脚本chat_neo.py 运行World模型
python3 chat_neo.py
--MODEL_NAME=/Users/weibinxiang/Documents/AI/Pth/rwkv-world/RWKV-4-World-CHNtuned-0.4B-v1-20230618-ctx4096
--tokenizer=rwkv_vocab_v20230424
--user=Question
--bot=Answer
python3 chat_neo.py
--MODEL_NAME=World模型文件路径,必填,但是不需要.pth后缀
--tokenizer=rwkv_vocab_v20230424 分词器,World模型只需要输入rwkv_vocab_v20230424即可,默认是Raven模型的20B_tokenizer.json分词器
--user=Question 模型输入标识,World模型使用Question/Answer,默认是Bot/Alice
--bot=Answer 模型输出标识,World模型使用Question/Answer,默认是Bot/Alice运行效果


Q&A
Training的时候常见问题
ModuleNotFoundError: No module named 'pytorch_lightning'
pip install pytorch-lightning==1.9.2ModuleNotFoundError: No module named 'deepspeed'
pip install deepspeed==0.7.0ChatRWKV常见问题
ModuleNotFoundError: No module named 'tokenizers'
pip install tokenizersLora常见问题
ModuleNotFoundError: No module named 'transformers'
pip install transformersModuleNotFoundError: No module named 'lm_dataformat'
pip install lm_dataformatModuleNotFoundError: No module named 'ftfy'
pip install ftfy基本上都是缺啥就安装啥就好!
RWKV相关文章
https:// arxiv.org/abs/2305.1304 8 论文
https:// zhuanlan.zhihu.com/p/60 5425639 RWKV 14B对比GLM 130B和NeoX 20B,展示RWKV的性能
https:// zhuanlan.zhihu.com/p/60 9154637 开源1.5/3/7B中文小说模型:显存3G就能跑7B模型,几行代码即可调用
https:// zhuanlan.zhihu.com/p/61 8011122 发布几个RWKV的Chat模型(包括英文和中文)7B/14B欢迎大家玩
https:// zhuanlan.zhihu.com/p/61 4655287 RWKV 14B 无微调无RLHF就能遵循各种指令,且在 3090 速度已达 23 token/s
https:// zhuanlan.zhihu.com/p/61 6351661 ChatRWKV(有可用猫娘模型!)微调/部署/使用/训练资源合集
https:// zhuanlan.zhihu.com/p/60 3840957 参与 ChatRWKV 项目,做开源 ChatGPT(可以在每个人电脑和手机直接运行的
https:// pypi.org/project/rwkv/
https:// 36kr.com/p/225774475920 5508?channel=wechat 开源LLM「RWKV」想要打造AI领域的Linux和Android|ChatAI
https:// mp.weixin.qq.com/s/7peB Lvx7NZqEQ6xfdOl0Cw HF宣布在transformers库中引入首个RNN模型:RWKV,一个结合了RNN与Transformer双重优点的模型
https:// github.com/search? o=desc&q=rwkv&s=updated&type=Repositories
===========以下内容没有深入了解,有需要的可以自行深入探讨===========
量化
当你设备资源不足的时候,可以考虑量化后运作
仓库地址 https:// github.com/saharNooby/r wkv.cpp
rwkv.cpp时纯cpu运作的
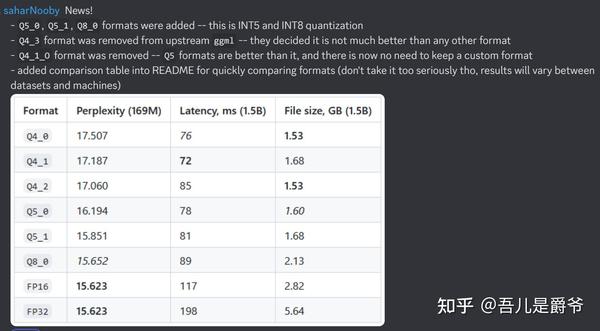
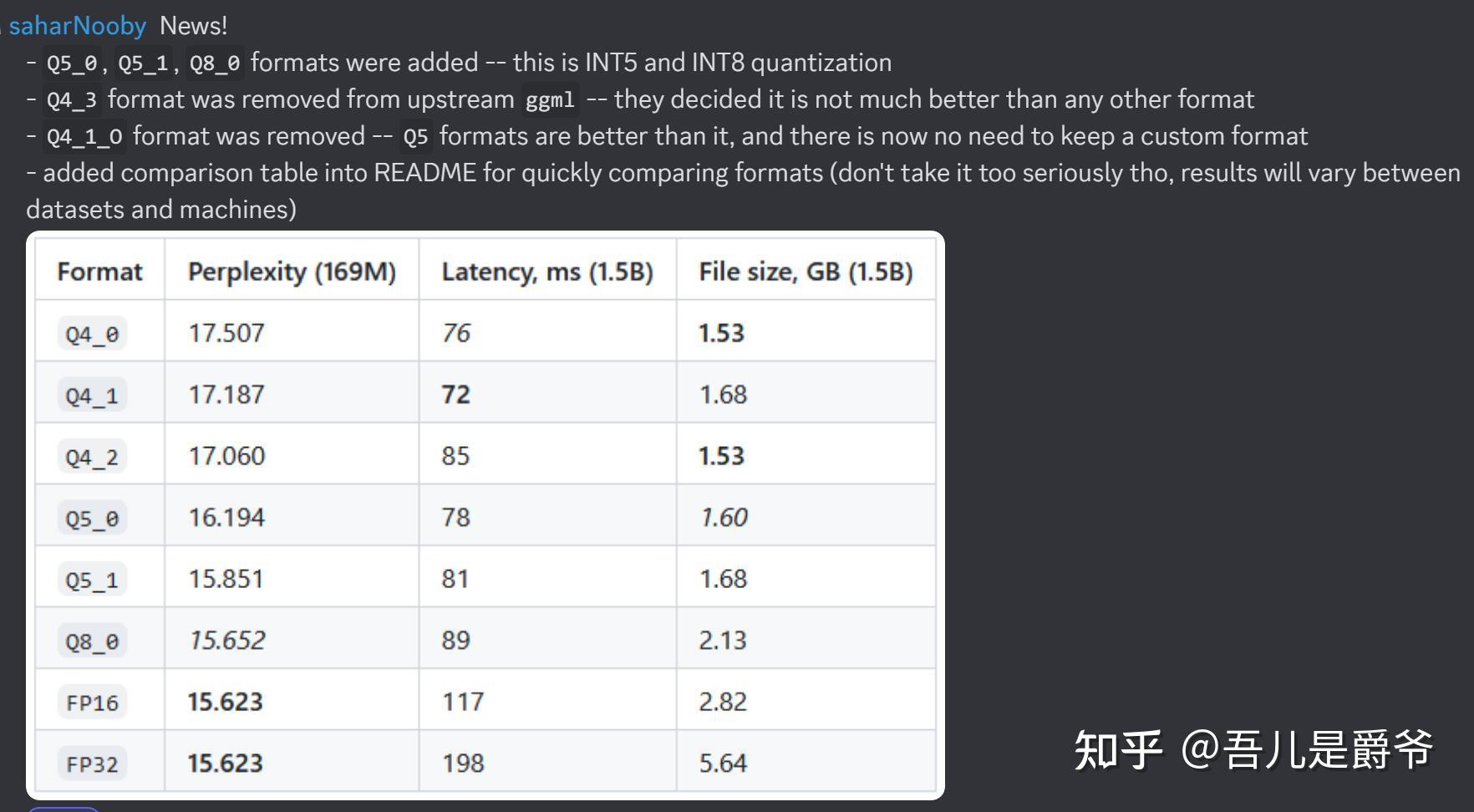
新版更新,现在 Q8_0 是最佳选择,可以看齐 FP16。其他策略量化rwkv损耗相对较大一些。
另外,还可以完全脱离 torch 编译 exe 有 CUDA 加速,而且用户甚至不需要装 CUDA: https:// github.com/harrisonvand erbyl/rwkv-cpp-cuda
WebUI
本地部署 Gradio 界面: https:// huggingface.co/spaces/B linkDL/Raven-RWKV-7B/tree/main
推荐UI: https:// github.com/l15y/wenda
QQ机器人: https:// github.com/cryscan/eloi se
桌面工具: https:// github.com/josStorer/RW KV-Runner
API
https:// github.com/t4wefan/Chat RWKV-flask-api
Android上
安卓编译 rwkv.cpp 方法
安装 termux https://f-droid.org/en/packages/com.termux/
termux-change-repo 选个快镜像
termux-setup-storage 给存储权限
然后 pkg update