|
|
|


如何剔除数据中的异常值?
关注者
76
被浏览
468,922
21 个回答


首先回归到问题本质,什么是「异常」?
用常识来理解,异常必须是小概率事件 。所以当你把大部分数据都通过某种方法检测为异常时,那么大概率是出错了。一般来说,我们默认异常在10%以内,甚至更低。在真实的场景下很多都是低于1%的。绝大部分机器学习工具库默认异常比例是10%。
其次,绝大部分异常检测算法的输出都是连续的数值。 假设有五个样本,那么检测算法会给出比如[0.1, 0.35, 12, 3.4, 0.2]这种结果。当你认为有1个异常时,那么12就是异常,有两个时可能[12, 3.4]会被认为是异常。所以异常的结果其实是排序,而“是”与“不是”取决于你认为异常的比例。
最后再讨论一下怎么选择异常的比例 :
- 假设你有历史数据,知道异常的大概比例,直接使用即可
- 如果条件允许,你可以随机挑选k个数据来人工验证异常比例,手动算一个异常的比例
- 当然,你可以观察异常值的变化情况,尤其是突然的“断层” 。比如异常值是[0.1, 0.2, 0.3, 0.2, 18, 19],那么大概认为[18,19]是异常时合理的。但绝大部分算法输出是非线性的,因此这个方法也仅供参考
- 训练多个模型(可以是算法或者参数上的不同),比如t个。然后找出每个模型异常值最高的k个样本,那么理论上一个样本可以做多出现t次。这样你可以选择一个阈值,比如 一个样本至少出现了0.5t次。这个其实只是把异常比例转化为了阈值。 用集成学习的思路增强选择的鲁棒性 。
- 如果这些方法都无法使用,就用默认的5%或者10%也行。
总体而言, 异常检测的输出是连续的,那么直接一刀切是没有太大的意义的。评估模型应该更多的使用基于排序的指标 ,比如ROC或者average precision。从保守意义上出发,或者说从数据预处理的角度出发,去掉小于10%的数据往往是可以接受的。

- 什么是异常值?
- 异常值出现的原因
- 异常值危害
- 异常值检测方法
- 异常值解决办法
什么是异常值?
所谓异常值,也称离群值,一般是指在所获统计数据中相对误差较大的观测数据,比如与平均值的偏差超过两倍标准差的观测数据。
异常值出现的原因
主要体现在以下几点:抽样的误差或者选取数据进行分析时存在问题;人为的记录或者人为的谎报等的数据比如‘测量男生的身高’搜集的数据非正常人的身高,如10m等。
异常值的检测是十分必要的,否则异常值的存在可能对分析结果存在“危害”。接下来说明异常值可能存在的危害。
异常值危害
如果数据中存在可能的异常值,均应在分析之前处理,防止异常值带来的干扰。
(1)异常值的存在可能会导致数据分布和真实分布差别很大。
(2)如果异常值在数据中影响较大,可能会影响数据集的均值和标准差,从而在数据分析中可能会带来错误的结果,比如t检验等。
(3)对于 SPSSAU 中的回归、聚类、机器学习中KNN等,如果数据存在异常值可能会导致结果有很大偏差。
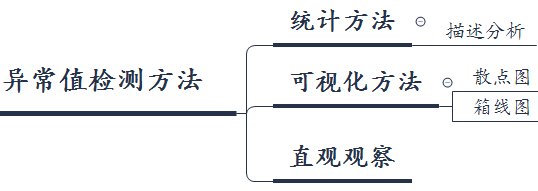
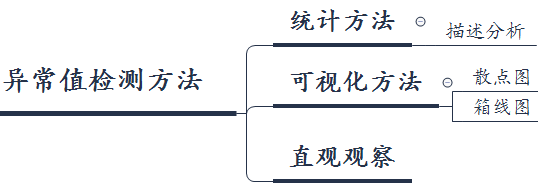
异常值检测方法
一般异常值的检测方法有基于统计的方法,可视化方法以及直观观察等。
描述分析
异常值为一般与平均值的偏差超过两倍标准差的测定值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。


利用SPSSAU描述分析可以得到数据的基础指标,比如最小值,最大值以及平均值等,根据最小值和最大值可以判断数据中是否存在异常值,并且进行处理。此方法的缺点是不能精准的查到异常值,所以常常用于初步判断。
可视化方法
利用图形方法进行查看数据中是否存在异常值,其中可以利用散点图或者箱线图。
散点图
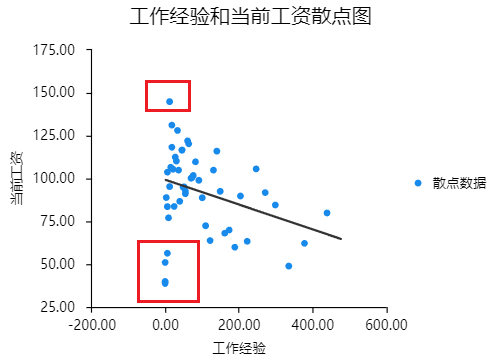
横坐标为自变量,纵坐标为因变量,通过散点图可以大致看出异常值点,为红色框内的数据。该办法能够大致看出异常值,但是主观性较强,如果想要大致查看异常值情况,可以使用该方法。
箱线图
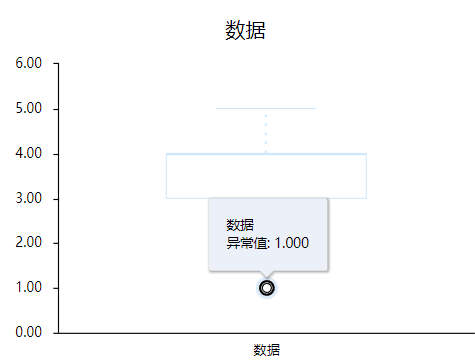


从箱线图可以看看出,此份数据中存在异常值,具体异常值查看SPSSAU提供的异常值汇总表格,其中此份数据的异常值共有6个,具体异常值的数字都是1。相比较其它方法箱线图更为直观,以及方法更加严谨。
直观观察
直观的看到离群值,比如一组数据大于都是在10附近,但是在数据中直观查看到有两个值大于1000或者为负数等,但是这种方法只适用于小样本数据(小于50)个。
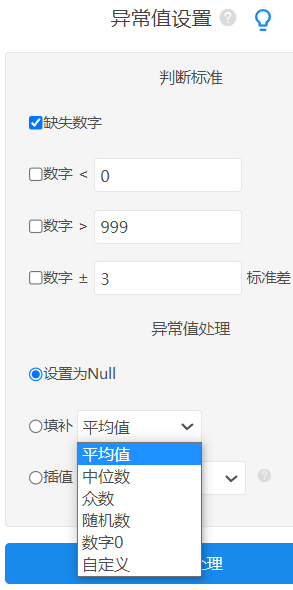
SPSSAU 异常值解决办法
异常值的判定没有固定标准,有时数据的异常值可能也存在有用的信息,是否需要剔除,应由分析人员自行判断。如果想要处理异常值一般有以下三种方法,将异常值设为null、填补法以及插值法。
如果异常值相对于数据不多可以直接将异常值设为null值。或者将异常值处理为null值后将异常值作为缺失值进行处理。SPSSAU有提供“填补法”和“插值法”,其中填补法包含平均值、中位数、众数、随机数、数字0以及自定义函数等。目前平均值比较常用,插值法针对的确缺失数据,插值法共有两种一个是线性插值一个是该点线性趋势插值。