

当字符串遇上Emoji

引子
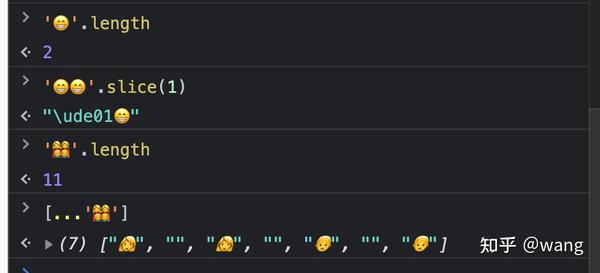
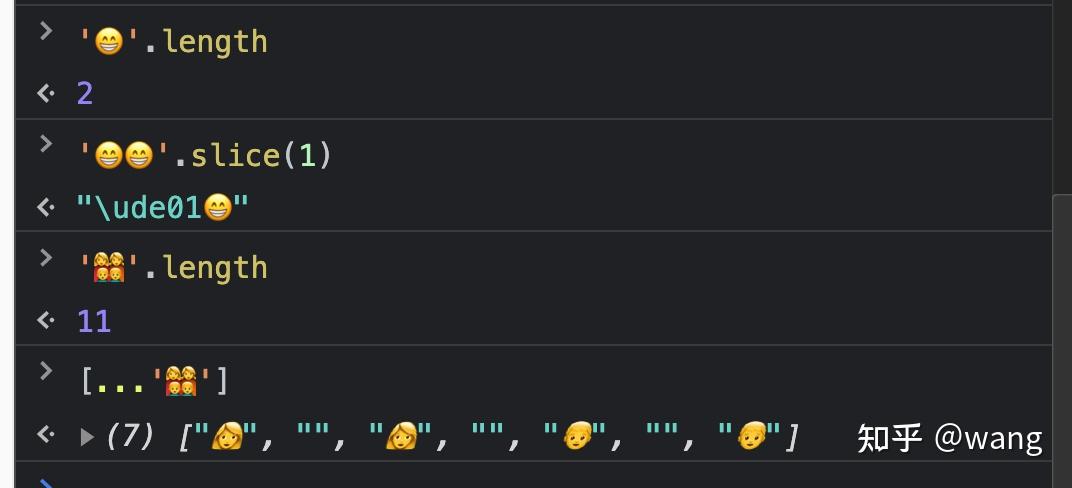
先来看看上面的几个例子:
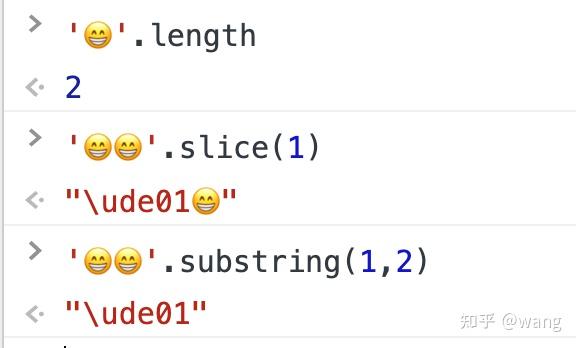
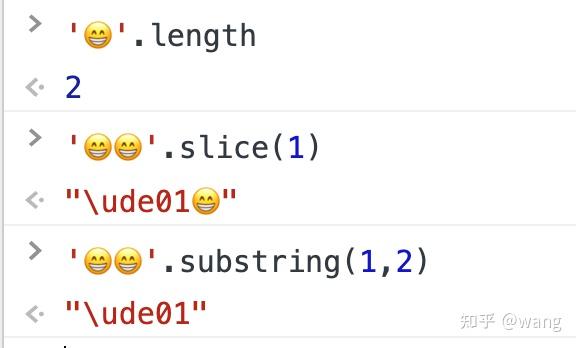
- 一个笑脸的长度是2
- " ".slice(1),结果出现了一个unicode码
- 一个家庭的Emoji获取长度结果得到了11
我们这篇文章将要解答以下问题:
- 字符串的长度真的是字符的个数吗?
- 字符串截取操作为什么可能出现了unicode?
- 一个Emoji的长度到底可能有多长?
关于编码的一些基础知识
在解决上述疑问时,先补充一些基础知识。
unicode
Unicode是一套字符编码方案,目标是把全世界的字符用数字编号编起来。(
划重点,unicode给每个字符分配了一个独一无二的编号。
)在7.0版中,一共收入了109449个符号。
Code point 码点
每个符号在unicode中的编号,就叫做码点。这个网站能看到字符和码点的对应关系:
https://
unicode-table.com/
Plane 平面
unicode的符号码位不是连续的,而是分区定义。每个分区大小为16^4。编号u+0000~u+FFFF所在区域称为
基本平面
(缩写BMP),所有最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。
剩下的字符都放在辅助平面(缩写SMP),码点范围从U+010000一直到U+10FFFF。
几种编码格式
我们经常会听到"UTF-8", "UTF-16"这些编码格式。其中UTF 的全称为 Unicode/UCS Transformation Format,即Unicode字符转换为某种格式之意。(划重点:
unicode只是给字符分配了一个编号,UTF-16、UTF-8解决了如何在计算机中存储、表示这些字符或者说编号的问题
)
UTF-32
由上文可以看出,一个字符最大的码点可能是`U+10FFFF`, 最多使用三个字节。而UTF-32编码使用4个字节表示每个字符,例如A的表示为: 0x00000047.这种编码会带来存储空间的极大浪费。所以极少使用。
UTF-16
该编码把两个字节长的比特位为一组,称作
码元
。那么每个码元有16个比特位,总共可以表示2^16种字符。或者说,我们可以把基本平面的每个字符用一个码元表示起来。
那么对于编号大于u+FFFF的字符怎么办?这时utf-8会用两个码元来表示。表示一个字符的两个码元叫做
代理对
(Surrogate Pair)。所有不常用的、不在基础平面的字符都需要两个码元,即4个字节长度的位置来存储。
那么我在解析的时候,怎么知道某个码元自己代表一个字符,还是跟相邻的另一个码元一起来表示一个字符呢?
这里另外一个小知识是,unicode编码的 u+{D800}~u+DBFF, 是不映射任何字符的。所以当解析到一个码元位于
D800-DBFF之间时,就知道需要和后边的一个码元一起解析。
例如,对于UTF-16编码出来的以下数据:
'\u0041\ud842\udfb7'
1、0x0041小于0xD800,所以它单独表示一个字符,查找unicode字符对照表可以查出表示大写字母: A
2、\ud842介于
D800-DBFF,需要和后边的码元一起解析。'\ud842\udfb7'一起解析出' '字,这是一个古汉语,跟'吉'是同一个意思。


UTF-8
而UTF-8使用的是一种变长的编码方法,一个字符可能使用1,2,4个字节。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同,这里不细说。
JavaScript使用的字符编码规范
JavaScript 使用UCS-2编码
JavaScript 使用了
UCS-2
编码,UCS-2编码固定使用2个字节存储每个字符,所以它只能正确表示基本面的字符,即编码小于0xFFFF的字符。后来utf-16发布时兼容了UCS-2编码,可以理解为USC-2编码是UTF-16的一个子集。
这也解释了为什么码点超出 0xFFFF的字符都不能被JavaScript正常处理。如以下case:
ES6 对unicode 增强了支持
- 可以将码点放入大括号,来表示字符,包括非基础平面的字符:
"\u{20BB7}"
// " "
"\u{41}\u{42}\u{43}"
// "ABC"
2. 为字符串添加了遍历器接口,该遍历器能识别大于0xFFFF的码点。
所以对于前端开发者而言,以下几种case需要考虑:
字符串的长度真的是字符的个数吗?
我们先查一查string的长度是怎么定义的:
Thelengthproperty of aStringobject contains the length of the string, in UTF-16 code units.lengthis a read-only data property of string instances. MDN
所以实际length表示的是字符串有几个码元(
code unit
)。
这时候我们就能解释为什么 ' '.length === 2了, 在unicode中的码位为:u+1F600 。在用UTF-16编码时,编码结果为:'\ud83d\u{de00}'。所以它的长度是2。
理论上所有码点超过0xFFFF的字符都会出现长度判断不正确的问题。
为什么字符串截取操作出现了unicode?
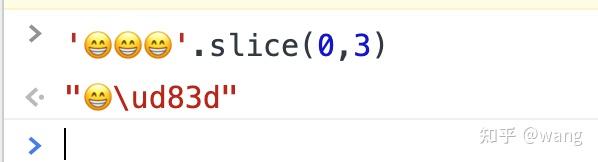
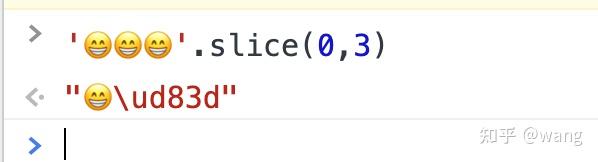
其实这也是因为截取的开始和结束位置是根据码元的长度计算的,所以出现了将一个字符的两个码元一分为二了。\ud83d是 的后一个码元。
为什么一个Emoji长度可能能达到11
?
从上文中我们可以确定的是,一个unicode字符用UTF-16编码表示一般只会占用一个码元(基16比特位)。对于不常见的字符,如Emoji或不常见的汉字,也可能会占用2个码元(即32比特位)。
那么怎么解释下面的行为呢?
' '.length // 8 因为还有一套Emoji规范,简单地说,该规范定义了Emoji几种合成的行为:
Emoji的合成行为
-
可以额外在人物的Emoji上修饰肤色
。语法格式是
<emoji>\ud83c[\udffb-\udfff],即U+D83C后面跟不同的几个值表示不同的肤色控制。肤色总共有5中,用\udffb-\udfff表示。
let colors = ['\udffb', '\udffc', '\udffd', '\udffe', '\udfff']
let defaultBoy = ' '
colors.map(color => defaultBoy + '\ud83c' + color)
// [" ", " ", " ", " ", " "]
- 可以将多个Emoji合成为一个Emoji , 如 实际上是由一个 ,一个 ,一个 合成的。具体语法为`<Emoji> U+200D <Emoji> U+200D <Emoji> ` 。U+200D表示将前后的Emoji合成的意思。
const man = ' ',women = ' ', daughter=' ', son = ' '
[man, women, son].join('\u200d') === " "
[man, women, daughter, son].join('\u200d')
" "
' '.length // 8, 每个基础Emoji长度为2,每个连接符长度为1,所以总长为 8
[...' '] // [" ", "", " ", "", " "] // 中间的空字符串其实就是 U+200D
" \u200D \u200D " // " "
-
键帽Emoji
:
0-9*#, 是由0-9的unicode加上一个Emoji修饰符,加一个键帽修饰符表示的。
[0,1,2,3,4,5].map(num => num + '\ufe0f\u20e3')
// ["0️⃣", "1️⃣", "2️⃣", "3️⃣", "4️⃣", "5️⃣"]
前端开发者需要注意的场景
如何正确地统计用户输入长度?
我们常常会在表单项上添加统计字数功能、或限制用户输入长度。
❌错误1:
对于字数统计的场景,直接使用了value.length:
那么可能就会出现出来的字数跟用户预期不符的情况。比如说用户刚刚输入一个Emoji,结果实时统计已输入长度已经到了2。
const userInput = ' ';
console.log(`you have inputed ${userInput.length} characters`);
// "you have inputed 2 characters"
❌ 错误2:使用Textarea的maxLength限制用户输入: Textarea的maxLength实际上也是基于对码元的计数,而不是对字符的计数。


✅方案1:使用字符串的Iterator统计长度。
字符串的迭代器能正确识别代理对的情况,如下例子:
const testStr = '123 '
for(let c of testStr) {
console.log(c)