0、问题的启发
几乎没有看到机器学习的书籍教你如何调参,不是说调参很高大上吗,为什么书中都不教大家?
问题示例:
你知道模型调参的方向吗,先调偏差还是方差,什么时候该终止呢?
如果你对奥卡姆剃刀原则开口即来,却不会回答,说明你看的书实践少了些,且自己没有思考过。
下文参考《机器学习:软件工程方法与实现》整理了调参流程、调参方法、实操和案例。如遇到了调参疑问,还可参考4.1节提供的思路。
1、背景和基础(方法论)
模型调参(一)—方法论
模型调参
一直是建模人员向往的高地,要求建模人员具有强大的综合能力。例如对数据业务的理解、算法本质的理解、合适的调试工具、做实验的方法和策略、细致的观察和分析能力,等等。
其中“
调试工具、做实验的方法和策略
”体现了软件工程的实践能力
调参过程可通俗表述为:给定一组数据D和具有可调N个参数的算法 ,调参的目的就是在由参数组成的N维向量集 里,挑选一组参数λ,使得算法在训练集学习后能在验证集取得最小的损失(最优的模型效果),
其数学表达式为式(12-1)
![\lambda^{*}=\underset{\lambda \in \Lambda}{\operatorname{argmin}} \mathbb{E}_{\left(D_{\text {train }}, \ D_{\mathrm{valid}} \ \ \right) \ \sim D} \mathbf{V}\left(\mathcal{L}, \mathcal{A}_{\lambda}, D_{\text {train }}, D_{\text {valid }}\right) \\]()
其中,N维向量集称为参数配置空间,由实数、正数、布尔和条件等类型的变量组成。实际上不同的特征处理方法、算法也可视为类别型变量,作为配置空间的一部分,这极大扩展了配置空间,构成了算法选择和超参数优化组合问题——CASH (Combined Algorithm Selection and Hyperparameter optimization problem)。
超参数和作弊的随机种子
初学者是否有过这样的疑问:“
机器学习不就是学习/求解参数吗,为什么还需要调参?
”
对这个问题的最直接回答是:调算法学习不到的参数。那么,
模型调参到底是调哪些参数呢?
答案是调
超参数(Hyperparameter),简称超参
那么什么是超参呢?
指的是
决定模型框架/结构或算法行为的参数。
随机种子是最常见的建模作弊的手段(或者建模工程师自己也没有意识到),当通过不断调整随机种子而择优选择的模型,就是作弊的模型。
调参三要素
在调参前通常需要了解3个调参要素:
目标函数、搜索域和优化算法
调参流程和方法
一定要铭记原则:
参数只有更好,没有最好,应适可而止
,朝着项目总体目标推进。
调参流程
调参首先应有方向性的指导:
先训练复杂的模型并在后续逐渐简化;反之,由简至繁逐渐改善模型,并建议使用方式一。
超参选取策略和特定模型超参推荐
超参的选取分为:
初次选取和启发式选取
推荐:
自动调参之元学习和代理模型
笔者简要的将自动调参划分为两种类型
-
利用学习过程中的经验:如何利用已有的“经验”的元学习(Meta-Learning)
-
利用代理模型:不直接优化原始模型,而是优化原模型的代理模型
2、方法和案例参考(实操)
模型调参(二)调参方法与XGBoost调参工具开发
Model-Free方法
模型无关(Model-Free)的方法指的是超参调整过程中无须建立其他模型,直接对目标模型超参优化,常见的有:
网格搜索和随机搜索。
网格搜索
该方法
穷举
搜索“网格”中的每一个超参点(定义好的超参组/配置空间),通过模型评估方法,找到模型性能最好的一组超参数作为网格搜索的结果。
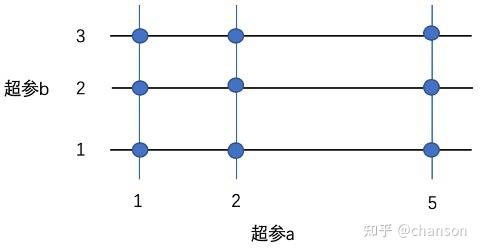
以两个超参(a,b)组成的配置空间为例,其形象化的描述如图12-3所示:
一个分类问题的网格搜索代码模板,供读者参考:
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
# 定义折数、评价指标等
def classify_gridsearch_cv(model,
grid,
folds=10,
n_repeats=3,
scoring='accuracy',
seed=42):
# 分类问题使用分层采样
cv = RepeatedStratifiedKFold(n_splits=folds,
n_repeats=n_repeats,
random_state=seed)
gs = GridSearchCV(estimator=model,
param_grid=grid,
n_jobs=-1,
cv=cv,
scoring=scoring,
error_score=0)
gs = gs.fit(X, y)
# 最好的模型效果
print("Best: {:.3f} : {}\n".format(gs.best_score_, gs.best_params_))
# 模型性能统计指标
means = gs.cv_results_['mean_test_score']
stds = gs.cv_results_['std_test_score']
params = gs.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("{:.3f} [{:.3f}] : {}".format(mean, stdev, param))
# 返回最好的模型
return gs.best_estimator_
随机搜索
随机搜索(Random Search)与网格搜索唯一的区别是如何定义超参空间。
在网格搜索中,超参空间是
人为定义好的“规范”的点
,而在随机搜索中,点不再“规范”,而是独立随机的选取,随机选取的实现由指定的
随机分布
确定,而随机的次数由指定的
迭代次数
确定。随机搜索通过随机的方式增加了获得最佳点的可能性,该搜索过程,专业术语称为
探索(exploration)
随机搜索的探索为
没有指引的随机探索(见下文的有指引的探索—贝叶斯优化)
Sklearn中提供了带交叉验证的RandomizedSearchCV。读者可套用网格搜索中的代码模板,稍加修改就能实现随机搜索。
XGBoost自动调参工具开发实战
功能和易用性设计:
1) 支持网格搜索(grid_search)和随机搜索(random_search);
2) 支持增量搜索(tune_sequence),即前一个参数确定后不再变化,继续下一个参数的调优,以节省调参时间,但其本质了放弃了多种参数的组合;
3) 每组参数有缺省值,支持用户自定义超参范围,以方便精细化控制;
作为调参工具,工程易用性设计如下:
1) 提供缺省的调优流程并提供帮助说明;
2) 提供用户自定义参数的自由组合;
3) 支持参数随时修改、随时清空;
4) 记录调参历史(参数和学习器)。
核心数据结构和方法
# 全局初始值重要参数
cur_params = {
'colsample_bytree': 1,
'gamma': 0,
'learning_rate': 0.1,
'max_depth': 3,
'min_child_weight': 1,
'n_estimators': 100,
'reg_alpha': 0,
'reg_lambda': 1,
'scale_pos_weight': 1,
'subsample': 1
# 1.缺省的调优顺序流程
param_grids_list = [
# 树结构是重点
# 集成结构--解决偏差
'n_estimators': range(100, 1000, 50)
'learning_rate': [0.01, 0.015, 0.025, 0.05, 0.1]
# 树结构参数--解决偏差
'max_depth': [3, 5, 7, 9, 12, 15, 17, 25]
'min_child_weight': [1, 3, 5, 7]
# 树结构(叶子结点)
'gamma': [0, 0.05, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0]
# 样本参数--解决方差
'subsample': [0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
'colsample_bytree': [0.4, 0.6, 0.7, 0.8, 0.9, 1.0]
# 正则参数--解决方差
'reg_alpha': [0, 0.1, 0.5, 1.0, 10, 100, 200, 1000]
'reg_lambda': [0.01, 0.1, 1.0, 10, 100, 200, 1000]
]
1、K折设计:二分类或多分类使用StratifiedKFold;计数类或回归类使用KFold
2、网格搜索:此处统一使用GridSearchCV,也可以使用xgb.cv
3、随机搜索:RandomizedSearchCV;要控制好随机参数的取值范围:根据超参类型进行设定。如
param_distributions = {
# np.random.uniform(low=0, high=1) 该函数会更安全:限制在0-1范围
'colsample_bytree':
uniform(params.get('colsample_bytree_loc', 0.2),
params.get('colsample_bytree_scale', 0.5)),
'max_depth':
sp_randint(params.get('max_depth_low', 2),
params.get('max_depth_high', 11)),
4、独立、增量式的搜索,相比全量参数的网格搜索效率会高点,但是最终效果会打折扣,逻辑为顺序调优。主要逻辑如下:
for pp in TuneXGB.param_grids_list:
self.tune_step(pp)
def tune_step()
grid_search
3、用于调参的算法(包)
模型调参(三)—贝叶斯方法和开源调参项目
贝叶斯方法
网格搜索需要人为指定解的范围,随机搜索具有随机探索未知更好解的可能性,而贝叶斯方法能够
启发式地探索更优解
只需给到它一些观察点(超参,性能),贝叶斯优化方法能够基于观察的先验,指导超参采样,并
权衡超参空间的探索(exploration)和开发(exploitation)。
在这个过程中使用了贝叶斯定理,故而称为贝叶斯优化
贝叶斯优化技术的实现是一种迭代式、序列化模式的优化框架,主要
包括一个代理模型和一个决定下一个评估点的收益函数(Acquisition Function)
。收益函数通过概率模型评估不同参数点的效能,选择最优的点继续迭代
案例
BayesianOptimization优化实例
开源包BayesianOptimization借用了sklearn.gaussian_process实现了基于高斯过程的贝叶斯优化。
Ray-Tune
Tune是一款可扩展的,主要应用于深度学习、强化学习(也可以用于机器学习)的超参调优框架,其官网介绍的主要特点有 :
1)10行代码就能启动多节点的分布式的超参搜索;
2)支持任何机器学习框架,包括PyTorch、XGBoost、MXNet和Keras;
3)可原生的和多种优化库集成,例如HyperOpt、Bayesian Optimization和Facebook Ax;
4)可选用多种可扩展算法,如Population Based Training (PBT), Vizier’s Median Stopping Rule, HyperBand/ASHA;
5)可使用TensorBoard进行可视化。
Tune运行于Ray分布式计算框架上,而Ray是一个用于构建和运行分布式应用程序快速而简洁的框架,更进一步的了解,可参考 。
另外,Ray还衍生了一个不错的项目modin:Pandas的大数据版本或并行化多核版本,支持KB到TB级别的数据量,感兴趣的读者可以进一步研究
optuna
Optuna称为
下一代超参调优框架
(A Next-generation Hyperparameter Optimization Framework)。
GitHub可参考相关链接 ,也可参考相关论文 。
本章小结
本章开篇讲述了模型调参问题的定义、超参数的理解和容易被大家忽视的“作弊的随机种子”——取随机最好的效果是没有意义的!
超参调整就是搜索模型结构的过程,就如调整树深,像是调整树的高度结构一样。
文中明确了调参的3个要素:目标函数、搜索域/超参空间、搜索算法。定义好了这3个要素就可以开始调参了
调参是先从复杂到简单还是从简单到复杂的方向的流程性问题,奥卡姆剃刀原则给出了提示。
由于手工调参的局限,书中介绍了自动调参涉及的元学习和代理模型方法,并提到了SmartML、Auto-sklearn等先进调参理念的开源实现
同时提到混合搜索:如贝叶斯+网格搜索、随机搜索+网格搜索。
1)网格搜索:固定备选的空间点;
2)随机搜索:随机选择的空间点;
3)贝叶斯:依分布选择的空间点。
调参实验中具有顺手的工具,调参想必会逐渐变成探索的乐趣。XGBoost自动调参工具实现了网格、随机和增量调参的模式,并在工程易用性上做了良好的设计
为了开阔读者的视野,12.6节介绍了笔者认为不错的开源项目:Ray-Tune、Optuna,以及适用于机器学习和深度学习的调参。
我们可以从中学到调参概念、先进的软件设计方法、调参的理念和调参工具的使用方法。从开源项目中学习,就是向全世界优秀的人学习!
本文摘编自《机器学习:软件工程方法与实现》,经出版方授权发布。