|
|
|


如何快速低成本训练私有领域的 AIGC 模型?
关注者
1,689
被浏览
564,427
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

介绍一个可操作性比较强的开源方案,不需要特别强的硬件,就可以低成本的训练私有领域的AIGC模型, Colossal-AI.
Colossal-AI 利用之前在大型模型加速方面的经验,成功发布了一个完整的开源稳定扩散(Stable Diffusion)预训练和微调解决方案。 该解决方案将预训练成本降低了6.5倍,微调硬件成本降低了7倍,同时还能加快整个过程! 微调任务流程还可以在RTX 2070/3050 PC上方便地完成,使得像稳定扩散这样的AIGC模型可以为那些没有非常强大的机器资源的人提供服务。
如何实现更低成本
Pretraining加速
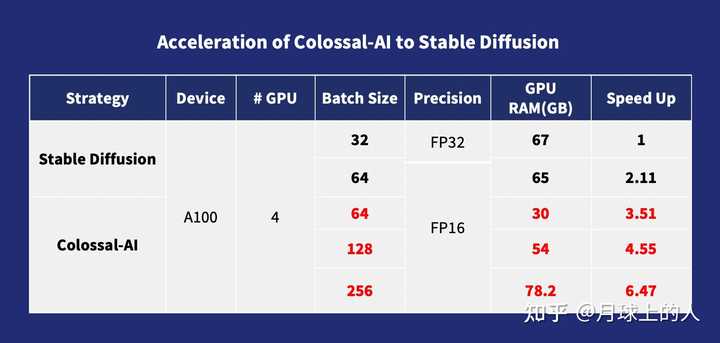
对于预训练来说,随着批量大小的增加,训练速度通常会提高。对于扩散模型也是如此。Colossal-AI通过其ZeRO和Gemini模块优化内存消耗。使用Flash-Attention替换Cross-Attention模块还有助于减少GPU内存占用。因此,用户可以在消费级GPU(如RTX 3080)上训练扩散模型。通过这种方式,批量大小也可以在计算专用GPU(如A100)上增加到256。 与stable-diffusion-v1-1中的DDP训练相比,这将加快训练速度6.5倍。这使得成本高达数百万美元的扩散模型训练变得更加实惠,为更多人探索AIGC应用开启了机会!
更为简单的Fine-tuning
Stable Diffusion的预训练使用了包含5850亿个图像文本对的LAION-5B数据集,需要240 TB的存储空间。加上模型本身的复杂度,预训练的成本是非常高昂的。Stability团队花费了超过5000万美元购买了一个拥有4000个A100 GPU的超级计算机。在这种情况下,更实际的选择是使用开源预训练模型权重来进行下游个性化任务的微调。
然而,现有开源微调解决方案中的并行训练方法主要使用DDP(分布式数据并行),在训练过程中需要大量的内存消耗。微调还需要使用顶尖的RTX 3090或4090消费级显卡才能开始。同时,许多开源训练框架在此阶段并没有提供完整的训练配置和脚本,需要用户花费额外的时间进行繁琐的任务和调试。
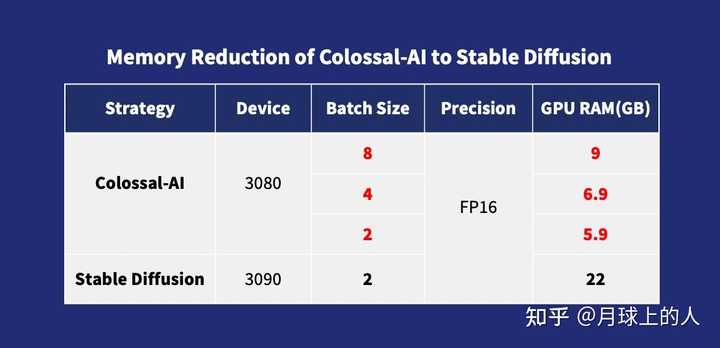
与其他解决方案不同,Colossal-AI是第一个同时公开发布训练配置和训练脚本的解决方案,使用户能够随时针对新的下游任务训练最新版本的扩散模型。这种解决方案更加灵活,适用范围更广。 由于像GPU内存使用优化这样的过程,使用Colossal-AI,微调任务过程可以轻松完成在个人电脑上的单个消费级别图形卡(如GeForce RTX 2070/3050 8GB)上 。与RTX 3090或4090相比,硬件成本可以降低约7倍,大大降低了类似Stable Diffusion的AIGC模型的门槛和成本。用户因此不再局限于使用现有权重进行推理,也更方便地完成个性化定制服务。 对于不敏感于速度的任务,可以使用Colossal-AI NVMe,它使用低成本的磁盘空间来减少内存消耗。
如何快速开始
与常见的机器学习开源项目不同,最流行的开源扩散(diffusion)项目是使用PyTorch Lightning构建的。PyTorch Lightning是一个库,旨在为PyTorch提供简洁、方便、灵活和高效的高级接口。通过PyTorch Lightning提供的高级抽象,DL实验变得更加易读和可重现,对于AI研究人员来说是非常方便的。
在PyTorch Lightning的邀请下,Colossal-AI已经成为大型模型训练的官方解决方案之一。通过这个集成,AI研究人员现在可以更有效地训练和利用扩散模型。一个例子就是稳定扩散模型的训练,现在只需要几行代码就可以启动了。
from colossalai.nn.optimizer import HybridAdam
from lightning.pytorch import trainer
class MyDiffuser(LightningModule):
def configure_sharded_model(self) -> None:
# create your model here
self.model = construct_diffuser_model(...)
def configure_optimizers(self):
# use the specified optimizer
optimizer = HybridAdam(self.model.parameters(), self.lr)
model = MyDiffuser()
trainer = Trainer(accelerator="gpu", devices=1, precision=16, strategy="colossalai")
trainer.fit(model)Colossal-AI和PyTorch Lightning还为流行的开源模型OPT和HuggingFace社区提供了出色的支持和优化。
如何低成本的更低成本Fine-tuning
Colossal-AI对HuggingFace的稳定扩散模型进行了微调,使得用户可以高效地用自己的数据集训练模型。用户只需要修改Dataloader来加载自己的微调数据集并读取预训练权重。用户可以简单地修改yaml配置文件并运行训练脚本,从而可以在个人计算机上微调个性化的模型。
model:
target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
your_sub_module_config:
target: your.model.import.path
params:
from_pretrained: 'your_file_path/unet/diffusion_pytorch_model.bin'
lightning:
trainer:
strategy:
target: pytorch_lightning.strategies.ColossalAIStrategy
params:
python main.py --logdir /your_log_dir -t -b config/train_colossalai.yaml部署预测
Colossal-AI还支持本地稳定扩散推理流程,允许用户在训练或微调后直接调用diffuser库并加载自己保存的模型参数,以直接进行推理,无需对代码进行任何其他更改。这使得新用户很容易熟悉推理过程,并允许习惯使用原始框架的用户快速入门。
from diffusers import StableDiffusionPipeline