


一分钟一个Pandas小技巧(二)

在逛Kaggle的时候发现了一篇不错的Pandas技巧,我将挑选一些有用的并外加一些自己的想法分享给大家。 本系列虽基础但带仍有一些奇怪操作,粗略扫一遍,您或将发现一些您需要的技巧。
纸上得来终觉浅,绝知此事要躬行,所谓的熟练使用Pandas是建立在您大致了解每个函数功能上,希望本系列能给您带来些许收获。
本篇所涉及知识点:
- map、apply、applymap
- groupby
- MultiIndex DataFrame
- 统计函数、累计函数
- agg、transform、filter
map、apply和applymap
先总结一下:
- map()适用于Series,相当于将Series中的每个元素作为参数带入指定函数,注意是 Series中的每个元素 。
- apply()适用于DataFrame的行或者列,将整个行列作为参数带入指定函数,注意是 DataFrame的行或列,即整个Series 。
- applymap()适用于DataFrame中的每个元素,注意是 DataFrame中的每个元素 。
map
Series.map(self,arg,na_action)
作用于一个Series上,DataFrame的一行或者一列都是Series。
map()最主要的用途是实现以下两个功能:
- 字典替换
- 简单的有参函数(有且仅有一个参数,其实就是Series里的每个元素了)
df = pd.DataFrame([['小王', 'm', 80], ['小红', 'f', 90], ['小明', 'x', 85], [
'小林', np.nan, 83], ], columns=['student', 'sex', 'score'])
student sex score
0 小王 m 80
1 小红 f 90
2 小明 x 85
3 小林 NaN 83使用dict对Series进行映射替换。如果Series中的值并没有在给定字典中出现,那该值会被替换为np.nan。
下面案例中我想把sex='m'替换为"男",sex='f'替换为"女",小明的sex='x'我并没有在字典中给出映射,所以map()后直接被替换为np.nan。
my_dict = {'m': '男', 'f': '女'}
df['dict'] = df['sex'].map(my_dict)
student sex score dict
0 小王 m 80 男
1 小红 f 90 女
2 小明 x 85 NaN
3 小林 NaN 83 NaN如果对于未给定的键我们也想统一替换,那就要在字典中设置默认值,接下来教大家如何设置字典默认值。
from collections import defaultdict
def ret():
describe:因为defaultdict接受一个工厂函数,所以咱们直接创建一个函数,返回Unknown
return :str
return 'Unknown'
# 生成一个新的dict,使用defaultdict函数并传入我们创建的工厂函数
# 当然你也可以填入其他的数据类型,具体类型及对应默认值如下:
# int->0,set->set(),str->'',list->[]
my_hasdefault_dict = defaultdict(ret)
# 将之前的dict再传入新的含有默认值的dict
my_dict = {'m': '男', 'f': '女'}
for k, v in my_dict.items():
my_hasdefault_dict[k] = v
# 因为小林的sex=np.nan没有在给定字典中出现,所以也替换成了默认值
df['hasdefault_dict'] = df['sex'].map(my_hasdefault_dict)
# 在map中设置na_action='ignore'时就会忽略np.nan,不进行任何操作
df['ignore_na'] = df['sex'].map(my_hasdefault_dict, na_action='ignore')
student sex score dict hasdefault_dict ignore_na
0 小王 m 80 男 男 男
1 小红 f 90 女 女 女
2 小明 x 85 NaN Unknown Unknown
3 小林 NaN 83 NaN Unknown NaNmap()可以应用一些简单的自定义函数。
def my_cut(x):
descrieb:对成绩分桶
return :str
if x >= 90:
return 'score>=90'
if 85 <= x < 90:
return '85<=score<90'
else:
return 'score<85'
# map里面只要写入函数名就可以,不用括号
df['my_cut'] = df['score'].map(my_cut)
# 上面的判断比较简单,所以我们可以改写成lambda的形式
# lambda的格式是 lambda x:结果1 if 条件1 else 结果2 if 条件2 else 结果3
df['cut_lambda'] = df['score'].map(
lambda x: 'score>=90' if x >= 90 else '85<=score<90' if 85 <= x < 90 else 'score<85')
# 当然上面只是为了演示map,其实用Pandas自带的cut更方便
# right=True是右闭区间,right=False是左闭区间
df['cut'] = pd.cut(df['score'], bins=[-np.inf, 85, 90, np.inf],
labels=['score<85', '85<=score<90', 'score>=90'], right=False)
student sex score my_cut cut_lambda cut
0 小王 m 80 score<85 score<85 score<85
1 小红 f 90 score>=90 score>=90 score>=90
2 小明 x 85 85<=score<90 85<=score<90 85<=score<90
3 小林 NaN 83 score<85 score<85 score<85apply
-
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds) -
Series.apply(self, func, convert_dtype=True, args=(), **kwds) -
GroupBy.apply(self, func, args, *kwargs) - ... apply()有好多,我们最主要的就是用到上面这三种结构下的apply()
apply()不可以像map()那样使用字典映射替换字符,但是可以通过字典调用函数(起码我还没用到过)。
df = pd.DataFrame([['小王', 'm', 80, '汉族'], ['小红', 'f', 90, '回族'], ['小明', 'm', 85, '汉族'], [
'小林', 'f', 83, '保安族'], ], columns=['student', 'sex', 'score', 'nationality'])
student sex score nationality
0 小王 m 80 汉族
1 小红 f 90 回族
2 小明 m 85 汉族
3 小林 f 83 保安族为了证明apply是真的可以字典调用函数,我们来做个没有实际意义的测试,结果是可行的。
# 如果sex=m则后面拼接ale,如果sex=f则后面拼接emale
func_dict = {'m': lambda x: x+'ale', 'f': lambda x: x+'emale'}
df['sex'].apply(func_dict)
m 0 male
1 fale
2 male
3 fale
f 0 memale
1 female
2 memale
3 female是不是感觉和map出来的效果有点不一样?继续往下看。
# apply可以添加参数,如果用*args接收参数,那就使用元组的方式按位置索引,**kwargs就按照字典方式按key索引
def birth(x, **kwargs):
return f'{x}身高{kwargs["height"]}cm'
# 调用随机函数,指定相同的范围
df['apply_birth'] = df['student'].apply(
birth, height=np.random.randint(160, 180))
df['map_birth'] = df['student'].map(
lambda x: f'{x}身高{np.random.randint(160,180)}cm')
student sex score nationality apply_birth map_birth
0 小王 m 80 汉族 小王身高164cm 小王身高171cm
1 小红 f 90 回族 小红身高164cm 小红身高178cm
2 小明 m 85 汉族 小明身高164cm 小明身高169cm
3 小林 f 83 保安族 小林身高164cm 小林身高175cm我们来对比一下map()和apply(),同样的想法却出现不一样的效果。apply()出来的身高都是一样的,而map()出来的身高是不一样的。所以就如之前的总结所说一般,map()作用于 Series中的每个元素 ,apply()作用于 整个Series 。
我们看一下apply()是如何作用于多行/列的,下面案例中我们调取多列来实现对少数民族同学加5分的操作。
# 多列选择后使用apply,可以使用位置索引选择列,比如这里x[1]代表的是df['score']
df['加分后成绩'] = df[['nationality', 'score']].apply(
lambda x: x[1]+5 if x[0] != '汉族' else x[1], axis=1)
student sex score nationality 加分后成绩
0 小王 m 80 汉族 80
1 小红 f 90 回族 95
2 小明 m 85 汉族 85
3 小林 f 83 保安族 88上面案例中为什么要用axis=1呢,下面的例子,请各位意会一下。

- axis=0是对行计算,返回的行数与原表列索引数相等。
- axis=1是对列进行计算,返回的行数应该与原表行索引数相等。
applymap
applymap()是DataFrame的方法,只能作用于整个DataFrame。
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
0 4 9
1 4 9
2 4 9
df.applymap(lambda x: x+2)
0 6 11
1 6 11
2 6 11
# 错误示范
df['A'].applymap(lambda x: x+2)
AttributeError: 'Series' object has no attribute 'applymap' 不得不会的groupby
敲黑板!pandas中相当重要的一环!
DataFrame.groupby(self, by=None, axis=0, level=None, as_index: bool = True, sort: bool = True, group_keys: bool = True, squeeze: bool = False, observed: bool = False)
返回的是DataFrameGroupBy对象,groupby的基本流程如下:
- 根据某些标准将数据分成组。
- 对每个组独立应用一个函数。
- 将结果组合到数据结构中。
import random
# 以下所有案例皆基于这个DataFrame
cat = ['product1', 'product2', 'product3']
df = pd.DataFrame(list(zip(pd.date_range(start='2020/1/1',end='2020/1/10'),random.choices('ABC', k=10), random.choices(cat, k=10), random.choices(
range(1, 100), k=10))), columns=['date','salesman', 'product', 'volume'])
date salesman product volume
0 2020-01-01 C product3 49
1 2020-01-02 C product3 30
2 2020-01-03 B product1 35
3 2020-01-04 A product3 63
4 2020-01-05 B product2 26
5 2020-01-06 A product3 37
6 2020-01-07 B product1 50
7 2020-01-08 C product2 16
8 2020-01-09 A product2 45
9 2020-01-10 B product3 22看到ABC,偷偷教大家一个Python快速打出26个英文字母的方法。
from string import ascii_uppercase # 26个大写字母
from string import ascii_lowercase # 26个小写字母
from string import ascii_uppercase # 52个字母,前26小写,后26大写
只要直接print(ascii_uppercase/ascii_lowercase/ascii_uppercase)就可以了。
我们想看一下销售员的总销量,相当于SQL中的group by。
df.groupby(by='salesman').sum()
volume
salesman
A 145
B 133
C 95再看一下各销售员每类产品的总销量。
groupby可以根据多个标签分组,但是注意,默认情况下多标签分组后获得的DataFrameGroupBy是含有MultiIndex的。
# 默认情况下sort=True,Pandas会将分组标签自动排序,也可以设置为False,加快groupby速度,但大多数情况还是让它排序吧
df_mulitindex = df.groupby(by=['salesman','product'],sort=True).sum()
df_mulitindex
volume
salesman product
A product2 45
product3 100
B product1 85
product2 26
product3 22
C product2 16
product3 79即使是MultiIndex DataFrame也一样可以groupby的,你可以用level也可以用by来控制分组的标签。
- 如果原DataFrame是普通索引,那只能设置by参数
- 如果是MultiIndex DataFrame,那by和level都可以设置,但是更推荐用level,别问为什么,问就是不知道
df_mulitindex.groupby(level='product',sort=False).sum()
volume
product
product2 87
product3 201
product1 85我想先不进行聚合运算,看看分好组的样子可以吗?接下来几个函数可以帮到你。
- df.groupby().first()返回每个分组的第一行
- df.groupby().last()返回每个分组的最后一行
- df.groupby().nth(n)返回每个分组的第n行
- df.groupby().head(n)返回每个分组前n行
- df.groupby().tail(n)返回每个分组后n行
groupby的第一步操作,是按照指定字段分组,所以首先我将原DataFrame对列索引进行排序,方便大家理解。
# ascending=False降序/True升序
df.sort_values(by=['salesman','product','volume'],ascending=[True,True,False])
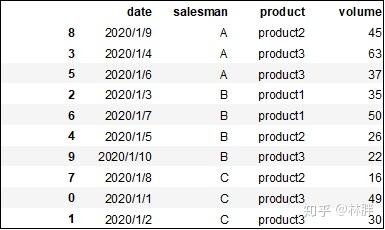
上述函数我就不一一展示,就举一例子,查询各业务员各类产品销量最高的那行数据。
df.sort_values(by='volume',ascending=False).groupby(by=['salesman','product']).first()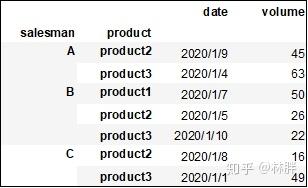
讲一讲MultiIndex
多了几个标签作为行索引而已,跟普通的Index没什么的,只是索引方式有那么一点点的小不同,看下去就知道。
# agg不知道是什么不要紧,下面会讲
df_multi =df.groupby(by=['salesman','product']).agg(vol_sum=('volume','sum'),vol_max=('volume','max'))
df_multi
vol_sum vol_max
salesman product
A product2 45 45
product3 100 63
B product1 85 50
product2 26 26
product3 22 22
C product2 16 16
product3 79 49还记得loc吗!标签索引,忘记了回头看一下第一篇。
# 最基本的索引其实就是加上括号,把元组作为索引条件
df_multi.loc[('B','product3')]# 这样返回的是Series
vol_sum 32
vol_max 32
Name: (B, product3), dtype: int64
df_multi.loc[[('B','product3')]]# 这样返回的是DataFrame
vol_sum vol_max
salesman product
B product3 32 32
# 切片,一样的
df_multi.loc[('B','product3'):('C','product3'),'vol_max'] # 这样返回的是Series
salesman product
B product3 32
C product2 96
product3 72
Name: vol_max, dtype: int64
df_multi.loc[('B','product3'):('C','product3'),['vol_max']] # 这样返回的是DataFrame
vol_max
salesman product
B product3 32
C product2 96
product3 72MultiIndex DataFrame怎么变为一维表?
- 分组时加入as_index=False使返回的DataFrame直接变为一维表
- 或使用reset_index()将含有MultiIndex的DataFrame变为一维表
df.groupby(by=['salesman','product'],as_index=False).sum()
df.groupby(by=['salesman','product']).sum().reset_index()
出来的效果都是这样
salesman product volume
0 A product2 45
1 A product3 100
2 B product1 85
3 B product2 26
4 B product3 22
5 C product2 16
6 C product3 79MultiIndex DataFrame怎么变成二维表?
- unstack()
df.groupby(by=['salesman','product']).sum().unstack()
volume
product product1 product2 product3
salesman
A NaN 45.0 100.0
B 85.0 26.0 22.0
C NaN 16.0 79.0DataFrameGroupBy可以用的统计函数
FunctionDescription mean()平均值sum()求和size()返回group的大小count()计数std()标准差var()方差sem()标准误describe()超级方便的数据表述函数,包括了很多常见统计量first()组中的第一个值last()组中的最后一个值nth()取n个值min()最小值max()最大值
如果确定要对某一列进行聚合运算,强烈建议先指出该列再使用聚合函数,可以提高效率。
df.groupby(by='salesman').describe()
volume
count mean std min 25% 50% 75% max
salesman
A 1.0 3.000000 NaN 3.0 3.00 3.0 3.0 3.0
B 6.0 46.166667 28.596620 2.0 32.75 47.5 66.0 80.0
C 3.0 77.666667 16.258331 65.0 68.50 72.0 84.0 96.0累计函数
累计函数,相信大家看一下案例就能理解了!
方法名函数功能 cumsum()依次给出前1、2、… 、n个数的和cumprod()依次给出前1、2、… 、n个数的积cummax()依次给出前1、2、… 、n个数的最大值cummin()依次给出前1、2、… 、n个数的最小值
d = {
'salesperson': [
'Nico',
'Carlos',
'Juan',
'Nico',
'Nico',
'Juan',
'Maria',
'Carlos',
'item': ['Car', 'Truck', 'Car', 'Truck', 'cAr', 'Car', 'Truck', 'Moto'],
df = pd.DataFrame(d)
salesperson item
0 Nico Car
1 Carlos Truck
2 Juan Car
3 Nico Truck
4 Nico cAr
5 Juan Car
6 Maria Truck
7 Carlos Moto
df['count_by_person'] = df.groupby(by='salesperson').cumcount() + 1
df['count_by_item'] = df.groupby(by='item').cumcount() + 1
df['count_by_both'] = df.groupby(by=['salesperson', 'item']).cumcount() + 1
df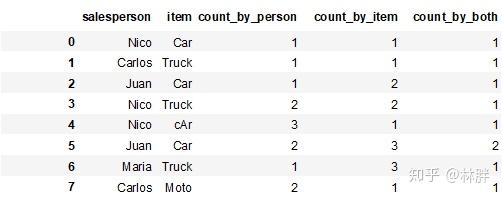

agg、transform、filter
agg
agg()是aggregate()的别称,就像isna()是isnull()的别称一样。
agg()主要用在DataFrameGroupBy上,当然也可以用在DataFrame上,是用来在多列上计算不同函数的。
# 用法一
# 直接使用列表列出所要使用的统计函数,具体可用函数已经在上面表中列出
# 可以用字符串形式表示函数,也可以直接打函数名不加引号,如果报错就打np.函数名(毕竟pandas是基于numpy)
df.groupby(by='salesman')['volume'].agg(['sum','max'])
sum max
salesman
A 145 63
B 133 50
C 95 49
# 用法二
# 可以自定义列名,格式是agg(name=(column,func))
df.groupby(by='salesman').agg(vol_max=('volume','max'),vol_sum=('volume','sum'))
vol_max vol_sum
salesman
A 63 145
B 50 133
C 49 95
# 方法三
# 您细细品一下效果
df.groupby(by='salesman').agg({'volume':['max','mean'],'date':['min','max']})
volume date
max mean min max
salesman
A 63 48.333333 2020-01-04 2020-01-09
B 50 33.250000 2020-01-03 2020-01-10
C 49 31.666667 2020-01-01 2020-01-08当然,agg()也可以自定义函数。
# 每个人的销量乘以100再求和
df.groupby(by='salesman').agg({"volume":lambda x:sum([i*100 for i in x])})
volume
sales man
A 14500
B 13300
C 9500agg也是可以用在DataFrame或Series上,但个人感觉没样啥用,还不如直接用apply。
df[['volume']].agg(['max','min'])
volume
max 63
min 16transform
转换,有时候还是有点用的,我们看一下实例。
# 我们重新创建一个DataFrame,适用于transform和filter的
df_temp = pd.DataFrame([['2020/1/1', 'A', 100], ['2020/2/1', 'A', 50], ['2020/3/1', 'A', np.nan], ['2020/1/1',
'B', 1000], ['2020/2/1', 'B', 3000], ['2020/3/1', 'B', 5000]], columns=['date', 'salesman', 'volume'])
df_temp
date salesman volume
0 2020/1/1 A 100.0
1 2020/2/1 A 50.0
2 2020/3/1 A NaN
3 2020/1/1 B 1000.0
4 2020/2/1 B 3000.0
5 2020/3/1 B 5000.0我们可以看到A业务员2020/3/1的销量为np.nan,没有记录,如果我们需要对数据进行清洗该怎么办呢?
直接删除吗,这不是最佳的选项。如果要填充,直接用整列的volume的平均值?那这样对B业务员是不是很吃亏?
所以我们可以尝试用A的均值来填充她的缺失值。
df_temp.volume = df_temp.groupby(by='salesman')['volume'].transform(lambda x:x.fillna(x.mean()))
df_temp
date salesman volume
0 2020/1/1 A 100.0
1 2020/2/1 A 50.0
2 2020/3/1 A 75.0
3 2020/1/1 B 1000.0
4 2020/2/1 B 3000.0
5 2020/3/1 B 5000.0filter
看名字就知道是过滤,可以自定义函数。
def filter_loser(x):
describe:筛选掉总销售量小于300的业务员
return
return x['volume'].sum()>=300