

![你真的会用索引么?[Mongo]](https://pic1.zhimg.com/v2-7428a4103d30061f74a6fdd37695e418_r.jpg?source=172ae18b)
你真的会用索引么?[Mongo]

一次奇怪的查询经历
如何奇怪了?
- 对 同一张表 ,用 同样的SQL ,查询200万条数据 耗时100ms ,查询二十条数据却 耗时30s 。
- 数据量少了10万倍,完全不是一个数量级的数据,耗时却多了300倍。
- 明明加了索引为什么还是那么慢?
下图是在本地简化模拟出来的查询结果,虽然没有那么夸张但是同样可以复现问题。
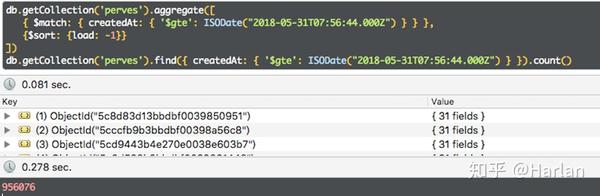

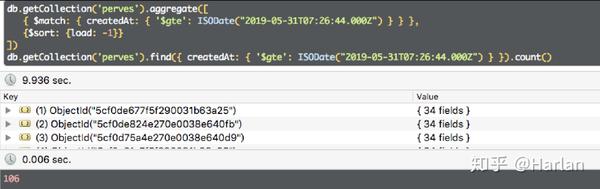

如上二图,通过相同查询条件以及相同的排序条件,进行查询,查询效率缺却天差地别,下面让我们来一起探索一下究竟是为什么?
索引概述
我们常常会看到一些乱七八糟的索引,所以我们用索引的真正目的是什么呢?
终极目的:借助索引快速搜索,有效减少了扫描的行数
精髓:不止要有索引,索引的过滤性还要好,区分度要足够高,这才是好的设计
索引的类型和属性
唯一索引
唯一索引是索引具有的一种属性,让索引具备唯一性,确保这张表中,该条索引数据不会重复出现。在每一次insert和update操作时,都会进行索引的唯一性校验,保证该索引的字段组合在表中唯一。
db.containers.createIndex({name: 1},{unique:true, background: true})
db.packages.createIndex({ appId: 1, version: 1 },{unique:true, background: true})
知识点一:
创建索引时,1表示按升序存储,-1表示按降序存储。
知识点二:
Mongo提供两种建索引的方式foreground和background。
前台操作,它会阻塞用户对数据的读写操作直到index构建完毕;
后台模式,不阻塞数据读写操作,独立的后台线程异步构建索引,此时仍然允许对数据的读写操作。
创建索引时一定要写{background: true}
创建索引时一定要写{background: true}
创建索引时一定要写{background: true}
复合索引
概念: 指的是将多个键组合到一起创建索引,终极目的是加速匹配多个键的查询。
看例子来理解复合索引是最直接的方式:


图中模拟了简单的航班信息表的数据。
对表中指定航班进行查询,查询后按价格排序。
db.getCollection('flight').find({flight: “CA12345”}).sort({price: 1})
在没有索引的情况下,那么他其实是会一条一条的扫描全部8条数据,找到 CA12345航班,然后再在内存中按价钱进行排序。
如果这时我给航班添加一条索引 db.flights.createIndex({ flight: 1 },{background: true}),那么索引会类似于下图一样,将数据按照索引规则进行排序,此时就只需要扫描4条 CA12345航班的数据,然后再在内存中进行排序。如果数据量大了以后,在内存中进行排序的代价是非常大的。


所以我们可以建立 复合索引 db.flights.createIndex({ flight: 1, price: 1 },{background: true})


让数据按照索引先将所有数据以航班号有序排列,再在航班号相同的数据集中按价格升序排列,这样在进行查询的时候,就可以准确的使用索引扫描4条数据,并且他们本身就是有序的,无需再进行额外的排序工作。以上实现了通过复合索引,让查询变得最优,这就是复合索引的作用。
内嵌索引
可以在嵌套的文档上建立索引,方式与建立正常索引完全一致。
个人信息表结构如下,包含了省市区三级的地址信息,如果想要给城市(city)添加索引,其实就和正常添索引一样
db.personInfos.createIndex({“address.city”:1})
const personInfo = new Schema({
name: { type: String, required: true },
address: {
province: { type: String, required: true },
city: { type: String, required: true },
district: { type: String, required: true },
}, {timestamps: true});知识点三:
对嵌套文档本身“address”建立索引,与对嵌套文档的某个字段(address.city)建立索引是完全不相同的。
对整个文档建立索引,只有在使用文档完整匹配时才会使用到这个索引,例如建立了这样一个索引db.personInfos.createIndex({“address”:1}),那么只有使用db.personInfos.find({“address”:{“province”:”xxx”,”city”:”xxx”,""district":"xxx"}})这种完整匹配时才会使用到这个索引,使用db.personInfos.find({“address.city”:”xxx”})是不会使用到该索引的。
数组索引
MongoDB支持对数组建立索引,这样就可以高效的搜索数组中的特定元素。
知识点四:
但是!对数组建立索引的代价是非常高的,他实际上是会对数组中的每一项都单独建立索引,就相当于假设数组中有十项,那么就会在原基础上,多出十倍的索引大小。如果有一百个一千个呢?
所以在mongo中是禁止对两个数组添加复合索引的,对两个数组添加索引那么索引大小将是爆炸增长,所以谨记在心。
过期索引(TTL)
可以针对某个时间字段,指定文档的过期时间(经过指定时间后过期 或 在某个时间点过期)
哈希索引(Hashed Index)
是指按照某个字段的hash值来建立索引,hash索引只能满足字段完全匹配的查询,不能满足范围查询等
地理位置索引(Geospatial Index)
能很好的解决一些场景,比如『查找附近的美食』、『查找附近的加油站』等
文本索引(Text Index)
能解决快速文本查找的需求,比如,日志平台,相对日志关键词查找,如果通过正则来查找的话效率极低,这时就可以通过文本索引的形式来进行查找
索引的优点
1.减少数据扫描:避免全表扫描代价
2.减少内存计算:避免分组排序计算
3.提供数据约束:唯一和时间约束性
索引的缺点
1.增加容量消耗:创建时需额外存储索引数据
2.增加修改代价:增删改都需要维护索引数据
3.索引依赖内存:会占用极其宝贵的内存资源
索引固然不全是优点,如果不能了解到索引可能带来的危害滥用索引,后果也是非常严重的。
索引虽然也是持久化在磁盘中的,但为了确保索引的速度,实际上需要将索引加载到内存中使用,使用过后还会进行缓存,内存资源相比磁盘空间那是非常的珍贵了。当内存不足以承载索引的时候,就会出现内存——磁盘交换的情况,这时会大大降低索引的性能。
有人说研究索引好累啊?我给我的每个字段都加一个索引不就完事了么?其实每个人都知道这样不好,但实战中好多人都是这样干的。无脑的给每个字段都加上索引就意味着每一次数据库操作,不仅需要更新文档,还需要有大量索引需要更新。mongo每次查询只会使用一个索引。想不到吧?不是你想的我先查航班,在用价格排序,会先走航班的索引,再走价格的索引,你做梦去吧,不可能的,他只会选定一条索引,并不会因为你给每个字端都加了索引就解决问题了。
知识点五:
为了追求索引的速度,索引是加载在内存中使用的,不能合理使用索引后果严重。
mongo每次查询只会使用一次索引!!!只有$or或查询特殊,他会给每一个或分支使用索引然后再合并
何时不应该使用索引
也有一些查询不使用索引会更快。 结果集在原集合中所占的比例越大,查询效率越慢 。因为使用索引需要进行两次查找:一次查找索引条目,一次根据索引指针去查找相应的文档。而全表扫描只需要进行一次查询。在最坏的情况,使用索引进行查找次数会是全表扫描的两倍。效率会明显比全表扫描低。
而相反在提取较小的子数据集时,索引就非常有效,这就是我们为什么会使用分页。
查询优化器
Mongo自带了一个查询优化器会为我们选择最合适的查询方案。
如果一个索引能够精确匹配一个查询,那么查询优化器就会使用这个索引。
如果不能精确匹配呢?可能会有几个索引都适合你的查询,那MongoDB是怎样选择的呢?
- MongoDB的查询计划会将多个索引并行的去执行,最先返回第101个结果的就是胜者,其他查询计划都会被终止,执行优胜的查询计划;
- 这个查询计划会被缓存,接下来相同的查询条件都会使用它;
何时查询计划缓存才会变呢?
- 在计划评估之后表发生了比较大的数据波动,查询优化器就会重新挑选可行的查询计划
- 建立索引时
- 每执行1000次查询之后,查询优化器就会重新评估查询计划
联合索引的优化
当你查询条件的顺序和你索引的顺序不一致的话,mongo会自动的调整查询顺序,保证你可以使用上索引。
例如:你的查询条件是(a,c,b)但是你的索引是(a,b,c)mongo会自动将你的查询条件调整为abc,寻找最优解。
聚合管道的优化
- 如果管道中不需要使用一个完整的文档的全部字段的话,管道不会将多余字段进行传递
- $sort 和 $limit 合并,在内存中只会维护limit个数量的文档,不需要将所有的文档维护在内存中,大大降低内存中sort的压力
然而管道中的索引使用情况是极其不佳的,在管道中,只有在管道最开始时的match sort可以使用到索引,一旦发生过project投射,group分组,lookup表关联,unwind打散等操作后,就完全无法使用索引。
希望通过本文能让你对Mongo的索引有更深的理解
Explain查询计划
提到查的慢,二话不说直接看查询计划好么?具体每一个字段的含义我就不做赘述了很容易查到,我截取winningPlan的部分和大家一起看一下。WinningPlan就是在查询计划中胜出的方案,那肯定就有被淘汰的方案,是在rejectPlan里。
// 查询计划中的winningPlan部分
"winningPlan": {
"stage": "FETCH",
"filter": {
"createdAt": {
"$gte": ISODate("2019-07-22T12:00:44.000Z")
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"load": 1
"indexName": "load_1",
"isMultiKey": false,
"multiKeyPaths": {
"load": []
"isUnique": false,
"isSparse": false,
"isPartial": false,
"indexVersion": 2,
"direction": "backward",
"indexBounds": {
"load": [
"[MaxKey, MinKey]"
},看不懂?没关系,先学习了下面两个知识点,我带你读一遍。
知识点六:
explain 结果将查询计划以阶段树的形式呈现。
每个阶段将其结果(文档或索引键)传递给父节点。
中间节点操纵由子节点产生的文档或索引键。
根节点是MongoDB从中派生结果集的最后阶段。
对于新人一定要特别注意:在看查询结果的阶段树的时候一定一定是从最里层一层一层往外看的,不是直接顺着读下来的。
知识点七:
在查询计划中出现了很多stage,下面列举的经常出现的stage以及他的含义:
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据前面扫描到的位置抓取完整文档
SORT:进行内存排序,最终返回结果
SORT_KEY_GENERATOR:获取每一个文档排序所用的键值
LIMIT:使用limit限制返回数
SKIP:使用skip进行跳过
IDHACK:针对_id进行查询
COUNTSCAN:count不使用用Index进行count时的stage返回
COUNT_SCAN:count使用了Index进行count时的stage返回
TEXT:使用全文索引进行查询时候的stage返回
Explain解读:
将解读写在了注释中,按顺序阅读
// 查询计划中的winningPlan部分
"winningPlan": {
"stage": "FETCH", // 5. 根据内层阶段树查到的索引去抓取完整的文档
"filter": { // 6. 再根据createdAt参数进行筛选
"createdAt": {
"$gte": ISODate("2019-07-22T12:00:44.000Z")
"inputStage": { // 1. 每个阶段将自己的查询结果传递给父阶段树,所以从里往外读Explain
"stage": "IXSCAN", // 2. IXSCAN该阶段使用了索引进行扫描
"keyPattern": {
"load": 1 // 3. 使用了 load:1 这条索引
"indexName": "load_1",
"isMultiKey": false,
"multiKeyPaths": {
"load": []
"isUnique": false,
"isSparse": false,
"isPartial": false,
"indexVersion": 2,
"direction": "backward",
"indexBounds": {