db 里边存了一堆允许重名的文档,需要导出,且自动给重名的文档叠加数字尾缀。比如有文档名字分别是【全国富婆通讯录】、【全国富婆通讯录】、【全国富婆通讯录(1)】…你就不要问为什么要上传重名文档到 db 了,甚至还有已经带了尾缀的文档(可能富婆的世界就是这么奇妙吧*!@##%^&…)
那么生成 doc 塞进 zip 时就会异常:
java.util.zip.ZipException: duplicate entry
导出文件(略),需要 导出 doc /并且压缩成 zip /并且数据源于富文本 请参考
Java 富文本 导出 word 压缩包
, 本篇主要讲导出的文件名重名处理。
用 Hashmap 对文件名字去重并存储叠加数字。
1)先有一个实体类 RichWoman.java
public class RichWoman {
String name = "";
String content = "";
public String getName() {
return name;
public void setName(String name) {
this.name = name;
public String getContent() {
return content;
public void setContent(String content) {
this.content = content;
2)再有一个叠加命名类 TestHashmap.java
import java.util.*;
public class TestHashmap {
public static void main(String[] args) {
List<RichWoman> dataList = new ArrayList<RichWoman>();
RichWoman data = new RichWoman();
data.setName("全国富婆通讯录");
data.setContent("111111");
dataList.add(data);
data = new RichWoman();
data.setName("全国富婆通讯录");
data.setContent("222222");
dataList.add(data);
data = new RichWoman();
data.setName("全国富婆通讯录");
data.setContent("333333");
dataList.add(data);
data = new RichWoman();
data.setName("全国富婆通讯录(1)");
data.setContent("444444");
dataList.add(data);
data = new RichWoman();
data.setName("全国富婆通讯录(1)");
data.setContent("555555");
dataList.add(data);
data = new RichWoman();
data.setName("全国富婆通讯录(1)");
data.setContent("666666");
dataList.add(data);
Map<String, Integer> nameMap = new HashMap<String, Integer>();
for (RichWoman param : dataList){
nameMap.put(param.getName(), 0);
for (RichWoman param : dataList){
String name = param.getName();
int count = nameMap.get(name);
String docName = "";
if (nameMap.containsKey(name)){
if (count > 0){
docName = name + "(" + count + ")";
if (nameMap.containsKey(docName)){
count++;
docName = name + "(" + count + ")";
}else {
docName = name;
}else {
docName = name;
count++;
nameMap.put(name, count);
System.out.println(docName + ".doc" + "-------" + param.getContent());
3)运行效果
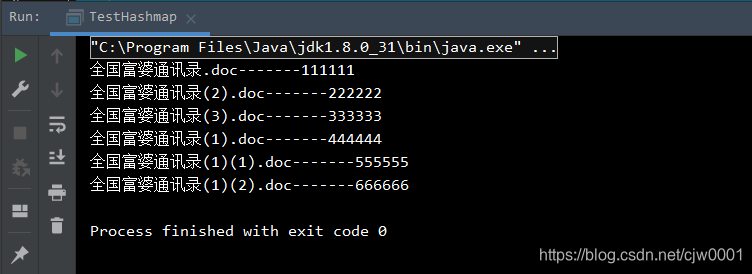
以上。如果有更优雅的办法欢迎留言讨论喔。
db 里边存了一堆允许重名的文档,需要导出,且自动给重名的文档叠加数字尾缀。比如有文档名字分别是【全国富婆通讯录】、【全国富婆通讯录】、【全国富婆通讯录(1)】...java.util.zip.ZipException: duplicate entry
import java.util.List;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
* 文件操作
* Created by heavenick on 2015/7/8.
public class FileUtil...
com.android.build.api.transform.TransformException:
java.util.zip.ZipException: duplicate entry: uk/co/senab/photoview/BuildConfig.class
意思:重复依赖,重复了条目。
在And...
* @param filePath 原始文件存放路径,例如D:/test/AAA.jpg
* @param fileName 原始文件名,例如AAA
* @param suffix 原始文件后缀,例如jpg
* @param num 原始文件名小括号中的数字,如果没有,传0
Java文件上传文件名重复自动加(1)
写了一个如果文件名重复 自动对文件名加(序号)的功能,总感觉哪里不太对,如果有更好的方法,希望能留言告诉我Thanks♪(・ω・)ノ。
makeQueryStringAllRegExp()方法在是从网上找的,具体的出处我也忘了。。。
* 转义正则特殊字符 ($()*+.[]?\^{}
* \\需要第一个替换,否则replace方法替换时会有逻辑bug
public String makeQueryString
import java.util.HashMap;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
* @author 落尘
public clas.
在Java中导出Excel文件名出现乱码的问题可以通过设置`Content-disposition`的header来解决。其中,使用`URLEncoder.encode`方法将文件名进行编码,再将编码后的文件名设置到header中。例如,在SSM框架下可以这样处理:所示的`exportXls`方法。这个方法使用了AutoPoi库来导出Excel文件,并且可以设置导出的文件名和其他参数。
总结来说,要解决Java导出Excel文件名乱码的问题,可以根据浏览器类型选择适合的文件名编码方式,或者使用工具类来简化导出操作。<span class="em">1</span><span class="em">2</span><span class="em">3</span>
#### 引用[.reference_title]
- *1* *2* [java项目poi插件导出Excel文件名中文乱码](https://blog.csdn.net/weixin_42129270/article/details/121425098)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_1"}}] [.reference_item style="max-width: 50%"]
- *3* [Java导出Excel表格文件名乱码问题](https://blog.csdn.net/m0_49790240/article/details/127434593)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_1"}}] [.reference_item style="max-width: 50%"]
[ .reference_list ]

