

【转载】搜索服务索引构建 Dump 系统迁移 Flink 项目分享

一、项目介绍
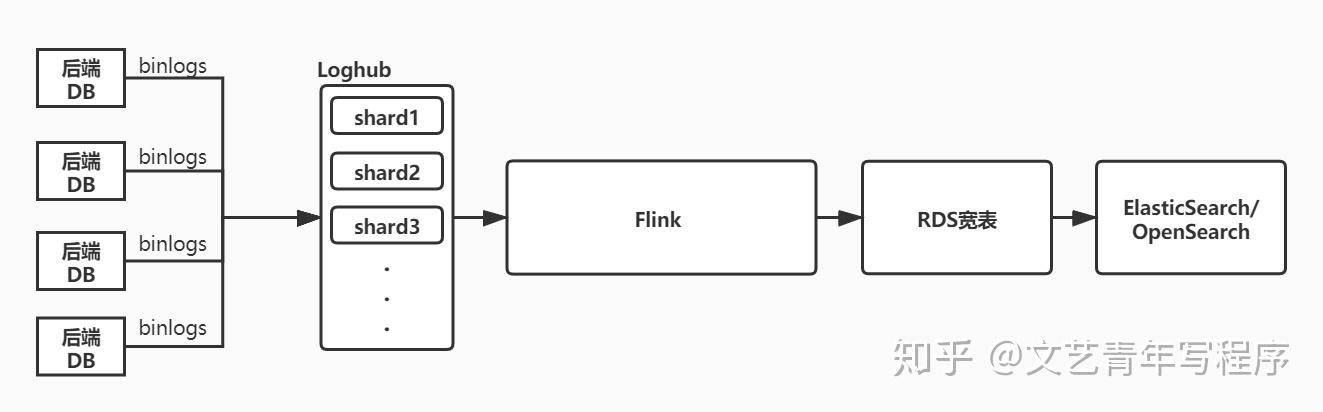
本项目的主要目的是将原搜索服务中构建索引的 Dump 系统独立出来(包括商品和社区的增量索引、商品全量索引、全量/增量索引的批流切换),使用 Flink 实时计算引擎进行重构和性能优化,同时尝试基于 Flink Table/SQL API,将实时计算流程封装为通用组件,实现业务逻辑的 Apollo 配置化。项目的设计思想参考了阿里 Flink SQL 开发平台,并在此基础上根据业务需要进行了一些扩展和定制,比如:以 update/delete 的方式 sink 到 rds、指定多列进行哈希分片写入 Loghub、 UDX 中的 Mysql/Redis/ES 连接池。项目可以在阿里云 Flink 平台上运行的同时也去除了与平台的耦合,可以直接使用 Flink 原生方式运行。

二、Flink 基础概念和运行机制
在Flink中的算子(Operator)分为三种理类型,分别为 Source,比如文件、Socket、Kafka 等,作为批或流的起点;Transform,比如 Filter,Map,FlatMap,Distinct 等数据转换操作;Sink,一般是数据存储,比如将结果数据写入Mysql、Redis、Kafka 等。 Flink 中的算子是天然并行的,每个算子都可以设置并行度(Parallelism),形成每个算子的子任务(SubTask)。

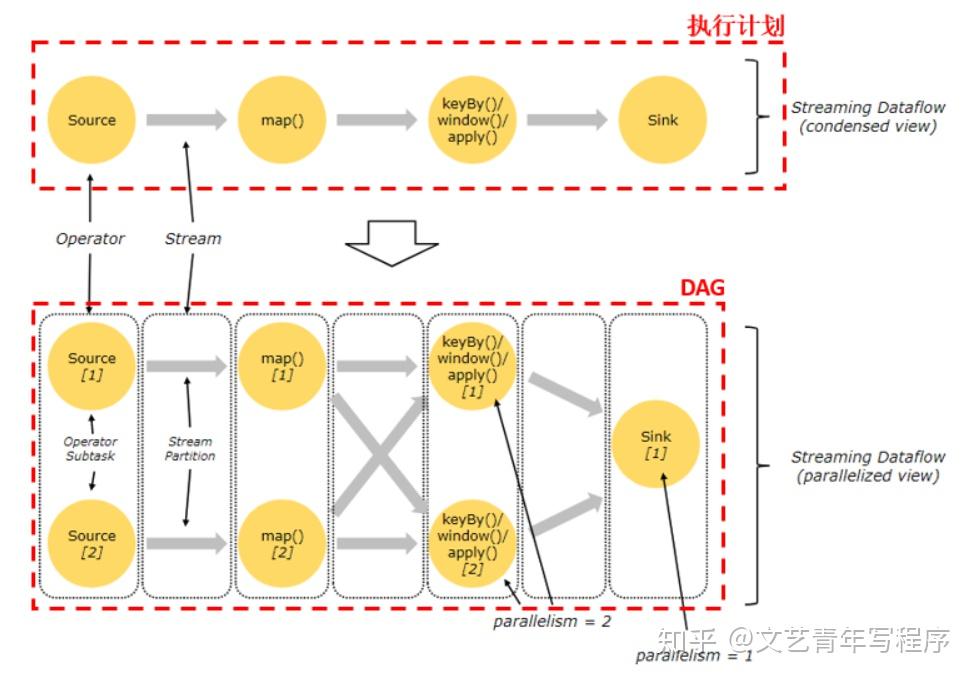
为了更高效地分布式执行,Flink 会尽可能地将算子的 SubTask 链接在一起,在一个线程中执行,叫做链式调用,目的是减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,提高吞吐量。
在不显式调用 disableChaining() 方法取消链式调用的情况下,有两种常见状况会使链式调用失效:
- 遇到 KeyBy 算子;
- 上下游算子的并行度不一致。
简而言之,除非发生了数据 Shuffle,Flink 默认保证消息不乱序。

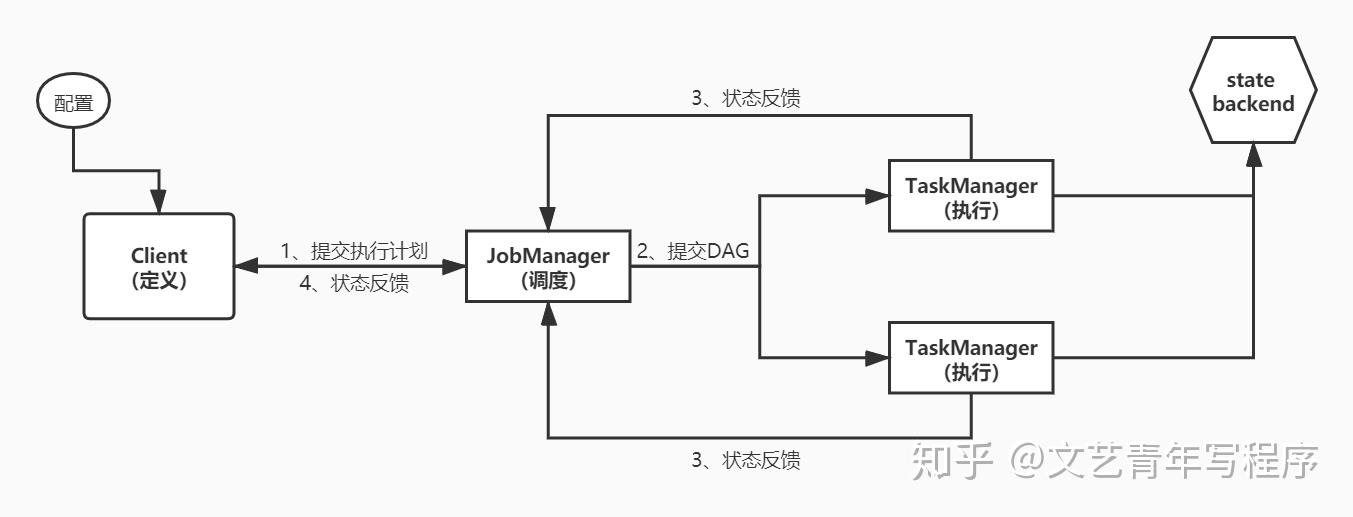
一个 Flink 程序从 Client 开始。用户首先提交 Flink 程序到 Client,Client 将其编译为执行计划,而后提交到 JobManager。JobManager 继续解析收到的执行计划,根据算子的并发度划分 SubTask,形成一个可以被实际调度的有向无环图(DAG),然后申请调度集群资源,发送 DAG 到 TaskManager 执行。

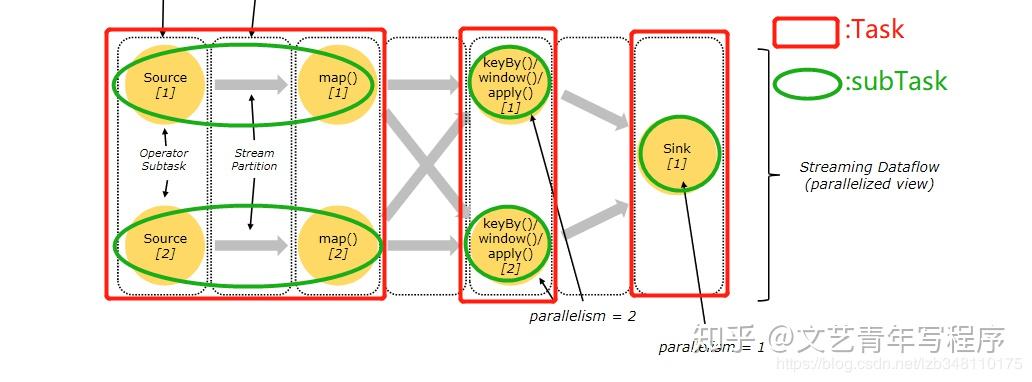
一个 TaskManager 就是一个 Java 虚拟机。Flink 将每一个 TaskManager 均分为多个独立的内存空间,叫做 Slot。这样来自不同执行计划的 Task 不会为了内存而竞争,而是每个 Task 都拥有一定数量的内存储备(这里不会涉及CPU的隔离,Slot 仅隔离内存)。同一个算子的 SubTasks 在不同的 Slot 中执行,即一个算子的最大并行度不能超过 Slot 总数。

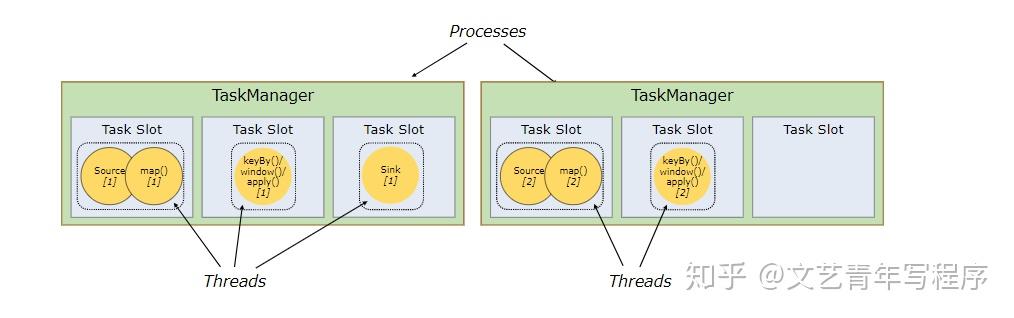
Flink 允许不同算子的 SubTask 共享 Slot,只要它们来自于同一个执行计划。这样的结果就是,一个 Slot 中可能含有一整条 Pipeline。

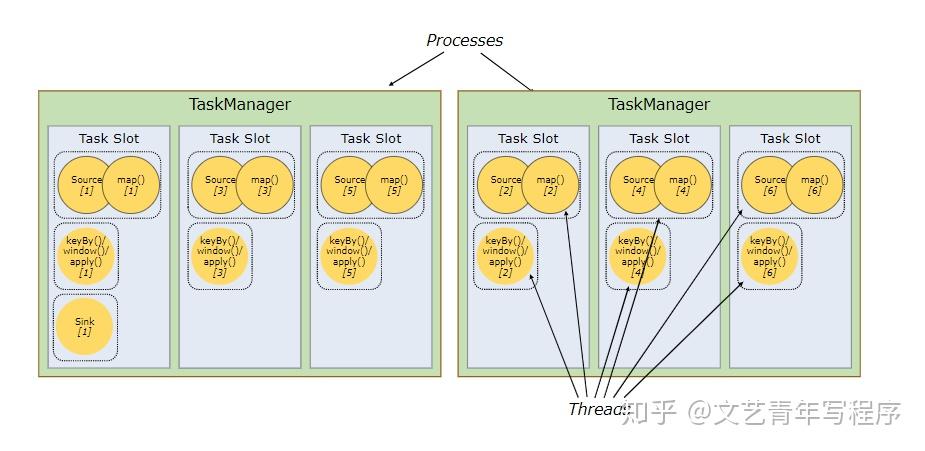
这样做有两个好处:
- 方便计算。所需 Slot 总数,就是最高并行度的算子的并行度;
- 提高资源利用率。原因是每个Slot 内存大小相同,如果没有 Slot 共享,那么简单的 source/map 操作就会占用与密集型操作 keyBy/window 一样多的资源,造成资源浪费。
三、数据处理的有序性和性能问题
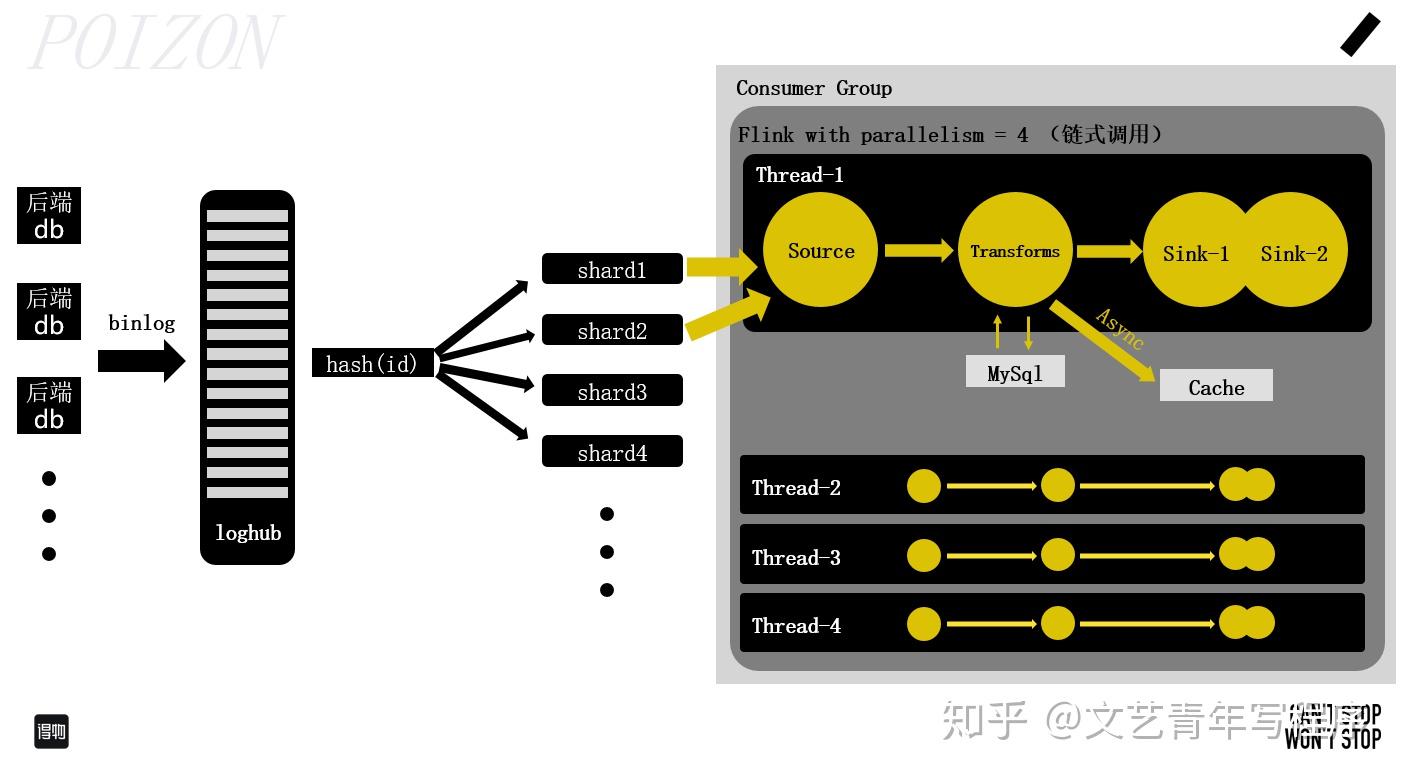
保证顺序消费往往需要牺牲性能。商品索引任务中,具有相同 spu_id 的数据需要被顺序消费,不同 spu_id 的数据没有先后顺序要求,可以安全地并行执行。 因此,项目需要根据商品id对 binlog 进行哈希分流。一种简单的方案是读取数据后增加 keyBy 算子。项目中没有直接这样做,而是增加了一个前置分流的 Flink 任务,这样做有几个好处:
- 将数据清洗 & 分流工作与索引服务的业务逻辑解耦,不受后续批流切换的影响;
- 方便指定 loghub 中 shard 的数量,且禁止自动分裂,以保持与后续 Flink 任务中的并行度一致,以及防止乱序发生;
- 索引任务中不进行 keyBy 操作,保证了所有算子的链式调用,无线程切换开销,也不会有背压 (back pressure) 问题。
前置分流后,相同的商品会顺序地出现在同一个 shard 中,不同的商品可能在不同的 shard 中。目前在测试环境中设置了4个 shard 且禁止分裂,与 Flink 任务的全局并行度一致。这样每个 pipeline 中所有的算子均为链式调用,每个 Slot 中包含数据处理的整个执行计划,在保证了相同商品ID被顺序消费的情况下,也能够并行消费不同商品ID以提高效率。
项目的特殊情况是一个流含有多个Sink,两个 Sink 的外部存储地址相同,但执行的操作不同。一个算子的下游是两个Sink,那么这两个 Sink 会并发执行吗?经过测试,默认情况下先被声明的 Sink 处理完成之后,才会进行下一个 Sink 操作,两个 Sink 操作在在同一个线程中串行处理。

而对于社区索引任务,所有 binlog 都应该按照日志产生的时间顺序消费,所以 Flink 任务的并行度设置为 1。如果原Logstore 中 shard 的数量大于1,就需要在应用中丢弃乱序的数据。
尽管在项目中的两个 Sink 算子是串行的,但是如果调用 disableChaining() 方法取消两个 Sink 的链式调用,就让它们并行处理,会发生什么呢? 两个 Sink 必然有快慢之分,对于上游算子来说,它必须缓存所有快 Sink 已经消费,而慢 Sink 还没有消费的数据,随着时间的增加,必然发生内存溢出吗?
四、Flink 的背压机制
Flink 在运行时主要由 operators 和 streams 两大组件构成。每个 operator 会消费中间态的流,并在流上进行转换,然后生成新的流。对于 Flink 的网络机制一种形象的类比是,Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样:一个较慢的接受者会降低发送者的发送速率,因为一旦队列满了(有界队列)发送者会被阻塞。Flink 解决背压的方案就是这种感觉:


如果下游算子处理较慢,会使 local buffer 数据积压,进而导致 netty 无法把数据放入 local buffer,此时 netty 就不会去socket 上读取新到达的数据,进而触发TCP协议的拥塞控制,所以 TCP 暂时也不会从上游的 socket 去读取新的数据。上游的 netty 也是一样的逻辑,它无法发送数据,也就不能从上游的 local buffer 中消费数据,所以上游的 local buffer 也会耗尽,上游算子处理数据之后申请不到本地buffer,就会导致上游的 process 被阻塞。如果还有相应的上游,则会一直反压上去,一直影响到 source,导致 source 也减缓从外部消息源读取的速度。
因此,算子间消费数据速度不一致,不会导致内存溢出,但整体吞吐量是由最慢的算子决定。
五、配置化设计思想
Flink 提供了 Table/SQL API,使业务逻辑 SQL 配置化成为可能。阿里云 Flink 平台可以直接编辑 SQL 进行流处理任务,在搜索索引 Dump 系统项目中,包括 SQL 的所有配置被全部迁移到了 Apollo 中。这样做有几个目的:
- 配置能够集中统一管理;
- 能够根据业务需要做功能扩展;
- 能够以原生的方式配置SQL运行,不依赖阿里 Flink 开发平台;
- 方便后续接入fusion监控。
Flink 中的 Source 和 Sink 是一种外部存储的概念,在项目中通过 Endpoints 统一配置,比如 Loghub 做 Source、使用 Update 的方式 Sink 到 MySQL。


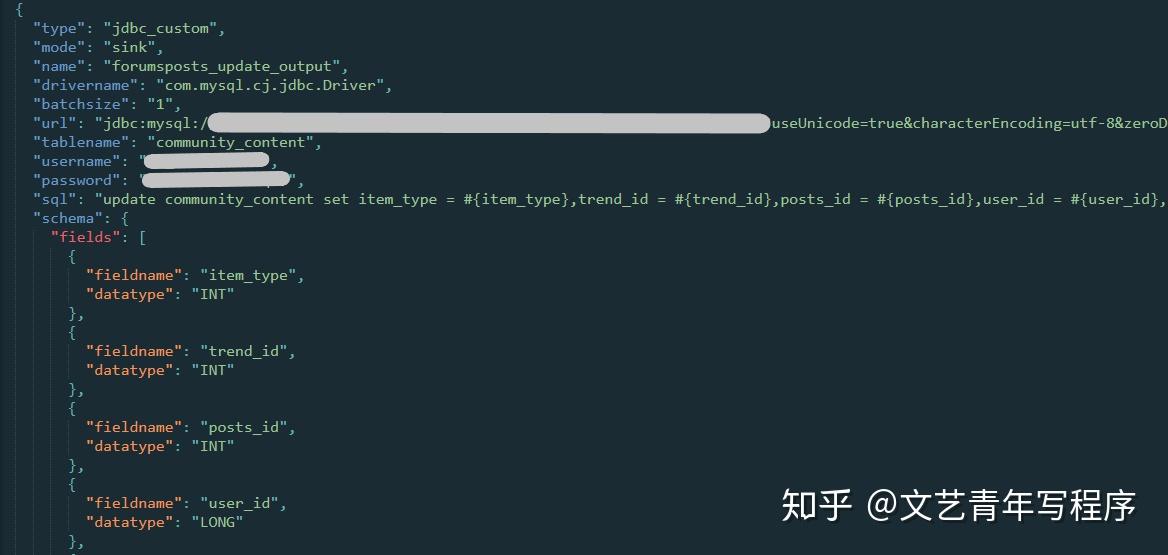
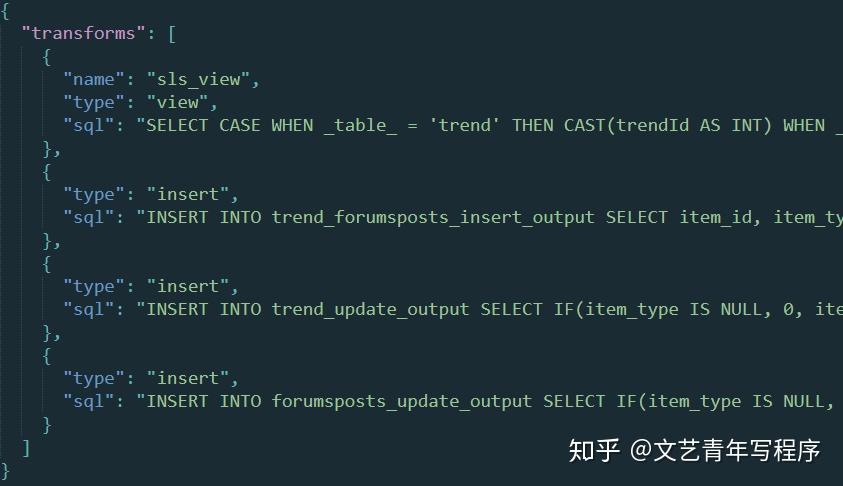
Flink 的 Transform 是另一种类型的配置,比如创建 VIEW、INSERT INTO。

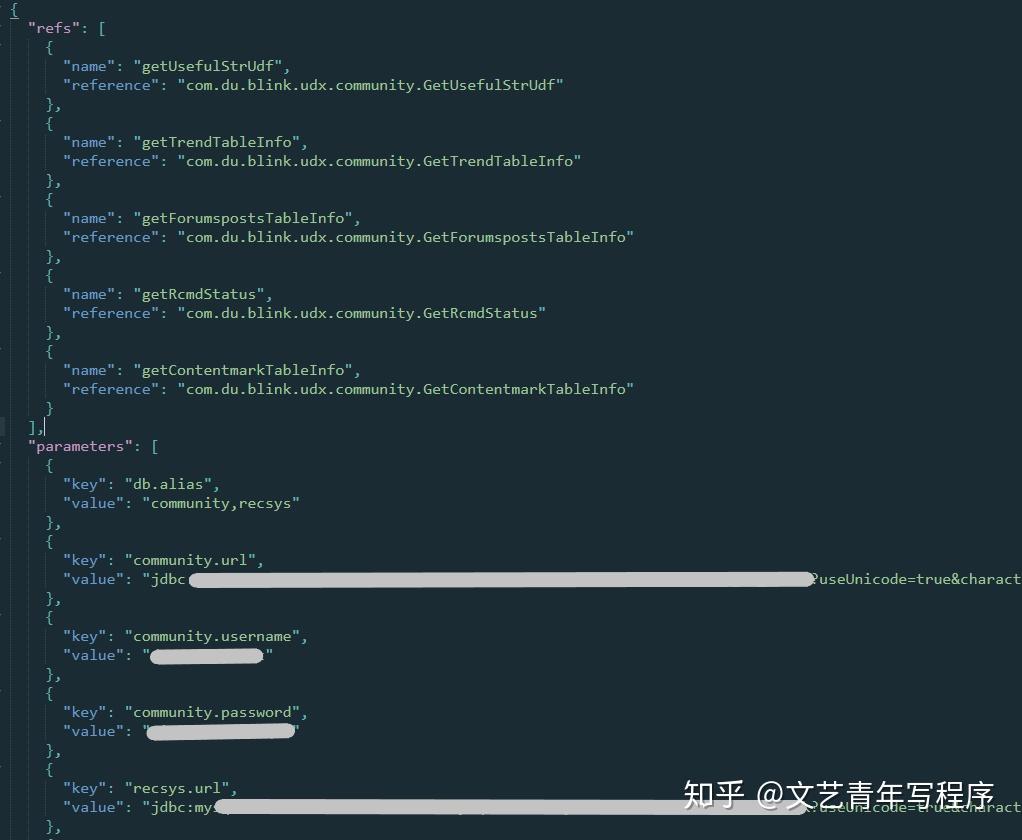
最后一种配置是用户的自定义函数UDX,包括UDX需要的参数配置。

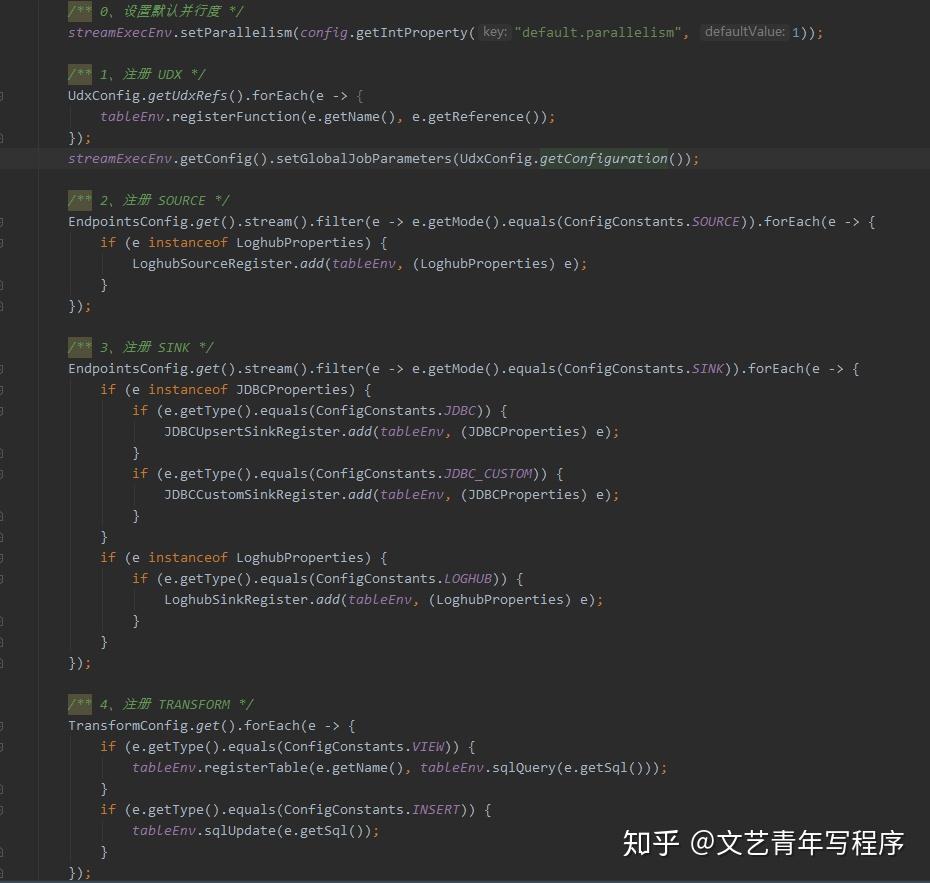
最后在程序的入口,将几种配置注册为对应类型的算子,启动即可。

六、商品增量/全量索引切换方案
需求:提供可以更新所有商品索引的批量任务接口,可以选择是否跳过队列中积压的数据。
解决方案:不再做独立的批处理任务,而是通过接口串行完成两步操作。第一步,根据是否需要跳过积压的数据,决定是否重启流计算以重置消费点位到最末端。第二步,待重启完成后,查询数据库中所有商品ID,写入 Loghub。之后流处理正常进行即可。

七、Flink 容错机制以及 exactly-once 语义的实现原理
Flink的一个重要特性是支持以 Exactly-Once 的方式处理数据流。比如我们经常需要对数据流进行 count、sum、max 等操作,这些操作的中间的结果就是需要保存的状态。如果发生宕机等故障,在恢复后可能需要保证既不丢失也不重复消费数据。
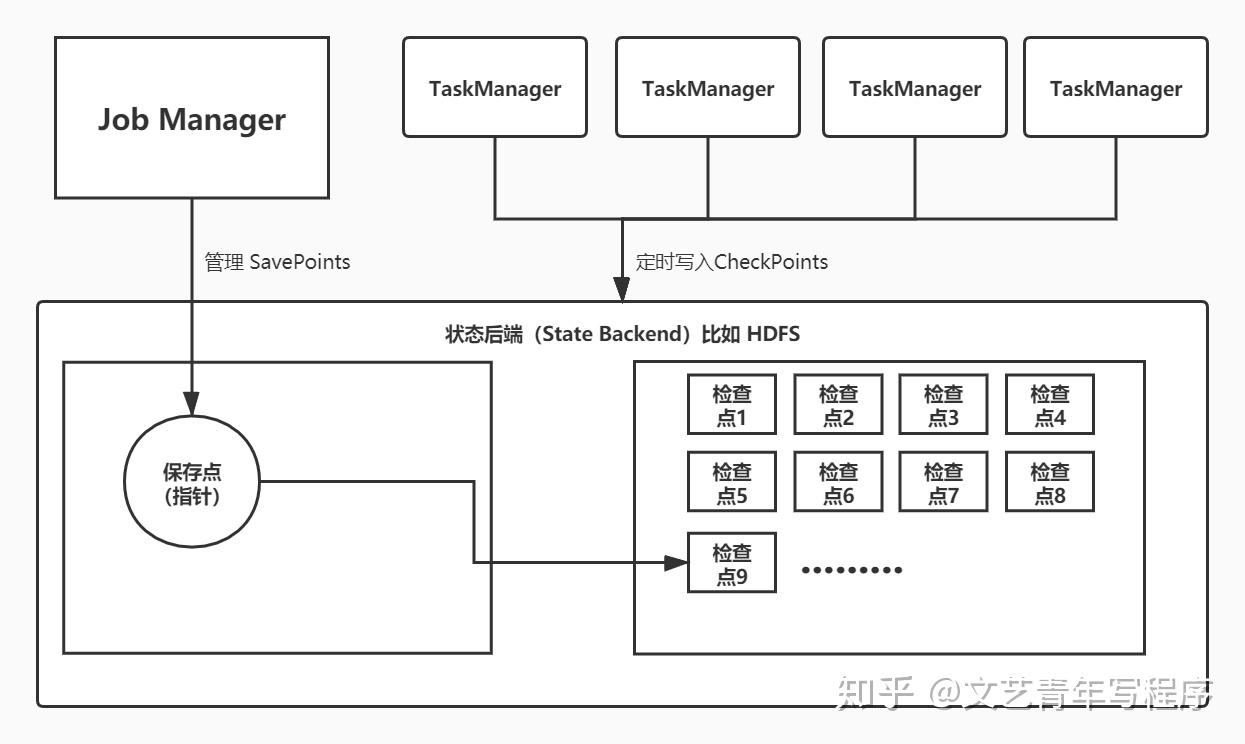
Flink 通过全局快照(Global Snapshot)实现 Exactly-Once 语义,这涉及到两个相似的概念:检查点(checkpoint)、保存点(savepoint)。

简单总结如下:
- CheckPoint 的侧重点是“容错”。Flink作业意外失败并重启之后,能够从之前保存的 CheckPoint 恢复运行;
- SavePoint 的侧重点是“维护”。Flink作业需要在人工干预下手动重启、升级、迁移或 A/B 测试时,先将状态整体写入可靠存储,维护完毕之后再从 SavePoint 恢复现场;
- SavePoint 与 CheckPoint 所用的算法是一样的,所以 SavePoint 本质上是特殊的 CheckPoint 。
Flink 生成检查点基于 Chandy-Lamport 算法,这个算法的目标是记录某个时刻集群所有节点的全局状态。如果只有一个节点,要完成一次 snapshot 只需停止处理新数据然后 dump 内存状态即可。而分布式系统在多台机器上运行,而且互相之间正在通信,要记录所有节点在某个时刻的状态以及此刻正在传输中的消息就困难了许多。
想象一个分布式系统的全局状态总是由三部分组成:
- 进程;
- 进程之间的 Channel;
- Channel 中的消息。
或者说是一个有向图:节点是进程,边是 Channel。

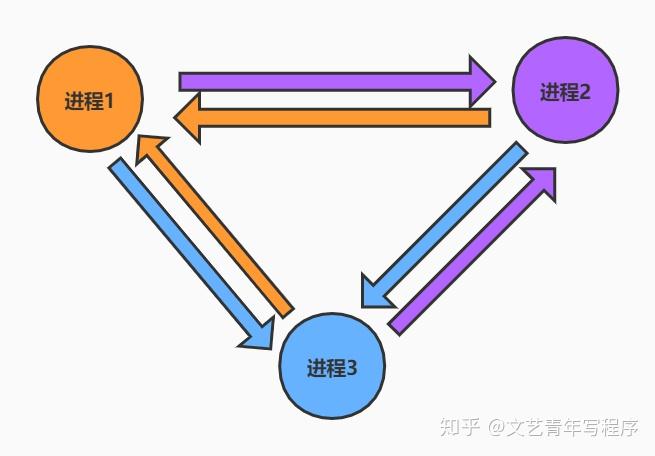
因为是有向图,所以每个进程对应着两类 channel: input channel, output channel。同时假设 Channel 是一个容量无限大的 FIFO 队列,收到的消息都是有序的。通过记录每个节点的本地状态和它的 input channel 中有序的消息,我们可以认为这是一个进程的局部快照。那么全局快照就是所有的进程的局部快照的合并。
基于上面的分布式系统模型来看 Chandy-Lamport 算法就会容易很多:
第一个发起snapshot的进程: 1. 做 local snapshot; 2. 广播 marker 到所有 output channels; 3. 记录接下来每个 input channel 中的数据; 其他进程: if ( 第一次收到 marker ) { 1. 做 local snapshot; 2. 广播 marker 到所有 output channels; 3. 记录接下来其他 input channel 中的数据; } else { 1. 停止记录收到 marker 的 input channel 中的消息。 }
对所有进程来说,当从所有 input channel 中都收到了这个 marker ,就将 local snapshot 和所有记录的数据持久化为 “带版本号的局部 CheckPoint ”。在State Backend 中,所有相同版本号的局部 CheckPoint 被视作一个完整的CheckPoint。

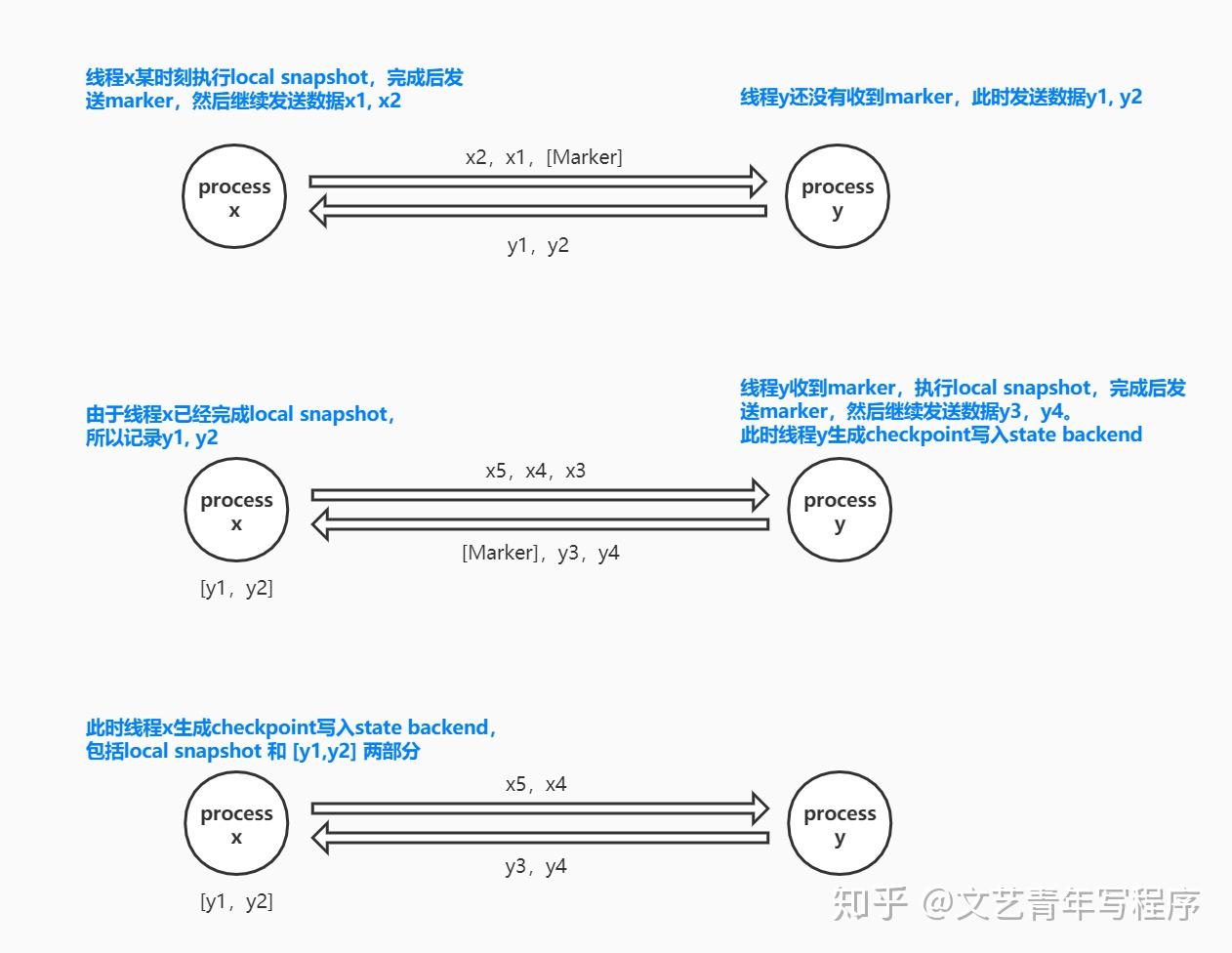
Chandy-Lamport 算法针对的是有向有环图,而 Flink 任务是 DAG(有向无环图),所以 Flink 在 Chandy-Lamport 算法的基础上做了一些改动,marker 在 Flink 中被称为 barrier:
- Barrier 周期性的被注入到所有的 Source 中,Source 节点看到 Barrier 后,会立即做 local snapshot,然后将Barrier发送到 Transform 算子。
- 当 Transform 算子从某个 input channel 收到 Barrier 后,它会立刻阻塞下游,并缓存这个 input channel 中接下来收到的消息,直到所有的 input channels 都收到 Barrier 之后,该 Transform 算子才会做 local snapshot,并向自己的所有 output channels 广播 Barrier。
- Sink 算子接受 Barrier 的操作流程与 Transform 算子一样,当所有的 Barrier 都到达了 Sink ,并且所有的 Sink 也完成了 local snapshot 之后,这一轮全局 snapshot 就完成了。
在 Flink 的 exactly-once 语义下,每个节点是需要等待所有 input channel 的 marker 到达后才做 local snaphot 和处理marker 后面的数据,因此节点的性能取决于最慢的 input channel,服务整体吞吐和性能也会降低。而在 at-least-once 语义,Flink 允许节点一直处理 input channel 中到达的数据,等到所有 marker 到达才做 local snapshot,这样一些 marker 后的数据也会加到 local snapshot 里面。如果节点发生故障从 global snapshot 恢复后,这部分marker后的数据会被重复计算,但换来的是服务整体更大的吞吐量。
在索引服务 Dump 系统中,因为数据是幂等的,可以容忍数据的重复消费,所以将 Flink 设置为 at-least-once 状态最为合理。