


机器学习顶刊汇总:AM、EnSM、Small Methods、ACS AMI、ES&T等成果





1. 王连洲/孙世静/王志亮AM: 机器学习指导光电化学水分解的掺杂剂选择


掺杂是调整金属氧化物基半导体用于太阳能驱动光电化学(PEC)水分解的有效策略。尽管进行了广泛的研究,掺杂剂的选择仍然在很大程度上取决于试错法。机器学习(ML)有望为高性能PEC系统的掺杂剂选择提供可预测的见解,因为它可以揭示掺杂剂的大量特征与掺杂光电极的PEC性能之间的相关性。
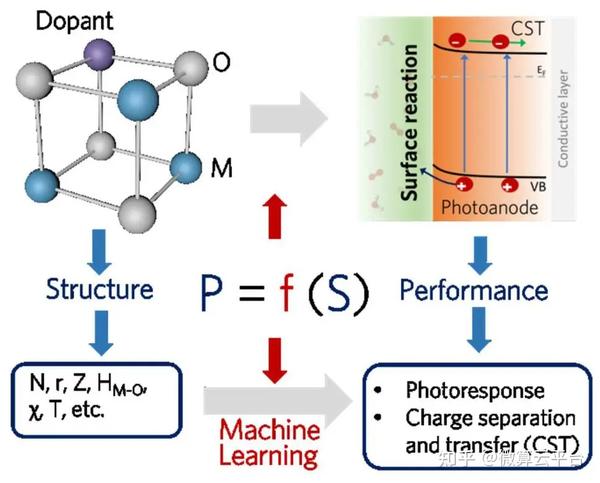
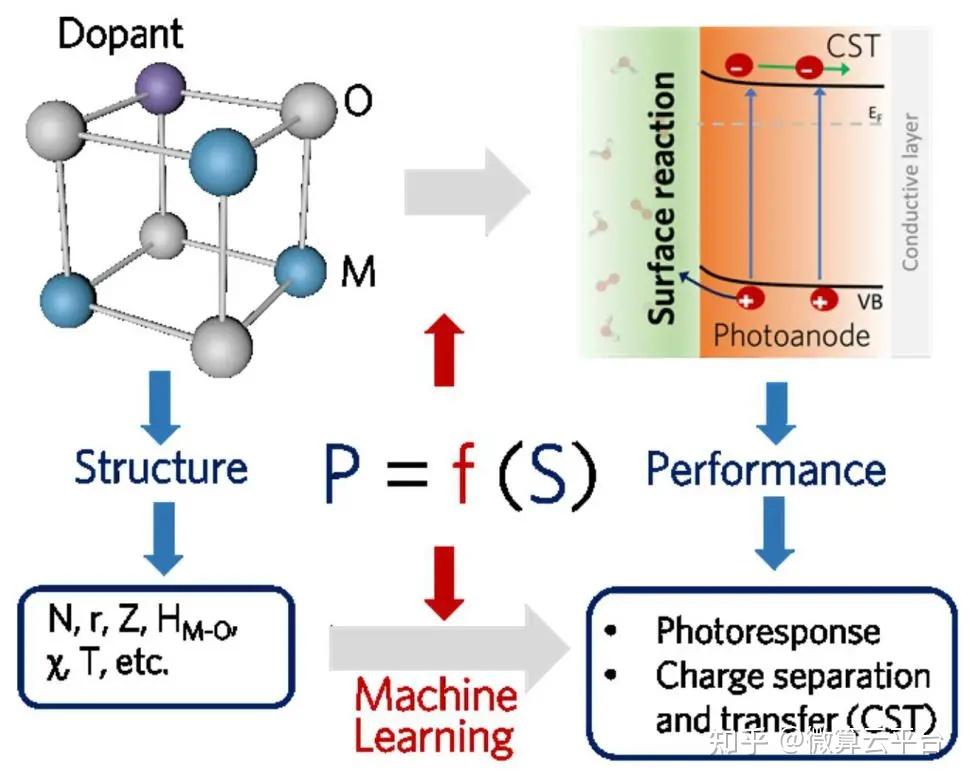
在此, 澳大利亚昆士兰大学王连洲教授、王志亮博士及美国麻省理工学院孙世静 等人首次报道了应用ML研究掺杂剂选择的关键标准,以改善光电极的PEC 响应。作者以赤铁矿Fe2O3作为原型半导体候选物,采用从17种掺杂剂中获取的数据(每种都包含五种独特的掺杂剂浓度)训练ML模型。在ML研究中,采用10个内在特征(如原子序数、离子半径、化学价等)和1个处理特征(掺杂剂浓度)作为描述符,并应用了六种不同的算法,包括基准线性回归(LR)、随机森林(RF)、梯度提升(GB)、支持向量回归(SVR)、K近邻回归(KNN)和神经网络(NN)。
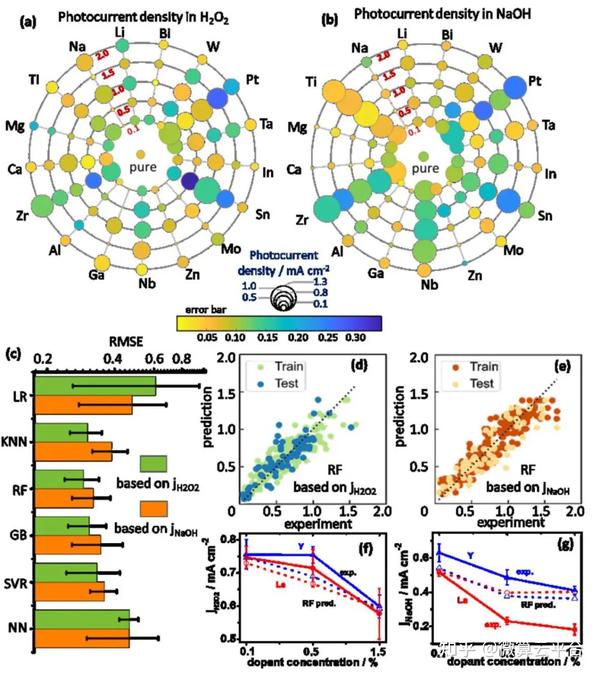
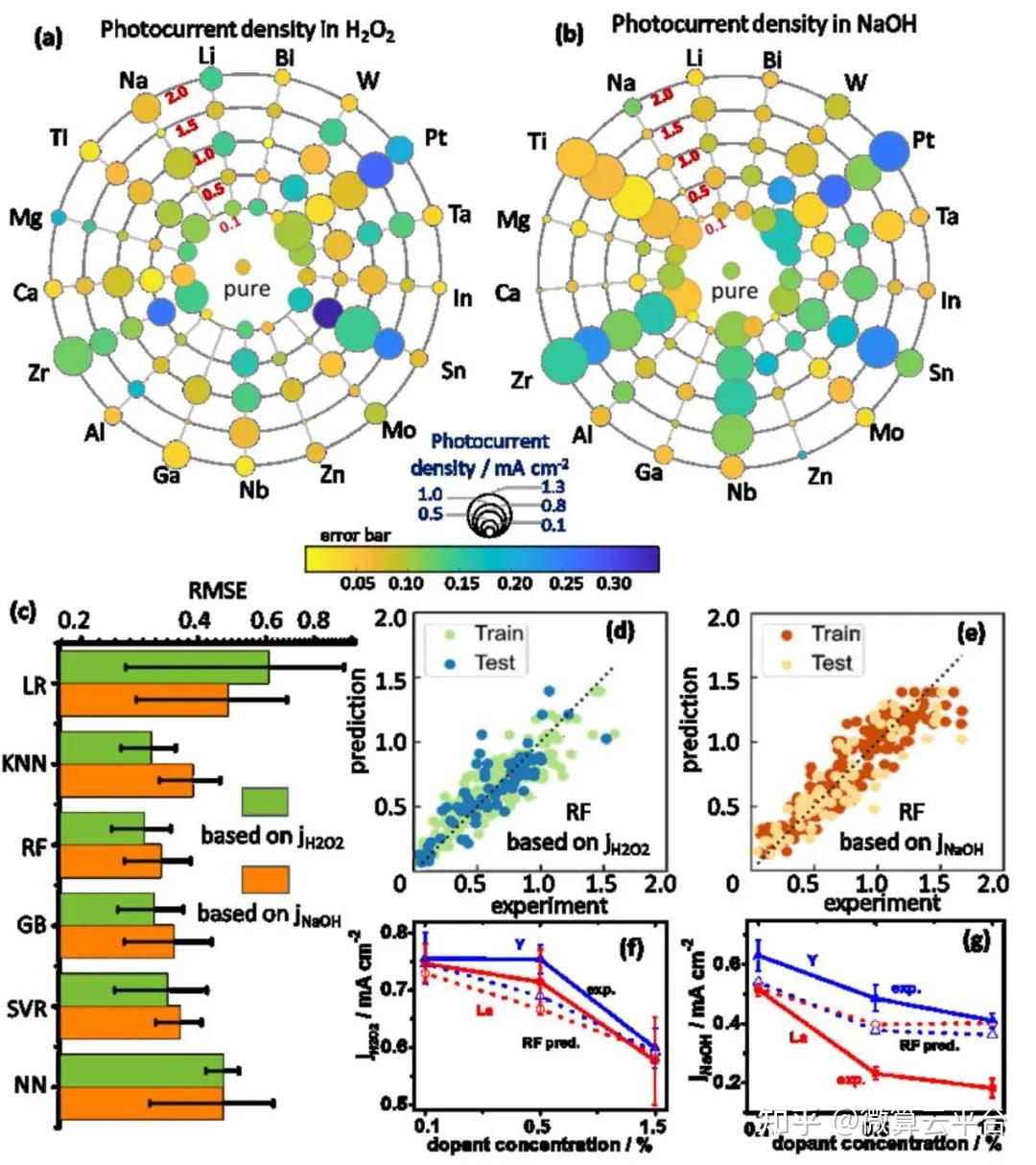
作者基于k折交叉验证,通过均方根误差(RMSE)比较RF、GB、SVR、KNN和NN的模型性能,与基准LR方法相比,KNN、RF 和GB显示出显著的改进。其中,由于批次间的变化,RF模型的RMSE与实验误差的数量级相同。经过训练的ML模型,作者成功预测了分别掺杂镧(La)和钇(Y)的Fe2O3光阳极的电荷分离和转移(CST)性能。通过SHAP分析对这些描述符的重要性进行排序,作者发现化学态、离子半径和金属-氧(M-O)键形成焓是促进CST的三个最重要的掺杂剂选择标准。此外,ML引导的掺杂剂选择已进一步扩展到典型的基于 CuO的光电阴极设计,展示了这种数据驱动方法的普适性。
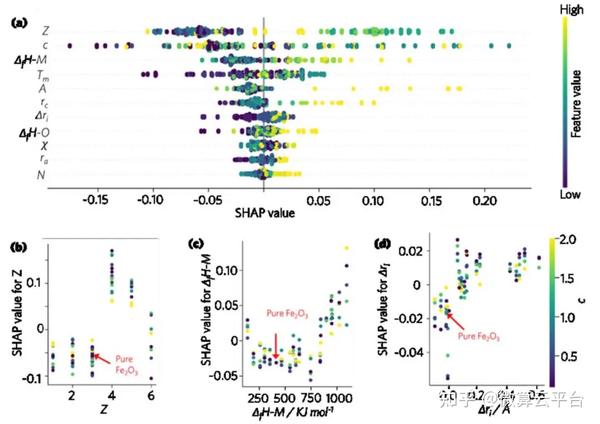
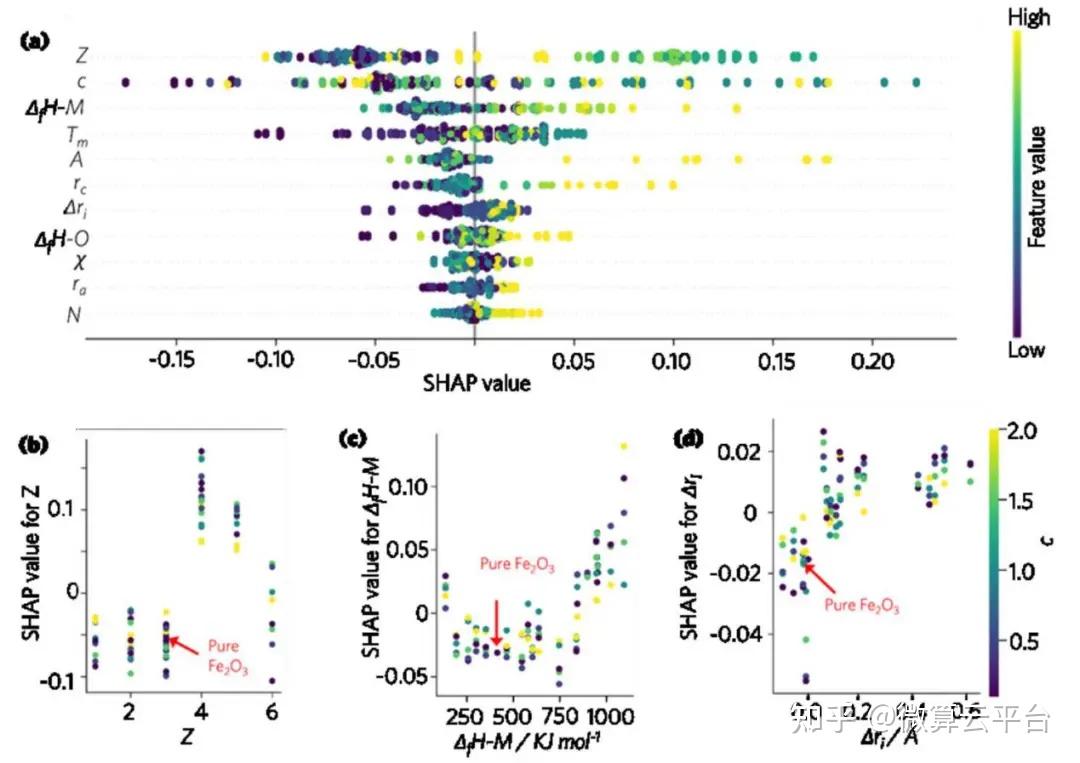
Machine Learning Guided Dopant Selection for Metal Oxide based Photoelectrochemical Water Splitting: The Case Study of Fe2O3and CuO, Advanced Materials 2021. DOI: 10.1002/adma.202106776
2. 重大胡晓松/谢翌EnSM: 敏感性分析+深度学习实现电池模型的无损参数识别


基于物理的电化学模型可以深入了解电池内部状态,并在电池设计优化及汽车和航空航天应用中显示出巨大潜力。然而,电化学模型的复杂性使其难以准确获得参数值,此外,电化学参数的识别通常通过耗时数小时至数周的大规模优化算法进行。
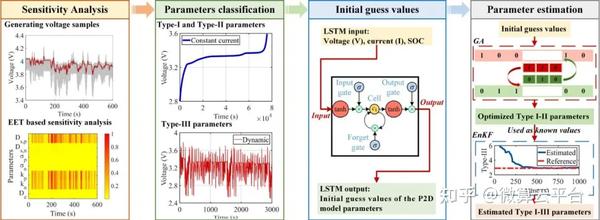
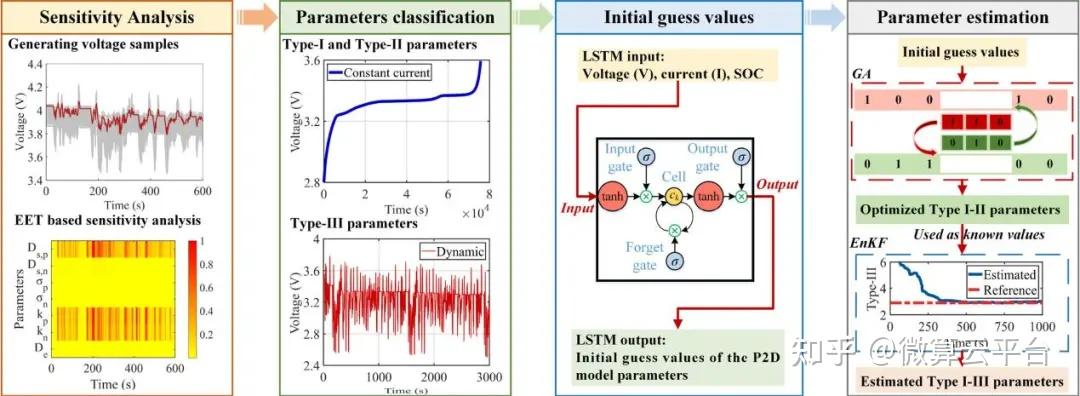
在此, 重庆大学胡晓松教授、谢翌副教授 等人提出了一种用于最常用的电化学准二维(P2D)模型的新型无损参数识别方法,包括几何参数和电化学参数。如果不拆卸电池,通常无法得到这些参数。整个参数识别过程包括三个关键步骤:参数敏感性分析和分类、初始猜测值生成和参数识别。首先,使用基于基本效应测试(EET)的全局敏感性分析找到P2D模型的14个敏感参数,并根据其最敏感的条件分为三类(Type-I、Type-II、Type-III)。其次,使用深度学习(长短期记忆网络,LSTM)算法获得这些未知参数的可行初始猜测值,这不仅可以帮助避免识别算法的发散问题,而且可以加快后续识别过程。最后,结合遗传算法(GA)和集成卡尔曼滤波器(EnKF)方法进行参数识别,逐步估计灵敏度高的参数。
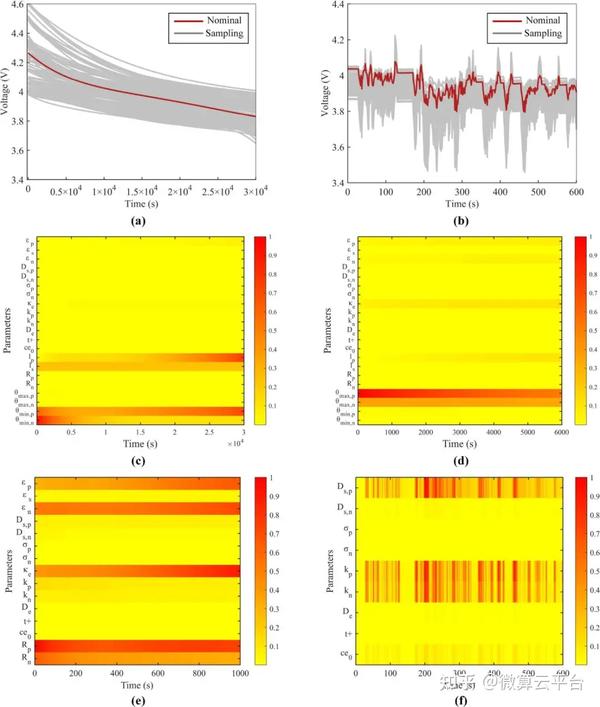
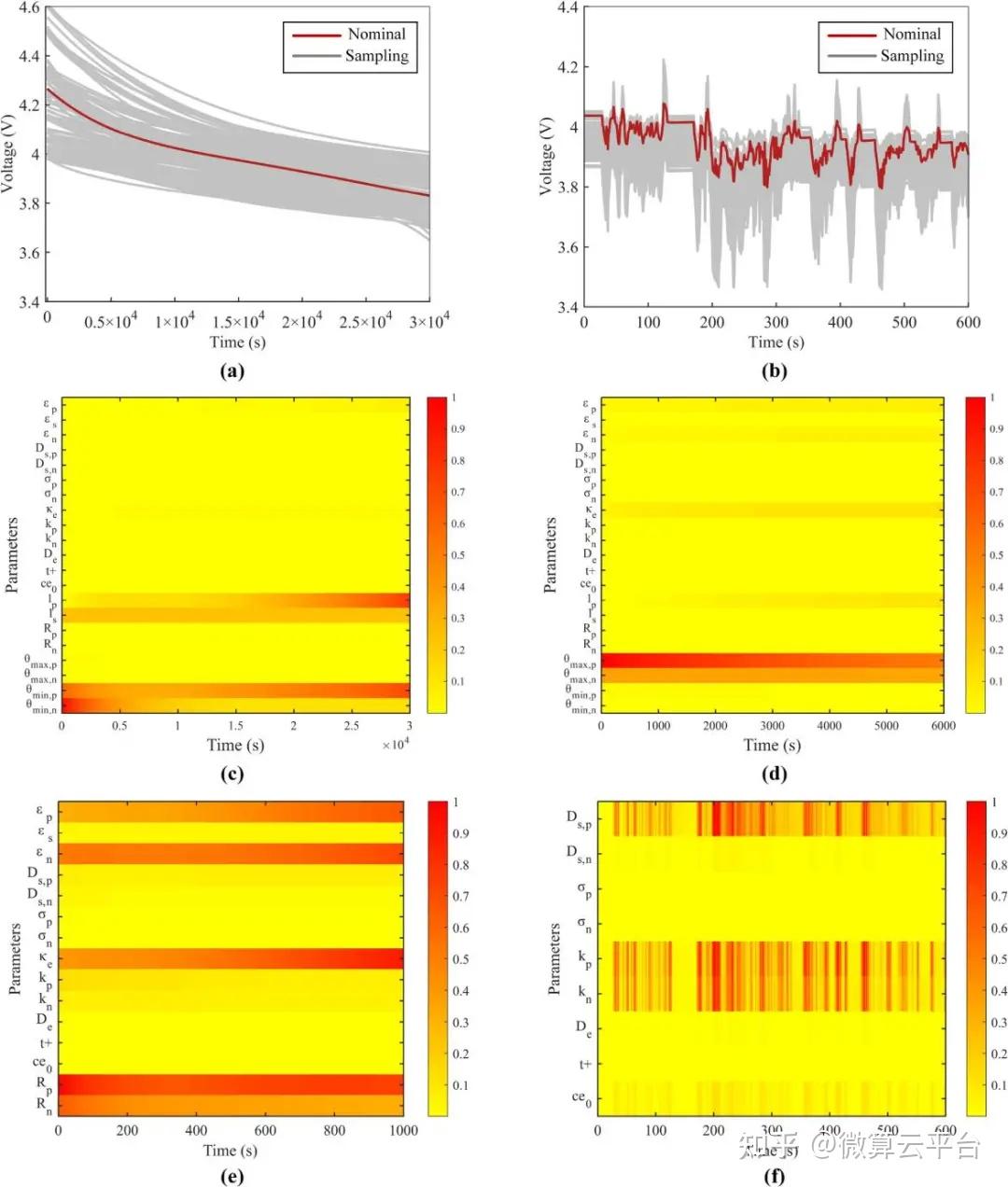
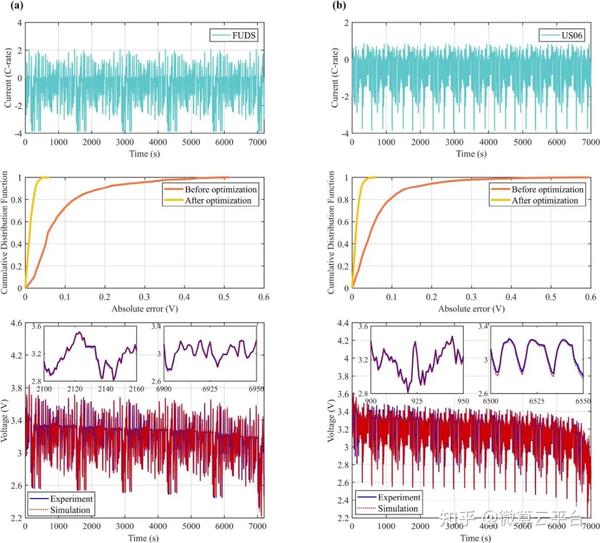
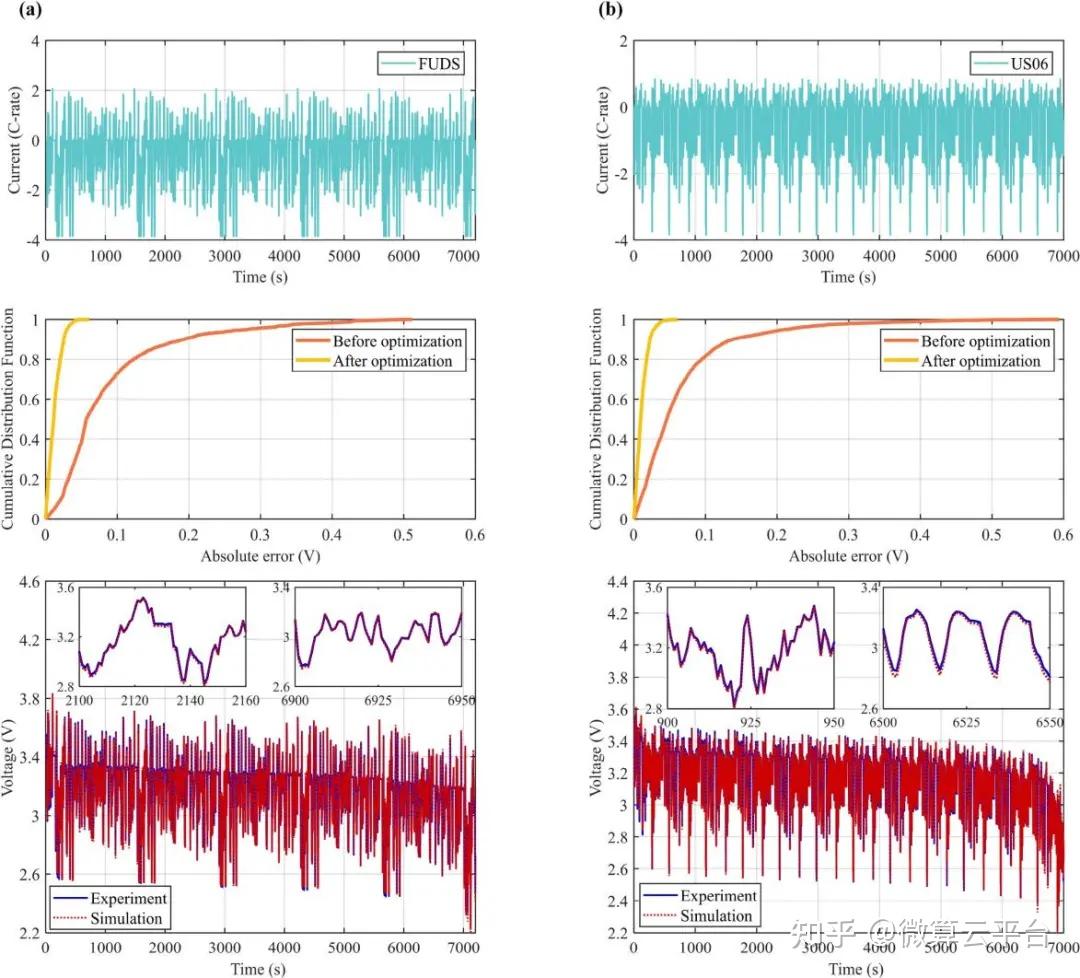
研究表明,使用模拟和实验数据可以在1小时内准确估计14个电化学参数。根据仿真结果,这14个参数都可以准确估计,大部分相对误差小于15%。使用估计值作为 P2D 模型参数,输出电压和内部状态都与参考值很好地匹配。在实验验证部分,使用两种常用的电动汽车动态测试条件验证参数识别的准确性。在估计P2D模型参数后,模型预测电压的均方根误差低于14 mV,进一步证明了所提方法的准确性。因此,这项研究为P2D模型的无损参数识别提供了一个通用框架,研究人员可以对他们的电池进行无损识别过程,凭借准确可靠的参数值,P2D模型可以成为电池设计和管理的强大工具。
Enabling high-fidelity electrochemical P2D modeling of lithium-ion batteries via fast and non-destructive parameter identification, Energy Storage Materials 2021. DOI: 10.1016/j.ensm.2021.12.044
3. 吉大&浙大Small Methods: 组合机器学习模型用于细胞的无标记和原位识别


活体和共培养系统中的细胞识别和计数在细胞相互作用研究中至关重要,但目前的方法主要依赖于复杂且耗时的染色技术。
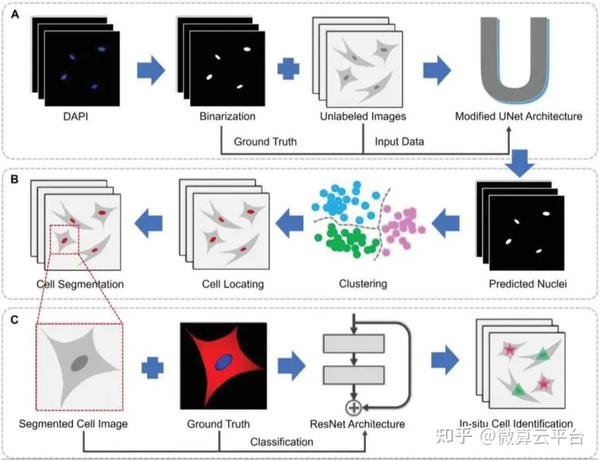
在此, 浙江大学计剑教授及吉林大学田圃教授 等人提出了一种无标记的原位方法,该方法具有一种新的思路,可以自动标记明场图像中的每个细胞。该方法基于包含卷积神经网络(CNN)模型和聚类算法的组合机器学习设计,可以实现对共培养细胞的识别、发现和即时计数。具体而言,CNN模型首先用于基于未标记的相位对比图像生成细胞核的虚拟图像,然后使用两种聚类算法根据虚拟核图像返回所有细胞的坐标。最后,基于坐标裁剪单个细胞的相位对比图像,并将其发送到另一个CNN模型以进行细胞类型识别。
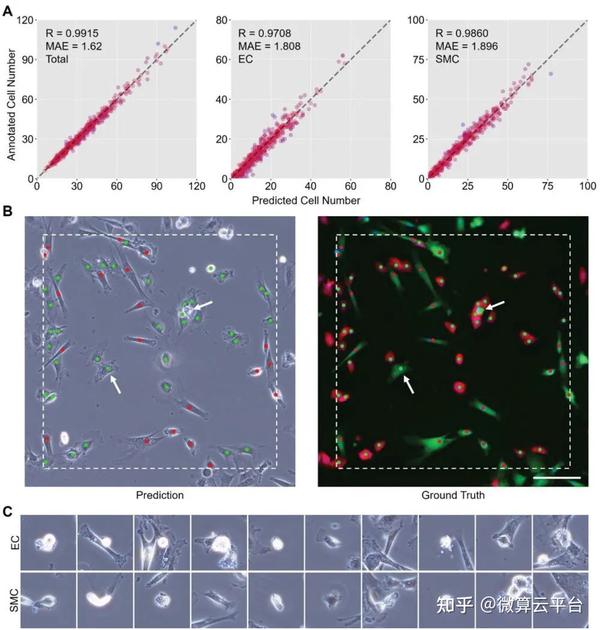
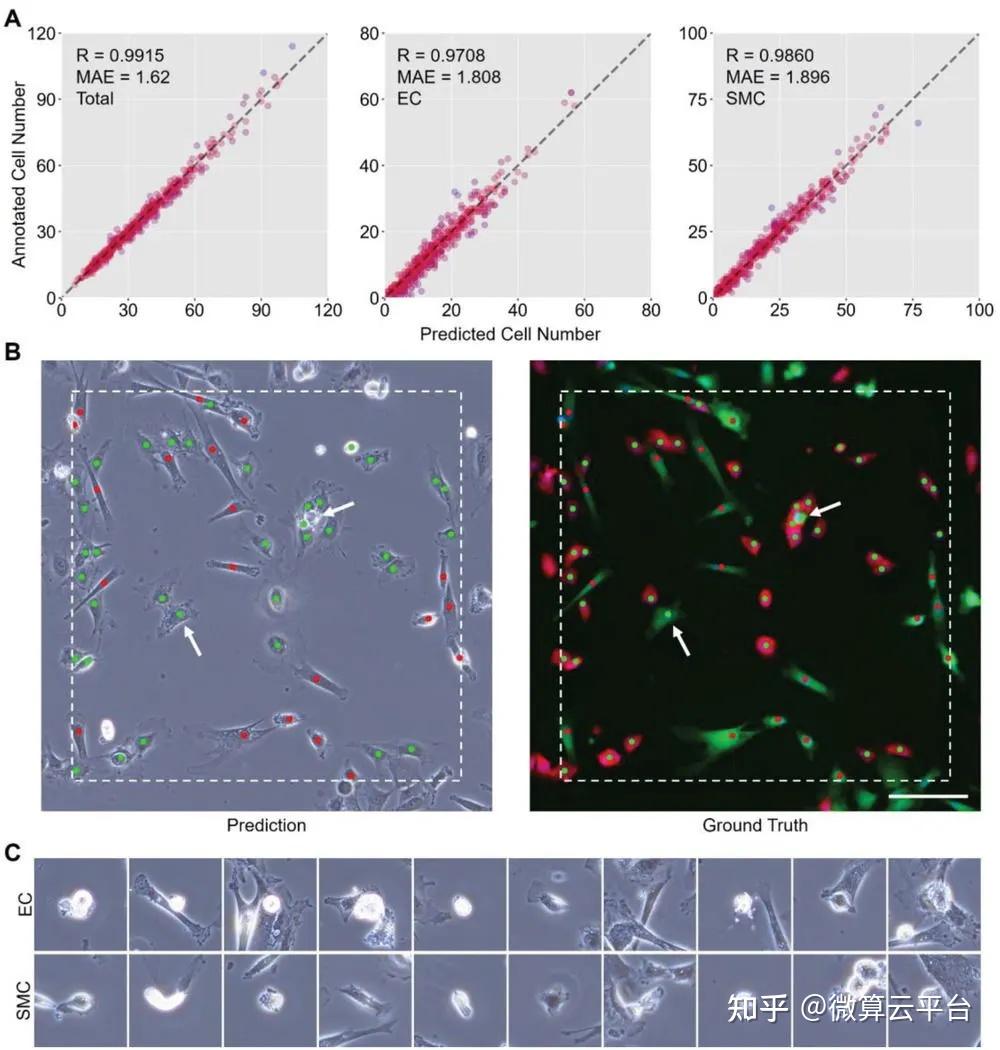
基于CNN的主要优点之一是模型结构的灵活性。虽然这里使用的图像来自包含两种细胞类型的共培养实验,但这种方法也可以通过模型的简单修改应用于许多其他研究。通过省略最后的分类步骤或在分类模型的输出层添加节点,可以实现对一种或两种以上类型细胞的无标签和实时跟踪。通过用降维算法替换ResNet 架构的最后几层,也可以对新的细胞表型或状态进行无监督探索。总之,这种组合方法是高度自动化和高效的,这在训练阶段几乎不需要手动注释图像。它在不同的细胞培养条件下显示出实用的性能,包括细胞比例、密度和底物材料,在实时细胞跟踪和分析方面具有巨大潜力。
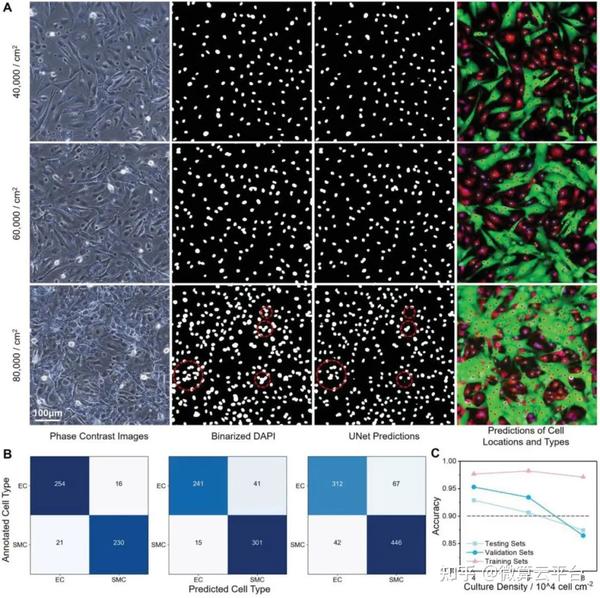
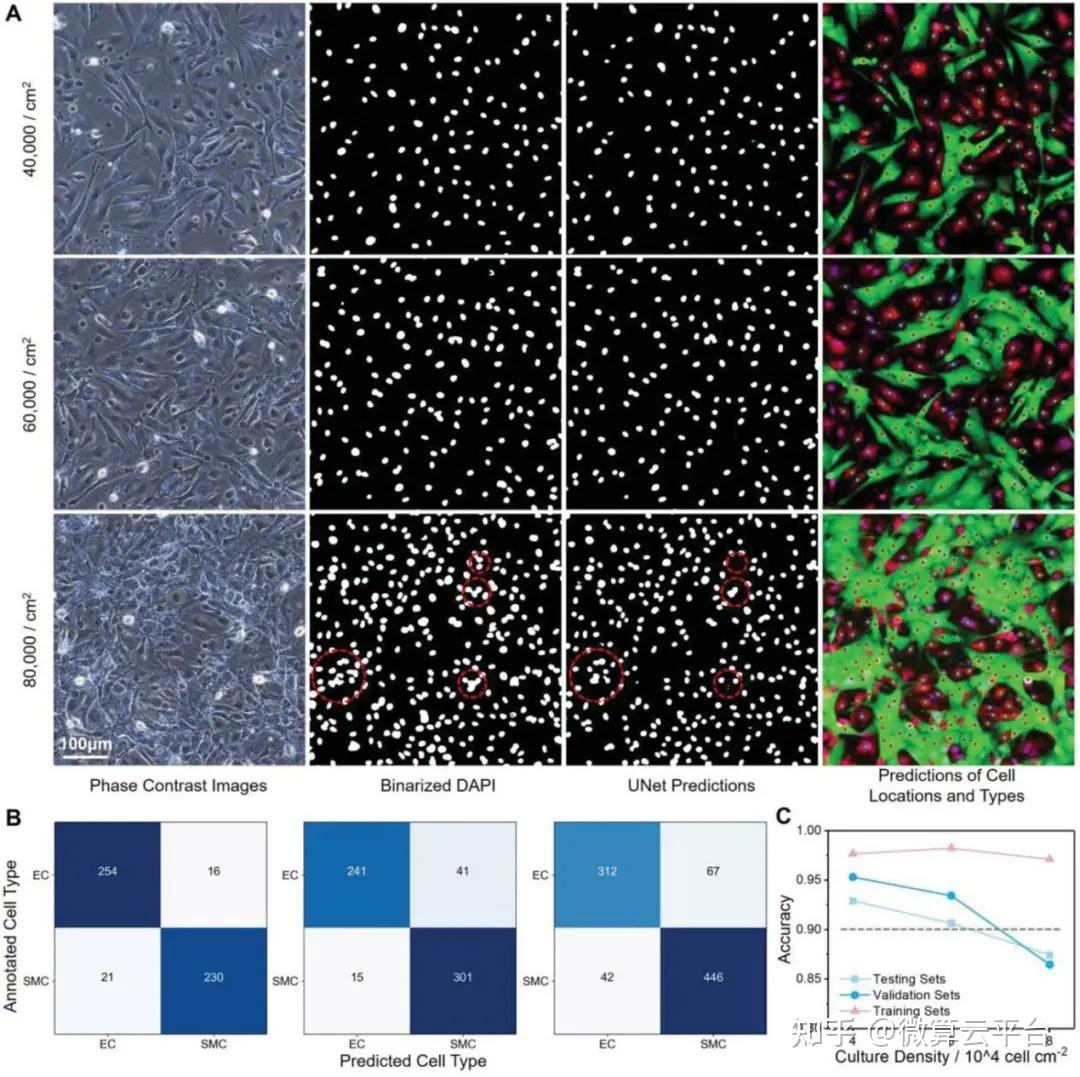
Label-Free and In Situ Identification of Cells via Combinational Machine Learning Models, Small Methods 2021. DOI: 10.1002/smtd.202101405
4. 纽约州立大学ACS AMI: 机器学习预测甲基铵锡基钙钛矿中的最佳Br掺杂


作为卤化铅钙钛矿潜在替代者的有机-无机卤化锡钙钛矿家族(MASnX3,其中X = Cl、Br、I)由于其带隙可调性,可通过用溴化学取代碘来覆盖广泛的可见太阳光谱。尽管这些钙钛矿太阳能电池具有巨大的潜力,但其稳定性一直是一个值得关注的领域。
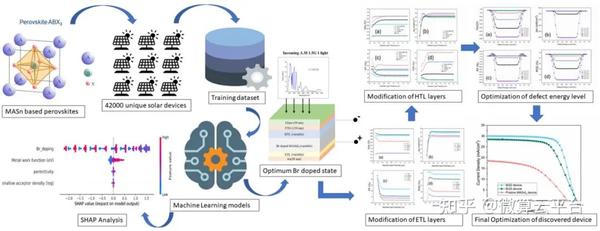
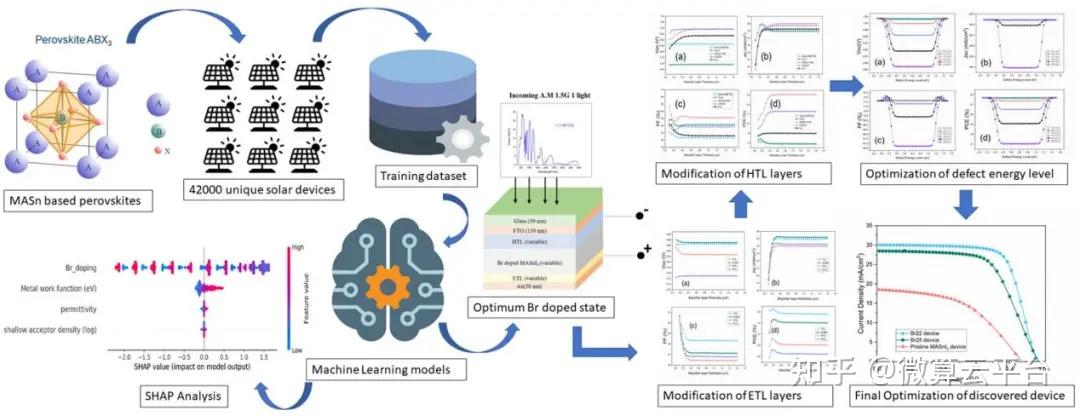
在此, 美国纽约州立大学Saquib Ahmed 等人基于监督机器学习(ML)准确预测单结MASnI3-xBrx器件中的最佳Br掺杂浓度,在使用太阳能电池电容模拟器 (SCAPS)构建的42000个独特器件上进行了数据驱动的优化。通过改变Br掺杂百分比、带隙、电子亲和力、串联电阻、背接触金属和受体浓度来研究这些器件,这些参数是专门选择的,因为它们的可调性质和可以通过器件的简单实验制备技术进行改性。作者利用五种不同的算法(线性回归(LR)、支持向量回归 (SVR)、多层感知机(MLP)、随机森林(RF)回归和极端梯度提升(Xgboost))来研究特征工程,此外,在设备内掺杂Br之前的第一步包括对纯锡基系统MASnI3的验证研究:实现了6.71% 的功率转换效率(PCE),与实验数据非常吻合。
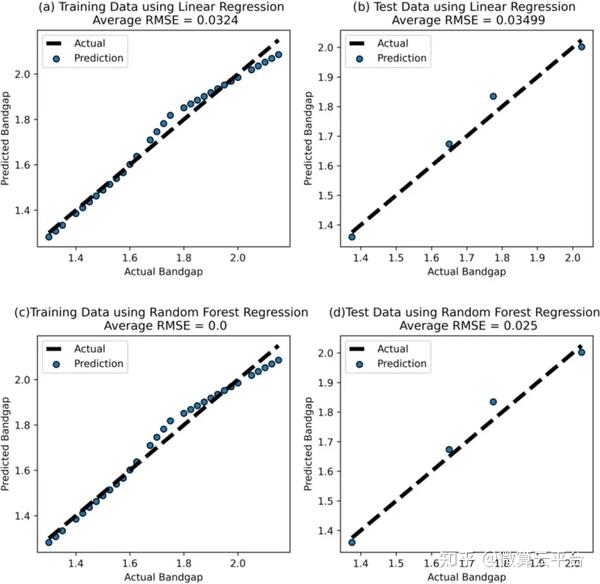
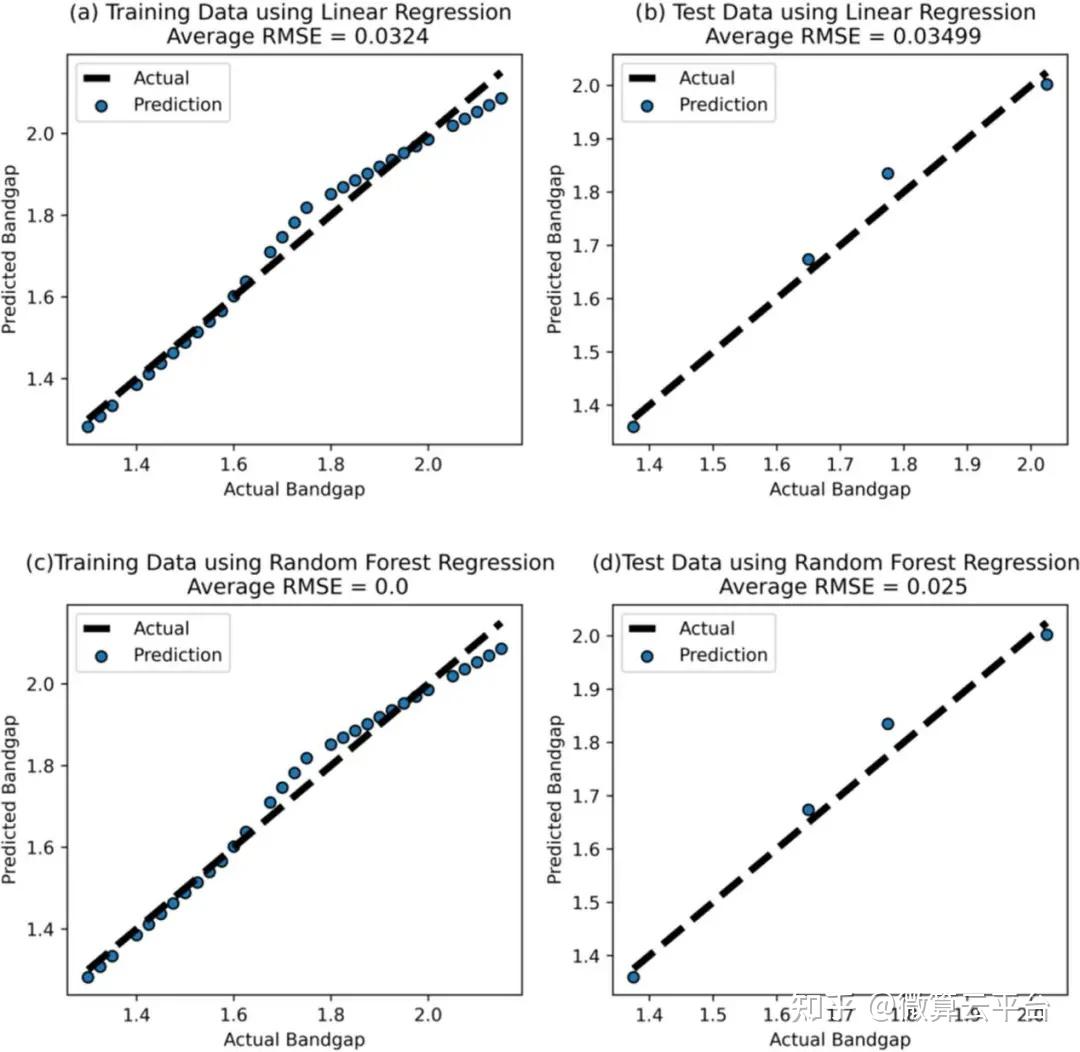
结果表明,最佳Br掺杂的ML分析导致发现了两种Br浓度分别为22.43% (Br22) 和25.63%(Br25)的器件,后者是通过更严格的分析获得的更精细的值。为了了解每个特征对PCE的总体和相对影响,作者使用SHAP方法进行分析。针对发现的两个器件,利用SCAPS进行了进一步的器件优化。作者尝试了吸收体厚度、体积和界面缺陷密度的调控及电子传输层(ETL)和空穴传输层 (HTL)材料的选择,通过载流子寿命研究分析了器件稳定性。在这些优化步骤之后,Br22和Br25的最终PCE值分别为20.72% 和17.37%。总之,当前工作的ML辅助定量分析为最佳Br掺杂锡基器件提供了极大的信心,使其被视为传统技术的可行且具有竞争力的无毒替代品。
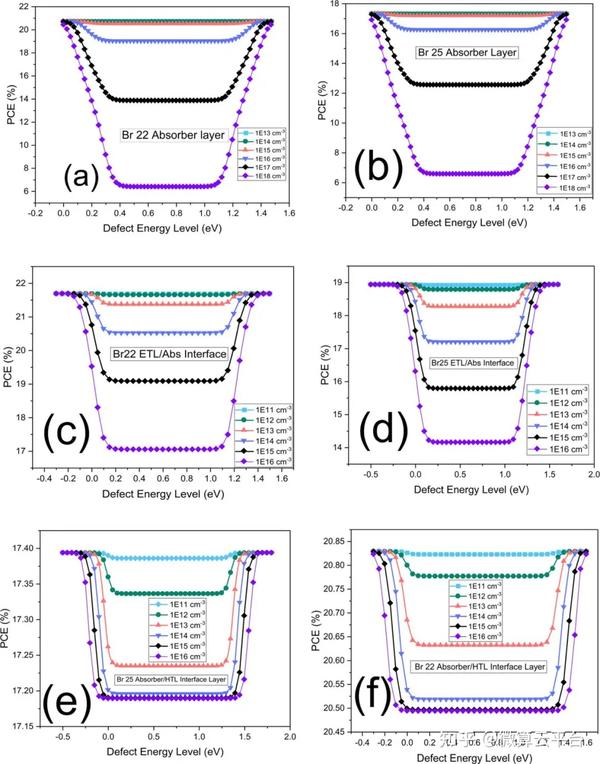
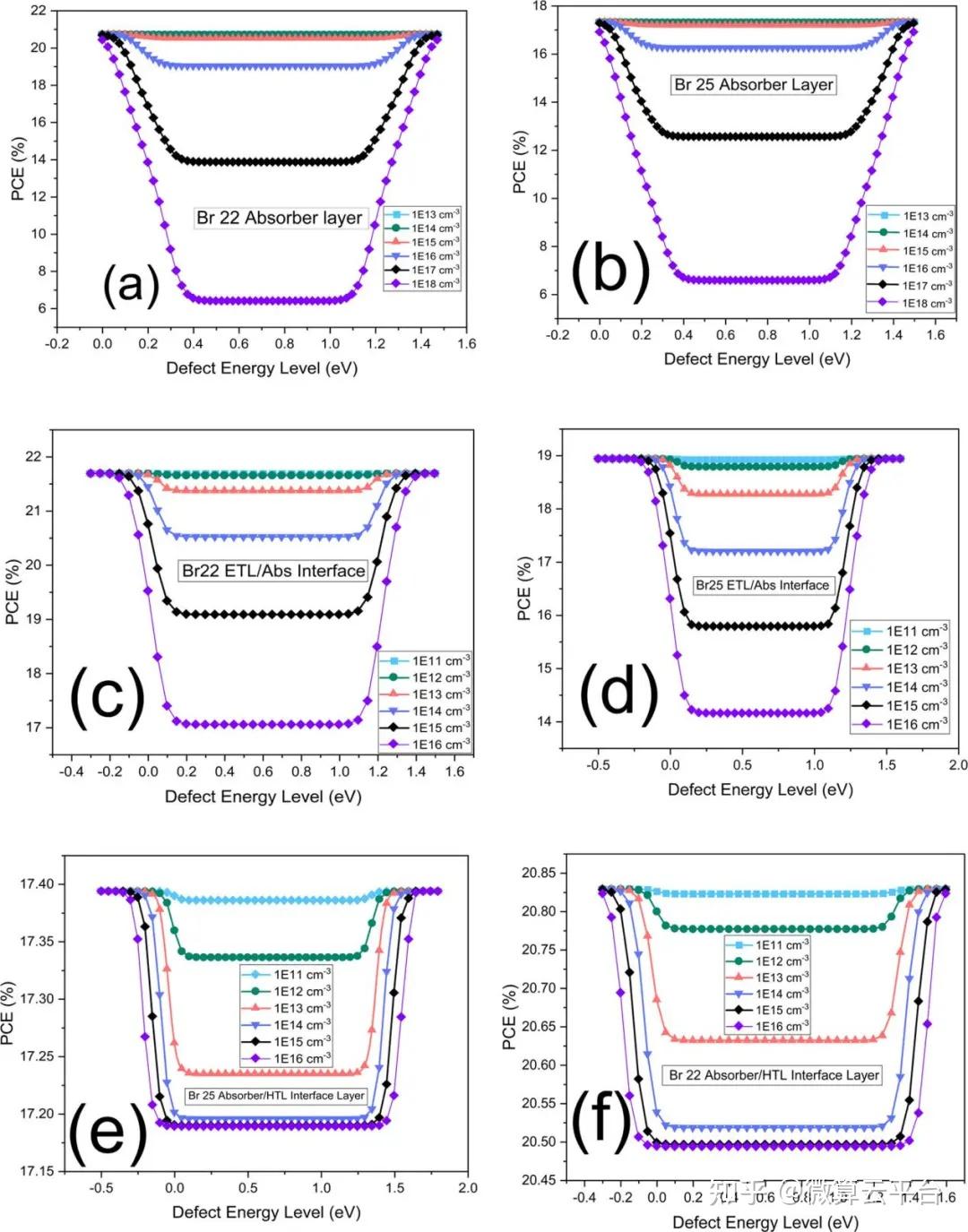
Supervised Machine Learning-Aided SCAPS-Based Quantitative Analysis for the Discovery of Optimum Bromine Doping in Methylammonium Tin-Based Perovskite (MASnI3–xBrx), ACS Applied Materials & Interfaces 2021. DOI: 10.1021/acsami.1c15030
5. 上交李金金ACS AMI: 仅需0.005秒,集成学习用于探索新型双钙钛矿!


无铅双钙钛矿(A2BB′X6)被认为是单钙钛矿的稳定和绿色光电替代品,但可能表现出间接带隙和高有效质量,从而限制了它们的最大光伏效率。此外,常规的实验试错法和高通量计算无法快速识别出理想的候选者。
在此, 上海交通大学李金金特别研究员 等人提出了一种集成学习方法,即梯度提升决策树算法(GBDT,它为特定目标集成了几个弱学习器)以快速识别合适的双钙钛矿。通过公差因子筛选,作者从元素周期表中的541695个结构中获得了23314个结构稳定性良好的双钙钛矿。为了预测这些双钙钛矿的带隙,作者从开源Materials Project 数据库中收集了1747个已知的双钙钛矿结构以及计算出的带隙(Eg)值,然后利用这个数据集建立了一个GBDT模型。通过“末位消除”特征选择和多次迭代,作者以高精度建立了三个目标类别的分类预测模型,并从 23314个潜在稳定的双钙钛矿中快速找到了6个合适的Eg值为1.0~2.0 eV的双钙钛矿。
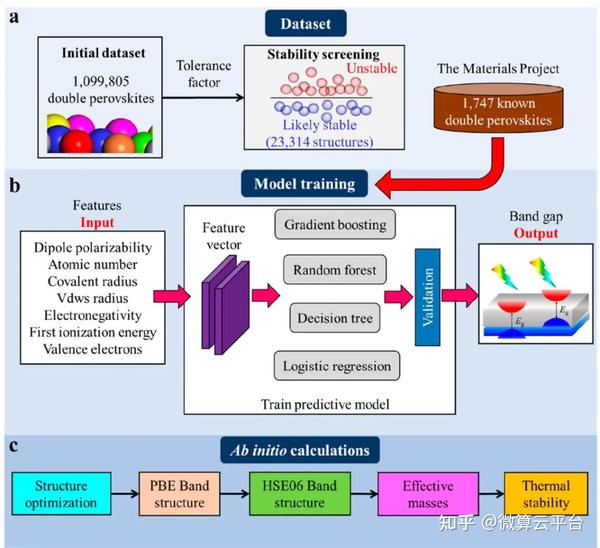
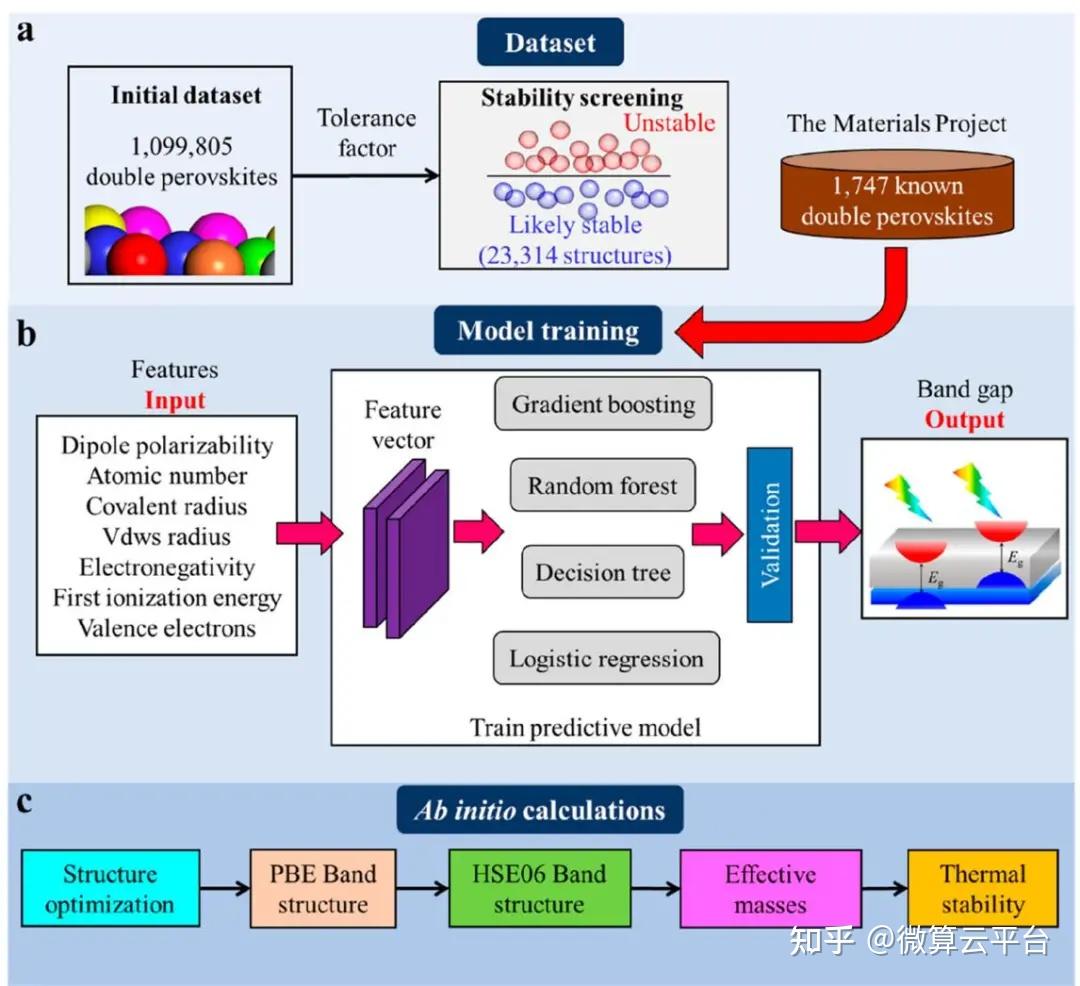
研究表明,训练有素的ML模型具有92% 的高预测精度和比DFT计算快108倍的计算速度(∼0.005秒VS 8019.13秒)。最终,作者选择了两种具有直接带隙和低有效质量且具有良好热稳定性的双钙钛矿(Cs2TlPBr6和Cs2AgIrBr6)。对于其他具有间接Eg或高有效质量的双钙钛矿,适当的带隙值也可以提供高载流子传输并具有优异的光电性能。总之,与传统的高通量第一性原理计算相比,这项研究所提出的集成学习方法极大地缩短了双钙钛矿的筛选周期,极大地促进了光伏器件的发展和应用。
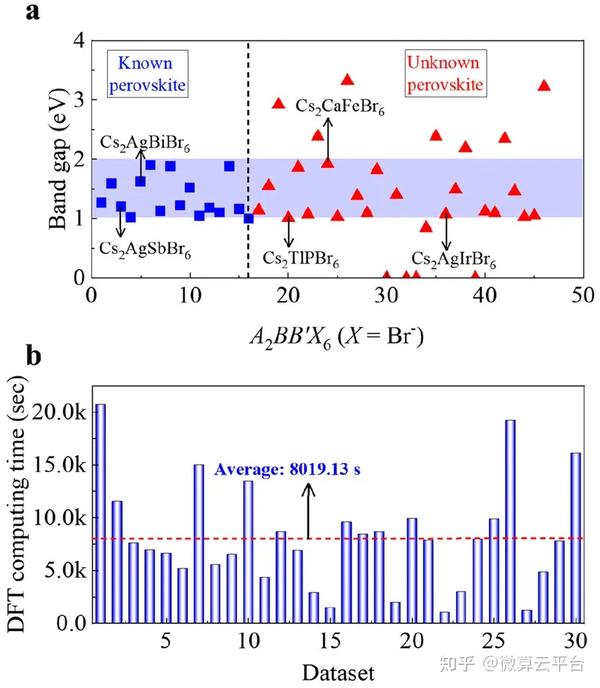
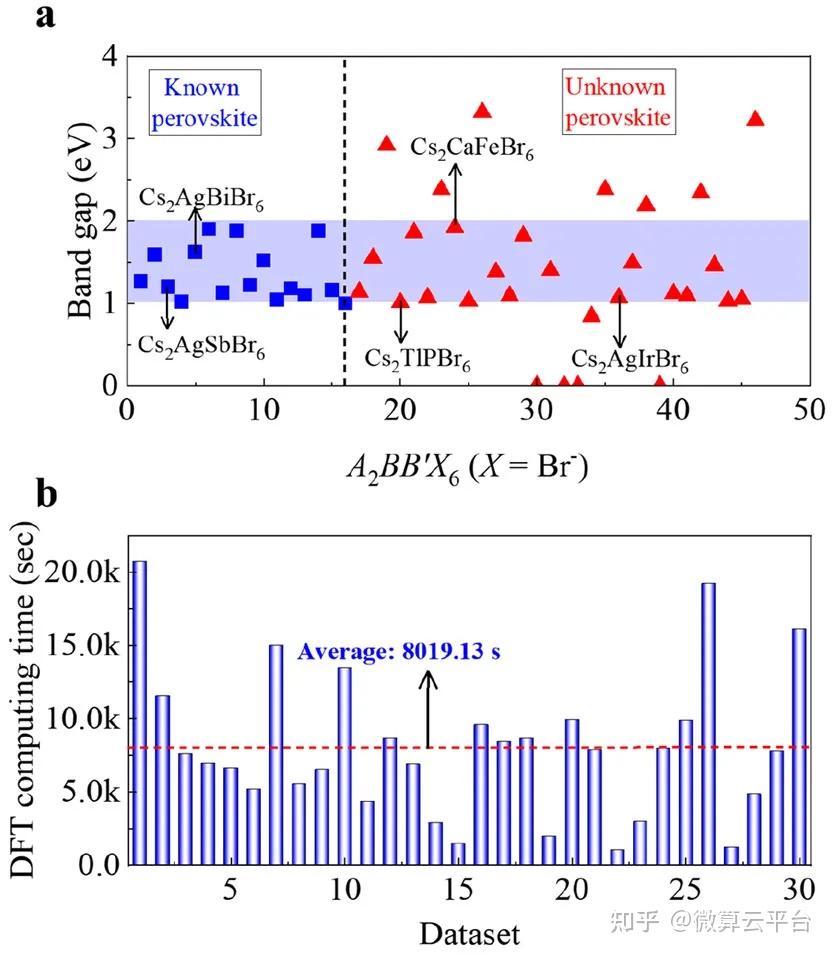
An Ensemble Learning Platform for the Large-Scale Exploration of New Double Perovskites, ACS Applied Materials & Interfaces 2021. DOI: 10.1021/acsami.1c18477
6. 佐治亚理工陈勇生教授ES&T: 基于机器学习-贝叶斯优化革新膜设计


聚合物膜设计是一个多维过程,涉及从无限的候选空间中选择膜材料和优化制造条件,而通过反复试验来探索整个空间是不可能的。机器学习(ML)算法可以管理复杂的多维数据集,具有强大的拟合能力,在膜科学界越来越受到关注。
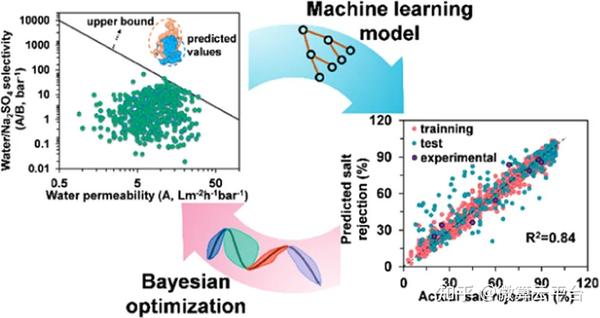
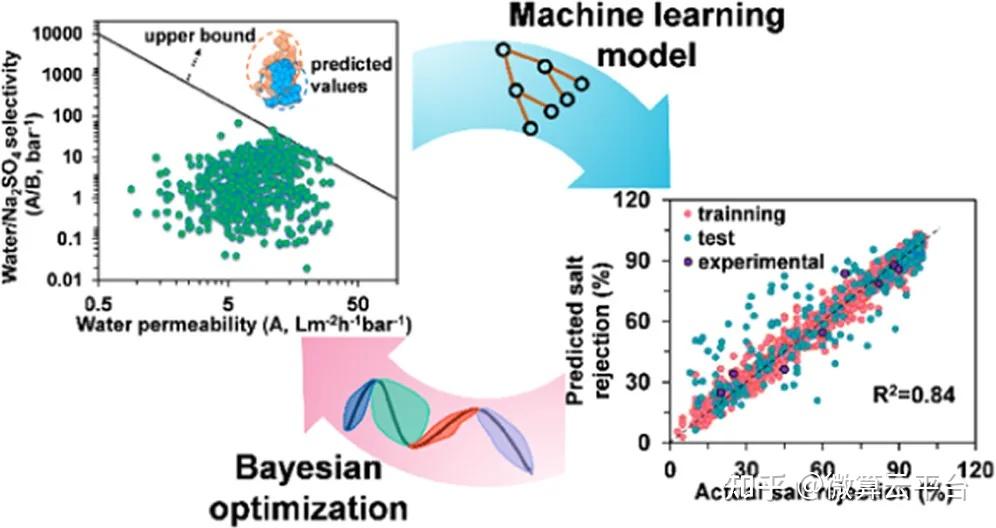
在此, 美国佐治亚理工学院陈勇生教授 等人提出了一种膜设计策略,利用基于机器学习的贝叶斯优化来从无限空间中精确识别未探索单体的最佳组合及其制造条件。作者构建了两个数据集:透水性(A)和脱盐率(R),A数据集有567个数据点,R数据集有1524个数据点。接下来,作者使用了两种基于树的ML算法作为候选:(1)XGBoost和(2)CatBoost,它们都能够处理缺失值。根据从ML模型解释中选择的原子组构建参考摩根指纹,从而快速筛选未开发的材料。此后,对成熟的ML模型进行贝叶斯优化来反向识别单体/制造条件组合的集合,这些组合有可能打破水/盐选择性和渗透性的上限。作者在确定的组合下制造了8种膜,发现它们超过了目前的上限。因此,基于ML的贝叶斯优化代表了下一代分离膜设计的范式转变。
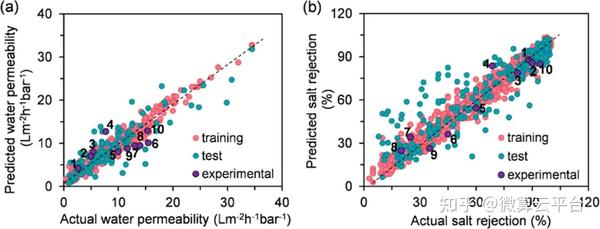
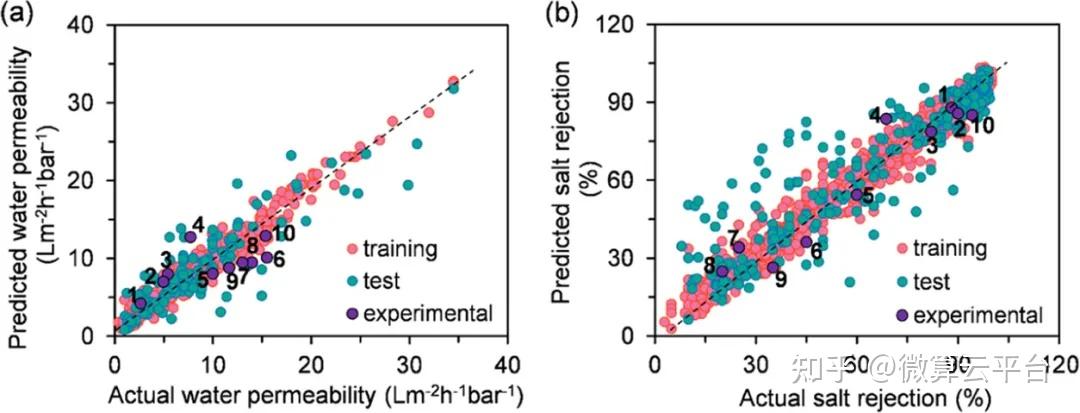
在这项工作中,作者主要关注平板膜。因此,开发的模型不能直接应用于中空纤维膜。然而,由于ML模型的预测性能在很大程度上取决于数据集的可用性、准确性和大小,随着与这些应用相关的更多研究的发表,本文中展示的策略可以很容易地扩展以开发适当的模型,并为这些新兴应用设计不同类型的膜提供指导。此外,分子动力学(MD)已广泛用于在原子水平上探索膜结构内溶质传输的研究。构建膜配置和基于MD的模拟可以增强目前有限的膜性能数据可用性,通过协同MD-ML方法阐明水和溶质通过分离膜运输的潜在分子机制仍然是未来研究的一个开放挑战。
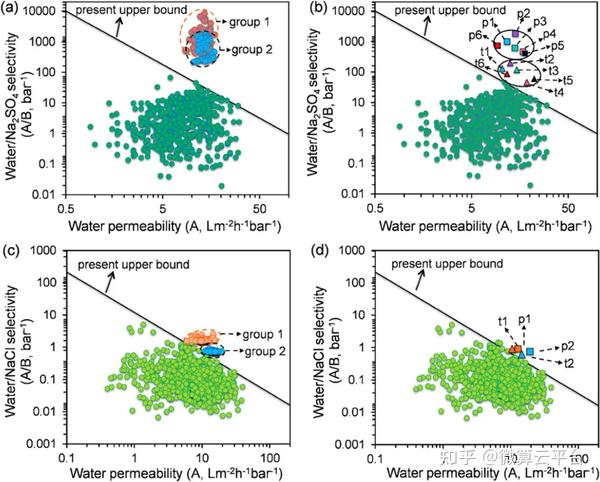
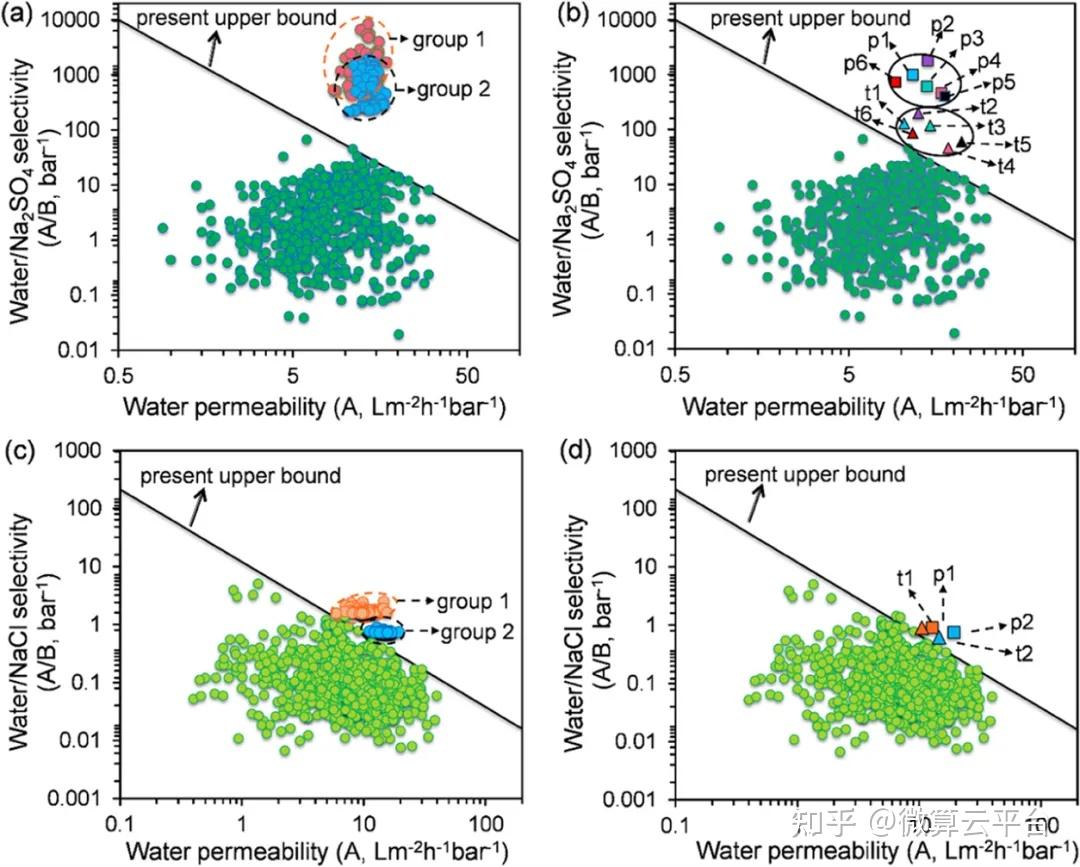
Revolutionizing Membrane Design Using Machine Learning-Bayesian Optimization, Environmental Science & Technology 2021. DOI: 10.1021/acs.est.1c04373
