ggbarplot(ToothGrowth, x = "dose", y = "len", add = "mean_se",
color = "supp", palette = "jco",
position = position_dodge(0.8))+
stat_compare_means(aes(group = supp), label = "p.signif", label.y = 29)
ggline(ToothGrowth, x = "dose", y = "len", add = "mean_se",
color = "supp", palette = "jco")+
stat_compare_means(aes(group = supp), label = "p.signif",
label.y = c(16, 25, 29))
注意:经过实际测试,笔者发现R语言中的统计方法计算结果的P值与SPSS中的P值存在差异。如,常规的方差分析(ANOVA) + 事后两两组间比较(如Bonferroni校正)使用上述R函数就很难得出与SPSS中一致的结果。如果需要使用SPSS的统计P值,建议对生成的图形进行后期修改。
References
原文链接:Add P-values and Significance Levels to ggplots
原文链接:http://www.sthda.com/english/articles/24-ggpubr-publication-ready-plots/76-add-p-values-and-significance-levels-to-ggplots/
p <- iris %>%
ggplot(aes(Species, Sepal.Length)) +
geom_violin(aes(fill = Species),trim = F) +
stat_boxplot(geom = 'errorbar', width = 0.1) +
我们的回答是你需要提取相关组的表达量,进行检验后再用ggplot函数添加即可;或者直接提取数据用ggplot作图那么显著添加也就不成问题了。时隔3月,我们这里提供 了一种函数,可以进行基因在两组之间的显著性分析。同时可进行批量的基因分析。这就是所有内容了,其实这样检验你用不用得到倒是其次,主要是这里面包含一些小的细节知识点,学会了就能和其他内容融汇贯通了,自己感悟吧!更多精彩内容请至KS科研分享与服务公众号。显著性检验函数,有点长,可自行保存成R文件,然后每次使用的时候source一下就可以了。
“ggplot2中的次级坐标轴”生活科学哥-R语言科学 2020-06-12 8:35在平时作图中,我们有时希望在一个坐标中进行二个坐标轴的设定,也是为了方便数据的显示。这个过程在EXCEL等当中比较容易实现,但是,如何在R中实现呢?今天我们就来讲一讲操作的过程。数据准备先准备如下数据:library(ggplot2)library(scales)library(magrittr)...
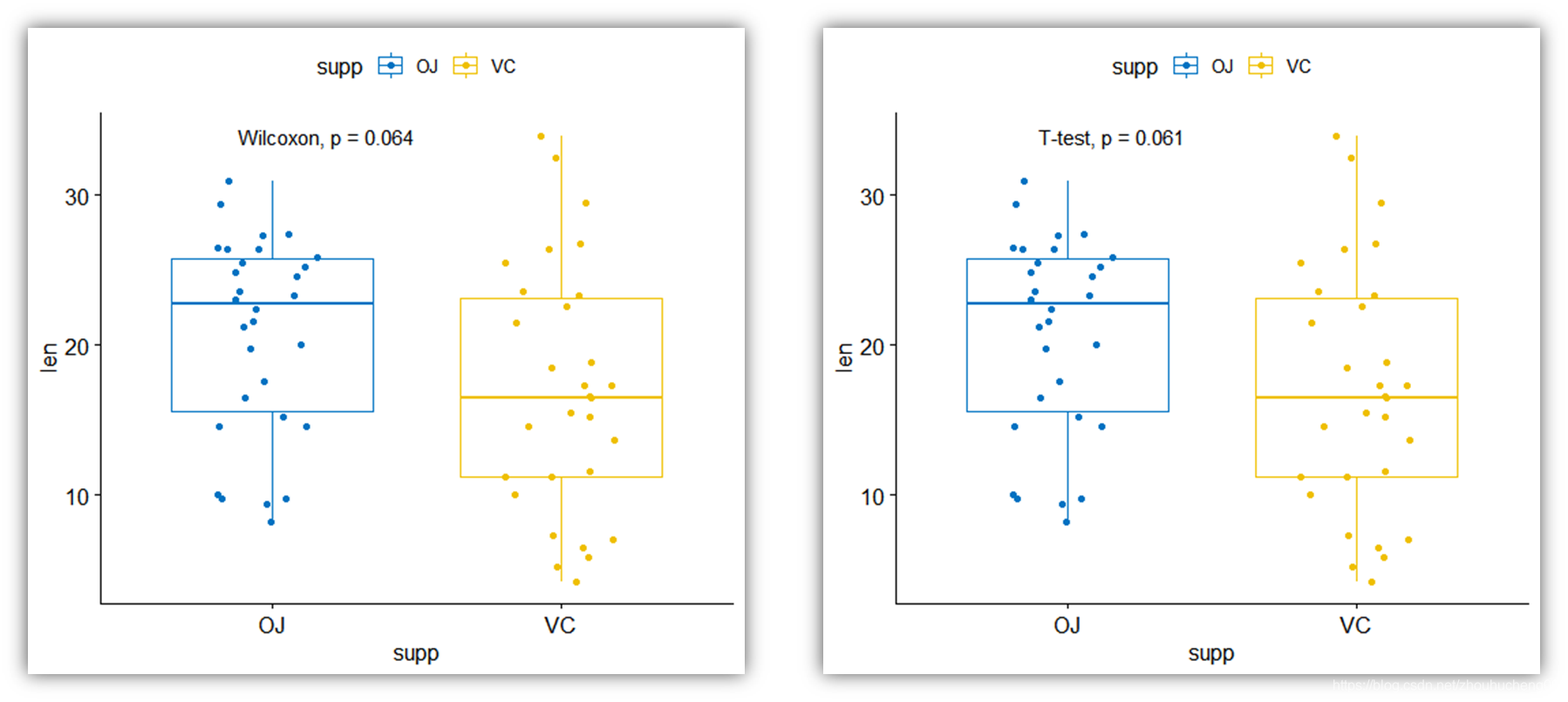
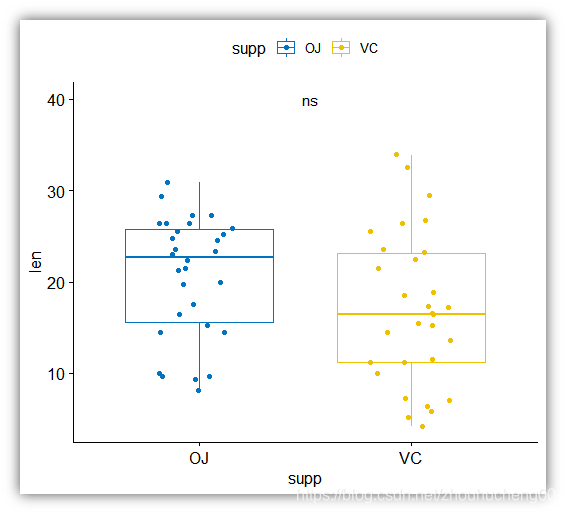
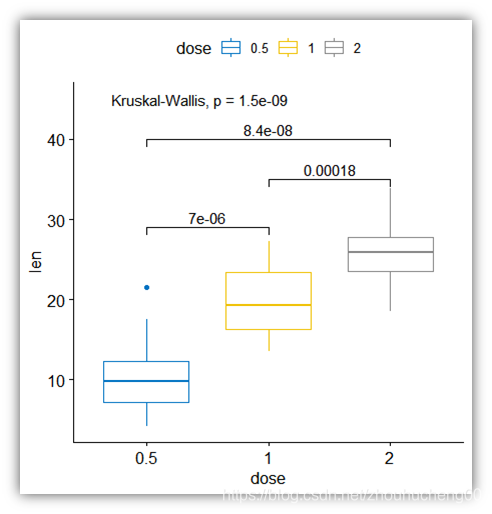
它包含一项评估维生素C对豚鼠牙齿生长的影响的研究数据。
实验在60只豚鼠上进行,其中每只豚鼠通过两种递送方法(橙汁,OJ,或抗坏血酸,VC)分别接受三种剂量水平的维生素C量(0.5、1和2 mg /天, VC)。
上图这样的单细胞StackedVlnPlot在高分文章中出现比较多,比较适合美观的展示多个marker gene的表达分布,而目前Seurat画小提琴图的函数VlnPlot是不能实现这样堆叠效果的。我们在《Seurat结果转为scanpy可处理对象》中介绍过scanpy中的sc.pl.stacked_violin函数可以实现StackedVlnPlot的功能:我们在《生信工程师的自我修养...
data <- data.frame(
individual=paste( "Mister ", seq(1,60), sep=""),
group=c( rep('A', 10), rep('B', 30), rep('C', 14), rep('D', 6)) ,
value1=sample( seq(
这是一个库和一对命令行程序,用于计算p值和临界值,以测试小数单位根和协整。
该程序是基于James G. MacKinnon和MortenØrregaardNielsen,“分数单位根和协整检验的数值分布函数”,《应用计量经济学》 ,第1卷,第1期中的描述进行建模的。 2014年1月29日,第161-171页。 编译此软件时,会自动下载与该论文相关的数据档案库中的数据 。
该程序由两个命令行二进制文件组成: fdpval和fdcrit 。 前者计算测试统计的p值,后者根据p值计算关键的测试统计值。 在不带参数的情况下运行每个程序会提供程序的使用信息。
可从获得该库的最新版本的源代码。
Debian,Ubuntu和其他Debian衍生Linux发行版
二进制版本可从。 通过在/etc/apt/sources.list中添加以下行之一,可以获得包含Debian衍生发行版
该函数中n阶循环是指可能你的数据集存在多种处理,也就是说存在不同处理变量间组合成新的子数据集。该函数的输出结果返回一个数据框,包含不同处理及bootstrap重采样的模型斜率的结果,最后可以利用统计学检验不同处理变量间的显著性差异。第一,可以实现不同类型模型的斜率比较;第二,可以解决不同变量处理间的多阶循环。主要参数的介绍data : 数据集R : bootstrap的次数sub : 需要对哪些变量进行划分成子数据集的循环equa : 对应构建模型的fomula。