


TigerGraph GSQL 入门
准备
请申请和下载TigerGraph终身免费开发者版本 Developer Edition
建议加入官方论坛 https:// groups.google.com/a/ope ngsql.org/forum/?hl=en#!forum/gsql-users
下载安装后,一个小时轻松搞定大图数据。
在本教程中,我们将向您展示如何创建图模式、在图中加载数据、编写简单的参数化查询以及运行查询。在开始之前,您需要安装TigerGraph系统,验证它正在工作,并清除以前的任何数据。这也有助于熟悉我们的图术语。
图是什么?
图是数据实体的集合和它们之间的连接。也就是说,它是一个数据实体的网络。
许多人把数据实体称为节点;在泰格图,我们称它为顶点。复数是顶点。我们称连接为边。顶点和边都可以有属性或属性。下图是一个包含7个顶点(以圆圈表示)和7条边(以直线表示)的图的可视化表示。
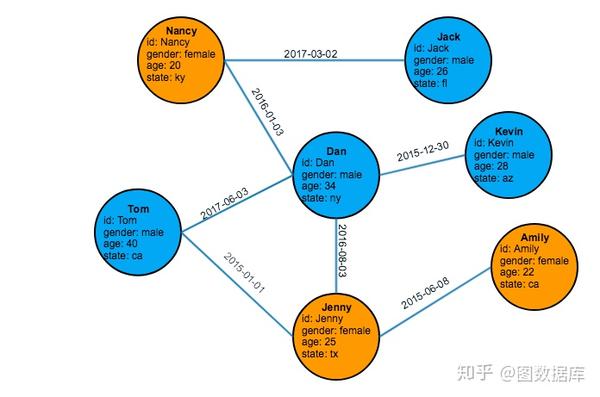

图1 友谊社交图
图模式是描述可以出现在图中的顶点(节点)和边(连接)类型的模型。上面的图有一种顶点(person)和一种边(friendship)。
模式图看起来像一个小图,除了每个节点代表一种顶点类型,每个链接代表一种边类型.
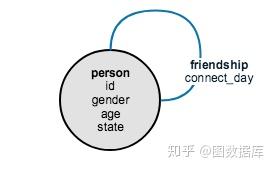
图2 友谊社交图模式
友谊的循环表明友谊是人与人之间的关系。
数据集
对于本教程,我们将创建并查询如图1所示的简单友谊社交图。此图的数据由csv(逗号分隔值)格式的两个文件组成。要继续学习本教程,请保存这两个文件,person.csv和freindship.csv,到你的TigerGraph本地磁盘。在我们的运行示例中,我们使用/home/tigergraph/文件夹来存储两个csv文件。
person.csv
name,gender,age,state
Tom,male,40,ca
Dan,male,34,ny
Jenny,female,25,tx
Kevin,male,28,az
Amily,female,22,ca
Nancy,female,20,ky
Jack,male,26,flfriendship.csv
person1,person2,date
Tom,Dan,2017-06-03
Tom,Jenny,2015-01-01
Dan,Jenny,2016-08-03
Jenny,Amily,2015-06-08
Dan,Nancy,2016-01-03
Nancy,Jack,2017-03-02
Dan,Kevin,2015-12-30准备TigerGraph环境
首先,让我们检查一下您是否可以访问GSQL。
- 打开一个Linux shell。
- 下面类型的空间。GSQL shell提示符应该如下所示。
#Linux shell
$ gsql
GSQL >如果GSQL shell没有启动,请尝试使用“gadmin restart all”重新设置系统。如果您需要进一步的帮助,请参阅泰格图知识库和常见问题。
如果这是您第一次使用GSQL,那么TigerGraph数据存储可能是空的。但是,如果您或其他人已经在系统上工作,那么可能已经有一个数据库了。您可以使用“ls”命令列出数据库目录来进行检查。如果它是空的,应该是这样:
#GSQL shell - an empty database catalog
GSQL > ls
---- Global vertices, edges, and all graphs
Vertex Types:
Edge Types:
Graphs:
Jobs:
Json API version: v2如果数据目录不是空的,您将需要清空它以启动本教程。我们假定你得到了你同事的许可。使用命令DROP ALL删除所有数据库数据、它的模式和所有相关的定义。这个命令运行大约需要一分钟。
#GSQL shell - DROP ALL
GSQL > drop all
Dropping all, about 1 minute ...
Abort all active loading jobs
[ABORT_SUCCESS] No active Loading Job to abort.
Shutdown restpp gse gpe ...
Graph store /usr/local/tigergraph/gstore/0/ has been cleared!
Everything is dropped.重新启动TigerGraph
如果由于任何原因需要重新启动TigerGraph,请使用以下命令序列:
#Linux shell - Restarting TigerGraph services
# Switch to the user account set up during installation
# The default is user=tigergraph, password=tigergraph
$ su tigergraph
Password:tigergraph
# Start all services
$ gadmin restart -fy提示:运行来自Linux的GSQL命令
您还可以从Linux shell中运行GSQL命令。要运行单个命令,只需使用“gsql”,后面跟着用单引号括起来的命令行。(如果没有解析歧义,则不需要引号;使用它们更安全。例如
#Linux shell - GSQL commands from a Linux shell
# "-g graphname" is need for a given graph
gsql -g social 'ls'
gsql 'drop all'
gsql 'ls'您还可以执行您在文件中存储的一系列命令,只需按文件的名称调用“gsql”。
完成之后,可以使用“quit”命令(不带引号)退出GSQL shell。
定义一个模式
对于本教程,我们将主要在GSQL shell中以交互模式工作。一些命令将来自Linux shell。创建GSQL图的第一步是定义它的模式。GSQL提供了一组DDL(数据定义语言)命令,类似于SQL DLL命令,用于建模顶点类型、边缘类型和图形。
创建一个顶点类型、
使用CREATE VERTEX命令定义一个名为person的顶点类型。这里,PRIMARY_ID是必需的:每个人都必须有一个唯一的标识符。其余部分是描述每个人顶点的可选属性列表,格式为attribute_name data_type, attribute_name data_type, ...
#GSQL command
CREATE VERTEX person (PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING)我们在所有的大写中显示GSQL关键字以突出显示它们,但是它们是不区分大小写的。\
GSQL将确认顶点类型的创建。
#GSQL shell
GSQL > CREATE VERTEX person (PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING)
The vertex type person is created.
GSQL >您可以创建任意多的顶点类型。
创建一个边类型
接下来,使用CREATE…EDGE命令创建一个名为friendship的EDGE类型。无定向的关键字表示这条边是双向边,这意味着信息可以从两个顶点开始流。如果您希望有一个单向连接,其中信息只从顶点流动,那么使用有向关键字代替无向关键字。这里,FROM和TO被要求指定边缘类型连接的两个顶点类型。一个单独的边通过给出它的源(从)顶点和目标(到)顶点的primary_id来指定。这些属性后面是可选的属性列表,就像顶点定义一样。
#GSQL command
CREATE UNDIRECTED EDGE friendship (FROM person, TO person, connect_day DATETIME)GSQL将确认边类型的创建。
#GSQL shell
GSQL > CREATE UNDIRECTED EDGE friendship (FROM person, TO person, connect_day DATETIME)
The edge type friendship is created.
GSQL >您可以创建尽可能多的边类型。
创建一个图
接下来,使用CREATE GRAPH命令创建一个名为social的图。这里,我们列出了我们想要在这个图中包含的顶点类型和边类型。
#GSQL command
CREATE GRAPH social (person, friendship)GSQL将在几秒钟后确认第一个图的创建,在此期间,它将目录信息推送给所有服务,如GSE、GPE和RESTPP。
#GSQL shell
GSQL > CREATE GRAPH social (person, friendship)
Restarting gse gpe restpp ...
Finish restarting services in 16.554 seconds!
The graph social is created.至此,我们创建了一个person顶点类型、一个friendship边类型和一个包含它们的社交图。现在您已经构建了您的第一个图模式!让我们通过在GSQL shell中输入“ls”命令来查看目录中的内容。
#GSQL shell
GSQL > ls
---- Global vertices, edges, and all graphs
Vertex Types:
- VERTEX person(PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING) WITH STATS="OUTDEGREE_BY_EDGETYPE"
Edge Types:
- UNDIRECTED EDGE friendship(FROM person, TO person, connect_day DATETIME)
Graphs:
- Graph social(person:v, friendship:e)
Jobs:
Json API version: v2加载数据
在创建图模式之后,下一步是将数据加载到其中。这里的任务是指导GSQL加载程序如何将一组数据文件中的字段关联到我们刚才定义的图模式的顶点类型和边类型中的属性。、
您应该有两个数据文件。person.csv和friendship.csv在本地磁盘上的csv。它们可以不在当前的文件夹中。
如果您出于任何原因需要退出GSQL shell,您可以通过输入“quit”(不带引号)来实现。输入gsql以再次进入。
定义一个数据加载的工作
下面的加载作业假设您的数据文件位于文件夹/home/tigergraph中。如果它们在其他地方,则在下面的加载作业脚本中替换“/home/tigergraph/person”。csv和“/ home / tigergraph /friendship.csv"和它们对应的文件路径。假设您(回到)GSQL shell中,输入以下命令集。
#GSQL commands to define a loading job
USE GRAPH social
BEGIN
CREATE LOADING JOB load_social FOR GRAPH social {
DEFINE FILENAME file1="/home/tigergraph/person.csv";
DEFINE FILENAME file2="/home/tigergraph/friendship.csv";
LOAD file1 TO VERTEX person VALUES ($"name", $"name", $"age", $"gender", $"state") USING header="true", separator=",";
LOAD file2 TO EDGE friendship VALUES ($0, $1, $2) USING header="true", separator=",";
END让我们来看看这些命令:
- 使用社交图:
告诉GSQL您希望使用哪个图。
- 开始……结束:
表明多行模式。GSQL shell将把这些标记之间的所有内容视为一个语句。这些只用于交互模式。如果运行存储在命令文件中的GSQL语句,命令解释器将研究整个文件,因此不需要开始和结束提示。
- 创建加载工作:
一个加载作业可以描述从多个文件到多个图对象的映射。每个文件必须分配给文件名变量。字段标签可以按名称或位置进行标记。名称标签需要源文件中的标题行。逐位标签使用整数表示源列位置0,1,…在上面的示例中,第一个LOAD语句按名称引用源文件列,而第二个LOAD语句按位置引用源文件列。请注意以下细节:
- file1中的列“name”被映射到两个字段,即PRIMARY_ID和person顶点的“name”属性。
- 在file1,性别先于年龄。在人的顶点,性别在年龄之后。在加载时,根据目标对象(在本 例中为person顶点)所需的顺序来声明属性。
- 每个LOAD语句都有一个using子句。这里它告诉GSQL,两个文件都包含一个标题行(无论我们是否选择使用名称,GSQL仍然需要知道是否将第一行作为数据)。它还指定列分隔符是逗号。GSQL可以处理任何单字符分隔符,而不仅仅是逗号。
当您运行CREATE LOADING JOB 语句时,GSQL将检查语法错误,并检查指定位置中的数据文件。如果没有检测到错误,它将编译并保存您的作业。
#GSQL shell
GSQL > USE GRAPH social
Using graph 'social'
GSQL > BEGIN
GSQL > CREATE LOADING JOB load_social FOR GRAPH social {
GSQL > DEFINE FILENAME file1="/home/tigergraph/person.csv";
GSQL > DEFINE FILENAME file2="/home/tigergraph/friendship.csv";
GSQL > LOAD file1 TO VERTEX person VALUES ($"name", $"name", $"age", $"gender", $"state") USING header="true", separator=",";
GSQL > LOAD file2 TO EDGE friendship VALUES ($0, $1, $2) USING header="true", separator=",";
GSQL > }
GSQL > END
The job load_social is created.运行一个加载的工作
现在可以运行加载作业,将数据加载到图中:
#GSQL command
RUN LOADING JOB load_social结果显示如下
#GSQL shell
GSQL > run loading job load_social
[Tip: Use "CTRL + C" to stop displaying the loading status update, then use "SHOW LOADING STATUS jobid" to track the loading progress again]
[Tip: Manage loading jobs with "ABORT/RESUME LOADING JOB jobid"]
Starting the following job, i.e.
JobName: load_social, jobid: social_m1.1528095850854
Loading log: '/home/tigergraph/tigergraph/logs/restpp/restpp_loader_logs/social/social_m1.1528095850854.log'
Job "social_m1.1528095850854" loading status
[FINISHED] m1 ( Finished: 2 / Total: 2 )
[LOADED]
+---------------------------------------------------------------------------+
| FILENAME | LOADED LINES | AVG SPEED | DURATION|
|/home/tigergraph/friendship.csv | 8 | 8 l/s | 1.00 s|
| /home/tigergraph/person.csv | 8 | 7 l/s | 1.00 s|
+---------------------------------------------------------------------------+注意加载日志文件的位置。本例假设您在默认位置/home/tigergraph/中安装了TigerGraph。在您的安装文件夹中是主要的产品文件夹,tigergraph。在tigergraph文件夹中有几个子文件夹,如日志、文档、配置、bin和gstore。如果您安装在一个不同的位置,例如/usr/local/,那么您将在/usr/local/tigergraph找到产品文件夹。
使用内置的SELECT查询进行查询
你现在有了一个有数据的图!您可以运行一些简单的内置查询来检查数据。
选择顶点
下面的GSQL命令报告person顶点的总数。person.csv数据文件标题行后有7行。
#GSQL command
SELECT count() FROM person类似地,下面的GSQL命令报告friendship边的总数。friendship.csv文件在标题行后也有7行。
#GSQL command
SELECT count() FROM person-(friendship)->person结果如下所示。
GSQL shell
GSQL > SELECT count() FROM person
"count": 7,
"v_type": "person"
GSQL > SELECT count() FROM person-(friendship)->person
"count": 14,
"e_type": "friendship"
GSQL >边数
为什么有14条边?对于无向边,GSQL实际上创建两条边,每个方向一条。
如果您想查看关于特定顶点集的详细信息,可以使用“SELECT *”和WHERE子句来指定谓词条件。以下是一些可以尝试的语句:
#GSQL command
SELECT * FROM person WHERE primary_id=="Tom"
SELECT name FROM person WHERE state=="ca"
SELECT name, age FROM person WHERE age > 30结果是JSON格式,如下所示。
#GSQL shell
GSQL > SELECT * FROM person WHERE primary_id=="Tom"
"v_id": "Tom",
"attributes": {
"gender": "male",
"name": "Tom",
"state": "ca",
"age": 40
"v_type": "person"
GSQL > SELECT name FROM person WHERE state=="ca"
"v_id": "Amily",
"attributes": {"name": "Amily"},
"v_type": "person"
"v_id": "Tom",
"attributes": {"name": "Tom"},
"v_type": "person"
GSQL > SELECT name, age FROM person WHERE age > 30
"v_id": "Tom",
"attributes": {
"name": "Tom",
"age": 40
"v_type": "person"
"v_id": "Dan",
"attributes": {
"name": "Dan",
"age": 34
"v_type": "person"
]选择边
以同样的方式,我们可以看到关于边的细节。为了描述一个边,您可以在三个部分中指定顶点和边的类型,并添加一些标点符号来表示遍历方向:
#GSQL syntax
source_type -(edge_type)-> target_type注意,无论是无向边还是有向边,总是使用箭头->。这是因为我们描述的是查询在图中的遍历(搜索)方向,而不是边本身的方向。
我们可以在WHERE子句中使用from_id谓词,从由“from_id”标识的顶点选择所有friendship边。关键字ANY表示允许任何边缘类型或任何目标顶点类型。以下两个查询的结果相同.
#GSQL command
SELECT * FROM person-(friendship)->person WHERE from_id =="Tom"
SELECT * FROM person-(ANY)->ANY WHERE from_id =="Tom"对内置边选择查询的限制
为了防止查询可能返回过多的输出项,内置边查询有以下限制:
1. 必须指定源顶点类型。
2. 必须指定from_id条件。
用户定义查询没有这样的限制。
结果如下所示。
#GSQL
GSQL > SELECT * FROM person-(friendship)->person WHERE from_id =="Tom"
"from_type": "person",
"to_type": "person",
"directed": false,
"from_id": "Tom",
"to_id": "Dan",
"attributes": {"connect_day": "2017-06-03 00:00:00"},
"e_type": "friendship"
"from_type": "person",
"to_type": "person",
"directed": false,
"from_id": "Tom",
"to_id": "Jenny",
"attributes": {"connect_day": "2015-01-01 00:00:00"},
"e_type": "friendship"
]另一种检查图大小的方法是使用管理员工具gadmin的选项之一。从Linux shell中输入命令
gadmin status graph -v
#Linux shell
[tigergraph@localhost ~]$ gadmin status graph -v
verbose is ON
=== graph ===
[m1 ][GRAPH][MSG ] Graph was loaded (/usr/local/tigergraph/gstore/0/part/): partition size is 4.00KiB, SchemaVersion: 0, VertexCount: 7, NumOfSkippedVertices: 0, NumOfDeletedVertices: 0, EdgeCount: 14
[m1 ][GRAPH][INIT] True
[INFO ][GRAPH][MSG ] Above vertex and edge counts are for internal use which show approximate topology size of the local graph partition. Use DML to get the correct graph topology information
[SUMMARY][GRAPH] graph is ready使用参数化GSQL查询进行查询
我们刚刚看到运行简单的内置查询是多么简单和快捷。然而,您无疑希望创建自定义或更复杂的查询。GSQL通过参数化的顶点集查询将最大的权力交给您。参数化查询允许您遍历从一个顶点到相邻的顶点集的图,一次又一次地执行计算过程,内置并行执行和方便的聚合操作。您甚至可以让一个查询调用另一个查询。我们从简单的学起。
写一个GSQL参数化查询有三个步骤。
- 在GSQL中定义查询。这个查询将被添加到GSQL目录中。
- 在目录中安装一个或多个查询,为每个查询生成一个REST端点。
- 运行已安装的查询,提供适当的参数,可以调用GSQL命令,也可以通过向REST端点发送HTTP请求。
一个简单的1-Hop查询
现在,让我们编写第一个GSQL查询。我们将显示作为输入参数的人的所有直接(1-hop)邻居。
#GSQL command
USE GRAPH social
CREATE QUERY hello(VERTEX<person> p) FOR GRAPH social{
Start = {p};
Result = SELECT tgt
FROM Start:s-(friendship:e) ->person:tgt;
PRINT Result;
}此查询具有一个SELECT语句。这里的SELECT语句比内置查询中的语句强大得多。在这里,您可以执行以下操作:查询开始时,通过从查询调用传入的参数p所标识的person顶点,将一个顶点集“Start”设置为“Start”。大括号告诉GSQL构造一个包含所包含项目的集合。
接下来,SELECT语句根据FROM子句中描述的模式描述了1跳遍历:
Start:s -(friendship:e)- >person:tgt
这基本上与我们用于内置select edges查询的语法相同。也就是说,我们从给定的源集(Start)中选择所有的边,这些边具有给定的边类型(friendship),并以给定的顶点类型(person)结束。我们以前没有见过的一个特性是使用“:alias”: “s”是顶点集别名,“e" 是边集别名,“tgt”是目标顶点集别名。
返回到初始子句和赋值(“Result = SELECT tgt”)。这里我们看到目标集的别名tgt。这意味着SELECT语句应该返回目标顶点集(通过SELECT查询块中的完整子句集进行过滤和处理),并将该输出集分配给名为Result的变量。
最后,我们打印出JSON格式的结果顶点集。
创建一个查询
与其在交互模式中定义查询,不如将查询存储在一个文件中,并使用@filename语法从GSQL shell中调用该文件。将上面的查询复制并粘贴到文件/home/tigergraph/hello.gsql中。然后,进入GSQL shell并使用@hello调用该文件(注意,如果您在开始gsql时没有在/home/tigergraph文件夹中,那么您可以使用绝对路径来调用gsql文件。例如 @/home/tigergraph/hello.gsql)。然后运行“ls”命令,查看新加的查询现在在目录中了。
GSQL > @hello.gsql
Using graph 'social'
The query hello has been added!
GSQL > ls
---- Graph social
Vertex Types:
- VERTEX person(PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING) WITH STATS="OUTDEGREE_BY_EDGETYPE"
Edge Types:
- UNDIRECTED EDGE friendship(from person, to person, connect_day DATETIME)
Graphs:
- Graph social(person:v, friendship:e)
Jobs:
- CREATE LOADING JOB load_social FOR GRAPH social {
DEFINE FILENAME file2 = "/home/tigergraph/friendship.csv";
DEFINE FILENAME file1 = "/home/tigergraph/person.csv";
LOAD file1 TO VERTEX person VALUES($"name", $"name", $"age", $"gender", $"state") USING SEPARATOR=",", HEADER="true", EOL="\n";
LOAD file2 TO EDGE friendship VALUES($0, $1, $2) USING SEPARATOR=",", HEADER="true", EOL="\n";
Queries:
- hello(vertex<person> p) 安装一个查询
但是,查询尚未安装;它还不能运行。在GSQL shell中,输入以下命令来安装刚刚添加的查询“hello”。
#GSQL command
INSTALL QUERY hello
#GSQL shell
GSQL > INSTALL QUERY hello
Start installing queries, about 1 minute ...
hello query: curl -X GET 'http://127.0.0.1:9000/query/social/hello?p=VALUE'. Add -H "Authorization: Bearer TOKEN" if authentication is enabled.
[========================================================================================================] 100% (1/1)数据库安装这个新查询大约需要1分钟。要有耐心!对于大型数据集上的查询,这种小的投资可以在更快的查询执行中获得多次回报,尤其是在使用不同参数多次运行查询时。安装将生成机器指令和一个REST端点。当进度条达到100%后,我们就可以运行这个查询了。
在GSQL中运行查询
要在GSQL中运行查询,请使用“run query”,后跟查询名和一组参数值。
#GSQL command - run query examples
RUN QUERY hello("Tom")结果以JSON格式显示。Tom有两个一步邻居,即Dan和Jenny。
#GSQL shell
GSQL > RUN QUERY hello("Tom")
"error": false,
"message": "",
"version": {
"schema": 0,
"api": "v2"
"results": [{"Result": [
"v_id": "Dan",
"attributes": {
"gender": "male",
"name": "Dan",
"state": "ny",
"age": 34
"v_type": "person"
"v_id": "Jenny",
"attributes": {
"gender": "female",
"name": "Jenny",
"state": "tx",
"age": 25
"v_type": "person"
}将查询作为REST端点运行
在后台,安装一个查询还会生成一个REST端点,这样就可以通过http调用来调用参数化查询。在Linux中,curl命令是提交http请求的最流行的方式。在下面的示例中,所有查询的标准部分用粗体显示;正常权重中的部分属于这个特定的查询和参数值。JSON结果将返回到Linux shell的标准输出。因此,我们的参数化查询变成了http服务!
#Linux shell
curl -X GET 'http://localhost:9000/query/social/hello?p=Tom'最后,要查看目录中查询的GSQL文本,可以使用
#GSQL command - show query example
#SHOW QUERY query_name. E.g.
SHOW QUERY hello恭喜你!至此,您已经完成了定义、安装和运行查询的整个过程。
一个更高级的查询
现在,让我们执行一个更高级的查询。这一次,我们将学习如何使用强大的内置累加器,它充当在图中遍历过程中访问的每个顶点的运行时属性。运行时意味着它们只在查询运行时存在;它们被称为累加器,因为它们是专门用来在查询的隐式并行处理过程中收集(积累)数据的。
#GSQL command file - hello2.gsql
USE GRAPH social
CREATE QUERY hello2 (VERTEX<person> p) FOR GRAPH social{
OrAccum @visited = false;
AvgAccum @@avgAge;
Start = {p};
FirstNeighbors = SELECT tgt
FROM Start:s -(friendship:e)-> person:tgt
ACCUM tgt.@visited += true, s.@visited += true;
SecondNeighbors = SELECT tgt
FROM FirstNeighbors -(:e)-> :tgt
WHERE tgt.@visited == false
POST_ACCUM @@avgAge += tgt.age;