1.简介:这是一个可以自动爬取快看漫画上的漫画,下载到本地,并自动发布到今日头条号的编程,无编程基础的人也可学会
2.学习:
1)对于学习python技术的,你可以学习python爬虫技术
2)对于做今日头条号自媒体的,可以节省很多时间去发布快漫上的漫画
3.展示:
1.python环境
Window 平台安装 Python:
以下为在 Window 平台上安装 Python 的简单步骤:
-
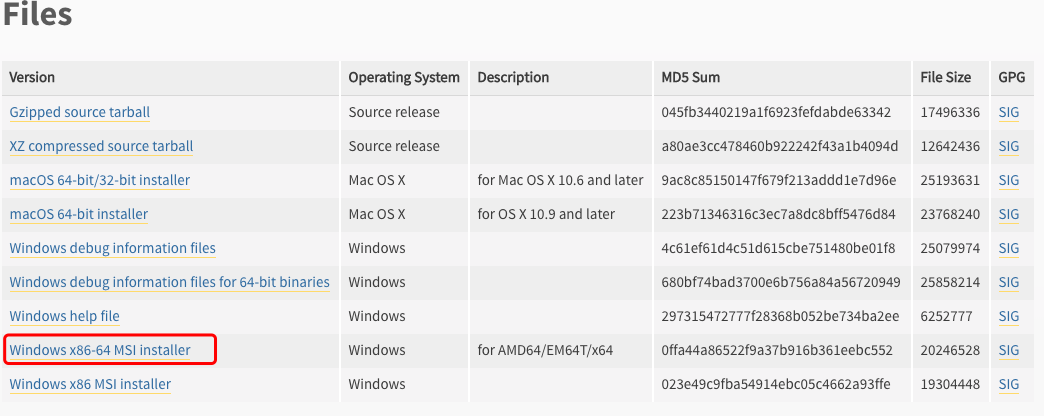
打开 WEB 浏览器访问
https://www.python.org/downloads/windows/
-

-
在下载列表中选择Window平台安装包,包格式为:
python-XYZ.msi
文件 , XYZ 为你要安装的版本号。
-
要使用安装程序
python-XYZ.msi
, Windows 系统必须支持 Microsoft Installer 2.0 搭配使用。只要保存安装文件到本地计算机,然后运行它,看看你的机器支持 MSI。Windows XP 和更高版本已经有 MSI,很多老机器也可以安装 MSI。
-
下载后,双击下载包,进入 Python 安装向导,安装非常简单,你只需要使用默认的设置一直点击"下一步"直到安装完成即可。
-
在 Windows 设置环境变量
在环境变量中添加Python目录:
在命令提示框中(cmd) :
输入
path=%path%;C:\Python
按下"Enter"。
注意:
C:\Python 是Python的安装目录。
也可以通过以下方式设置:
-
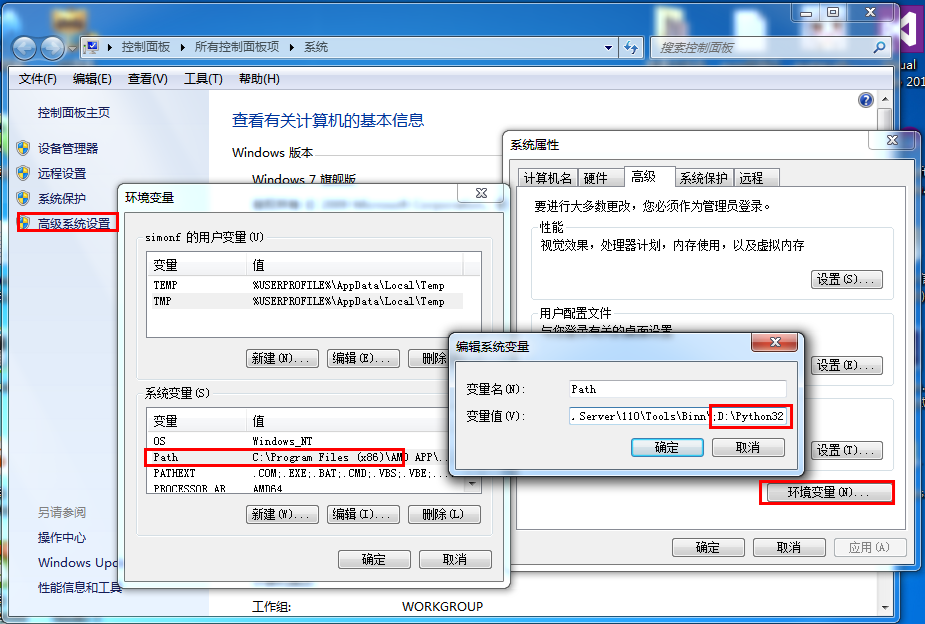
右键点击"计算机",然后点击"属性"
-
然后点击"高级系统设置"
-
-
选择"系统变量"窗口下面的"Path",双击即可!
-
-
然后在"Path"行,添加python安装路径即可(我的D:\Python32),所以在后面,添加该路径即可。
ps:记住,路径直接用分号";"隔开!
-
最后设置成功以后,在cmd命令行,输入命令"python",就可以有相关显示。
2.头条号
获取登录用的cookies
打开链接:
https://mp.toutiao.com
,登录头条号后,按F12打开调试页面
1.资料目录:
2.目录介绍:
1)cookies.txt :存在头条号的登录cookie,在第一步获取
2)get_and_push.py:爬取快漫并发布推文至头条号的脚本
3)url.txt: 要爬取的快漫文章链接
4)img:爬取的漫画保存的路径
四,操作实例:
1.下载资源:
https://gitee.com/lyc-git/get_kkmh_and_push_toutiao
2.设置cookie配置
3.设置要爬取的快漫上的图文链接
快漫:
https://www.kuaikanmanhua.com
如要这个图文的漫画:
https://www.kuaikanmanhua.com/web/comic/102684/
4.运行脚本
5.查看结果,发布成功
一,介绍1.简介:这是一个可以自动爬取快看漫画上的漫画,下载到本地,并自动发布到今日头条号的编程,无编程基础的人也可学会2.学习:1)对于学习python技术的,你可以学习python爬虫技术2)对于做今日头条号自媒体的,可以节省很多时间去发布快漫上的漫画3.展示:二,前提1.python环境Window 平台安装 Python:以下为在 Win...
用我的三脚猫
python
和懵逼的web开经验,做了一个每天
自动
发送今日
头条
微
头条
的小公举。
下面就分享给大家现个丑。
当然先从登录开始,我仅做了一个cookie的登录,打开今日
头条
登录后,F12-------network
找到user_login_status_api
划横线的就是登陆的api,注意请求方式是GET
记录cookie
referer和user-agent
ok! 有了这些,我们就能写程序完成登录部分了。
import requests
简要描述:
由于微博
没
有像csdn这样的支持跨平台内容导出的功能,于是开发了基于模拟人操作、chrome浏览器的工具,主要功能是将微博内容
自动
同步到今日
头条
微
头条
,实现内容
自动
迁移,省下不少人工。
使用说明:
一、电脑端登录今日
头条
二、下载安装chrome插件及辅助工具(meitool)
1、下载地址:
链接: https://pan.baidu.com/s/1VSB-Utrow-v5...
本文介绍如何使用后羿采集器的智能模式,免费采集今日
头条
的
文章
标题、
文章
内容、
文章
评论等信息数据。
采集工具简介:
后羿采集器(www.houyicaiji.com)是一款基于人工智能技术的网页采集器,只需要输入网址就能够
自动
识别网页数据,无需配置即可完成数据采集,是业内首家支持三种操作系统(包括Windows、Mac和Linux)的网络
爬虫
软件。
该软件是一款真正免费的数据采集软件...
原标题:运用
Python
多线程
爬虫
下载
漫画
以前,我都是买
漫画
书看的,那个时候
没
有电脑。今天,我到网上看了一下,发现网上提供
漫画
看,但是时时需要网络啊!为什么不将它下载下来呢!
文章
目录原标题:运用
Python
多线程
爬虫
下载
漫画
1.怎样实现1.1
爬取
我们需要的数据(网页链接、
漫画
名称、
漫画
章节名称)2.完整代码3.总结
1.怎样实现
这个项目需要的模块有:requests、urllib、threading、os、sys
其中requests模块也可以不用,只要urllib模块即可,但我觉得requests模块
爬取
数据代码量少。
os模块主要是为了创建文件夹,sys主要是为了结束程序(当然,这
Python
3从零开始
爬取
今日
头条
的新闻【一、开发环境搭建】
Python
3从零开始
爬取
今日
头条
的新闻【二、首页热点新闻抓取】
Python
3从零开始
爬取
今日
头条
的新闻【三、滚动到底
自动
加载】
Python
3从零开始
爬取
今日
头条
的新闻【四、模拟点击切换tab标签获取内容】
Python
3从零开始
爬取
今日
头条
的新闻【五、解析
头条
视频真实播放地址】

