

python正则贪婪与非贪婪

字符串:
Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8我们将匹配到包含三个整数的数据集:1171590364-6-8
贪婪模式
代码
import re
data = 'Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8'
patt = '.+(\d+-\d+-\d+)'
m = re.match(patt, data)
m.group(1)效果
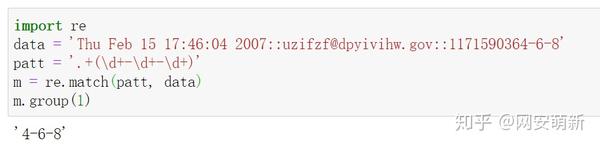
我们将提取 1171590364-6-8,而不仅仅是 4-6-8。第一个整数的其余部分在哪 儿?
问题在于正则表达式本质上实现贪婪匹配。这就意味着对于该通配符模式,将对正则表达 式从左至右按顺序求值,而且试图获取匹配该模式的尽可能多的字符。
在之前的示例中,使用 “.+”获取从字符串起始位置开始的全部单个字符,包括所期望的第一个整数字段。\d+仅仅需 要一个数字,因此将得到“4”
其中.+匹配了从字符串起始部分到所期望的第一个数字的全部 内容:
“Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::117159036”非贪婪模式
使用“非贪婪”操作符“?”。可以在“*”、“+”或者“?”之后使 用该操作符。该操作符将要求正则表达式引擎匹配尽可能少的字符。因此,如果在“.+”之 后放置一个“?”,我们将获得所期望的结果
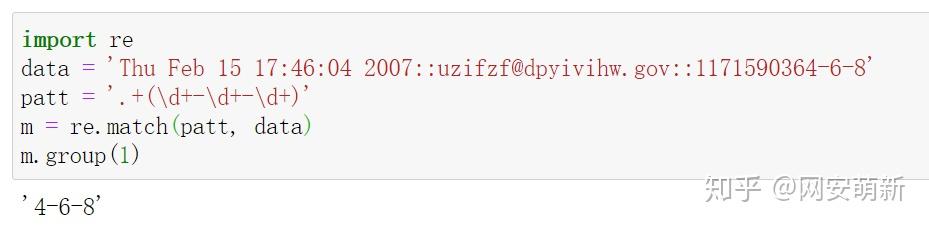
代码
import re
data = 'Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8'
patt = '.+?(\d+-\d+-\d+)'