

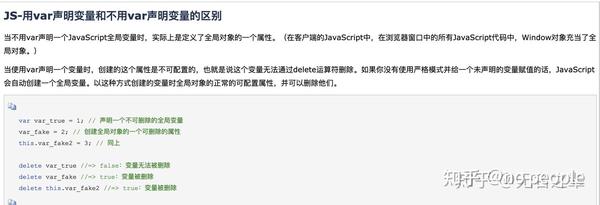
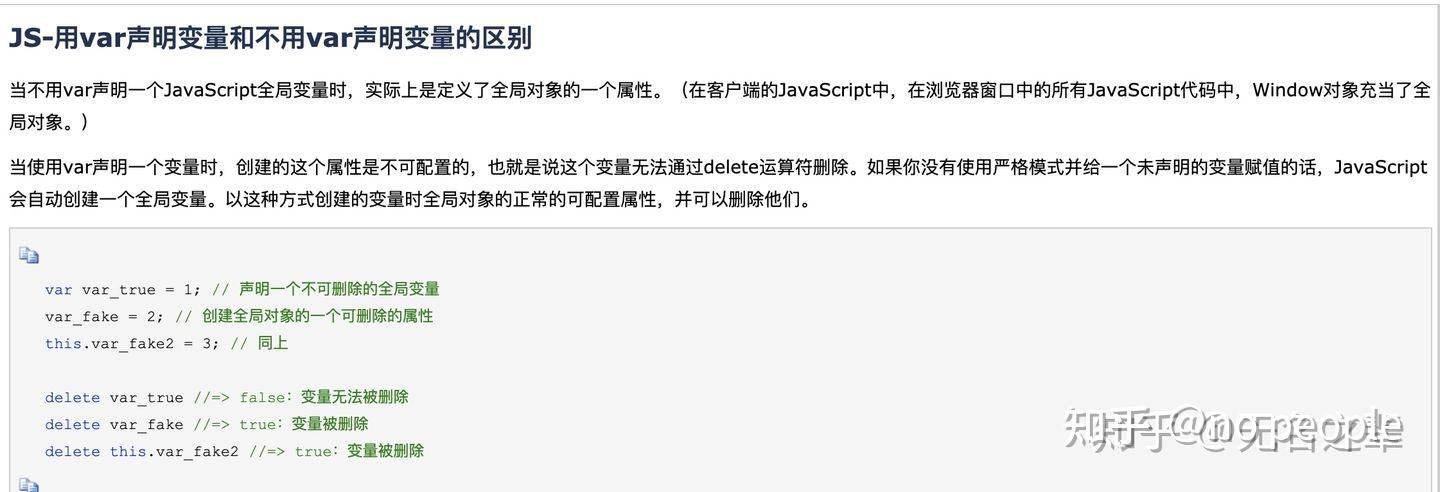
JS知识点梳理-上篇

基本数据类型
基础数据类型和引用数据类型都有哪些
- 基础类型:undefined 、 null、number、string、boolean、symbol(唯一,可以用属性名,不可覆盖)
- 引用类型:object对象类型(Object 、Array 、Function 、Data )
undefined
- void 和 undefined的区别
void 0代替undefined的优势
- 安全赋值
- 从上面的区别中,可以看出用void 0来代替undefined进行赋值确实更安全,所以几乎所有的脚手架工具都集成了undefined转void 0的能力
- 更短 void 0对比undefined,浏览器传输过程中具有更少的字节数
根本原因在于ECMAScript 5之前,undefined作为全局属性,是可读写,某些质量不高的库会覆盖undefined的值,导致直接赋值undefined不符合预期,在 ECMAScript 5之后,undefined设置成只读,也就不存在上面所说的问题,兼容性方面也基本不存在太大问题。
- 产生undefined的场景
1 未初始化变量
2 访问不存在的属性
3 函数参数未传递
4 函数返回值未return
5 void操作符
null是js关键字,类型是object,是特殊的对象,含义是非对象
undefined是预定义的全局变量,值是未定义, typeof 返回undefined
转换成 Boolean 时均为 false,转换成 Number 时有所不同
!!(null); // false
!!(undefined); // false
Number(null); // 0
Number(undefined); // NaN
null == undefined; //true
null === undefined; //false
null
null是一个普通值,需要主动使用,和12、'abc'、false没多大区别
- 只有主动使用时,null才会出现
- 没有声明null不会自己蹦出来
undefined是一个特殊值,是js中最后的备选方案
当我们向js要求一个“不存在的东西”时,会得到undefined(例如:没赋值的变量、没return的函数、没传的参数)
对来说,null更接近其他语言的空、而undefined则是js特有的机制
null本质上是个零,undefined本质上是个特殊对象
1、在js的dom元素获取中,如果没有获取到指定的元素对象,结果一般是null。
2、Object.prototype.__proto__的值是null。
3、在正则捕获的时候,如果没有捕获到结果,默认也是null。
https://juejin.cn/post/6943055278212382750
boolean
Boolean转换:以下六个为false,其他都为true
undefined
0 (+0 -0)
false
Number
- js精度问题 0.1+0.2 === 0.3原因
因为0.1和0.2转换为二进制是一个无限循环小数 循环1100,而整数的范围是 负 2的53次方和 正的2的 53次方
转换规则十进制转二进制:正整数 要点:除二取余,倒序排列,负数: 将该负整数对应的正整数先转换成二进制,然后对其“取补”,再对取补后的结果加1即可 。小数转换为二进制 要点:乘二取整,正序排列
- Number api语法
Number.MAX_SAFE_INTEGER 常量表示在 JavaScript 中最大的安全整数(maxinum safe integer)(2 53- 1)。
Number.MAX_VALUE Number.MAX_VALUE属性表示在 JavaScript 里所能表示的最大数值。MAX_VALUE 属性值接近于1.79E+308。大于MAX_VALUE 的值代表 "Infinity"。
Number.MIN_SAFE_INTEGER Number.MIN_SAFE_INTEGER代表在 JavaScript中最小的安全的integer型数字 (-(2 53- 1)).
Number.MIN_VALUE Number.MIN_VALUE属性表示在 JavaScript 中所能表示的最小的正值。MIN_VALUE 属性是 JavaScript 里最接近 0 的正值,而不是最小的负值。MIN_VALUE 的值约为 5e-324。小于 MIN_VALUE ("underflow values") 的值将会转换为 0。
Number.NaN Number.NaN 表示“非数字”(Not-A-Number)。和 NaN 相同。不必创建一个 Number 实例来访问该属性,使用 Number.NaN 来访问该静态属性。
Number.NEGATIVE_INFINITY Number.NEGATIVE_INFINITY 属性表示负无穷大。
不用创建一个 Number 实例,使用 Number.NEGATIVE_INFINITY 来访问该静态属性。
Number.POSITIVE_INFINITY Number.POSITIVE_INFINITY 属性表示正无穷大。
不必创建一个 Number 实例,可使用 Number.POSITIVE_INFINITY 来访问该静态属性。
-----------
常用的几个api
Number.EPSILON可以用来设置“能够接受的误差范围”
Number.isFinite() 方法用来检测传入的参数是否是一个有穷数。
Number.isInteger() 方法用来判断给定的参数是否为整数。
Number.isNaN() 方法确定传递的值是否为NaN,并且检查其类型是否为Number。它是原来的全局isNaN()的更稳妥的版本。
Number.isSafeInteger() Number.isSafeInteger()方法用来判断传入的参数值是否是一个“安全整数”(safe integer)。
Number.parseFloat()可以把一个字符串解析成浮点数。该方法与全局的parseFloat()函数相同,并且处于 ECMAScript 6 规范中(用于全局变量的模块化)。
Number.parseInt() number.parseInt() 方法依据指定基数 [ 参数 radix 的值],把字符串 [ 参数 string 的值] 解析成整数。
Number.prototype.toPrecision() toPrecision()方法以指定的精度返回该数值对象的字符串表示。
Number.prototype.toSource()
Number.prototype.toString()
Number.prototype.valueOf()
var numObj = new Number(10);
console.log(typeof numObj); // object
var num = numObj.valueOf();
console.log(num); // 10
console.log(typeof num); // number
Number.isFinite()用来检查一个数值是否为有限的(finite),即不是Infinity。如果参数类型不是数值,Number.isFinite一律返回false。Number.isNaN()用来检查一个值是否为NaN。
Number.parseInt(), Number.parseFloat() Number.isInteger()用来判断一个数值是否为整数。JavaScript 内部,整数和浮点数采用的是同样的储存方法,所以 25 和 25.0 被视为同一个值。
Number.EPSILON可以用来设置“能够接受的误差范围”。比如,误差范围设为 2 的-50 次方(即Number.EPSILON * Math.pow(2, 2)),即如果两个浮点数的差小于这个值,我们就认为这两个浮点数相等。
function withinErrorMargin (left, right) {
return Math.abs(left - right) < Number.EPSILON * Math.pow(2, 2);
Number.isSafeInteger()
JavaScript 能够准确表示的整数范围在-2^53到2^53之间(不含两个端点),超过这个范围,无法精确表示这个值。ES6 引入了Number.MAX_SAFE_INTEGER和Number.MIN_SAFE_INTEGER这两个常量,用来表示这个范围的上下限。
JavaScript 所有数字都保存成 64 位浮点数,这给数值的表示带来了两大限制。一是数值的精度只能到 53 个二进制位(相当于 16 个十进制位),大于这个范围的整数,JavaScript 是无法精确表示,这使得 JavaScript 不适合进行科学和金融方面的精确计算。二是大于或等于2的1024次方的数值,JavaScript 无法表示,会返回Infinity。
// 超过 53 个二进制位的数值,无法保持精度
Math.pow(2, 53) === Math.pow(2, 53) + 1 // true
// 超过 2 的 1024 次方的数值,无法表示
Math.pow(2, 1024) // Infinity
- Number的特性
Number([]) 0
Number({}) NaN
Number(false) 0
Number(NaN) NaN
Number("a") NaN
Number("11") 11
Number("")) 0
Number(null) 0
Number(undefined) NaN
如果被转换的是布尔值,true和false分别被转换为1和0两个数字。
如果被转换的是数值,则只是进行传入和返回。
如果被转换的是null,返回的是0
如果被转换的是undefined,返回的是NaN。
字符串只包含数字(包含正负号),则将其转换为十进制数值。
字符串包含符合规则的浮点数字,则将其转换为对应的浮点数值。
字符串包含符合规则的十六进制格式,则将其转换为同等大小的十进制整数值。
字符串为空,则转换为0。
字符串中包含除以上规则外的字符,转换为NaN。
对象的转换,会调用valueOf()方法,再用前面的规则返回相应的值。如果转换的结果是NaN,则可以调用toString()方法,然后再用前面的规则转换得到的字符串。
注:如果转换的是Date对象返回的是此刻到1970年1月1日0点0分0秒0毫秒的毫秒数。
链接:https://juejin.cn/post/6844903664948101127
- number 2021
ES2021,允许 JavaScript 的数值使用下划线(_)作为分隔符。这个数值分隔符没有指定间隔的位数,也就是说,可以每三位添加一个分隔符,也可以每一位、每两位、每四位添加一个。数值分隔符只是一种书写便利,对于 JavaScript 内部数值的存储和输出,并没有影响。下面三个将字符串转成数值的函数,不支持数值分隔符。 Number() parseInt() parseFloat() 不能放在数值的最前面(leading)或最后面(trailing)。 不能两个或两个以上的分隔符连在一起。 小数点的前后不能有分隔符。 科学计数法里面,表示指数的e或E前后不能有分隔符。
123_00 === 12_300 // true
12345_00 === 123_4500 // true
12345_00 === 1_234_500 // true
// 全部报错
3_.141
3._141
1_e12
1e_12
123__456
_1464301
1464301_
let num = 12_345;
num // 12345
num.toString() // 12345
BigInt
BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。 JavaScript中Number.MAX_SAFE_INTEGER表示最⼤安全数字,计算结果是9007199254740991,即在这个数范围内不会出现精度丢 失(⼩数除外)。但是⼀旦超过这个范围, js就会出现计算不准确的情况 ,这在⼤数计算的时候不得不依靠⼀些第三⽅库进⾏解决,因此 官⽅提出了BigInt来解决此问题。
ES2020引入了一种新的数据类型 BigInt(大整数),来解决这个问题,这是 ECMAScript 的第八种数据类型。BigInt 只用来表示整数,没有位数的限制,任何位数的整数都可以精确表示。 为了与 Number 类型区别,BigInt 类型的数据必须添加后缀n 。BigInt 同样可以使用各种进制表示,都要加上后缀n。BigInt 与普通整数是两种值,它们之间并不相等。 typeof运算符对于 BigInt 类型的数据返回bigint 。BigInt 可以使用负号(-),但是不能使用正号(+),因为会与 asm.js 冲突。JavaScript 原生提供BigInt函数,可以用它生成 BigInt 类型的数值。转换规则基本与Number()一致,将其他类型的值转为 BigInt。可以使用Boolean()、Number()和String()这三个方法,将 BigInt 可以转为布尔值、数值和字符串类型。
1234 // 普通整数
1234n // BigInt
// BigInt 的运算
1n + 2n // 3n
typeof 123n // 'bigint'
42n === 42 // false
BigInt(123) // 123n
BigInt('123') // 123n
BigInt(false) // 0n
BigInt(true) // 1n
Boolean(0n) // false
Boolean(1n) // true
Number(1n) // 1
String(1n) // "1"
BigInt 继承了 Object 对象的两个实例方法。
BigInt.prototype.toString()
BigInt.prototype.valueOf()
它还继承了 Number 对象的一个实例方法。
BigInt.prototype.toLocaleString()
BigInt.asUintN(width, BigInt): 给定的 BigInt 转为 0 到 2width - 1 之间对应的值。
BigInt.asIntN(width, BigInt):给定的 BigInt 转为 -2width - 1 到 2width - 1 - 1 之间对应的值。
BigInt.parseInt(string[, radix]):近似于Number.parseInt(),将一个字符串转换成指定进制的 BigInt。
const max = 2n ** (64n - 1n) - 1n;
BigInt.asIntN(64, max)
// 9223372036854775807n
BigInt.asIntN(64, max + 1n)
// -9223372036854775808n
BigInt.asUintN(64, max + 1n)
// 9223372036854775808n
String
- string api
string
str.slice(start,end):提取字符串的某一部分,并放回一个新的字符串,包括start,但是不包 end
参数: 以0开始的位置,可选结束的位置 返回值一个截取的新的字符串
不会改变原来的值
str.subString(start,end)
substring() 方法返回一个字符串在开始索引到结束索引之间的一个子集, 或从开始索引直到字符串的末尾的一个子集。包括start,但是不包括end
参数:开始位置的索引,结束位置的索引 返回值,包含字符串指定部分新的字符串
str.slice(start,end)和str.subString(start,end) 区别
substring与slice的两个参数当为正数时基本一致,除了substring会比较两个参数大小,小的排在前面。
substring的第一个参数为负数时,则自动认为是0,而第二个参数为负数时,由于表示的是结束值,那绝对返回时空字符串了。
slice的第一个参数为负数时,则会将字符串长度与此负数相加(和倒着数一致),而第二个参数为负数时,同样是将字符串长度
与此负数相加(和倒着数一致)。
3 str.concat(str1,str2....)
将一个或多个字符串相连,返回一个新的字符串 参数:一个或多个字符串 返回值: 新的字符串
不改变原来字符串
性能不如+,+=
4 str.split(分隔符, 分隔片段数量) 将字符串对象分割为字符串数组 参数,分隔符,以及要截取分隔片段数量
返回值:以分隔符出现位置分隔而出的array
5 str.indexOf(查找字符串,开始查找位置) 查找特定字符串在str出现第一次的位置,未找到返回-1
参数: 要查找的值,开始查找的位置 返回值,第一次出现的索引,未找到返回-1
不改变原来字符串
6 str.lastIndexOf(查找字符串,开始查找位置) 查找特定字符串在str出现最后一次的位置,未找到返回-1
参数: 要查找的值,开始查找的位置 返回值,最后一次出现的索引,未找到返回-1
不改变原来字符串
7 str.charAt(index) 从一个字符串中返回index位置的字符
参数 index 一个介于0和字符串长度减1之间的整数。 返回值: index位置的字符串
不改变原字符
8 str.match(正则) 在字符串中满足正则的元素组成的数组
参数: 筛选的正则 返回值: 满足正则的字符串的字符串
9 str.search(正则) 在str 搜索符合正则的元素第一个元素的索引
参数:正则 返回值:返回字符串满足正则匹配的第一次出现的索引,否则返回-1
10 trimStart(),trimEnd() :ES2019对字符串实例新增了trimStart()和trimEnd()这两个方法。它们的行为与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。它们返回的都是新字符串,不会修改原始字符串。
参数: 返回值 新字符串
不会改变原字符串
11 at() 方法接受一个整数作为参数,返回参数指定位置的字符,支持负索引(即倒数的位置)。
const sentence = 'The quick brown fox jumps over the lazy dog.';
console.log(sentence.at(3)); // ''
Symbol
https:// juejin.cn/post/70173752 85699952648
- symbol和bigint对比
Symbol 代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题。
BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了
Number 能够表示的安全整数范围。
JavaScript中Number.MAX_SAFE_INTEGER表示最⼤安全数字,计算结果是9007199254740991,即在这个数范围内不会出现精度丢
失(⼩数除外)。但是⼀旦超过这个范围,js就会出现计算不准确的情况,这在⼤数计算的时候不得不依靠⼀些第三⽅库进⾏解决,因此
官⽅提出了BigInt来解决此问题。Object
- object api
// 常用api 设置 原型链 遍历的
Object.create()
Object.defineProperties(obj,props) 直接在一个对象上定义新的属性或修改现有属性,并返回该对象。
Object.defineProperty(obj,key,prop) 会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象。
Object.prototype.hasOwnProperty() 方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。
Object.getPrototypeOf() 方法返回指定对象的原型(内部[[Prototype]]属性的值)。
Object.setPrototypeOf() 方法设置一个指定的对象的原型 ( 即, 内部[[Prototype]]属性)到另一个对象或 null。
Object.prototype.isPrototypeOf() 方法用于测试一个对象是否存在于另一个对象的原型链上。
Object.is() 判断两个值是否为同一个值
Object.entries(obj) 此方法返回一个给定对象自身可枚举属性的键值对数组,其排列与使用for...in 循环遍历该对象时返回的顺序
一致(区别在于 for-in 循环还会枚举原型链中的属性)
Object.fromEntries() 方法把键值对列表转换为一个对象
Object.keys() 返回所有可枚举属性
Object.getOwnPropertyNames() 由指定对象的所有自身属性的属性名(包括不可枚举属性但不包括Symbol值作为名称的属性)组成的数组。
Object.keys(obj)和 getOwnPropertyNames区别在于 keys返回所有可枚举属性,也就是 enumerable为true属性
getOwnPropertyNames返回不管enumerable为true和false 都返回,见下例子
Object.getOwnPropertySymbols() 方法返回一个给定对象自身的所有 Symbol 属性的数组。
Object.freeze()
Object.getOwnPropertyDescriptor() 方法返回指定对象上一个自有属性对应的属性描述符。(自有属性指的是直接赋予该对象的属性,不需要从原型链上进行查找的属性)
Object.getOwnPropertyDescriptors() 方法用来获取一个对象的所有自身属性的描述符。
Object.prototype.toLocaleString() 方法返回一个该对象的字符串表示。此方法被用于派生对象为了特定语言环境的目的(locale-specific purposes)而重载使用。
toString() toString()方法返回一个表示该对象的字符串。
Object.prototype.valueOf() valueOf() 方法返回指定对象的原始值。
-------------
var obj = {};
Object.defineProperties(obj, {
'property1': {
value: true,
writable: true
'property2': {
value: 'Hello',
writable: false
// etc. etc.
------------------------------
Object.entries(obj) 例子-------
const object1 = {
a: 'somestring',
b: 42
for (const [key, value] of Object.entries(object1)) {
console.log(`${key}: ${value}`);
// expected output:
// "a: somestring"
// "b: 42"
-----------------------
const prototype1 = {};
const object1 = Object.create(prototype1);
console.log(Object.getPrototypeOf(object1) === prototype1);
// expected output: true
--------------------
const entries = new Map([
['foo', 'bar'],
['baz', 42]
const obj = Object.fromEntries(entries);
console.log(obj);
// expected output: Object { foo: "bar", baz: 42 }
------------------------
const object1 = {
property1: 42
const descriptor1 = Object.getOwnPropertyDescriptor(object1, 'property1');
console.log(descriptor1.configurable);
// expected output: true
console.log(descriptor1.value);
// expected output: 42
var arr = ["a", "b", "c"];
console.log(Object.getOwnPropertyNames(arr).sort()); // ["0", "1", "2", "length"]
var obj = {};
var a = Symbol("a");
var b = Symbol.for("b");
obj[a] = "localSymbol";
obj[b] = "globalSymbol";
var objectSymbols = Object.getOwnPropertySymbols(obj);
console.log(objectSymbols.length); // 2
console.log(objectSymbols) // [Symbol(a), Symbol(b)]
console.log(objectSymbols[0]) // Symbol(a)
var dict = Object.setPrototypeOf({}, null);
--------------------------------------
const obj = {};
Object.defineProperties(obj, {
property1: {enumerable: true, value: 1},
property2: {enumerable: false, value: 2},
console.log(Object.keys(obj));
console.log(Object.getOwnPropertyNames(obj));
> Array ["property1"]
> Array ["property1", "property2"]
-
ES6 一共有 5 种方法可以遍历对象的属性
下面说的 继承就是原型链上的属性 - for...in: 继承的 可枚举 不含 Symbol
- Object.keys(obj) 不含继承 可枚举 不含Symbol
- Object.getOwnPropertyNames(obj) 不含继承 可枚举不可枚举 不含Symbol
- Object.getOwnPropertySymbols(obj) 只含有SYmbol属性
- Reflect.ownKeys(obj) 不含继承 可枚举不可枚举 包含Symbol
ES6 一共有 5 种方法可以遍历对象的属性。
(1)for...in: 继承的 可枚举 不含 Symbol
for...in循环遍历对象自身的和继承的可枚举属性(不含 Symbol 属性)。包含遍历 对象原型链上的属性
(2)Object.keys(obj) 不含继承 可枚举 不含Symbol
Object.keys返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含 Symbol 属性)的键名。不包含遍历原型链属性
(3)Object.getOwnPropertyNames(obj) 不含继承 可枚举不可枚举 不含Symbol
Object.getOwnPropertyNames返回一个数组,包含对象自身的所有属性(不含 Symbol 属性,但是包括不可枚举属性)的键名。
(4)Object.getOwnPropertySymbols(obj) 只含有SYmbol属性
Object.getOwnPropertySymbols返回一个数组,包含对象自身的所有 Symbol 属性的键名。
(5)Reflect.ownKeys(obj) 不含继承 可枚举不可枚举 包含Symbol
Reflect.ownKeys返回一个数组,包含对象自身的(不含继承的)所有键名,不管键名是 Symbol 或字符串,也不管是否可枚举。
不包括原型链上的属性
以上的 5 种方法遍历对象的键名,都遵守同样的属性遍历的次序规则。
首先遍历所有数值键,按照数值升序排列。
其次遍历所有字符串键,按照加入时间升序排列。
最后遍历所有 Symbol 键,按照加入时间升序排列。
Reflect.ownKeys({ [Symbol()]:0, b:0, 10:0, 2:0, a:0 })
// ['2', '10', 'b', 'a', Symbol()]
上面代码中,Reflect.ownKeys方法返回一个数组,包含了参数对象的所有属性。这个数组的属性次序是这样的,
首先是数值属性2和10,其次是字符串属性b和a,最后是 Symbol 属性。-
数据属性
[Configurable]] : 可配置 表示能否通过 delete 删除属性从而重新定义属性,能否修改属性的特性,或者能否把属性修改为访问器属性。 - [[Enumerable]] : 可枚举 表示能否通过 for-in 循环返回属性。
- [[Writable]] : 可写 表示能否修改属性的值
-
[[Value]] : 包含这个属性的数据值。读取属性值的时候,从这个位置读;写入属性值时,把新值保存在这个位置。默认值是 undefined。 像这样(var obj = new Object(); obj.name = "percy";)或者像通过对象字面量(var obj = {name: "percy"};)直接在对象上定义的属性,它们的 [[Configurable]]、[[Enumerable]] 和 [[Writable]] 特性默认都被设置为 true,而 [[Value]] 特性被设置为指定的值。 没有按上面的2种方法为对象添加属性,而直接通过Object.defineProperty()为对象添加属性以及值,这种情况下,这个对象的这个属性的另外3个特性的默认值都是 false。
要修改属性默认的特性,必须使用 ECMAScript 的 Object.defineProperty() 方法。 -
Object.defineProperty( obj, prop, descriptor) obj:需要定义属性的对象。 prop:需定义或修改的属性的名字。 descriptor:一个包含设置特性的对象 存取器属性几种特性:访问器属性不包含数据值,它们包含一对儿getter和setter函数(不过,这两个函数都不是必需的)。在读取访问器属性时,会调用 getter 函数,在写入访问器属性时,又会调用 setter 函数并传入新值。访问器属性有如下4个特性:对比数据属性 没有Writable以及value
[[Configurable]]:表示能否通过 delete 删除属性从而重新定义属性,能否修改属性的特性,或者能否把属性修改为数据属性。[[Enumerable]]:表示能否通过 for-in 循环返回属性。[[Get]]:在读取属性时调用的函数。默认值为 undefined。[[Set]]:在写入属性时调用的函数。默认值为 undefined。 访问器属性不能直接定义,必须使用Object.defineProperty()来定义。
- super 关键字 super 关键字 我们知道,this关键字总是指向函数所在的当前对象,ES6 又新增了另一个类似的关键字super,指向当前对象的原型对象。
const proto = {
foo: 'hello'
const obj = {
foo: 'world',
find() {
return super.foo;
Object.setPrototypeOf(obj, proto);
obj.find() // "hello"
上面代码中,对象obj.find()方法之中,通过super.foo引用了原型对象proto的foo属性。
注意,super关键字表示原型对象时,只能用在对象的方法之中,用在其他地方都会报错。
// 报错
const obj = {
foo: super.foo
// 报错
const obj = {
foo: () => super.foo
// 报错
const obj = {
foo: function () {
return super.foo
上面三种super的用法都会报错,因为对于 JavaScript 引擎来说,这里的super都没有用在对象的方法之中。第一种写法是super用在属性里面,第二种和第三种写法是super用在一个函数里面,然后赋值给foo属性。目前,只有对象方法的简写法可以让 JavaScript 引擎确认,定义的是对象的方法。
JavaScript 引擎内部,super.foo等同于Object.getPrototypeOf(this).foo(属性)或Object.getPrototypeOf(this).foo.call(this)(方法)。
const proto = {
x: 'hello',
foo() {
console.log(this.x);
const obj = {
x: 'world',
foo() {
super.foo();
Object.setPrototypeOf(obj, proto);
obj.foo() // "world"
上面代码中,super.foo指向原型对象proto的foo方法,但是绑定的this却还是当前对象obj,因此输出的就是world。
Proxy
Proxy对象用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等)。
const p = new Proxy(target, handler)target:要使用Proxy包装的目标对象:对象,包括原生数组,函数,甚至另一个代理)
handler:定义的捕获器函数,支持 13种捕获器函数常用下面5种
handler.get(target, property, receiver):属性读取操作的捕获器。
handler.set(target, propKey, value, receiver):属性设置操作的捕获器。
handler.deleteProperty(target, propKey):delete 操作符的捕获器。
handler.ownKeys(target):Object.getOwnPropertyNames 方法和 Object.getOwnPropertySymbols 方法的捕获器。
handler.has(target, propKey):in 操作符的捕获器。
target —— 是目标对象,该对象作为第一个参数传递给 new Proxy,
property —— 目标属性名,
property —— 目标属性的值,
receiver —— 如果目标属性是一个 getter 访问器属性,则 receiver 就是本次读取属性所在的 this 对象。通常,这就是
proxy 对象本身(或者,如果我们从代理继承,则是从该代理继承的对象)。在捕获器的get和set函数里打印receiver或者console
.log(arguments);会陷入死循环
const target = {
_name: 'xiaoming',
get name() {
return this._name;
const handler = {
_name: 'xiaohong',
get (target, property, receiver) {
//console.log(arguments);
//如果执行这个,因为会打印receiver,所以会陷入死循环
//因为console.log(arguments)中有对receiver的引用,这个操作会触发get,陷入死循环,是一种内存泄露的情况
return target[property];//**
// return Reflect.get(target, property, receiver);
const proxy = new Proxy(target, handler);
const admin = {
__proto__: proxy,
_name: 'xiaohuang',
console.log(admin.name);//xiaoming
console.log(proxy.name);//xiaomingReflect
Reflect 是一个内置的对象,它提供拦截 JavaScript 操作的方法。这些方法与 proxy handlers 的方法相同。Reflect 不是一个函数对象,因此它是不可构造的。
Reflect 的所有属性和方法都是静态的,该对象提供了与 Proxy handler 对象相关的 13 个方法。同样,这里阿宝哥只列举以下 5 个常用的方法:
- Reflect.get(target, propertyKey[, receiver]):获取对象身上某个属性的值,类似于 target[name]。
- Reflect.set(target, propertyKey, value[, receiver]):将值赋值给属性的函数。返回一个布尔值,如果更新成功,则返回 true。
- Reflect.deleteProperty(target, propertyKey):删除 target 对象的指定属性,相当于执行 delete target[name]。
- Reflect.has(target, propertyKey):判断一个对象是否存在某个属性,和 in 运算符的功能完全相同。
- Reflect.ownKeys(target):返回一个包含所有自身属性(不包含继承属性)的数组。
在实际的 Proxy 使用场景中,我们往往会结合 Reflect 对象提供的静态方法来实现某些特定的功能。为了让大家能够更好地理解并掌握 Proxy 对象,接下来的环节,阿宝哥将列举 Proxy 对象的 6 个使用场景。
Map
Map的构造函数接受一个可Iterator的值作为参数 Js Es6 Map对象
const person = [
['name', 'zhangsan', ], ['age', 23], ['name', 'lisi'], ['age', 34]
const personMap = new Map(person) // Map { 'name' => 'lisi', 'age' => 34 }-
map和object区别,
Object 结构提供了“字符串—值”的对应,Map 结构提供了“值—值”的对应,是一种更完善的 Hash 结构实现。如果你需要“键值对”的数据结构,Map 比 Object 更合适。
Map默认情况下不包含任何键,所有键都是开发人员添加进去的。不像Object原型链上有一些默认的键。
Map的键可以是任意类型数据,就连函数都可以。Object的键只能是String或Symbol。
Map的键值对个数可以轻易通过size属性获取,Object需要手动计算。
Map在频繁增删键值对的场景下性能要比Object好。
https://juejin.cn/post/6981995678327111717- 什么时候用Map?
要添加的键值名和Object上的默认键值名冲突,又不想改名时,可以换用Map。
需要String和Symbol以外的数据类型做键值时,用Map。
键值对很多,有需要计算数量时,用Map。
需要频繁增删键值对时,用Map。-
WeakMap 和 Map 的性能有什么差别?
WeakMap与Map的区别有两点 1 WeakMap只接收对象作为健名,不接受其他类型作为健名 2 weakMap的健名所指向的对象,不计入垃圾回收机制。
WeakMap 就是为了解决这个问题而诞生的,它的键名所引用的对象都是弱引用,即垃圾回收机制不将该引用考虑在内。因此,只
要所引用的对象的其他引用都被清除,垃圾回收机制就会释放该对象所占用的内存。也就是说,一旦不再需要,WeakMap 里面的键名
对象和所对应的键值对会自动消失,不用手动删除引用。
基本上,如果你要往对象上添加数据,又不想干扰垃圾回收机制,就可以使用 WeakMap。一个典型应用场景是,在网页的 DOM 元素
上添加数据,就可以使用WeakMap结构。当该 DOM 元素被清除,其所对应的WeakMap记录就会自动被移除。
weakMap的专用场合就是,它的键所对应的对象,可能会在将来消失。WeakMap结构有助于防止内存泄漏。- map 的api
Map.prototype.set(key, value)
Map.prototype.get(key)
Map.prototype.has(key)
Map.prototype.delete(key)
Map.prototype.keys():返回键名的遍历器。
Map.prototype.values():返回键值的遍历器。
Map.prototype.entries():返回所有成员的遍历器。
Map.prototype.forEach():遍历 Map 的所有成员。
使用 for..of 方法迭代 Map:
for (let [key, value] of map) {
console.log(key + " = " + value);
/*输出:
键名1 = 更改后键值1
键名2 = 键值2
键名3 = 键值3*/
for (let key of map.keys()) {
console.log(key);
/* 输出:
使用 forEach() 方法迭代 Map:
// 注意:这里不是写错了,参数就是 键值在前,键名在后
map.forEach(function(value, key) {
console.log(key + " = " + value);
/*输出:
键名1 = 更改后键值1
键名2 = 键值2
键名3 = 键值3*/
Map合并
let first = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
let second = new Map([
[1, 'uno'],
[2, 'dos']
// 合并两个Map对象时,如果有重复的键值,则后面的会覆盖前面的。
// 展开运算符本质上是将Map对象转换成数组。
let merged = new Map([...first, ...second]);
console.log(merged.get(1)); // uno
console.log(merged.get(2)); // dos
console.log(merged.get(3)); // three
Map对象也能与数组合并:
// Map对象同数组进行合并时,如果有重复的键值,则后面的会覆盖前面的。
let merged = new Map([...first, ...second, [1, 'eins']]);
console.log(merged.get(1)); // eins
Array
for in 遍历数组和对象(会遍历任意其他自定义添加的属性)返回值是 for in 循环数组 返回 字符串形式index,不一定按次序访问元素(不建议),循环对象 返回 字符串的obj的key
for of 遍历 数组,字符串 set map 等可迭代的数据结构(任何具有 Symbol.iterator 属性的元素都是可迭代的。),
返回 每个元素value,如下例 Js中for in 和for of的区别
* if分别使用return、break、continue的区别 * break:使用break可以退出当前的循环 * continue:用于跳过当次循环 * return:使用return可以结束整个函数
循环中可以跳出循环的有 (标准for循环 for in for of 三个只能break停止跳出循环,不能return, 待确认 ) every some(return)
不能跳出循环的右: forEach filter map reduce
for 循环和 forEach循环的区别在于?
- fo r循环为原生语法糖,无上下文,而forEach则是Array上的方法。
- for 循环可以通过break, continue进行中途退出循环,而forEach则不行。
- 数组常见点总结 返回新数组: slice concat filter
不会改变原数组的方法有 slice concat + findindex(indexof lastindexof) + 所有数组循环方法(some every forEach filter map reduce) Array.from
使用 hasOwnProperty 只遍历对象本身属性而不是原型
//for in 应用于数组
Array.prototype.sayHello = function(){
console.log("Hello")
Array.prototype.str = 'world';
var myArray = [1,2,10,30,100];
myArray.name='数组';
for(let index in myArray){
console.log(index);
//输出结果如下
0,1,2,3,4,name,str,sayHello
//for in 应用于对象中
Object.prototype.sayHello = function(){
console.log('Hello');
Obeject.prototype.str = 'World';
var myObject = {name:'zhangsan',age:100};
for(let index in myObject){
console.log(index);
//输出结果
name,age,str,sayHello
//首先输出的是对象的属性名,再是对象原型中的属性和方法,
//如果不想让其输出原型中的属性和方法,可以使用hasOwnProperty方法进行过滤
for(let index in myObject){
if(myObject.hasOwnProperty(index)){
console.log(index)
//输出结果为
name,age
//你也可以用Object.keys()方法获取所有的自身可枚举属性组成的数组。
Object.keys(myObject)- array api
targetArray.push('a') 添加到数组结尾
参数是单个元素,或多个元素
返回值是新数组的数目
改变原数组,可用targetArray来获取添加后的数组 实现: 时间复杂度是O(n) 空间复杂度是0
Array.prototype.push = function ( ...elements ) {
var initLength = this.length // 保存一下最初的长度
for ( var i = 0; i < elements.length; i++ ) {
this[ initArrLength + i ] = elements[ i ]
return this.length
targetArray.pop() 删除数组最后一个元素
返回值是删除的最后一个元素。
改变原数组,可用targetArray 来获取删除后的数组
Array.prototype.pop = function () {
var lastItem = this[ this.length-1 ]
arr.length--; // 这里我通过数组长度减一,自动就减掉数组的最后一项
return lastItem
targetArray.shift() 删除数组第一个元素
返回值是删除的第一个元素
改变原数组,可用targetArray 来获取删除后的数组
Array.prototype.shift = function () {
var fitstItem = this[ 0 ]
for ( var i = 0; i < arr.length; i++ ) {
arr[ i ] = arr[ i + 1 ]
arr.length--; // 这里我通过数组长度减一,自动就减掉数组的最后一项
return fitstItem
targetArray.unshift('a') 将元素添加到数组开头
参数是单个元素或多个元素
返回值是 新数组的数目
改变原数组,可用targetArray来获取添加后的数组。
Array.prototype.unshift = function ( ...elements ) {
for ( let i = this.length + ( elements.length - 1 ); i >= 0; i-- ) {
this[ i ] = this[ i - ( elements.length ) ]
console.log( this )
for ( var i = 0; i < elements.length; i++ ) {
this[ i ] = elements[ i ]
return this.length
targetArray.sort(fn || null) 对数组进行排序,无参数按照Unicode位点进行排序。
参数是 空或者一个函数
返回值是排序后的数组
改变原来的数组,可用targetArray来获取排序后的数组
数组排序 targetArray.sort((a,b)=>a-b)
添加图片注释,不超过 140 字(可选)
具体源码实现 targetArray.reverse() 对数组进行反转
返回值是排序后的数组
改变原来的数组,可用targetArray来获取排序后的数组
var arr = [1,2,3,4,5];
Array.prototype.myReverse = function (){
for(var i=0;i<this.length/2; i++){
var temp =this[i];
this[i] = this[this.length -1-i];
this[this.length-1-i] = temp;}
return this;
arr.myReverse();
targetArray.slice(start,end) 切取数组的某一部分
参数是 可选的开始结束
返回值是截取的数组
并不会改变原数组,可以用tar
如何获取截取后的数组?
Array.prototype.slice = function(begin, end){
let result = []
begin = begin || 0
end = end || this.length
for(let i = begin; i< end; i++){
result.push(this[i])
return result
于是很多前端用 slice 来将伪数组,转化成数组
array = Array.prototye.slice.call(arrayLike)
array = [].slice.call(arrayLike)
ES 6 看不下去这种蹩脚的转化方法,出了一个新的 API
array = Array.from(arrayLike)
专门用来将伪数组转化成真数组。
P.S. 伪数组与真数组的区别就是:伪数组的原型链中没有 Array.prototype,而真数组的原型链中有 Array.prototype。因此伪数组没有 pop、join 等属性。
targetArray.splice(start,num,addEle,....) 是为了解决 获取截取后的数组因为slice为切片,单纯截取的功能,
splice 是删除以及添加功能
参数 开始删除的位置,删除的个数, 添加的元素
返回值是 要删除的元素 数组
会改变原数组,splice后可以用原数组获取删除后的数组
targetArray.concat() 合并数组
参数是多个值 或者多个数组
返回值 是合并后新的数组
不会改变原来数组
targetArray.indexOf() 获取当前元素的索引
参数 是单个元素
返回值 元素在数组中的索引,如果不存在返回-1
不会改变原数组
targetArray.lastIndexOf() 获取当前元素在数组中最后一个出现的位置
参数 单个元素
返回值 元素在数组中的索引,不存在返回-1
不会改变原数组
targetArray.findIndex(fn) 返回满足查找函数第一个索引。
参数 :fn
返回值:符合条件的值得索引
不改变原数组
targetArray.includes() : 判断一个数组是否包含一个指定的值,根据情况,如果包含则返回 true,否则返回false。
参数:判断的元素
返回值:布尔值
targetArray.every 每个元素都满足需求返回true,只要有一个不满足返回false.
参数:函数(item,index,当前数组targetArray)=>{},this指针
返回值: true或者false 不会改变原数组。
targetArray.some 至少有一个满足就返回true,一个都不满足返回false.
参数:函数(item,index,当前数组targetArray)=>{},this指针
返回值: true或者false 比较 for in , for of , forEach 区别?
forEach: 缺点: 不能中断循环(使用break语句或使用return语句) 返回值 underfind
for…in: 可以遍历对象和数组 ,缺点: 循环不仅会遍历数组元素,还会遍历任意其他自定义添加的属性 break 可以中断,
for...of: for-of 循环不仅仅支持数组的遍历。同样适用于很多类似数组的对象, 字符串的遍历, 使用 break, continue 和 return
targetArray.forEach 循环每一次
参数: 函数(item,index,当前数组targetArray)=>{},this指针
返回值 underfind 不改变值
function Counter() {
this.sum = 0;
this.count = 0;
Counter.prototype.add = function(array) {
array.forEach(function(entry) {
this.sum += entry;
++this.count;
}, this);
//console.log(this);
var obj = new Counter();
obj.add([1, 3, 5, 7]);
obj.count;
// 4 === (1+1+1+1)
obj.sum;
// 16 === (1+3+5+7)
targetArray.filter 筛选出一个新数组,符合条件的数组。
参数:函数(item,index,当前数组targetArray)=>{},this指针
返回值: 返回符合条件组成的数组。 targetArray.find 方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined 参数: callack,thisArg
返回值: 返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined
targetArray.map 为一个数组每个元素执行元素,返回一个数组。
参数:函数(item,index,当前数组targetArray)=>{},this指针
返回值 每个执行元素后组成的数组。
targetArray.reduce 数组中的每个元素执行一个由您提供的reducer函数(升序执行),将其结果汇总为单个返回值
参数 fn ,初始值,fn四个参数:累加器 accumulator 当前值 currentValue 当前索引 currentIndex 数组 Array。
当没有初始值:循环过程如下:
[0, 1, 2, 3, 4].reduce(function(accumulator, currentValue, currentIndex, array){
return accumulator + currentValue;
添加图片注释,不超过 140 字(可选)
当有初始值,执行 5次:
[0, 1, 2, 3, 4].reduce((accumulator, currentValue, currentIndex, array) => { return accumulator + currentValue; }, 10 );
添加图片注释,不超过 140 字(可选)
场景:求和,将二维数组转一维,计算数组中出现次数,数组去重
。。。。。
之前遗忘:
targetArray.join 将一个数组所有元素拼接为字符串
参数:数组元素拼接为字符串后,连接符号,默认为逗号
返回值: 所有数组元素连接的字符串。
var elements = ['Fire', 'Air', 'Water'];
console.log(elements.join());
// expected output: "Fire,Air,Water"
flat 会按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。
参数:深度
返回值: 一个包含将数组与子数组中所有元素的新数组。
var arr1 = [1, 2, [3, 4]];
arr1.flat();
// [1, 2, 3, 4]
var arr2 = [1, 2, [3, 4, [5, 6]]];
arr2.flat();
// [1, 2, 3, 4, [5, 6]]
var arr3 = [1, 2, [3, 4, [5, 6]]];
arr3.flat(2);
// [1, 2, 3, 4, 5, 6]
//使用 Infinity 作为深度,展开任意深度的嵌套数组
arr3.flat(Infinity);
// [1, 2, 3, 4, 5, 6]
fill:方法用一个固定值填充一个数组中从起始索引到终止索引内的全部元素。不包括终止索引。
var array1 = [1, 2, 3, 4];
// fill with 0 from position 2 until position 4
console.log(array1.fill(0, 2, 4));
// expected output: [1, 2, 0, 0]
// fill with 5 from position 1
console.log(array1.fill(5, 1));
// expected output: [1, 5, 5, 5]
console.log(array1.fill(6));
// expected output: [6, 6, 6, 6]
reduce使用场景
https://aotu.io/notes/2016/04/14/js-reduce/index.html https://exp-team.github.io/blog/2017/03/09/js/reduce2/
字符统计/单词统计同理
let str = 'abcdaabc';
str.split('').reduce((res, cur) => {
res[cur] ? res[cur] ++ : res[cur] = 1 // 如果cur第一次出现,记为1
return res; // 否则记录数+1
}, {})
求加法(乘法同理)
let arr = [1, 2, 3, 4, 5];
arr.reduce((sum, curr) => sum + curr, 0); // 得到15
此基础上还可以求平均值
let arr = [1, 2, 3, 4, 4, 1]
let newArr = arr.reduce((pre,cur) => {
if(!pre.includes(cur)){
return pre.concat(cur)
}else{
return pre
},[]) // 得到 [1, 2, 3, 4]
数组维度转换
let arr = [[0, 1], [2, 3], [4, 5]] // 二维数组
let newArr = arr.reduce((pre,cur) => {
return pre.concat(cur) // 合并pre 与 cur, 并返回一个新数组
},[])
console.log(newArr); // 一维数组 [0, 1, 2, 3, 4, 5]
数组操作:
4 数组去重 https://juejin.cn/post/6844903986210816013#heading-38
Array ES6
Array.from(arrayLike,mapFn) : 用于将类数组对象和可遍历对象转化为数组
arrayLike: Arrays(数组), Strings(字符串), Maps(映射), Sets(集合)
返回值: 新的数组实例, 不改变原数组
Array.from([1, 2, 3], x => x + x);
Array.of(1,2,3) : 创建一个具有可变数量参数的新数组实例
返回值: 新的Array实例。 不改变原数组
- for 循环和 forEach循环的区别在于?
for循环为原生语法糖,无上下文,而forEach则是Array上的方法。
for 循环可以通过break, continue进行中途退出循环,而forEach则不行。
- 不改变原数组的方法有哪些?
数组方法:slice(start,end),返回值是截取的数组, 不改变原属组。splice(start,num,addEle,....) 是为了解决 获取截取后的数组因为slice为切片,单纯截取的功能,返回值是 要删除的元素 数组,会改变原数组 . forEach 返回 underfined
不改变原属组的方法: slice,concat,flat, join ,判断存在方法,循环方法
- 类数组和真实数组转换方法?
Array.prototye.slice.call(arrayLike)
array = Array.from(arrayLike)
P.S. 伪数组与真数组的区别就是:伪数组的原型链中没有 Array.prototype,而真数组的原型链中有 Array.prototype。因此伪数组没有 pop、join 等属性。
- 数组的扩展
扩展运算符:rest参数逆运算,将数组转为用逗号分隔的参数序列,应用 合并数组,与解构赋值连用(const [first, ...rest] = [1, 2, 3, 4, 5])
Array.from(替代es5的 [].slice.call(arrayLike)):类似数组的对象(array-like object)和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)。
Array.of(3, 11, 8) 用于将一组值,转换为数组。: Array.of(3, 11, 8) // [3,11,8],
Array.of() // [] Array.of(undefined) // [undefined] (替代弥补数组构造函数Array()的不足,因为参数个数的不同,会导致Array()的行为有差异。Array(3) // [, , ,])
数组实例的 includes(target,from) (替代indexOf 找到参数值的第一个出现位置,所以要去比较是否不等于-1,这会导致对NaN的误判,[NaN].indexOf(NaN) -1 [NaN].includes(NaN) // true)
flat 方法 方法, find方法弥补indexOf NaN不足
数组有10万个数据,取第一个和取第10万个的耗时多久?
答:数组可以直接根据索引取的对应的元素,所以不管取哪个位置的元素的时间复杂度都是 O(1)
JavaScript 没有真正意义上的数组,所有的数组其实是对象,其“索引”看起来是数字,其实会被转换成字符串,作为属性名(对象的 key)来使用。所以无论是取第 1 个还是取第 10 万个元素,都是用 key 精确查找哈希表的过程,其消耗时间大致相同。
得出结论:消耗时间几乎一致,差异可以忽略不计
原文链接:https://blog.csdn.net/L_C_sunny/article/details/117984374Set
- set和array的区别 set: 类似于数组,但是成员的值都是唯一的,没有重复的值。Set本身是一个构造函数,用来生成 Set 数据结构 参数:可以接受一个数组(或者具有 iterable 接口的其他数据结构)作为参数
const set = new Set([1, 2, 3, 4, 4]); [...set] 数组去重: [...new Set(array)]
- WeakSet和set区别 WeakSet 的成员只能是对象,而不能是其他类型的值。
WeakSet 中的对象都是弱引用,(
其实就是存在感很弱的人,我是WeakSet,我手里有股票,假如股票被GC统一回收,如果强势的人握着,就不会回收,但是对于我WeakSet,不管我手里握着都会被回收
)即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于 WeakSet 之中。
内部成员随时可能消失,所以不可以遍历
new WeakSet(数组或类数组对象) 参数: WeakSet 可以接受一个数组或类似数组的对象作为参数。(实际上,任何具有 Iterable 接口的对象,都可以作为 WeakSet 的参数。
- set的api
Set.prototype.constructor:构造函数,默认就是Set函数。
Set.prototype.size:返回Set实例的成员总数。
Set 实例的方法分为两大类:操作方法(用于操作数据)和遍历方法(用于遍历成员)。下面先介绍四个操作方法。
Set.prototype.add(value):添加某个值,返回 Set 结构本身。
Set.prototype.delete(value):删除某个值,返回一个布尔值,表示删除是否成功。
Set.prototype.has(value):返回一个布尔值,表示该值是否为Set的成员。
Set.prototype.clear():清除所有成员,没有返回值。
Set 结构的实例有四个遍历方法,可以用于遍历成员。
Set.prototype.keys():返回键名的遍历器
Set.prototype.values():返回键值的遍历器
Set.prototype.entries():返回键值对的遍历器
Set.prototype.forEach():使用回调函数遍历每个成员
Function
- 创建函数的两种方式
1. 声明方式:用function关键字进行声明,但只有变量/常量/函数具有声明方式
function 函数名(形参){函数体;return 返回值;}
具有完整的声明提前
2 函数表达式
var 函数名=function(形参){函数体;return 返回值;}
在程序正式执行前,会将var声明的变量和function声明的函数集中提前到当前作用域顶部,但赋值留在原地
有声明提前,但赋值留在原地
3 构造函数方式
var 函数名=new Function("形参",...,"函数体")
函数体在动态拼接时使用
- 函数的 arguments和reset操作符
arguments是类数组对象,rest为数组对象
如何获取函数参数的长度,如果直接未用rest,可以用arguments.length或者funName.length来
如果还有reset操作符,funName.length不能正确获取长度,可以用arguments.length正确获取,如果只有reset,可以用reset.length来获取
重载
相同的函数根据传入的实参不同,会自动选择相应函数执行
目的:减少程序员负担
注意:js不支持重载,因为js不允许同时存在多个同名函数,最后一个会覆盖之前的所有函数
函数内部使用,类数组:下标、length、遍历
作用:可以借助实参,则不需要创建形参
使用arguments实现重载:通过判断arguments,实现功能
//传入一个实参做乘方,传入两个实参做加法
function f1(){
if(arguments.length==1){
return Math.pow(arguments[0],2);
}else if(arguments.length==2){
return arguments[0]+arguments[1];
console.log(f1(8));
console.log(f1(8,9);
ES6 引入 rest 参数(形式为...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了。
rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中。arguments对象不是数组,而是一个类似数组的对象。
所以为了使用数组的方法
- 箭头函数
箭头函数有几个使用注意点。
(1)箭头函数没有自己的this对象(详见下文)。
(2)不可以当作构造函数,也就是说,不可以对箭头函数使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
上面四点中,最重要的是第一点。对于普通函数来说,内部的this指向函数运行时所在的对象,但是这一点对箭头函数不成立。它没有自己的this对象,内部的this就是定义时上层作用域中的this。也就是说,箭头函数内部的this指向是固定的,相比之下,普通函数的this指向是可变的。箭头函数实际上可以让this指向固定化,绑定this使得它不再可变,这种特性很有利于封装回调函数。下面是一个例子,DOM 事件的回调函数封装在一个对象里面。箭头函数里面根本没有自己的this,而是引用外层的this。
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
var id = 21;
foo.call({ id: 42 });
// id: 42
function Timer() {
this.s1 = 0;
this.s2 = 0;
// 箭头函数
setInterval(() => this.s1++, 1000);
// 普通函数
setInterval(function () {
this.s2++;
}, 1000);
var timer = new Timer();
setTimeout(() => console.log('s1: ', timer.s1), 3100);
setTimeout(() => console.log('s2: ', timer.s2), 3100);
// s1: 3
// s2: 0
function foo() {
return () => {
return () => {
return () => {
console.log('id:', this.id);
var f = foo.call({id: 1});
var t1 = f.call({id: 2})()(); // id: 1
var t2 = f().call({id: 3})(); // id: 1
var t3 = f()().call({id: 4}); // id: 1
答案是this的指向只有一个,就是函数foo的this,这是因为所有的内层函数都是箭头函数,都没有自己的this,它们的this其实都是最外层foo函数的this。所以不管怎么嵌套,t1、t2、t3都输出同样的结果。如果这个例子的所有内层函数都写成普通函数,那么每个函数的this都指向运行时所在的不同对象。
除了this,以下三个变量在箭头函数之中也是不存在的,指向外层函数的对应变量:arguments、super、new.target。
不适用场合
由于箭头函数使得this从“动态”变成“静态”,下面两个场合不应该使用箭头函数。第一个场合是定义对象的方法,且该方法内部包括this。第二个场合是需要动态this的时候,也不应使用箭头函数。
const cat = {
lives: 9,
jumps: () => {
this.lives--;
上面代码中,cat.jumps()方法是一个箭头函数,这是错误的。调用cat.jumps()时,如果是普通函数,该方法内部的this指向cat;如果写成上面那样的箭头函数,使得this指向全局对象,因此不会得到预期结果。这是因为对象不构成单独的作用域,导致jumps箭头函数定义时的作用域就是全局作用域。
globalThis.s = 21;
const obj = {
s: 42,
m: () => console.log(this.s)
obj.m() // 21
上面例子中,obj.m()使用箭头函数定义。JavaScript 引擎的处理方法是,先在全局空间生成这个箭头函数,然后赋值给obj.m,这导致箭头函数内部的this指向全局对象,所以obj.m()输出的是全局空间的21,而不是对象内部的42。上面的代码实际上等同于下面的代码。
var button = document.getElementById('press');
button.addEventListener('click', () => {
this.classList.toggle('on');
上面代码运行时,点击按钮会报错,因为button的监听函数是一个箭头函数,导致里面的this就是全局对象。如果
- es6新增
1 函数参数的默认值 function log(x, y = 'World') {}
2 函数length属性,rest 参数也不会计入length属性。
3 reset参数...参数,替代arguments对象(是一个类数组,转化为数组才可以使用数组方法,Array.prototype.slice.call(arguments)),reset参数后不能有其他参数,会报错
只要参数使用了默认值、解构赋值、或者扩展运算符,就不能显式指定严格模式。(解决办法,全局严格模式,或者,把函数包在一个无参数的立即执行函数里面)
4 name属性
5 箭头函数
第一个场合是定义对象的方法,且该方法内部包括this。
const cat = {
lives: 9,
jumps: () => {
this.lives--;
第二个场合是需要动态this的时候,也不应使用箭头函数。
var button = document.getElementById('press');
button.addEventListener('click', () => {
this.classList.toggle('on');
- function 新增 尾调用优化和尾递归 尾调用(Tail Call)是函数式编程的一个重要概念,本身非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
// 等同于
function f() {
return g(3);
// 等同于
g(3);
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。这就叫做“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行“尾调用优化”。
function addOne(a){
var one = 1;
function inner(b){
return b + one;
return inner(a);
上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。注意,目前只有 Safari 浏览器支持尾调用优化,Chrome 和 Firefox 都不支持。
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。由此可见,“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6 亦是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署“尾调用优化”。这就是说,ES6 中只要使用尾递归,就不会发生栈溢出(或者层层递归造成的超时),相对节省内存。
递归函数的改写
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量total,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算5的阶乘,需要传入两个参数5和1?
两个方法可以解决这个问题。方法一是在尾递归函数之外,再提供一个正常形式的函数。上面代码通过一个正常形式的阶乘函数factorial,调用尾递归函数tailFactorial,看起来就正常多了。
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
第二种方法就简单多了,就是采用 ES6 的函数默认值。上面代码中,参数total有默认值1,所以调用时不用提供这个值。总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持“尾调用优化”的语言(比如 Lua,ES6),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
factorial(5) // 120
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
factorial(5, 1) // 120
function tailFactorial(n, total) {
if (n === 1) return total;
return tailFactorial(n - 1, n * total);
function factorial(n) {
return tailFactorial(n, 1);
factorial(5) // 120
function currying(fn, n) {
return function (m) {
return fn.call(this, m, n);
function tailFactorial(n, total) {
if (n === 1) return total;
return tailFactorial(n - 1, n * total);
const factorial = currying(tailFactorial, 1);
factorial(5) // 120
function factorial(n, total = 1) {
if (n === 1) return total;
return factorial(n - 1, n * total);
factorial(5) // 120
ES2017允许函数的最后一个参数有尾逗号(trailing comma)。ES2019 对函数实例的toString()方法做出了修改。toString()方法返回函数代码本身,以前会省略注释和空格。
function /* foo comment */ foo () {}
foo.toString()
// function foo() {}
上面代码中,函数foo的原始代码包含注释,函数名foo和圆括号之间有空格,但是toString()方法都把它们省略了。修改后的toString()方法,明确要求返回一模一样的原始代码。
- function的防抖节流
防抖和节流
https://zhuanlan.zhihu.com/p/80566067 https://www.jianshu.com/p/b5fcb9a04b17
防抖debounce:就是点击多次就执行最后一次,因为前几次都清除掉了(搜索输入,窗口resize)
节流throttle: 在规定时间内,只执行一次(滚动加载,高频点击)
若time都是3s后执行,那么多次点击debounce后,执行是在最后一次+3s执行
多次点击throttle是在第一次点击+3s后执行
https://blog.csdn.net/mxydl2009/article/details/93868911
防抖:—触发高频事件后 n 秒后函数只会执行一次,如果 n 秒内高频事件再 次被触发,则重新计算时间
function debounce(func, time) {
var timer;
return function() {
// 注意这里是清楚上一次缓存的旧timer
clearTimeout(timer);
timer = setTimeout(() => {
console.log(this,'asd')
func.apply(this, arguments);
}, time);
节流——高频事件触发,但在 n 秒内只会执行一次,所以节流会稀释函数的执 行频率。
function throttle (fn,delay){
var timer;
return function (){
if(!timer){
timer = setTimeout(()=>{
fn.apply(this,arguments)
timer = null
},delay)
-
function基本api
Class
-
为什么会产生class类语法?
其他OOP(面向对象的语言)都有类的概念比如java,一些初学js的人感到困惑,有人尝试将构造函数写法封装成kclass写法,后续在es6中正式发布为class
-
class与之前普通函数有什么不同?相同点?
不同点: 1 不存在变量提升 2 默认使用严格模式,不可更改 3 所有方法不可枚举 注:非绑定当前对象的方法
相同点: 类的数据类型是函数
类的实例方法和静态方法 实例属性和静态属性
类的实例方法和实例属性: 在constructor里面以及直接在class定义属性( 实例属性是定义在类的实例上, 会被实例继承 方法定义在类的原型上,之可以在实例上调用方法是因为,实例继承了原型,所以可以在实例上调用原型上的方法。 )
类的静态方法和静态属性: 前面都有static 方法( 是类本来的属性,不会被实例继承 定义在class类上 可以直接调用,非定义在类的原型上 非定义在类的实例上 )
---------------------
es6的静态方法
class Person{
#x; // 私有属性
_count = 0; 实例属性 1
constructor(name){
this._name=name; /*实例属性 2*/
run(){ /*实例方法*/
console.log(this._name);
static info = 'es6 静态属性' // 静态属性
static work(){ // 静态方法
console.log('这是es6里面的静态方法');
// 私有方法
#method = () => {
// ...
Person.instance='这是一个静态方法的属性';
var p=new Person('张三');
p.run();
Person.work(); /*es6里面的静态方法*/
console.log(Person.instance);函数的实例方法和静态方法 实例属性和静态属性
实例方法和实例属性: 在函数内的 方法和属性
挂在原型上的实例方法和实例属性:函数名.prototype.[实例方法] 或者 函数名.prototype.[实例属性]
静态方法和静态属性: 函数名.[静态方法] 或者 函数名.[静态属性]
es5 静态方法
function Person(name,age) {
//构造函数里面的方法和属性
this.name=name; // 实例属性,可以通过对象.属性访问的属性叫实例属性
this.age=age;
this.run=function(){ // 实例方法
console.log(`${this.name}---${this.age}`)
//原型链上面的属性和方法可以被多个实例共享
Person.prototype.sex='男';
Person.prototype.work=function(){ // 实例方法,挂载在原型链,生成的对象可直接点方法的方式调用
console.log(`${this.name}---${this.age}---${this.sex}`);
// 静态属性,挂载在构造函数
Person.info = 'nice'
//静态方法
Person.setName=function(){
console.log('静态方法');
var p=new Person('zhangsan','20'); /*实例方法是通过实例化来调用的,静态是通过类名直接调用*/
p.run();
p.work();
Person.setName(); /*执行静态方法*/


Constructor的作用
constructor方法是类的构造函数,是一个默认方法,通过new命令创建对象实例时,自动调用该方法。一个类必须有constructor 方法,如果没有显式定义,一个默认的constructor 方法会被默认添加。所以即使你没有添加构造函数,也是会有一个默认的构造函数的。一般constructor方法返回实例对象this,但是也可以指定constructor 方法返回一个全新的对象,让返回的实例对象不是该类的实例
Super的作用 理解 es6 class 中 constructor 方法 和 super 的作用 ES6 class继承与super关键词深入探索 - 掘金
Super 既可以作为函数使用也可以作为对象使用,
class A {}
class B extends A {
constructor() {
super(); // ES6 要求,子类的构造函数必须执行一次 super 函数,否则会报错。
}当做函数使用: s uper代表了父类的构造函数, 但是返回的是子类B的实例,即super 内部的this指向的是B,所以super()在这里相当于 A.prototype.constructor.call(this,props)
当做对象使用: 在普通方法中指向父类的原型对象,在静态方法中,指向父类
class A {
c() {
return 2;
class B extends A {
constructor() {
super();
console.log(super.c()); // 2
let b = new B();上面代码中,子类 B 当中的 super.c(),就是将 super 当作一个对象使用。这时,super 在普通方法之中,指向 A.prototype, 所以 super.c() 就相当于 A.prototype.c()。
通过 super 调用父类的方法时,super 会绑定子类的 this。
class A {
constructor {
this.x = 1;
s() {
console.log(this.x);
class B extends A {
constructor {
super();
this.x = 2;
m() {
super.s();
let b = new B();
b.m(); // 2
上面代码中,super.s() 虽然调用的是 A.prototytpe.s(),但是 A.prototytpe.s()会绑定子类 B 的 this,导致输出的是 2,而不是 1。也就是说,实际上执行的是 super.s.call(this)。
由于绑定子类的 this,所以如果通过 super 对某个属性赋值,这时 super 就是 this,赋值的属性会变成子类实例的属性。
class A {
constructor {
this.x = 1;
class B extends A {
constructor {
super();
this.x = 2;
super.x = 3;
console.log(super.x); // undefined
console.log(this.x); // 3
let b = new B();
上面代码中,super.x 赋值为 3,这时等同于对 this.x 赋值为 3。而当读取 super.x 的时候,调用的是 A.prototype.x,但并没有 x 方法,所以返回 undefined。
注意,使用 super 的时候,必须显式指定是作为函数,还是作为对象使用,否则会报错。
class A {}
class B extends A {
constructor() {
super();
console.log(super); // 报错
上面代码中,console.log(super);的当中的super,无法看出是作为函数使用,还是作为对象使用,所以 JavaScript 引擎解析代码的时候就会报错。这是,如果能清晰的表明super的数据类型,就不会报错。
类的私有方法以及私有属性: 是为了解决类中的所有方法以及属性都可以暴露给外部,所以类的私有方法以及私有属性对外是不可以见的,只能在内部使用,
类中方法 this的指向 : 在class中 ,this默认指向类的实例,就是在class中,定义类的时候默认使用的是严格模式。所以在严格模式下,由于this不能指向全局变量,因此这里就变成了undefined。
class中的getter和setter的理解:
3 静态方法为什么会出现?es5的静态方法和es6有什么区别?
类相当于实例的原型,所有在类中定义的方法,都会被实例继承。
如果在一个方法前,加上static关键字,就表示该方法不会被实例继承,而是直接通过类点方法来调用,这就称为“静态方法”。
要不然不用静态方法,要先new 一个类,要调用new一个实例,然后调用实例上的方法,要注意的是,调用实例上的方法,实际上也是调用原型上的方法,方法都是定义在类的prototype上即定义在原型上。
之所以出现静态方法就是因为原型对象这个东西,在类上定义方法实际上就相当于es5的在实例对象上定义方法。构造函数的prototype属性叫做原型对象,原型对象很特殊,具有一个普通对象没有的能力,将它的属性共享给其他对象。 - 谈谈你对class中的getter和setter的理解? 先谈谈对象的getter以及setter属性,
-
对象的属性分为两种,一种是数据属性,下面的a,是一个简单的值。另一种是存取器属性,这种用getter和setter方法定义的属性,其实也是属性,这个函数没有function关键字,也没有使用冒号将属性名和函数体分开,但函数体的结束和下一个方法之前是有逗号,当程序查询存取器属性值时,js调用getter方法,无参数,这个方法的返回值就是该属性存取表达式的值。当程序设置一个存取器属性值时,可以调用setter方法,将赋值表达式右侧的值当做参数传入setter。
- 数据属性有4个描述其行为的特性:
对比数据属性有哪些优点?相当于一个队属性value设施一个钩子,如果钩子函数里面值改变从而会导致这个函数值也会改变,之前对于数据属性这个没有一个连带的效果的。这个属性实际用在什么地方?
function Person() {
this.name = name
// 1. 首先给 Person.prototype 原型对象添加了 describe 方法 。
Person.prototype.describe = function(){
console.log('Hello, my name is ' + this.name + '.');
// 2. 实例化对象的 __proto__ 指向 Person.prototype
var jane = new Person('jane');
jane.__proto__ === Person.prototype;
// 3. 读取 describe 方法时,实际会沿着原型链查找到 Person.prototype 原型对象上。
jane.describe() // Hello, my name is jane.
--------------------
-----------------------------------------------------------------------
//理解 属性挂在类的实例上,方法挂在类的原型上
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
toString() {
return '(' + this.x + ', ' + this.y + ')';
var point = new Point(2, 3);
point.toString() // (2, 3)
point.hasOwnProperty('x') // true
point.hasOwnProperty('y') // true
point.hasOwnProperty('toString') // false
point.__proto__.hasOwnProperty('toString') // true
point.__proto__ = 构造函数.prototype = 原型对象
---------------------------------------------------
// 理解可以通过proto来改变添加 原型上的方法
var p1 = new Point(2,3);
var p2 = new Point(3,2);
p1.__proto__.printName = function () { return 'Oops' };
p1.printName() // "Oops"
p2.printName() // "Oops"
var p3 = new Point(4,2);
p3.printName() // "Oops"
-------------------------------------------------------------------
var person = {}; // 新建一个空对象
Object.defineProperty(person,"name",{
value: "percy"
console.log(Object.getOwnPropertyDescriptor(person,"name"));
// 打印:Object {value: "percy", writable: false, enumerable: false, configurable: false}
--------------------------------------------------------------------
var person = {name: "percy"};
Object.defineProperty(person,"name",{
writable: false
console.log(person.name); // percy
person.name = "zyj";
console.log(person.name); // percy
for(let prop in person){
console.log(prop + " : " + person[prop]);
} // name : percy
Object.defineProperty(person,"name",{
enumerable: false
for(let prop in person){
console.log(prop + " : " + person[prop]);
} // 什么也没打印
Object.defineProperty(person,"name",{
configurable: false
Object.defineProperty(person,"name",{
configurable: true
}); // 报错:TypeError: Cannot redefine property: name(…)
// 一旦把属性定义为不可配置的,那么就再也不能把属性定义回可配置的了。
----------------------------------------------------------------------------------------------
var book = {
_year : 2004,
edition : 1
Object.defineProperty(book,"year",{
get : function () {
alert(this._year);
set : function (newValue) {
if (newValue > 2004) {
this._year = newValue;
this.edition += newValue - 2004;
book.year; // 弹出窗口,显示 2004
book.year = 2005;
console.log(book.edition); // 2
---------------------
var obj = {
get a(){
return this._a_;
set a(val){
this._a_ = val;
obj.a = 1;
console.log(obj.a);//1
----------------------
class App {
handleClick() {
console.log(this)
const app = new App
const func = app.handleClick
<button onclick="func()">click</button>
// 打印 undefined
<button onclick="app.handleClick()">click</button>
// 打印 App
---------------
const func = app.handleClick;
func(); //调用func的环境是全局环境。
-------------------------------------
class App {
handle() {
console.log(this)
function test1 () {
console.log(this);
var test2 = function(){
"use strict";
console.log(this);
const app = new App();
const func = app.handle;
func(); //undefined
test1(); //window
test2(); //undefined
--------------
解决办法就是绑定this,箭头函数
class Logger{
constructor(){
this.printName = this.printName.bind(this);
//...
class Logger{
constructor(){
this.printName = (name = 'there') => {
this.print(name);
----------------------
class IncreasingCounter {
_count = 0; 实例属性
---------------------------
constructor() {
this._count = 0; 实例属性
get value() {
console.log('Getting the current value!');
return this._count;
increment() {
this._count++;
-------------
/ 老写法
class Foo {}
Foo.prop = 1;
// 新写法
class Foo {
static prop = 1;//Class 内部只有静态方法,没有静态属性。现在有一个提案提供了类的静态属性,写法是在实例属性法的前面,加上static关键字。
---------------
class Point {
constructor(x, y) {
this.#x = x;
this.#y = y;
equals(point) {
return this.#x === point.#x && this.#y === point.#y;
------------
class Foo {
#privateValue = 42;
static getPrivateValue(foo) {
return foo.#privateValue;
Foo.getPrivateValue(new Foo()); // >> 42
------------------
class Foo {
constructor() {
this.#method();
#method() {
// ...
class Foo {
constructor() {
this.#method();
#method = () => {
// ...

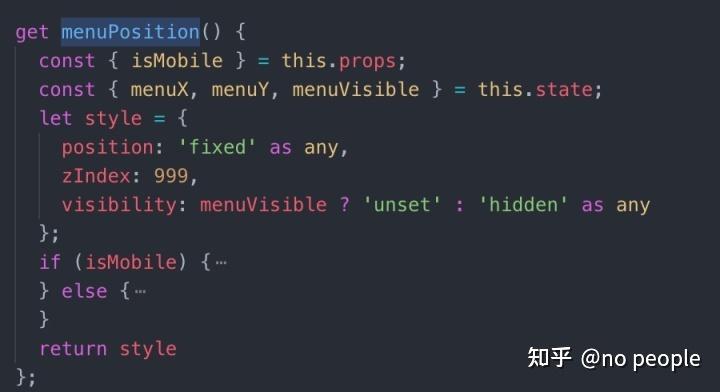
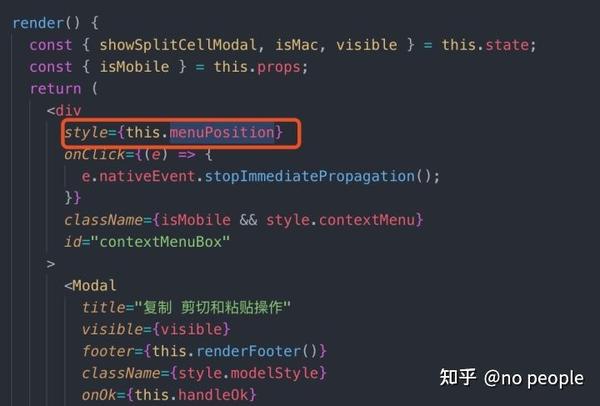
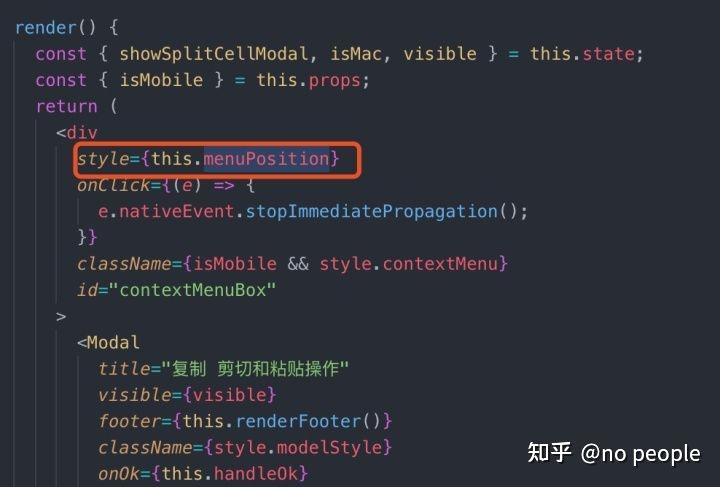
装饰器
https:// juejin.cn/post/68449035 81372383239
装饰器(Decorator)是一种与类(class)相关的语法,用来注释或修改类和类方法。
1 类的装饰器: 修改了类的行为,为它加上了静态属性。装饰器函数的参数为类本身
@eat
class Person {
constructor() {}
function eat(target, key, descriptor) {
console.log('吃饭');
console.log(target);
console.log(key);
console.log(descriptor);
target.prototype.act = '我要吃饭';
const jack = new Person();
console.log(jack.act);
// 吃饭
// [Function: Person]
// undefined
// undefined
// 我要吃饭
第一个参数target的原型prototype上添加一个属性act,并赋值为'我要吃饭'.然后将函数eat作为装饰在Person这个类本身上.
最后,构造一个Person的实例jack,并打印jack上的act属性.
然后从下面的运行结果中我们可以看出,代码中会先打印出'吃饭',然后是参数
target
,其次是参数
key
,再然后是参数
descriptor
.最后才是
jack
的
act
属性.
这是因为装饰器对类的行为的改变,是代码编译时发生的,而不是在运行时。这意味着,装饰器能在编译阶段运行代码。也就是说,装饰器本质就是编译时执行的函数。
2 方法的装饰器
Decorator
的最终本质就是一个函数,这个函数通过接受目标对象的三个参数:
所装饰的类的本身
、
所装饰的类的某个属性的key值
、
所装饰的类的某个属性的描述对象
.
并通过对这三个参数的操作,已达到为类扩展功能的目的
看了上面那段代码的运行结果,你可能会用这么一个疑问.Decorator所传进来的三个参数: target、key、descriptor.为什么只有target有值,而key和descriptor则都是undefined了.事实上这是因为你将装饰器Decorator装饰在类本身上所导致的.在ES中装饰器并不仅仅只能装饰在类本身上,也可以装饰在类的属性上.当装饰在类的属性上时.key和descriptor也就有了用武之地.请看下面这段代码:
class Person {
constructor() {}
@test
name() {console.log('张三');}
function test(target, key, descriptor) {
console.log(target);
console.log(key);
console.log(descriptor);
const student = new Person();
student.name();
// Person {}
// name
// { value: [Function: name], writable: true, enumerable: false, configurable: true }
// 张三为什么修饰器不能用于函数?
修饰器只能用于类和类的方法,不能用于修饰函数,因为存在函数提升。
由于存在函数提升,使得修饰器不能用于函数。类是不会提升的,所以就没有这方面的问题。
RegExp 正则
添加千分符 正则表达式/\B(?=(\d{3})+(?!\d))/解释 https:// blog.csdn.net/qq_371525 33/article/details/108485385 https:// blog.csdn.net/qq_371525 33/article/details/108485385 https:// blog.csdn.net/qq_371525 33/article/details/108485385 添加千分符 正则表达式/\B(?=(\d{3})+(?!\d))/解释
- 正则常见考点
千分位分隔符: /\B(?=(\d{3})+(?!\d))/g
验证邮箱: /^[\w_-]+@[\w_-]+(\.[\w_-]+)+$/
手机号: ^(1[3-9])\d{9}$
// (1)匹配 16 进制颜色值
var regex = /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g;
// (2)匹配日期,如 yyyy-mm-dd 格式
var regex = /^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$/;
// (3)匹配 qq 号
var regex = /^[1-9][0-9]{4,10}$/g;
// (4)手机号码正则
var regex = /^1[34578]\d{9}$/g;
// (5)用户名正则
var regex = /^[a-zA-Z\$][a-zA-Z0-9_\$]{4,16}$/;
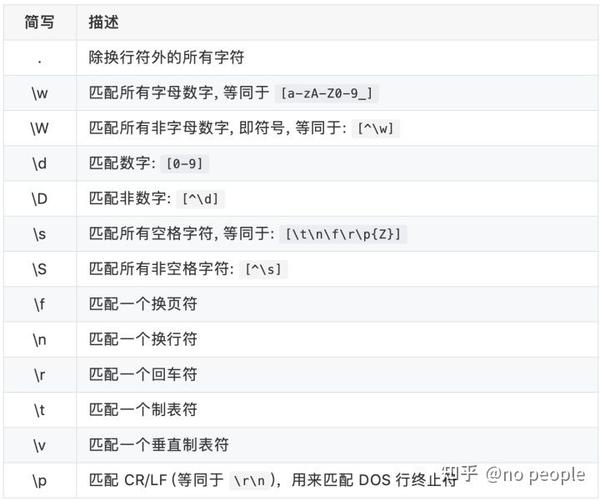
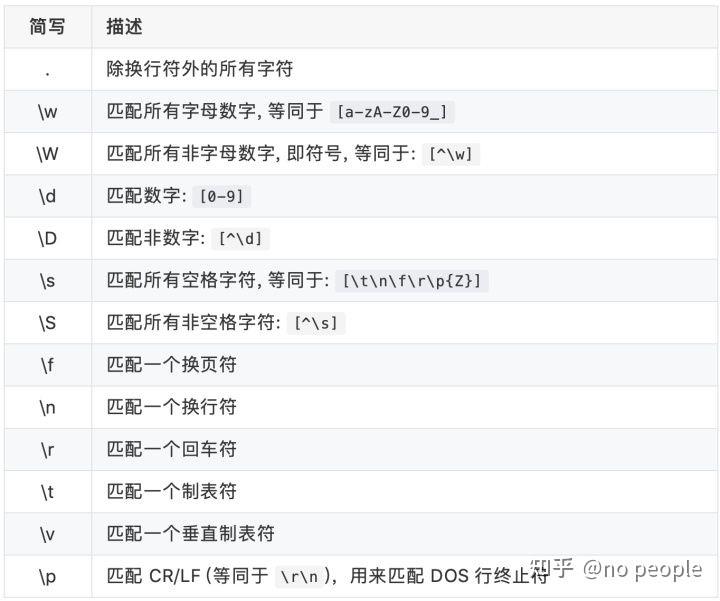
- 正则元字符和简写


- 正则 以下列出 ?=、?<=、?!、?<! 的使用区别
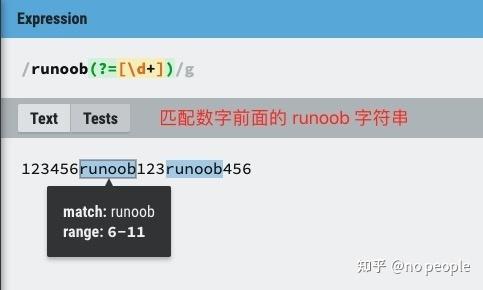
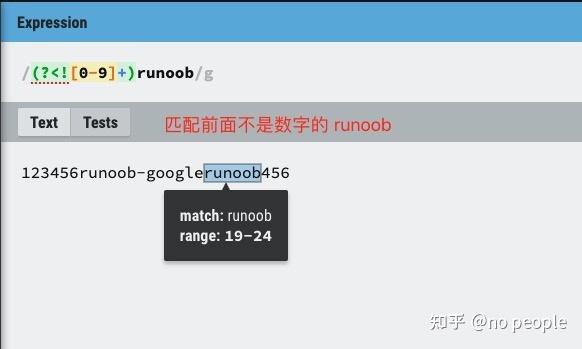
exp1(?=exp2):查找 exp2 前面的 exp1。
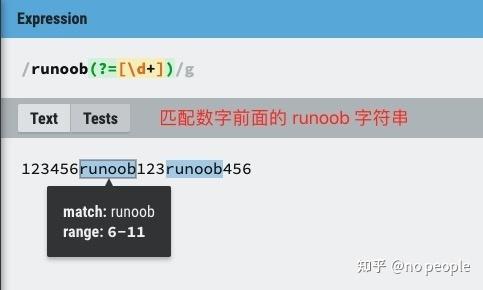
(?<=exp2)exp1:查找 exp2 后面的 exp1。


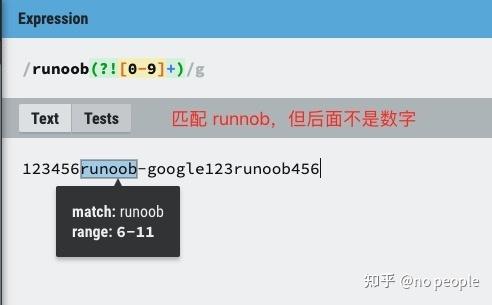
exp1(?!exp2):查找后面不是 exp2 的 exp1。
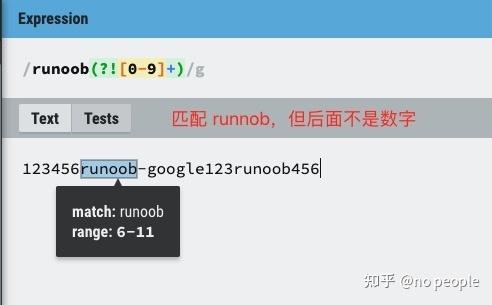
(?<!exp2)exp1:查找前面不是 exp2 的 exp1。
字符串关于正则匹配:字符串对象共有 4 个方法,可以使用正则表达式:match()、replace()、search()和split()。ES6 将这 4 个方法,在语言内部全部调用RegExp的实例方法,从而做到所有与正则相关的方法,全都定义在RegExp对象上。
Date
- date api
new Date().getFullYear() // 2020 获取四位的当前年份数字
new Date().getMonth() // 4 返回当前的月份数字减一,所以一般我们会在后面加一表示当前的月份
new Date().getDate() // 14 获取今天是当前月第几天
new Date().getHours() // 15 获取现在的小时,24格式
new Date().getMinutes() // 22 获取现在的分钟
new Date().getSeconds() // 31 获取现在的秒
new Date().getMilliseconds() // 793 获取现在的毫秒
new Date().getTime() // 1589440967857 返回距 1970 年 1 月 1 日之间的毫秒数
new Date().getDay() // 4 返回今天星期几的数字基本数据类型的转换
- 1 原始值转布尔
在 JavaScript 中,只有 6 种值可以被转换成 false,其他都会被转换成 true。
console.log(Boolean()) // false
console.log(Boolean(false)) // false
console.log(Boolean(undefined)) // false
console.log(Boolean(null)) // false
console.log(Boolean(+0)) // false
console.log(Boolean(-0)) // false
console.log(Boolean(NaN)) // false
console.log(Boolean("")) // false
console.log(Boolean({})) // true
console.log(Boolean([])) // true
其他值到布尔类型的值的转换规则?
以下这些是假值: • undefined • null • false • +0、-0 和 NaN • ""
假值的布尔强制类型转换结果为 false。从逻辑上说,假值列表以外的都应该是真值
- 2 原始值转数字
console.log(Number()) // +0
console.log(Number(undefined)) // NaN
console.log(Number(null)) // +0
Number(NaN) NaN
Number([]) 0
Number({}) NaN
console.log(Number(false)) // +0
console.log(Number(true)) // 1
console.log(Number("123")) // 123
console.log(Number("-123")) // -123
console.log(Number("1.2")) // 1.2
console.log(Number("000123")) // 123
console.log(Number("-000123")) // -123
console.log(Number("0x11")) // 17
console.log(Number("")) // 0
console.log(Number(" ")) // 0
console.log(Number("123 123")) // NaN
console.log(Number("foo")) // NaN
console.log(Number("100a")) // NaN
3 原始值转字符 如果 String 函数不传参数,返回空字符串,如果有参数,调用 ToString(value),而 ToString 也给了一个对应的结果表。表如下:
Undefined "undefined"
Null "null"
Boolean 如果参数是 true,返回 "true"。参数为 false,返回 "false"
Number 又是比较复杂,可以看例子
String 返回与之相等的值
4 ToPrimitive 那接下来就要看看 ToPrimitive 了,在了解了 toString 和 valueOf 方法后,这个也很简单。
让我们看规范 9.1,函数语法表示如下:
ToPrimitive(input[, PreferredType]) 第一个参数是 input,表示要处理的输入值。
第二个参数是 PreferredType,非必填,表示希望转换成的类型,有两个值可以选,Number 或者 String。
当不传入 PreferredType 时,如果 input 是日期类型,相当于传入 String,否则,都相当于传入 Number。
如果传入的 input 是 Undefined、Null、Boolean、Number、String 类型,直接返回该值。
如果是 ToPrimitive(obj, Number),处理步骤如下:
如果 obj 为 基本类型,直接返回 否则,调用 valueOf 方法,如果返回一个原始值,则 JavaScript 将其返回。 否则,调用 toString 方法,如果返回一个原始值,则 JavaScript 将其返回。 否则,JavaScript 抛出一个类型错误异常。 如果是 ToPrimitive(obj, String),处理步骤如下:
如果 obj为 基本类型,直接返回 否则,调用 toString 方法,如果返回一个原始值,则 JavaScript 将其返回。 否则,调用 valueOf 方法,如果返回一个原始值,则 JavaScript 将其返回。 否则,JavaScript 抛出一个类型错误异常。
对象转字符串 所以总结下,对象转字符串(就是 Number() 函数)可以概括为:
如果对象具有 toString 方法,则调用这个方法。如果他返回一个原始值,JavaScript 将这个值转换为字符串,并返回这个字符串结果。
如果对象没有 toString 方法,或者这个方法并不返回一个原始值,那么 JavaScript 会调用 valueOf 方法。如果存在这个方法,则 JavaScript 调用它。如果返回值是原始值,JavaScript 将这个值转换为字符串,并返回这个字符串的结果。
否则,JavaScript 无法从 toString 或者 valueOf 获得一个原始值,这时它将抛出一个类型错误异常。
对象转数字 对象转数字的过程中,JavaScript 做了同样的事情,只是它会首先尝试 valueOf 方法
如果对象具有 valueOf 方法,且返回一个原始值,则 JavaScript 将这个原始值转换为数字并返回这个数字
否则,如果对象具有 toString 方法,且返回一个原始值,则 JavaScript 将其转换并返回。 否则,JavaScript 抛出一个类型错误异常。 举个例子:
console.log(Number({})) // NaN
console.log(Number({a : 1})) // NaN
console.log(Number([])) // 0
console.log(Number([0])) // 0
console.log(Number([1, 2, 3])) // NaN
console.log(Number(function(){var a = 1;})) // NaN
console.log(Number(/\d+/g)) // NaN
console.log(Number(new Date(2010, 0, 1))) // 1262275200000
console.log(Number(new Error('a'))) // NaN
注意,在这个例子中,[] 和 [0] 都返回了 0,而 [1, 2, 3] 却返回了一个 NaN。我们分析一下原因:
当我们 Number([]) 的时候,先调用 [] 的 valueOf 方法,此时返回 [],因为返回了一个对象而不是原始值,所以又调用了 toString 方法,此时返回一个空字符串,接下来调用 ToNumber 这个规范上的方法,参照对应表,转换为 0, 所以最后的结果为 0。
而当我们 Number([1, 2, 3]) 的时候,先调用 [1, 2, 3] 的 valueOf 方法,此时返回 [1, 2, 3],再调用 toString 方法,此时返回 1,2,3,接下来调用 ToNumber,参照对应表,因为无法转换为数字,所以最后的结果为 NaN。
- 隐式类型转换方法有哪些
- JS里面的装箱和拆箱操作
字符串是基本数据类型,基本类型是没有方法的,但为什么字符串还有很多方法?这个例子我用的是字符串的属性,原理都是一样的。
JavaScript为我们提供了三种特殊的包装用类型:String、Number和Boolean,方便我们操作对应的基本类型。在调用length的时候,JS引擎会先对原始类型数据进行包装,术语叫装箱。
执行这段代码是,JS引擎会从内存中读取str的值,然后会执行下面的操作:
创建String类型的一个实例 let newStr=new String();
在实例上调用该方法 let length=newStr.length;
销毁这个实例 newStr=null判断数据类型的方法
- 每种方法的优缺点
1 typeof
typeof 记住特殊的两个 null和数组 不可以判断,其他类型都可以判断
typeof null == 'object'(小写)(原因,因为null的机器码是000,和对象机器码相同) typeof [] == 'object';
typeof NaN; // "number"
000:对象 1:整数 010:浮点数 100:字符串 110:布尔
有 2 个值比较特殊: undefined:用 - (−2^30)表示。 null:对应机器码的 NULL 指针,一般是全零。
2 instanceof
检测某个实例是否属于某个类,测试构造函数的prototype属性是否出现在对象的原型链中的任何位置
instanceof 运算符用于判断构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
instanceof用法: A(实例) instanceof B(构造函数);实现原理主要是判断A._proto_属相是否指向 B的prototype 即 原型对象。链接
基本数据值都不可以用instanceof来检测
用instanceof检测的时候,只要当前的这个类在实例的原型链上(可以通过原型链__proto__找到它),检测出来的结果都是true
var oDiv = document.getElementById("div1");
//HTMLDivElement->HTMLElement->Element->Node->EventTarget->Object
console.log(oDiv instanceof HTMLDivElement);//->true
console.log(oDiv instanceof Node);//->true
console.log(oDiv instanceof Object);//->true
在类的原型继承中,instanceof检测出来的结果其实是不准确的
function Fn() {
Fn.prototype = new Array;//->Fn子类继承了Array这个父类中的属性和方法
var f = new Fn;
console.log(f instanceof Array);//->true
3 Object.prototype.toString.call
Object.prototype.toString.call(value) ->找到Object原型上的toString方法,让方法执行,并且让方法中的this变为value(value->就是我们要检测数据类型的值)
Object.prototype.toString常用来判断对象值属于哪种内置属性,它返回一个JSON字符串——"[object 数据类型]"。
var toString = Object.prototype.toString;
console.log(toString.call(1));//[object Number]
console.log(toString.call(undefined));//[object Undefined]
console.log(toString.call(null));//[object Null]
console.log(toString.call(false));//[object Boolean]
console.log(toString.call("s"));//[object String]
console.log(toString.call({}));//[object Object]
console.log(toString.call(/[a]/g));//[object RegExp]
Object.prototype.toString.call([]) // [object Array]
Object.prototype.toString.call(NaN) // [object Number]
同样是检测对象obj调用toString方法,obj.toString()的结果和Object.prototype.toString.call(obj)的结果不一样,
这是为什么?
这是因为toString是Object的原型方法,而Array、function等类型作为Object的实例,都重写了toString方法。不同的对象类
型调用toString方法时,
根据原型链的知识,调用的是对应的重写之后的toString方法(function类型返回内容为函数体的字符串,Array类型返回元素组成
的字符串…),
而不会去调用Object上原型toString方法(返回对象的具体类型),所以采用obj.toString()不能得到其对象类型,只能将obj转换
为字符串类型;
因此,在想要得到对象的具体类型时,应该调用Object原型上的toString方法。
- 实现instanceof
实例 instanceof 构造函数
构造函数的prototype即原型 是否指向 实例的原型
https://www.cnblogs.com/ArthurXml/p/6555509.html
https://zhuanlan.zhihu.com/p/113068039
https://zhuanlan.zhihu.com/p/105487552
https://github.com/tjx666/deep-in-fe/blob/master/src/instanceof/instanceOf.js
A.isPrototypeOf(B) 判断的是A对象是否存在于B对象的原型链之中
A instanceof B 判断的是B.prototype是否存在与A的原型链之中
module.exports = instanceOf;
* 检测构造函数的原型是否在实例的原型链上
function myInstanceof(left, right) {
// 获取对象的原型
let proto = Object.getPrototypeOf(left)
// 获取构造函数的 prototype 对象
let prototype = right.prototype;
// 判断构造函数的 prototype 对象是否在对象的原型链上
while (true) {
if (!proto) return false;
if (proto === prototype) return true;
// 如果没有找到,就继续从其原型上找,Object.getPrototypeOf方法用来获取指定对象的原型
proto = Object.getPrototypeOf(proto);
* 检测构造函数的原型是否在实例的原型链上
* @param {object} a
* @param {Object} b
function instanceOf(a, b) {
return a !== null && (a.__proto__ == b.prototype || instanceOf(a.__proto__, b))
内存模型
这些数据可以分为原始数据类型和引用数据类型:
栈:原始数据类型(Undefined、Null、Boolean、Number、String)
堆:引用数据类型(对象、数组和函数)
两种类型的区别在于存储位置的不同:
引用类型的值是同时保存在栈内存和堆内存中的对象。
原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储;
引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定。如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
堆和栈的概念存在于数据结构和操作系统内存中,在数据结构中:
在数据结构中,栈中数据的存取方式为先进后出。
堆是一个优先队列,是按优先级来进行排序的,优先级可以按照大小来规定。
在操作系统中,内存被分为栈区和堆区:
栈区内存由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆区内存一般由开发着分配释放,若开发者不释放,程序结束时可能由垃圾回收机制回收。
let obj = {a: 0};
function fun(obj){
obj.a =1;
obj = {a:1}; // 相当于新建一个obj 和上面传入的并不一样
obj.b = 2;
console.log(obj)
fun(obj)
console.log(obj)深浅拷贝问题
https:// segmentfault.com/a/1190 000020255831
- 深浅拷贝的实现方法
1 实现浅拷贝的方法
= 赋值操作
展开运算符 {...a}
object.assign()
map, filter, reduce , Array.slice
展开运算符:
const a = {
en: 'Bye',
de: 'Tschüss'
let b = {...a}
b.de = 'Ciao'
console.log(b.de) // Ciao
console.log(a.de) // Tschüss
const a = {
foods: {
dinner: 'Pasta'
let b = {...a}
b.foods.dinner = 'Soup' // changes for both objects
console.log(b.foods.dinner) // Soup
console.log(a.foods.dinner) // Soup
如果对象内部包含对象,那么内部嵌套的对象也不会被拷贝,因为它们只是引用。因此改变嵌套对象,所有的实例中的嵌套对象的属性都会被改变。所以说上面的场景全部都只实现了浅拷贝。
assign:
const a = {
en: 'Bye',
de: 'Tschüss',
cc: { 'name': 'aa' }
let b = Object.assign({}, a)
b.de = 'Ciao'
b.cc.name = 'bb'
console.log(b.de) // Ciao
console.log(a.de) // Tschüss
console.log(b.cc) // { name: 'bb'}
console.log(a.cc) // { name: 'bb'}
如果对象内部包含对象,那么内部嵌套的对象也不会被拷贝,因为它们只是引用。因此改变嵌套对象,所有的实例中的嵌套对象的属性都会被改变。所以说上面的场景全部都只实现了浅拷贝。
自己只实现拷贝一层的浅拷贝方法:
// 只复制第一层的浅拷贝
function simpleCopy(obj1) {
var obj2 = Array.isArray(obj1) ? [] : {};
for (let i in obj1) {
obj2[i] = obj1[i];
return obj2;
var obj1 = {
a: 1,
b: 2,
var obj2 = simpleCopy(obj1);
obj2.a = 3;
obj2.c.d = 4;
alert(obj1.a); // 1
alert(obj2.a); // 3
alert(obj1.c.d); // 4
alert(obj2.c.d); // 4
function shallowClone(copyObj){
var obj = {}
for(var i in copyObj){
obj[i] = copyObj[i]
return obj
var x = {
a: 1,
b: { f: {g: 1}},
c: [1,2,3]
let y = shallowClone(x)
y.a=2 这时x不受影响,当修改y.c.push(4),这样x会受影响,因为浅拷贝只是针对一层的拷贝。
2 实现深拷贝方法
JSON.stringify与JSON.parse
lodash _.clone
Array的slice和concat方法 返回新数组,只是对于数组中元素为基本类型来说是深拷贝,如果为对象,则为浅拷贝
自己实现深拷贝以及有哪些缺点
JSON.stringify 和JSON.parse
const a = {
foods: {
dinner: 'Pasta'
let b = JSON.parse(JSON.stringify(a))
b.foods.dinner = 'Soup'
console.log(b.foods.dinner) // Soup
console.log(a.foods.dinner) // Pasta
undefined、任意的函数以及symbol作为对象属性值时JSON.stringify()对跳过(忽略)它们进行序列化
undefined、任意的函数以及symbol作为数组元素值时,JSON.stringify()将会将它们序列化为null
undefined、任意的函数以及symbol被JSON.stringify()作为单独的值进行序列化时,都会返回undefined
布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值。
序列化可枚举的属性。
对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
let obj = {
name: 'muyiy',
a: undefined,
b: Symbol('muyiy'),
c: function() {}
console.log(obj);
// name: "muyiy",
// a: undefined,
// b: Symbol(muyiy),
// c: ƒ ()
let b = JSON.parse(JSON.stringify(obj));
console.log(b);
// {name: "muyiy"}
let obj = {
a: 1,
c: 2,
obj.a = obj.b;
obj.b.c = obj.a;
let b = JSON.parse(JSON.stringify(obj));
// Uncaught TypeError: Converting circular structure to JSON
slice.concat 局限性
var arr1 = [{"name":"weifeng"},{"name":"boy"}];//原数组
var arr2 = [].concat(arr1);//拷贝数组
arr1[1].name="girl";
console.log(arr1);// [{"name":"weifeng"},{"name":"girl"}]
console.log(arr2);//[{"name":"weifeng"},{"name":"girl"}
https://www.jianshu.com/p/cf1e9d7e94fb
www.jianshu.com
- 自己实现一个深拷贝
隐式转换
核心语法问题(执行上下文,作用域,作用域链,,this,闭包)
执行上下文的概念
-
什么是执行上下文 :
在初始化堆栈空间后,在执行一段代码后,会生成一个执行上下文。 -
执行上下文的分类
执行上下文包括 全局执行上下文 和函数执行上下文 -
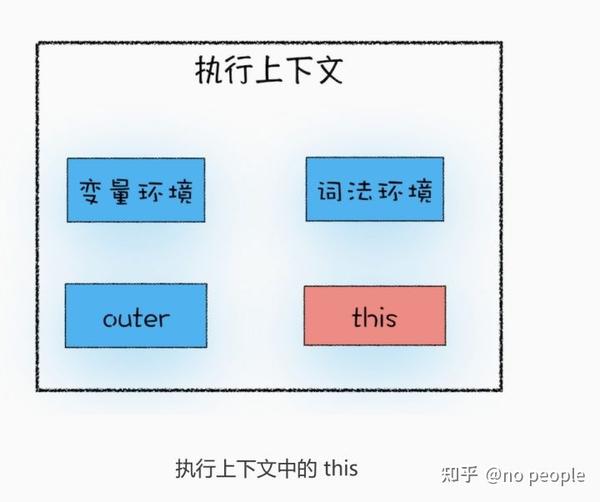
执行上下文都有哪些部分组成
变量环境,词法环境,outer,this 。 let声明的变量都会放在 词法环境 中,在编译时候不会提升。var声明的变量都会放在 变量环境 中。浏览器环境中全局执行上下文具有 window对象,this关键字,webapi setTimeout XMLHttpRequest 内容。词法环境包含 let,const变量的内容。
(JavaScript 代码执行过程中,需要先做变量提升,而之所以需要实现变量提升,是因为 JavaScript 代码在执行之前需要先编译。 在编译阶段,变量和函数会被存放到变量环境中,变量的默认值会被设置为 undefined;在代码执行阶段,JavaScript 引擎会从变量环境中去查找自定义的变量和函 数。 如果在编译阶段,存在两个相同的函数,那么最终存放在变量环境中的是最后定义的那个,这是因为后定义的会覆盖掉之前定义的。)
变量环境 和 词法环境 都是维护的栈结构。
函数执行上下文 和 全局执行上下文都保存栈 中,当函数执行完毕后,调用栈会弹出,所以会出现栈溢出的情况因为 当分配的调用栈空间被占满时,会引发“堆栈溢出”问题。
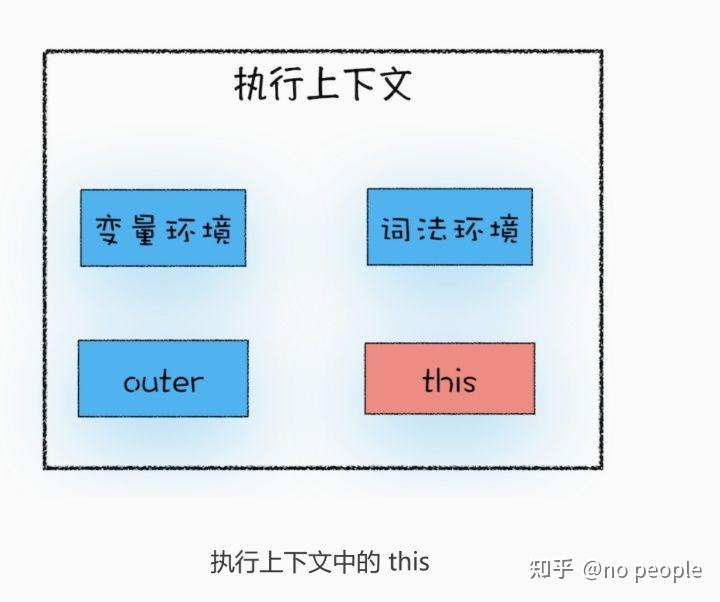
全局执行上下文在 V8 的生存周期内是不会被销毁的,它会一直保存在堆中,这样当下次在 需要使用函数或者全局变量时,就不需要重新创建了。另外,当你执行了一段全局代码时, 如果全局代码中有声明的函数或者定义的变量,那么函数对象和声明的变量都会被添加到全 局执行上下文中
作用域链查找顺序(静态作用域)
1 执行上下文中 变量环境以及词法环境的查找变量的顺序
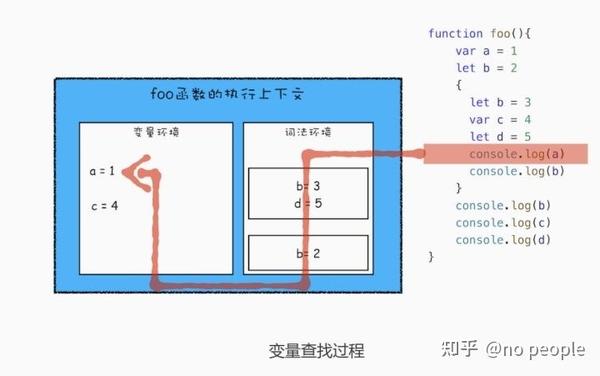
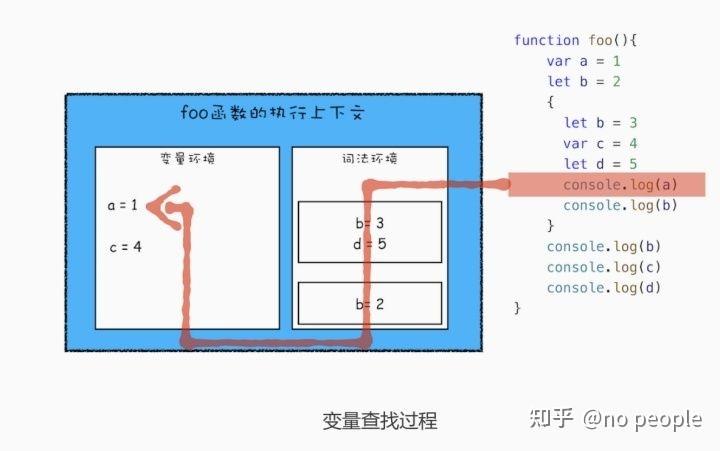
从图中可以看出,当进入函数的作用域块时,作用域块中通过 let 声明的变量,会被存放在词法环境的一个单独的区域中,这个区域中的变量并不影响作用域块外面的变量,比如在作用域外面声明了变量 b,在该作用域块内部也声明了变量 b,当执行到作用域内部时,它们都是独立的存在。其实,在 词法环境内部 , 维护了一个小型栈结构 , 栈底是函数最外层的变量 ,进入一个作用 域块后,就会把 该作用域块内部的变量压到栈顶 ;当作用域执行完成之后,该作用域的信息 就会从栈顶弹出,这就是词法环境的结构。需要注意下,我这里所讲的 变量是指通过 let 或者 const 声明的变量。
需要在词法环境和变 量环境中查找变量 a 的值了,具体查找方式是: 沿着词法环境的栈顶向下查询,如果在词 法环境中的某个块中查找到了,就直接返回给 JavaScript 引擎,如果没有查找到,那么继 续在变量环境中查找。
2 词法作用域的查找顺序,即静态作用域,不带let,带 let 即
如果带 let,其实就是多了一步,在执行上下文查找的时候,先找词法环境,然后在看变量环境
例子:
function bar() {
console.log(myName)
function foo() {
var myName = " 极客邦 "
bar()
var myName = " 极客时间 "
foo()
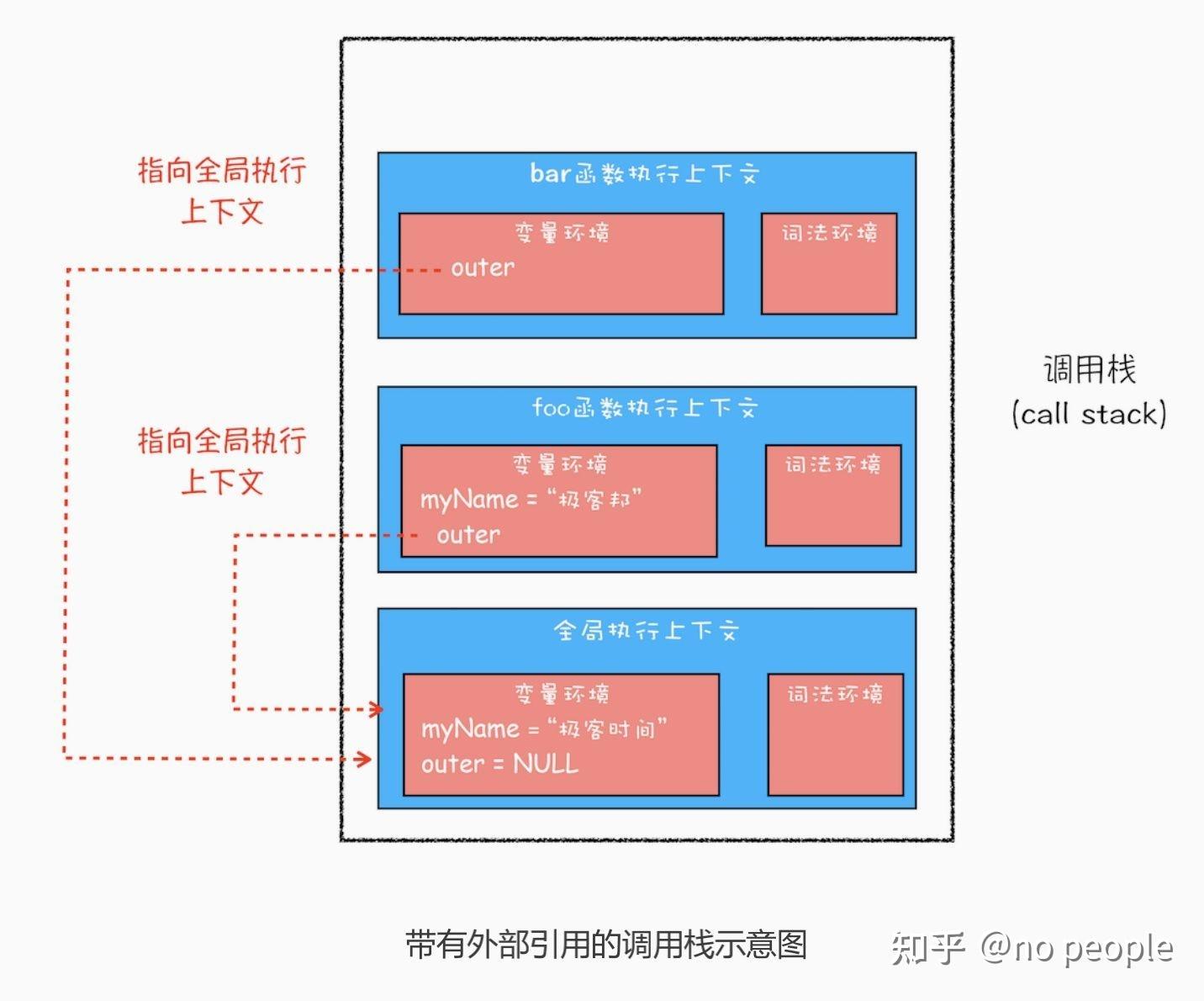
从图中可以看出,bar 函数和 foo 函数的 outer 都是指向全局上下文的,这也就意味着如 果在 bar 函数或者 foo 函数中使用了外部变量,那么 JavaScript 引擎会去全局执行上下文 中查找。我们把这个查找的链条就称为作用域链。 变量是通过作用域链来查找的了,foo 函数调用的 bar 函数,那为什么 bar 函数的外部引用是全局执行上下文,而不是 foo 函数的执行上下文?
要回答这个问题,你还需要知道什么是词法作用域。这是因为在 JavaScript 执行过程中, 其作用域链是由词法作用域决定的。
- 词法作用域(静态作用域)和动态作用域 词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作 用域,通过它就能够预测代码在执行过程中如何查找标识符。
和静态作用域相对的是动态作用域,动态作用域并不关心函数和作用域是如何声明以及在何 处声明的,只关心它们从何处调用。换句话说,动态作用域链是基于调用栈的,而不是基于函数 定义的位置的
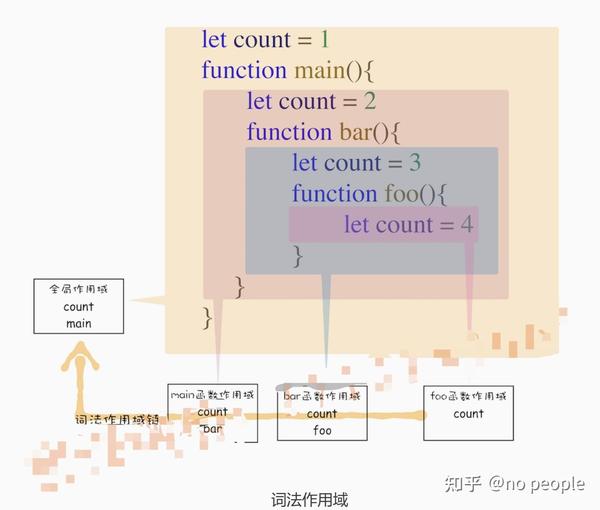
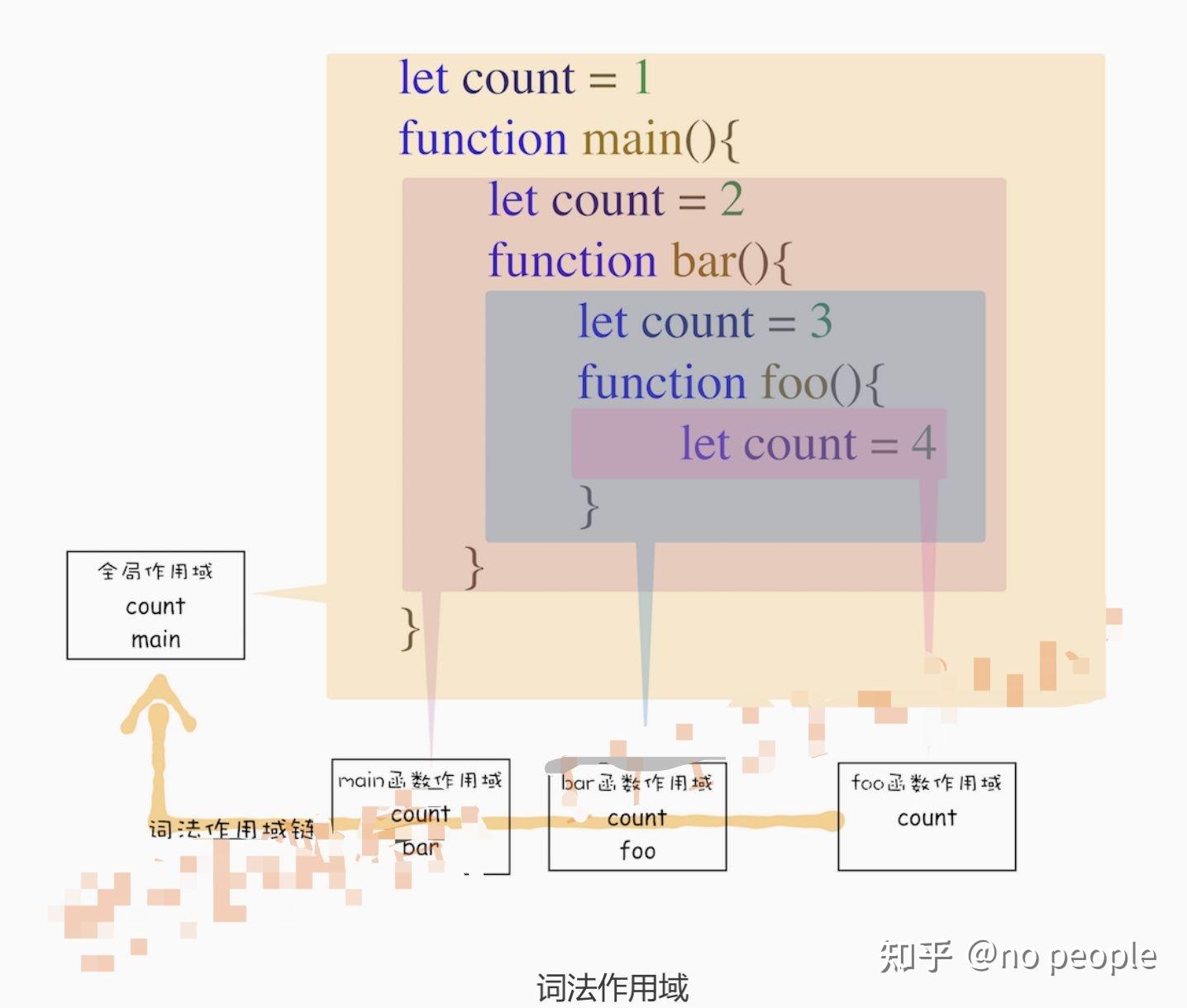
词法作用域就是根据代码的位置来决定的,其中 main 函数包含了 bar 函数,bar 函数中包含了 foo 函数,因为 JavaScript 作用域链是由词法作用域决定的,所 以 整个词法作用域链的顺序是:foo 函数作用域—>bar 函数作用域—>main 函数作用域 —> 全局作用域。 了 解了词法作用域以及 JavaScript 中的作用域链,我们再回过头来看看上面的那个问题: 在开头那段代码中,foo 函数调用了 bar 函数,那为什么 bar 函数的外部引用是全局执行 上下文,而不是 foo 函数的执行上下文? 这是因为根据词法作用域,foo 和 bar 的上级作用域都是全局作用域,所以如果 foo 或者 bar 函数使用了一个它们没有定义的变量,那么它们会到全局作用域去查找。也就是说,词 法作用域是代码阶段就决定好的,和函数是怎么调用的没有关系。
带 let 的 查找顺序
- 块级作用域的变量查找
function bar() {
var myName = " 极客世界 "
let test1 = 100
if (1) {
let myName = "Chrome 浏览器 "
console.log(test)
function foo() {
var myName = " 极客邦 "
let test = 2
let test = 3
bar()
var myName = " 极客时间 "
let myAge = 10
let test = 1
foo()
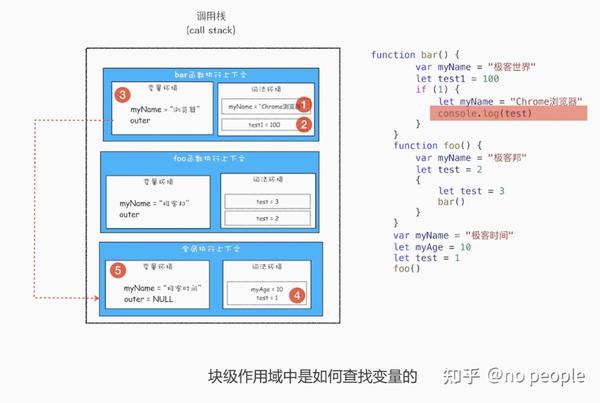
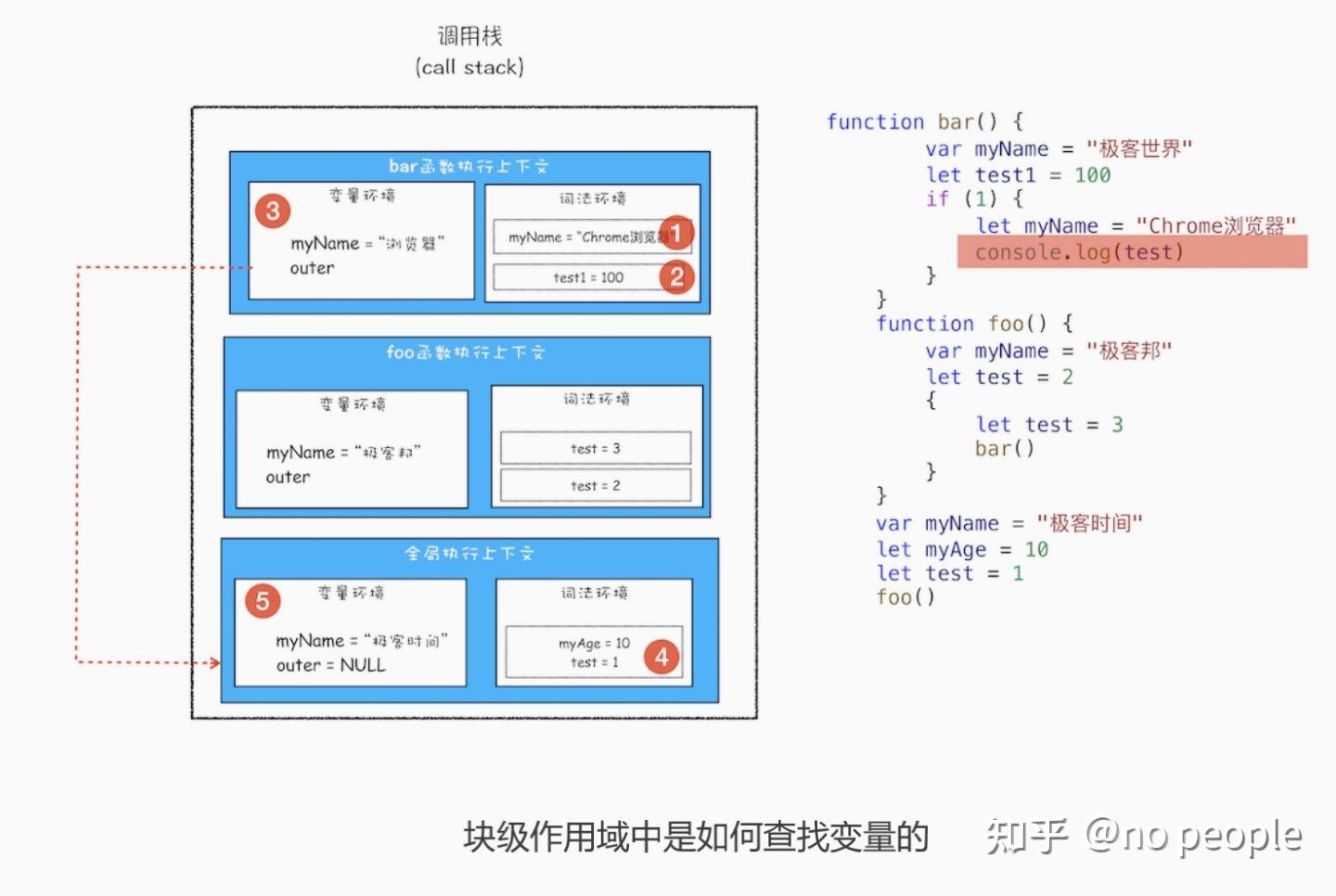
现在是执行到 bar 函数的 if 语块之内,需要打印出来变量 test,那么就需要查找到 test 变 量的值,其查找过程我已经在上图中使用序号 1、2、3、4、5 标记出来了。 下面我就来解释下这个过程。首先是在 bar 函数的执行上下文中查找,但因为 bar 函数的 执行上下文中没有定义 test 变量,所以根据词法作用域的规则,下一步就在 bar 函数的外 部作用域中查找,也就是全局作用域。 至于单个执行上下文中如何查找变量,
this 动态作用域。 11-this:从JavaScript执行上下文的视角讲清楚_~怎么回事啊~的博客-CSDN博客
但是箭头函数是静态作用域
-
为什么会出现this this产生的原因:
总结: - 首先this属于我们执行上下文中的一部分,分为全局执行上下文this,函数执行ia上下文的this,以及evel执行执行上下文的this
- this的出现就是为了弥补js 词法态作用域的缺陷,因为在其他语言中,在对象内部方法中使用对象内部属性是一个非常常见的需求,其他语言例如c都是支持的,但是在js中,对象内部方法中依据静态作用域的特性,访问的其实是全局变量。所以为了弥补js 静态作用域的缺陷,发明了this。this其实是动态作用域,在js执行时候确定。 回答this指向的问题。修改 call apply bind 区别
-
箭头函数的出现是为了解决this指向混乱,不可控的问题。箭头函数的this 本质其实是一种将我们动动态作用域体系转为词法作用域体系。箭头函数不具有自己作用域,指向一般为外层作用域,但是作为函数的属性值,指向window。回答 箭头函数以及普通函数的区别
在这段 C++ 代码中,我同样调用了 bar 对象中的 printName 方法,最后打印出来的值就 是 bar 对象的内部变量 myName 值——“time.geekbang.com”,而并不是最外面定义 变量 myName 的值——“极客邦”,所以在对象内部的方法中使用对象内部的属性是一 个非常普遍的需求。但是 JavaScript 的作用域机制并不支持这一点,基于这个需求, JavaScript 又搞出来另外一套this 机制。
var bar = {
myName:"time.geekbang.com",
printName: function () {
console.log(myName)
function foo() {
let myName = " 极客时间 "
return bar.printName
let myName = " 极客邦 "
let _printName = foo()
_printName()
bar.printName()
相信你已经知道了,在 printName 函数里面使用的变量 myName 是属于全局作用域下面的,所以最终打印出来的值都是“极客邦”。这是因为 JavaScript 语言的作用域链是由词法作用域决定的,而词法作用域是由代码结构来确定的。
不过按照常理来说,调用bar.printName方法时,该方法内部的变量 myName 应该使用 bar 对象中的,因为它们是一个整体,大多数面向对象语言都是这样设计的,比如我用 C++ 改写了上面那段代码,如下所示:
#include <iostream>
using namespace std;
class Bar{
public:
char* myName;
Bar(){
myName = "time.geekbang.com";
void printName(){
cout<< myName <<endl;
} bar;
char* myName = " 极客邦 ";
int main() {
bar.printName();
return 0;
在这段 C++ 代码中,我同样调用了 bar 对象中的 printName 方法,最后打印出来的值就是 bar 对象的内部变量 myName 值——“time.geekbang.com”,而并不是最外面定义变量 myName 的值——“极客邦”,所以在对象内部的方法中使用对象内部的属性是一个非常普遍的需求。但是 JavaScript 的作用域机制并不支持这一点,基于这个需求,JavaScript 又搞出来另外一套this 机制。
所以,在 JavaScript 中可以使用 this 实现在 printName 函数中访问到 bar 对象的 myName 属性了。具体该怎么操作呢?你可以调整 printName 的代码,如下所示:- this 指向的问题
除 箭头函数 外函数的this在其执行时才被确定,指向其调用者。箭头函数的this在定义时就被确定了,箭头函数没有自己的 this 值,箭头函数中所使用的 this 都是来自函数作用域链,箭头函数中的this从上层作用域寻找。
1. 指向window情况,有 直接调用,二级调用 以及 setTimeout
2. 指向调用者
3. new情况:如果返回值是一个对象,那么this指向的就是那个返回的对象,如果返回值不是一个对象那么this还是指向函数的实例。
4. call apply bind影响this的指向指向改变的那个对象
5. 箭头函数this指向 上下文this, 定义时所在的对象, 箭头函数作为对象属性时候的this指向是window
6. 严格模式下 this 指向underfind
补充: 剪头函数的this 指向window
var name = 'window';
var A = {
name: 'A',
sayHello: () => {
console.log(this.name)
A.sayHello();// 还是以为输出A ? 错啦,其实输出的是window
由于对象是作为对象字面量的属性定义的,对象字面量在全局代码中定义,因此,箭头函数内部的this值与全局函数的this值相同
https://zhuanlan.zhihu.com/p/57204184
箭头函数有几个使用注意点。
(1)箭头函数没有自己的this对象(详见下文)。
(2)不可以当作构造函数,也就是说,不可以对箭头函数使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
上面四点中,最重要的是第一点。对于普通函数来说,内部的this指向函数运行时所在的对象,但是这一点对箭头函数不成立。
它没有自己的this对象,内部的this就是定义时上层作用域中的this。也就是说,箭头函数内部的this指向是固定的,
相比之下,普通函数的this指向是可变的。箭头函数实际上可以让this指向固定化,绑定this使得它不再可变,
这种特性很有利于封装回调函数。下面是一个例子,DOM 事件的回调函数封装在一个对象里面。箭头函数里面根本没有自己的this,
而是引用外层的this。
let a = {
c:function(){
console.log(this);
e:()=>{
console.log(this);
d:function(){
console.log(this);
a.b.c(); //c
//在函数作为对象的属性情况下,function函数和箭头函数中的this指向不相同。箭头函数中的this并没有指向调用该函数的对象,而是指向window。
a.b.e(); //window
a.d(); //a
https://blog.csdn.net/cake_eat/article/details/114889279-
修改this 指向的方法 apply,bind,call,区别:
apply第二参数为数组,bind,call第二参数为 按顺序传递参数,第一参数都为要指向的对象。 2 bind 绑定后需要手动调用才可以执行,apply,call 是执行变化后立即执行。
- this的缺陷
- 嵌套函数中的 this 不会从外层函数中继承
我认为这是一个严重的设计错误,并影响了后来的很多开发者,让他们“前赴后继”迷失在 该错误中。我们还是结合下面这样一段代码来分析下:
var myObj = {
name : " 极客时间 ",
showThis: function(){
console.log(this)
function bar(){
console.log(this)
// var self = this
// function bar(){
// self.name = " 极客邦 "
// var bar = ()=>{
// this.name = " 极客邦 "
// console.log(this)
bar()
myObj.showThis()
你会发现函数 bar 中的 this 指向的是全局 window 对象,而函数 showThis 中的 this 指向的是 myObj 对象。这就是 JavaScript
中非常容 易让人迷惑的地方之一,也是很多问题的源头。 你可以通过一个小技巧来解决这个问题,比如在 showThis 函数中声明一个变量 self 用来
保存 this,然后在 bar 函数中使用 self:
最终 myObj 中的 name 属性值变 成了“极客邦”。其实,这个方法的的本质是把 this 体系转换为了作用域的体系。 其实,
你也可以使用 ES6 中的箭头函数来解决这个问题,结合下面代码:
执行这段代码,你会发现它也输出了我们想要的结果,也就是箭头函数 bar 里面的 this 是 指向 myObj 对象的。
这是因为 ES6 中的箭头函数并不会创建其自身的执行上下文,所以 箭头函数中的 this 取决于它的外部函数。 通过上面的讲解,
你现在应该知道了 this 没有作用域的限制,这点和变量不一样,所以嵌 套函数不会从调用它的函数中继承 this,这样会造成很多
不符合直觉的代码。要解决这个 问题,你可以有两种思路: 第一种是把 this 保存为一个 self 变量,再利用变量的作用域机制传递
给嵌套函数。第二种是继续使用 this,但是要把嵌套函数改为箭头函数,因为箭头函数没有自己的执 行上下文,所以它会继承调用函数中的 this。2 普通函数中的 this 默认指向全局对象 window
上面我们已经介绍过了,在默认情况下调用一个函数,其执行上下文中的 this 是默认指向 全局对象 window 的。 不过这个设计也是一种缺陷,因为在实际工作中,我们并不希望函数执行上下文中的 this 默认指向全局对象,因为这样会打破数据的边界,造成一些误操作。如果要让函数执行上下 文中的 this 指向某个对象,最好的方式是通过 call 方法来显示调用。 这个问题可以通过设置 JavaScript 的“严格模式”来解决。在严格模式下,默认执行一个 函数,其函数的执行上下文中的 this 值是 undefined,这就解决上面的问题了
变量提升
Const:const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。为了保证对象属性也不可更改可以使用冻结const foo = Object.freeze({}),比如将一个对象给const就会报错/
let 特点: 块级作用域,不存在变量提升, 暂时性死区, let、const声明的变量不会被挂载到window下
let之前模拟块级作用域?匿名函数模拟
没有块级作用域的危害:1 内层变量可能会覆盖外层变量。2 循环变量泄漏为全局变量
let const 声明的变量也不可以被delete删除
块级作用域对函数的影响: 为了兼容老代码,在块级作用域中声明函数,函数声明类似于var,即会提升到全局作用域或函数作用域的头部。所以我们在声明函数时候应尽量使用函数表达式方法声明函数
Const:const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。为了保证对象属性也不可更改可以使用冻结const foo = Object.freeze({});
const foo = {};
// 为 foo 添加一个属性,可以成功
foo.prop = 123;
foo.prop // 123
// 将 foo 指向另一个对象,就会报错
foo = {}; // TypeError: "foo" is read-only
function(){
//块级作用域
var a = [];
for (var i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
a[6](); // 10
var tmp = new Date();
function f() {
console.log(tmp);
if (false) {
var tmp = 'hello world';
f(); // undefined
- 变量提升带来的问题 变量提升带来的问题?
var myname = " 极客时间 "
function showName(){
console.log(myname);
if(0){
var myname = " 极客邦 "
console.log(myname);
showName()
1 变量在不察觉情况下被覆盖掉
这输出的结果和其他大部分支持块级作用域的语言都不一样,比如上面 C 语言输出的就是 全局变量,所以这会很容易造成误解,特别是在你会一些其他语言的基础之上,再来学JavaScript,你会觉得这种结果很不自然。
2 本应销毁变量没有被销毁
function foo(){
for (var i = 0; i < 7; i++) {
console.log(i);
foo()
如果你使用 C 语言或者其他的大部分语言实现类似代码,在 for 循环结束之后,i 就已经被 销毁了,但是在 JavaScript 代码中,i 的值并未被销毁,所以最后打印出来的是 7。这同样也是由变量提升而导致的,在创建执行上下文阶段,变量 i 就已经被提升了,所以当 for 循环结束之后,变量 i 并没有被销毁。 这依旧和其他支持块级作用域的语言表现是不一致的,所以必然会给一些人造成误解。
闭包
- 闭包的定义
是在一个函数内部创建另一个函数。你可以说内部函数访问内部函数外的变量,导致变量不会被GC机制回收。
- 闭包的优点以及缺点?
优点: 定义私有变量和方法,不污染全局环境;
javascript 没有 java 中那种 public private 的访问权限控制,对象中的所用方法和属性均可以
访问,这就造成了安全隐患,内部的属性任何开发者都可以随意修改。虽然语言层面不支持私有属性的创建,
但是我们可以用闭包的手段来模拟出私有属性:
// 模拟私有属性
function getGeneratorFunc () {
var _name = 'John';
var _age = 22;
return function () {
return {
getName: function () {return _name;},
getAge: function() {return _age;}
var obj = getGeneratorFunc()();
obj.getName(); // John
obj.getAge(); // 22
obj._age; // undefined缺点: 内存泄漏,
- 造成内存泄漏 除了 闭包外
https:// juejin.cn/post/69841884 10659340324
1 意外的全局变量,全局变量不容易被GC回收,误将局部变量设置为全局变量
函数中的局部变量在函数执行结束后这些变量已经不再被需要,所以垃圾回收器会识别并释放它们。但是对于全局变量,
垃圾回收器很难判断这些变量什么时候才不被需要,所以全局变量通常不会被回收,我们使用全局变量是 OK 的,
但同时我们要避免一些额外的全局变量产生
2 还有 DOM元素忘记注销掉其中绑定的事件方法,未调用 removeEventListener
3 setInterval,setTimeout,requestAnimationFrame 定时器未调用 clearInterval,clearTimeout,cancelAnimationFrame
方法去销毁
4 警惕 遗忘的Set和map 对 对象的引用,set map 都是强引用,我们手动销毁对象后,set,map依旧会引用,不会被回收,
应该尽量使用weakMap和weakSet
let obj = {id: 1}
let weakSet = new WeakSet([obj])
let weakMap = new WeakMap([[obj, 'hahaha']])
// 重写obj引用
obj = null
// {id: 1} 将在下一次 GC 中从内存中删除
5 未清理的console
如何分析内存泄漏,具体看浏览器章节,这里简单说一下方法
定位:观察performance的js heap 如果内存在一次gc回收后,内存一直处于短短嘘嘘上升状态就说明存在内存泄漏
分析: Memory tab Summary 选项切换为 comparison 选项,也就是对比当前快照与之前一次快照的内存区别
下方的表格代表
New:新建了多少个对象
Deleted:回收了多少个对象
Delta:新建的对象数 减去 回收的对象数,重点关注 Delta ,只要它是正数就可能存在问题
https://juejin.cn/post/6984188410659340324#heading-12-
闭包的应用场景
JS 闭包经典使用场景和含闭包必刷题 - 掘金
1 节流防抖用闭包 2 自执行函数 3 函数作为参数 4 函数 return 函数
- 闭包的原理是 作用域链 ,闭包中是如何执行作用域链的
function foo() {
var myName = " 极客时间 "
let test1 = 1
const test2 = 2
var innerBar = {
getName:function(){
console.log(test1)
return myName
setName:function(newName){
myName = newName
return innerBar
var bar = foo()
bar.setName(" 极客邦 ")
bar.getName()
console.log(bar.getName())
首先我们看看当执行到 foo 函数内部的return innerBar这行代码时调用栈的情况,
innerBar 是一个对象,包含了 getName 和 setName 的两个方 法(通常我们把对象内部的函数称为方法)。这两个方法都是在 foo 函数内 部定义的,并且这两个方法内部都使用了 myName 和 test1 两个变量。 根据词法作用域的规则,内部函数 getName 和 setName 总是可以访问它们的外部函数 foo 中的变量,所以当 innerBar 对象返回给全局变量 bar 时,虽然 foo 函数已经执行结束,但是 getName 和 setName 函数依然可以使用 foo 函数中的变量 myName 和 test1。所以当 foo 函数执行完成之后,其整个调用栈的状态如下图所示:
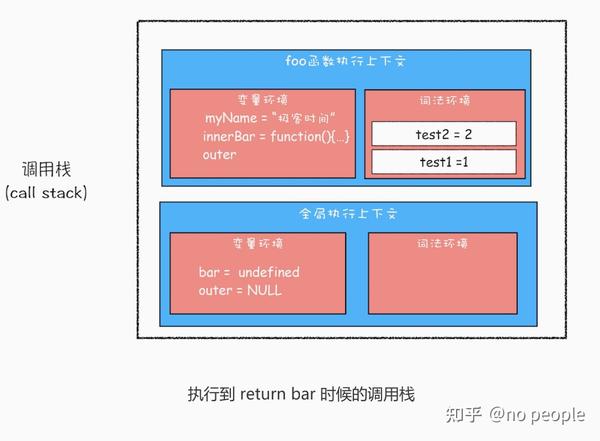
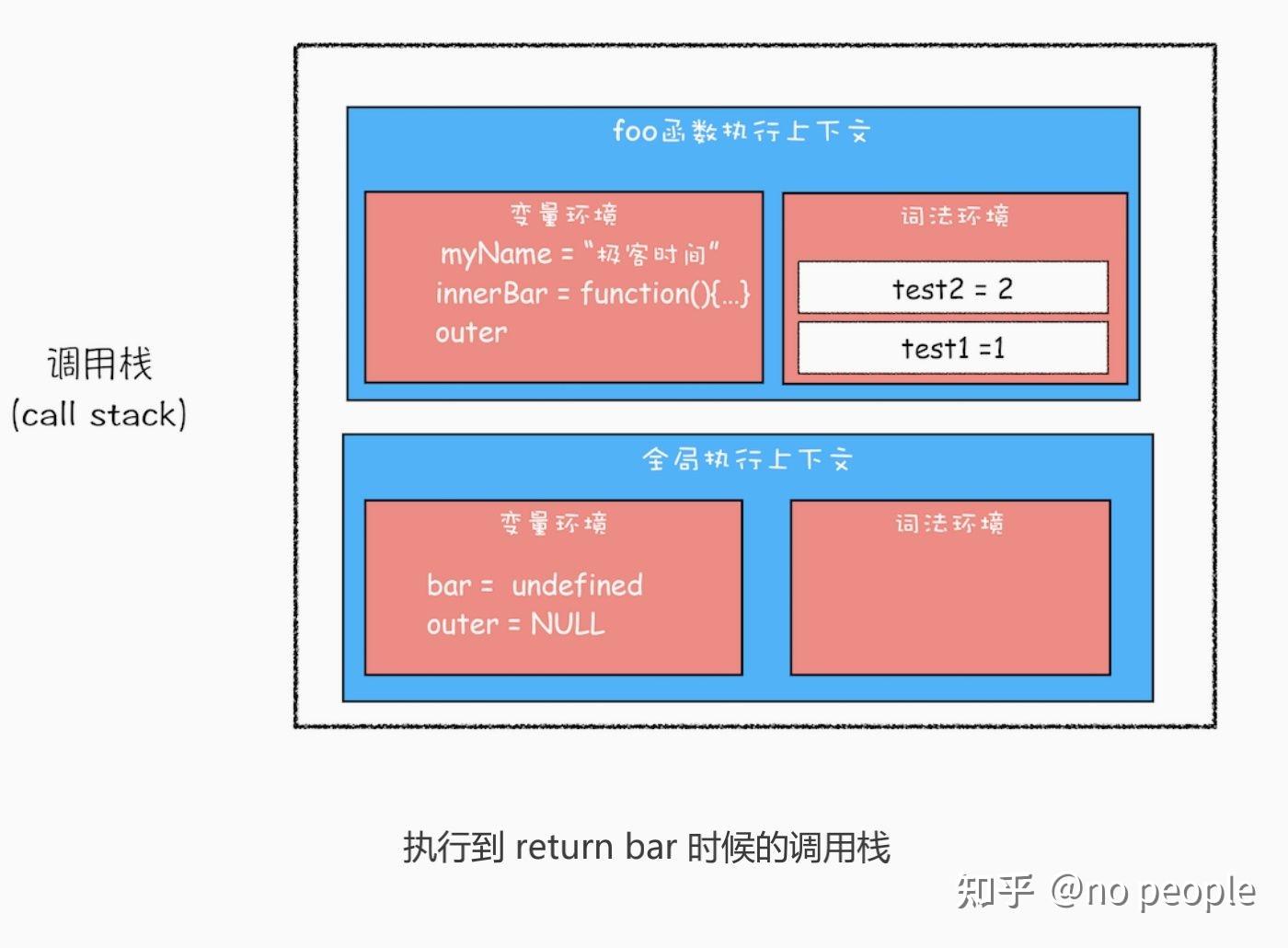
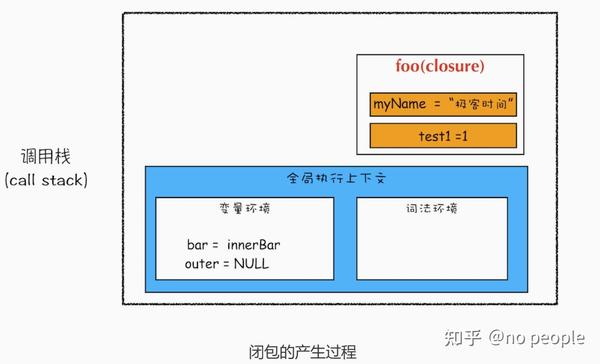
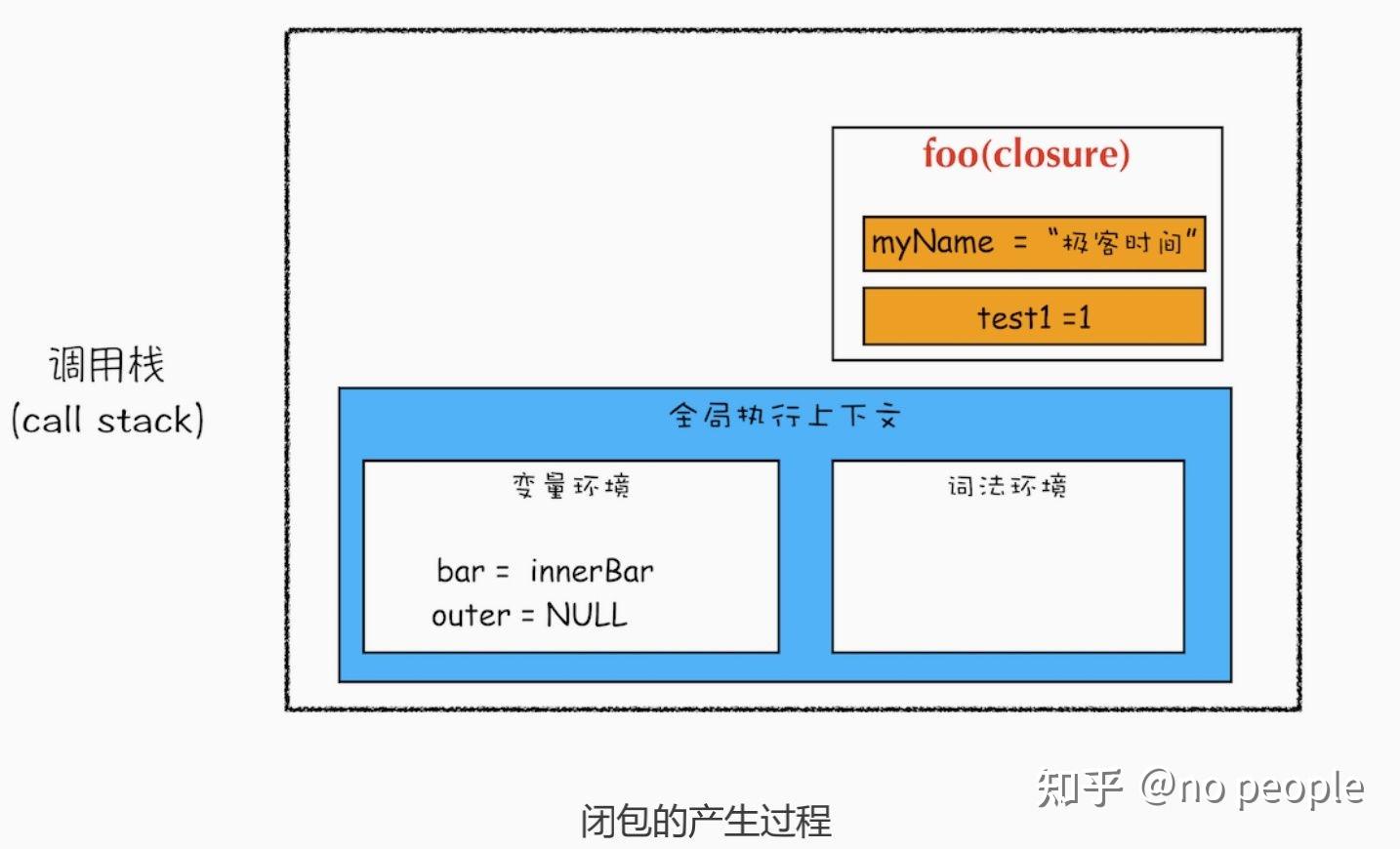
从上图可以看出,foo 函数执行完成之后,其执行上下文从栈顶弹出了,但是由于返回的 setName 和 getName 方法中使用了 foo 函数内部的变量 myName 和 test1,所以这两 个变量依然保存在内存中。这像极了 setName 和 getName 方法背的一个专属背包,无论 在哪里调用了 setName 和 getName 方法,它们都会背着这个 foo 函数的专属背包。 之所以是专属背包,是因为除了 setName 和 getName 函数之外,其他任何地方都是无法 访问该背包的,我们就可以把这个背包称为 foo 函数的闭包。
在 JavaScript 中,根据词法作用域的 规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个 内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集 合就称为 foo 函数的闭包。
那这些闭包是如何使用的呢?当执行到 bar.setName 方法中的myName = "极客邦"这句 代码时,JavaScript 引擎会沿着“当前执行上下文–>foo 函数闭包–> 全局执行上下文”的 顺序来查找 myName 变量,你可以参考下面的调用栈状态图:
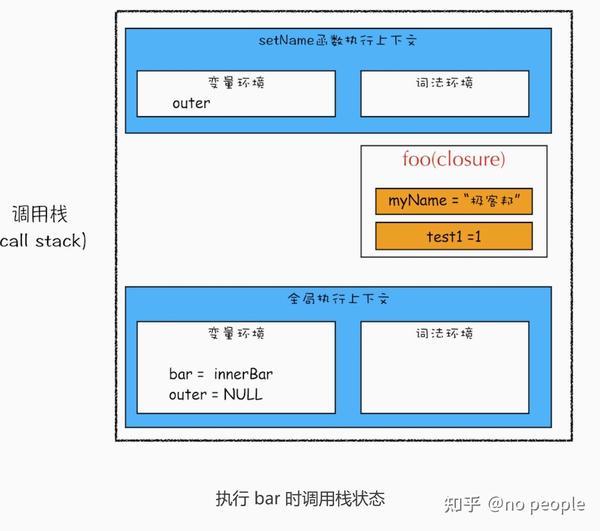
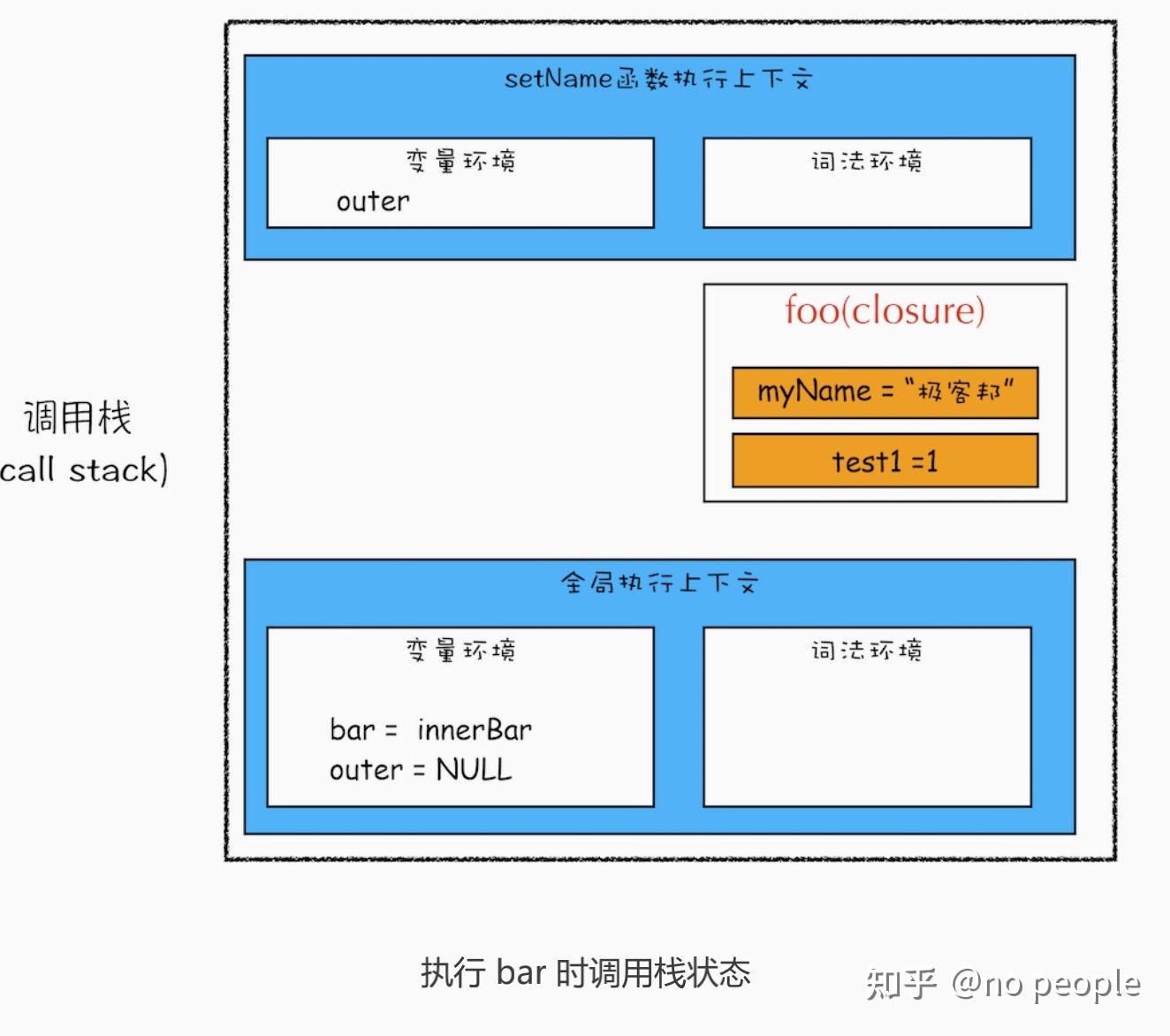
从图中可以看出,setName 的执行上下文中没有 myName 变量,foo 函数的闭包中包含 了变量 myName,所以调用 setName 时,会修改 foo 闭包中的 myName 变量的值。 同样的流程,当调用 bar.getName 的时候,所访问的变量 myName 也是位于 foo 函数闭 包中的。 你也可以通过“开发者工具”来看看闭包的情况,打开 Chrome 的“开发者工具”,在 bar 函数任意地方打上断点,然后刷新页面,可以看到如下内容:
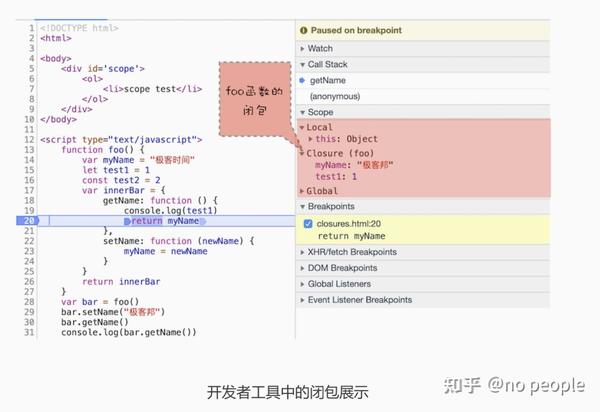
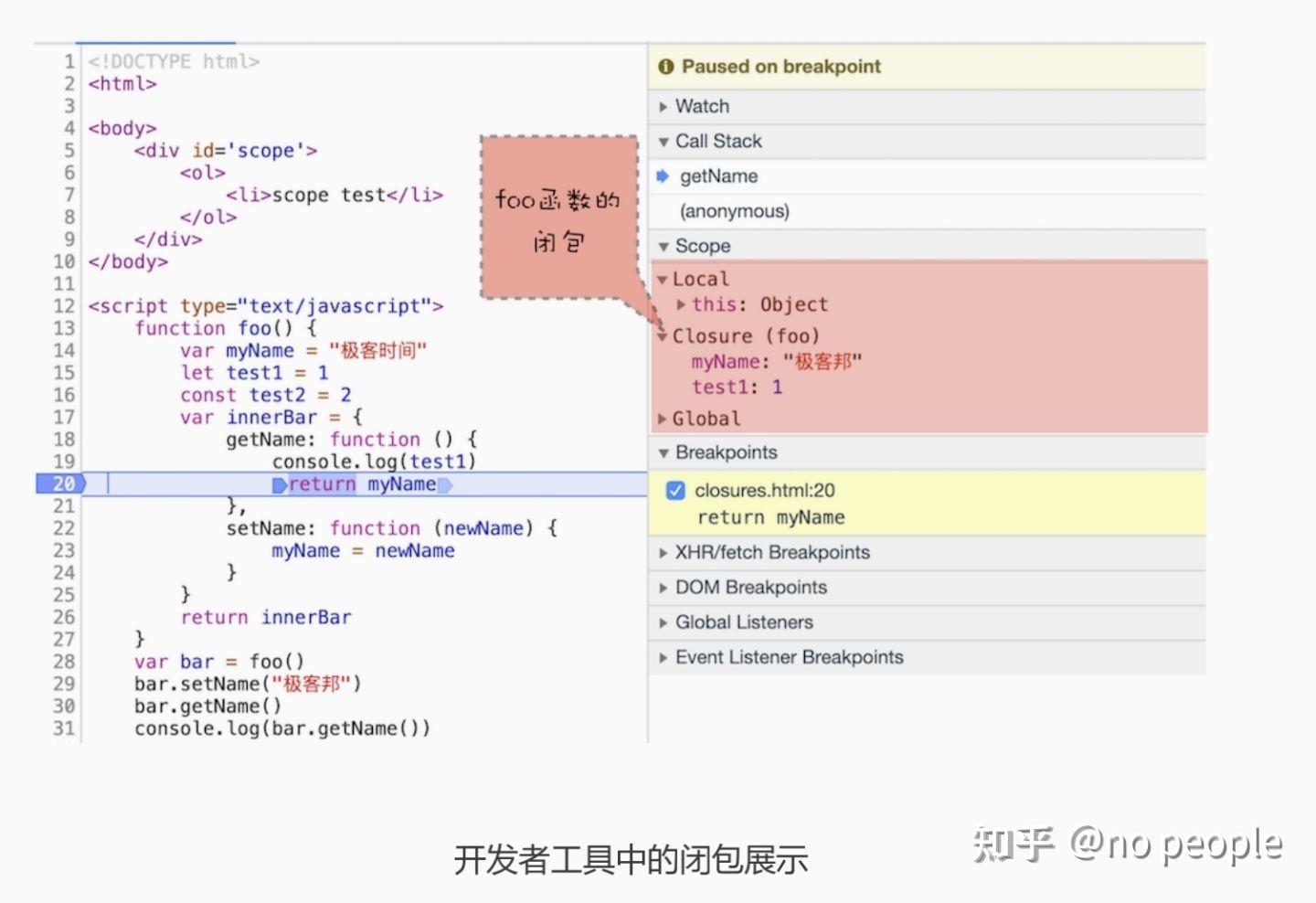
从图中可以看出来,当调用 bar.getName 的时候,右边 Scope 项就体现出了作用域链的 情况:Local 就是当前的 getName 函数的作用域,Closure(foo) 是指 foo 函数的闭包, 最下面的 Global 就是指全局作用域,从“Local–>Closure(foo)–>Global”就是一个完整 的作用域链。 所以说,你以后也可以通过 Scope 来查看实际代码作用域链的情况,这样调试代码也会比 较方便。
闭包面试题: https:// juejin.cn/post/68449034 74212143117
1 for (var i = 0; i < 5; i++) {
setTimeout(function() {
console.log(new Date, i);
}, 1000);
console.log(new Date, i); 打印 5,5,5,5,5,5,时间 分别是 先打印e1一个 5 ,然后一起出来 5个 5
2017-03-18T00:43:45.873Z 5
2017-03-18T00:43:46.866Z 5
2017-03-18T00:43:46.868Z 5
2017-03-18T00:43:46.868Z 5
2017-03-18T00:43:46.868Z 5
2017-03-18T00:43:46.868Z 5
2 期望输出 5 0,1,2,3,4 怎么改
for (var i = 0; i < 5; i++) {
(function(j) { // j = i
setTimeout(function() {
console.log(new Date, j);
}, 1000);
})(i);
console.log(new Date, i);
var output = function (i) {
setTimeout(function() {
console.log(new Date, i);
}, 1000);
for (var i = 0; i < 5; i++) {
output(i); // 这里传过去的 i 值被复制了
console.log(new Date, i);
for (var i = 0; i < 5; i++) {
setTimeout(function(j) {
console.log(new Date, j);
}, 1000, i);
console.log(new Date, i);
3 如果期望代码的输出变成 0 -> 1 -> 2 -> 3 -> 4 -> 5,并且要求原有的代码块中的循环和两处 console.log 不变,
该怎么改造代码?新的需求可以精确的描述为:代码执行时,立即输出 0,之后每隔 1 秒依次输出 1,2,3,4,
循环结束后在大概第 5 秒的时候输出 5
const tasks = [];
for (var i = 0; i < 5; i++) { // 这里 i 的声明不能改成 let,如果要改该怎么做?
((j) => {
tasks.push(new Promise((resolve) => {
setTimeout(() => {
console.log(new Date, j);
resolve(); // 这里一定要 resolve,否则代码不会按预期 work
}, 1000 * j); // 定时器的超时时间逐步增加
})(i);
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(new Date, i);
}, 1000); // 注意这里只需要把超时设置为 1 秒
const tasks = []; // 这里存放异步操作的 Promise
const output = (i) => new Promise((resolve) => {
setTimeout(() => {
console.log(new Date, i);
resolve();
}, 1000 * i);
// 生成全部的异步操作
for (var i = 0; i < 5; i++) {
tasks.push(output(i));
// 异步操作完成之后,输出最后的 i
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(new Date, i);
}, 1000);
4 使用 何使用 ES7 中的 async/await 特性来让这段代码变的更简洁?
// 模拟其他语言中的 sleep,实际上可以是任何异步操作
const sleep = (timeountMS) => new Promise((resolve) => {
setTimeout(resolve, timeountMS);
(async () => { // 声明即执行的 async 函数表达式
for (var i = 0; i < 5; i++) {
if (i > 0) {
await sleep(1000);
console.log(new Date, i);
await sleep(1000);
console.log(new Date, i);
})();原型链
function Foo(){} ====> 这是构造函数(用来初始化新创建的对象的函数叫做构造函数)
var f1 = new Foo ====> 实例对象 (通过构造函数的new操作创建的对象是实例对象,可以一个构造函数,构造多个实例对象)
Foo.prototype ====>原型对象(实例对象的原型对象);
记忆步骤:6 条线
1 实例对象 f1
2 原型对象 Foo.prototype
3 Object.prototype
4 构造函数 Foo
5 Function.prototype
6 Object
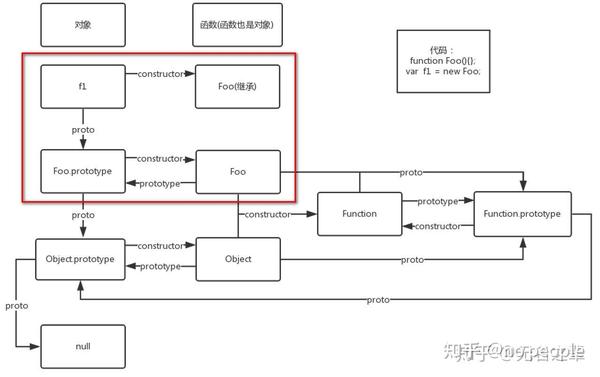
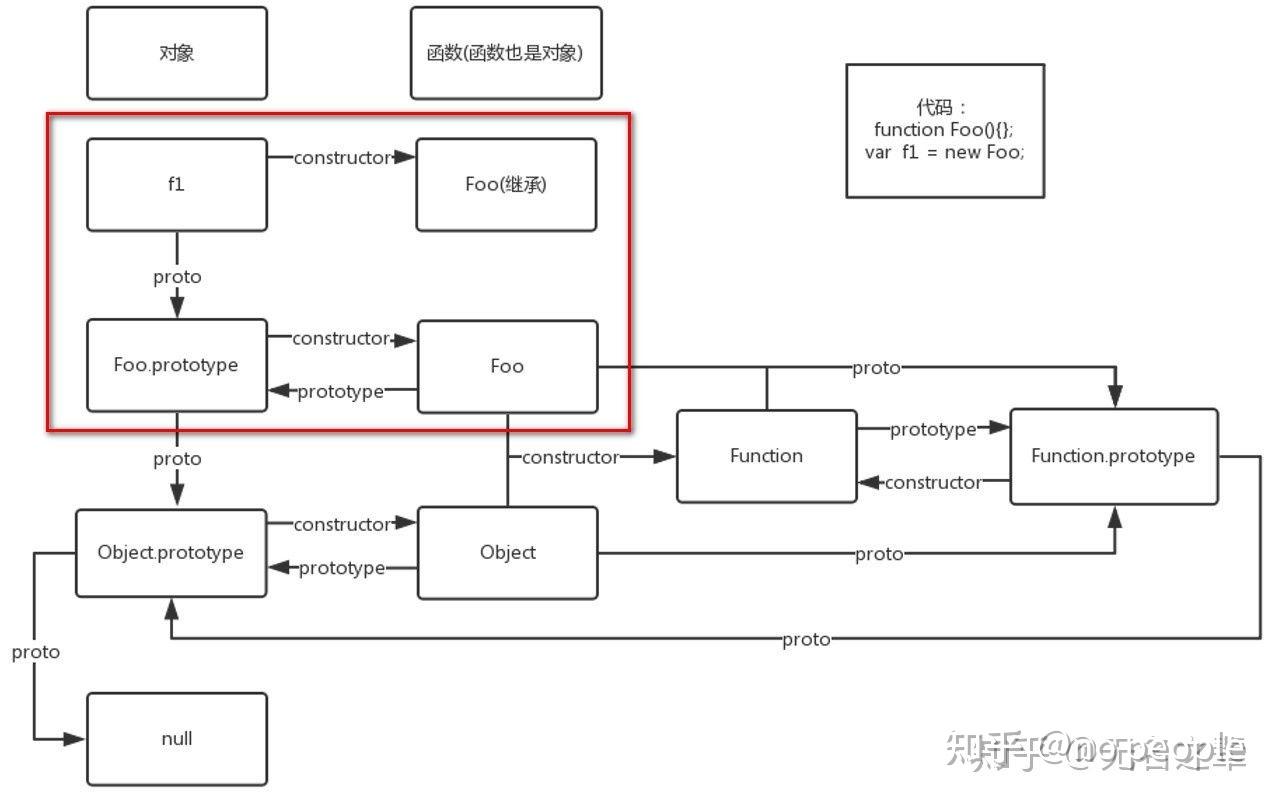
实例对象f1本身并没有constructor属性,但它可以继承原型对象Foo.prototype的constructor属性
function Foo(){};
var f1 = new Foo;console.log(Foo.prototype.constructor === Foo);//true
console.log(f1.constructor === Foo);//true
console.log(f1.hasOwnProperty('constructor'));//false
原型与原型链的面试题: https:// juejin.cn/post/69430358 36691087397
function Foo() {
getName = function() {
console.log(1)
return this
Foo.getName = function() {
console.log(2)
Foo.prototype.getName = function() {
console.log(3)
var getName = function() {
console.log(4)
function getName() {
console.log(5)
Foo.getName();
getName();
Foo().getName();
getName()
new Foo.getName();
new Foo().getName();
在变量提升阶段带 var 和 function 都会变量提升,两则的区别在于 var 只声明为 undefined 不定义,function 的同时声明和定义。同名的 getName 会先声明和定义赋值一个函数的推内存地址,也就是上面输出 console.log(5) 的函数地址,在 JS 代码执行后 getName 被重新赋值一个新堆内存地址 console.log(4)。Foo.getName() 就是函数作为对象的调用,1中的输出就是2;
2 中 getName() 输出就是4,因为 getName() 的引用地址是 console.log(4)中的;
3 中 Foo().getName(),Foo()执行后全局下的 getName 引用地址再次改变成 console.log(1) 且返回了 this指向 window 输出结果就是1;
4 中getName是全局下的,输出自然是也是1;
5中 new Foo.getName() 函数执行输出 2;
6 中new Foo().getName() => new A.getName(),先对 new Foo() 实例化再对 A.getName() 调用,对 new Foo() 实例化调用的 getName() 方法是原型 prototype 上的,输出就是 3;
7 中 new new Foo().getName() => new B.getName(),先对 new Foo() 实例化再对 new B.getName() 实例化,new B.getName() 同时也在执行 B.getName() 方法输出的还是实例 B 上的方法也就是原型 prototype 的 getName。
2 某腾原型重定向面试题,求下面输出结果
function Fn(){
var n = 10
this.m = 20
this.aa = function() {
console.log(this.m)
Fn.prototype.bb = function () {
console.log(this.n)
var f1 = new Fn
Fn.prototype = {
aa: function(){
console.log(this.m + 10)
var f2 = new Fn
console.log(f1.constructor) // ==> function Fn(){...}
console.log(f2.constructor) // ==> Object() { [native code] }
f1.bb() // undefined
f1.aa() // 20
f2.aa() // 20
f2.__proto__.aa() // NaN
f2.bb() // Uncaught TypeError: f2.bb is not a function
3 某腾的一道原型个原型链面试题,求下面输出结果
function fun(){
this.a = 0
this.b = function(){
alert(this.a)
fun.prototype = {
b: function(){
this.a = 20
alert(this.a)
c: function (){
this.a = 30
alert(this.a)
var my_fun = new fun()
my_fun.b() // 0
my_fun.c() // 30继承方式,并描述缺点
- 原型链继承
- 构造继承
- 组合继承
- 原型式继承
- 寄生式继承
- 寄生组合继承
- JS继承的实现方式
既然要实现继承,那么首先我们得有一个父类,代码如下:
// 定义一个动物类
function Animal (name) {
// 属性
this.name = name || 'Animal';
// 实例方法
this.sleep = function(){
console.log(this.name + '正在睡觉!');
// 原型方法
Animal.prototype.eat = function(food) {
console.log(this.name + '正在吃:' + food);
1、原型链继承
核心: 将父类的实例作为子类的原型
function Cat(){
Cat.prototype = new Animal();
Cat.prototype.name = 'cat';
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.eat('fish'));
console.log(cat.sleep());
console.log(cat instanceof Animal); //true
console.log(cat instanceof Cat); //true
缺点:
1 可以在Cat构造函数中,为Cat实例增加实例属性。如果要新增原型属性和方法,则必须放在new Animal()这样的语句之后执行。不能放在构造器里面
2 来自原型对象的所有属性被所有实例共享。
非常纯粹的继承关系,实例是子类的实例,也是父类的实例 父类新增原型方法/原型属性,子类都能访问到 简单,易于实现 缺点:
要想为子类新增属性和方法,必须要在new Animal()这样的语句之后执行,不能放到构造器中 无法实现多继承
来自原型对象的所有属性被所有实例共享(来自原型对象的引用属性是所有实例共享的)(详细请看附录代码: 示例1)
创建子类实例时,无法向父类构造函数传参
1 创建子类实例无法向父类构造函数传参。(如果传参后,父类的属性将成为子类原型属性,不属于子类实例属性不符合面向对象规范)
2 由于子类原型中包含父类的属性,子类所有实例都共享这些属性,当某个实例修改引用类型属性,其他实例的这个引用属性也一同被修改。链接
Child.prototype = new Parent();
var Person1 = new Child();
Person1.newArr.push("kuli");
console.log(Person1.newArr); // ["heyushuo","kebi","kuli"]
var Person2 = new Child();
console.log(Person2.newArr); // ["heyushuo","kebi","kuli"]
推荐指数:★★(3、4两大致命缺陷)
2017-8-17 10:21:43补充:感谢 MMHS 指出。缺点1中描述有误:可以在Cat构造函数中,为Cat实例增加实例属性。如果要新增原型属性和方法,则必须放在new Animal()这样的语句之后执行。
2018-9-10 00:03:45补充:感谢 IRVING_J 指出。缺点3中的描述不够充分。更正为:来自原型对象的所有属性被所有实例共享。
2、构造继承
核心:使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
function Cat(name){
Animal.call(this,name);
this.name = name || 'Tom';
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // false
console.log(cat instanceof Cat); // true
特点:
解决了1中,子类实例共享父类引用属性的问题 创建子类实例时,可以向父类传递参数 可以实现多继承(call多个父类对象) 缺点:
实例并不是父类的实例,只是子类的实例
只能继承父类的实例属性和方法,不能继承原型属性/方法
无法实现函数复用,每个子类都有父类实例函数的副本,影响性能
构造函数继承解决了原型链继承中不可以给父类传参数的问题,同时因为借用父类的属性,所以每次new一个子实例都是新的一份父实例属性副本。
缺点:在父类型构造函数(testFun)以及原型(getSuperValue)中各定义一个方法,子实例只能调用构造函数中方法(testFun)
推荐指数:★★(缺点3)
3、组合继承
核心:通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用
function Cat(name){
Animal.call(this);
this.name = name || 'Tom';
Cat.prototype = new Animal();
// 感谢 @学无止境c 的提醒,组合继承也是需要修复构造函数指向的。
Cat.prototype.constructor = Cat;
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // true
console.log(cat instanceof Cat); // true
特点:
弥补了方式2的缺陷,可以继承实例属性/方法,也可以继承原型属性/方法
既是子类的实例,也是父类的实例
不存在引用属性共享问题
可传参
函数可复用
缺点:
调用了两次父类构造函数,生成了两份实例(子类实例将子类原型上的那份屏蔽了) 推荐指数:★★★★(仅仅多消耗了一点内存)
特点:弥补了原型链继承的引用属性共享问题以及不可以给父类传参问题,同时解决了方式二构造函数继承中 子类实例不可以继承父类原型中方法问题,既可以继承构造函数以及原型中方法。
缺点:两次调用父类构造函数,子类继承父类的属性,一组在子类实例上,一组在子类原型上,造成多余的属性,实例上的屏蔽原型上的同名属性。
3、实例继承(原型式继承)
核心:为父类实例添加新特性,作为子类实例返回
function Cat(name){
var instance = new Animal();
instance.prototype = name || 'Tom';
return instance;
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // true
console.log(cat instanceof Cat); // false
特点:
不限制调用方式,不管是new 子类()还是子类(),返回的对象具有相同的效果 缺点:
实例是父类的实例,不是子类的实例
不支持多继承
原型式继承的的实现方法与普通继承的实现方法不同,原型式继承并没有使用严格意义上的构造函数,而是借 助原型可以基于已有的对象创建新对象,同时还不必因此创建自定义类型。
缺点:和原型链继承一样,所有实例都会继承父类原型上的属性
给原型添加属性后,所有实例都会所有实例都会继承原型上的属性; 无法实现复用 。
4、寄生式继承
给原型式继承套了个壳子。
function object(o) {
function F() { }
F.prototype = o;
return new F();
/* 寄生式继承 */
function createAnother(original) {
var clone = object(original);
clone.sayHi = function () {
alert('hi');
console.log(clone);
return clone;
var person = {
name: 'wuyuchang',
friends: ['yzy', 'Nick', 'Rose']
var anotherPerson = createAnother(person);
缺点:和原型式继承一样,子实例共享父实例的属性
6、寄生组合继承
核心:通过寄生方式,砍掉父类的实例属性,这样,在调用两次父类的构造的时候,就不会初始化两次实例方法/属性,避免的组合继承的缺点
function Cat(name){
Animal.call(this);
this.name = name || 'Tom';
(function(){
// 创建一个没有实例方法的类
var Super = function(){};
Super.prototype = Animal.prototype;
//将实例作为子类的原型
Cat.prototype = new Super();
})();
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // true
console.log(cat instanceof Cat); //true
感谢 @bluedrink 提醒,该实现没有修复constructor。
Cat.prototype.constructor = Cat; // 需要修复下构造函数
特点:
堪称完美 缺点:
实现较为复杂 推荐指数:★★★★(实现复杂,扣掉一颗星)
- es6的构造函数以及继承 理解es6 class构造以及继承的底层实现原理 链接 类的实现
class Parent {
constructor(a){
this.filed1 = a;
filed2 = 2;
func1 = function(){}
// babel转后
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
var Parent = function Parent(a) {
_classCallCheck(this, Parent);
this.filed2 = 2;
this.func1 = function () { };
this.filed1 = a;
class的底层依然是构造函数,
首先调用_classCallCheck来检查是否通过new函数来调用函数,如果有 person(实例对象) instanceof Perent 返回的肯定是true,如果没有返回时false,报错。 将class内部的变量和函数赋给this 执行constuctor内部的逻辑。 return this (构造函数默认在最后我们做了)。 继承实现
class Child extends Parent {
constructor(a,b) {
super(a);
this.filed3 = b;
filed4 = 1;
func2 = function(){}
// babel转后
var Child = function (_Parent) {
_inherits(Child, _Parent);
function Child(a, b) {
_classCallCheck(this, Child);
var _this = _possibleConstructorReturn(this, (Child.__proto__ || Object.getPrototypeOf(Child)).call(this, a));
_this.filed4 = 1;
_this.func2 = function () {};
_this.filed3 = b;
return _this;
return Child;
}(Parent);
调用_inherits函数继承父类的proptype
- 校验父构造函数。
(2) 典型的寄生继承:用父类构造函数的proptype创建一个空对象,并将这个对象指向子类构造函数的proptype。
用一个闭包保存父类引用,在闭包内部做子类构造逻辑。 new检查。 用当前this调用父类构造函数。 将行子类class内部的变量和函数赋给this。 执行子类constuctor内部的逻辑。 es6实际上是为我们提供了一个“组合寄生继承”的简单写法。 super
super代表父类构造函数。super.fun1() 等同于 Parent.fun1() 或 Parent.prototype.fun1()。
super() 等同于Parent.prototype.construtor() 当我们没有写子类构造函数时:
var Child = function (_Parent) {
_inherits(Child, _Parent);
function Child() {
_classCallCheck(this, Child);
return _possibleConstructorReturn(this, (Child.__proto__ || Object.getPrototypeOf(Child)).apply(this, arguments));
return Child;
}(Parent);
可见默认的构造函数中会主动调用父类构造函数,并默认把当前constructor传递的参数传给了父类。所以当我们声明了constructor后必须主动调用super(),否则无法调用父构造函数,无法完成继承。典型的例子就是Reatc的Component中,我们声明constructor后必须调用super(props),因为父类要在构造函数中对props做一些初始化操作。
- 设计模式
- 原型链的经典的题目 https:// juejin.cn/post/68449034 48022876173 https://www. shangmayuan.com/a/d89ec 0ed6ac54c9ca05d9c0e.html
-
no people:JS 知识点梳理-下篇
Function面试题
异步和事件循环
回调函数
优点:1 无命名传递函数,减少变量使用 2 函数调用操作委托给另一个函数,减少代码编写
缺点:1 使用try catch 无法捕获错误(try...catch是被设计成捕获当前执行环境的异常,意思是只能捕获同步代码里面的异常,异步调用里面的异常无法捕获。 2 不能return 3 回调地狱
1 Promise 使用
创造了一个Promise:
const promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
调用回调有两种方式:
方式一: then中包含 sucess以及 fail 不推荐
promise.then(function(value) {
// success
}, function(error) {
// failure
方式二: then,catch 用法(推荐)
catch方法作用是为了处理promise内部发生的错误,如果没有catch方法,放发生错误时候,不会退出进程,终止脚本执行,promise的内部错误不会影响到外部的代码,会吃掉错误。catch语句不仅可以替代then第二个参数,来实现reject的回调函数,而且还是可以捕获promise内部错误,
相当于比then的第二个参数多一些功能,所以我们尽量不要写then的而参数即reject的回调,要多使用catch函数。catch返回值是一个promise对象,后面还以跟then方法
.then(result => console.log(result))
.catch(error => console.log(error))
// Error: failrejected和catch捕获错误区别
- 1.网络异常(比如断网),会直接进入catch而不会进入then的第二个回调,同时Promise内部错误会进入Catch
- 2.reject 是 Promise 的方法,而 catch 是 Promise 实例的方法
- 3.onRejected 从不处理来自同一个.then(onFulfilled)回调的被拒绝的 promise,并且.catch两者都接受。
- try catch不能捕获promise的异常,因为try catch只能捕获同步函数的异常,因为promise异步已经入栈,不在try catch的栈
2. promise 优缺点
优点
- 解决了回调地狱的问题
- 更好的错误捕获 reject
- 将异步操作以同步操作的流程表达出来
缺点
但过多的链式调用可读性仍然不佳,流程控制也不方便
- 如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
-
无法取消promise 会用blueBird ,promise-abortable 一些库
取消的话,
方法 1 使用 race 方法
//传入一个正在执行的promise
function getPromiseWithAbort(p){
let obj = {};
//内部定一个新的promise,用来终止执行
let p1 = new Promise(function(resolve, reject){
obj.abort = reject;
obj.promise = Promise.race([p, p1]);
return obj;
var promise = new Promise((resolve)=>{
setTimeout(()=>{
resolve('123')
},3000)
var obj = getPromiseWithAbort(promise)
obj.promise.then(res=>{console.log(res)})
//如果要取消
obj.abort('取消执行')
-
方法 2 使用 promise-abortable
const promise = new AbortablePromise((resolve, reject, signal) => {
const xhr = $.ajax({ url, success: resolve, error: reject });
signal.onabort = xhr.abort.bind(xhr);
promise.abort();
作者:Devi
链接:https://www.zhihu.com/question/63262461/answer/731331576
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成) Promise Q实现此功能 Progress Notification
return uploadFile()
.then(function () {
// Success uploading the file
}, function (err) {
// There was an error, and we get the reason for error
}, function (progress) {
// We get notified of the upload's progress as it is executed
Like fail, Q also provides a shorthand for progress callbacks called progress:
return uploadFile().progress(function (progress) {
// We get notified of the upload's progress
3 promise api
finally: 不管promise最后的状态,在执行完then或catch指定的回调函数以后,都会执行finally方法指定的回调函数。
promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});
promise race: const p = Promise.race([p1, p2, p3]); 只要p1、p2、p3之中有一个实例率先改变状态,p的状态就跟着改变。那个率先改变的 Promise 实例的返回值,就传递给p的回调函数。
all: const p = Promise.all([p1, p2, p3]); (1)只有p1、p2、p3的状态都变成fulfilled,p的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。2)只要p1、p2、p3之中有一个被rejected,p的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。
any: 只要参数实例有一个变成fulfilled状态,包装实例就会变成fulfilled状态;如果所有参数实例都变成rejected状态,包装实例就会变成rejected状态。
allSettled: Promise.allSettled()方法接受一个数组作为参数,数组的每个成员都是一个 Promise 对象,并返回一个新的 Promise 对象。只有等到参数数组的所有 Promise 对象都发生状态变更(不管是fulfilled还是rejected),返回的 Promise 对象才会发生状态变更。
const resolved = Promise.resolve(42);
const rejected = Promise.reject(-1);
const allSettledPromise = Promise.allSettled([resolved, rejected]);
allSettledPromise.then(function (results) {
console.log(results);
// { status: 'fulfilled', value: 42 },
// { status: 'rejected', reason: -1 }
Promises错误捕获
1 没法用 try catch 因为try catch只能处理同步的错误,对异步错误没有办法捕获
4 promise 实现原理
- new promise属于同步的,then属于异步的
- resolve后不应该有语句,应该直接return掉 resolve语句,因为相当于resolve后流程旧结束所以不应该有,如果有还会执行,并且resolve后面语句属于同步语句
1 const p1 = new Promise(function (resolve, reject) {
// ...
const p2 = new Promise(function (resolve, reject) {
// ...
resolve(p1);
1 resolve 参数可以有两个值,如果非promise,那么直接将状态结束,传递value给then,如果是resolve一个promise,那么就会先执行(resolve里面的promise),将 (里面的promise)resolve后,再出来执行执行resolve(p1).会把resove值传给then。
2 then方法会返回新的promise,这是串行promise的基础,从而支持链式调用。执行handle方法,handle方法会把then的参数(那个参数 promise)以及 then生成的promise(桥接 promise)的 resolve传进去,然后,如果then中的参数是个promise,那么传入handle执行,我们桥接promise会变为pedding状态,把这个桥接promise存入callback队列,return,然后对(参数promise)进行resolve操作,等到参数resolve完成后,接着我们桥接resove执行。
3 最后执行then后面的then方法
function Promise(fn){
var state = 'pending',value = null,callbacks = [];
this.then = function(onFulfilled){
return new Promise(function(resolve){
handle({
onFulfilled: onFulfilled || null,
resolve: resolve
function handle(callback){
if(state == 'pending'){
callbacks.push(callback);
return;
if(!callback.onFulfilled){
callback.resolve(value);
return;
var ret = callback.onFulfilled(value);
callback.resolve(ret)
function resolve(newValue){
if(newValue && (typeof newValue === 'object' || typeof newValue === 'function')){
var then = newValue.then;
if(typeof then === 'function'){
then.call(newValue,resolve,reject);
return;
state = 'fulfilled';
value = newValue;
execute();
function reject(reason){
state = 'rejected';
value = reason;
execute();
function execute(){
setTimeout(function(){
callbacks.forEach(function(callback){
handle(callback)
fn(resolve,reject)
手写题 写一个 es6 的继承过程
// 这个是要实现的方法
createClass = fun(sons, super) {
// TODO
return fn;
// 这是个 es6 的一个例子,要实现 extends 的功能。
class Man extends Human {
cons (args) {
super(args)
// xxxxx
speak() {
console.log('')
}6 promise 面试题
Generator
ES6 新引入了 Generator 函数,可以通过 yield 关键字,把函数的执行流挂起,通过next()方法可以切换到下一个状态,为改变执行流程提供了可能,从而为异步编程提供解决方案。
优缺点: 优点:没有了Promise的一堆then(),异步操作更像同步操作,代码更加清晰。 缺点:不能自动执行异步操作,需要写多个next()方法,需要配合使用Thunk函数和Co模块才能做到自动执行。
Generator和Async 区别对比
-
async/await自带执行器,不需要手动调用next()就能自动执行下一步 -
async函数返回值是Promise对象,而Generator返回的是生成器对象 -
await能够返回Promise的resolve/reject的值
1 Generator 使用
function * count() {
yield 1
yield 2
return 3
var c = count()
console.log(c.next()) // { value: 1, done: false }
console.log(c.next()) // { value: 2, done: false }
console.log(c.next()) // { value: 3, done: true }
console.log(c.next()) // { value: undefined, done: true }
next方法可以传递参数
function* myGenerator() {
console.log(yield '1') //test1
console.log(yield '2') //test2
console.log(yield '3') //test3
// 获取迭代器
const gen = myGenerator();
gen.next()
gen.next('test1')
gen.next('test2')
gen.next('test3')
2 Generator 实现原理
实现原理: https:// juejin.cn/post/68449040 96525189128
包含一个context context里面有pre,cur,done,以及stop变量,生成器将yield将代码分隔成switch-case块,然后执行的话,判断done是否完成,没有完成执行switch case语句,同时改变context的next的值,下次执行next方法会根据next值判断执行,return result
// 生成器函数根据yield语句将代码分割为switch-case块,后续通过切换_context.prev和_context.next来分别执行各个case
function gen$(_context) {
while (1) {
switch (_context.prev = _context.next) {
case 0:
_context.next = 2;
return 'result1';
case 2:
_context.next = 4;
return 'result2';
case 4:
_context.next = 6;
return 'result3';
case 6:
case "end":
return _context.stop();
// 低配版context
var context = {
next:0,
prev: 0,
done: false,
stop: function stop () {
this.done = true
// 低配版invoke
let gen = function() {
return {
next: function() {
value = context.done ? undefined: gen$(context)
done = context.done
return {
value,
// 测试使用
var g = gen()
g.next() // {value: "result1", done: false}
g.next() // {value: "result2", done: false}
g.next() // {value: "result3", done: false}
g.next() // {value: undefined, done: true}
这段代码并不难理解,我们分析一下调用流程:
1 我们定义的function* 生成器函数被转化为以上代码
2 转化后的代码分为三大块:
gen$(_context)由yield分割生成器函数代码而来
context对象用于储存函数执行上下文
invoke()方法定义next(),用于执行gen$(_context)来跳到下一步
3 当我们调用g.next(),就相当于调用invoke()方法,执行gen$(_context),进入switch语句,switch根据context的标识,执行对应的case块,return对应结果
4 当生成器函数运行到末尾(没有下一个yield或已经return),switch匹配不到对应代码块,就会return空值,这时g.next()返回{value: undefined, done: true}
总结: 从中我们可以看出,Generator实现的核心在于上下文的保存,函数并没有真的被挂起,每一次yield,其实都执行了一遍传入的生成器函数,
只是在这个过程中间用了一个context对象储存上下文,使得每次执行生成器函数的时候,都可以从上一个执行结果开始执行,看起来就像函数被挂起了一样Generator错误捕获
可以通过 try catch对于Gerator构造体函数内以及外j进行捕获,但是如果不捕获会中断若是 Generator 的错误没有被捕获,就不会继续执行
1 在函数内捕获
function * F(){
yield 1
}catch(e){
console.log(e)
var f=F();
f.next()//增长了一句next执行,能够执行generator里面的内容
// 需要调用next方法 这个generator的原理有关,调用F()仅仅返回一个状态生成器,并无执行generator里面的方法,
所以在f上直接跑错误是没法捕获的
f.throw(new Error('test1'))
//捕获错误 Error test12 在Gerator构造体外部捕获,在构造体外部捕获,能够直接f.throw
function F(){
yield 1;
yield 2;
return 3;
var f=F();
f.throw(new Error('test1'))
}catch(e){
console.log(e)
// Error test1未处理 若是 Generator 的错误没有被捕获,就不会继续执行
function F(){
yield 1;
throw new Error('test1');
yield 2;
return 3
var f=F();
f.next() // {value:1,done:false}
f.next() // {value:undefined,done:true}async
1 async实现原理
2 async的执行顺序
3 async await 返回值
4 async await 错误捕获
手写 async
手写async await的最简实现(20行) - 掘金 手写async await的最简实现(20行) - 掘金
async函数是generator函数的语法糖,实现原理,其实是通过 返回一个promise,然后再promise里面有个递归函数,这个会根据传入的key,进行筛选,如果generator返回的是done,则resolve出去,如果done为false,则继续执行Promise.resolve方法递归调用step 接着传入next以及val的值,进行下一步genrator的switch切换
function asyncToGenerator(generatorFunc) {
return function() {
const gen = generatorFunc.apply(this, arguments)
return new Promise((resolve, reject) => {
function step(key, arg) {
let generatorResult
try {
generatorResult = gen[key](arg)
} catch (error) {
return reject(error)
const { value, done } = generatorResult
if (done) {
return resolve(value)
} else {
return Promise.resolve(value).then(val => step('next', val), err => step('throw', err))
step("next")
相对于promise 两者最大应用场景不同是什么?
接口不存在继发关系,使用promise.all。如果存在继发关系,存在相互依赖的关系,使用async await,比如登录页面的
async函数返回值是什么,作用是?:async函数将后面函数包装成promise,不管return 不return,都是一个promise对象,但是如果return了 then的调用者就是 await 123 这个promise, 如果不return 那么then的调用者是谁?答案是Promise.resolve(undefined) 这个promise。 不管函数是否return,都是一个promise对象。同时 return的值也会将其包装为promise。未返回 为underfind,也会执行Promise.resolve(underfind). 无await 是顺序执行,无阻塞后面语句
await理解:await会将后面的值转化为promise,可以执行return ,await后面代码就不执行了,还有一种情况后面代码不执行,就是await一个promise.reject,或者resolve,提前结束。不return的场景适用于,串行接口,直接await
await后跟promise.reject会中断代码执行,走catch,防止await后面的reject中断程序运行,将await放入try catch中。
async function testAsync() {
return "hello async";
const result = testAsync();
console.log(result); // Promise { 'hello async' }
testAsync().then(v => {
console.log(v); // 输出 hello async
------
async function f() {
return 'hello world';
f().then(v => console.log(v))
基础写法:
函数声明: async function foo() {}
函数表达式: const foo = async function(){}
箭头函数:const foo = async()=>{}
对象写法:let obj = {async foo(){}}
obj.foo().then(()=>{console.log('123')})
------------
async function f() {
// 等同于
// return 123;
return await 123;
f().then(v => console.log(v))
-------------------------
async function f() {
await Promise.reject('出错了'); //没有return
console.log('reject后面不执行') // reject后面不执行
.then(v => console.log(v))
.catch(e => console.log(e)) // 也会捕获
// 出错了
----------------------------
补救 reject
async function f() {
try {
await Promise.reject('出错了');
} catch(e) {
return await Promise.resolve('hello world');
.then(v => console.log(v))
- 其他语言的异步,java和C,golang
async 的错误处理
1 async 中的错误处理 可以用函数的catch进行捕获,await的错误处理,可以用await后的catch捕获也可以用async的catch进行捕获,如果 await的错误没有被捕获,则会中断async函数的执行
1 async function F(){
throw new Error('test1')
var f=F();
f.catch(function(e){console.log(e)});
// Error:test1
2 async function F(){
await Promise.reject('Error test1').catch(function(e){
console.log(e)
var f=F(); // Error:test1
2.1 async function F(){
await Promise.reject('Error test1')
var f=F(); // Error:test1
f.catch(function(e){
console.log(e)