


Python空间数据可视化利器之Geopandas

提及空间数据可化视,不少人可能对ArcGIS,Qgis耳熟能详,R等编程语言同样也十分强大。R语言中对于空间数据的处理有sp,maptools,rgdal等实用的包。随着Python在数据处理领域的能力日趋强大,在空间数据可视化方面,Python同样有着出色的表现。
目前在python中,对于空间数据的可视化,最常用的库是Basemap。Geopandas作为后起之秀,因为其简单易学,得到越来越多用户的拥趸。Basemap,无论是从安装还是使用上都比较繁锁,相比之下,Geopandas更简单易学。从其名字看起来,Geopandas肯定与pandas有渊源,实际上正是如此,Geopandas承继了Pandas的诸多优点因此,熟悉pandas的用户,在使用Geopandas时会更加得心应手。
在空间数据可视化方面,最常见的图形为空间分布图,即对于同一个变量不同区域的不同数值,赋予不同的颜色,从而直观上查看某一个变量的空间分布状况。接下来,本文以中国地图shp文件和2015年各省市人均gdp为例,简要介绍如何用geopandas作空间分布图。我的系统环境为Win 10 x64 + Python 3.5(Anaconda3 v4.2.0)。
在运行之前,要确保python安装Geopandas库。Geopandas库依赖于其它的库,除了常见的numpy、pandas之外,还有shapely、fiona、six、pyproj,如果要使用Geopandas更高级的绘图功能,还要安装descartes、pysal。关于Geopandas更具体的介绍,见 http:// geopandas.org/ 。使用Geopans绘图其实很简单,核心代码其实只有几行,代码汇总如下:
#===================================我是分割线===============================
import pandas as pd
import numpy as np
import geopandas as gp
import matplotlib.pyplot as plt
data = pd.read_csv('china_data.csv', encoding = 'gb18030')#读取人均GDP数据
china_geod = gp.GeoDataFrame.from_file('bou2_4p.shp', encoding = 'gb18030')
china_geod.plot()#查看地图
data_geod = gp.GeoDataFrame(data)#将data转换为Geopandas.DataFrame
china_geod = china_geod.rename(index = str, columns = {'NAME':'prov'})#修改列名
da_merge = china_geod.merge(data_geod, on = 'prov', how = 'left')#数据合并
sum(np.isnan(da_merge['gdpc']))#有54行有空值
da_merge['gdpc'][np.isnan(da_merge['gdpc'])] = 14.0#填充缺失数据
da_merge.plot('gdpc', k = 4, cmap = plt.cm.Greens)#图形初步
da_merge.plot('gdpc', k = 4, cmap = plt.cm.Greens, alpha= 1)
#颜色不够明显,将颜色透明度参数alhpa设置为1
da_merge.plot('gdpc', k = 4, cmap = plt.cm.Greens, scheme = 'percentiles',alpha= 1, figsize = (9, 9), legend = True)#添加图例,设置图形大小
plt.text(x = 76, y = 16, s = u'单位:万元', fontsize = 13)#添加文字
plt.title(u'2015年各省市人均GDP', fontsize=15)#设置图形标题
plt.gca().xaxis.set_major_locator(plt.NullLocator())#去掉x轴刻度
plt.gca().yaxis.set_major_locator(plt.NullLocator())#去年y轴刻度
#=========================================================================
绘图主要分三个步骤进行,第一步:读取shp地图文件和数据文件,第二步:DataFrame合并,第三步:绘图并修改图形参数。在读取文件之前,首先要导入相应的库:
import pandas as pd
import numpy as np
import geopandas as gp
import matplotlib.pyplot as plt
接下来,使用read_csv函数和GeoDataFrame.from_file函数分别读取包含人均GDP数据的csv文件和中国省份地图的shp文件。用head函数来查看这两个文件的数据结构,用plot函数初步查看地图:
#该csv文件中有中文,所以在read_csv函数中设置encoding参数为gb18030
data = pd.read_csv('china_data.csv', encoding = 'gb18030')
china_geod = gp.GeoDataFrame.from_file('bou2_4p.shp', encoding = 'gb18030')#读取shp文件
data.head(6) #data数据只有两列,分别是prov(列名),gdpc(人均GDP)
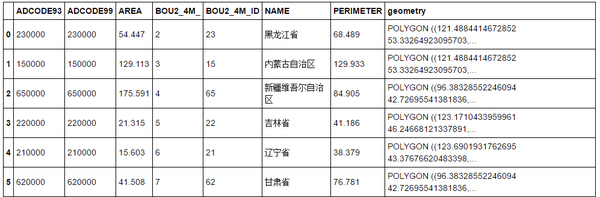
china_geod.head(6)#如表1所示
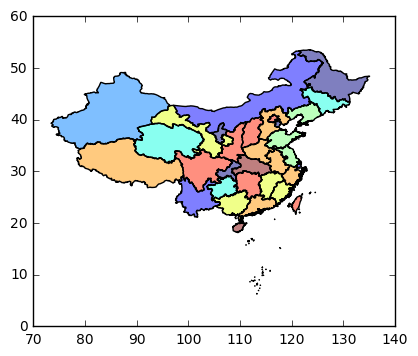
china_geod.plot()#查看地图,如图1所示
表1 china_geod数据的前6行

下面进行数据合并。在进行数据合并之前,要先转换 ,并修改列名。data是pandas.DataFrame,而china_geod则是一个geopandas.DataFrame,为了下面使用geopandas的merge函数进行数据合并,先要将pandas.DataFrame转换为geopandas.DataFrame。此外,使用merge函数进行合并时,两个DataFrame中相同数据的列名必须一致,在china_geodp这个GeoDataFrame中显示省份的列名为’NAME’,而在data pandas.DataFrame中,对应的列名为prov,在里使用rename函数将china_geodp的NAME这一列重新命名为prov。
data_geod = gp.GeoDataFrame(data)##将data转换为geopandas.DataFrame
china_geod = china_geod.rename(index = str, columns = {'NAME':'prov'})#修改列名
da_merge = china_geod.merge(data_geod, on = 'prov', how = 'left')#数据合并
sum(np.isnan(da_merge['gdpc']))#有54行有缺失数据
da_merge['gdpc'][np.isnan(da_merge['gdpc'])] = 14.0#填充缺失数据
da_merge.plot('gdpc', k = 4, cmap = plt.cm.Greens)#图形初步,如图2所示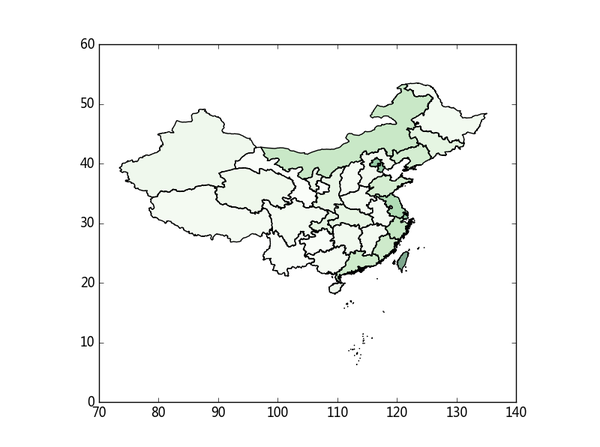

图2 绘图初步
对geopandas.DataFrame使用plot函数时,主要设置column、k、cmap参数,其中column为Geopandas.DataFrame列名,k为显示的颜色数量,cmap为颜色类型,此外legend为是否设置图例,scheme为配色方案(调用此参数时需要安装pysal库), figsize为图形大小。
#颜色不够明显,将透明度参数alpha设为1
da_merge.plot('gdpc', k = 4, cmap = plt.cm.Greens, alpha= 1.0)