


如何在pandas中使用set_index( )与reset_index( )设置索引

在数据分析过程中,有时出于增强数据可读性或其他原因,我们需要对数据表的索引值进行设定。在之前的文章中也有涉及过,在我们的pandas中,常用set_index( )与reset_index( )这两个函数进行索引设置,下面我们来了解一下这两个函数的用法。
一、set_index( )
1、函数体及主要参数解释:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)参数解释:
keys :列标签或列标签/数组列表,需要设置为索引的列
drop: 默认为True,删除用作新索引的列
append: 是否将列附加到现有索引,默认为 False 。
inplace :输入布尔值,表示当前操作是否对原数据生效,默认为 False 。
verify_integrity :检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为 false。
2、实例说明:
首先还是先创建一个实验数据表:
import pandas as pd
import numpy as np
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age':[50, 43, 34, 40, 25, 25, 45, 32]})
df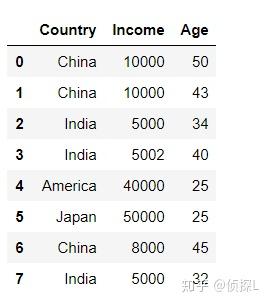
下面我们尝试将‘Country’这一列作为索引:
df_new = df.set_index('Country',drop=True, append=False, inplace=False, verify_integrity=False)
df_new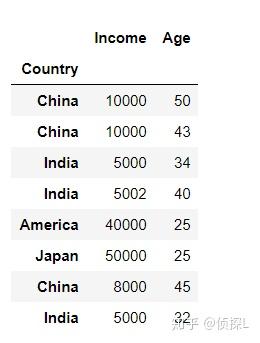
可以看到,在上一步的代码中,是指定了 drop=True,也就是删除用作新索引的列 ,下面师门尝试将 drop=False.
df_new1 = df.set_index('Country',drop=False, append=False, inplace=False, verify_integrity=False)
df_new1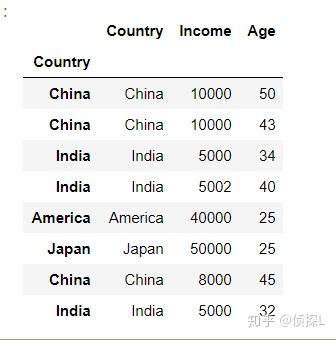
可以看到这个时候,被作为索引的那一列数据仍然被保留下来了。
下面,我们再探索一下 append 参数的用法。( append的用法: 是否将列附加到现有索引,默认为 False 。)
由上面代码结果可以看到,当 append=False 时:
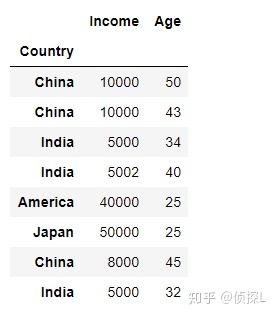
我们来试试 append=True 的情况:
df_new1 = df.set_index('Country',drop=True, append=True, inplace=False, verify_integrity=False)