


描述统计学常用的四个关键指标

- 什么是描述统计学?
描述统计学 是找到几个关键的数字来描述数据集的整体情况。
描述数据的四个关键指标:平均数(均值)、四分位数、标准差、标准分。
众数
(M),是在一堆数据中出现最频繁的数据,即频数最大的数据,在统计分布上具有明显集中趋势点的数值,代表数据的一般水平。用众数代表一组数据,可靠性较差。
均值( \mu ): 也是我们常说的平均值,将所以的数据相加再除以数据的个数。
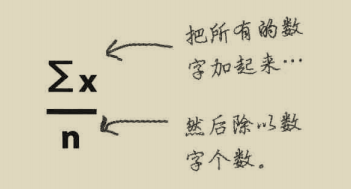
使用均值时它的缺点是对异常值不敏感,当存在异常值时均值是不准确的,我们就需要用中位数来表达。
四分位数
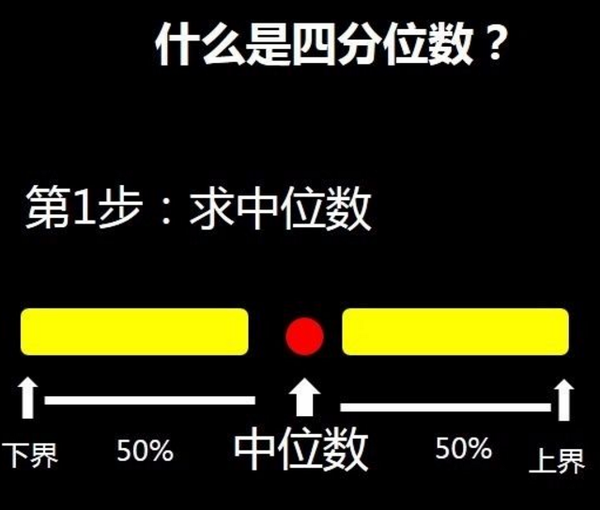
1.中位数
(1)首先将所以的数据按从小到大排序。
(2)选取中间的数值。如果数值为单数则取中间的数值,如果为双数则取中间两个数的平均值,它永远处于中间。


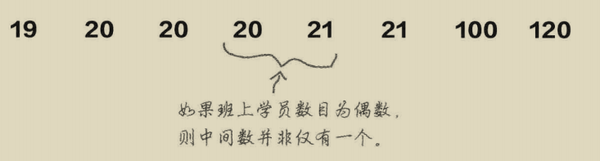
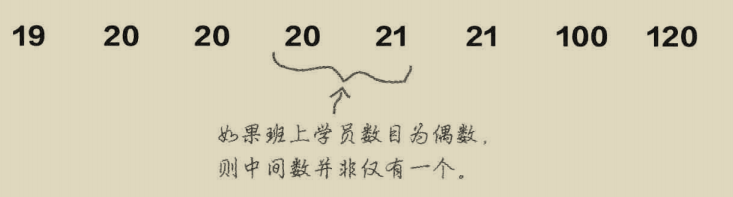
通过上面的图可以看到,图1的均值为38,而中间值为20,这个差异由100和102造成的。当数据中有特别大的数值时,均值就不够准确的表达。中位数相对于均值更客观点一些。
2.四分位数
(1)将数据按升序排列,将这些数据分为四个相等的数据段。
(2)对中位数平分的两段数据再求中位数,分别是下四分位数,上四分位数。
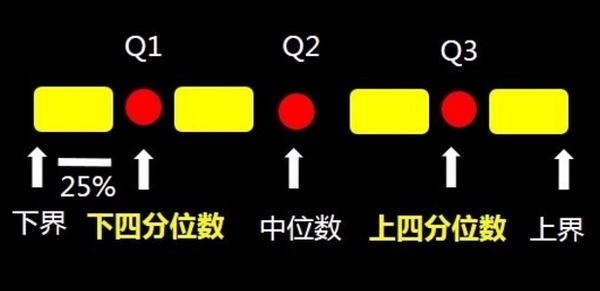
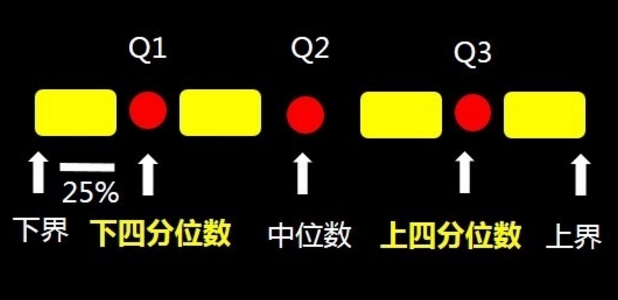
其中的(Q1)为最小的四分位数称为下四分位数,最大的(Q3)为四分位数中上四分位数,中间的四分位数为中位数(Q2)。数据集中的最小值为 下界 ,数据集中的最大值为 上界 。
每两个四分位数之间的距离为四分位距。
四分位距=上四分位数-下四分位数(Q3-Q1)。
全距 :指的是数据的扩展范围,用数据中的最大值减去数据中的最小值。


四分位距的优点是:与全距相比,较少受到异常值的影响,主要目的就是剔除异常值。
四分位距竟用了处于中心位置的50%的数据,无论异常值是极大值还是极小值,均被排除在外,从而得到稳定的数据。
箱线图
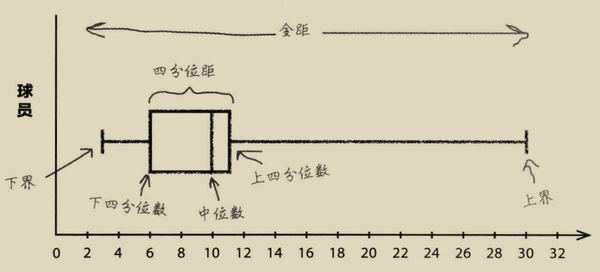
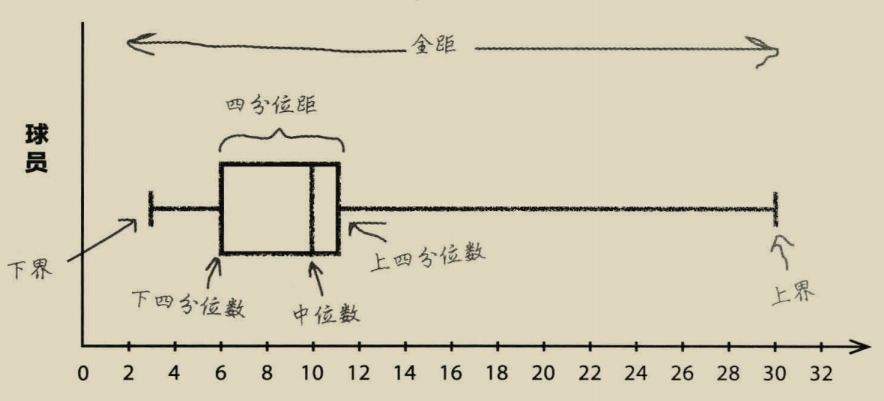
箱线图 可以让我们直观让的理解四分位数,并方便我们看出数据中的趋势。
我们把四分位距画成箱子的形状,箱线图的左边为下四分位数,右边为上四分位数,其中画出中位数。
四分位数的应用:
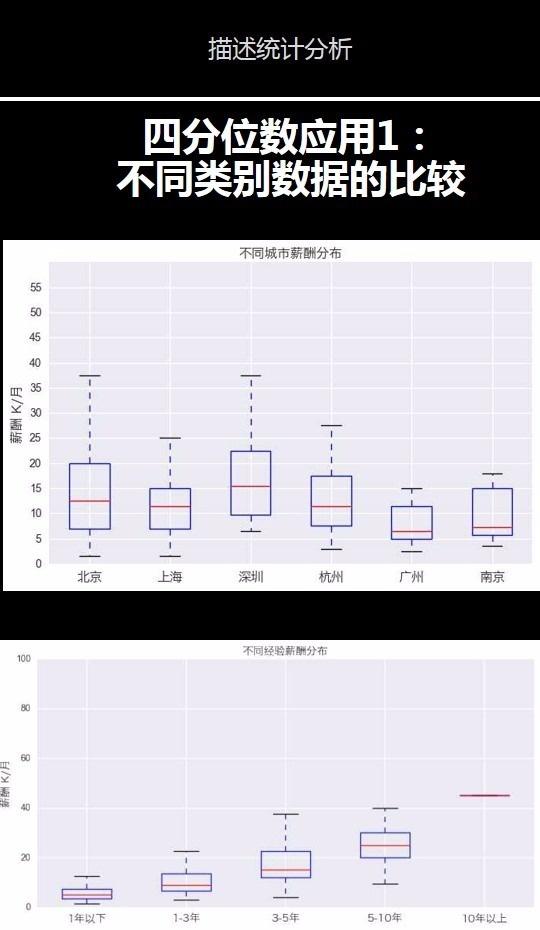
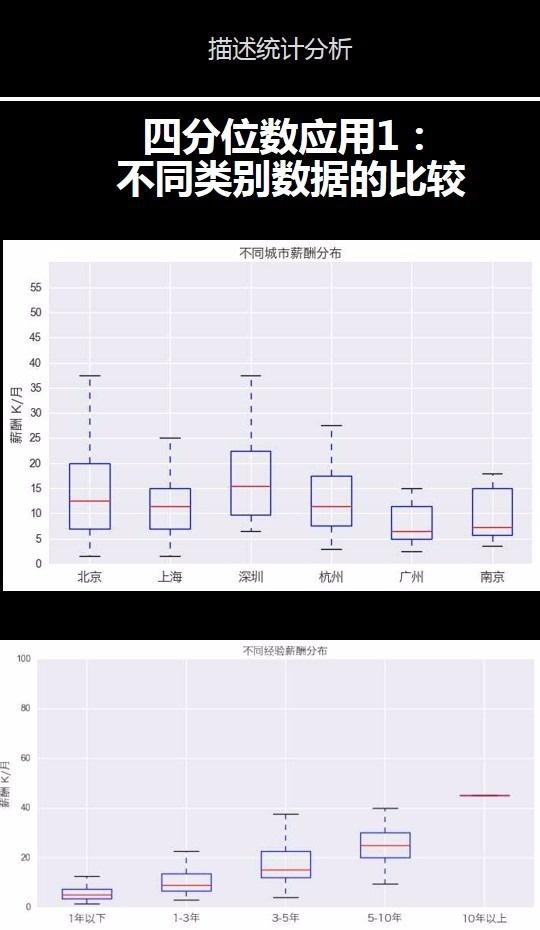
通过上图比较发现,我们可以哼容易看出这些城市的薪酬分布,其中深圳、北京、上海、杭州;随着工作年限的上升,工资的上升非常明显,尤其是3-5年的跨度很大。
- 如何识别可能异常值?
(1)运用技术手段从大量数据中找出哪些可能是异常值。
(2)对找出的这些异常值的准确性进行进一步的检查,以确定如何处理这些异常值。
异常值可能有三种:
第一种是可能被错误标记、记录的数据值,如果是错误的数据,我们可以对其修正。
第二种是异常值可能是被错误包含在数据集中的值,如果是这样的话,就把异常值删除。
第三种是异常值可能是一个反常的数据值,被正确记录到了数据集中,这种情况的话是应该被保留的。
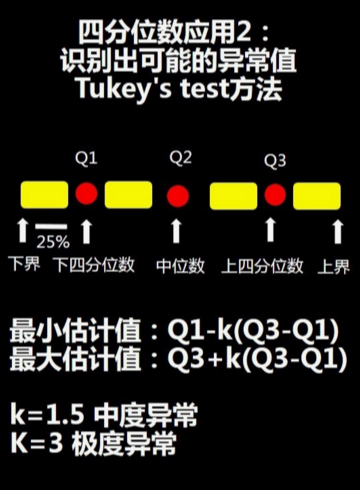
根据上图中的tukey's test方法求出最小估计值和最大估计值,若超过最小估计值和最大估计值的数值就可能是异常值。
若k=1.5,计算出的就是中度异常的范围,如果是3,就是极度异常的范围,超过这个范围的数值,就有可能是异常值。
四分位数的优点:可以从整体集中描述分布状态。
缺点:不能告诉我们数据集的波动情况。
标准差(波动大小=离散程度=变异性)
方差:主要用于度量数据分散性的方法,
标准差( \sigma ):主要得出是数值与均值的距离的平方数的平均值,
公式如下:
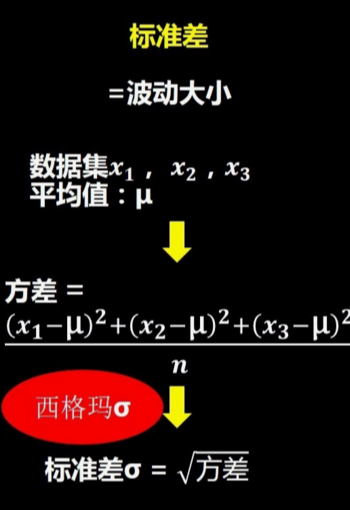
平方后才能准确反映每次变化偏离平均值的情况。
方差和标准差都是用来描述数据的分散性的,其主要的目的都是用来计算数据的稳定性,并比较那个数据的稳定性更好。
这里要注意标准差的单位等同于计算数据的单位;标准差大点或者小点好要取决于我们要用来做什么事情,让我们来看下面的例子:
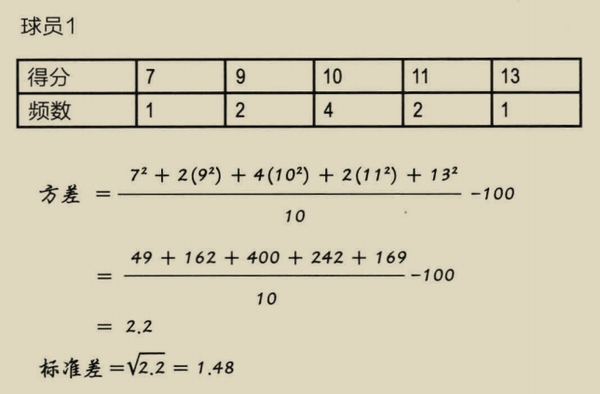




球员1和球员2的标准差都比较小,说明 数值聚集在均值周围。而球员3标准差为7.02,即在典型情况下,得分与均值的距离为7.02.因此,球员1最稳定,球员3最不稳定。
标准分
使用标准分可以对不同数据集中的数据进行比较,而这些数据集的均值和标准差各部相同。
公式如下:

标准分表示【某个数值】距离平均值多少个标准差,如果某个数值的标准分等于零,那表示数值是等于平均值的,如果标准分大于零,那表示数值是大于平均值的,如果标准分小于零,那数值是小于平均值的。
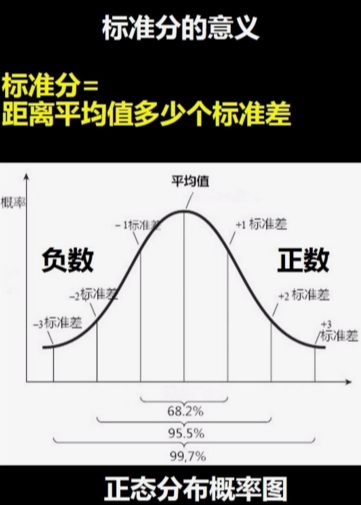
标准分就是建立一个模型将两组数据放在同一个模型中进行比较。
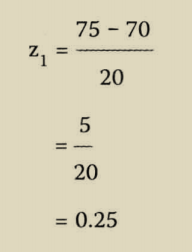
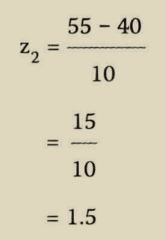
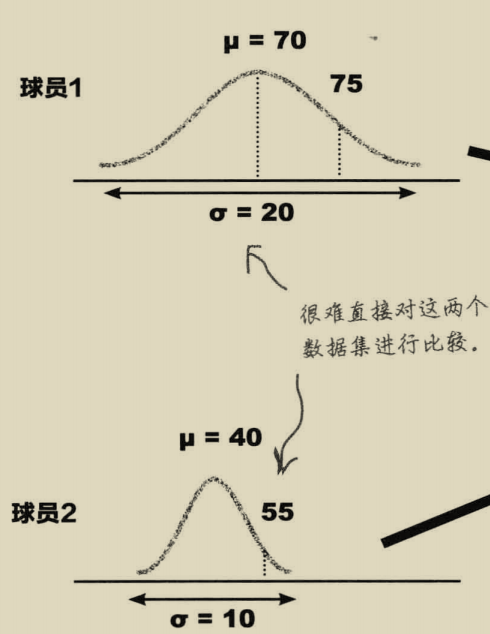
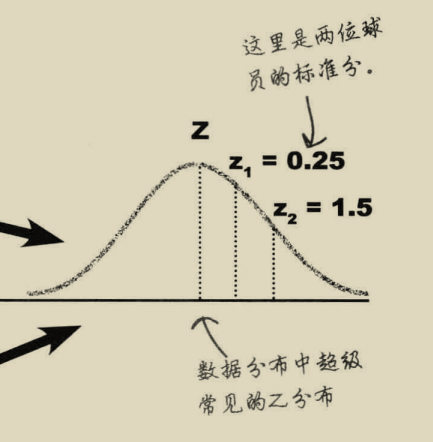
这样我们可以看出球员1的标准分是0.25,而球员2的标准分是1.5,将得分标准化后,球员2的得分比球员2得分更高。尽管球员1是一个优秀的投篮手,投篮率比球员2高,但相对于本人的历史纪录确实球员2更好。
