


purrr 批处理(批处理,总有一天会想起我,值得收藏)

purrr
purrr 是一个严重被低估一个R包,这个包的神奇之处在与能帮批量处理问题,例如,可以read 多个文件,跑模型的时候,可以批量输入多个参数,并把结果合并起来做比较,极大的提高效率,所以,你即使现在看不懂,当你有一天重复调参心烦时候,请想起这篇文章,先收藏了吧,记得关注。
背景:迭代 也就是loop
迭代无处不在。它支撑着许多数学和统计学。如果您曾经见过ΣΣ符号,那么您已经看过(并且可能已经使用过)迭代。
它也非常有用。任何时候你必须多次重复某种动作,迭代是你最好的朋友。在心理学中,这通常意味着从实验中读取一堆单独的数据文件,用一系列不同的预测因子或结果重复分析,或者创建一系列数字。
library(psych)
library(knitr)
library(kableExtra)
library(gridExtra)
library(plyr)
library(tidyverse)输入for循环。 for循环是计算机科学中迭代的“OG”形式。基本语法如下。基本上,我们可以使用for循环来循环并打印一系列内容
for(i in letters[1:5]){
print(i)
## [1] "a"
## [1] "b"
## [1] "c"
## [1] "d"
## [1] "e"读入多个文件:
data_path <- ""
files <- list.files(data_path)
data <- list()
for(i in files){
data[[i]] <- read.csv(i, stringsAsFactors = F)
data <- combine(data)1 上面的循环定义数据的路径,
2 读取该路径中的所有文件,
3 创建一个空列表来存储数据文件,
4 单独循环遍历每个文件并将它们保存到列表中,
5 并组合每个读取的数据文件成一个数据框。
这一切都很好,并且工作得很好。但是,如果您有不同主题的多个数据文件,例如,如果他们完成了写作任务和内存任务,会发生什么?或者,您可能像我一样处理纵向数据,并且对于不同类别(例如,健康,心理等),通常会在给定年份内拥有多个数据文件。在这种情况下,上面的循环可能不起作用。这些文件可能具有不同的属性或存储在不同的位置(为了您自己的理智)
data_path <- ""
directories <- list.files(data_path)
files <- c("health", "person")
data <- data.frame
for(i in directories){
for(k in files){
tmp <- read.csv(sprintf("%s/%s/%s.csv", data_path, i, k), stringsAsFactors = F)
tmp$file <- k
data <- bind_rows(data, tmp)
在这种情况下,它有点复杂。
首先,我们将每个文件加载到列表中的方法在这里不能很好地工作,因为我们正在迭代2个变量。因此,我们必须将每个文件保存到一个名为“tmp”的对象中,然后必须将其与先前迭代的数据连接起来。这样做的缺点是我们必须使用某种“强力”方法来做到这一点,这并不理想。数据收集经常出错,这意味着文件可能有不同的列。第三,当循环失败时,它拒绝继续。而你留下了几个变量(i和k),并且必须尝试向后工作以找出出错的地方。
听起来烦人吗?请输入purrr!
purrr解决方案:
purrr是我最喜欢的迭代替代品。它通过将所有内容保存在一个对象中来使我保持井井有条。它可以很好地处理诸如possibly()和safely()之类的函数来捕获和处理错误。
purrr可以用于比我在这里讨论的更多的东西。如果您想了解更多信息,可以查看Hadley Wickham的R for Data Science或purrr文档。
我将专注于我如何使用purrr:读取数据,清理,运行模型,制作表格和绘制图表。
嵌套数据框架:
在我们学习如何使用purrr之前,我们需要了解嵌套数据框是什么。如果您曾经使用过R中的列表,那么就在那里。基本上,嵌套数据框采用您可能熟悉的常规数据框并添加一些新功能。它仍然有列,行和单元格,但构成这些单元格的内容不限于数字,字符串或逻辑。相反,你可以提供你想要的任何东西:列表,模型,数据框,情节等!
如果这让你有点怪,想象一下。想象一下,你就是我:你使用个性数据,并希望使用Big 5中的每一个来单独预测一些结果,如健康和生活满意度。
ipip50 <- read.csv("https://raw.githubusercontent.com/emoriebeck/R-tutorials/master/purrr/ipip50_sample.csv", stringsAsFactors = F)
# let's recode the exercise variable (exer)
# 0 = "veryRarelyNever"; 1 = "less1mo"; 2 = "less1wk"; 3 = "1or2wk"; 4 = "3or5wk"; 5 = "more5wk"
ipip50 <- ipip50 %>%
mutate(exer = mapvalues(exer, unique(exer), c(3,4,0,5,2,1)))
真正糟糕的解决方案是编写代码来对这些数据进行建模,再制作结果表并绘制图表。然后,您将复制并粘贴该代码9次,更改关键变量,以对其他特征 - 结果对执行相同的步骤。过了一段时间,你可以单独运行它们。
一个更好的解决方案是循环,您可以使用嵌套循环来完成每个特征 - 结果对的步骤。如何存储这些值可能会有点不稳定,并且经常会出现一堆不同的列表或者混乱的全局环境。
但最好的解决方案是purrr。好吧,我们从嵌套数据框开始:
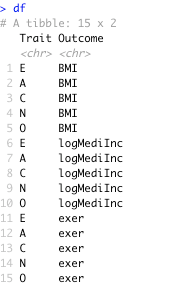
df <- expand.grid(
Trait = c("E", "A", "C", "N", "O"),
Outcome = c("BMI", "logMediInc", "exer"),
stringsAsFactors = F
) %>%
tbl_df
要做到这一点,我们使用一个名为expand_grid()的有用的小函数,它基本上取你给它的东西,并返回一个包含所有变量组合的数据框。这可以具有的列数没有限制。在这里,我们将它包含“Trait”,其中包含Big 5的向量,以及“Outcome”,其中包含我们结果的向量,从而生成包含2列和10行的数据框。
现在我们已经有了这个,我们几乎准备好开始建模,制表和绘制数据。首先,我们需要确保我们的数据准备就绪。我发现使用purrr处理数据的最简单方法是首先将数据转换为long格式,其中expand_grid()数据框中的所有列都以长格式表示。这将允许我们在公式和函数中使用一致的变量名,并使用dplyr辅助函数filter()将正确的数据提供给不同的程序。那么让我们来看看我们的Big 5数据并做到这一点。
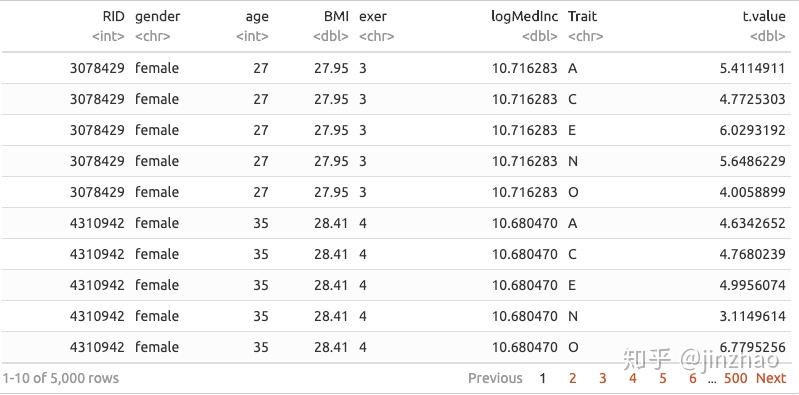
# Let's make the trait data long and create composites
(ipip50_composites <- ipip50 %>%
gather(key = item, value = value, A_1:O_10) %>%
separate(item, c("Trait", "item"), sep = "_") %>%
group_by(RID, gender, age, BMI, exer, logMedInc, Trait) %>%
summarise(t.value = mean(value, na.rm = T)))

# Now let's make the outcomes long
ipip50_composites <- ipip50_composites %>%
gather(key = outcome, value = o.value, BMI:logMedInc)
现在我们的数据是长格式的,我们有几个选择。第一种方法是使用tidyr包中的nest()函数按特征和结果对数据进行分块。这将产生一个包含3列的数据框:1为Trait编制索引,1为索引成果,1为索引该特征和结果组合的数据。
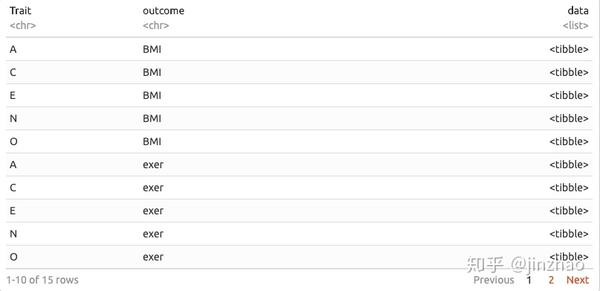
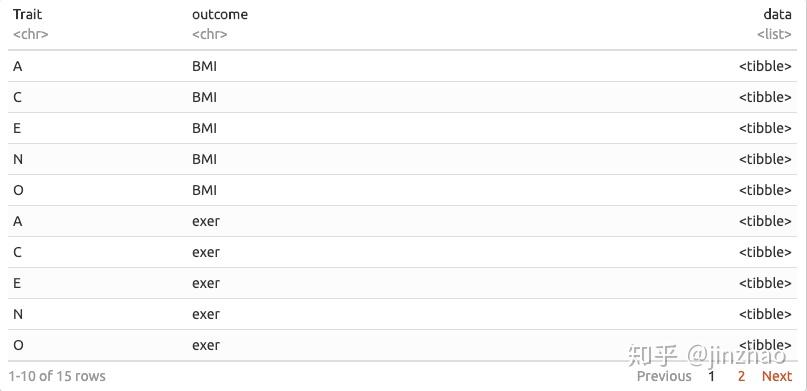
基本上,不是“数据”列中的单元格是单个数字,逻辑或字符值,而是每个单元格都是数据框架!注意,“data”列的类是列表(因此名称为“list column”),每个单元的类是tibble。 o_O很酷,对吧?原因如下:通过在单个单元格中为每个特征/结果组合放置数据的数据框,我们可以像在普通数据框中的单元格一样对每个单元格进行操作。
map()函数
我说有点因为我们需要另一个函数,这次来自purrr包(yay!),名为map()。现在我的目的不是通过各种可能的方式来使用它。如果您想了解更多详细信息,请访问 http:// r4ds.had.co.nz/many-mod els.html 。我的目标是向你展示,一个心理学研究生,每个人都使用purrr。单:天。在我的研究中。 我们想要做的是运用一个人格模型来预测每个特质和结果组合的结果。现在我们有一个数据框,每个数据框嵌套在一个数据框中,我们已经准备好了。这是如何做。
(ipip50_nested <- ipip50_nested %>%
mutate(model = map(data, ~lm(o.value ~ t.value, data = .))))
那里发生了什么?好吧,我们使用来自dplyr的mutate()在我们的数据框中创建一个名为“model”的新列。然后,我们使用map()函数告诉它我们想要获取“数据”中的每个单元格“列并运行一个线性模型,从人格(t.value)预测我们的结果(o.value)。随后是“data =。”部分,因为我们位于dplyr管道中。
如您所见,这会产生一个名为“model”的新列。与数据列一样,“model”列的类是一个列表,列中任何单个单元格的类都是S3类“lm” “,这只是线性模型。
现在,这绝对是运行大量模型的快捷方式,但到目前为止,这并不比for循环更好。但是我们的嵌套数据框架可以胜过for循环。我们不会仅仅为了这样做而运行模型。我们想要提取信息并通常以表格或图形形式报告。使用map()和purrr,我们可以为每个模型创建一个表格和图形,并将其存储在我们的数据框中。不再处理其内容难以访问的笨重列表或看似无限数量的对象混乱您的环境。它全部存储在一个数据框架中。 (抱歉大喊,但我认为这样做的好处不容小觑。)
(ipip50_nested <- ipip50_nested %>%
mutate(tidy = map(model, broom::tidy)))
Unnesting
使用broom包中的tidy()函数,我们现在有另一列。同样,列的类是“列表”,但单元格的类是“data.frame”。我们怎么用呢?好吧,我们之前使用的nest()函数有一个名为unnest()的兄弟。它与nest()相反;它需要我们的列表列并扩展它。因此,由于我们在“整洁”列的每个单元格中都有2 x 5数据帧,当我们不再使用它时,每个特征和结果组合都会有行(嵌套数据框中只有1个)。这将通过演示更有意义:
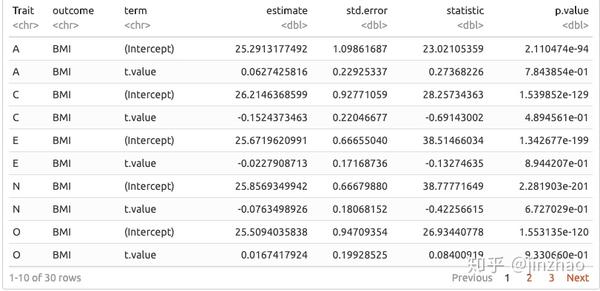
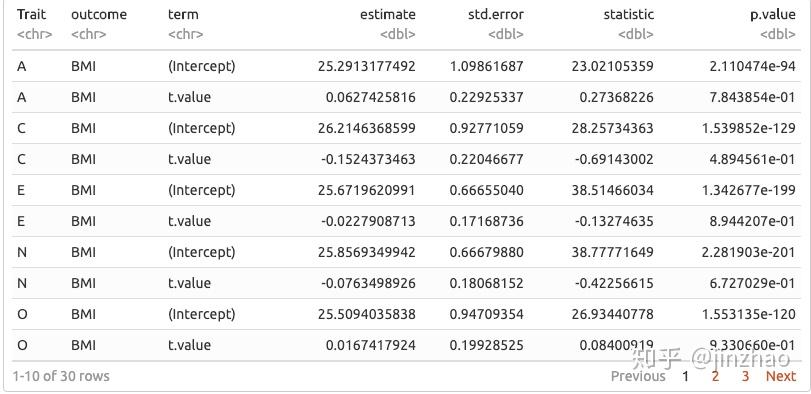
挺整洁的,对吧?从这里开始,我们可能想要做一些不同的事情。 purrr是我们所有人的朋友。我将在下面做几个,只是为了向您展示您的选择。
创建一个表
当我们有多个预测变量和结果时,我们通常希望将所有这些信息粉碎成一个表,预测变量表为不同的行,结果为不同的列(反之亦然)。我们通常包括模型中每个项的估计和置信区间或标准误差(在我们的例子中是Intercept和t.value)。
让我们为每个结果创建一个包含不同列的表,并为每个特征创建不同的行:
(tab <- ipip50_nested %>%
unnest(tidy, .drop = T) %>%
select(Trait:std.error) %>%
rename(b = estimate, SE = std.error) %>%
gather(key = tmp, value = value, b, SE) %>%
unite(tmp, outcome, tmp, sep = ".") %>%
spread(key = tmp, value = value))
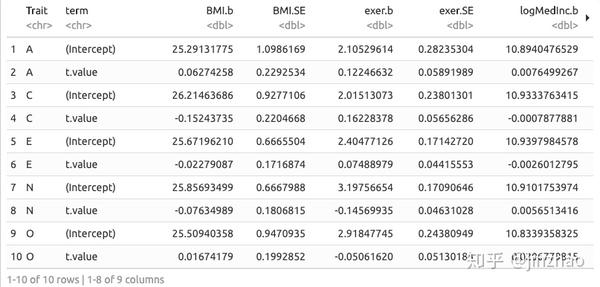
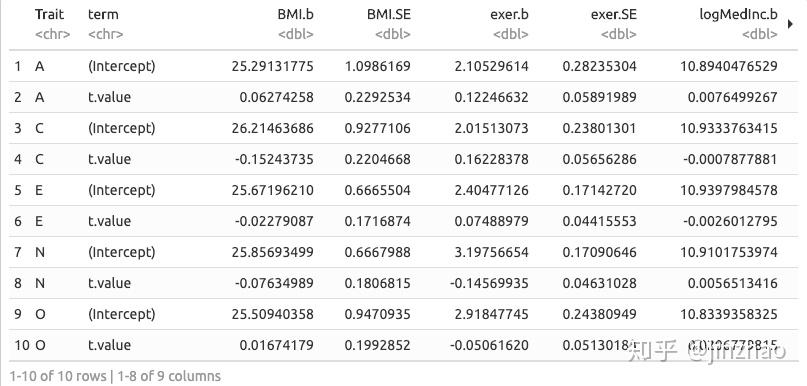
tab %>% select(-Trait) %>%
kable(., "html", booktabs = T, escape = F, digits = 2,
col.names = c("Term", rep(c("b", "SE"), times = 3))) %>%
kable_styling(full_width = F) %>%
column_spec(2:7, width = "2cm") %>%