

PySpark实战 18:使用 Python 扩展 PYSPARK:RDD 和用户定义函数 (2)

8.3 大数据只是大量的小数据:使用 PANDAS UDF
Spark 3.0 为 pandas UDF 带来了大量改进和新功能,包括标量迭代器、映射迭代器和联合映射 pandas UDF。 本章是使用最新的可用版本 Spark 2.4.5 编写的,但我计划在我将它们放在显微镜下后包括一个包含新的 Spark 3.0 UDF 的新部分(并在必要时刷新当前材料)。
Python UDF 虽然非常灵活,但一次只能对一条记录进行操作,就像 RDD 的 map() 方法一样。 本节介绍一种处理 UDF 的新方法:pandas(或矢量化)UDF。 就像他们的名字所表明的那样,他们依赖于 pandas,一个非常流行的 Python 数据操作库。
矢量化 UDF 在 Spark 2.3(标量、分组映射)中引入,并在 Spark 2.4(分组聚合)中得到改进。 我建议在书中各处使用最新的稳定版本,但本节需要它。
pandas UDF 的核心可以看作是在数据框架内分发 pandas 数据操作代码。 在第 1 章中,我解释了 Spark 将大量数据分布在多个分区中,并通过主从分离来协调转换和操作。 在我们的模型中,pandas UDF 就像将每个数据块视为一个独立的 pandas 数据框。
8.3.1 设置我们的环境:连接器和库
在本节中,我使用美国国家海洋和大气管理局 (NOAA) 的全球地表每日摘要 (GSOD) 数据集。 此数据可从多个来源获得,但最容易访问的来源之一是通过 BigQuery 提供的 Google 公共数据集存储库。 我使用 BigQuery 连接器连接到 Spark 来摄取数据(GitHub - GoogleCloudDataproc/spark-bigquery-connector:Apache Spark 的 BigQuery 数据源:将 BigQuery 中的数据读入 DataFrames,将 DataFrames 写入 BigQuery 表。)。 他们的 Github 上的说明可能会随着时间的推移而改变,因此请根据需要参考他们的 README。 对于 Spark 2.4.5,您需要下载 spark_bigquery_latest.jar。 如果您使用的是 Spark 3.0,则需要您的 Scala 版本(2.11 或 2.12,取决于您的 Spark 安装)的 jar。
要访问数据,您还需要一个 Google Cloud Platform (GCP) 帐户。 创建帐户后,您需要创建一个服务帐户和一个服务帐户密钥,以告知 BigQuery 以编程方式授予您访问公共数据的权限。 为此,选择“服务帐户”(在“IAM 和管理”下)并单击“+ 创建服务帐户”。 为您的服务帐户名称取一个有趣的名称。 在服务帐户权限菜单中,选择“BigQuery → BigQuery admin”并单击“继续”。 在最后一步中,单击“+ CREATE KEY”并选择 JSON。 下载密钥并将其存储在安全的地方。
像对待任何其他密码一样对待此密钥。 如果恶意人员窃取了您的密钥,请返回“服务帐户”菜单并删除此密钥,重新创建一个新密钥。
使用矢量化 UDF 分析数据之前的最后一步是安装 PyArrow。 PyArrow 是 Apache Arrow 项目 ( arrow.apache.org/ ) 的 python 绑定,这是一个内存数据序列化库。 它提供了 PySpark 数据框架和 Pandas 数据框架之间的桥梁。 如果您使用的是 Spark 2.3 或 2.4,您还需要在 Spark 根目录的 conf/spark-env.sh 文件中设置一个标志。 在 conf/ 目录中,您应该找到一个 spark-env.sh.template 文件。 制作一个副本,将其命名为 spark-env.sh 并在文件中添加此行。
ARROW_PRE_0_15_IPC_FORMAT=1这将告诉 PyArrow 使用与 Spark 2.X 兼容的序列化格式,而不是仅与 Spark 3.0 兼容的更新格式。 Spark JIRA 票证包含有关此的更多信息(pandas udf 不适用于最新的 pyarrow 版本 (0.15.0))。 您还可以使用 PyArrow 版本 0.14 并完全避免该问题。
如果您在云中使用 PySpark,请参阅您的提供商文档。 每个云提供商都有不同的方式来管理 Spark 依赖项和库。 要快速回顾最流行的 Spark 云产品,请参阅附录 C。
最后,我们可以(重新)启动我们的 PySpark shell,安装新的库。 pyspark 和 spark-submit 命令采用可选的 --jars 参数,用于加载 Spark 安装的外部依赖项。
pyspark --jars spark-bigquery-latest.jar或者,如果您通过 Python/IPython shell 使用 PySpark,则可以在创建 SparkSession 时直接从 Maven(Java/Scala 的 PyPI 等价物)加载库。
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(
"spark.jars.packages",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.11:0.15.1-beta", ❶
).getOrCreate()
# Ivy Default Cache set to: /Users/jonathan_rioux/.ivy2/cache
# The jars for the packages stored in: /Users/jonathan_rioux/.ivy2/jars
# :: loading settings :: url = jar:file:/usr/local/Cellar/apache-spark/2.4.5/libexec/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
# com.google.cloud.spark#spark-bigquery-with-dependencies_2.11 added as a dependency
# :: resolving dependencies :: org.apache.spark#spark-submit-parent-035f1392-cda4-4935-a62b-969bda5449d5;1.0
# confs: [default]
# found com.google.cloud.spark#spark-bigquery-with-dependencies_2.11;0.15.1-beta in central
# :: resolution report :: resolve 134ms :: artifacts dl 2ms
# :: modules in use:
# com.google.cloud.spark#spark-bigquery-with-dependencies_2.11;0.15.1-beta from central in [default]
# ---------------------------------------------------------------------
# | | modules || artifacts |
# | conf | number| search|dwnlded|evicted|| number|dwnlded|
# ---------------------------------------------------------------------
# | default | 1 | 0 | 0 | 0 || 1 | 0 |
# ---------------------------------------------------------------------
# :: retrieving :: org.apache.spark#spark-submit-parent-035f1392-cda4-4935-a62b-969bda5449d5
# confs: [default]
# 0 artifacts copied, 1 already retrieved (0kB/4ms)
# [...]❶我拿的是最新的Spark/Scala版本推荐的包版本(2.4.5/2.11)
如果您有一个 SparkSession 已经在进行中,那么仅仅 spark.stop() 并尝试重新启动是不够的。 您需要完全停止 JVM 进程。 尝试在不重新启动 PySpark/Python REPL 的情况下执行此操作是一种令人沮丧的练习,因此只需终止并重新开始。 如果你使用代码清单 8.12 中的方法并且没有看到类似的 jar 语句,那么它就不会工作。
8.3.2 准备我们的数据
在我们开始处理我们的 pandas UDF 之前,我们需要从 BigQuery 中提取数据并将多个表组装到一个内聚的数据框架中。 从 BigQuery 读取数据非常简单。 我使用 bigquery 专用的 SparkReader——由我们嵌入到 PySpark shell 的连接器库提供——提供两个选项:
表参数,指向我们要摄取的表。 格式为project.dataset.table:bigquery-public-data是一个所有人都可以使用的项目。
credentialsFile 是 8.3.1 中下载的 JSON 密钥。 您需要根据文件的位置相应地调整路径和文件名。
如果您使用的是 Google DataProc,则无需提供 credentialsFile,因为权限将通过您的 GCP 帐户授予。 BigQuery 连接器的文档将提供最新的说明。 附录 C 涵盖云中的 Spark,包括 Google DataProc。
该代码在清单 8.13 中可用。 对于我的 gsod 表,我需要将这些表联合到一个单一的内聚数据框中。 虽然我可以像第 7 章那样链接多个 union(),但我使用 reduce 运算符走了一条更优雅的路线,这次是将它应用到我的列表理解中。
from functools import reduce
from pyspark.sql import DataFrame
def read_df_from_bq(year): ❶
return (
spark.read.format("bigquery") ❷
.option("table", f"bigquery-public-data.noaa_gsod.gsod{year}") ❸
.option("credentialsFile", "bq-key.json") ❹
.load()
gsod = (
reduce(
DataFrame.union, [read_df_from_bq(year) for year in range(2010, 2020)] ❺
.dropna(subset=["year", "mo", "da", "temp"])
.where(F.col("temp") != 9999.9)
)❶由于所有表格的读取方式相同,我将读取例程抽象为一个可重用的函数,返回结果数据框。
❷我通过 format() 方法使用 bigquery specialized reader。
❸stations 表在 BigQuery 下的 bigquery-public-data.noaa_gsod.gsodXXXX 下可用,其中 XXXX 是四位数年份。
❹我将我的 JSON 服务帐户密钥传递给 credentialsFile 选项,以告诉 Google 我可以使用 BigQuery 服务。
❺DataFrame.union 可以作为参数传递给 reduce,它将我列表中的所有表成对合并为一个表。
如果我们把它分解成离散的步骤,就更容易理解 reduce 操作。
我从一系列年份开始(在我的示例中为 2010 年至 2020 年,包括 2010 年但不包括 2020 年)。 为此,我使用 range() 函数。
我通过列表推导将我的辅助函数 read_df_from_bq() 应用于每年,生成一个数据框列表。 我不必担心内存消耗,因为列表仅包含对数据框 (DataFrame[...]) 的引用。
作为缩减函数,我使用 DataFrame.union 函数。 此方法在应用于数据框 (df.union()) 时采用单个参数,因为有一个隐式 self 映射到调用该方法的数据框。 如果我们静态地应用该函数,从通用的 DataFrame 对象中使用它,那么它会将两个数据帧作为参数并将数据帧合并为一个数据帧。
我们可以使用 for 循环迭代地执行此操作。 在清单 8.14 中,我展示了如何在不使用 reduce() 的情况下实现相同的目标。 由于高阶函数通常会产生更清晰的代码,所以我更喜欢使用它们而不是在有意义的地方循环构造。
gsod_alt = read_df_from_bq(2010) ❶
for year in range(2011, 2020):
gsod_alt = gsod_alt.union(read_df_from_bq(year))❶当使用循环方法联合表时,您需要一个显式的起始种子。 我使用 2010 年的表格。
reduce 方法只有在所有表都没有任何问题的情况下才有效; 相同的模式,来自列名、顺序和类型。 谷歌通过为我们预先清理所有数据来为我们做实事
如果您使用的是本地 Spark,加载 2010-2019 将使本章中的示例相当慢。 我仅在处理本地实例时才使用 2018,这样我就不必等待太长时间来执行代码。 相反,如果您正在使用更强大的设置,则可以将年数添加到范围中。 gsod 表可以追溯到 1929 年。
8.3.3 标量 UDF
标量 UDF 是最常见的 pandas UDF 类型。 顾名思义,它们处理标量值:对于传入的每条记录,它需要返回一条记录。 它们的行为就像常规的 Python UDF,只有一个关键区别。 Python UDF 一次处理一条记录,您可以通过常规 Python 代码表达您的逻辑。 标量 UDF 一次处理一个系列,您可以通过 pandas 代码表达您的逻辑。 区别很微妙,而且更容易从视觉上解释。
在 Python UDF 中,当您将列对象传递给 UDF 时,PySpark 将解压每个值,执行计算,然后返回 Column 对象中每条记录的值。 在标量 UDF 中,如图 8.5 所示,PySpark 将(通过 PyArrow)每个分区列序列化为 pandas Series 对象(pandas.Series - pandas 1.5.2 文档)。 然后,您直接对 Series 对象执行操作,从您的 UDF 返回一个具有相同维度的 Series。 从最终用户的角度来看,它们在功能上是相同的。在第 9 章中,我讨论了 Python UDF 与标量 UDF 的性能影响。
图 8.5。 将 Python UDF 与 pandas 标量 UDF 进行比较。 前者将一列拆分为单个记录,后者将它们拆分为系列。
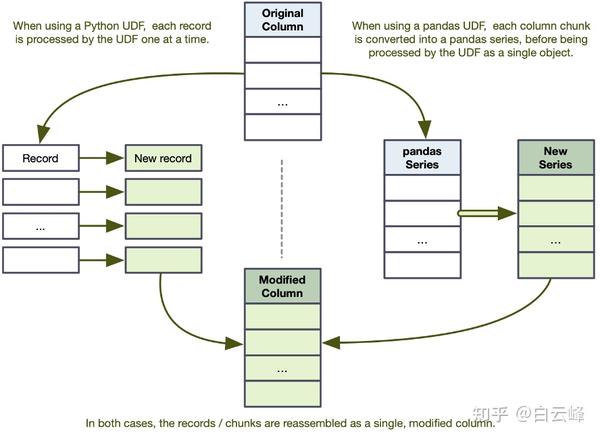
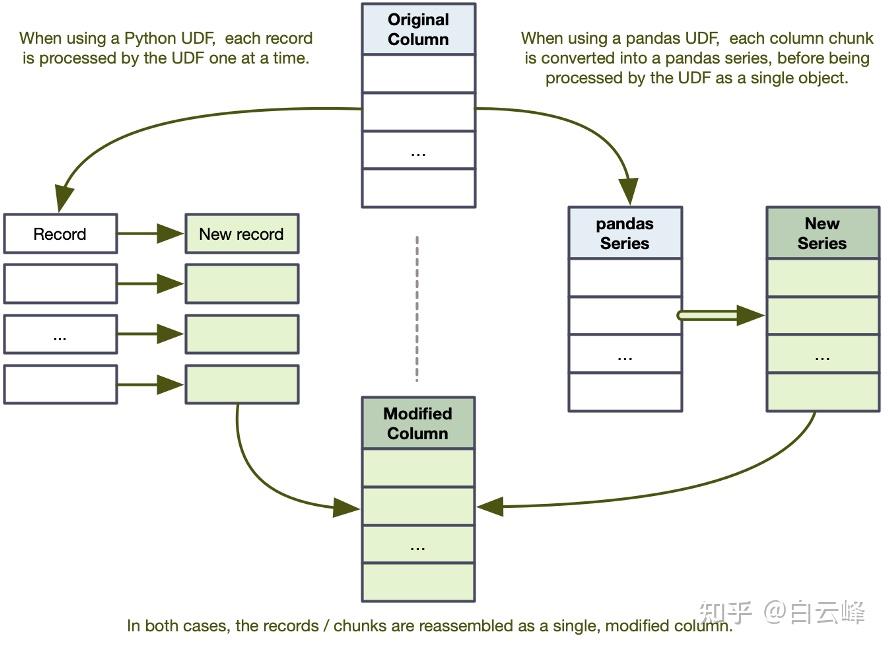
PySpark 不保证您传递给标量 UDF 的列将如何在系列中拆分,因此您需要确保您的 UDF 不依赖于特定的细分。 对中断的更多控制,参见代码清单 8.17。
现在有了它是如何工作的? 标量 UDF,让我们自己创建一个。 我选择创建一个简单的函数,将华氏度转换为摄氏度。 在加拿大,我们根据用途使用两种量表:F 用于烹饪,C 用于体温或室外温度。 我不知道 95 华氏度是热还是冷,但我知道在 10 摄氏度时如何穿衣,但我的晚餐在 350 华氏度时烹饪。
我的函数如清单 8.15 所示。 构建块非常相似; 有两个明显的主要区别。
我再次使用 pyspark.sql.functions 模块中的 pandas_udf() 而不是 udf()。 第一个参数是函数的返回类型 (DoubleType()),第二个参数是我正在创建的 pandas UDF 类型的指示符,这里是 PandasUDFType.SCALAR。
我的代码本身可以按原样用于常规 python UDF。 我(ab)使用了你可以用 pandas Series 进行算术运算的事实。 如果需要,您可以使用任何 Series 方法。
import pandas as pd
@F.pandas_udf(T.DoubleType(), F.PandasUDFType.SCALAR) ❶
def f_to_c(degrees):
"""Transforms Farhenheit to Celcius."""
return (degrees - 32) * 5 / 9
f_to_c.func(pd.Series(range(32, 213))) ❷
# 0 0.000000
# 1 0.555556
# 2 1.111111
# 3 1.666667
# 4 2.222222
# ...
# 176 97.777778
# 177 98.333333
# 178 98.888889
# 179 99.444444
# 180 100.000000
# Length: 181, dtype: float64
gsod = gsod.withColumn("temp_c", f_to_c(F.col("temp")))
gsod.select("temp", "temp_c").distinct().show(5)
# +-----+-------------------+
# | temp| temp_c|
# +-----+-------------------+
# | 37.2| 2.8888888888888906|
# | 85.9| 29.944444444444443|
# | 53.5| 11.944444444444445|
# | 71.6| 21.999999999999996|
# |-27.6|-33.111111111111114|
# +-----+-------------------+
# only showing top 5 rows❶对于标量UDF,最大的变化发生在使用的装饰器上。 我也可以直接使用 pandas_udf 函数。
❷为了测试我的函数,我将它应用于从 32 到 212(包括 0 到 100 摄氏度)的每个华氏度值,使用返回 UDF 的本地版本的 func 属性。
标量 UDF 与 Python 常规 UDF 一样,在您要应用于数据框的记录方式转换(或“映射”)在库存 PySpark 函数 (pyspark.sql.functions) 中不可用时非常方便。 创建一个“华氏度到摄氏度”转换器作为核心 Spark 的一部分会有点紧张,因此使用 PySpark 或 (pandas) 标量 UDF 是一种扩展核心功能的方法,而且不会大惊小怪。 接下来,我们将了解如何更好地控制拆分并在 PySpark 中使用拆分-应用-组合模式。
词汇很重要:分区与块
在谈论 PySpark 如何为 pandas UDF 拆分数据时,使用分区这个词可能很诱人。 不过,Spark 已经有了分区的概念:它们指的是工作节点上包含的物理数据。 使用 pandas UDF 时,Spark 可以将分区用作块,但也可以决定拆分它们或四处移动一些数据。 因此,我改用块或组(用于分组的 pandas UDF)。 更少的困惑,更多的数据乐趣。
8.3.4 分组地图UDF
分组映射 UDF 是 PySpark 对拆分-应用-组合模式的回答。 拆分-应用-组合的核心只是数据分析中经常使用的一系列三个步骤。
首先,您将数据集拆分为逻辑块。
然后,您将一个函数独立地应用于每个块。
最后,您将这些块组合成一个统一的数据集。
老实说,直到有一天有人指着我的代码说“这是你在那里做的一些很好的拆分-应用-组合工作”,我才知道这个模式的名字。 您可能也会直观地使用它。 在 PySpark 的世界里,我更多地把它看作是一个划分和进程的移动,如图 8.6 所示。
图 8.6。 视觉上描绘的拆分-应用-组合。 我们对数据框进行分块/分组,用 pandas 处理每个数据框,然后再次将它们合并成一个 (Spark) 数据框。
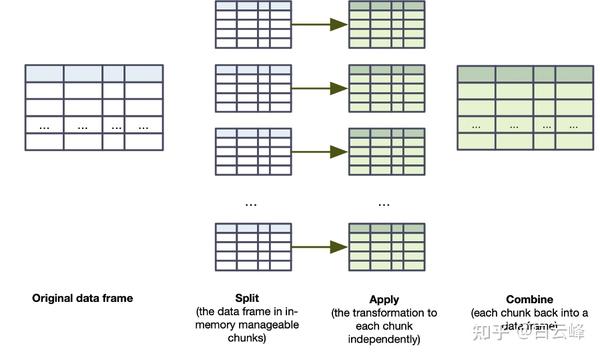
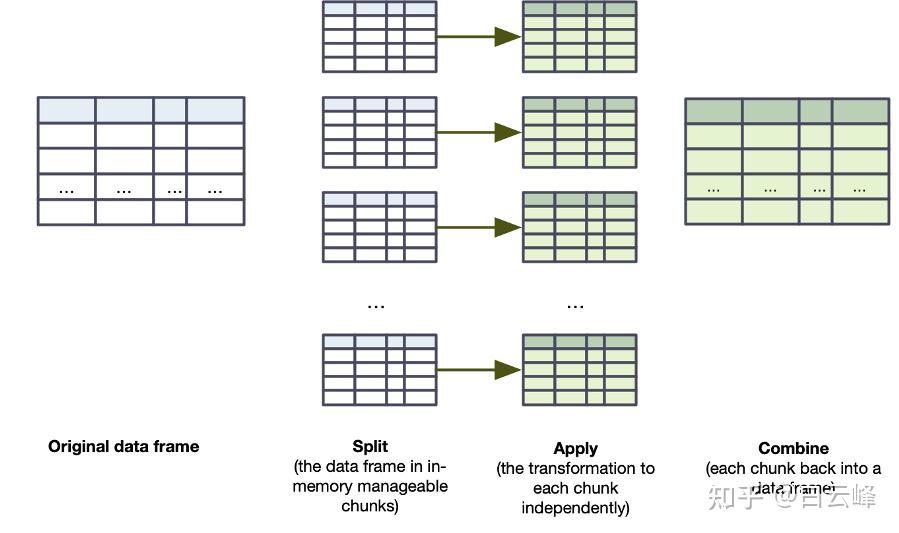
在查看 PySpark 管道之前,我们先关注等式的 pandas 方面。 标量 UDF 依赖于 pandas Series,分组地图 UDF 使用 pandas DataFrame。 图 8.6 中步骤 1 中的每个逻辑块都变成了一个准备好执行操作的 DataFrame。 我们的 UDF 还必须返回一个 DataFrame。
Grouped map UDF 也将 pandas_udf() 作为装饰器,这次使用的是 PandasUDFtype.GROUPED_MAP 类型。 返回类型也更冗长:因为我们在 pandas DataFrame 中有多个列,所以我们必须在 StructType() 中提供模式。 要更深入地了解模式,请前往第 6 章。
@F.pandas_udf(
T.StructType(
T.StructField("stn", T.StringType()),
T.StructField("year", T.StringType()),
T.StructField("mo", T.StringType()),
T.StructField("da", T.StringType()),
T.StructField("temp", T.DoubleType()),
T.StructField("temp_norm", T.DoubleType()),
F.PandasUDFType.GROUPED_MAP,
def scale_temperature(temp_by_day):
"""Returns a simple normalization of the temperature for a site.
If the temperature is constant for the whole window, defaults to 0.5."""
temp = temp_by_day.temp
answer = temp_by_day[["stn", "year", "mo", "da", "temp"]]
if temp.min() == temp.max():
return answer.assign(temp_norm=0.5)
return answer.assign(temp_norm=(temp - temp.min()) / (temp.max() - temp.min()))pandas_udf() 也将采用类似 SQL 的模式作为字符串参数。 对于清单 8.16,我们可以使用 stn string、name string、country string、year string、mo string、da string、temp double、temp_norm double 作为返回类型。
与本章到目前为止看到的 UDF 相比,主要区别在于 UDF 的返回类型。 在 Python 和标量 UDF 中,我们返回了单个列。 在这里,我们返回一个完整的 (pandas) DataFrame。 在清单 8.16 中,我们返回的 DataFrame 包含六列。 我的 UDF 只添加了一个新列 temp_norm,它将从零到一的标度接收到的温度列进行缩放。 由于我的 UDF 中有一个除法,如果我的块中的最低温度等于最高温度,我将给出一个合理的值 0.5。 默认情况下,pandas 将为除以零提供无限值:PySpark 会将其解释为 null。
现在完成了“应用”步骤,剩下的就是小菜一碟。 我在第 5 章打破了重点:我们使用 groupby() 将数据帧拆分为可管理的块,然后将我们的函数传递给 apply() 方法。 您可以在清单 8.17 中看到结果。
gsod = gsod.where(F.col("year") == "2018") ❶
gsod = gsod.groupby("stn", "year", "mo").apply(scale_temperature)
gsod.show(5, False)
# +------+----+---+---+-------------------+-------------------+
# |stn |year|mo |da |temp_c |temp_norm |
# +------+----+---+---+-------------------+-------------------+
# |010250|2018|12 |08 |-5.666666666666667 |0.06282722513088991|
# |010250|2018|12 |27 |-2.0555555555555554|0.40314136125654443|
# |010250|2018|12 |31 |-1.6111111111111103|0.4450261780104712 |
# |010250|2018|12 |19 |-2.4444444444444438|0.3664921465968586 |
# |010250|2018|12 |04 |2.5555555555555562 |0.8376963350785341 |
# +------+----+---+---+-------------------+-------------------+
# only showing top 5 rows❶如果您在本地工作,保留一年的数据将确保您不会等待太久才能获得结果。
我按三个字段分组,stn、year 和 mo。 与第 5 章中看到的 groupby()/agg() 组合不同,其中键隐式存在于结果数据框中,应用的 UDF 需要返回我们想要在结果数据框中出现的任何列。 我的 UDF 在其返回值中有六列,apply() 之后的数据框有相同的六列,遵循表 8.1 中看到的相同类型等价。 实际上,您创建分组映射 UDF 时考虑了 groupby() 模式,因此不匹配的风险很低。
能力越大,责任越大:按数据框分组时,确保每个块都是“熊猫大小”,即它可以舒适地加载到内存中。 如果一个或多个块太大,您将遇到内存不足的异常。
当您拥有可以独立处理的不同数据组时,分组地图 UDF 会大放异彩。 在清单 8.17 的例子中,我们为(站、年、月)的每个组合缩放温度。 当您觉得您的代码可以处理数据框中的一些不同组时,分组地图 UDF 是一个不错的选择。
8.3.5 分组聚合 UDF
我们使用分组聚合 UDF 结束了对 pandas 用户定义函数的浏览。 它们可以被认为是我们目前所见的组合,因为它们将 pandas Series 作为参数但返回一个简单的标量值。 从这个意义上说,它们类似于 Spark 聚合函数:每个组都由一个值汇总。
对于分组聚合 UDF,我们仍然依赖于 groupby() 提供的“拆分”步骤——这使得它们类似于分组映射 UDF——但这次,我们将 UDF 应用于 agg() 方法,只是聚合函数。 对于我的分组聚合 UDF,我想做一些比重现常见违规者(计数、最小值、最大值、平均值)更复杂的事情。 在清单 8.18 中,我使用 scikit-learn 的 LinearRegression 对象计算给定时间段内(缩放的)温度的线性斜率。 您无需了解 scikit-learn 或机器学习即可继续:我正在使用基本功能并解释每个步骤。
这不是机器学习练习:我只是使用 scikit-learn 的管道来创建一个功能。 本书的第 3 部分介绍了 Spark 中的机器学习。 不要将这段代码当作健壮的模型训练练习!
from sklearn.linear_model import LinearRegression ❶
@F.pandas_udf(T.DoubleType(), F.PandasUDFType.GROUPED_AGG)
def rate_of_change_temperature(day, temp):
"""Returns the slope of the daily temperature for a given period of time."""
return (
LinearRegression() ❷
.fit(X=day.astype("int").values.reshape(-1, 1), y=temp) ❸
.coef_[0] ❹
)❶我从 sklearn.linear_model 导入线性回归对象
❷我初始化LinearRegression对象。
❸fit方法训练模型,使用day Series作为特征,temp series作为预测。
❹因为我只有一个特征,所以我选择 coef_ 属性的第一个值作为我的斜率。
要在 scikit-learn 中训练模型,我们首先要初始化模型对象。 在这种情况下,我使用不带任何其他参数的 LinearRegression()。 然后我拟合模型,提供 X(我的特征矩阵)和 y(我的预测向量)。 在这种情况下,因为我只有一个特征,所以我需要重塑我的 X 矩阵,否则 scikit-learn 会抱怨形状不匹配。
在 fit 方法的最后,我们的 LinearRegression 对象训练了一个模型,并且在线性回归的情况下,将其系数保存在 coef_ 向量中。 因为我真的只关心系数,所以我只是提取并返回它。
将分组聚合 UDF 应用于我们的数据框很容易。 在清单 8.19 中,我 groupby() 站代码、名称和国家,以及年份和月份。 我将新创建的分组聚合函数作为参数传递给 agg(),将我的 Column 对象作为参数传递给 UDF。
result = gsod.groupby("stn", "year", "mo").agg(
rate_of_change_temperature(gsod["da"], gsod["temp_norm"]).alias( ❶
"rt_chg_temp"
result.show(5, False)
# +------+----+---+---------------------+
# |stn |year|mo |rt_chg_temp |
# +------+----+---+---------------------+
# |010250|2018|12 |-0.01014397905759162 |
# |011120|2018|11 |-0.01704736746691528 |
# |011150|2018|10 |-0.013510329829648423|
# |011510|2018|03 |0.020159116598556657 |
# |011800|2018|06 |0.012645501680677372 |
# +------+----+---+---------------------+
# only showing top 5 rows
result.groupby("stn").agg(
F.sum(F.when(F.col("rt_chg_temp") > 0, 1).otherwise(0)).alias("temp_increasing"),
F.count("rt_chg_temp").alias("count"),
).where(F.col("count") > 6).select(
F.col("stn"),
(F.col("temp_increasing") / F.col("count")).alias("temp_increasing_ratio"),
).orderBy(
"temp_increasing_ratio"
).show(
5, False
# +------+---------------------+ ❷
# |stn |temp_increasing_ratio|
# +------+---------------------+
# |681115|0.0 |
# |384572|0.0 |
# |682720|0.0 |
# |672310|0.0 |
# |654530|0.08333333333333333 |
# +------+---------------------+