


Python | 数据爬虫

最近实习的一项工作需要爬取交易所的行情数据。但是我从来没有做过爬虫,所以靠着度娘加上自己不断摸索最终完成了,发现爬虫是很有趣(?) 的一件事情。对于爬虫方法以及反爬手段也有了很多心得,在这里记录下来,希望能对看到这篇的朋友有所帮助。由于涉及到我的工作结果,所以完整的代码以及具体的内容格式修正不会展示,只会展示部分关键代码,因为不是计算机专业出身,一些网页结构相关原理讲得不是很清楚,只是代表我自己的理解,如有错误欢迎指正。
1. 获取URL
Internet上的每一个网页都具有一个唯一的名称标识,通常称之为 URL (Uniform Resource Locator, 统一资源定位器)。它是统一资源定位标志,简单地说URL就是web地址,俗称“网址”。
我们想实现的是输入指定日期,可以获取当日的期货/期权的行情数据,所以URL中必然含有对应日期。但是我们可以发现要想获得日行情数据,需要在交易所网页点击日历栏,选择日期、期货/期权、品种,然后点击“查询”,才会得到行情表。(如下图所示,以郑商所为例)
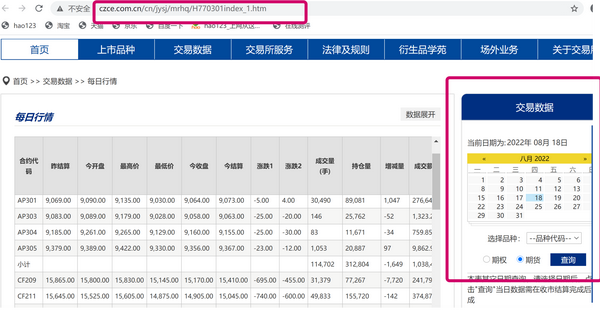
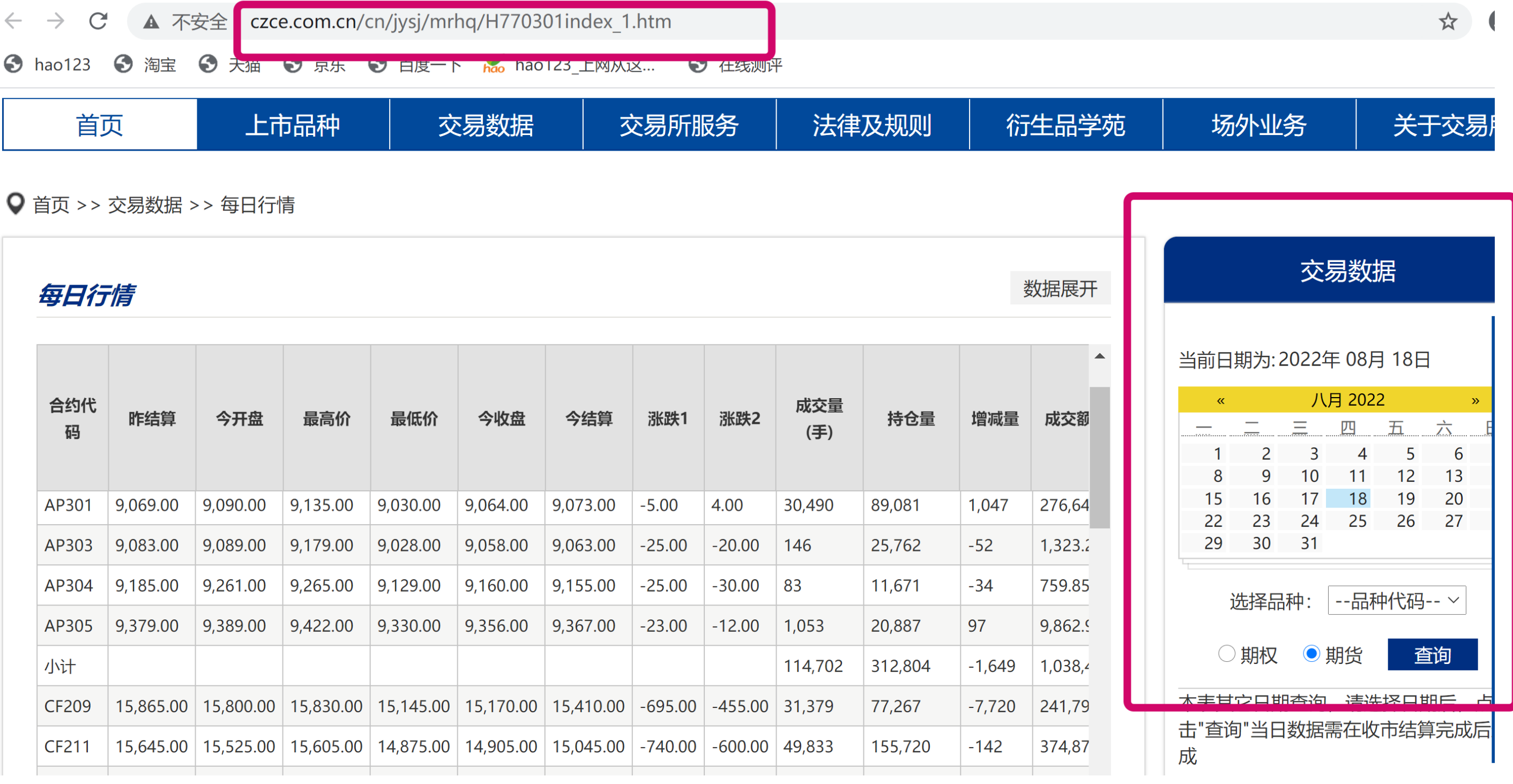
此时图中最上面搜索栏对应的网址并不是我们想要的最终URL,我们需要通过开发者工具,来获取我们想要的request URL。我们可以在谷歌浏览器按F12,通过查看网络界面来查看header等与网络连接相关的信息。
具体操作:F12--Network--All-ctrlR刷新页面--通过search方法搜索合约名快速定位--查看Headers--General--Request URL, 即可获得包含我们想要的网络信息的URL。
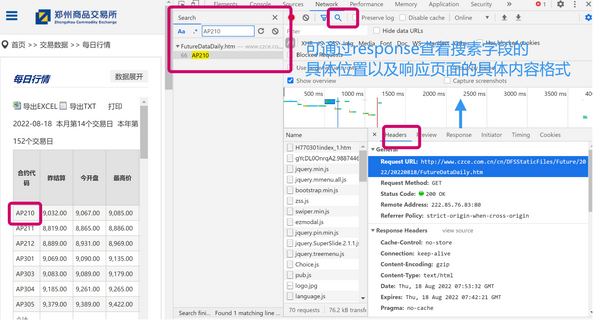
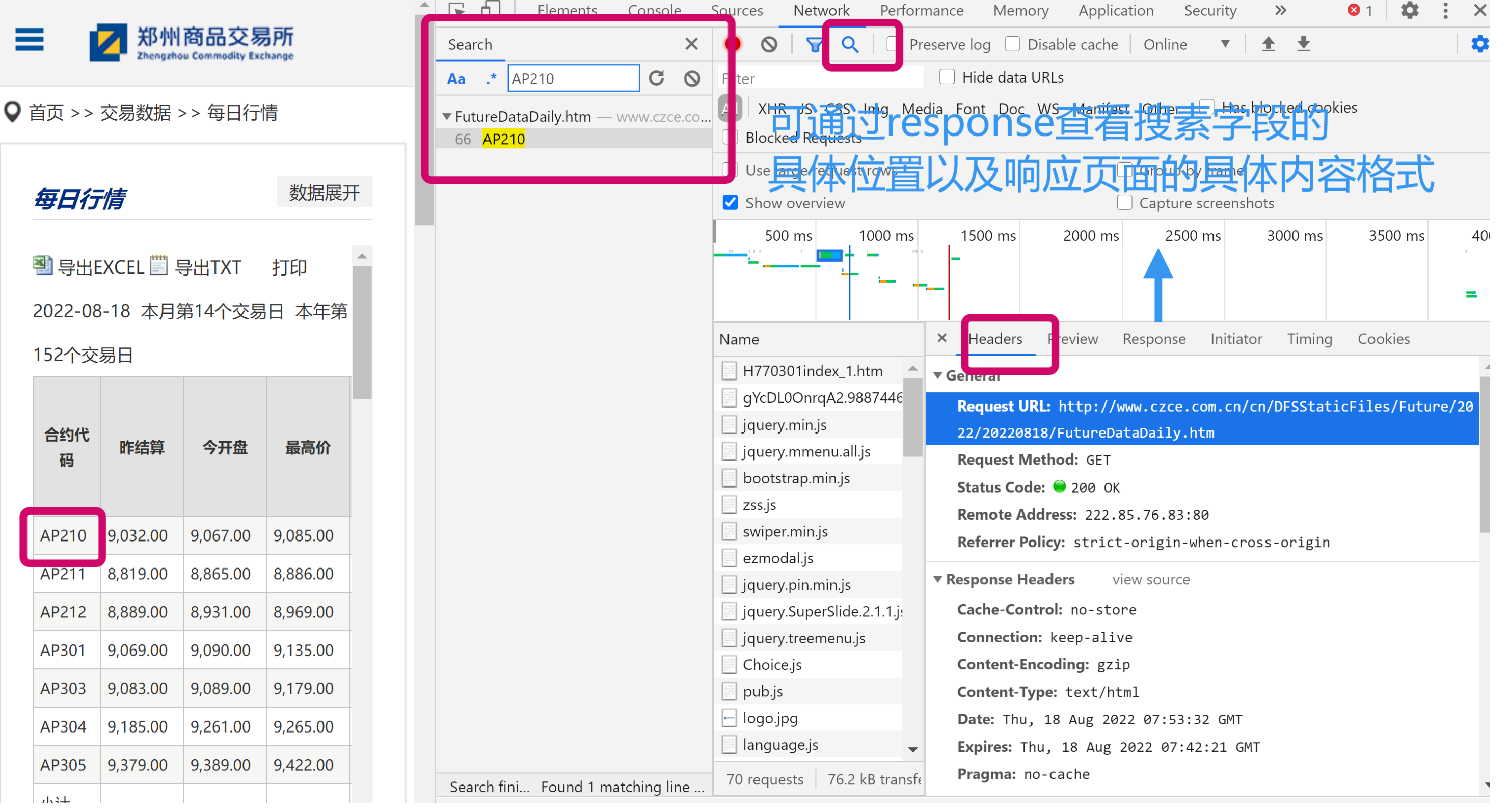
通过以上方法我们得到了各所某特定日期的行情数据request URL:
date = '20220818'
#郑商所--期货
url1 = "http://www.czce.com.cn/cn/DFSStaticFiles/Future/2022/"+date+"/FutureDataDaily.htm"
#郑商所--期权
url2 = "http://www.czce.com.cn/cn/DFSStaticFiles/Option/2022/"+date+"/OptionDataDaily.htm"
url = "http://www.cffex.com.cn/sj/hqsj/rtj/" + str(date[0:6]) + "/" + str(date[6:8]) + "/index.xml?id=39"
#上期所--期货
url1 = "https://www.shfe.com.cn/data/dailydata/kx/kx"+date+".dat"
#上期所--期权
url2 = "https://www.shfe.com.cn/data/dailydata/option/kx/kx"+date+".dat"
#大商所--期货
url1 = 'http://www.dce.com.cn/publicweb/quotesdata/dayQuotesCh.html?dayQuotes.variety=all&dayQuotes.trade_type=0&' \
'year='+str(date[0:4]) + '&month=' + str(int(date[4:6]) - 1) + '&day=' + str(int(date[6:8]))
#大商所--期权
url2 = 'http://www.dce.com.cn/publicweb/quotesdata/dayQuotesCh.html?dayQuotes.variety=all&dayQuotes.trade_type=1' \
'&year='+str(date[0:4]) + '&month=' + str(int(date[4:6]) - 1) + '&day=' + str(int(date[6:8]))
2. 获取并解析网页内容
我们想通过标签来定位我们所需的数据,进而将这些数据从网页代码中解析出来。
要想获得网页代码,我们需要向目标站点发起请求,服务器响应后会传给我们一个response,将我们所需的网页内容(HTML、JSON等)发给我们,根据其内容类型我们来进行解析。我们利用request库的get函数来获取。并可以通过response.text来分析网页内容。
2.1 HTML
HTML (HyperText Markup Language,超文本标记语言)是一种用于创建网页的标准标记语言。它包括一系列 标签 ,通过这些标签可以将网络上的 文档 格式统一,使分散的 Internet 资源连接为一个逻辑整体。
反爬机制:某些门户网站会对访问该网站的请求中的User-Agent进行捕获和判断,如果该请求的User-Agent为爬虫程序,则拒绝向该请求提供数据。我们可以通过伪装header来构造模拟浏览器 :
fake_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/
537.36 (KHTML, like Gecko) Chrome/79.0
.3945.79 Safari/537.36'}
response = requests.get(url, headers=fake_headers) # 请求参数里面把假的请求header加上
file_obj = open('zss.html', 'w', encoding="utf-8") # 以写模式打开名叫 zss.html的文件,指定编码为utf-8
file_obj.write(response.content.decode('utf-8')) # 把响应的html内容
file_obj = open('zss.html', 'r', encoding="utf-8") # 以读方式打开文件名为douban.html的文件
html = file_obj.read() # 把文件的内容全部读取出来并赋值给html变量
由print出的response.text结果可以看到中金所的请求内容很简洁,我们可以利用正则方法来获得所需的数据。将请求内容与真实数据对比,可获得与不同pattern相匹配的全部内容。利用re.findall函数。
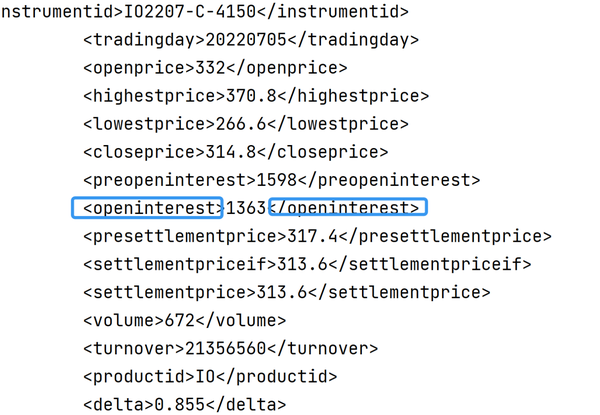
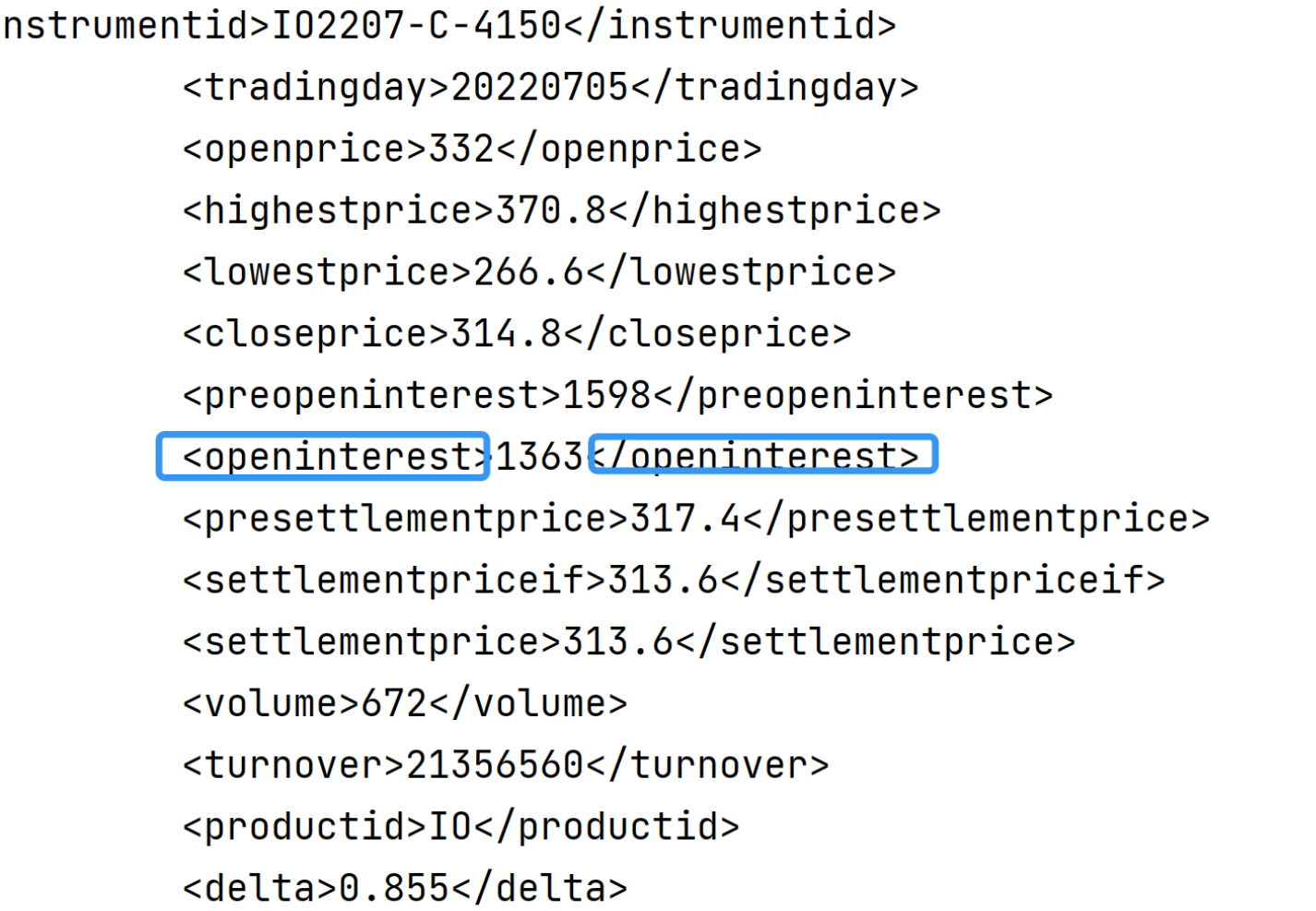
pat0 = r'<productid>(.*)</productid>' # 品种代码
pat1 = r' <instrumentid>(.*)</instrumentid>' # 合约代码
pat2 = r'<volume>(.*)</volume>' # 成交量
pat3 = r'<openinterest>(.*)</openinterest>' # 今持仓
pat4 = r'<preopeninterest>(.*)</preopeninterest>' # 前持仓
pat5 = r'<settlementpriceif>(.*)</settlementpriceif>' # 今结算
pat6 = r'<presettlementprice>(.*)</presettlementprice>' # 前结算
data1 = {
'品种代码': re.findall(pat0, html),
'合约代码': re.findall(pat1,html ),
'成交量': re.findall(pat2, html),
'今持仓': re.findall(pat3, html),
'前持仓': re.findall(pat4, html),
'今结算': re.findall(pat5,html),
'前结算': re.findall(pat6, html),
df1 = pd.DataFrame(data1)而对于郑商所而言我们可以看到响应的存储形式为表格的形式,数据都是存在<body>标签下。
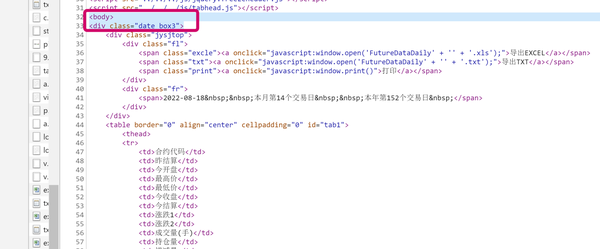
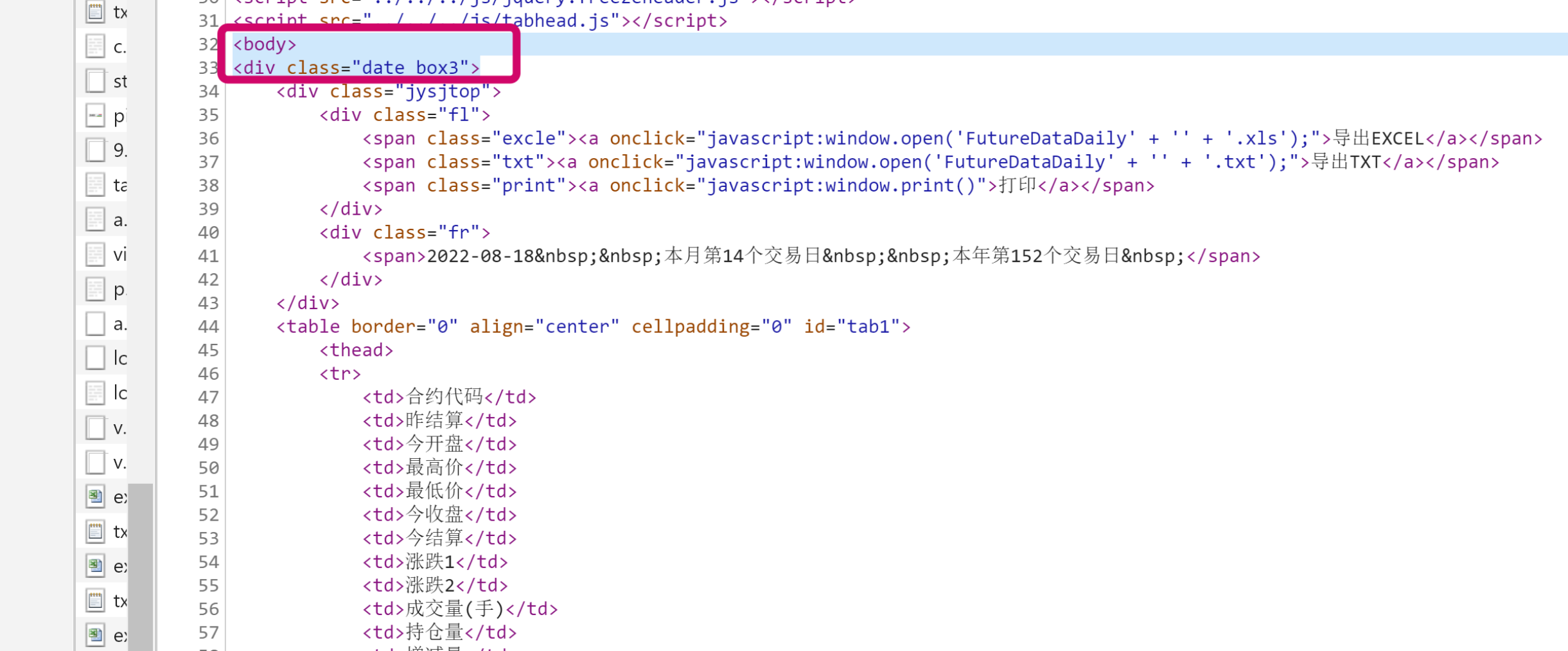
Beautiful Soup是一个可以从HTML或XML中提取数据的Python库。可根据class名来对数据进行定位。分析页面代码我们可以发现数据全部存储在”date_box3“这个class中,而每一行的数据都存储在两个<tr>之间。
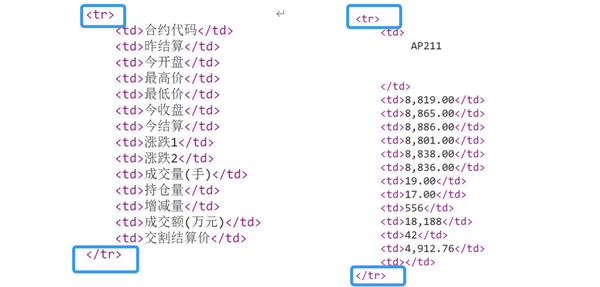

所以我们试图找到这个class下的所有tr标签,将其内容解析出来。
from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup
soup = BeautifulSoup(Z_html(date), 'lxml') # 初始化BeautifulSoup
trade_data = soup.find('div', class_="date_box3").find_all('tr') # 先找到最大的div,对应的class与标签这样我们就解析出了所有的<tr>的内容。可以观察到我们想要的数据都存在于<td>之间 :
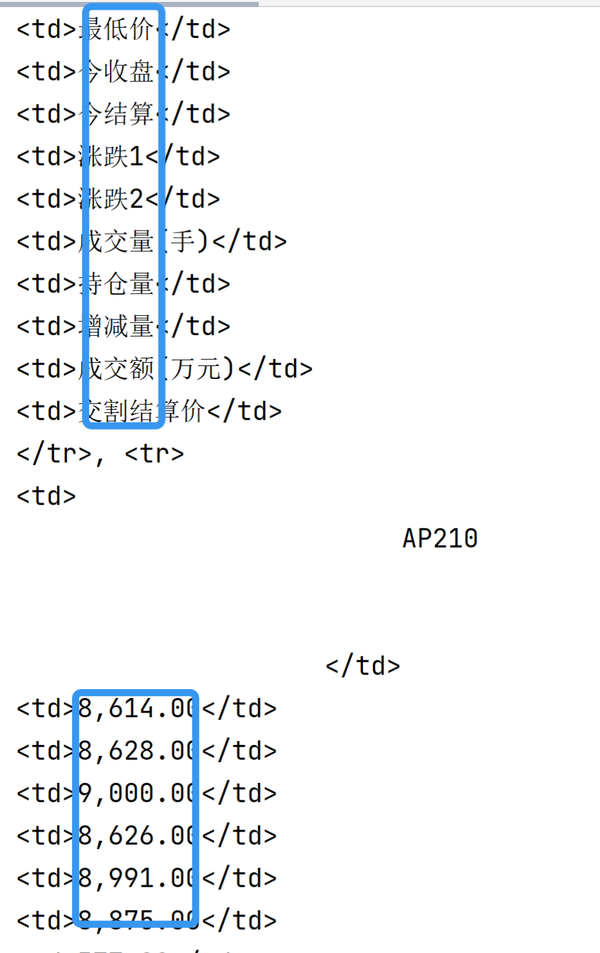
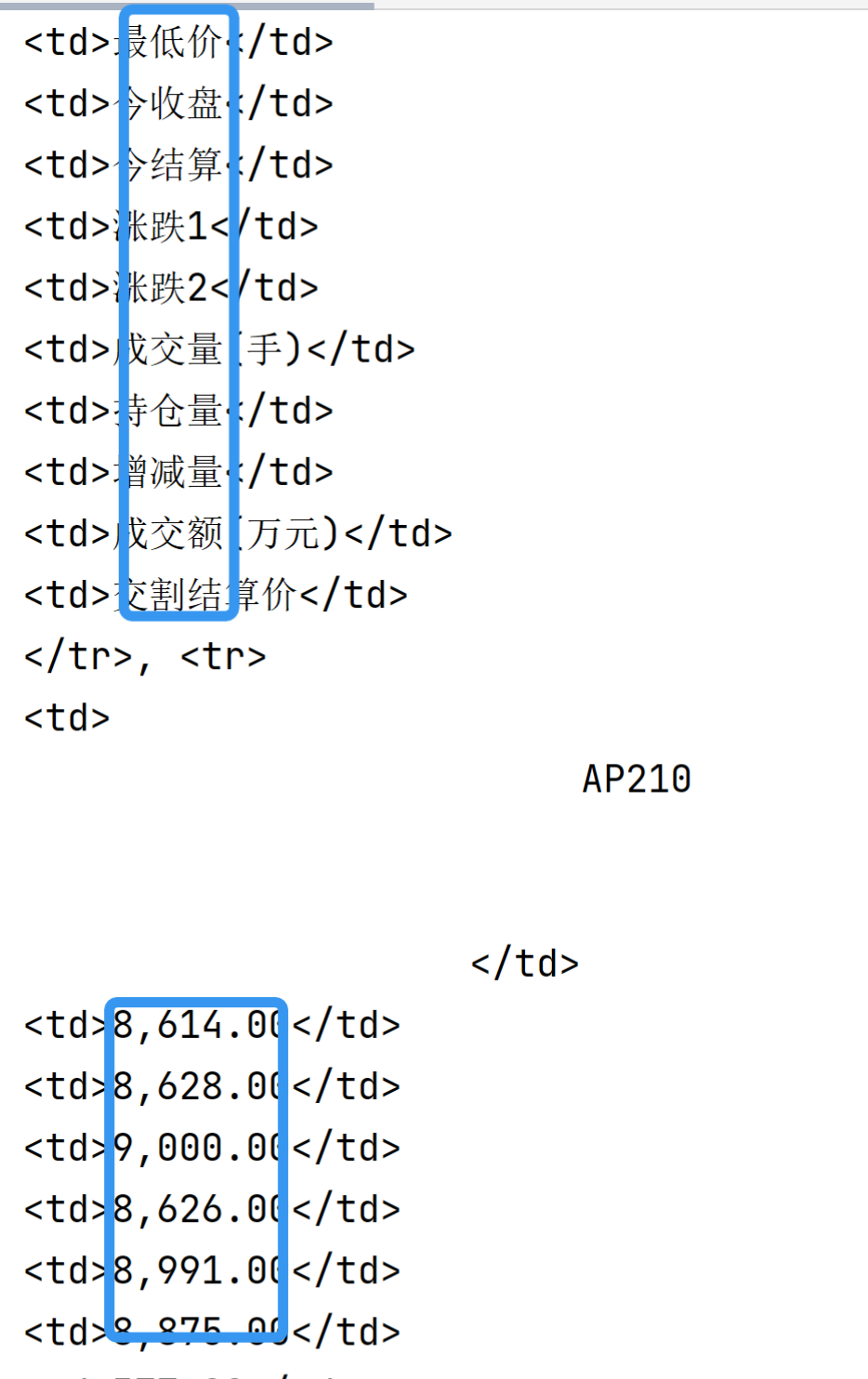
我们需要将每两个<tr>标签之间的<td>解析出来,存入一个list中,最后就得到了我们所需要的表。
listtotal=[]
for j in range(len(trade_data)-2):
td = trade_data [j].find_all('td')
listcol = []
for i in range(len(td)):
listcol.append(td[i].get_text().strip())
listtotal.append(listcol)
df=pd.DataFrame(listtotal)#这时候是以行为标准写入的
df.columns = listtotal[0]
df.drop([0], inplace=True)2.2 JSON
JSON ( JavaScript Object Notation, JS对象简谱)是一种轻量级的数据交换格式。它基于 ECMAScript (European Computer Manufacturers Association, 欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
对于上期所,我们发现请求的内容为JSON格式:
fake_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/
537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
response = requests.post(url, headers=fake_headers)
print(response.text)

所以需要利用JSON包来进行解析,发现解析后为一个列表,列表内容为每个合约对应一个字典 :
trade_data = json.loads(response.text)['o_curinstrument']
print(trade_data)

可直接存入dataframe:
df = pd.DataFrame.from_dict(trade_data)3. Selenium反爬
在爬取大商所的行情数据时出现了问题,前期按照前面的方法是可以爬取的,但是后面就开始返回状态码为412。
状态码 412含义为:Precondition Failed,服务器在验证在请求的头字段中给出先决条件时,没能满足其中的一个或多个。这个状态码允许客户端在获取资源时在请求的元信息(请求头字段数据)中设置先决条件,以此避免该请求方法被应用到其希望的内容以外的资源上。
也就是说,我们被系统反爬虫机制识别到了。之后采用添加cookie与伪装header的办法都无法解决,于是采用Selenium来进行爬取。
Selenium 是一个用于web应用程序 自动化测试 的工具,直接运行在浏览器当中,支持chrome、firefox等主流浏览器。可以通过代码控制与页面上元素进行交互(点击、输入等),也可以获取指定元素的内容。
也就是说,它不需要像前面讲述的方法那样构造请求再解析数据,而是自动为我们生成一个浏览器环境,我们通过设置参数让对方误以为我们是在进行正常的人为交互操作,因此不易被反爬虫机制命中。而它的缺点就在于只有当页面被完全加载的时候才可以进一步获取数据,可能会存在超时访问的问题,我们需要加入显式/隐式等待,这里对应的浏览器驱动选择的是火狐浏览器(谷歌一直出现无法访问的bug)。
options = webdriver.FirefoxOptions()
options.page_load_strategy = 'eager'
options.set_preference('devtools.netmonitor.responseBodyLimit', 0)
from selenium.webdriver.chrome.service import Service
s = Service('此处为浏览器对应的geckodriver.exe的地址')
driver = webdriver.Firefox(service=s, options=options)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
driver.implicitly_wait(60)
driver.get(url)
# 显式等待:显式地等待某个元素被加载,总计出现在<ul class="infoTip"><li>说明: </li>之前
wait = WebDriverWait(driver, 10, 0.1)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'infoTip')))我们查看页面代码可以发现数据都保存在'dataArea'这一class内。我们需要利用 driver.find_element 函数按类名将数据取出。


data = driver.find_element(by=By.CLASS_NAME, value='dataArea')
print(type(data.text)) #<class 'str'>
print(data.text)
输出的结果为一整个字符串:
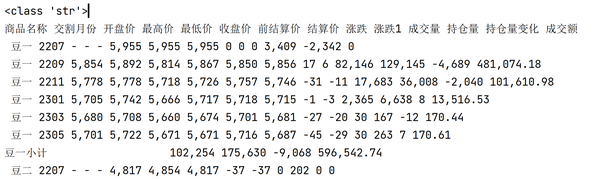
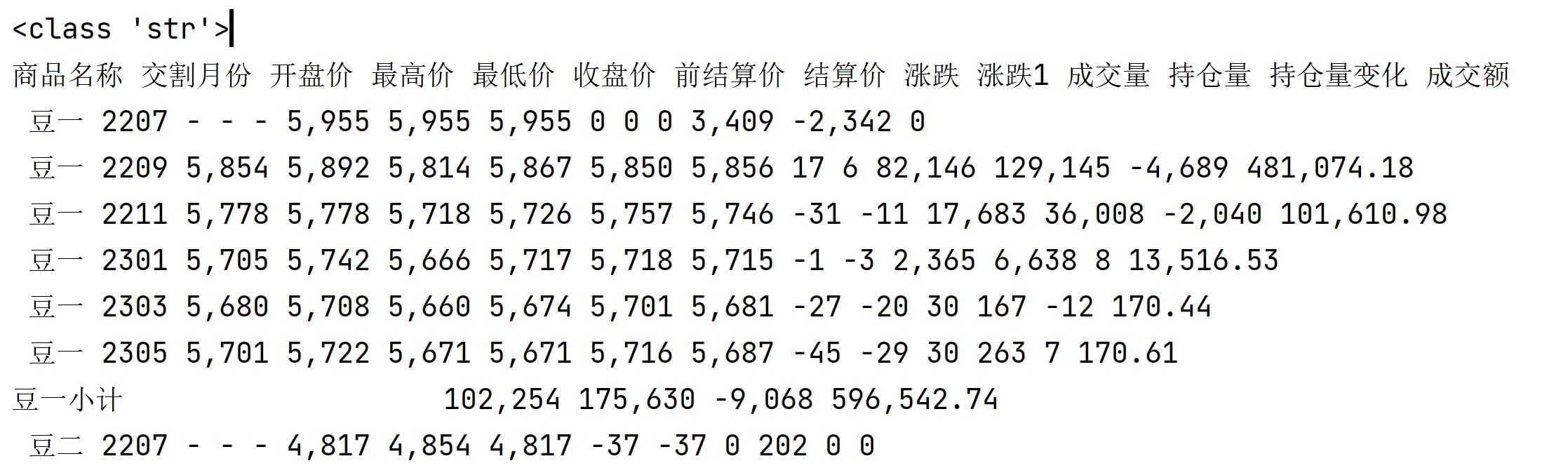
我们可先按换行符将整个字符串分隔,每行为一个字符串,再对每行数据用空格进行分隔,最后就得到了表格。
# 将字符串分隔开
datalist = data.text.split('\n')
driver.quit()
for i in range(len(datalist)):