


又快又稳,研究、落地全都要!姿态估计全能选手 RTMPose 来啦!


姿态估计,计算机视觉的核心任务之一,还原纷繁外表之下的空间信息,洞察千姿百态背后的本征结构。
MMPose 作为 OpenMMLab 开源算法体系中的姿态估计算法库,自 2020 年发布以来,经过 2 年的不断迭代打磨,已经成为姿态估计领域覆盖算法最多,功能最全的开源算法库之一。
近年来,前沿姿态估计算法不断迭代,在公开数据集上的性能屡创新高(目前姿态估计的 SOTA 算法精度已经在 MS COCO 数据集上超过了 80% AP),但在工业界的实际业务中, 主流应用的依然是几年前的算法。 明明有前沿的 SOTA 算法和模型,然而在真实的业务中却很难落地,工业界的小伙伴们只能望洋兴叹。为什么呢?
这一切的原因都在于,这些算法都 太慢了! 沉重的计算量与高昂的延迟,意味着昂贵的硬件与成本,而移动端和各种边缘设备由于算力本身受限,算法精度又会一落千丈。更何况,很多应用本身就对算法实时性有着极高的要求。
RTMPose,正是为此而来 。随着 MMPose 1.0 的发布,为了让 MMPose 能够在更多业务场景和产品中帮助到大家,MMPose 团队重点推进了业界可用的高性能算法的研发,经过潜心酝酿与砥砺打磨,RTMPose 终于来啦!
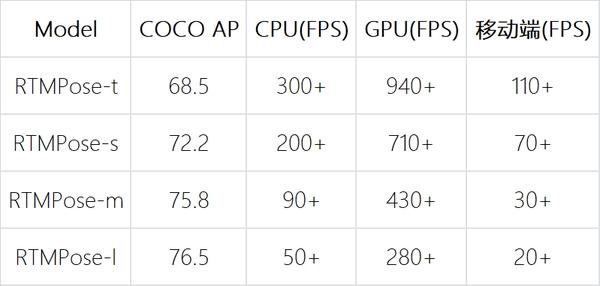
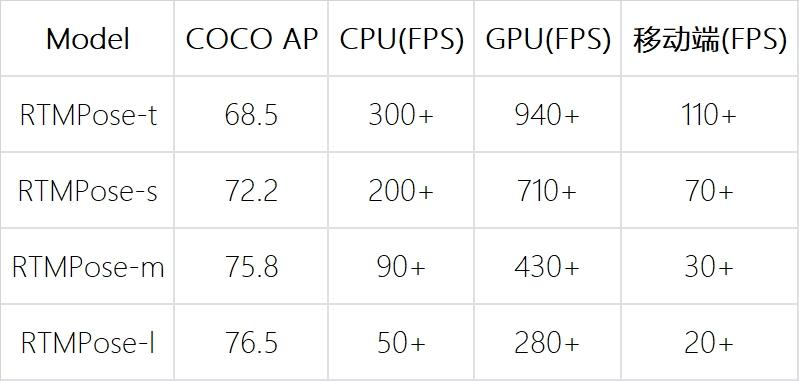
通过研究多人姿态估计算法的五个方面:范式、骨干网络、定位算法、训练策略和部署推理,我们的 RTMPose-m 模型在 COCO 上达到 75.8%AP 的同时,能在 Intel i7-11700 CPU 上用 ONNXRuntime 达到 90+FPS ,在 NVIDIA GTX 1660 Ti GPU 上用 TensorRT 达到 430+FPS。 RTMPose-s 以 72.2%AP 的性能,在手机端 Snapdragon865 芯片上用 ncnn 部署达到 70+FPS 。
在 MMDeploy 的帮助下,我们的项目支持 CPU、GPU、Jetson、移动端等多种平台,支持 ONNXRuntime、TensorRT、ncnn、OpenVINO、RKNN 等多种部署框架。
欢迎体验
效果展示
让我们一起先看看 RTMPose 的检测效果。





统一的性能对比
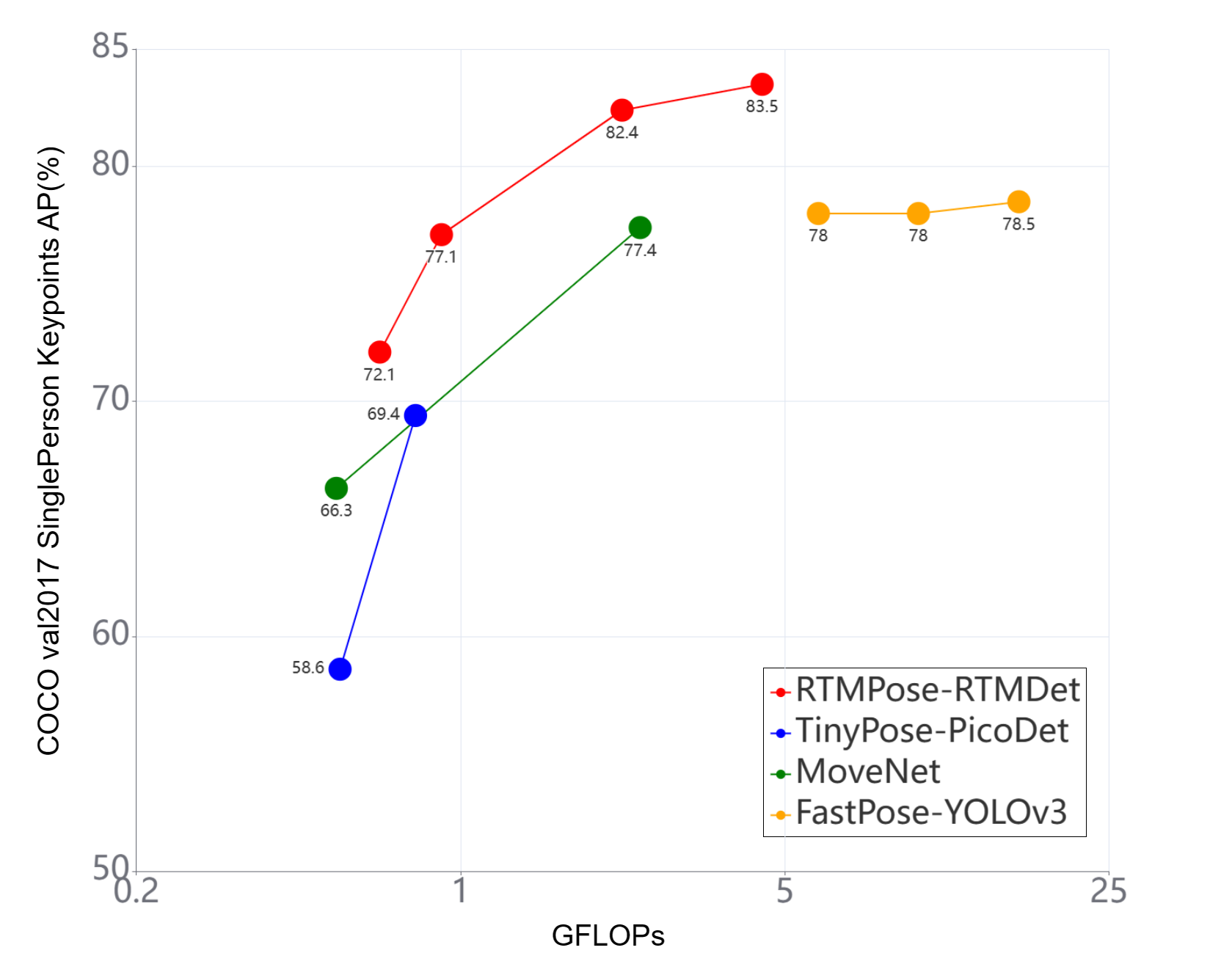
在调研过程中我们发现,当前市场上主流的姿态估计项目,比如基于 PaddleDetection 的 PP-TinyPose、上交开源的 AlphaPose、Google 发布的 MoveNet 和 MediaPipe 等,它们缺乏统一的对比,在汇报精度时,各自使用的验证集、硬件等都存在差异,即使是同一份 COCO val2017 数据集,大家也按照不同的标准进行了人工筛选和过滤,并且未公开。
于是,我们在相同硬件上逐一部署,在统一的 COCO val2017 上测试了它们的性能表现,与 RTMPose 进行对比。
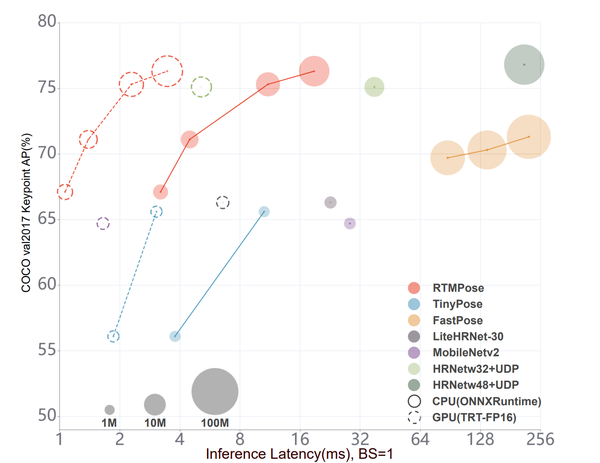

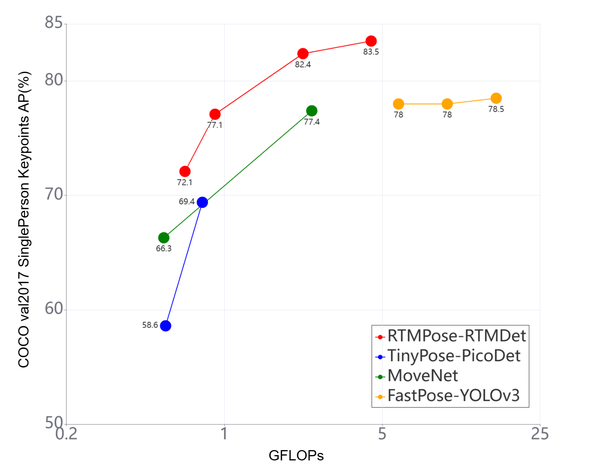
考虑到各自针对的应用场景不同,比如 PP-TinyPose 和 MoveNet 都是针对移动端设计的姿态估计算法,面向的也主要是单人姿态估计,所以我们也从 COCO val2017 构建了一个单人验证集来进行仔细对比。
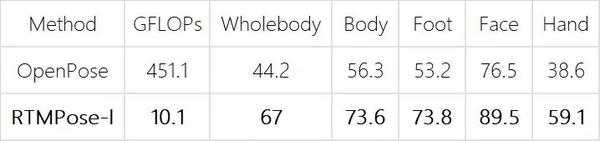
在全身姿态估计任务上,相较于成名许久的 OpenPose, RTMPose 也实现了全方位的超越。
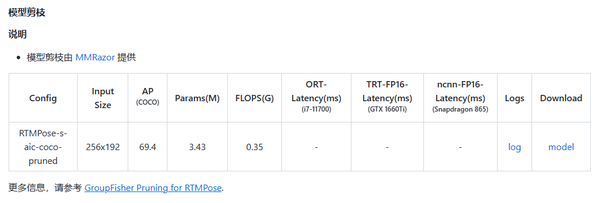
通过上述对比可以看到,RTMPose 与主流姿态估计项目相比有着更加优秀的精度-速度平衡。后续还会有基于 MMRazor 的剪枝、蒸馏和量化算法加入到 RTMPose 项目中,进一步强化轻量模型性能。

内测业务表现
RTMPose 自预热以来受到了社区的热烈关注,我们邀请了一批工业界的积极用户参与到内测中,以下是社区小伙伴在自己的公司业务数据和设备上试用后的反馈结果:
部署实测


业务性能数据
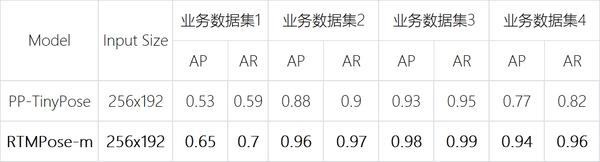

通过内测反馈可以看到,RTMPose 可以方便地部署到各种不同硬件上,在落地业务上更是直接带来了 十多个百分点的精度提升 ~
友好的上手教程
我们为用户准备了详细的中英文教程,手把手带领大家进行模型的训练、部署和推理,不论你是在 CPU、GPU还是手机端、Jetson 平台,使用的语言是 Python、C++ 还是 JAVA,都可以快速进行 RTMPose 的部署。

基于 MMDeploy 预编译包,用户可以省去复杂的环境配置与安装,快速感受 RTMPose 带来的极速体验。


致谢
感谢积极参与内测的社区小伙伴们(以下排名不分先后)。


(欢迎体验)