


都什么年代了,还有人在 MySQL 索引上碰一鼻子灰?

推荐阅读:
前言
索引有很多种,hash索引,B树索引,B+树索引,全文索引等。Mysql支持多种存储引擎,多种存储引擎对索引的支持也各不相同。本文探究Mysql为什么使用B+树来作为索引的数据结构,索引的原理已经Sql中索引的优化。
Mysql官方对索引的定义是:索引(Index)是帮助Mysql高效获取数据的数据结构。提取句子主干就是:索引是数据结构。
索引的原理
索引的目的
索引的目的在于提高查询或检索效率。例如我们要在字典中查询“mysql”这个单词,是不是先要查询m开头的单词表,然后在查询第二个字母为y的单词,然后缩小范围继续找,知道找到“mysql”这个单词为止或者查无此词。这就好像我们沿着一个树从树根开始找,沿着主干,树干,到最后的末梢,走了其中的一条路径。这比一个查询一个链表的结构,从头找到尾,在大多数情况下,效率要高得多。
Mysql的索引为什么是B+树
为什么不用普通的二叉树,这里就不必多说了,因为对于大的数据量,二叉树的高度太高,索引的效率低下。这里主要说明为什么不用B树( B-树就是B树 ),而是用B+树。
B树(B-树)介绍
我们都知道二叉树查询的时间复杂度为O(logN),查询效率已经够高了,但为什么还要有B树和B+树呢?答案是磁盘IO。我们都知道,IO操作的效率很低,当有存储的有很大的数据量,查询的时候,我们不可能把全部数据都加载到内存中,只能逐一加载磁盘页,每个磁盘页对应树的节点,造成大量的磁盘IO操作(最坏情况下,磁盘IO操作次数是树的高度),平衡二叉树由于树的高度太大造成磁盘IO读写过于频繁,从而导致效率低下,所以多路查找树-B树/B+树应运而生。
下面是一个三阶的B树(实际中节点元素很多)
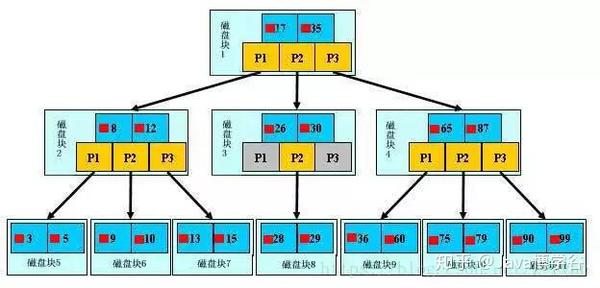

- B树有以下特点:在一个节点中存放着数据和指针,且相互间隔
- 在同一个节点中,key是增序的
- 如果一个节点最左边的指针不为空,则它指定的节点左右的key小于最左边的key。中间的指针指向的节点的key位于相邻两个key的中间。
- B树中不同节点存放的key和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中B树往往对每个节点申请同等大小的空间
- 每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d
B+树
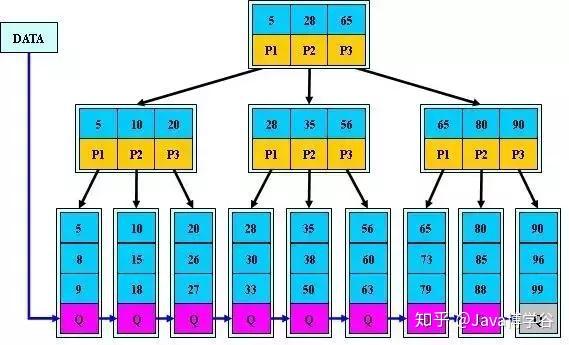

B+树有以下特点:
- 内节点不存储data,只存储key和指针,叶子结点不存储指针,只存储key和data
- 内节点和叶子结点的大小不同,因为存储的东西不同
- 每个非叶子结点的指针上限为2d而不是2d+1
- 因为节点内部没有data,所以有更多的空间放key,所以B+树的出度一般比B树要大,而对于一定的数据,出度大的话,树的深度就小,所以B+树的检索效率比B树高
为什么B+树比B树更适合Mysql索引
- B+树的磁盘读取代价低:因为B+树的非叶子结点没有存储数据,所以如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
- B+树的查询效率更稳定:由于B+树的分支结点并不是最终指向文件内容的结点,只是叶子结点的索引,所以任意关键字的查找都必须从根节点走向分支结点,查询路径相同。但B树的分支结点保存有数据,所以查询路径可能不同。
- B+树便于执行扫库操作:由于B+树的数据都存储在叶子节点上,分支节点均为索引,方便扫库,只需扫一遍叶子即可。但是B树在分支节点上都保存着数据,要找到具体的顺序数据,需要执行一次中序遍历来查找
Mysql的索引实现
我们知道Mysql有两种常用的存储引擎,MyISAM和InnoDB,这两种存储引擎对索引的实现方式是不同的。
MyISAM索引实现
MyISAM使用B+树作为索引的结构,叶子结点的data域存放的是数据记录的地址。


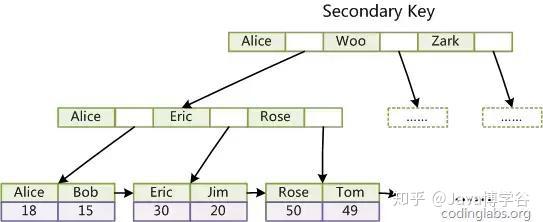
上图中是以Col1作为主键的MyISAM主索引的示意图。可以看到,组下面一层叶子结点的data域存放的是数据记录的地址。如果我们在字段Col2上建一个辅助索引,那么索引的结构如下:
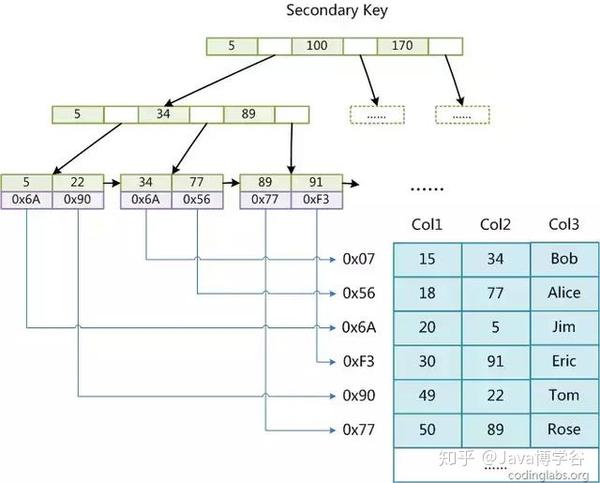

MyISAM索引检索算法是这样的,首先按照B+树的搜索算法查询索引,如果指定的key存在,则取出data域的值,然后用data域的地址查询数据记录。MyISAM的索引方式也叫“非聚集的”,跟InnoDB的“聚集索引”相区分,因为数据记录和索引不在一起。InnoDB索引实现
InnoDB的索引实现方式与MyISAM的索引实现方式的区别有两个:
第一,InnoDB的数据文件本身就是索引文件。在InnoDB中,数据文件本身就是按B+树组织的一个索引结构,而且是主索引结构。数据和索引在一起,叶子结点保存了完整的数据记录,这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
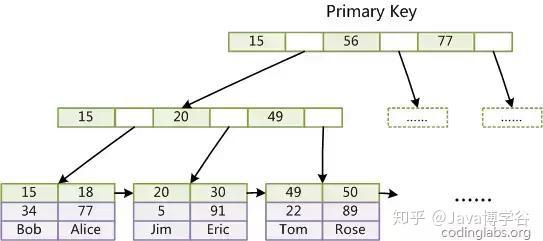

第二,InnoDB辅助索引的data域存储的是相应记录主键的值而不是地址。如图,下图是定义在Col3上的一个辅助索引的示意图。叶子结点存储了col3的值和对应的主键col1的值。

索引优化
墙裂建议使用自增主键
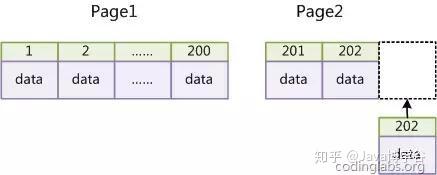
在使用InnoDB作为存储引擎时,如果没有特殊需要,请永远是用一个与业务无关的自增字段作为主键,而且这个字段长度不宜过大。为什么?InnoDB使用聚集索引,数据记录本身存放在主索引(B+树)的叶子结点上,这就要求同一个叶子结点(大小为一个内存页或磁盘页)的数据记录按主键顺序存放,每当一条新的记录插入时,mysql会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。如果使用自增主键,那么每次插入新的记录,记录就会顺序插入到当前节点的下一个位置。这样就会形成一个紧凑的索引结构,每次插入不需要移动已有数据,因此效率很高。如下图:

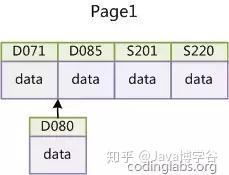
如果使用非自增主键(例如身份证号或学号这种无序字符串),每次插入主键近似随机,每次记录都要插入到现有索引页的中间的某个位置,这时不得不移动元素来完成插入,增加了开销。如下图:
索引的最左前缀原则
联合索引:mysql可以将多个列按照顺序作为一个索引,这种索引叫做联合索引。
索引的最左匹配原则是:假如索引列分别为A,B,C,顺序也是A,B,C,那么:
- 查询的时候,如果查询【A】,【A,B】,【A,B,C】,可以使用索引查询。
- 如果查询的时候,查询【A,C】,由于中间缺失了B,那么C这个索引是用不到的,只能用到A索引。
- 如果查询的时候,查询【B】,【B,C】或【C】,由于缺失了最左前缀A,那么是用不到这个联合索引的,除非有其他索引。
- 如果查询的时候使用范围查询,并且是最左前缀,那么可以用到索引,但是范围后面的字段无法用到索引。
这个原则可以结合索引的原理来理解:Mysql索引是B+树这种复合结构,当索引是联合索引,比如【name,age,sex】时,B+树是按照从左到右的顺序建立索引树的。当(张三,20,M)这样的数据来检索时,B+树会优先根据name来确定下一步的搜索方向,如果name相同再比较name和sex,最后得到检索的数据。但当(20,M)这样的数据来的时候,mysql就不知道该查哪个节点,因为建立索引的时候,name就是第一个比较因子,必须先根据name去确定下一步去哪里搜索。当(张三,M)这样的数据来时,可以根据name是“张三”,来确定下一步的搜索,然后再去匹配性别是“M”的数据,因此只能用到联合索引中name这个索引。
其他原则
1、尽量选择区分度高的列作为索引,区分度公式:count(distinct col)/count(*),表示字段不重复的比例,比例越大,我们扫描的记录数就越少,唯一性的列的区分度为1。这就是为什么不建议在状态,性别这样区分度很小的列上建立索引的原因。
2、索引列在sql语句中不能参与运算,否则会导致索引失效。例如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。应该改成create_time = unix_timestamp(’2014-05-29’);
3、联合索引比单个索引的性价比更高。例如,建立【A,B,C】这个联合索引,相当于建立了【A】,【A,B】,【A,B,C】这三个索引。这就要求我们尽量的扩展索引而不是新建索引,具体情况还需具体分析。
4、频繁进行查询的字段应该新建索引,与其他表进行关联的字段可以考虑新建索引,查询中排序的字段可以考虑建立索引以提高排序的效率(这里举个例子,很多时候查询记录希望按照创建时间倒序返回,通常有人会这样做order by create_time desc,但是如果create_time不是索引,而这个表有自增主键id,那么order by id desc返回结果一样,但是效率会提高)。
Mysql优化
导致sql执行慢的原因
1、硬件问题:如网络速度慢,内存不足,I/O吞吐量小,磁盘空间满了等。
2、没有使用索引或者索引失效。
3、数据过多(分库分表)。
4、服务器或参数设置不当。
分析解决慢sql方法
1、先观察,开启慢查询日志,设置相应的阈值(比如超过3秒就是慢sql),再生产环境跑个一天,看看哪些sql比较慢。
2、explain和慢sql分析,比如sql语句写的不好,没有使用索引或者索引失效,或者sql语句太过复杂,关联查询和嵌套子查询太多等等。
3、Show Profile是比explain更近一步的执行细节,可以查询到执行每一个SQL都干了什么事,这些事分别花了多少秒。
4、找DBA或者运维对Mysql进行服务器的参数调优。
配置优化
基本配置
- innodb_buffer_pool_size:这是安装完InnoDB后第一个应该设置的选项。缓冲池是数据和索引缓存的地方:这个值越大越好,这能保证你在大多数的读取操作时使用的是内存而不是硬盘。典型的值是5-6GB(8GB内存),20-25GB(32GB内存),100-120GB(128GB内存)。
- innodb_log_file_size:这是redo日志的大小。redo日志被用于确保写操作快速而可靠并且在崩溃时恢复。一直到MySQL 5.5,redo日志的总尺寸被限定在4GB(默认可以有2个log文件)。这在MySQL5.6里被提高了。如果你知道你的应用程序需要频繁的写入数据并且你使用的时MySQL5.6,一开始就可以设置成4G。
- max_connections:如果你经常看到'Too many connections'错误,是因为max_connections的值太低了因为应用程序没有正确的关闭数据库连接,你需要比默认的151连接数更大的值。max_connection值被设高了(例如1000或更高)之后一个主要缺陷是当服务器运行1000个或更高的活动事务时会变的没有响应。
InnoDB配置
- innodb_file_per_table:这项设置告知InnoDB是否需要将所有表的数据和索引存放在共享表空间里(innodb_file_per_table = OFF) 或者为每张表的数据单独放在一个.ibd文件(innodb_file_per_table = ON)。每张表一个文件允许你在drop、truncate或者rebuild表时回收磁盘空间。这对于一些高级特性也是有必要的,比如数据压缩。你不想让每张表一个文件的主要场景是:有非常多的表(比如10k+)。
- innodb_flush_log_at_trx_commit:默认值为1,表示InnoDB完全支持ACID特性。当你的主要关注点是数据安全的时候这个值是最合适的,比如在一个主节点上。但是对于磁盘(读写)速度较慢的系统,它会带来很巨大的开销,因为每次将改变flush到redo日志都需要额外的fsyncs。将它的值设置为2会导致不太可靠(reliable)因为提交的事务仅仅每秒才flush一次到redo日志,但对于一些场景是可以接受的,比如对于主节点的备份节点这个值是可以接受。
- innodb_flush_method:这项配置决定了数据和日志写入硬盘的方式。一般来说,如果你有硬件RAID控制器,并且其独立缓存采用write-back机制,并有着电池断电保护,那么应该设置配置为O_DIRECT;否则,大多数情况下应将其设为fdatasync(默认值)
- innodb_log_buffer_size:这项配置决定了为尚未执行的事务分配的缓存。其默认值(1MB)一般来说已经够用了,但是如果你的事务中包含有二进制大对象或者大文本字段的话,这点缓存很快就会被填满并触发额外的I/O操作。
执行计划Explain
准备数据
CREATE TABLE `user_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL DEFAULT '',
`age` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_index` (`name`)
)ENGINE = InnoDB DEFAULT CHARSET = utf8;
INSERT INTO user_info (name, age) VALUES ('xys', 20);
INSERT INTO user_info (name, age) VALUES ('a', 21);
INSERT INTO user_info (name, age) VALUES ('b', 23);
INSERT INTO user_info (name, age) VALUES ('c', 50);
INSERT INTO user_info (name, age) VALUES ('d', 15);
INSERT INTO user_info (name, age) VALUES ('e', 20);
INSERT INTO user_info (name, age) VALUES ('f', 21);
INSERT INTO user_info (name, age) VALUES ('g', 23);
INSERT INTO user_info (name, age) VALUES ('h', 50);
INSERT INTO user_info (name, age) VALUES ('i', 15);
CREATE TABLE `order_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`user_id` BIGINT(20) DEFAULT NULL,
`product_name` VARCHAR(50) NOT NULL DEFAULT '',
`productor` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
)ENGINE = InnoDB DEFAULT CHARSET = utf8;
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p2', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'DX');