


应工作需求,up在本地搭建了ChatGLM3-6B大语言模型,搭建过程遇到不少问题,踩了不少坑,幸亏网上有许多大佬写的经验分享,让我最终得以搭建成功,故写此经验分享,希望能帮到更多人。

部署前准备
python安装:
建议安装Python 3.11,3.12貌似不稳定。官网下载安装即可:https://www.python.org/downloads/windows/
cuda安装:
ChatGLM3依赖于pytorch深度学习框架,pytorch(GPU版本)借助cuda调用GPU提高计算性能。 ChatGLM3要求torch版本>=2.1.0,对应的cuda版本需>=11.8。 在终端输入命令:nvidia-smi 查看自己gpu最大支持哪个版本cuda:
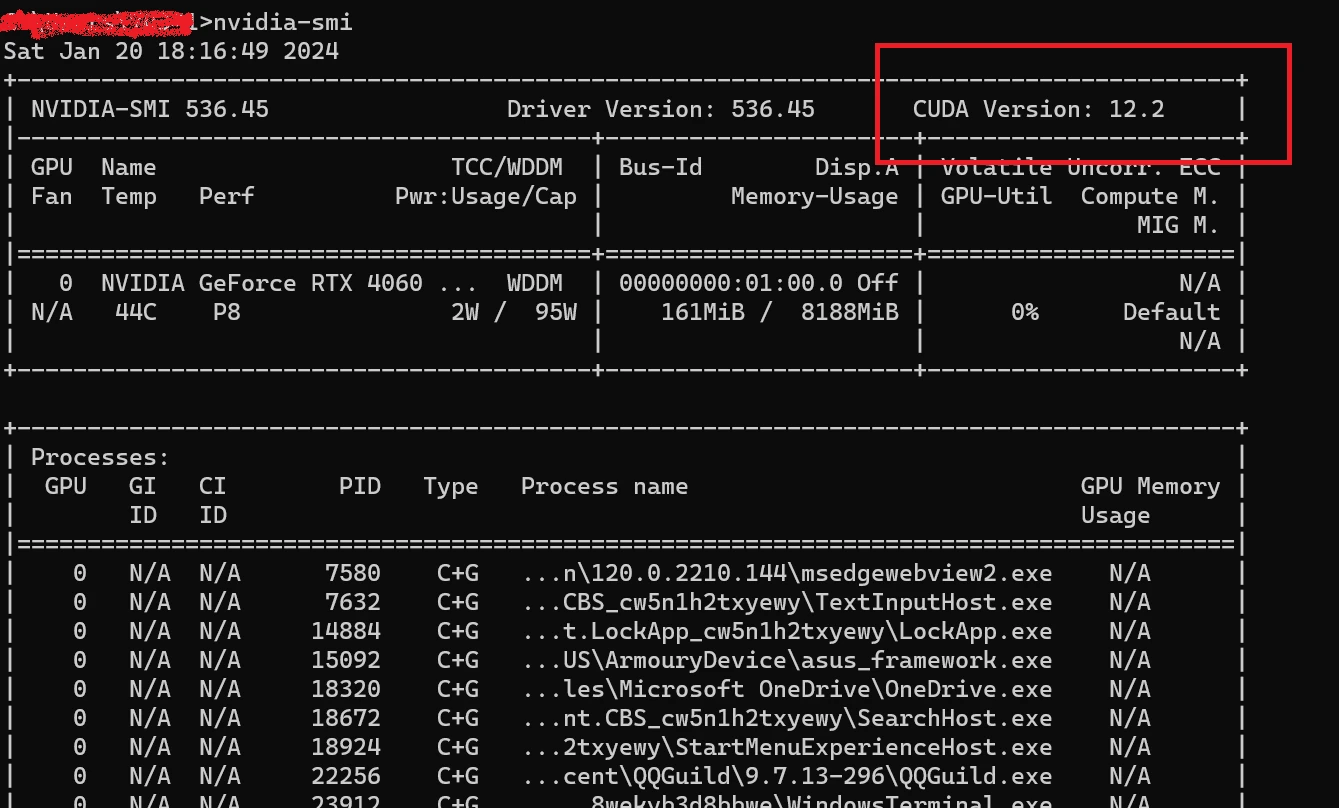
如果支持的最大版本低于11.8,可以先去NVIDIA官网更新显卡驱动,再输入该命令查看。up准备装的是cuda12.1,从cuda官网直接下载安装即可:https://developer.nvidia.com/cuda-toolkit-archive 记住cuda装的位置
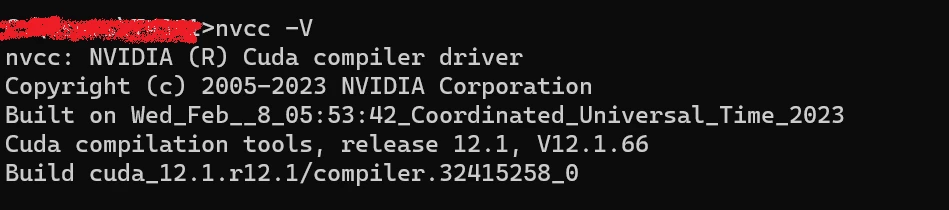
安装完毕后,终端输入nvcc -V,出现类似下图结果代表安装成功。
cuDNN安装:
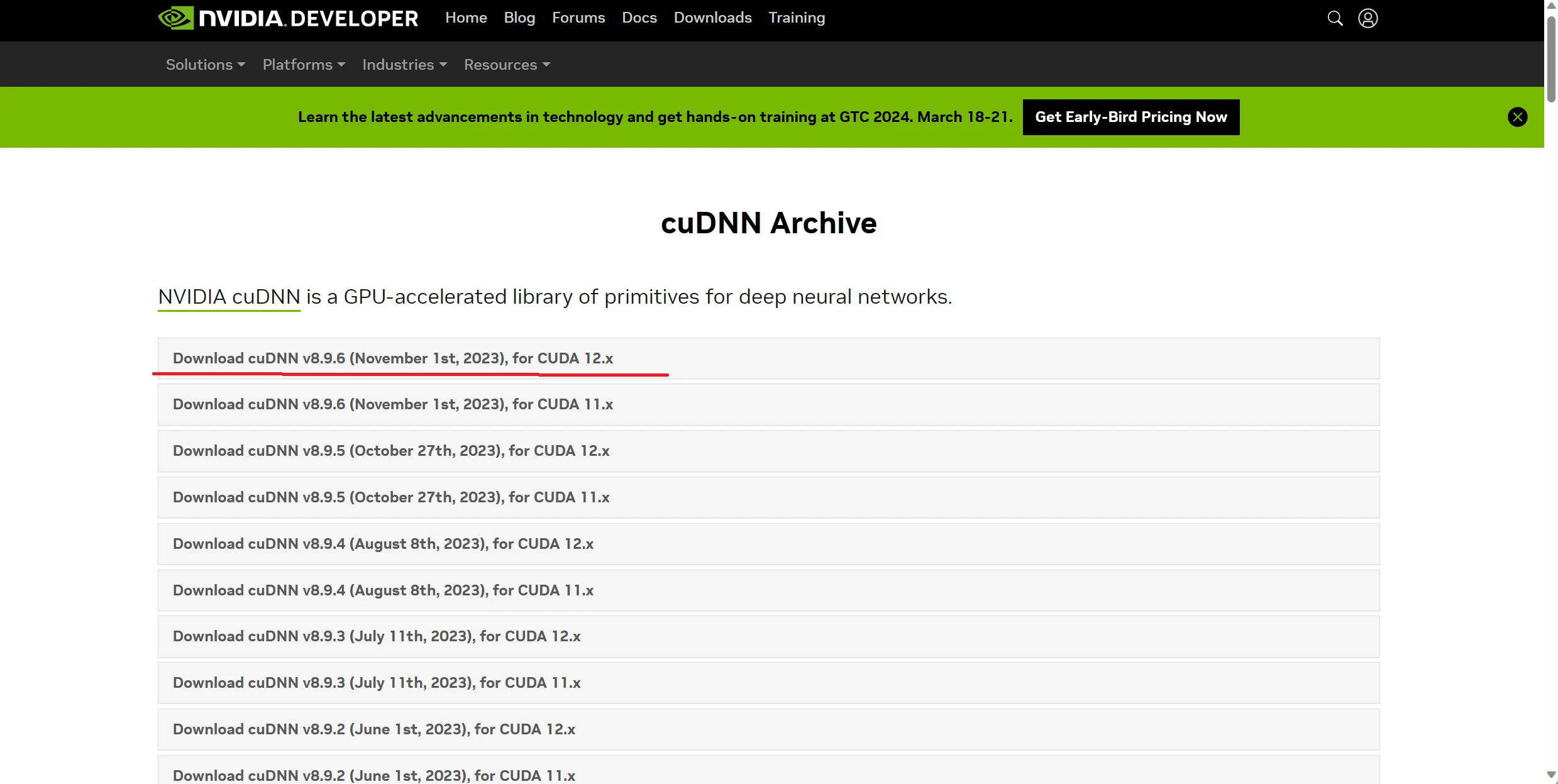
基于cuda的深度神经网络GPU加速库,官网:https://developer.nvidia.com/rdp/cudnn-archive
下载前要先用NVIDIA账号登陆,没有可以注册一个, 注意要与刚下的cuda版本对应
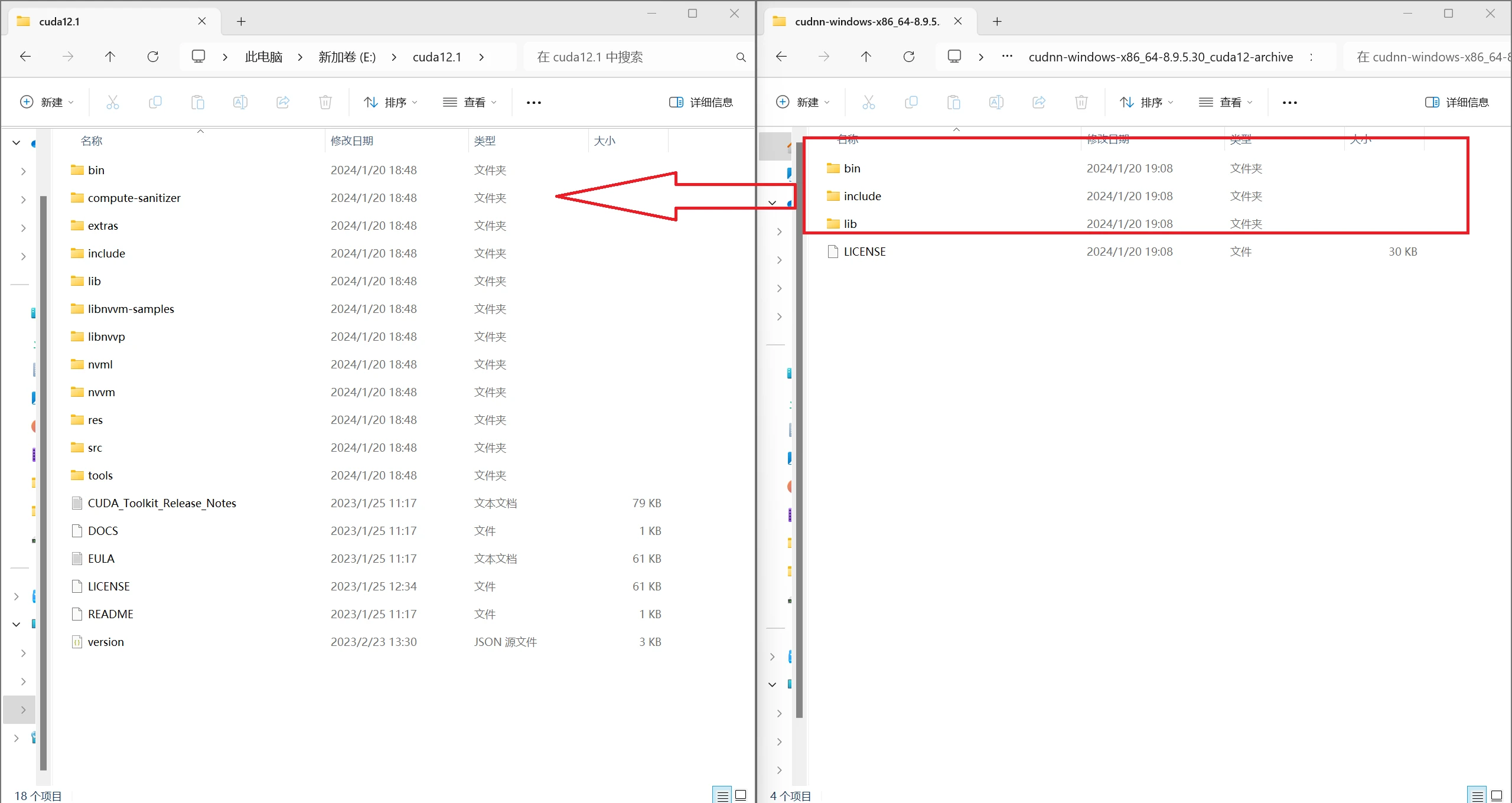
下载完是一个zip包, 解压后把bin、include、lib这三个文件夹拷贝至刚刚安装的cuda目录下
模型部署
在GitHub上下载源码:https://github.com/THUDM/ChatGLM3
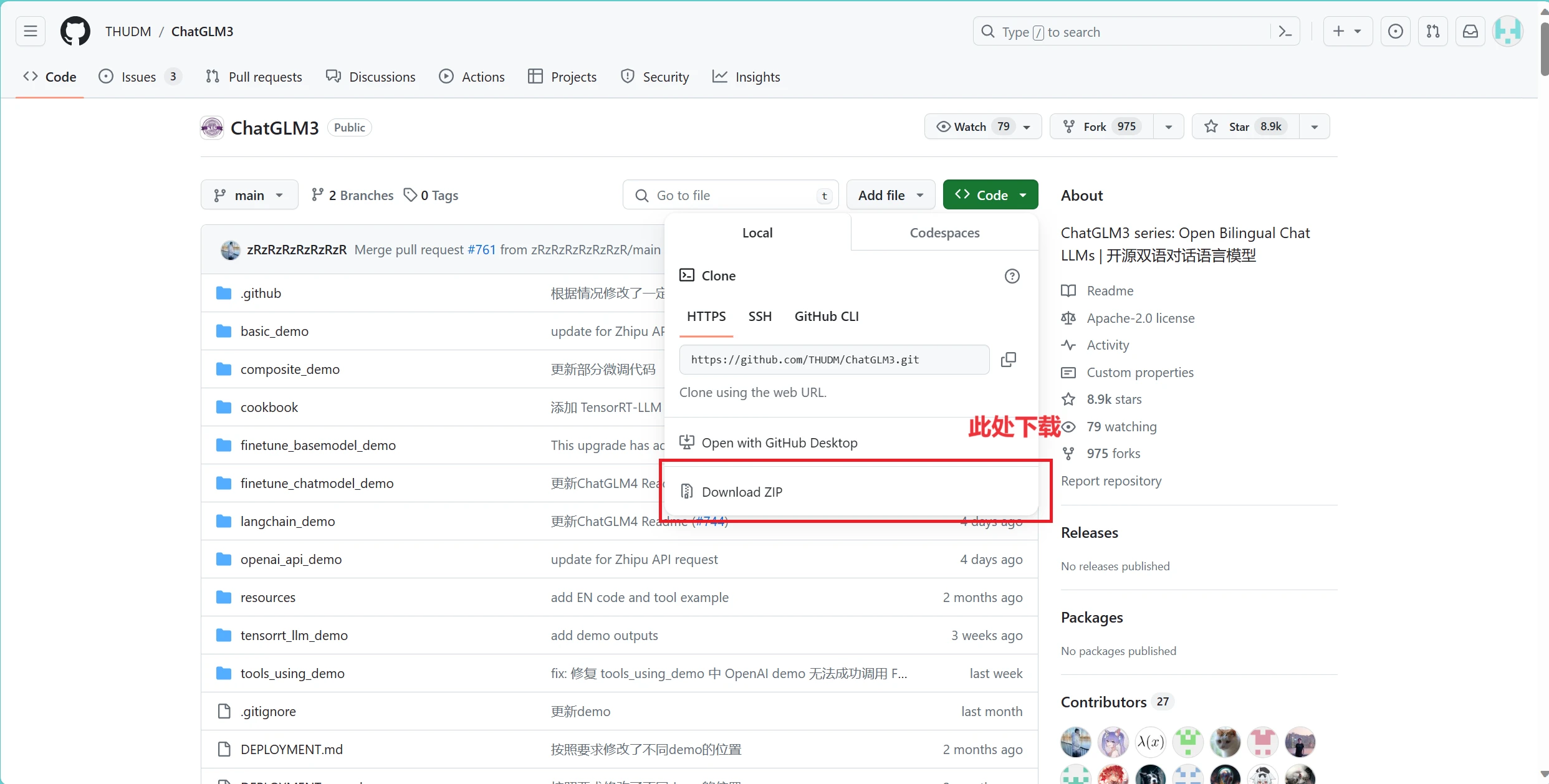
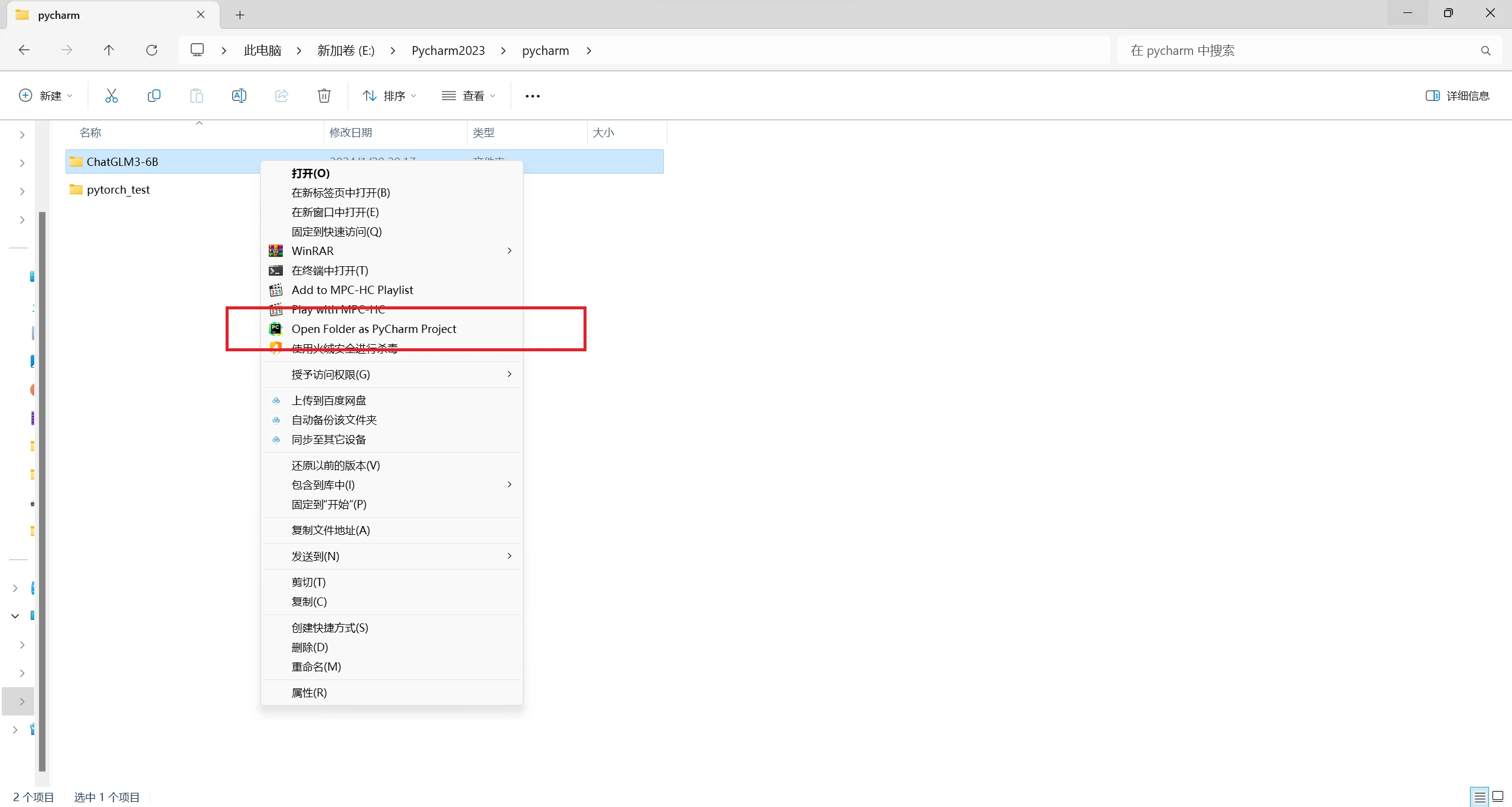
下载到本地后右键单击,选则用Pycharm打开此文件夹
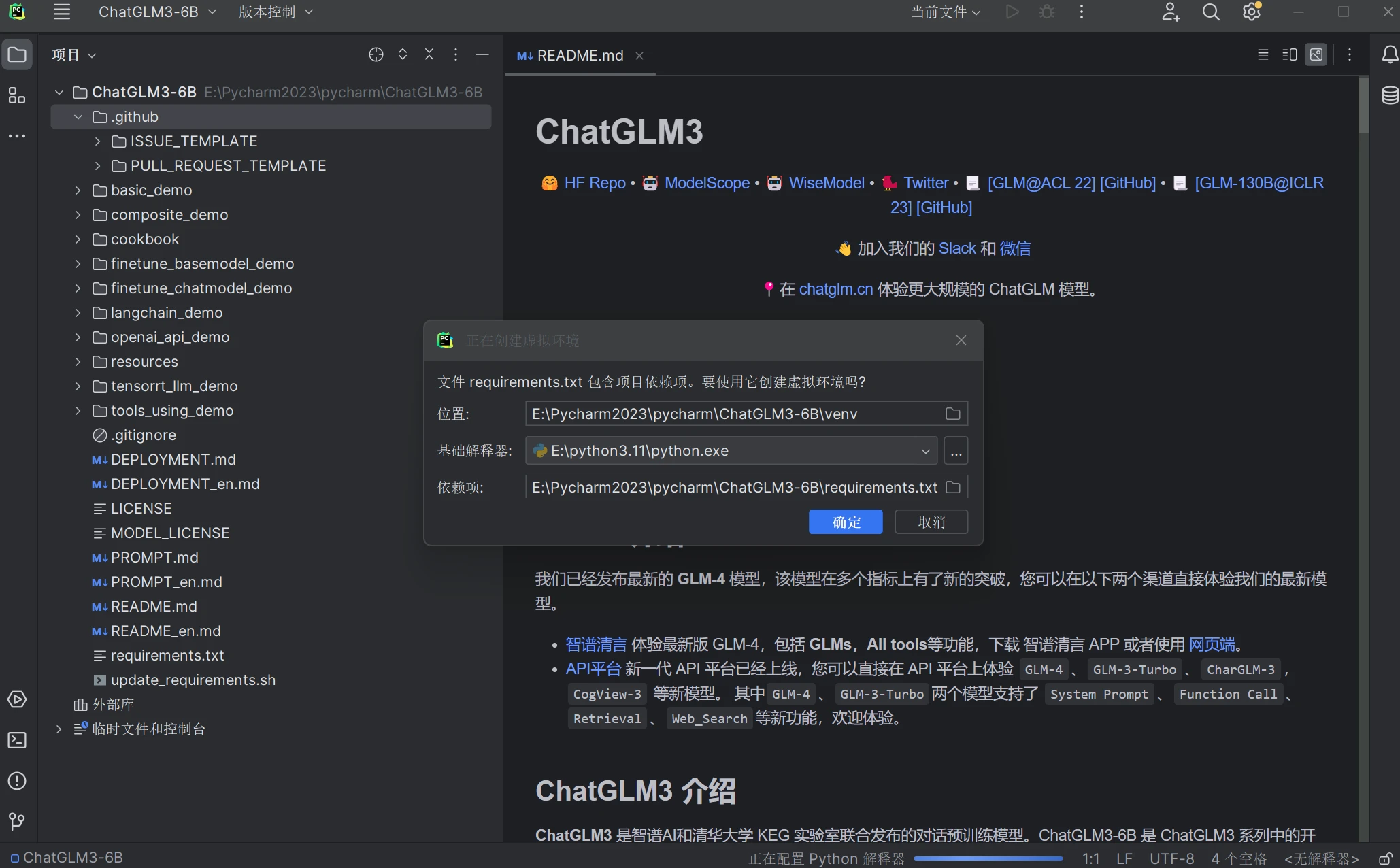
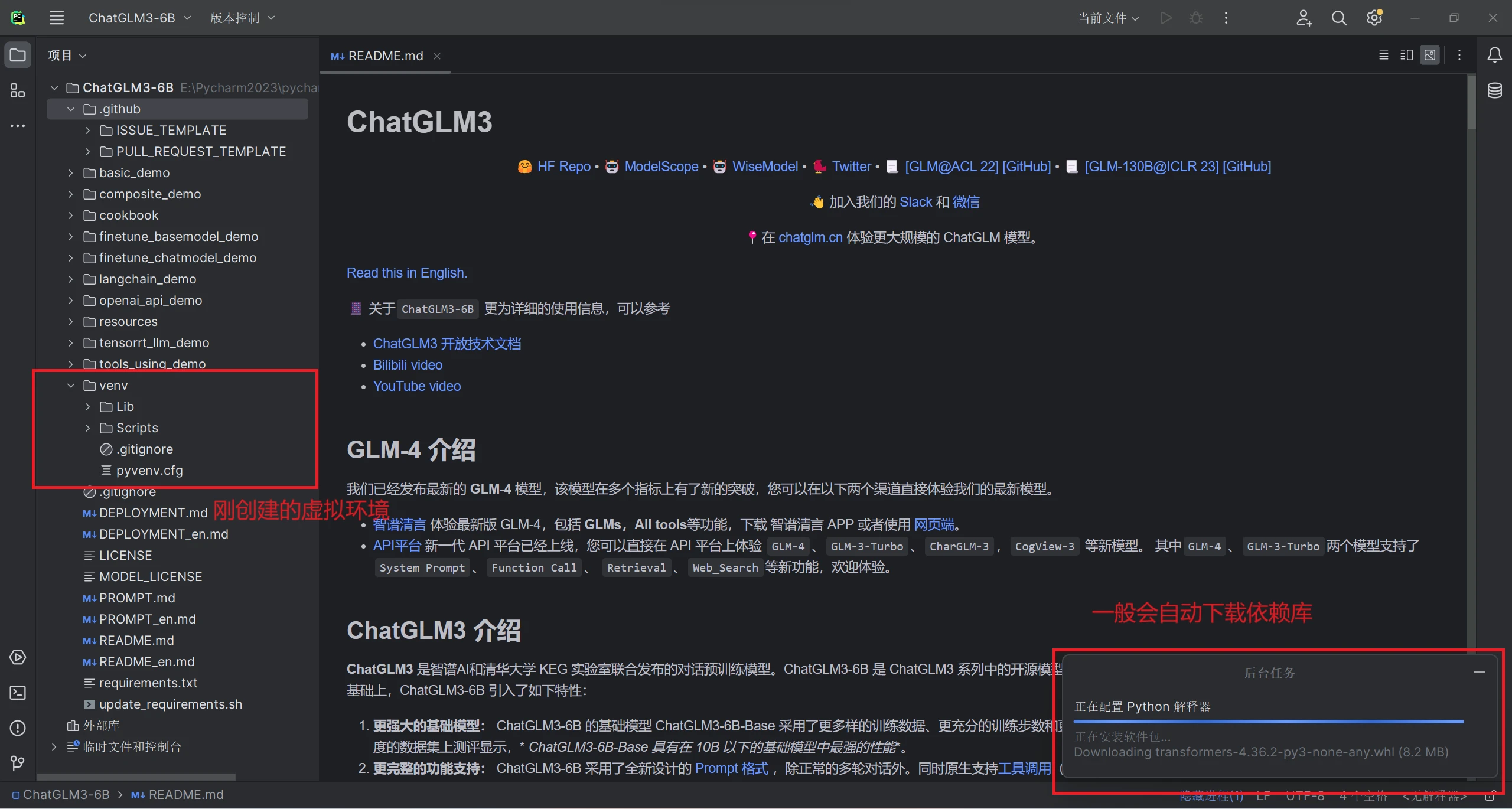
打开后Pycharm会提醒是否使用 requirements.txt(文档为该项目的依赖库)创建虚拟环境,点击确定创建后会在虚拟环境中自动安装 requirements.txt 中列出的库(建议在虚拟环境而非本地环境安装这些库)
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='E:\chatglm3_model')
如果自动安装速度很慢或没有自动安装,在Pycharm打开终端使用清华源镜像手动安装:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后新建个python脚本导入torch库,检查下 torch.cuda.is_available() 输出,如果为True证明安装的是GPU版本torch,否则是CPU版本,建议安装GPU版本
接着下载模型,模型优先发布在Hugging Face上,地址:https://huggingface.co/THUDM/chatglm3-6b
不翻墙下载速度很慢,也可以从ModelScope(魔搭社区)下载,地址:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
此处以魔搭社区为例,新建一个python脚本,输入如下两行命令:

from modelscope import snapshot_download
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='E:\chatglm3_model')
参数cache_dir是模型下载的位置,可以依需求自行修改。当然需要先用pip安装modelscope这个库。
如果不事先下载好模型,后续运行代码时会自动从Hugging Face下载模型(可能要翻墙),且会自动下载到C盘(直接把up C盘干爆了)
运行模型
以下介绍三个运行模型的demo,更多运行方式可以参考官方文档https://github.com/THUDM/ChatGLM3
命令行对话:
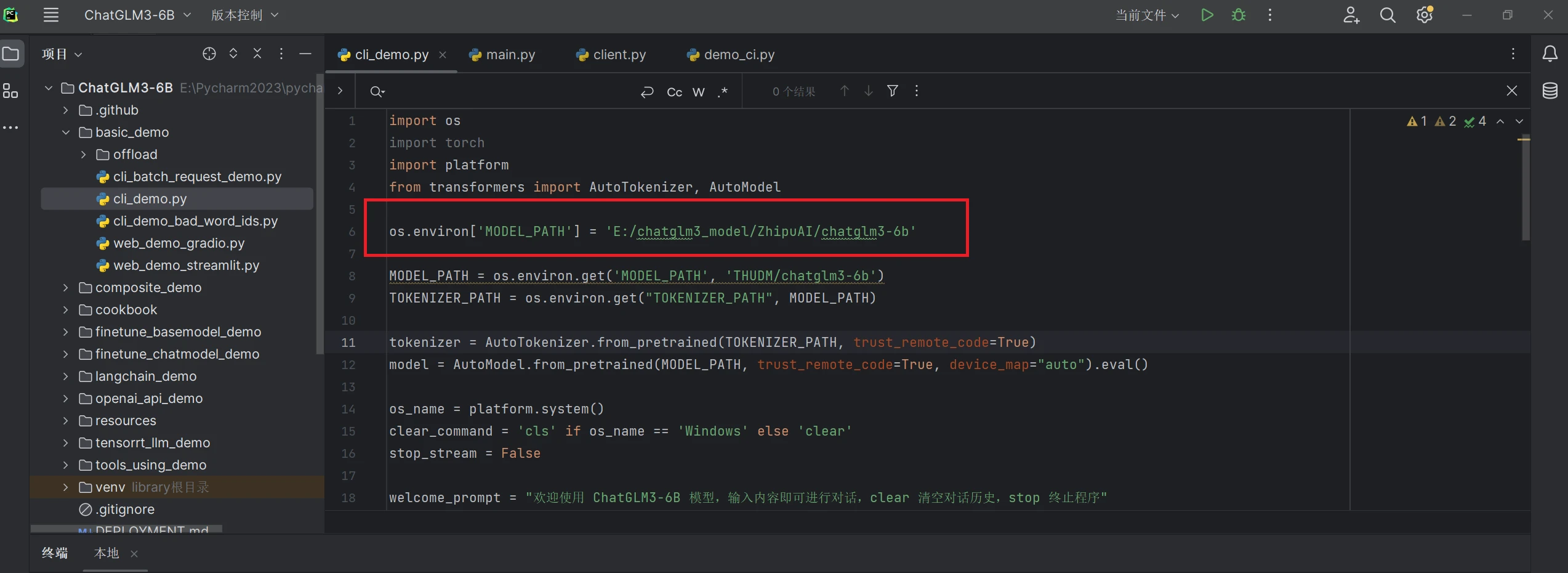
打开basic_demo下的cli_demo.py文件,把模型在本地路径添加到环境变量中,加一行代码即可(如果不添加运行会从Hugging Face下载模型)
up这里运行时报错
ValueError
:
The current `device_map` had weights offloaded to the disk
.
Please provide an `offload_folder`
for
them
.
大概是因为GPU或CPU内存不够导致,参照Hugging Face上大佬给出的解决办法,修改加载模型的代码
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto", offload_folder="offload", torch_dtype=torch.float16).eval()
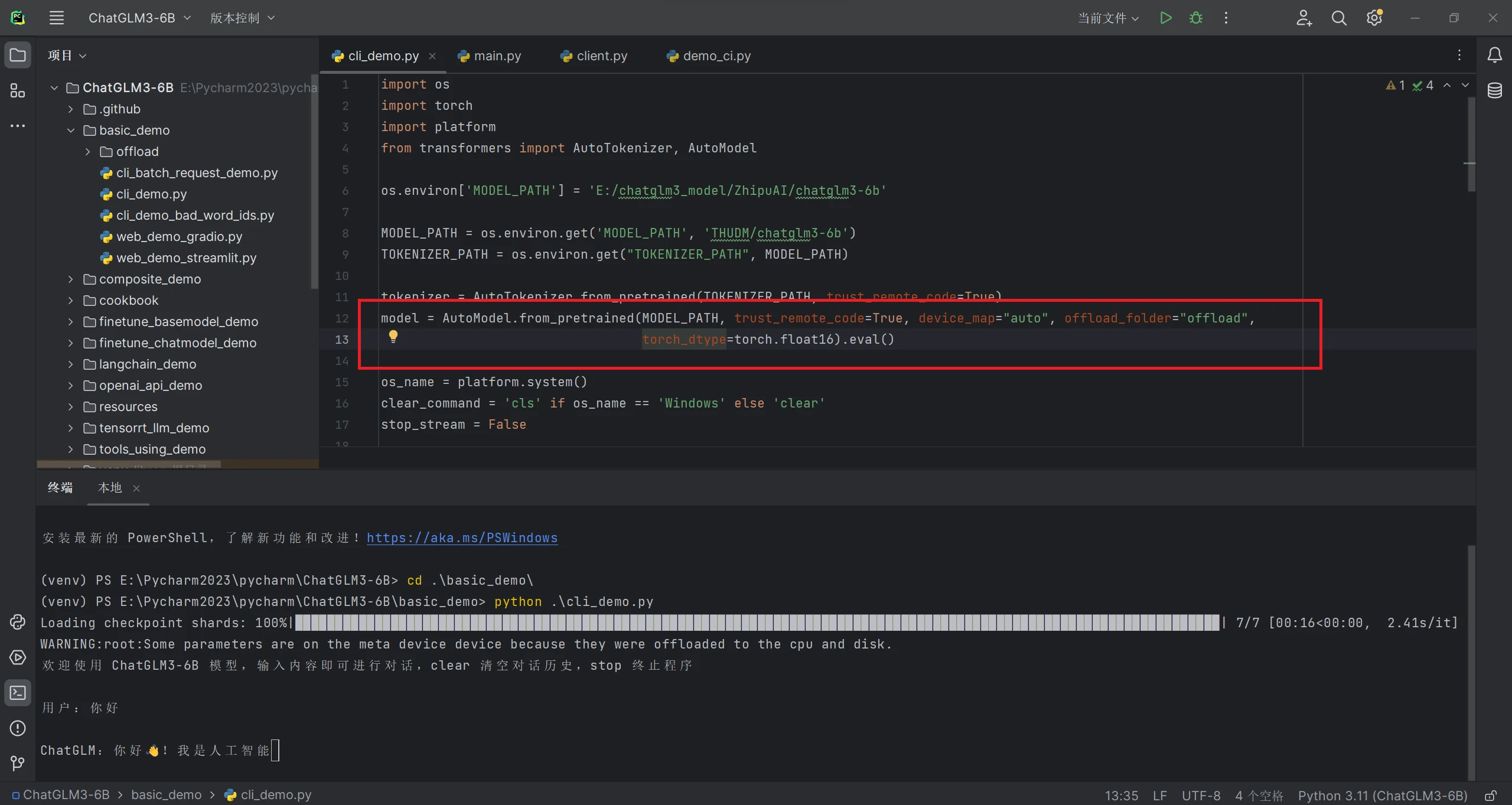
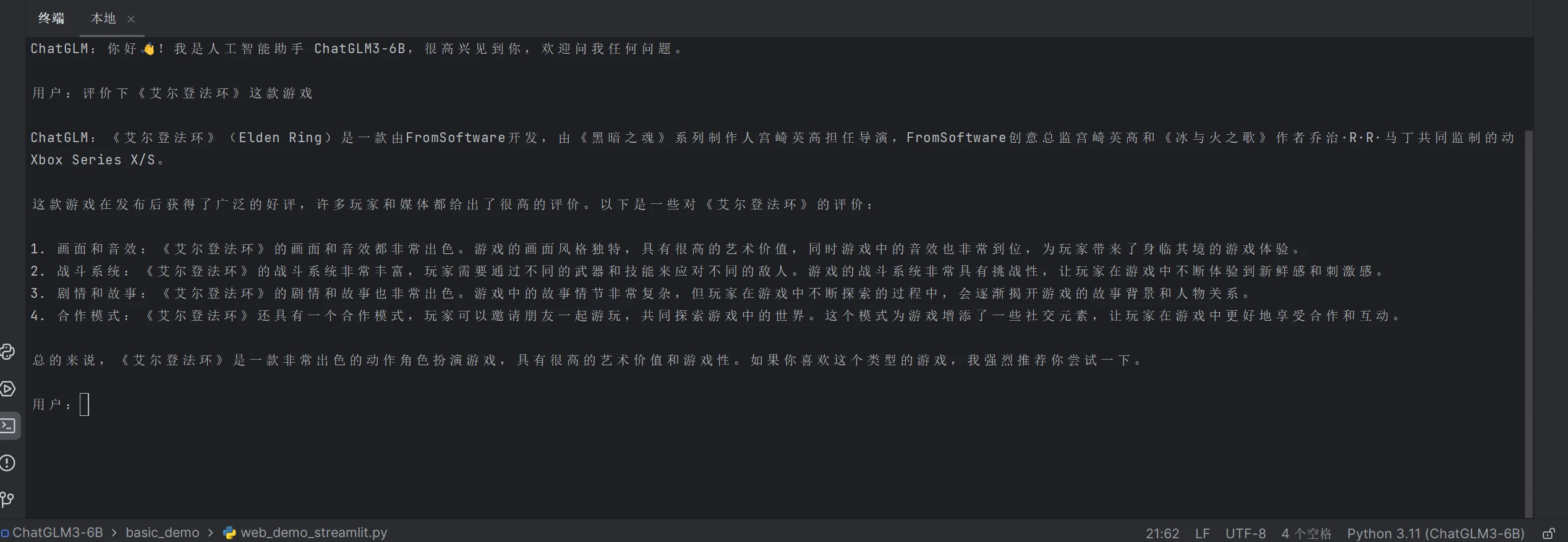
终端输入python cli_demo.py 运行代码,可以在终端与其对话,看看AI怎么评价老头环
借助streamlit工具在网页端对话:
打开basic_demo下的web_demo_streamlit.py文件,和cli_demo.py文件一样,把模型路径加到环境变量中, 该文件中加载模型代码在函数get_model()中 。 终端输入指令
streamlit run web_demo_streamlit.py
运行成功后会打开一个网页,在对话框输入问题即可
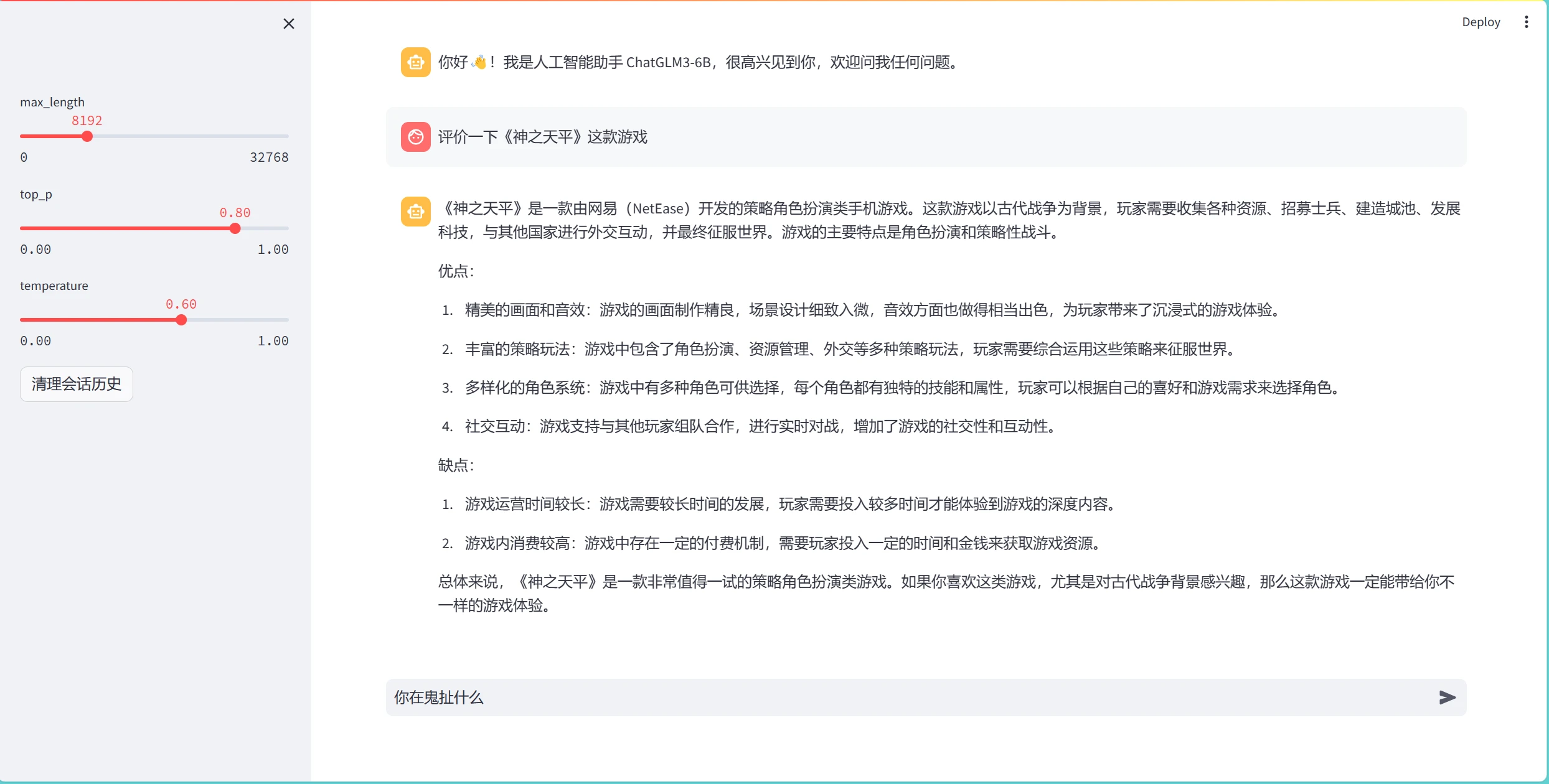
冷知识:《神之天平》是网易开发的手游~
综合demo:
这个demo集成了对话、工具调用和代码解释器三种功能。代码解释器功能需要Jupyter内核。命令行输入 pip install jupyter 安装。
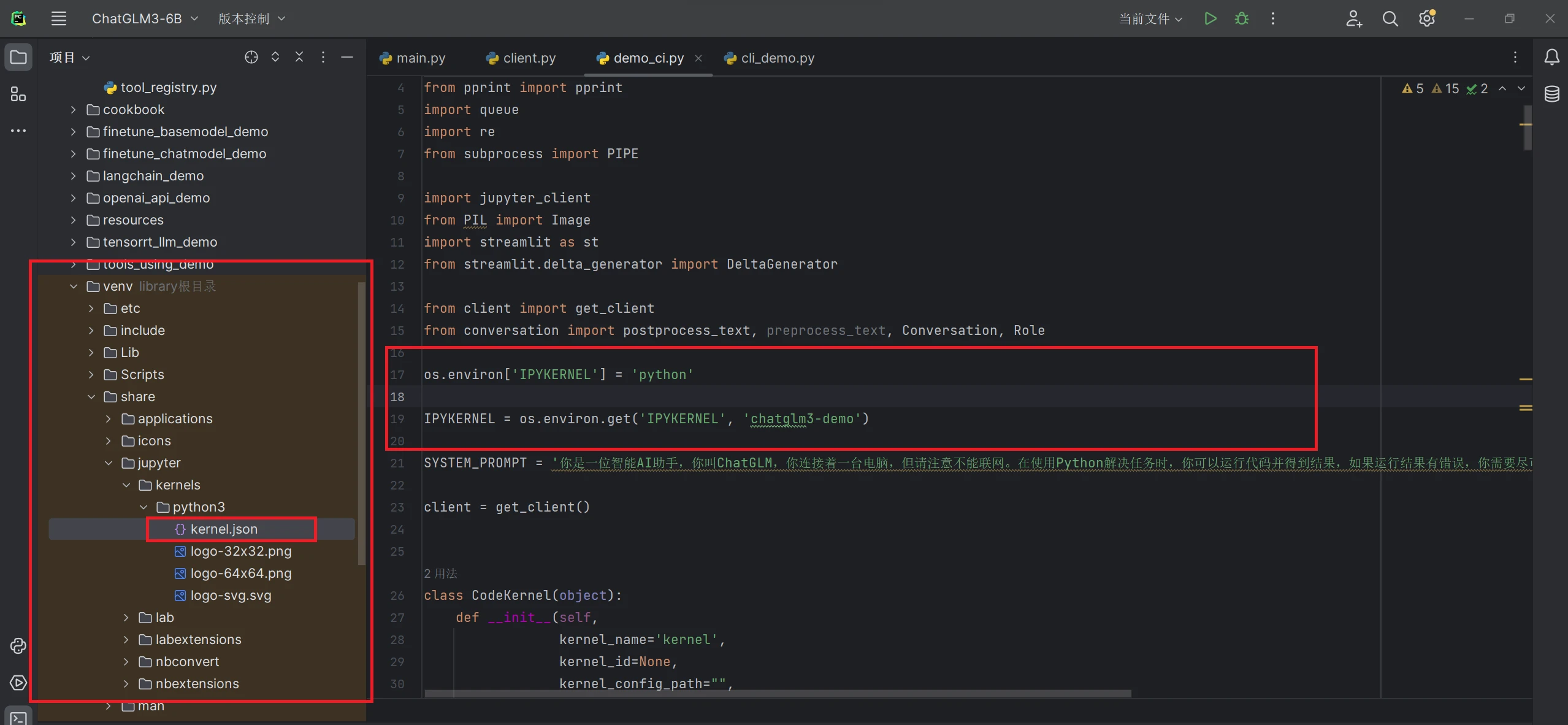
安装完成后,打开composite_demo路径下的demo_ci.py文件,加一行代码用来加载IPYKERNEL内核(IPYKERNEL是Jupyter运行Python3代码的内核)
os.environ['IPYKERNEL'] = 'python'
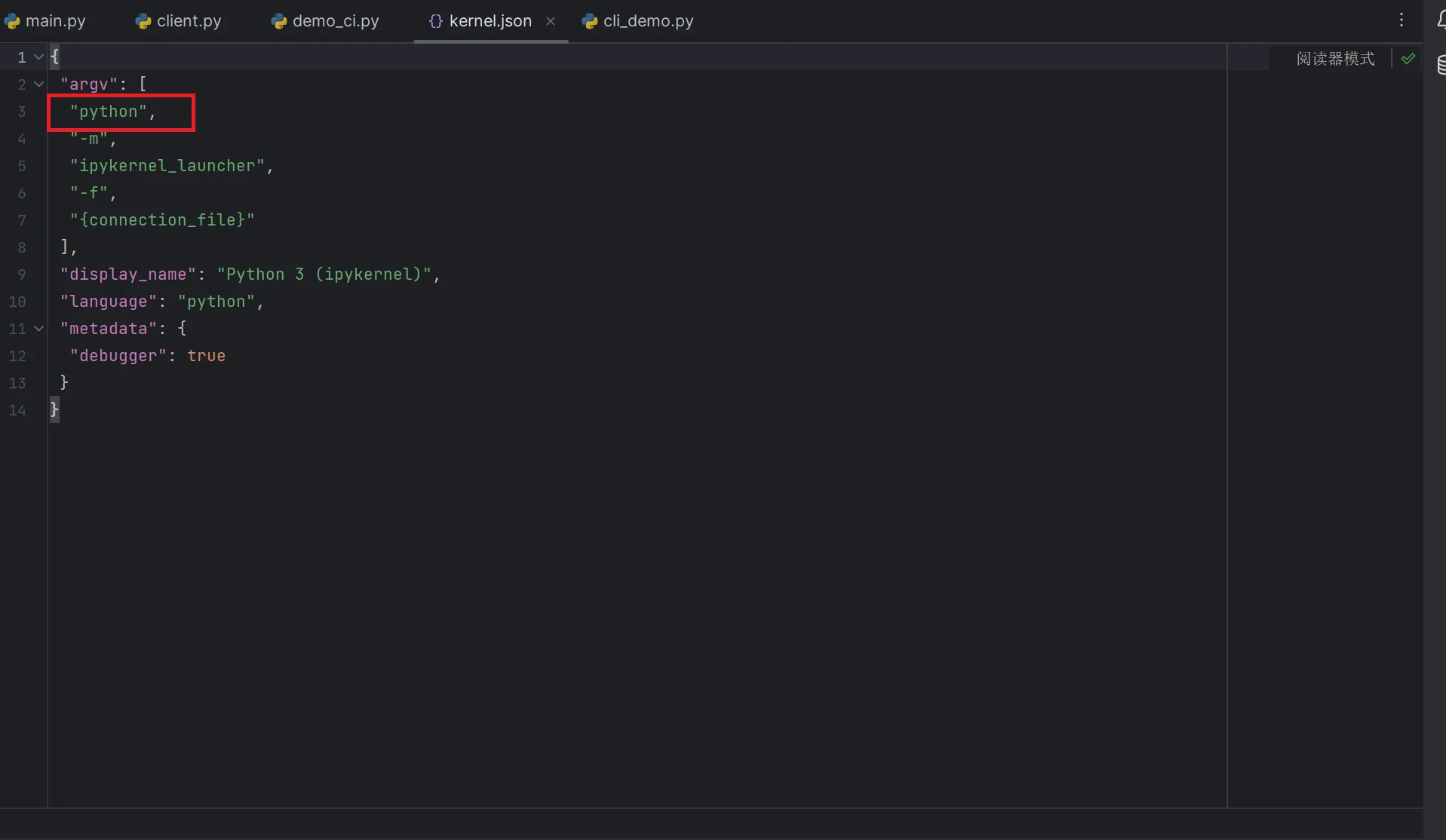
’python‘是内核名字,可以在venv/share/jupyter/python3/kernel.json查看你的jupyter内核名
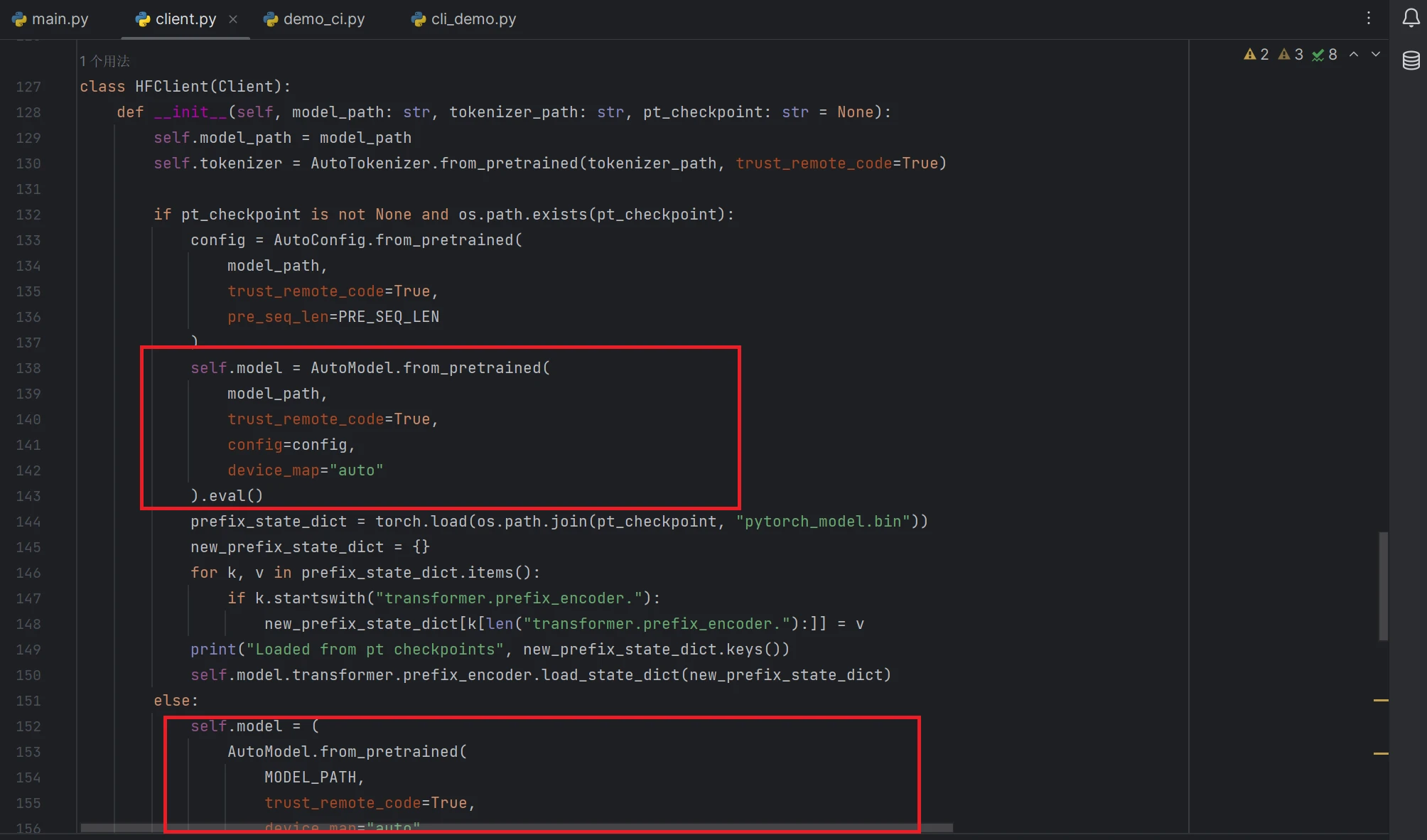
接着打开composite_demo下client.py,同以往一样将模型路径加到环境变量里,接着在该文件中找到HFClient类,可以看到里面有加载模型对应的命令,如果前面运行有跟我一样报错的话,改下第二个红框里代码即可,第一个红框应该是加载微调后的模型对应的代码
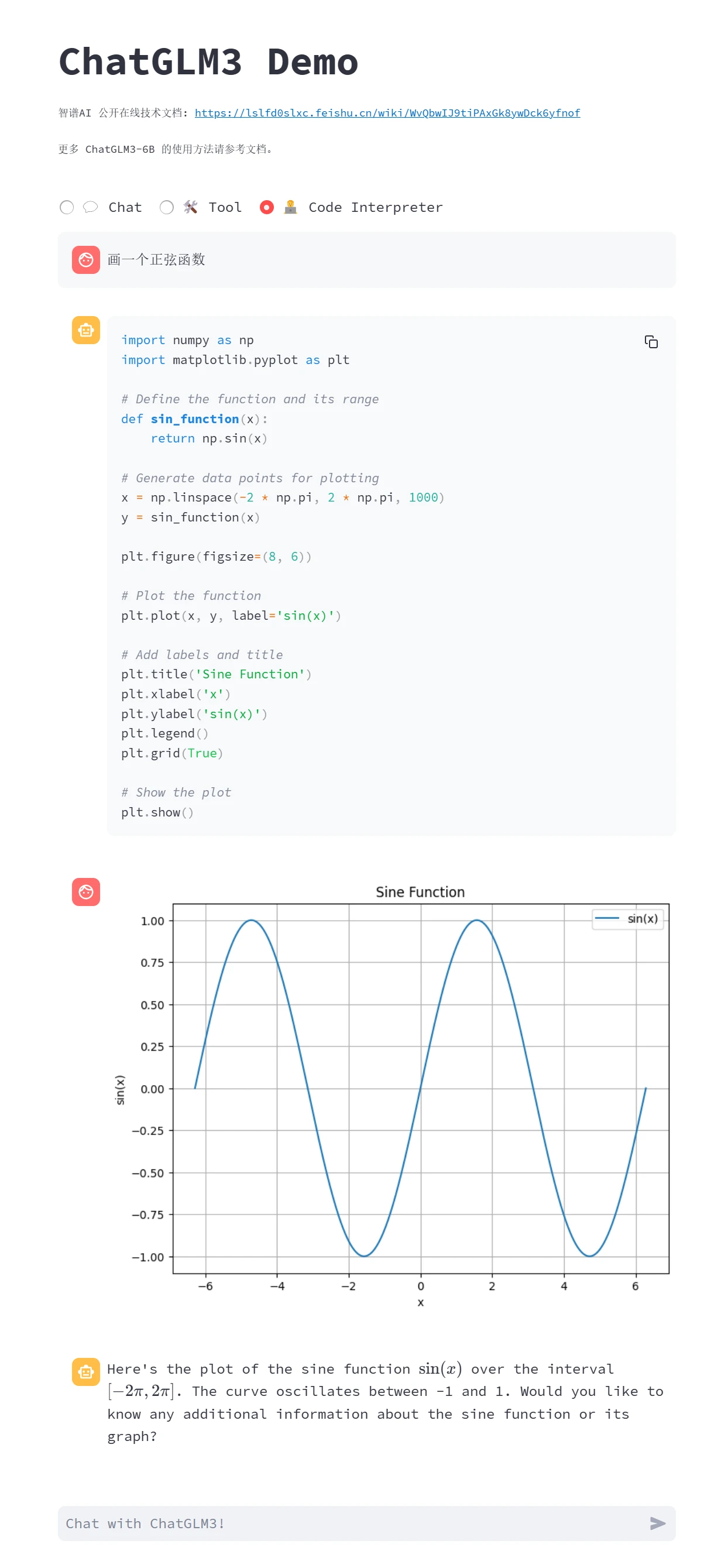
用streamlit运行目录下的main.py文件 streamlit run main.py
运行成功后会打开一个网页,选则Code Interpreter功能,在此功能性,模型能够写python脚本并且运行,同时也可以运行用户自己写的python脚本
模型量化
在官方文档中提到了
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型
以命令行对话为例,找到加载模型的代码(前文已提到不同demo下该代码的位置),修改其为

记得要将device_map="auto"去掉 , quantize中参数4也可改为8,本人笔记本4060显卡在4-bit量化后能够流畅运行,但模型输出效果也会差一些,毕竟硬件太拉。。。
至此已经完成了ChatGLM3本地部署,如果想让模型侧重于某方面应用,后续还需要微调。
参考的网上文章:
https://github.com/THUDM/ChatGLM3
https://blog.csdn.net/xi5214/article/details/134879703
https://blog.csdn.net/itorac/article/details/134599146
https://huggingface.co/blog/accelerate-large-models