你可以使用 Python 的正则表达式来实现这个功能。首先,你需要导入 Python 的 re 模块,然后使用 re.findall 函数来查找所有包含多个关键词的句子。
例如,如果你想在文档中查找所有包含 "keyword1" 和 "keyword2" 的句子,你可以使用以下代码:
import re
# 读取文档内容
with open('document.txt', 'r') as f:
文章目录一、需求二、分析及思路三、整体代码
根据关键词,从Word文档里的表格中提取所需要的数据汇总到Excel中,并汇总到Excel中做台帐。
二、分析及思路
常规表格中,我们一般会通过横向填写或者竖向填写的方式来进行内容的填写,有些单元格还会有合并的情况,如下图所示,通过 python 的 docx 模块,可以完成 word 文档的信息提取:
2.1 遍历文件夹中,需要提取的 docx 文件(这里最好是把将要提取的文件放在一个文件夹中)
2.2 通过 docx 模块里面的 table 方法,
可以使用Python的第三方库python-docx和openpyxl来实现。首先使用python-docx读取word文档,然后找到表格内容并提取,最后使用openpyxl将表格内容保存到excel中。具体实现可以搜索相关教程或者使用以下代码作为参考:
```python
import docx
from openpyxl import Workbook
# 打开word文档
doc = docx.Document('example.docx')
# 创建一个excel文件
wb = Workbook()
ws = wb.active
# 遍历文档中的表格
for table in doc.tables:
# 遍历表格中的行
for i, row in enumerate(table.rows):
# 创建一个excel的行
excel_row = []
# 遍历行中的单元格
for cell in row.cells:
# 将单元格的内容添加到excel_row列表中
excel_row.append(cell.text)
# 在excel中插入一行数据
ws.append(excel_row)
# 保存excel文件
wb.save('example.xlsx')
注意:以上代码只能提取简单的表格,如果表格中包含合并单元格或者其他复杂的格式,可能需要进行额外的处理。



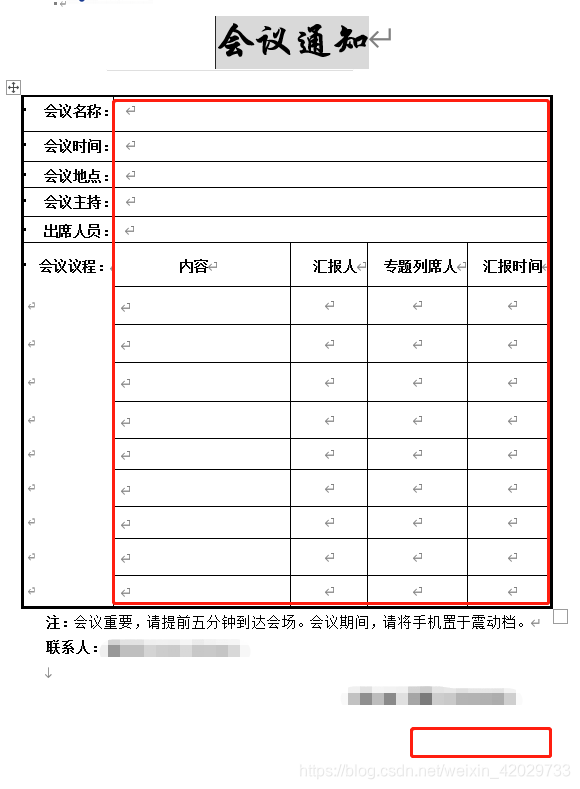
 ,公司让我开发一个自动取数脚本,各种不兼容把我搞死
,公司让我开发一个自动取数脚本,各种不兼容把我搞死