

从 C++20 标准来看 memory order

转载自:
memory order 是什么?
所以首要的问题是 memory order 是什么? 以及为啥 c++ 要引入 memory order? 首先来看一个场景: 现在有线程 A, B; A 作为生产者, 其会负责某个对象 obj 的初始化工作, 在完成初始化之后, 设置 flag ready 告诉消费者 B, 对象准备就绪, 可以使用了. 用 mutex 实现如下:
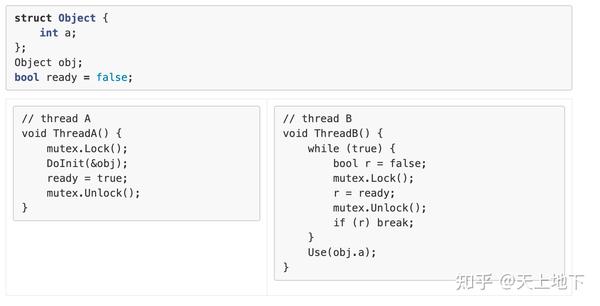
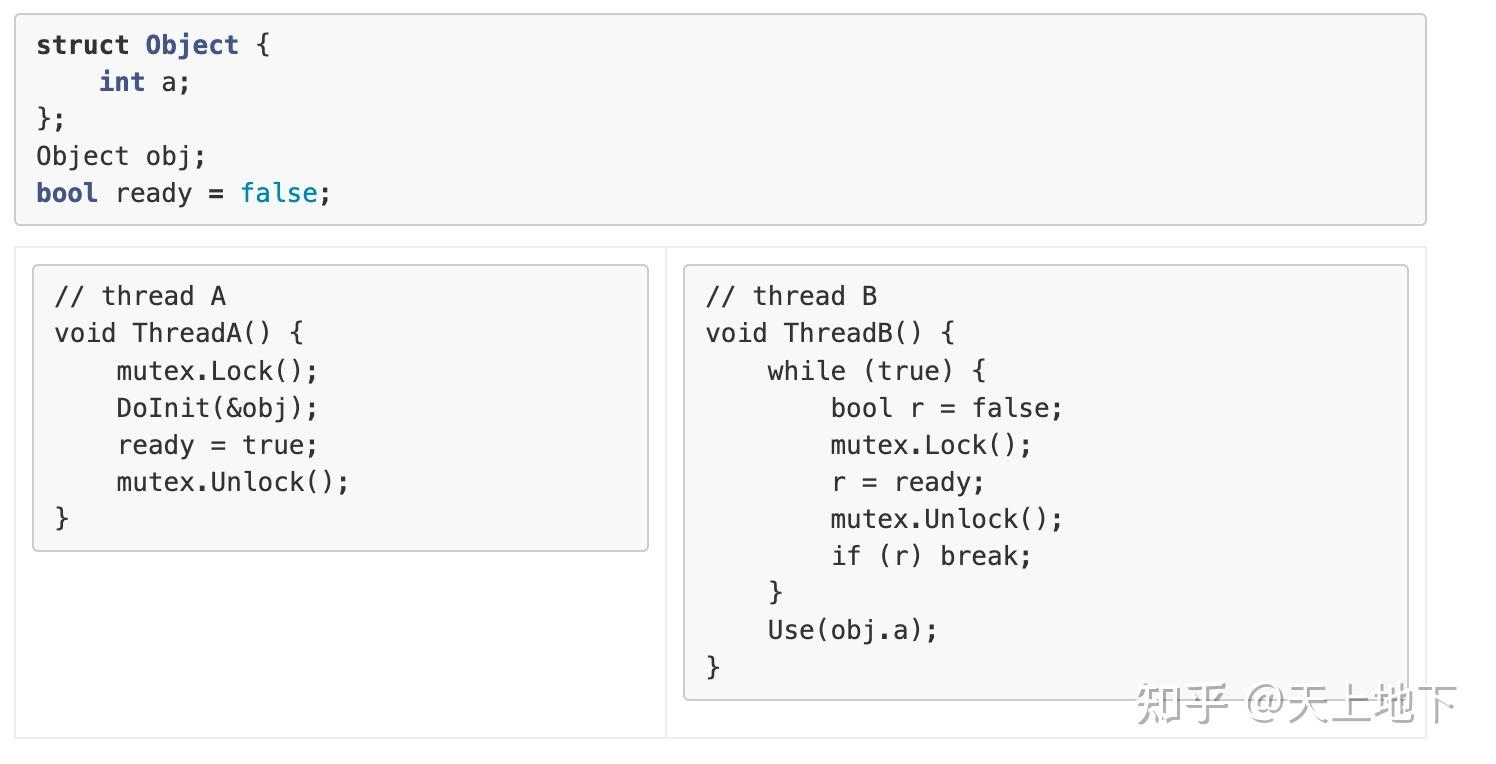
可以很明显地看出这种实现的缺陷, 太费时了. 所以大佬们想出了另外一种方案:


但这种方案有一个问题, 不同的硬件平台具有不同的内存模型. 也就是在 thread B 看到 ready=true 时, 并不意味着 obj 已经完成了初始化, 或者说并不意味着 DoInit(&obj) 对 obj 的更改对 thread B 可见. 完全可能出现一种情况, thread A DoInit(&obj) 对 obj 所做的所有改动仍缓存在 thread A 所在 CPU0 store buffer 中, 对运行在 CPU3 上的 thread B 完全不可见. 这点背景知识可参考 我们都应该了解的 memory barrier 以及背后细节 . 大佬们需要在 atomic_store, atomic_read 之外根据硬件平台各自的要求加入额外的 fetch/barrier 操作使得如上模型正确性成立. 很显然这是个很大成本的操作, 需要对各个硬件平台的内存模型有着精确的了解. 最近随着国产化的流行, 大量的代码从 x86-64 平台迁移到 arm, 我们也遇到过不少由于不了解 arm 平台内存模型, 未正确加入相应 fence/barrier 指令而导致的各种各样的坑. 这么坑往往与高并发有关, 而且很难复现与排查!
因此 c++11 在引入多线程的同时引入了自己的 c++ memory order 模型, 开发者只需要按照 c++ memory order 语义, 在使用原子操作/fence 时指定相应的 memory order. 编译器会负责根据各个平台的要求翻译为正确的指令集合. 在 c++11 引入了 memory order 之后, llvm 也基于此定义了 llvm memory order, 我们可以不严谨地认为 llvm memory order 等同于 c++ memory order. 同样, 基于 llvm 构建的 rust 对应的 rust memory order 我们也可以认为与 c++11 memory order 一致.
真没必要掌握!
但老实说, c++ memory order 到真没有必要掌握了解. 大不了直接用 mutex 嘛, 再不济总是使用 memory_order::seq_cst 嘛. 就像 golang 一样, 从 The Go Memory Model 可以看到, golang 是非常不鼓励使用基于原子操作来实现同步的:
Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access.
To serialize access, protect the data with channel operations or other synchronization primitives such as those in the sync and sync/atomic packages.
If you must read the rest of this document to understand the behavior of your program, you are being too clever.
Don’t be clever.
虽然是有丁点好处~
虽然说对 c++ memory order 的精确掌握可以让我们写出正确且 极致 高效的代码. 举个例子:
void PopulateQueue()
unsigned constexpr kNumOfItems = 20;
for (unsigned i = 0; i<kNumOfItems; ++i) queue_data.push_back(i); // 0
count.store(kNumOfItems, std::memory_order_seq_cst); // #1
void ConsumeQueueItems()
while (true) {
int item_index;
if ((item_index = count.fetch_sub(1, std::memory_order_seq_cst)) <= 0) continue; // #2
Process(queue_data[item_index - 1]); // 3
int main()
std::thread a(PopulateQueue);
std::thread b(ConsumeQueueItems);
std::thread c(ConsumeQueueItems);
a.join();
b.join();
c.join();
return global;
}
这里
#1
,
#2
处的 memory_order 参数取
(seq_cst, seq_cst)
,
(release, acq_rel)
,
(release, acquire)
都不影响程序的正确性. 但在 arm 这种只弱一致性内存模型平台上的编译结果来看,
(release, acq_rel)
将比
(seq_cst, seq_cst)
少一条 dmb, Data Memory Barrier 指令. 而
(release, acquire)
又进一步比
(release, acq_rel)
再少一条 dmb 指令. 就算是 x86-64 这种提供了强一致性内存模型的平台, 使用
(release, acq_rel)
也能比
(seq_cst, seq_cst)
少一条 xchg 指令, 要知道 xchg 可是自带隐式 LOCK 语言的啊,这得多影响性能啊!(夸张).
memory order介绍
在 c++20 标准中, 与 memory order 有关的章节主要集中在 6.9.1 Sequential execution, 6.9.2 Multi-threaded executions and data races, 31.4 Order and consistency 中. 要想精确掌握 memory order, 对这些内容的硬啃是避免不了的. 所以我这里不会再试图复述标准中的内容. 而是归纳总结了常用 memory order 的语义. 并提供了一些例子, 再结合标准中的条款来论证为啥例子中的行为会是这样. 最后再零零散散记录了对标准中一些难以理解的部分的理解.
很明显可以看到标准中总共定义了 relaxed, consume, acquire, release, acq_rel, seq_cst 6 个 memory order. 其中 consume 目测要被废弃了. 简单来说 consume 可以视为是 acquire 的子集, 具有比 acquire 更弱的 order 要求. 也就是说在可能的情况下, 使用 consume 比 acquire 负担会更少. c++11 一开始提出 consume, 是想着给予实现充分的自由, 以及更大的性能发挥空间. 但从实际情况上看, 如同 c++20 标准所说, consume 还是挺鸡肋的, 所以目前大佬中准备从标准中移除 consume. 这里不再介绍 consume 相关的语义. 剩余几种 memory order 可以与标准库提供的 atomic operations 结合在一起使用, 使得这些操作除了能原子执行之外, 还自带同步的特效. 如文章一开始举例所示, atomic_store(&ready, true), atomic_read() 只是纯粹的原子操作, 并没有同步的语义. 因此 thread B 看到 ready=true, 并不意味能看到 obj 初始化之后的结果. 而参照 c++ memory order 语义在执行原子操作的同时加上 memory order 的要求, 便使得原子操作同时也带有了同步的光环, 可以确保 thread B 在看到 ready=true 的同时, obj 初始化之后的结果对 thread B 也一定可见. 从 c++ 标准库文档中可以看到, c++ 所有原子操作都同时带有 order 参数, 开发者可以通过 order 指定正确的 memory order 使得原子操作同时也具有同步的语义. 下面会介绍如何正确地指定 memory order 参数.
relaxed
relaxed! 指定了 relaxed 的原子操作其实并不是个 synchronization operations, 并不具有同步的光环. 当开发者使用 relaxed 时, 意味着开发者只是想执行一个纯粹的原子操作, 对 memory order 没有任何要求. 原子操作意味着对于外界来说, 要么看到操作执行前的状态, 要么看到操作执行结束的状态, 并不会看到操作执行过程中的中间状态. 举个不恰当的例子, 在 armv7 上, 执行
f_s = 0x3333333333
, 这里 f_s 是 uint64_t 的全局变量, 会分为两条指令执行, 一条负责前 32bit 的写入, 另一条负责后 32bit 的写入. 也即对于其他线程, 是可能看到 f_s 取值为 0x33333333 这一中间状态的. 但如果使用了原子操作, 则不会有这种问题. 可以在 godbolt 上看下 f_s = 0x3333333333 原子/非原子执行时对应的汇编.
relaxed, 一般使用场景, 是用在计数器场景中. 比如 llvm libstdc++ 中对于 shared_ptr 的实现, 在自增引用计数的时候使用的就是 relaxed:
template <class _Tp>
inline _LIBCPP_INLINE_VISIBILITY _Tp
__libcpp_atomic_refcount_increment(_Tp& __t) _NOEXCEPT
#if defined(_LIBCPP_HAS_BUILTIN_ATOMIC_SUPPORT) && !defined(_LIBCPP_HAS_NO_THREADS)
return __atomic_add_fetch(&__t, 1, __ATOMIC_RELAXED);
#else
return __t += 1;
#endif
}我之前有个疑惑就是, thread A, B 同时执行 fetch_add(relaxed) 这类 read-modify-write 操作时, 会不会看到的是同一个初始值? 也即会不会 A 执行 fetch_add() 后的结果对 B 尚不可见. 这点标准中已经有了解答, 可以理解为 read-modify-write 操作看到的总是最新值!
Atomic read-modify-write operations shall always read the last value (in the modification order) written before the write associated with the read-modify-write operation.另一个疑惑是, thread A atomic_store(any memory order) 的 side effects 对 thread B 是否立即可见? 也即 thread B 执行 atomic_read(any memory order) 是否能立即看到 A 写入值. 或者举个例子:
std::atomic_bool stop(false);
// thread A
stop.store(true, std::memory_order_relaxed);
// thread B
while (!stop.load(std::memory_order_relaxed)) ;
thread B 是否可能会一直看不到 thread A 写入到 stop 中的值, 而一直死循环? 标准也有了解答. 即 thread A 对 stop 的写入对 B 并不会立刻可见, 但会确保在一段时间之后可见.
An implementation should ensure that the last value (in modification order) assigned by an atomic or synchronization operation will become visible to all other threads in a finite period of time.
Implementations should make atomic stores visible to atomic loads within a reasonable amount of time.acquire, release, acq_rel
acquire, release, acq_rel, 这仨 memory order 只是指定了原子操作同时也是个 acquire operation 或者是个 release operation. 标准通过指定了 acquire operation, release operation 的行为使得原子操作具有了同步的语义. 在这种场景下, 对于原子读操作, 合法的 memory order 只有 acquire, 此时表明原子读操作同时也是个 acquire operation. 对于原子写操作, 合法的 memory order 只有 release, 此时意味着原子写操作同时也是个 release operation. 对于原子 read-modify-write 操作, 倒是可以指定为这仨中任一个; 当指定了 acquire, 意味着 read-modify-write 只是个 acquire operation; 当指定了 release, 意味着 read-modify-write 只是个 release operation; 当指定了 acq_rel, 意味着 read-modify-write 先是个 acquire operation, 再是个 release operation.
简单来说, 若 A 是个 atomic release operation, B 是个 atomic acquire operation, 并且 B 读取到了 A 写入的值, 那么 A synchronizes with B. A synchronizes with B 也就意味着 A happens before B. A happens before B 意味着所有先于 A 发生的各种 side effects, 比如值修改, 对 B 都是可见的. 如下所示:
int i = 0;
std::atomic<bool> ready {false};
// thread A
i = 20181218; // 1