

机器学习中的可解释性方法:简要调查

翻译自 Interpretability Methods in Machine Learning: A Brief Survey - Two Sigma
模型不可知的可解释性方法
出于演示目的,让我们考虑一个小的时间序列数据集。时间序列只是按时间顺序索引的一系列数据点。它是金融行业中最常见的数据类型。定量研究的一个常见目标是使用统计和机器学习方法识别金融时间序列数据中的趋势、季节性变化和相关性。


sklearn.ensemble.RandomForestRegressor - scikit-learn 0.24.2 documentation
方法 1:部分依赖图 (PDP)
PDP显示了一个或两个特征对机器学习模型的预测结果的边际效应。
它可以帮助研究人员确定随着各种特征的调整,模型预测会发生什么变化。
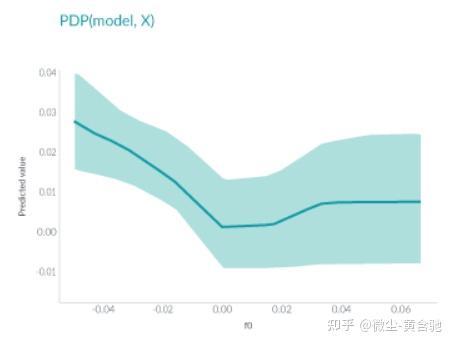
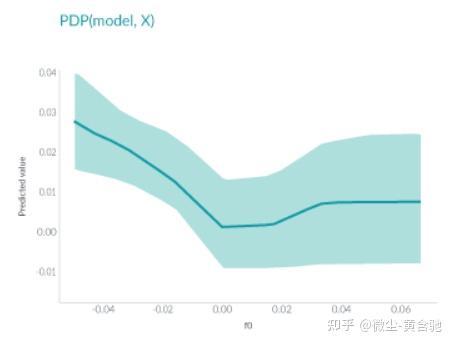
在此图中,x 轴表示特征 f0 的值,y 轴表示预测值。阴影区域中的实线显示了平均预测如何随着 f0 值的变化而变化。
PDP 非常直观且易于实现,但由于它仅显示平均边际效应,因此 可能隐藏异质效应 。 例如,一个特征可能显示与一半数据的预测呈正相关,但对另一半显示负相关。PDP 的图将只是一条水平线。
方法 2:个人条件期望 (ICE)
个人条件期望 或 ICE 与 PDP 非常相似,但 ICE 不是绘制平均值,而是每个实例显示一条线。
这种方法比 PDP 更直观,因为每条线代表一个实例的预测,如果一个实例改变了感兴趣的特征。
与部分依赖一样,ICE 有助于解释模型的预测随着特定特征的变化而发生的变化。
ICE 每个实例显示一行:
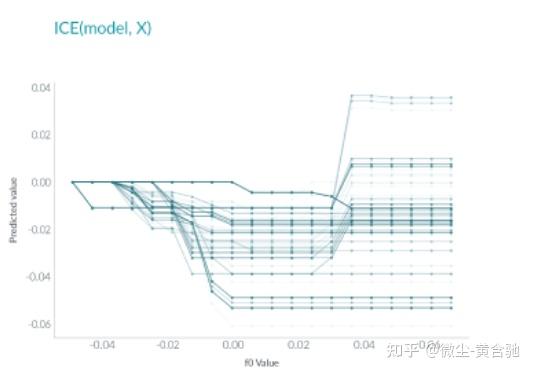
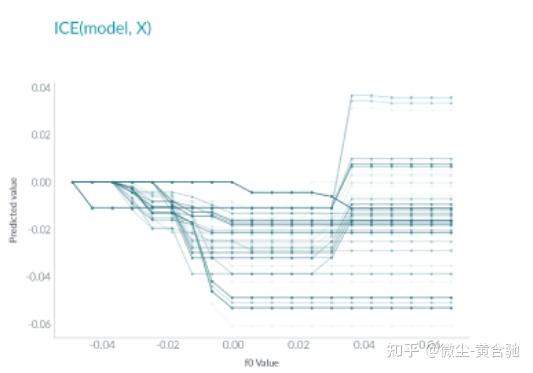
与 PDP 不同,ICE 曲线可以揭示异质关系。然而,这种好处也伴随着代价:它可能不像 PDP 那样容易看到平均效果。
方法 3:置换特征重要性
置换
特征重要性
是另一种传统的可解释性方法。
特征的重要性是特征值打乱后模型预测误差的增加。换句话说,它有助于定义模型中的特征如何对其做出的预测做出贡献。
PDP vs. ICE vs. 特征重要性
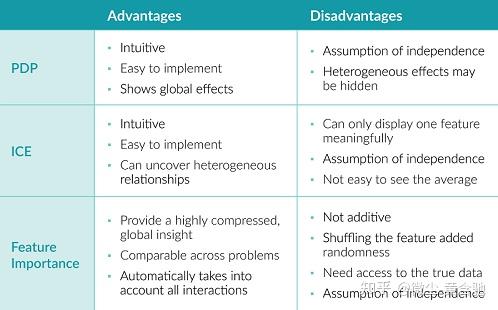
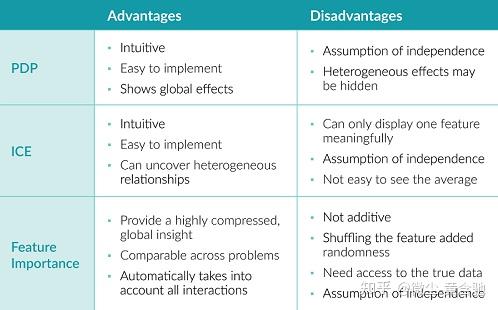
以上三种方法都直观且易于实现。
PDP 显示全局效应,同时隐藏异质效应。ICE 可以发现异质效应,但很难看到平均值。
特征重要性提供了一种理解模型行为的简洁方法。误差率(而不是误差)的使用使得不同问题的测量具有可比性。它会自动考虑与其他特征的所有交互。然而,特征重要性的相互作用不是相加的;对特征进行混洗会增加随机性,因此每次的结果可能不同;此方法需要不少真实数据,这在许多情况下是不可能的。
此外,所有三种方法都假设特征的独立性,因此如果特征是相关的,那么嘿嘿嘿。
方法 4:全局代理
全局代理方法训练一个可解释的模型来近似黑盒模型的预测。
这个过程很简单。首先,使用经过训练的黑盒模型对数据集进行预测,然后在该数据集和预测上训练可解释的模型。训练好的可解释模型现在变成了原始模型的代理,我们需要做的就是解释代理模型。请注意,代理模型可以是任何可解释的模型:线性模型、决策树、人类定义的规则等。
使用可解释的模型来近似黑盒模型会引入额外的误差,但可以通过 R方轻松测量额外的误差。
但是,由于代理模型仅根据黑盒模型的预测而不是真实结果进行训练,因此全局代理模型只能解释黑盒模型,而不能解释数据。
方法 5:本地代理 (LIME)
Local Surrogate 或 LIME (用于 Local Interpretable Model-agnostic Explanations)与 global surrogate 不同,它不尝试解释整个模型。相反,它训练可解释的模型来近似单个预测。
LIME 试图了解当我们扰乱数据样本时预测是如何变化的。下面是一个 LIME 的例子,它解释了为什么这张图片被模型归类为树蛙。
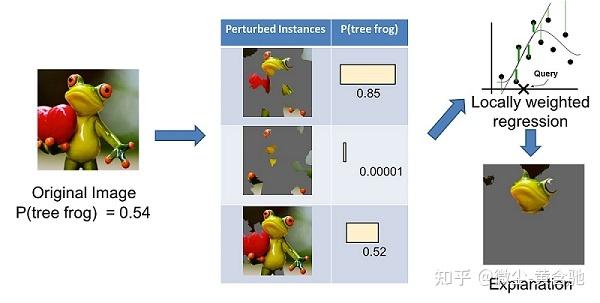
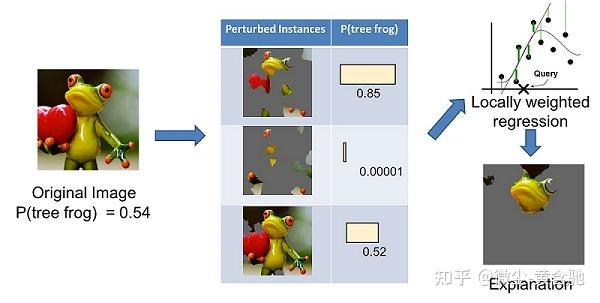
首先,左边的图像被分成可解释的部分。然后,LIME 通过“关闭”一些可解释的组件(使它们变灰)来生成扰动实例的数据集。
对于每个扰动的实例,使用经过训练的模型来获取图像中树蛙的概率,然后在该数据集上学习局部加权线性模型。最后,给出具有最高正权重的组件作为解释。
全局与局部替代方法
全局和局部代理方法都有优缺点。
全局代理关心解释模型的整个逻辑,而局部代理只对理解特定预测感兴趣。
使用全局代理方法,任何可解释的模型都可以用作代理,并且可以轻松衡量代理模型与黑盒模型的接近程度。
但是,由于代理模型仅根据黑盒模型的预测而不是真实结果进行训练,因此它们只能解释模型,而不能解释数据。此外,代理模型在很多情况下比黑盒模型更简单,可能只能对部分数据给出很好的解释,而不是整个数据集。
另一方面,局部代理方法没有这些缺点。此外,局部代理方法是模型不可知的:如果您需要针对您的问题尝试不同的黑盒模型,您仍然可以使用相同的代理模型进行解释。与全局代理方法给出的解释相比,局部代理方法的解释往往简短、对比鲜明且人性化。
但是,本地代理有其自身的问题。
首先,LIME 使用内核来定义区域内的数据点以用于本地解释,但很难为任务找到合适的内核设置。在 LIME 中进行采样的方式可能会导致不切实际的数据点,且本地解释可能会偏向于这些数据点。
另一个问题是解释的不稳定性。两个非常接近的点可能会导致两种截然不同的解释。
方法 6:沙普利值 (SHAPLEY)
Shapley Value
的概念 来自博弈论。该方法可以通过假设实例的每个特征值是游戏中的“玩家”来解释预测。每个玩家的贡献是通过在其余玩家的所有子集中添加和删除玩家来衡量的。一名球员的沙普利值是其所有贡献的加权总和。
Shapley 值是可加的且局部准确。如果将所有特征的 Shapley 值加起来,再加上基值,即预测均值。这是许多其他方法所没有的功能。
这是
来自 github
的
示例
。该实验尝试使用 Xgboost 模型预测具有 13 个特征的房价。


该图显示了每个特征的 Shapley 值,表示将模型结果从基础值推到最终预测的贡献。红色表示正面贡献,蓝色表示负面贡献。
该图显示,在此数据集中,称为 LSTAT(基于教育程度和职业的人口较低状态百分比)的特征对预测的影响最大,而较高的 LSTAT 会降低预测的房价。
正如数据科学家 Christoph Molnar 在
Interpretable Machine Learning 中
指出的那样,Shapley Value 可能是提供完整解释的唯一方法,它是具有最强理论基础的解释方法。
但是,Shapley 值在计算上是昂贵的。最近开发的核SHAP方法做了一个快速核逼近来解决这个问题,但是面对大量的背景数据,该方法仍然需要大量的计算。
与 LIME 不同,Shapley Value 不返回预测模型;计算新数据实例的 Shapley 值需要访问真实数据,而不仅仅是预测函数。
如何选择“正确”的可解释性工具?
下表总结了本文中涵盖的方法,按复杂度从低到高排序。


研究人员应如何决定哪种方法最适合给定的问题?请记住以下三个注意事项:
- 您需要了解模型的整个逻辑,还是只关心特定决策的原因?这将帮助您决定是需要全局方法还是局部方法。
- 你的时间限制是多少?如果用户需要快速做出决定,最好有一个易于理解的解释。但是,如果决策时间不是限制因素,人们可能更喜欢更复杂和详尽的解释。
- 用户的专业水平如何?预测模型的用户可能在任务中具有不同的背景知识和经验。他们可以是决策者、科学家、工程师等。了解任务中的用户体验是感知模型可解释性的一个关键方面。领域专家可能更喜欢更复杂的解释,而其他人可能想要一种易于理解和记忆的解释。
