


python上手--python操作数据库

数据是所有业务处理的核心,不管是交易数据、财务数据还是用户数据,都是非常有价值的。前面一篇文章介绍了python读写文件的方法,我们可以用文件方式来存放数据,不过使用文件方式时不容易管理,同时还容易丢失,会带来许多问题。目前主流的方法都是采用数据库软件,通过数据库软件来组织和存放数据,不管是读还是存都非常方便,速度也有保障。本篇介绍python操作数据库软件的主要方法。
(1)python操作sqlite3
SQLite是采用c来编写的轻量级基于磁盘的关系型数据库,由于其轻量级、操作方便的特点,该数据库成为了数据规模较小类程序的首选。python软件内置了sqlite3库,在python开发时直接使用导入方式即可:
import sqlite3对于数据库的操作我在之前专栏文章里对关系型数据库的设计和主要操作进行了讲解,链接如下:
使用sqlite我们也按照这些操作类型进行介绍,下面我们使用一个小的案例来说明整个操作过程。
步骤1:准备使用sqlite数据库,开始导入sqlite3数据库
import sqlite3步骤2:连接数据库,同时创建一个demo数据库名字,如果已存在就是连接,如果不存在则为新建。使用sqlite3库的connect方法,在参数中给定数据库的名称,执行该语句将返回一个连接对象。
conn=sqlite3.connect('demo.db')步骤3:根据业务需求组装sql命令语句,这里需要知晓并且熟悉一些sql命令,即新建数据表、插入记录、删除记录、更新记录和查询记录等。例如首先我们需要新建一个user数据表:
sql='create table user ( userid integer primary key autoincrement, \
username varchar(20), userpwd varchar(20))'代码中创建了一个主键userid,设定autoincrement自增,数据类型为整型integer,username用户名为varchar变长度类型,给定长度为20,userpwd密码与username一样。
步骤4:执行SQL操作命令,完成数据的业务操作。这里我们沿着步骤3新建数据表完成这个创建过程,即在数据库的demo中创建一个用户user表。实际操作的时候可以直接使用步骤1返回的连接对象,调用其execute方法,传入sql语句。执行sql命令后返回的也是一个对象。我看一般都是使用连接对象的游标方式,这里我直接使用了连接对象,貌似也正常运行了:
conn.execute(sql) #这里可以直接使用连接对象的执行方法
#c=conn.cursor() #也可以使用创建游标对象的方式
#c.execute(sql) #调用游标的执行方法步骤5:保存连接结果,同时关闭数据库服务
conn.commit() #确认并保存结果
conn.close() #关闭数据库通过上面的步骤执行后,我们就已经新建了一个数据库和数据表,数据库名为demo,数据表名为user,并且在user表里定义了三个字段,分别是id,username和userpwd。有了user表后,接下来就可以实施一些操作,如添加数据、查询数据、删除数据和更新数据。对于添加、删除和更新这三种操作,我们需要反馈的结果就是成功与否,也就是返回的是逻辑布尔值,而对于查询数据,则需要返回数据表中存在的数据。由此我们可以组装一个函数来处理这四种操作,由此来简化代码;
def db_action(sql,actionType=0): #构建数据库操作函数,actionType默认为0,即非查询操作
try: #加入异常处理
res=conn.execute(sql) #调用连接对象的execute执行方法,传入sql语句
if actionType==1: #如果操作类型为1,代表查询
return res #返回查询结果对象
else: #其他类型,包括删除/更新/新增
return True #否则返回逻辑真值
except ValueError as e: #抛出异常
print(e)有了这个公用函数,使用起来就方便多了。接下来我们首先给数据表里增加几行记录:
import sqlite3
conn=sqlite3.connect('demo.db')
def db_action(sql,actionType=0):
try:
res=conn.execute(sql)
if actionType==1:
return res
else:
return True
except ValueError as e:
print(e)
#插入新用户记录
userList="(null,'程咬金12322','1234'),(null,'caojianhua','cao1234'),(null,'lina','lina123'),(null,'dar','dar23'),(null,'caojh','cao123')"
sql='insert into user values '+userList #组装sql语句
if db_action(sql,0)==True: #调用db_action操作函数,当操作类型为0表示非查询业务
print("插入记录成功!")
conn.commit()
conn.close()然后我们可以查询一下现有用户列表:
#查询现有用户列表
sql="select * from user"
userList=db_action(sql,1) #返回结果是列表形式
for user in userList: #遍历用户列表
print(user)
conn.commit()
conn.close()执行代码后运行结果如下:


也可以更新或者删除现有用户,具体代码参考如下:
#更新指定用户记录
sql="update user set userpwd='cao1234' where username='caojianhua'"
if db_action(sql,0)==True:
print("更新记录成功!")
#删除指定用户记录
sql="delete from user where username='dar'"
if db_action(sql,0)==True:
print("删除记录成功!")
conn.commit()
conn.close()上述数据库操作过程实际上还可以更抽象一些,就是封装成一个类,专用处理数据相关业务:
class dbUtils:
def __init__(self,dbName): #连接数据库
import sqlite3
self.conn=sqlite3.connect(dbName)
def db_action(self,sql,actionType=0): #进行相关业务操作
try:
res=self.conn.execute(sql)
if actionType==1: #当操作类型为1时代表为查询业务,返回查询列表
return res.fetchall()
else: #当操作类型不为1时代表为新增、删除或更新业务,返回逻辑值
return True
except ValueError as e:
print(e)
def close(self): #关闭数据库
self.conn.commit()
self.conn.close()再使用的时候就更为方便:
#查询现有用户列表
sql="select * from user" #组装操作sql语句
userDb=dbUtils('demo.db') #调用数据库工具类并连接数据库
userList=userDb.db_action(sql,1) #调用操作类函数并返回查询结果
userDb.close() #关闭数据库
for user in userList: #打印查询结果
print(user)与sqlite类似,mysql等关系型数据操作步骤是一样的。这里不赘述,只是需要注意这一点就行,那就是对于mysql与python之间的连接,需要安装使用mysql与python的接口库MySQLdb ,然后再在python中导入这个库,并调用其connect方法,给定登录myql软件的ip地址,用户名和密码,以及数据库名即可。参考如下:
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "test123", "TESTDB", charset='utf8' )(2)python操作Redis数据库
Redis数据库是典型的非关系型数据库,不要求满足各种范式要求,也不要求有字段定义,非常灵活。其主要结构为key-value键值对,key类型为字符串类型,value类型包括字符串、集合、链表、hash类型等。Redis数据库为内存存储,所以速度很快,目前应用场景较多,主要作为业务与数据库之间的缓存层,当在前端发送请求时,先发送到redis数据库中进行缓存处理,然后设定一定的心跳时间,让redis与服务器mysql数据库保持一致。比如电商系统,对于众多下单但未进行交易结算的业务,如果直接写入数据库,涉及数据写入和读取会给服务器带来非常大的压力,这时可以将这部分未结算的业务放到redis缓存数据库中,用户取消订单时直接修改redis中订单状态即可,由于是内存型缓存和处理,速度就会非常快。而且redis支持存储的value类型非常全面,还可以实现消息队列,实现起来也非常简单。下面我们先从redis的安装开始:
Redis的安装和配置非常简单,从其官网或者github上直接下载下来解压缩即可:
在磁盘解压缩后,打开文件夹,内容如下:
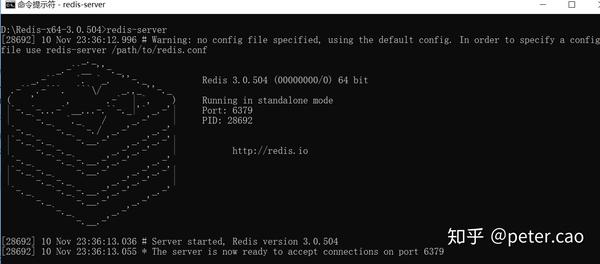
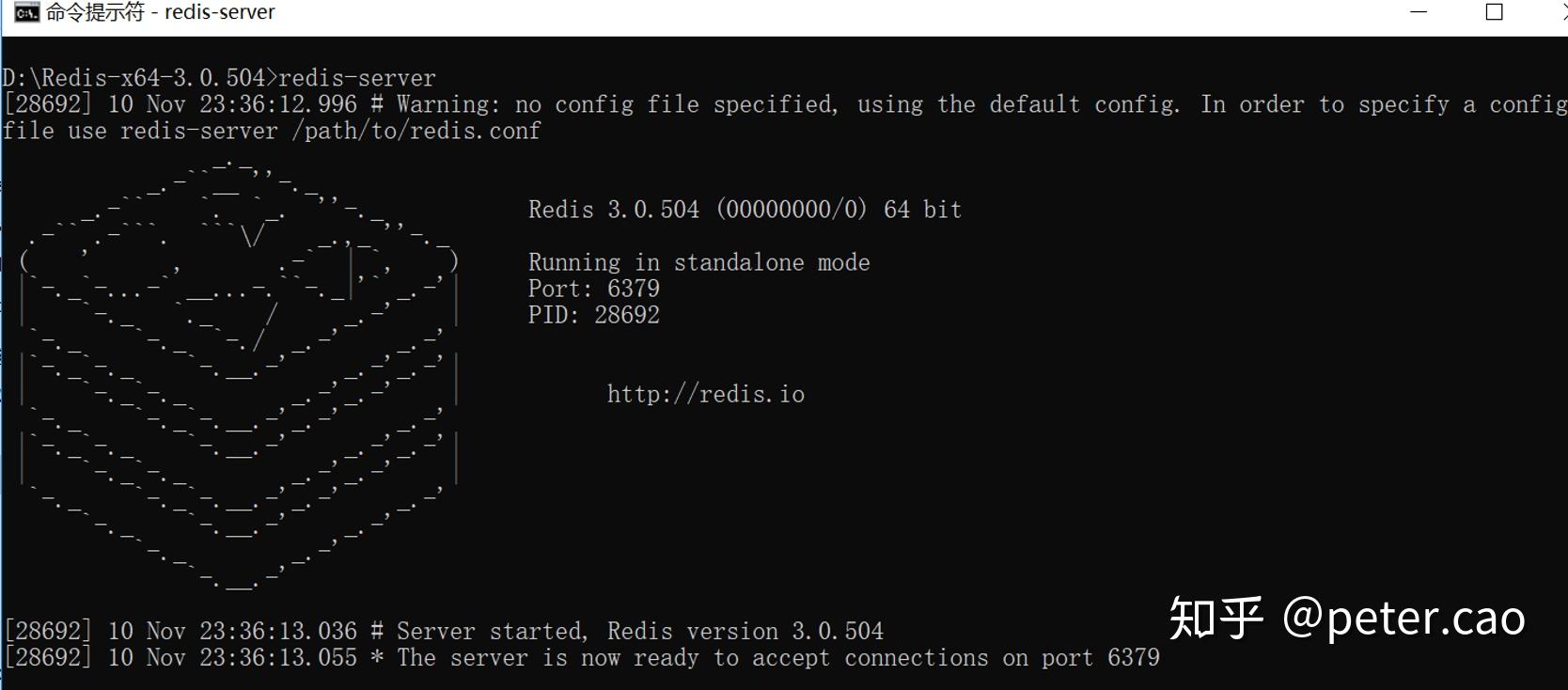
然后打开windows的命令窗口cmd,找到redis解压缩的磁盘目录位置,进入这个文件夹,然后通过键盘敲入redis-server,回车运行就会弹出如下窗口:
此时在该窗口下方提示:服务器已经启动,端口为6379,也就是redis在这个机器上连接的时候使用方式为:本地访问127.0.0.1,端口6379。网络访问:本机公网IP,端口6379。
服务启动后,就可以开始使用python导包和测试使用了。在python中这个redis没有内置,需要导入redis库,在cmd窗口使用:
pip install redis应该很快就可以安装完毕。接下来我们也按照操作sqlite数据库方式分步骤实施:
步骤1:首先要启动redis服务器,在上述cmd窗口运行redis-server.exe文件即可。
步骤2:python软件中安装redis库并在代码行带入该库,同时连接上redis服务器,此时python操作的时候相当于redis的一个控制台端,与在redis安装目录下使用redis-cli.exe shell命令基本类似。我们这里继续使用anaconda的spyder模块。
import redis
redis_db=redis.Redis(host='127.0.0.1',port=6379,db=0)代码调用redis类的Redis连接方法,设定服务器地址,端口号和数据库编号。redis默认一共可以设置16个数据库,如果设置db为0,就是连接第一个数据库。当然也可以修改该配置项,如果不设置,默认为第一个。因为redis库文件都在下载的site-packages里,可以读取其源码进而理解相关类和函数的使用方法。
步骤3:可以开始存储数据了,首先我们来看字符串类型。因为数据结构全是键值对,所以存储的时候都是key-value对,关键词为set,格式为set('key','value'):
redis_db.set('name','caojianhua')
redis_db.set('age',18)
redis_db.set('resume','he is now in Tianjin, and owns Geosail')步骤4:读取redis第一个数据库中的数据,读取的时候使用get(key=keyname)方式:
nameinfo=redis_db.get('name')
ageinfo=redis_db.get('age')上面为使用字符串类型作为value。整个代码如果写成函数如下:
import redis
red_db=redis.Redis(host='localhost',port=6379,db=0)
def setData():
red_db.set('name','caojianhua1')
red_db.set('age','18')
red_db.set('resume','he is now specialist')
print("ok")
def getData():
print(red_db.keys())
#先存储数据
setData()
#再读取数据
getData()上述过程完成了数据存储和读取的过程。如果我们要实现redis作为数据缓存,mysql或者sqlite作为数据存储,还要去实现redis与mysql的同步才行,也就是在频繁查询操作时,先查redis内存缓存中是否存在,如果有,就读取redis中的数据,这样速度会很快,避免直接操作数据库。另外也可以采用mysql里的触发机制,当有数据更新时自动同步到redis中。
下面介绍redis的value类型为集合类型set,集合类型可以看做数据容器(类似数组容器)。不过在这个集合里数据不能重复,而且是无序排列的。
我们可以直接从存储set类型数据开始,到读取数据,其基本代码参考如下:
import redis
red_db=redis.Redis(host='localhost',port=6379,db=1)
def setSetData():
#sadd(key,values):增加集合,给key名集合中添加value,注意value不能重复
red_db.sadd('student','cao','peter','zhangsan','lisi')
def getSetData():
#smembers(key):用于获取key中所有value
print(red_db.smembers('student'))
#srandmember(key,numbers):设定随机获取key集合中任意几个值
print(red_db.srandmember('student',2))
def calSetData():
#集合的操作:并集sunion、交集sinter、差集sdiff
red_db.sadd('employee','lina','zhangsan','lisi1','liuwu')
print(red_db.sunion('student','employee'))
print(red_db.sdiff('student','employee'))
print(red_db.sinter('student','employee'))
#对两个集合的交集运算结果保存为新的集合
red_db.sinterstore('stuem','student','employee')
print(red_db.smembers('stuem'))
setSetData()
calSetData()这里我们直接新建一个redis数据库,序号为1,然后使用连接对象的sadd方法添加集合,smembers方法查看集合中的数据,使用sunion方法查看两个集合中的并集结果,使用sdiff方法查看两个集合的差集结果,使用sinter方法查看两个集合中的交集结果。还可以使用sunionstore、sdiffstore、sinterstore等方法分别将集合运算的结果保存成新的集合。
redis中存储hash类型数据是非常有意义的,类似于字典结构键值对。hash类型基本格式为:
name : {key-value}, {key-value}, {key-value} ...
例如保存一个商品的条目信息:
shoes: {'name': 'Nike', 'price':500,'remains': 1000,'production': 'China'}
这种格式的数据其实非常多,由于没有严格的范式和关系固定要求,结构中key-value可以无限增加,比较灵活。如下代码实践:
import redis
red_db2=redis.Redis(host='localhost',port=6379,db=2)
def setHashData():
#hset(name,key,values):增加hash名为name,添加其键值对表述
red_db2.hset('student','name','peter')
red_db2.hset('student','age','18')
red_db2.hset('student','career','engineer')
#hmset批量添加键值对
red_db2.hmset('shoes',{'name':'Nike','price':500,'store':2000})
def getHashData():
#hget(name):用于获取name中所有键值对
print(red_db2.hget('student','name'))