

Hugging Face教程 - 5、huggingface的datasets库使用

介绍
本章主要介绍Hugging Face下的另外一个重要库:Datasets库,用来处理数据集的一个python库。当微调一个模型时候,需要在以下三个方面使用该库,如下。
- 从Huggingface Hub上下载和缓冲数据集(也可以本地哟!)
-
使用
Dataset.map()预处理数据 - 加载和计算指标
Datasets库可以很方便的完成上述三个操作,另外在本章中我们着重关注如下问题。
- 当你的数据集不在Dataset Hub上时,怎么办?
- 如何分割与合并数据集(使用类似Pandas的操作方式)?
- 当你的模型达到超过内存加载能力时怎么办?
- 内存映射和Apache的Arrow是什么?
- 如何创建自己的数据集并上传到datasets的Hub?
本章学习的数据集操作方法在后续章节(高级分词方法和语言模型的微调)会经常用到。(数据是深度学习的基础,极为重要)
当你的数据集不在Dataset Hub上时,怎么办?
在前面章节中已经知道如何从
Hugging Face Hub
上下载和缓存数据集(使用
load_dataset
直接指定Hub上已有的数据集名称)。但是我们经常会遇到需要加载本地和远程服务器上数据的情况,本节就是介绍如何使用Hugging Face的Datasets库来完成那些Hub没有的数据集加载方法。
处理本地和远程服务器上的数据集
Datasets库提供了很多的加载脚本,主要支持如下几种常见数据格式,如下表所示。
| Data format | Loading script | Example |
|---|---|---|
| CSV & TSV | csv | load_dataset("csv", data_files="my_file.csv") |
| Text文本文件 | text | load_dataset("text", data_files="my_file.txt") |
| JSON & JSON Lines文件 | json | load_dataset("json", data_files="my_file.jsonl") |
| Pickled DataFrames(pandas) | pandas | load_dataset("pandas", data_files="my_dataframe.pkl") |
如上面表格中的example所示,只需要在
load_dataset()
函数中指定加载数据的类型(csv或tsv表格数据、text文本数据、json或json lines格式数据已经pandas保存的pickle文件)以及设置参数
data_files
来指定一个或多个文件即可。下面我们使用上面的方法加载本地文件,后面会介绍加载远程数据。
加载本地数据集
下面我们以 SQuAD-it dataset 为例,这个数据集是一个在意大利语的大规模文本问答数据集。
该数据集的训练和测试数据存在Github上,可以使用如下命令下载数据(通过
wget
工具)。
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
上面的命令会下载训练数据文件
SQuAD_it-train.json.gz
和测试数据文件
SQuAD_it-test.json.gz
,使用
gzip
命令解压,如下所示。
!gzip -dkv SQuAD_it-*.json.gz
SQuAD_it-test.json.gz: 87.4% -- replaced with SQuAD_it-test.json
SQuAD_it-train.json.gz: 82.2% -- replaced with SQuAD_it-train.json 如上所示,解压文件有 SQuAD_it-train.json 和 SQuAD_it-text.json 。由文件名后缀可知,数据为json格式。如果是.jsonl后缀,那么就是json lines格式。
上面代码中的感叹号
!
是在jupyter notebook上运行终端命令时需要添加的,如果直接在终端运行那么就不需要这个感叹号了!
在使用函数
load_dataset()
函数加载数据集时,我们需要知道加载的文件是JSON格式(类似于嵌套字典)还是JSON Lines格式(类似于包含嵌套字典的列表)。因为SQuAD-it数据集的文本都存储在
data
域中,因此我们可以在
load_dataset()
函数上设置参数
field
来指定取哪个域名对应的数据。
from datasets import load_dataset
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
默认情况,加载本地数据集后,会得到键值为
train
的
DatasetDict
对象。通过在notebook上输入
squad_it_dataset
可以观察数据集的情况。
squad_it_dataset
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
如上所示,输入数据集名称,可以显示数据集
train split
下的数目以及数据集各列名称。可以通过索引查看数据集的具体内容。
squad_it_dataset["train"][0]
"title": "Terremoto del Sichuan del 2008",
"paragraphs": [
"context": "Il terremoto del Sichuan del 2008 o il terremoto...",
"qas": [
"answers": [{"answer_start": 29
, "text": "2008"}],
"id": "56cdca7862d2951400fa6826",
"question": "In quale anno si è verificato il terremoto nel Sichuan?",
}
通过上面的代码,我们已经加载了本地文件数据(其实也可以指定加载文件,这个后面会介绍)!然而在训练模型的时候一般需要准备训练和测试数据,即在
DatasetDict
对象中有
train
和
test
域。有了这两个域之后,可以很方便的通过调用
Dataset.map()
函数完成两个数据集的预处理。同时加载训练和测试数据集,可以设置
data_files
字典对象,通过字典的键值来指定阈名称。
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
squad_it_dataset
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
test: Dataset({
features: ['title', 'paragraphs'],
num_rows: 48
})
得到上面的
DatasetDict
对象后,就可以是用方便的对数据集进行数据清洗、分词等数据预处理操作。
load_dataset()
函数的
data_files
参数非常灵活。它可以是单个文件路径,文件路径列表或者是字典(键为split名称,值为数据文件路径),也可以使用
glob
库来匹配满足指定格式的数据文件(例如使用
data_files="*.json"
,可以一次性加载本地路径上的所有json后缀名文件),具体可以参考链接
documentation
。
Datasets库的加载脚本包含解压缩文件功能,因此可以在
data_files
中直接将压缩包数据文件路径,它会自动完成解压缩的步骤,如下所示。
data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
当你不想手动解压GZIP文件时,上面提供的功能确实很省事。当然,对于ZIP和TAR格式,加载脚本也是支持的。只需要通过
data_files
参数设置好即可!
上面主要介绍如何加载本地文件,下面介绍如何加载远端数据(在远程服务器或设备上)。
加载远端数据
如果兄弟在大厂上班的话(数据一般在云上,本地存储能力有限),使用
load_dataset()
函数加载远端数据和加载本地文件的代码区别不大,只是将本地文件路径修改为URL路径。例如对于
SQuAD-it-dataset
数据集,可以如下设置
data_files
参数进行加载。
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {
"train": url + "SQuAD_it-train.json.gz",
"test": url + "SQuAD_it-test.json.gz",
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
上面的代码会返回与更前面代码结果一直的
DatasetDict
对象,该对象存储了我们想要加载的数据。该方法是发现加载的路径地址为URL时,会调用网络加载模块下载和解压数据,并存储为
DatasetDict
对象。一句话,省心省力,很pythonic。上面介绍了一些本地和远端数据的加载方法,下面要介绍一些具体的数据集操作。这些操作对于建立训练pipeline是很重要的!
两个试验。一是可以使用上面的代码以本地和远端模式加载GitHub或 UCI Machine Learning Repository 的数据;二是加载CSV或text格式的数据(把load_dataset()函数中的json换成csv或text即可)。
分割和合并数据集
一般情况下的数据并不能直接满足模型训练的要求,要做一些处理(例如分割数据集为训练和验证两个集合、将文本转化为input_ids等等)。本节主要介绍这些方法。
切割数据集
与Pandas类似,Datasets库提供了许多处理
Dataset
和
DatasetDict
的函数。在第三章
Chapter 3
中我们已经见过
Dataset.map()
函数的使用了,这里主要介绍其他的函数。
这里以 UC Irvine Machine Learning Repository 提供的数据集 Drug Review Dataset 为例。该数据集的任务是人们对药品的评论,有10个等次。
下面使用
wget
和
unzip
工具下载和解压数据。
!wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip"
!unzip drugsCom_raw.zip
下载的文件格式为TSV,因为TSV是CSV格式的一种(CSV 使用逗号做分隔符,TSV使用
\t
制表符做分隔符),所以我们可以使用
csv
脚本来加载该类文件,但是需要在函数
load_dataset()
函数中指定
delemiter
参数为
\t
。
from datasets import load_dataset
data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
# \t is the tab character in Python
drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
当加载好数据之后,一个很好的习惯是抽样观察下数据具体的情况。Datasets库提供了
.shuffle()
和
select()
函数来打乱和选择数据,如下所示(随机采样1000个样本)。
drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
# Peek at the first few examples
drug_sample[:3]
{'Unnamed: 0': [87571, 178045, 80482],
'drugName': ['Naproxen', 'Duloxetine', 'Mobic'],
'condition': ['Gout, Acute', 'ibromyalgia', 'Inflammatory Conditions'],
'review': ['"like the previous person mention, I'm a strong believer of aleve, it works faster for my gout than the prescription meds I take. No more going to the doctor for refills.....Aleve works!"',
'"I have taken Cymbalta for about a year and a half for fibromyalgia pain. It is great\r\nas a pain reducer and an anti-depressant, however, the side effects outweighed \r\nany benefit I got from it. I had trouble with restlessness, being tired constantly,\r\ndizziness, dry mouth, numbness and tingling in my feet, and horrible sweating. I am\r\nbeing weaned off of it now. Went from 60 mg to 30mg and now to 15 mg. I will be\r\noff completely in about a week. The fibro pain is coming back, but I would rather deal with it than the side effects."',
'"I have been taking Mobic for over a year with no side effects other than an elevated blood pressure. I had severe knee and ankle pain which completely went away after taking Mobic. I attempted to stop the medication however pain returned after a few days."'],
'rating': [9.0, 3.0, 10.0],
'date': ['September 2, 2015', 'November 7, 2011', 'June 5, 2013'],
'usefulCount': [36, 13, 128]}
观察上面代码可知,我们在
Dataset.shuffle()
中设置了随机种子(相同随机种子的情况下,每次随机得到的结果一致,毕竟计算机的随机是伪随机)。
Dataset.select()
需要输入一个迭代器或者索引列表,这里输入
range(1000)
将随机打乱后的前1000条数据取出来。从上面的数据显示结果中,我们观察到一些异常数据情况。
-
Unnamed: 0列的数据貌似是病人的ID号; -
condition列的文本是大小写混合的; -
reviews文本长短不一,并且包含特殊字符,例如
\r\n换行符和HTML符号&\#039;。
让我们使用Datasets的函数来验证我们上面提出的三个看法。为了测试
Unnamed: 0
列是否为病人ID,可以使用
Dataset.unique()
函数来得到该列数字的数量是否与病人的数量(也即数据行数)一致,如下面代码所示。
for split in drug_dataset.keys():
assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
上面的代码返回
True
表明
Unnamed: 0
就是病人的ID,为了提高可读性,我们使用函数
DatasetDict.rename_column()
来修改列名。
drug_dataset = drug_dataset.rename_column(
original_column_name="Unnamed: 0", new_column_name="patient_id"
drug_dataset
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
num_rows: 161297
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
num_rows: 53766
})可以尝试对列drugName和condition使用Dataset.unique()来获取这些列的类别数。
下面使用
Dataset.map()
函数归一化
condition
标签(所谓归一化就是所有字母都小写),该函数在链接
Chapter 3
中已经用过。需要向函数传入操作数据集一行数据(可以是多个split)的函数名称。
def lowercase_condition(example):
return {"condition": example["condition"].lower()}
drug_dataset.map(lowercase_condition)
AttributeError: 'NoneType' object has no attribute 'lower'
上面代码报错,报错提示
NoneType
对象没有
lower
函数,表明错误是由数据中的空对象导致的。我们可以使用
Dataset.filter()
来滤除空对象以及其它符合条件的数据。该功能也可以使用
Dataset.map()
函数来实现,也即通过设置参数(过滤函数)来实现,如下所示。
def filter_nones(x):
return x["condition"] is not None
使用
drug_dataset.filter(filter_nones)
来过滤数据,这里推荐使用
lambda
函数来定义函数,对于操作简单的函数,使用
lambda
可以很方便的定义,而不需要专门写函数(代码比较长)。
lambda
函数的格式如下。
lambda <arguments> : <expression>
这里的
lambda
是定义
lambda
函数的关键词,
<arguments>
是该函数的参数,可以是一个参数,也可以是参数列表(是函数的输入),
<expression>
是函数体,包含了对变量的具体操作。如下面的例子所示,使用
lambda
实现了平方操作。
lambda x : x * x 传入数值到上面函数,如下所示(为了可读性,可以给上面的函数一个名字)。
(lambda x: x * x)(3)
9 下面是定义的 lambda 函数有两个参数,使用逗号分开,功能是计算三角形的面积。
(lambda base, height: 0.5 * base * height)(4, 8)
16.0 Lambda 函数的应用场景主要是很小的和作用单一的函数(更多 Lambda 函数的信息可以参考链接 Real Python tutorial )。我们在Dataset库上使用 Lambda 函数来执行map和filter操作,如下使用 Lambda 函数来完成过滤空数据操作。
drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
当
None
数据被过滤之后,再归一化
condition
列就不会报错了。
drug_dataset = drug_dataset.map(lowercase_condition)
# Check that lowercasing worked
drug_dataset["train"]["condition"][:3]
['left ventricular dysfunction', 'adhd', 'birth control']
结果显示没有报错!我们已经完成了标签清洗的工作(
condition
列是标签?),同样的方法可以用在其它列上,大家可以试试。
创建新列
当进行文本数据探索性分析的时候,一般会计算每个文本的词个数。因为有点文本只有一个单词,例如Great!,而有点文本非常长。为了计算这个长度,我们首先对文本使用空格进行分词(因为是英文,如果中文就直接算字符个数好了)。
Let’s define a simple function that counts the number of words in each review:
def compute_review_length(example):
return {"review_length": len(example["review"].split())}
与前面的
lowercase_condition()
函数不同,
compute_review_length()
返回一个字典。该字典的键值在原数据集对象中没有。该函数传入
Dataset.map()
后会创建新列(通过对数据集中的每个数据计算得到字典后,新增键值
review_length
得到)。
drug_dataset = drug_dataset.map(compute_review_length)
# Inspect the first training example
drug_dataset["train"][0]
{'patient_id': 206461,
'drugName': 'Valsartan',
'condition': 'left ventricular dysfunction',
'review': '"It has no side effect, I take it in combination of Bystolic 5 Mg and Fish Oil"',
'rating': 9.0,
'date': 'May 20, 2012',
'usefulCount': 27,
'review_length': 17}
与预期一致,我们看到在训练数据集中新增了列
review_length
。我们可以使用
Dataset.sort()
根据列名进行排序(默认由低到高排序)。
drug_dataset["train"].sort("review_length")[:3]
{'patient_id': [103488, 23627, 20558],
'drugName': ['Loestrin 21 1 / 20', 'Chlorzoxazone', 'Nucynta'],
'condition': ['birth control', 'muscle spasm', 'pain'],
'review': ['"Excellent."', '"useless"', '"ok"'],
'rating': [10.0, 1.0, 6.0],
'date': ['November 4, 2008', 'March 24, 2017', 'August 20, 2016'],
'usefulCount': [5, 2
, 10],
'review_length': [1, 1, 1]} 一些评论文本确实只有一个单词,看起来文本和标签对应关系倒是没有太大问题,但是也不能排除文本信息不够导致标签判断困难的情况发生。
还有一种给数据集增加新列的方法是
Dataset.add_column()
函数。该函数可以导入一个Python列表或Numpy数组。该方法可以在一些
Dataset.map()
不太方便实现的情况下使用。
下面我们使用
Dataset.filter()
函数来过滤文本长度小于30的数据。与操作
condition
列类似,我们使用
Lambda
函数来设置文本长度阈值,并执行过滤操作。
drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
print(drug_dataset.num_rows)
{'train': 138514, 'test': 46108} 从上面代码执行结果可知,我们大约删除了15%的原始数据和测试数据。
使用
Dataset.sort()
函数来获取最大长度的文本,可以从链接
documentation
中获取帮助,即通过设置参数来空降序排列。
最后一个问题是如何过滤文本中的HTML字符,我们可以使用Python库
html
来过滤这些特殊字符。
import html
text = "I'm a transformer called BERT"
html.unescape(text)
"I'm a transformer called BERT"
使用
Dataset.map()
实现批量处理。
drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
从上面这些代码可知,
Dataset.map()
函数是非常有用的数据处理函数,下面我们详细介绍下。
小超人
map()
方法的妙用
Dataset.map()
方法有一个
batched
参数,设置为True,表示进行批量数据处理(默认设置是一次性处理1000个数据)。以上节中的HTML数据转换为例,我们可以设置该参数来加速数据处理过程。
如果
Dataset.map()
函数中设置参数
batched=True
,那么输入到map中函数的参数为一个字典,字典中的每个值为一个列表而不是一个单独值。与之对应的,
Dataset.map()
函数的返回值也必须是值为列表的字典。如下所示。
new_drug_dataset = drug_dataset.map(
lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True
) 如果在jupyter notebook上运行代码(可以看到运行时间),你会发现批处理的速度比非批处理快。只要内存、总线带宽和CPU速度够快的情况下批尺寸越大,速度就越快。
使用
Dataset.map(..., batched=True)
可以在第6章
Chapter 6
中实现快速分词(批量进行文本分词)。如下所示,我们使用快速分词器进行药品评论的批量分词操作。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["review"], truncation=True)
在第三章
Chapter 3
中,我们也可以通过向
tokenizer
函数一次性输入多个文本,来提高分词速度(没有使用
batched=True
)。这里以及后面我们尽量使用
batched=True
来进行分词预处理,可以使用%time在Notebook中观察代码运行时间。
%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
在jupyter notebook中,在一个cell的开头输入
%%time
可以计算本cell的运行时间。
动动手!对比有无batched=True和AutoTokenizer.from_pretrained()有无use_fast=True这四种情况下的代码运行速度。
下表为上述测试的结果。
| Options | Fast tokenizer | Slow tokenizer |
|---|---|---|
| batched=True | 10.8s | 4min41s |
| batched=False | 59.2s | 5min3s |
由上表可知,最快的分词操作比最慢的分词操作,快了30倍(我勒个去!)。这么快的原因:一是批量处理了,二是分词器的底层使用了并行计算效果贼好的Rust编程语言来实现。
并行化分词取得了将近6倍速度的提升,在进行批量数据处理时使用并行化,可以大大提升处理速度(单个数据分词处理进行并行处理当然没有啥效果,一个数据怎么并行!!!)。
Dataset.map()
也包括其他的并行处理技术。因为并不是所有的分词器都是用Rust实现的,这个时候可以通过设置
num_proc
增加处理进程提高分词处理速度。
slow_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
def slow_tokenize_function(examples):
return slow_tokenizer(examples["review"], truncation=True)
tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_proc=8)
可以在前面试验的基础上增加
num_proc
参数(
num_proc=8
时的效果往往很好了),结果如下。
| Options | Fast tokenizer | Slow tokenizer |
|---|---|---|
| batched=True | 10.8s | 4min41s |
| batched=False | 59.2s | 5min3s |
| batched=True, num_proc=8 | 6.52s | 41.3s |
| batched=False, num_proc=8 | 9.49s | 45.2s |
从上表可知,多进程对多批次快速分词也有加速作用。而在
batched=False
的情况下,slow tokenizer的多进程比fast tokenizer的单进程处理要快。但是通常情况,不推荐在
batched=True
情况下设置
num_proc=8
(为什么?)。
通常使用
num_proc
来加速操作是推荐的,但是如果调用该多进程操作的函数或代码片段本身就要执行多进程操作那么有可能会报错(例如使用torch.distributed进行多卡训练时,就不推荐数据分词使用多进程了)。
Dataset.map()
函数的功能非常强大,我们在进行NLP任务预处理的时候会使用该函数(批量将输入预处理成模型需要的输入格式)。
在机器学习任务中,一个 example 通常定义为模型的输入(也成为特征集合)。在Dataset中,模型输入是Dataset的列(对应特征)。但是在某些任务中,例如问答任务中,这个特征属于单个列,而这些特征是从一个 example 中抽取出来的。
上面提示如果不清楚的话,后面会逐步介绍。下面我们对
examples
进行分词,并设置最大截断长度为128(tokens最多128个)。通过设置
return_overflowing_tokens=True
来返回所有的文本片段(由于文本比较长,默认情况下超过预设截断长度的token会被丢失。如果设置了
return_overflowing_tokens=True
则会返回所有的token片段)。
def tokenize_and_split(examples):
return tokenizer(
examples["review"],
truncation=True,
max_length=128,
return_overflowing_tokens=True,
) 让我们测试下上面的函数。
result = tokenize_and_split(drug_dataset["train"][0])
[len(inp) for inp in result["input_ids"]]
[128, 49] 从上面代码运行结果可知,我们训练数据的 example 的长度过长被分割为两个特征:一个是128 token长度,另一个是49 token长度。(如果是问答,那么第一个sequence会保留吗?)下面将该函数应用到整个数据集上。
tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000 Oh no!天哪,又报错了!从报错信息可知,我们输入了1000个examples,但是输出了1463。报错是由于这两个数字没有相等导致的(shape error,是因为保留截断数据导致的)。
The problem is that we’re trying to mix two different datasets of different sizes: the
drug_dataset
columns will have a certain number of examples (the 1,000 in our error), but the
tokenized_dataset
we are building will have more (the 1,463 in the error message). That doesn’t work for a
Dataset
, so we need to either remove the columns from the old dataset or make them the same size as they are in the new dataset. We can do the former with the
remove_columns
argument:
上面错误出现是因为
drug_dataset
的列(1000)和
tokenized_dataset
的列(1463)大小不一致导致的,因此我们可以通过移除旧列来解决该问题,通过设置参数
remove_columns
来实现。
tokenized_dataset = drug_dataset.map(
tokenize_and_split, batched=True, remove_columns=drug_dataset["train"].column_names
) 现在代码正常运行。我们发现运行结果的数据比原来数据增加了。
len(tokenized_dataset["train"]), len(drug_dataset["train"])
(206772, 138514)
除了设置
remove_columns
,还可以通过
overflow_to_sample_mapping
参数返回的值来解决上述问题(形状不统一的问题)。设置该参数可以得到新特征与example的对应关系。通过该映射关系,可以将
Dataset.map()
的返回结果做个处理,实现形状匹配,如下所示。
def tokenize_and_split(examples):
result = tokenizer(
examples["review"],
truncation=True,
max_length=128,
return_overflowing_tokens=True,
# Extract mapping between new and old indices
sample_map = result.pop("overflow_to_sample_mapping")
for key, values in examples.items():
result[key] = [values[i] for i in sample_map]
return result 上面的代码是work的,nice!
tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
tokenized_dataset
DatasetDict({
train: Dataset({
features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
num_rows: 206772
test: Dataset({
features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
num_rows: 68876
}) 从结果可知,我们得到的结果与原始数据大小一致,且不需要删除旧的field。如果需要保留这些旧的field进行后处理,那么可以考虑上述方法。
尽管在大多数场合,Dataset提供的方法可以满足我们的需求,但是有时候仍然会有一些特殊的操作需求,这个Dataset也没法满足(例如
DataFrame.groupby()
或更高阶的可视化操作)等,需要将Dataset对象进行转换。Datasets提供了丰富的数据转换方式,例如可以和Pandas\Numpy\Pytorch\Tensorflow\Jax进行互换,下面介绍。
Dataset
s 和
DataFrame
的互相转换
Datasets库使用
Dataset.set_format()
函数来实现与其他库数据格式的转换,因为使用了内存映射操作,数据可以很快速方便的完成数据转换。下面为转换为pandas数据格式。
drug_dataset.set_format("pandas")
用下面的代码查看数据,我们可以看到其已经是
pandas.DataFrame
格式了(原来是字典格式)。
drug_dataset["train"][:3]| patient_id | drugName | condition | review | rating | date | usefulCount | review_length | |
|---|---|---|---|---|---|---|---|---|
| 0 | 95260 | Guanfacine | adhd | "My son is halfway through his fourth week of Intuniv..." | 8.0 | April 27, 2010 | 192 | 141 |
| 1 | 92703 | Lybrel | birth control | "I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | 5.0 | December 14, 2009 | 17 | 134 |
| 2 | 138000 | Ortho Evra | birth control | "This is my first time using any form of birth control..." | 8.0 | November 3, 2015 | 10 | 89 |
下面是用
drug_dataset["train"]
创建
pandas.DataFrame
数据。
train_df = drug_dataset["train"][:]
解释下上面的代码,我们在前面通过代码
Dataset.set_format()
设置了数据集的数据格式,它是在对象的函数
__getitem__()
函数中发挥作用,也就是提取数据的时候发挥作用。那么我们要得到一个完成数据集的
Pandas.DataFrame
数据,就要对
drug_dataset["train"]
进行切分(这里使用
[:]
全部获取,如果没有则获得的数据是
Dataset
而不是
Pandas.DataFrame
)。
转换为
Pandas.DataFrame
之后,就可以调用
pandas
函数来操作数据,下面是计算每个
condition
对应的数量。
frequencies = (
train_df["condition"]
.value_counts()
.to_frame()
.reset_index()
.rename(columns={"index": "condition", "condition": "frequency"})
frequencies.head()| condition | frequency | |
|---|---|---|
| 0 | birth control | 27655 |
| 1 | depression | 8023 |
| 2 | acne | 5209 |
| 3 | anxiety | 4991 |
| 4 | pain | 4744 |
如果你使用
Pandas
方法操作得到新的数据集
pandas.DataFrame
格式数据,那么也可以使用
Dataset.from_pandas()
来将数据转换为
Dataset
对象。
from datasets import Dataset
freq_dataset = Dataset.from_pandas(frequencies)
freq_dataset
Dataset({
features: ['condition', 'frequency'],
num_rows: 819
})
动动手!计算每个drug的平均分,并转换为新的
Dataset
对象。
上面已经介绍了许多基于Datasets的预处理技术,下面还需要创建验证数据集用来训练分类模型,在继续下节前,我们先复位数据格式,如下面代码所示。
drug_dataset.reset_format()创建验证集
尽管已经有了测试集,但是在实际训练过程还是需要创建验证集。如果直接使用测试集做验证集,那么很容得到对测试集效果很好的模型,而这种模型往往是过拟合的,因此需要单独创建一个验证集来选择模型,最后用测试集来测试模型的泛化能力。
Datasets库提供函数
Dataset.train_test_split()
来分割训练和验证数据集(该函数的思想来源预sklearn),如下面代码所示(设置随机种子保证每次分割结果一致)。
drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
# Rename the default "test" split to "validation"
drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
# Add the "test" set to our `DatasetDict`
drug_dataset_clean["test"] = drug_dataset["test"]
drug_dataset_clean
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 110811
validation: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 27703
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 46108
}) 如上所示,我们准备好了模型训练所需的数据集,后面会介绍如何训练和上传到datasets Hub上,在这之前,我们先看看如何保存dataset(到本地)。
保存数据集
保存datasets可以方便的略过数据预处理,直接加载已经处理好的数据是一个很好的办法(避免重复操作)。Datsets提供了三个函数来保存
Dataset
。
| Data format | Function |
|---|---|
| Arrow | Dataset.save_to_disk() |
| CSV | Dataset.to_csv() |
| JSON | Dataset.to_json() |
如下所示,我们保存清洗后的数据集(保存为Arrow格式)。
drug_dataset_clean.save_to_disk("drug-reviews")
上述代码执行后,会在本级目录下创建
drug-reviews
目录(数据保存目录)。
drug-reviews/
├── dataset_dict.json
├── test
│ ├── dataset.arrow
│ ├── dataset_info.json
│ └── state.json
├── train
│ ├── dataset.arrow
│ ├── dataset_info.json
│ ├── indices.arrow
│ └── state.json
└── validation
├── dataset.arrow
├── dataset_info.json
├── indices.arrow
└── state.json
从上面结果可知,每个split都有自己的arrow文件
dataset.arrow
、元数据文件
dataset_info.json
和
state.json
。这个存储方式非常方便快速实现对大数据集的操作。
数据集保存好之后,我们可以调用
load_from_disk()
来加载数据集。
from datasets import load_from_disk
drug_dataset_reloaded = load_from_disk("drug-reviews")
drug_dataset_reloaded
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
num_rows: 110811
validation: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
num_rows: 27703
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
num_rows: 46108
}) 对于CSV和JSON格式,我们可以按照split的划分进行保存,即迭代读取相关数据,然后保存为csv或json格式。
for split, dataset in drug_dataset_clean.items():
dataset.to_json(f"drug-reviews-{split}.jsonl") 上面的代码是把数据保存为 JSON Lines format 格式,即每一行为一个json数据,如下所示。
!head -n 1 drug-reviews-train.jsonl
{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
然后使用
load_dataset
来加载上面保存的数据。
data_files = {
"train": "drug-reviews-train.jsonl",
"validation": "drug-reviews-validation.jsonl",
"test": "drug-reviews-test.jsonl",
drug_dataset_reloaded = load_dataset("json", data_files=data_files) 到目前位置,我们已经完成了基于Datasets库的数据处理操作,也得到一个干净的数据集,可方便用于模型训练。读者可以考虑如下两个试验。
- 使用该数据集训练分类模型,看看效果如何(使用RoBERTa)
-
使用
summarizationpipeline来获取每个review的摘要
上面我们介绍了如何加载本地和远端数据集,以及一些数据集的具体操作(满足模型训练的需求)。下面我们介绍如果数据量很大的情况下,如何快速加载数据集使得其满足模型训练需求。
大数据?Datasets加载数据的艺术!
现在上GB的数据集是非常常见的,例如训练BERT和GPT2的数据集。加载如此之大的数据集对内存大要求很高。预训练GPT2的数据集包含8百万个文档和40GB的文本。如果你有尝试加载过这些数据,就会知道这有多么的麻烦!
Datasets针对大数据加载的痛点做了很多工作,在加载数据上使用内存映射的方法,使得加载数据不再受内存大小的限制,只要磁盘空间够大,就能够快速加载大数据文件。
本节将介绍如何加载825GB大小的语料库,该库名称为 the Pile 。
什么是Pile?
Pile数据集是
EleutherAI
组织创建,用来进行大规模语言模型的预训练使用。它涉及了非常多的领域,包括科学类文章、GItHub上的代码和清洗好的网络文本。训练语料为
14 GB chunks
,读者可以下若干个独立的片段。然我们首先看下PubMed摘要数据集,该数据集包含了1千5百万个
PubMed
上的生物出版书籍。数据是
JSON Lines format
格式(每行是一个
json
),并使用库
zstandard
压缩,安装此库使用如下代码。
!pip install zstandard
我们可以使用加载远端数据的方法调用
load_dataset
函数,如下所示。
from datasets import load_dataset
# This takes a few minutes to run, so go grab a tea or coffee while you wait :)
data_files = "https://mystic.the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst"
pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
pubmed_dataset
Dataset({
features: ['meta', 'text'],
num_rows: 15518009
}) 可以看到,该数据集有15,518,009行和2列数据。
默认情况下,加载数据集的过程中会解压数据,并保存在硬盘上。为了节省硬盘空间,可以在load_dataset()函数中设置DownloadConfig(delete_extracted=True)参数。具体可参考链接 documentation
让我们看下某个数据的具体内容,如下。
pubmed_dataset[0]
{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'} 从上面结果可知,该数据是医疗文本的摘要数据。下面我们看下该数据集占用内存情况。
内存映射的魔法
一个获取内存占用大小的Python库是
psutil
库,可以使用如下代码安装。
!pip install psutil
该库提供了
Process
类来获取现有进程占用内存的大小。
import psutil
# Process.memory_info is expressed in bytes, so convert to megabytes
print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
RAM used: 5678.33 MB
上面代码中的属性
rss
是指
resident set size
,是该进程占用内存的大小。当然该内存也包含Python解释器和psutil库占用内存,因此数据集占用内存会比
5678.33MB
要小一点点。下面我们做个对比,看下实际的数据集占用磁盘空间大小,可以使用属性
dataset_size
得到(因为得到的存储空间度量单位是字节,我们需要手动转换为GB大小)。
print(f"Number of files in dataset : {pubmed_dataset.dataset_size}")
size_gb = pubmed_dataset.dataset_size / (1024**3)
print(f"Dataset size (cache file) : {size_gb:.2f} GB")
Number of files in dataset : 20979437051
Dataset size (cache file) : 19.54 GB 实际数据集占用磁盘空间接近20GB。综上,使用内存映射技术加载数据集节省了大量内存。
动动手!加载Pile数据集下的其它子集,并重复上面的步骤。
如果读者对pandas库很熟悉的话,会知道一个著名的Wes Kinney准则,该准则的意思是:如果加载数据需要的内存一般是该数据大小的5到10倍。而Datasets采用一种叫做内存映射的技术来处理该问题。该技术建立了内存到文件系统的一个映射关系来快速加载数据,而不需要一次性将所有数据加载到内存当中。
内存映射文件可以使用
Dataset.map()
函数来进行并行操作(不需要移动或拷贝数据)。内存映射方法基于
Apache Arrow
的内存格式以及
pyarrow
库实现(更多关于Apache Arrow的细节,以及预Pandas的比较,可以参考链接
Dejan Simic’s blog post
)。下面我们做些测试。
import timeit
code_snippet = """batch_size = 1000
for idx in range(0, len(pubmed_dataset), batch_size):
_ = pubmed_dataset[idx:idx + batch_size]
time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
print(
f"Iterated over {len(pubmed_dataset)} examples (about {size_gb:.1f} GB) in "
f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
上面的代码使用Python的
timeit
模块来计算代码块
code_snippet
的执行时间。结果显示上述代码以GB级别的速度在迭代的读取数据。上面的方法在大多数场景下是实用的,当时当数据量特别大的时候,比如我们要处理完整的Pile数据集(825GB),那么首先要下载下来,这就已经很费时了。为解决该问题,Datasets提供了一个流式数据加载方式,它可以实现在线的下载和处理数据(不需要下载完整的数据)。下面详细介绍。
如果在jupyter notebook上运行代码,可以使用
"https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit">%%timeit magic function
。
流式加载数据集
使用
load_dataset()
函数实现流式加载数据集,只需要设置参数
streaming=True
。下面是使用流式加载数据集的方式,加载PubMed摘要数据集。
pubmed_dataset_streamed = load_dataset(
"json", data_files=data_files, split="train", streaming=True
)
与我们熟悉的
Dataset
不同,上面代码返回的结果为
IterableDataset
对象。如果要读取
IterableDataset
对象数据,我们需要使用迭代读取的方式。
next(iter(pubmed_dataset_streamed))
{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
与
Dataset.map()
函数类似,如果要做数据预处理的话,可以使用
IterableDataset.map()
函数进行操作。与
Dataset.map()
的主要区别在于,
IterableDataset.map()
处理的结果也需要迭代读取。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
tokenized_dataset = pubmed_dataset_streamed.map(lambda x: tokenizer(x["text"]))
next(iter(tokenized_dataset))
{'input_ids': [101, 4958, 5178
, 4328, 6779, ...], 'attention_mask': [1, 1, 1, 1, 1, ...]}为了加速流式数据的分词,可以设置参数batched=True。默认的批尺寸为1000,如果要指定其他值,可以修改参数batch_size。
同样也可以使用
IterableDataset.shuffle()
函数打乱数据,但是与
Dataset.shuffle()
函数类似,
IterableDataset.shuffle()
只会打乱在缓存中的数据,即只有
buffer_size
个数据会被打乱。
shuffled_dataset = pubmed_dataset_streamed.shuffle(buffer_size=10_000, seed=42)
next(iter(shuffled_dataset))
{'meta': {'pmid': 11410799, 'language': 'eng'},
'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'}
在上面例子中,我们从缓存的10000个examples中随机抽取了一个example。一旦这个example被读取,那么缓存会弹出该example,并将第10001个example移入缓存(是队列呀!)。也可以使用
IterableDataset.take()和
IterableDataset.skip()
读取流式数据
(类似
Dataset.select()
操作)。下面是从PubMed摘要数据集中读取5个examples的代码。
dataset_head = pubmed_dataset_streamed.take(5)
list(dataset_head)
[{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
{'meta': {'pmid': 11409575, 'language': 'eng'},
'text': 'Clinical signs of hypoxaemia in children with acute lower respiratory infection: indicators of oxygen therapy ...'},
{'meta': {'pmid': 11409576, 'language': 'eng'},
'text': "Hypoxaemia in children with severe pneumonia in Papua New Guinea ..."},
{'meta': {'pmid': 11409577, 'language': 'eng'},
'text': 'Oxygen concentrators and cylinders ...'},
{'meta': {'pmid': 11409578, 'language': 'eng'},
'text': 'Oxygen supply in rural africa: a personal experience ...'}]
类似的,可以使用
IterableDataset.skip()
函数来创建训练和验证数据集split,如下所示。
# Skip the first 1,000 examples and include the rest in the training set
train_dataset = shuffled_dataset.skip(1000)
# Take the first 1,000 examples for the validation set
validation_dataset = shuffled_dataset.take(1000)
下面我们看下流式数据的一个常用方法:需要将若干个数据集拼接为一个数据集(基于
interleave_datasets()
函数,将一个
IterableDataset
对象列表转换为一个
IterableDataset
对象)。上面的方法对于加载超大数据集是非常有用的,以Pile的FreeLaw子数据集加载(该数据集包含51GB大小的US法庭判决案例)为例。
law_dataset_streamed = load_dataset(
"json",
data_files="https://mystic.the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
split="train",
streaming=True,
next(iter(law_dataset_streamed))
{'meta': {'case_ID': '110921.json',
'case_jurisdiction': 'scotus.tar.gz',
'date_created': '2010-04-28T17:12:49Z'},
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}
上面的数据集足够大来测试我们内存的抗压能力(一般32GB内存都加载不了这么大的数据集)。下面我们使用
interleave_datasets()
函数来加载FreeLaw和PubMed摘要数据集,如下所示。
from itertools import islice
from datasets import interleave_datasets
combined_dataset = interleave_datasets([pubmed_dataset_streamed, law_dataset_streamed])
list(islice(combined_dataset, 2))
[{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
{'meta': {'case_ID': '110921.json',
'case_jurisdiction': 'scotus.tar.gz',
'date_created': '2010-04-28T17:12:49Z'},
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}]
这里使用基于Python
itertools
工具中的
islice()
函数来获取数据集中的前两个example,我们发现这两个例子,第一个对应第一个合并的数据集,第二个对应第二个合并的数据集。
最后,如果要加载全部825GB的Pile数据集,那么可以采用如下代码。
base_url = "https://mystic.the-eye.eu/public/AI/pile/"
data_files = {
"train": [base_url + "train/" + f"{idx:02d}.jsonl.zst" for idx in range(30)],
"validation": base_url + "val.jsonl.zst",
"test": base_url + "test.jsonl.zst",
pile_dataset = load_dataset("json", data_files=data_files, streaming=True)
next(iter(pile_dataset["train"]))
{'meta': {'pile_set_name': 'Pile-CC'},
'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web...'}动动手!使用大型常规语料库(例如mc4或oscar等)的部分数据集,来构建多语种数据集。说白了就是找多个相同列结构的数据集,用interleave_dataset()来构建大型的流式数据集。
现在我们有了处理各种大小尺寸数据集的加载方法。当时在处理各种NLP问题时,你不得不自己创建需要的数据集来训练符合你特定NLP需求的数据集,下面就针对如何创建数据集展开讨论。
创建自己的数据集
大多数时候你需要解决的NLP问题没有现成的数据集可供使用,那么你就需要自己创建数据集。在本节中介绍如何创建 GitHub issues 的语料(跟踪和解决代码的BUG),该语料可以用于多种应用的功能,主要包括:
- 探索开通和关闭issue和推动请求需要花费的时间
- 可以基于issue的描述构建标签(例如“bug,” “enhancement,”或“question”),来训练一个多标签分类器
- 创建一个语义搜索引擎,具备根据用户访问快速定位相关issue的功能
本节介绍如何构建语料库,下节主要介绍如何构建语义搜索引擎。issue主要来源于Datasets库的issue。下面介绍如何获取数据,并且探索下这些数据包含什么信息。
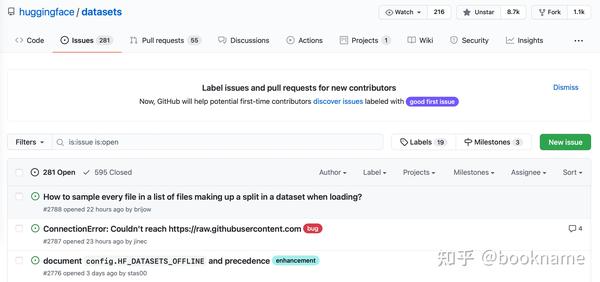
获取数据
在Datasets的Repo上可以看到,如下图。有331个开放的issue和668个关闭的issue。
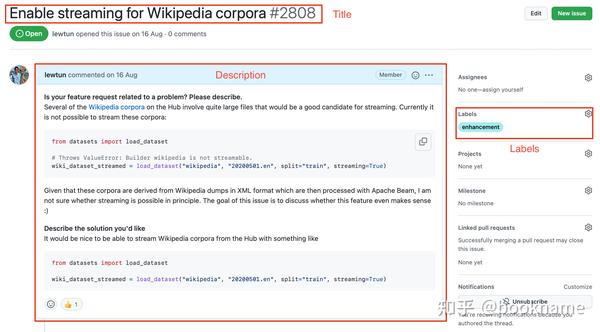
如下所示,一个issue包含一个标题、一个评论和一系列标签(表示该issue的类别)。

为了下载所有repo的issues,我们使用
GitHub REST API
。该API返回
f="https://docs.github.com/en/rest/reference/issues#list-repository-issues">Issues endpoint,是一个JSON对象(该JSON对象中包含了标题、描述和一个标签集合等等)。
使用
requests
库来下载issues是非常方便,该库是处理HTTP请求的标准Python库(标准Python库是指安装Python时就会自带的库,但是版本可能需要更新)。可以通过如下代码安装(国内的话,最好指定下载源)。
!pip install requests
安装好
requests
库之后,可以使用GET方法来获取
Issues
的JSON格式数据。如下代码所示,获取首页上的第一个issue。
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)
上面代码中的
response
包含requests返回的大量有用信息,包括HTTP状态码,如下。
response.status_code
200
上面HTTP状态码为
200
,表示请求返回成功(更多的HTTP状态码表示意义可以参考链接
here
)。除了状态码之外,我们更加关心返回的数据情况。返回数据主要在
response
的
payload
属性中,该属性可能会有多种格式,丽日字节、字符串或JSON格式,因为前面使用API返回的是JSON格式,因此这里的
payload
是JSON格式,如下。
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]
上面返回的信息好多呀!官网上让我们主要关注
title
,
body
, and
number
这三个域,前两个代表本issue的标题和内容,
number
表示打开本issue的用户数量。
可以查看下上面JSON中的一些url,甚至可以打开这些url对应的网页看看会得到什么结果。
有了基于网络(其实就是爬虫)获取Github的issue数据的方法,但是GitHub有个网络访问限制,就是一个小时内每个用户只能访问60次issue。我们按照GitHub’s [instructions来设置 personal access token 私人访问token来将访问次数提高为一小时5000次,这个时候需要提供heads(包含token),如下所示。
GITHUB_TOKEN = xxx # Copy your GitHub token here
headers = {"Authorization": f"token {GITHUB_TOKEN}"}私有token请不要共享,保护隐私。
现在设置好私有token后,我们创建Github issue的爬虫代码。
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Number of issues to return per page
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Query with state=all to get both open and closed issues
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len
(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Flush batch for next time period
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)
现在调用
fetch_issues()
函数就可以在Github访问限制下获取issue数据,下载后的数据会保存在
repository_name-issues.jsonl
文件中,该文件为JSON LINES对象,下面我们运行
fetch_issues()
函数。
# Depending on your internet connection, this can take several minutes to run...
fetch_issues()
下载好数据后,我们使用前面介绍过的
load_dataset()
函数加载。
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
}) OK,上述结果表明我们成功创建了issue数据集!仔细观察下数据的大小,发现我们数据有3019个,但是Dataset的issue只有1000个issue,这是因为我们的爬虫程序把pull requests也下载下来了,所以数据增加,后面是要做数据清洗的。爬虫的原则是尽可能多的获取数据。
GitHub的API函数的返回结果包含pull_request键,可以从返回结果中甘茶是否包含pull_request键来盘是否为pull request。而且pull request返回的id是issue的id,这个也是pull request的特征之一。
正因为issue和pull request不一样,且pull request并不是我们想要的数据,因此我们需要数据进一步处理。
清洗数据
前面介绍了,可以基于返回结果中的
pull_request
来判断是否pull request。下面我们随机抽取数据观察下是否存在这个规律,另外为了提高可读性,我们使用
Dataset.shuffle()
和
Dataset.select()
,并将
html_url
和
pull_request
列zip后进行对比展示。
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Print out the URL and pull request entries
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")
>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}
从上面代码的返回结果可知,pull request返回一系列URL,但是我们需要的issue是None。那么我们可以创建新列
is_pull_request
来标记一个数据是否为pull request。
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)动动手!给个任务,大家计算下Datasets的issue的生命周期。可以通过Dataset.filter()过滤pull request和开放的issue,然后使用Dataset.set_format()得到pandas架构,进而基于两个属性created_at和cloased_at计算该issue的生命周期,当然进行可视化,效果更好。
尽管通过很多预处理(删除或重命名某些列),但还是推荐大家尽量保持数据的原始模样(可以方便的应用在多个用途)。
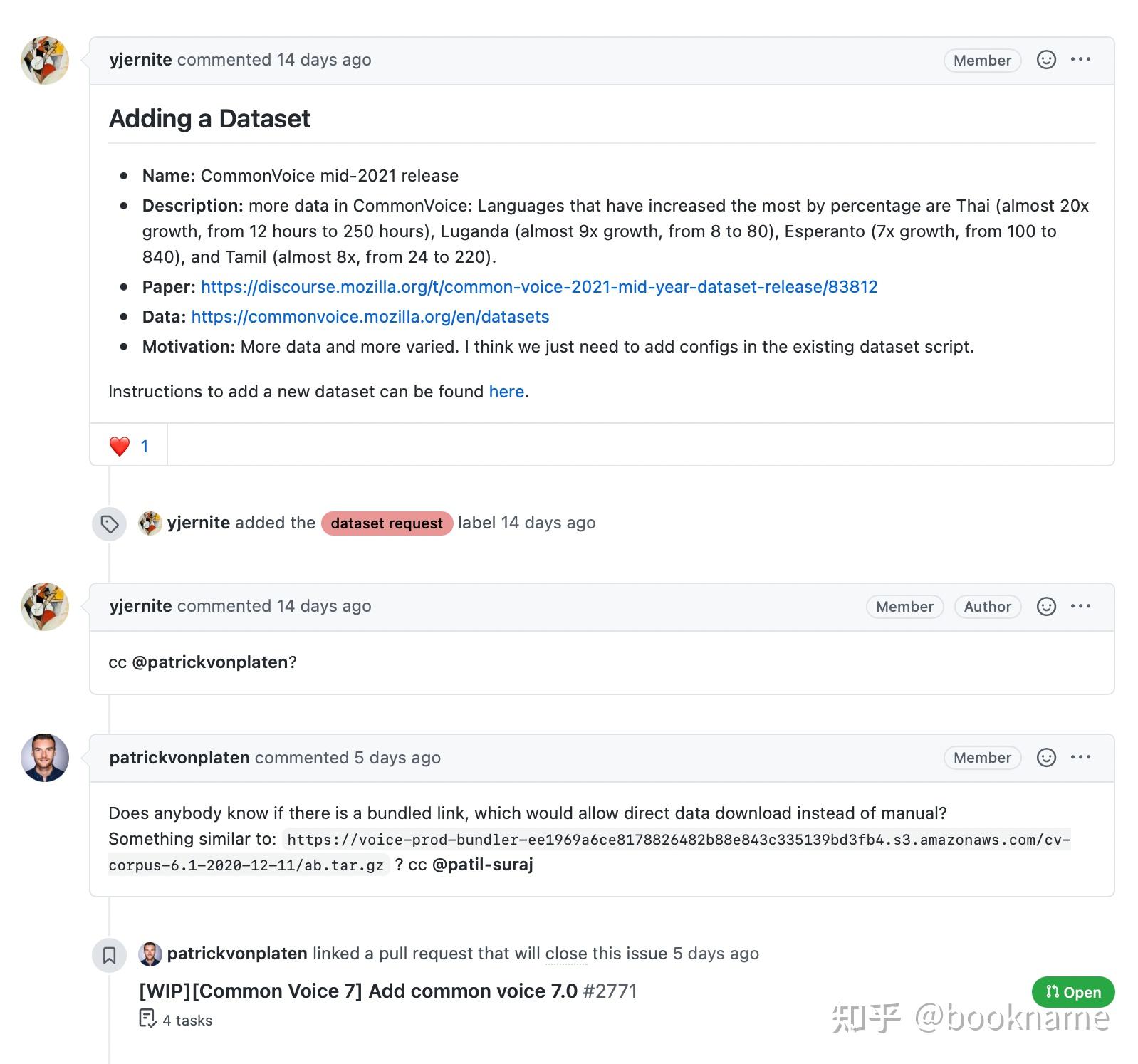
在将数据集上传到Hugging Face Hub之前,我们还需要做件事,就是把issue的评论和issue进行关联(通过GitHub REST API来实现)。
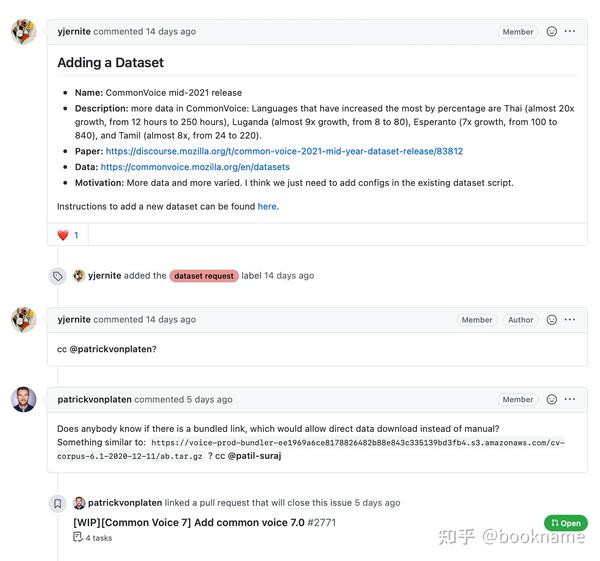
扩增数据集
如下图所示,一个issue或pull request的评论包含了丰富的信息,这些信息对于构建问答类的搜索引擎非常重要 。
GitHub REST API提供了
"https://docs.github.com/en/rest/reference/issues#list-issue-comments">Comments endpoint
来按照issue编号来获取该issue的所有评论,下面我们测试看下效果。
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url':
'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]
从上面爬虫返回结果可知,评论内容存储在
body
域中,下面我们编写函数将评论提取出来。
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Test our function works as expected
get_comments(2792)
["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
结果正确,下面我们使用
Dataset.map()
函数将
comments
评论列添加到我们的数据集中。
# Depending on your internet connection, this can take a few minutes...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
) 最后将修改后的数据保存为jsonl格式,方便我们上传到Hugging Face Hub上,如下。
issues_with_comments_dataset.to_json("issues-datasets-with-hf-doc-builder.jsonl")上传数据集到Hugging Face Hub
前面章节我们已经完成了包含评论的数据集,下面我们将其上传到Hub方便大家共享使用(还真是无私呀)!在模型共享时我们就提到了可以使用和模型共享一样的API来上传数据集,下面具体介绍。首先使用
list_datasets()
函数看下Hub上已经有的数据集。
from huggingface_hub import list_datasets
all_datasets = list_datasets()
print(f"Number of datasets on Hub: {len(all_datasets)}")
print(all_datasets[0])
Number of datasets on Hub: 1487
Dataset Name: acronym_identification, Tags: ['annotations_creators:expert-generated', 'language_creators:found', 'languages:en', 'licenses:mit', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'task_categories:structure-prediction', 'task_ids:structure-prediction-other-acronym-identification'] 从结果可知,Hub上已经有1487个数据集,而且返回结果中还提供了数据集的一些元数据情况。
与模型上传一样,需要使用注册的token在Hub上先创建一个Dataset的repo。这个token在第一次注册Hugging Face的会员会提供。使用代码注册如下所示。
from huggingface_hub import notebook_login
notebook_login() 运行上面代码会要求填入用户名和密码,成功后会将注册token存放在路径 ~/.huggingface/token 下。如果在终端注册,可使用如下命令。
huggingface-cli login
登录成功后,可以使用
create_repo()
函数创建新的repo。
from huggingface_hub import create_repo
repo_url = create_repo(name="github-issues", repo_type="dataset")
repo_url
'https://huggingface.co/datasets/lewtun/github-issues'
在上面例子中,我们使用用户名
lewtun
创建了一个名为
github-issues
的空数据集repo(用户名必须是在Hub上注册的用户名)。
动动手!自己动手完成上面教程的操作,记住保管好的自己的注册token。
下一步就是从Hub上克隆空repo到本地,然后将数据集相关文件放入该repo文件夹中。Hub提供了
Repository
类来处理常用的Git命令,我们可以使用该类来完成克隆操作,如下所示。
from huggingface_hub import Repository
repo = Repository(local_dir="github-issues", clone_from=repo_url)
!cp issues-datasets-with-hf-doc-builder.jsonl github-issues/ 默认情况下,大文件使用Git LFS来进行跟踪,后缀为 .bin, .gz和.zip ( 在文件 .gitattributes 中记录)。如果要让Git LFS追踪JSON LINES个格式文件,需要使用如下代码进行格式添加。
repo.lfs_track("*.jsonl")
然后可以使用
Repository.push_to_hub()
将数据集上传到Hub。
repo.push_to_hub()
然后在网页中观察我们的上传结果(登录
repo_url
),如下所示。
上传好之后,我们就可以使用
load_dataset()
和repo ID和路径来读取数据集了。
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments'
, 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
从上面加载数据集结果可知,我们可以使用
load_dataset()
从Hub上加载我们自己创建的数据集了,其他人也可以采用同样的方法进行数据集加载。下面我们需要创建数据集的卡片或文档,来介绍我们的数据集是如何创建以及如何使用等相关有用信息。
除了上面使用代码的方法进行数据集上传,还可以使用命令行的方式进行数据集上传(huggingface-cli)。具体可参考链接 Datasets guide
创建数据集卡片
撰写良好的文档是非常好的习惯。通过这个文档,大家可以了解这个数据集是做什么任务的,存在什么问题以及基础的数据分析结果等等。
在Hugging Face Hub,文档存储在repo下的文件
README.md
中。创建该文件之前包括两个步骤:
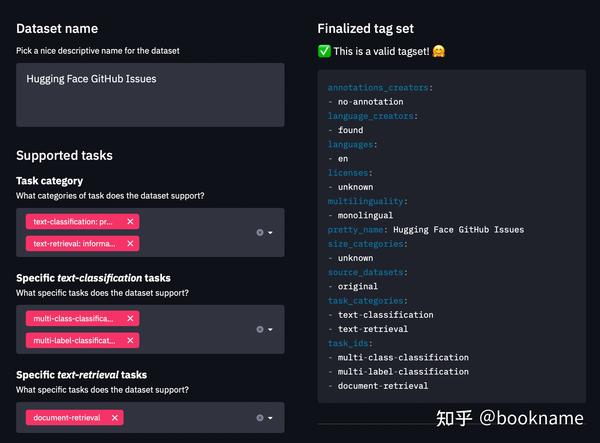
-
使用
datasets-tagging application 来创建YAML格式的数据集元数据标签。这些标签用来在Hugging Face Hub上进行检索操作,方便快速被他人检索发现。前面我们已经创建了自定义数据集,那么我们需要同时克隆datasets-tagging的repo,并且在本地运行,示例结果如下。
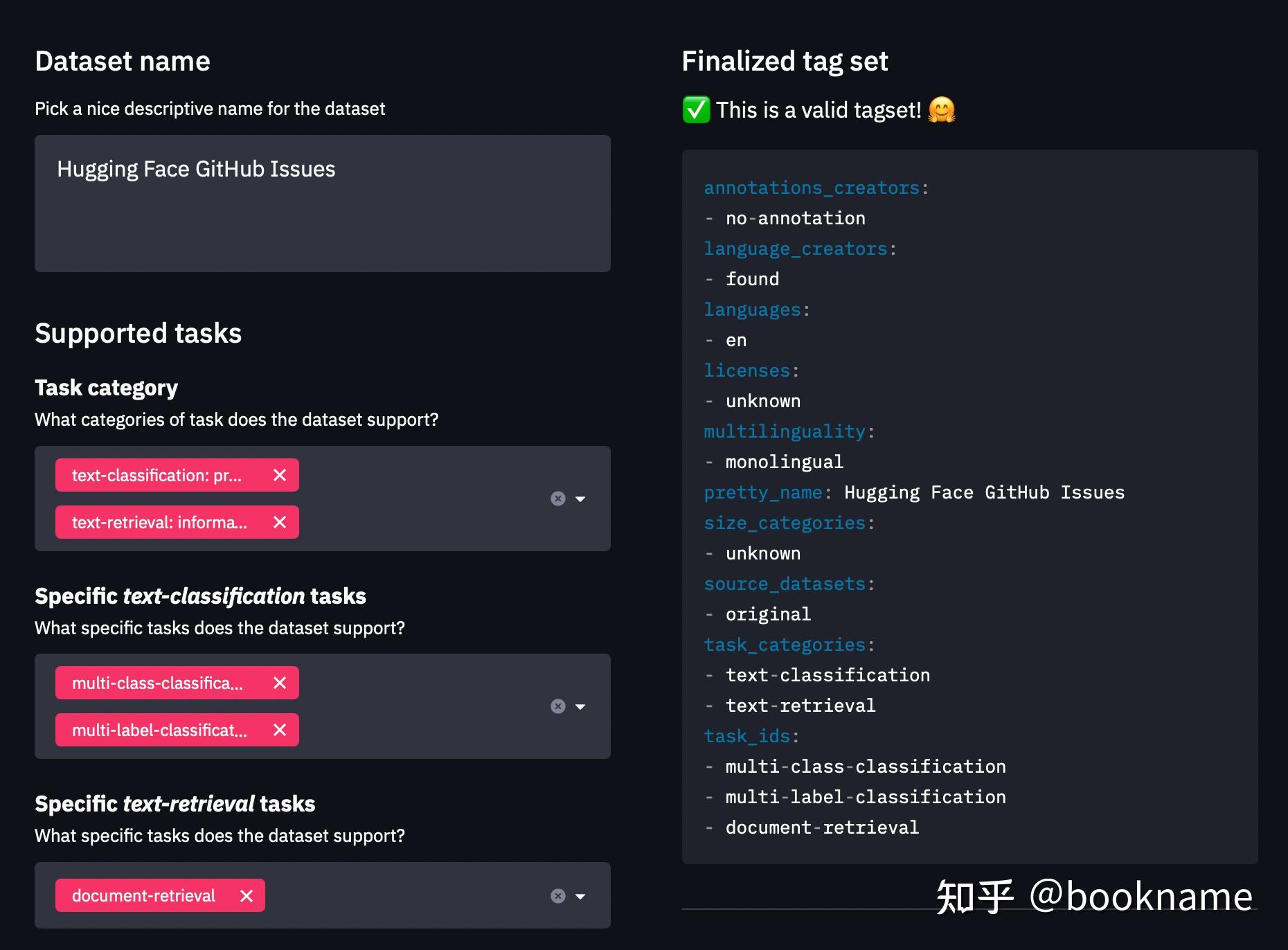
- 阅读 Datasets guide 来创建数据集卡片,并且使用该向导作为创建模板。
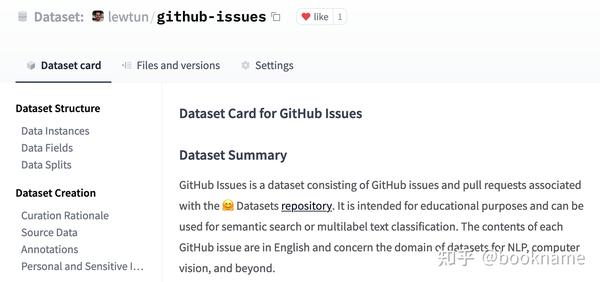
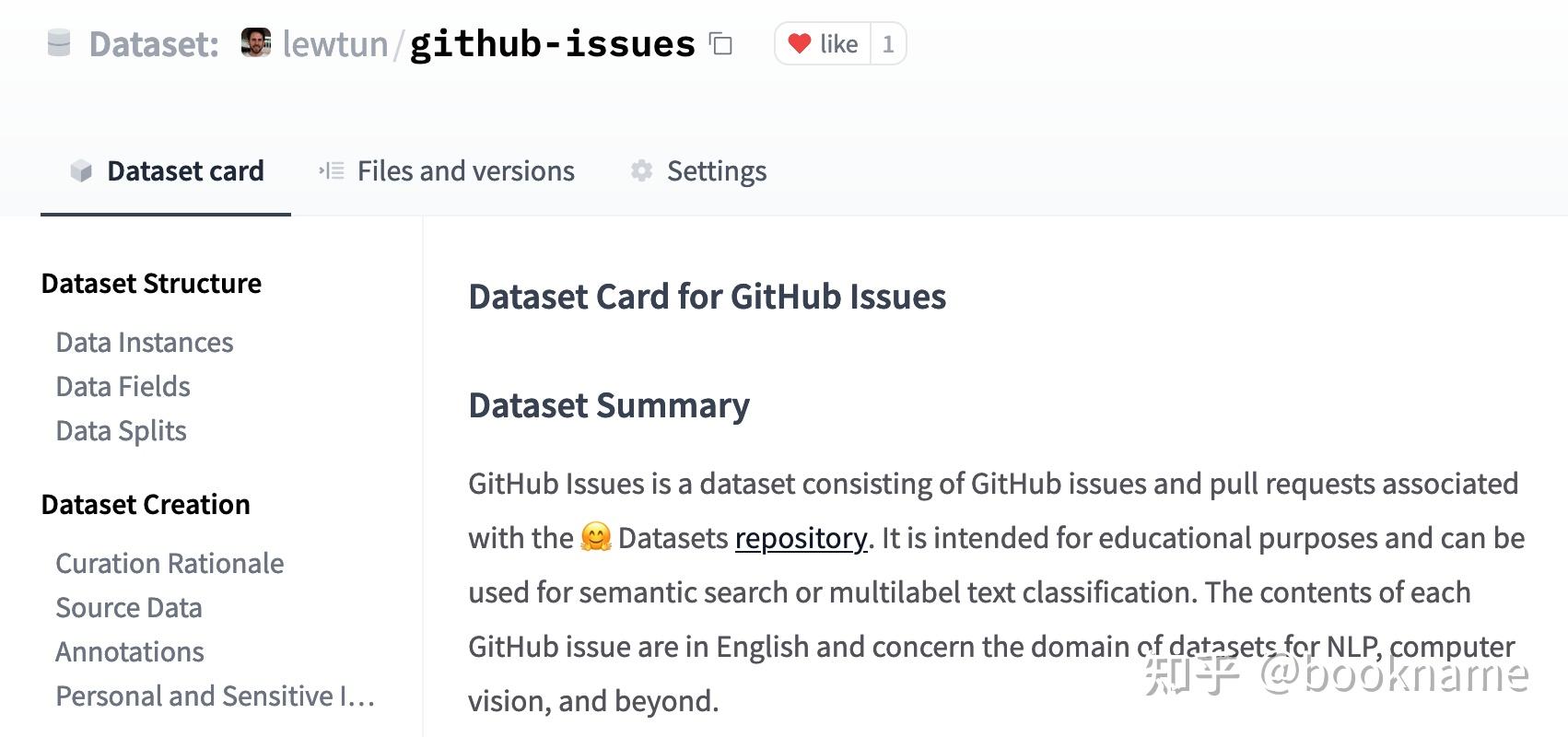
你也可以直接在Hub上创建
README.md
文件,并且会自动给出一个模板(在
lewtun/github-issues
数据集repo中)。下面是一个完整数据集卡片的示例。
动动手!分别使用dataset-tagging应用和 Datasets guide 来创建README.md文件
本节我们介绍了如何在Hub上创建数据集repo和文档卡片,以及如何在Hub上共享数据集。在下节中我们使用基于新创建的数据集构建一个语义搜索引擎,来搜索与问题最匹配的issus和评论。
基于FAISS的语义检索引擎
前面我们创建了Issues及其相关评论的数据集,下面我们基于该数据集,使用faiss引擎构建一个搜索引擎,实现快速匹配与检索问题相关的issues和评论。
使用embeddings来做语义搜索
学习了第一章 Chapter 1 ,我们知道基于Transformer架构的语言模型将一个文本片段中的每个token用一个embedding向量表示,当然也可以将这些embedding变量池化为一个单独的向量来表示整个句子、段落甚至文章。这些embedding向量可以用点积相似度(也可以是其他相似度计算方法)来计算文档之间的相似度。
在本节中我们使用embeddings是向量来开发一个语义搜索引擎。该引擎基于语义信息进行检索,比传统的基于关键词的检索方法更有优势。
加载和准备数据集
首先我们要从Hub上下载和缓存数据,这里采用Hugging Face Hub的函数来获取数据路径,如下所示。
from huggingface_hub import hf_hub_url
data_files = hf_hub_url(
repo_id="lewtun/github-issues",
filename="datasets-issues-with-hf-doc-builder.jsonl",
repo_type="dataset",
)
下面我们基于
data_files
得到的URL地址,通过
load_dataset()
函数加载数据。
from datasets import load_dataset
issues_dataset = load_dataset("json", data_files=data_files, split="train")
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
上面只加载train split数据(通过设置
load_dataset()
函数的参数
split="train"
),因此返回的结果是
Dataset
而不是
DatasetDict
。加载数据之后,首先需要把pull request数据和评论为空的数据过滤掉,因为这两个数据对问答检索没有用。
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 771
})
我们发现数据集有很多列,对于问答检索问题,我们关系的列有"title", "body", "html_url", "comments",因此我们只把数据集中这些数据保留下来,使用
Dataset.remove_columns()
来删除不需要的列。
columns = issues_dataset.column_names
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)
issues_dataset
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 771
})
为了创建我们的embedding向量,由于每个列的评论为一个列表,我们采用
explode
的方式扩增数据,也就评论列表的每个元素与
html_url, title, body
组成的新的一行。在Pandas中使用
DataFrame.explode() function
实现。下面我们看看如何实现。
issues_dataset
.set_format("pandas")
df = issues_dataset[:] 我们先看下评论数据长什么样子(有四个元素的列表),如下。
df["comments"][0].tolist()
['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
'cannot connect,even by Web browser,please check that there is some problems。',
'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
当我们
explode
上面的数据集时,我们期望每个列只有一个评论,如下。
comments_df = df.explode("comments", ignore_index=True)
comments_df.head(4)| html_url | title | comments | body | |
|---|---|---|---|---|
| 0 | https:// github.com/huggingface/ datasets/issues/2787 | ConnectionError: Couldn't reach https:// raw.githubusercontent.com | the bug code locate in :\r\n if data_args.task_name is not None... | Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
| 1 | https:// github.com/huggingface/ datasets/issues/2787 | ConnectionError: Couldn't reach https:// raw.githubusercontent.com | Hi @jinec,\r\n\r\nFrom time to time we get this kind of ConnectionError coming from the http:// github.com website: https:// raw.githubusercontent.com.. . | Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
| 2 | https:// github.com/huggingface/ datasets/issues/2787 | ConnectionError: Couldn't reach https:// raw.githubusercontent.com | cannot connect,even by Web browser,please check that there is some problems。 | Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
| 3 | https:// github.com/huggingface/ datasets/issues/2787 | ConnectionError: Couldn't reach https:// raw.githubusercontent.com | I can access https:// raw.githubusercontent.com /huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
结果很好!我们复制了除
comments
列之外的列,并且每一行只有一个评论。然后需要将Pandas格式转换为Datasets格式,如下。
from datasets import Dataset
comments_dataset = Dataset.from_pandas(comments_df)
comments_dataset
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 2842
}) 好的,我们得到了需要的数据!数据预处理还真是花时间呀!
动动手!除了上面的操作方法,还可以使用Dataset.map()方法进行comments列的处理。大家可以参考链接 “Batch mapping” 。
现在每行一个评论了,下面我们创建新列
comments_length
来看下每个评论包含多少单词。
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())}
)
下面我们过滤评论单词很少的评论,因为这些评论大多是类似
cc@lewtun
或者
"Thanks!"
的没有太多含义的评论,对问答搜索没有什么帮助,因此将它们过滤。另外过滤评论使用的单词长度没有太多限制,这里设置为15个单词,效果也不错。
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
comments_dataset
Dataset({
features: ['html_url', 'title', 'comments', 'body', 'comment_length'],
num_rows: 2098
})
最后再将
title, description, commets
一起合并为一个text span。下面使用
Dataset.map()
来实现。
def concatenate_text(examples):
return {
"text": examples["title"]
+ " \n "
+ examples["body"]
+ " \n "
+ examples["comments"]
comments_dataset = comments_dataset.map(concatenate_text) 基于上面清洗过的数据,我们计算embedding向量。
创建文本的embedding
在第二章
Chapter 2
我们知道可以使用
AutoModel
类来获取token的embedding向量。我们需要在 Model Hub上寻找合适的模型。幸运的是,已经有人做了这种模型相关的工作,这个模型称为
sentence-transformers
,是专门用来生成embedding的。在该模型的文档
documentation
,我们可以找到适合需求的模型(即非对称语义检索问题,搜索语句很短,被检索语句很长)。我们在
model overview table
列表中选择了
multi-qa-mpnet-base-dot-v1
模型来作为语义检索模型。下面加载模型。
from transformers import AutoTokenizer, AutoModel
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt) 为了加速获取embedding向量的速度,我们将模型加载到GPU上,如下所示。
import torch
device = torch.device("cuda")
model.to(device)
前面已经介绍了,我们需要为每个Github issue获取一个单独的向量,因此需要池化或平均化我们的token embedding向量列表。一个常用做法是使用
[CLS]
token对应的embbding作为issue的向量表示,下面我们从最后的隐状态张量中获取
[CLS]
token的embedding向量。
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0] 下面,我们创建一个辅助函数来进行四个操作:
- 文档列表分词
- 导入GPU
- 输入模型
- 获取CLS向量
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output) 我们使用一个数据进行测试,观察结果。
embedding = get_embeddings(comments_dataset["text"][0])
embedding.shape
torch.Size([1, 768])
从结果可知,输出结果符合预期(是一个768维的向量!)下面我们使用
Dataset.map()
函数来批量获取embedding向量,如下所示。
embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
) 注意到上面代码,将embeding格式转化为Numpy数组格式,是因为在使用FAISS进行索引的时候要求是该格式。
使用FAISS进行高效相似度检索
通过上节的处理,我们得到了embedding向量数据集,该数据集被用来进行相似度检索。我们这里使用FAISS工具(FAISS是
Facebook AI Similarity Search
的缩写),该工具是一个高效的密集数据检索工具(就是为了embedding检索用的)。
FAISS的基本思想是通过创建一个名为
索引
的数据结构,来实现对embeding的快速检索,在
Dataset
上创建FAISS索引so easy,只需要调用
Dataset.add_faiss_index()
并指定列名即可(真是so easy)。
embeddings_dataset.add_faiss_index(column="embeddings")
添加FAISS索引之后,然后可以使用
Dataset.get_nearest_examples()
函数进行问题检索了。下面我们使用一个例子进行测试。
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
question_embedding.shape
torch.Size([1, 768]) 现在我们获得了检索问题的embedding向量,然后使用检索函数来获取相似issue的embedding向量,如下。
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)
Dataset.get_nearest_examples()
函数返回两个记过,第一个是问题与匹配issue的相似度得分,另一个是返回的issue,下面我们将结果转化为pandas格式,并打印出来观察结果。
import pandas as pd
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True) 下面我们按照相似度得分由高到底的顺序,查看问题检索结果。
for _, row in samples_df.iterrows():
print(f"COMMENT: {row.comments}")
print(f"SCORE: {row.scores}")
print(f"TITLE: {row.title}")
print(f"URL: {row.html_url}")
print("=" * 50)
print()
COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
SCORE: 25.505046844482422
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
You can now use them offline
\`\`\`python
datasets = load_dataset("text", data_files=data_files)
\`\`\`
We'll do a new release soon
SCORE: 24.555509567260742
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
----------
> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
\`\`\`python
load_dataset("./my_dataset")
\`\`\`
and the dataset script will generate your dataset once and for all.
----------
About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
cf #1724
SCORE: 24.14896583557129
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
> 1. (online machine)
> import datasets
> data = datasets.load_dataset(...)
> data.save_to_disk(/YOUR/DATASET/DIR)
> 2. copy the dir from online to the offline machine
> 3. (offline machine)
> import datasets
> data = datasets.load_from_disk(/SAVED/DATA/DIR)
SCORE: 22.893993377685547
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: here is my way to load a dataset offline, but it **requires** an online machine
1. (online machine)
\`\`\`
import datasets
data = datasets.load_dataset(...)
data.save_to_disk(/YOUR/DATASET/DIR)
\`\`\`
2. copy the dir from online to the offline machine
3. (offline machine)
\`\`\`
import datasets
data = datasets.load_from_disk(/SAVED/DATA/DIR)
\`\`\`