|
|
|


强化学习中sarsa算法是不是比q-learning算法收敛速度更慢?
关注者
38
被浏览
27,018
4 个回答

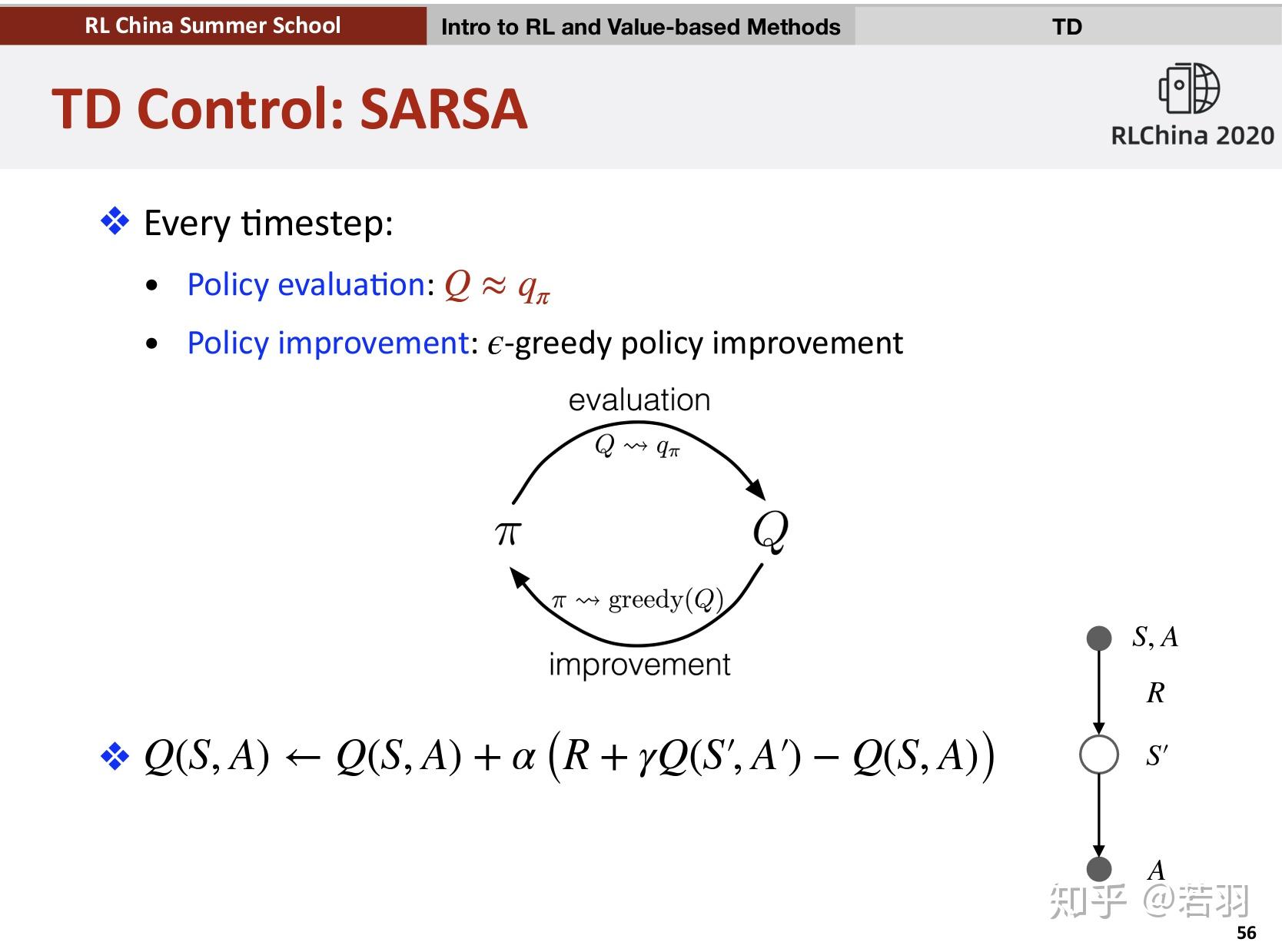
首先明确一下SARSA和Q-Learning和区别在哪里。
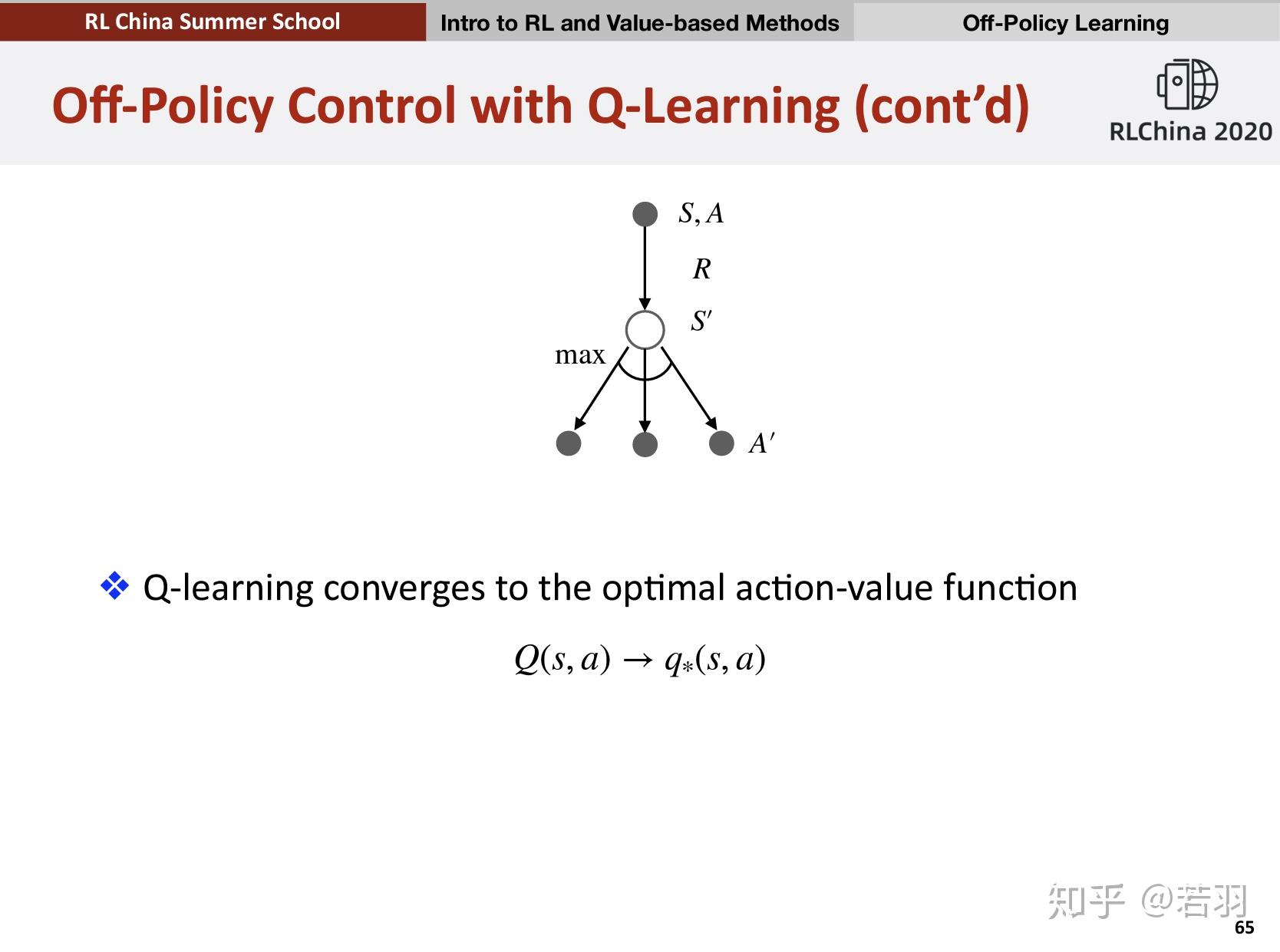
它们都是Temporal Difference方法,不过SARSA是一种on-policy方法,Q-Learning是一种off-policy方法。On-policy方法在一定程度上解决了exploring starts这个假设,让策略既greedy又exploratory,最后得到的策略也一定程度上达到最优。Off-policy方法就更加直接了,分别在策略估计和策略提升的时候使用两种策略,一个具有探索性的策略专门用于产生episode积累经验,称为behavior policy,另一个则是更具贪婪性,用来学习成为最优策略的target policy。




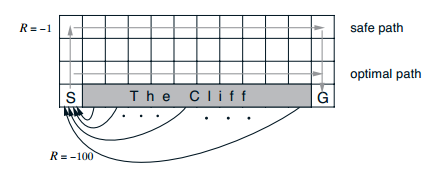
那我们就举Sutton书上的Cliff Walking例子来比较一下这两个方法,看看到底收敛速度如何?


在实验中,SARSA和Q-Learning的 \varepsilon -greedy 策略的 \varepsilon 都取0.1,都经过1000次episodes训练,得到如下效果。

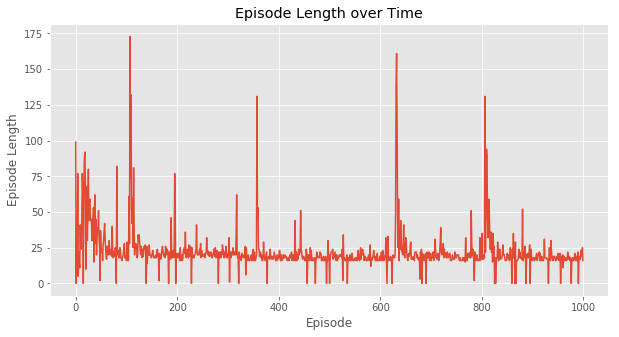
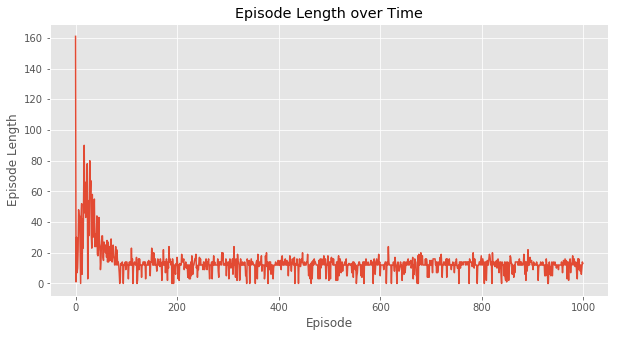

这是每次episode的耗费的时间,可以看出在一开始训练,两种方法都完成一次episode都比较耗时,但Q-Learning在不到100次episode以后基本稳定在每次episode20毫秒左右。而SARSA由于算法的保守性,会有一点几率采取random policy,所以可以看到,即使已经“收敛”,但还是会因为采取了新action导致episode变长。
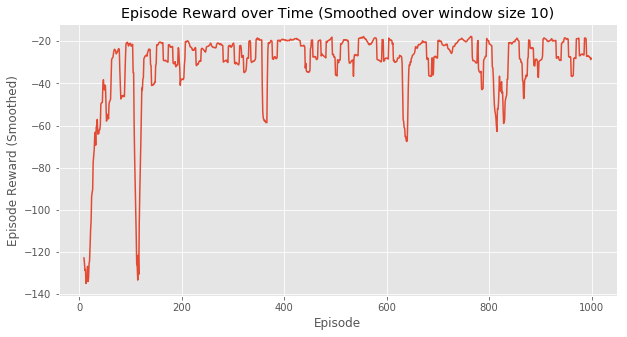
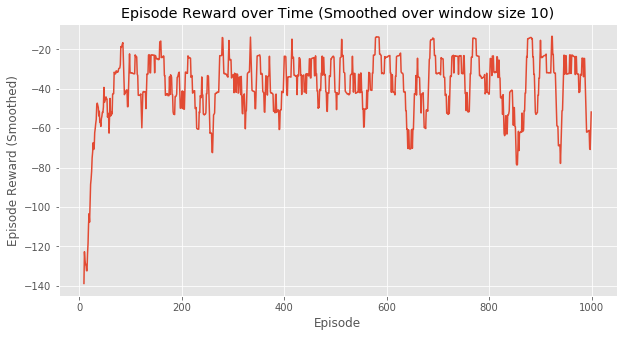
这两个图的对比就可以说明一个问题,SARSA是一个保守点的算法,而Q-Learning则更大胆,反应在实验中,就是Q-Learning会偏向于走在悬崖边上,而SARSA会走在悬崖靠上一点的路径。
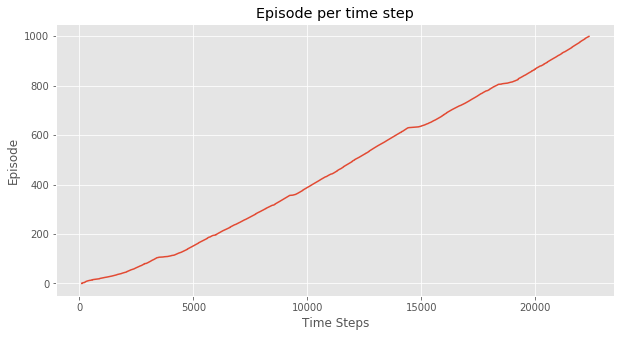
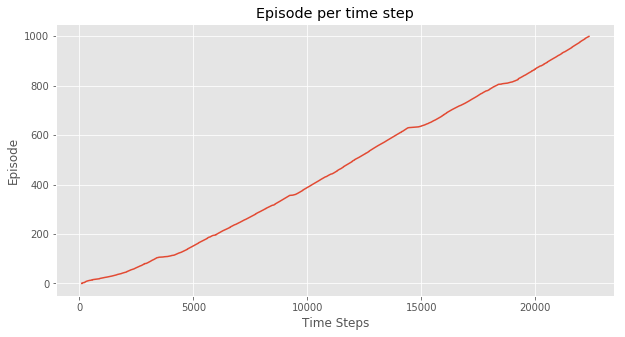
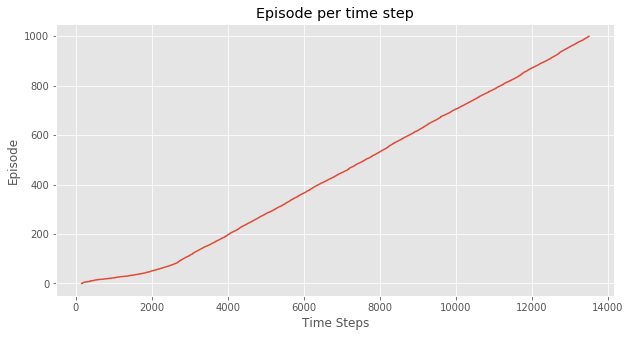

直观地,完成1000次episode,SARSA显然花的时间更多。换句话说, SARSA收敛速度会更慢 。但从结果上看,达到最优策略并不需要1000次episode的训练,100次左右就够了,但这个时间其实相差很小。
欢迎关注我的专栏:

先说结论,是的。
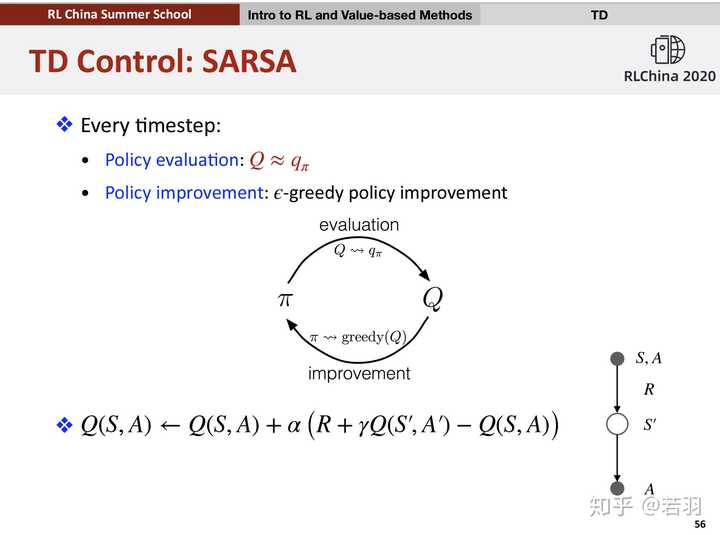





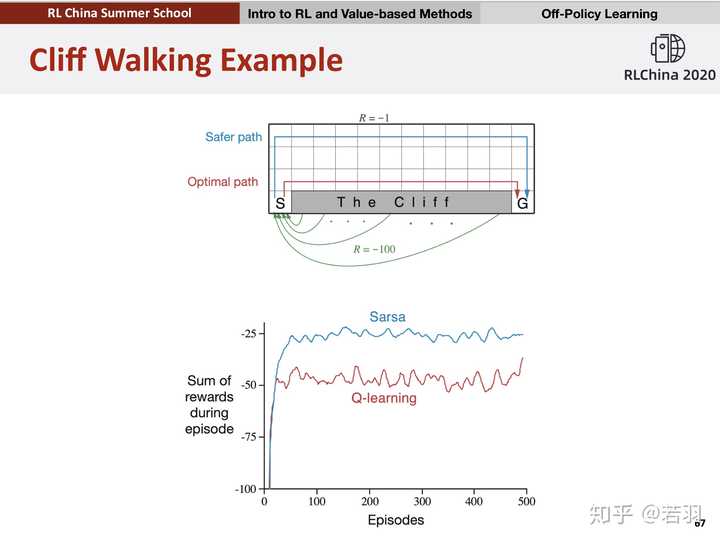
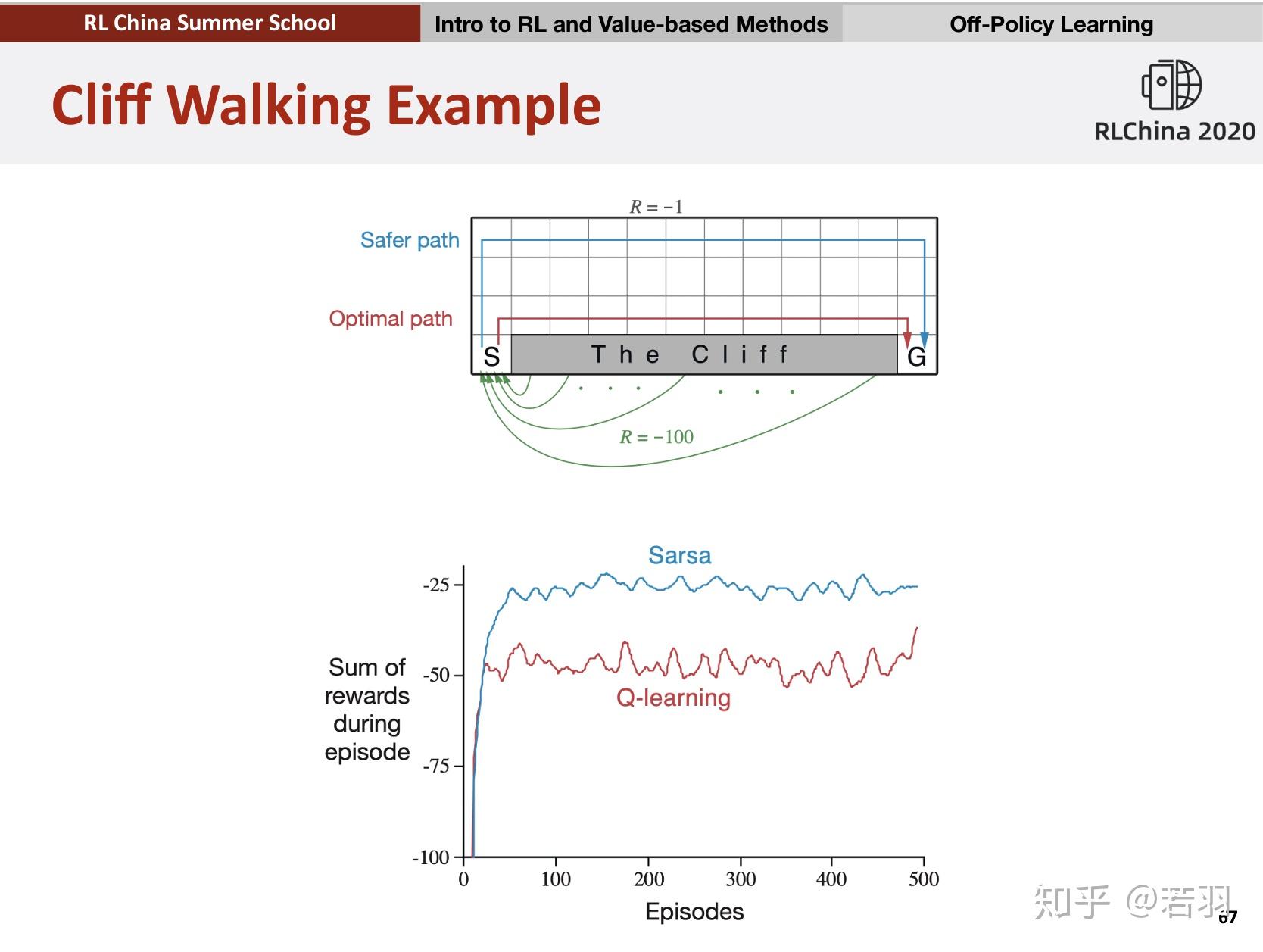
这是最近某个强化学习讲座的课件,北大卢宗青老师用的Richard Sutton书里的例子,saras是on-policy学习,q-learning是off-policy学习。sarsa的学习比较保守稳健,每一个episode和每个episode的每个step都会执行episilon-greedy探索;q-learning则倾向于利用经验的累积,学习到最优策略。在悬崖行走曲线上,q-learning方法是optimal的,但会有风险,sarsa方法是安全的,但学习的episode曲线也被拉长了。