


学习建模-个人信用风险评估模型实例


一、项目背景
最近偶然看到一个金融数据建模的比赛,刚好近期工作内容就在金融信用方向,所以对这个比较感兴趣,于是工作之余找来数据做一些研究。项目是银联商务公司联合狗熊会(有人听过这个组织么?)共同组织的一次金融数据建模比赛,比赛数据由银联商务公司提供。项目的具体目的是根据输入数据来预测用户是否会发生贷款逾期行为。
二、数据简介
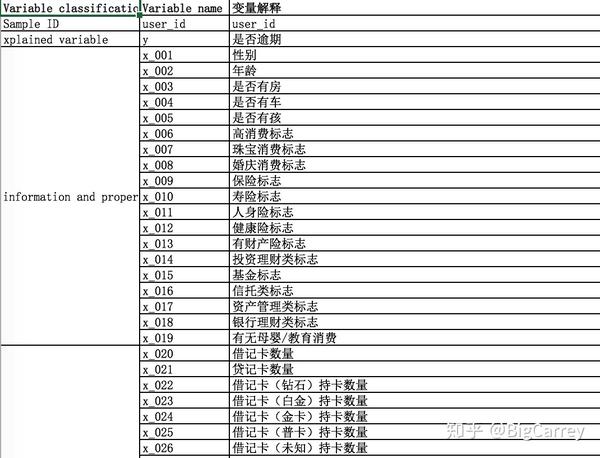
官方提供了一份CSV格式的数据,和一份数据字典。数据集中共有201个字段,除去没有实际意义的用户ID字段,和我们要预测的逾期标签,剩下的输入变量共有199个,包括了身份信息及财产状况、持卡信息、交易信息、放款信息、还款信息、申请贷款信息6个大类。
数据集的结构和内容如下(变量太多,只截取前几行):

三、数据探索
面对任何业务、任何数据,第一时间要做的工作就是数据探索,从某种意义上来说,数据探索可以说是建模前期最重要的工作。一般来讲,数据探索主要包括数据观察、数据质量分析、探索性数据分析等部分。笔者曾经专门写文章探讨了关于数据质量分析的内容,详见: 数据分析师必修课(1)——数据质量评估 ,这里不再展开。
- 数据观察
第一步首先对数据集整体情况进行一些简单的观察,构建对数据集的感官认识。


可以看到,在数据集中,比赛官方已经给出了用户逾期标签,也就是说已经明确的定义了样本的“好”“坏”标签,其中,有逾期行为的标志为“1”,即怀样本;无逾期行为的标志为“0”,即好样本。我们不在需要对数据进行样本好坏标签的定义,节约很多工作量。
另外,user_id字段对建模来说是没有意义的,可以删除。删除后剩余变量199个。
# 导入相关库包
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import seaborn as sns
import numpy as np
%matplotlib inline
sns.set()
# 载入数据
df = pd.read_csv('model_sample.csv')
print('Data size: ',df.shape)
print('Bad samples:', df['y'].sum())
print('Good samples:', df.shape[0] - df['y'].sum())

数据集约有11K左右的样本,其中好坏样本比例约为4:1。从样本总量以及坏样本数量上来说,完全能够满足建模的需求。需要注意的是:
- 一般来说,在进行信用风险建模的时候,坏样本量最好能达到1K以上;
- 样本不均衡问题是信用建模时最经常遇到的问题,如果好坏样本比例达到10:1甚至更高,则必须采取一些措施处理不均衡问题。
本例中,由于好坏样本数量基本在同一数量级,可以不采取措施。
另外一个常见问题是数据缺失问题,可以说,数据缺失问题几乎是任何建模工作必然面临的问题。对此进行一些观察:
# 观察数据缺失情况
ll = {}
for cl in df.columns:
ll[cl] = df[cl].isnull().sum() / df[cl].shape[0]
df_null_rate = pd.DataFrame(ll, index=['rate'])
df_null_rate.T.to_csv('null_rate.csv')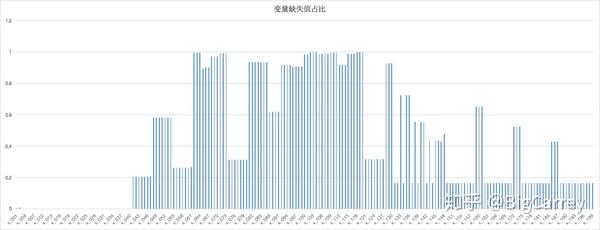

数据集中存在大量的缺失值,有48个字段的缺失值甚至达到了90%以上。对于这些缺失值过多的变量,后续处理的时候可以考虑删除。
- 单变量分析
数据探索的第二步是单变量分析,在单变量分析过程中,我们会对样本数据的缺失值、错误值和异常值情况有更深入的了解。同时,对单一变量分布形态的观察也为后续特征工程部分的工作提供基本的依据。
在本例中,我主要对一些关键变量的分布情况进行观察:
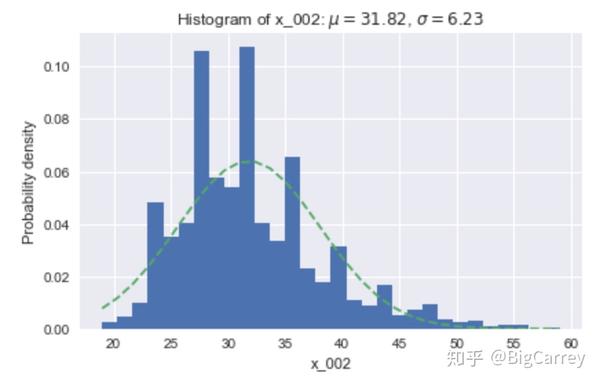

用户年龄分布基本符合正态分布。
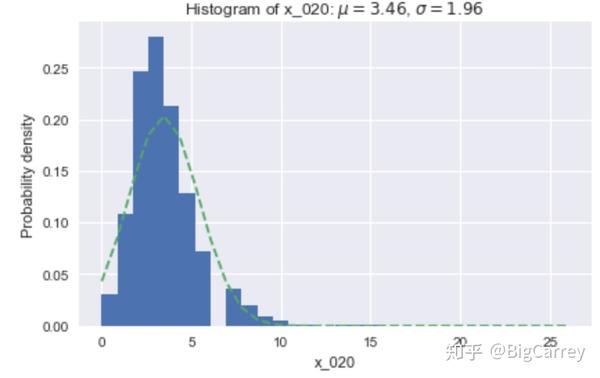

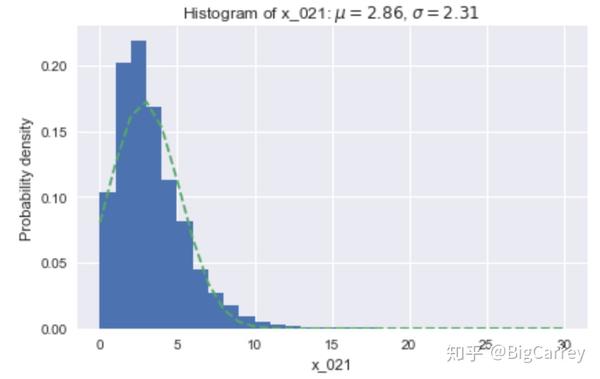

用户持有卡片数量基本符合正态分布,略微右偏。
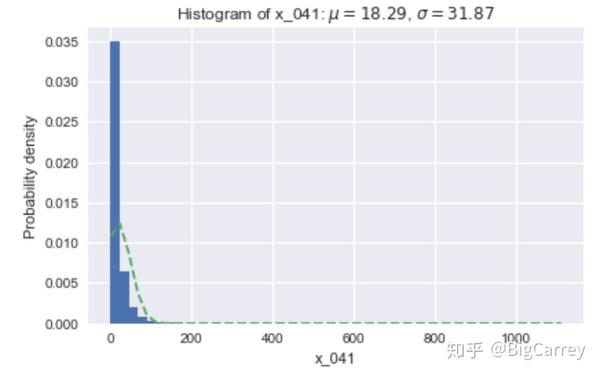

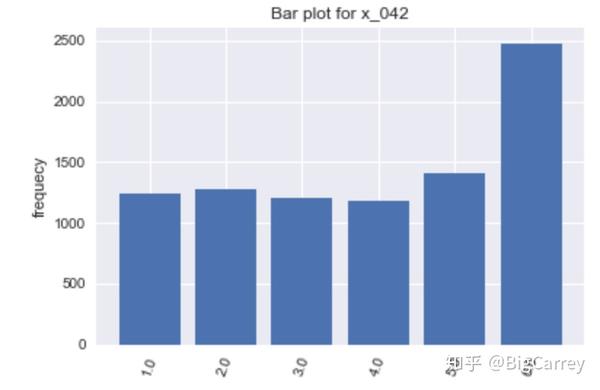

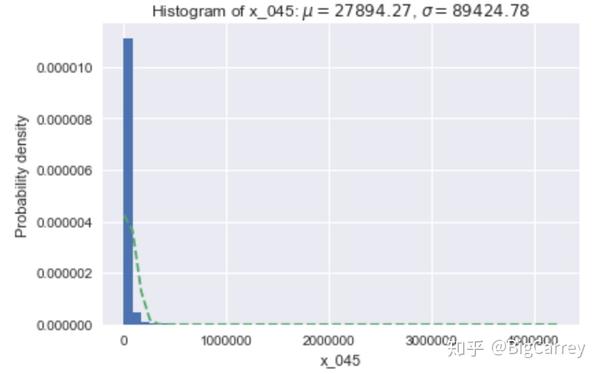

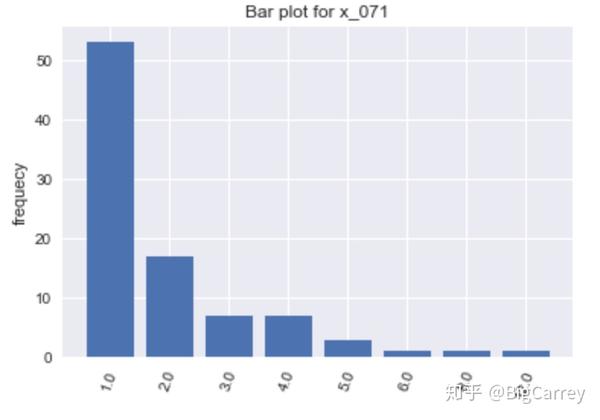

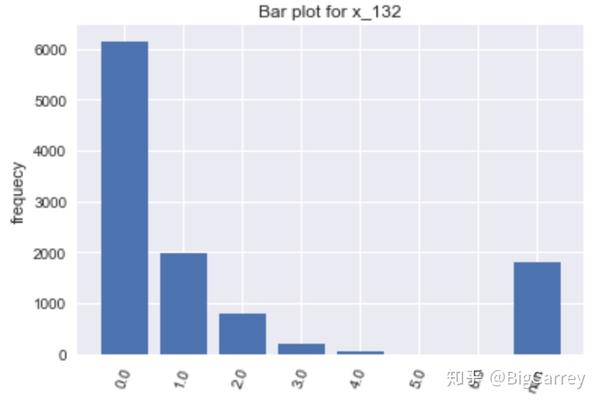

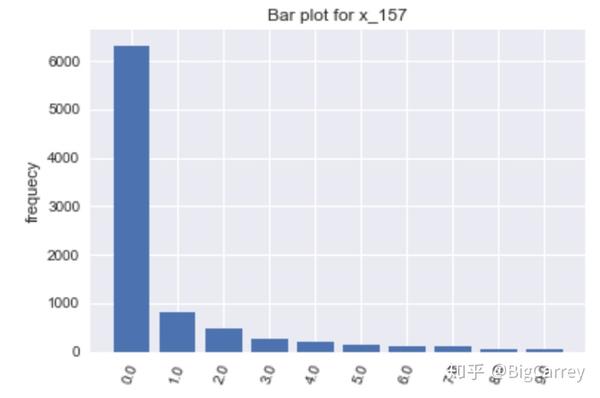

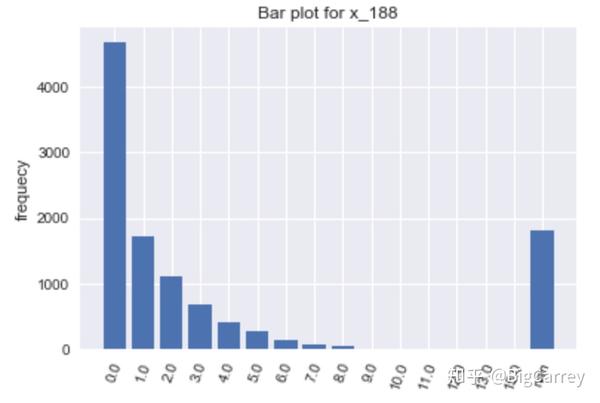

在上图中可以清楚的看到,有很多变量不符合正态分布。除了年龄和持卡数量这些变量,其他大多数变量都是长尾右偏分布,但这些均符合常识逻辑。另外,存在部分变量的取值虽然是离散的,但取值范围较大,在后续处理时应当做连续变量处理。
以上仅是所有变量观察中很小的一部分,其余变量的观察情况不再展开。实际上,单变量分析是整个数据建模的核心部分,也是最耗时、最需要耐心和坚持的环节。
四、特征工程
业界有一句广为流传的话:
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
由此可以看出特征工程在建模中的重要意义和核心地位。基于前面的数据探索工作,我对数据集中存在的问题有了大致的掌握,接下来逐一处理。
(一)首先进行缺失值处理
缺失值处理是特征工程阶段重点要解决的核心问题之一,也是难点之一。其复杂之处在于引起缺失值的情况多种多样、可采用的处理手段多种多样、不同算法对缺失值的敏感程度也有很大差异。
引起缺失值的情况可以分为以下三类:
- 随机缺失(Missing At Random, MAR)
- 完全随机缺失(Missing Completely At Random, MCAR)
- 非随机缺失(Missing At Non-Random, MANR)
处理缺失值的常用手段有:删除缺失值、统计量填充、特殊值填充、保留缺失值等。
在处理缺失值的时候,要综合考虑各类因素然后选择合适的处理方式。首先要考虑的是引起数据缺失的原因,也就是数据缺失对应的实际业务意义。其次要考虑算法对缺失值的敏感程度。最后要考虑不同的处理方式带来的成本效益影响。根据实际经验,有一些处理缺失值的简单判别原则可供参考:
- 缺失值占比高于90%(一个经验上的临界值)的变量通常对区分目标变量的贡献度不大,可考虑删除该变量;
- 相较于线性回归、逻辑回归等算法,基于决策树的算法对于缺失值的敏感度更低,存在一定缺失值的情况下也能适用;
- 基于业务经验来判断缺失值的产生原因,并据此使用具有实际业务意义的特定值来填充往往是最好的处理手段;
在本例中,首先参考数据探索阶段得出的缺失值占比情况,把占比高于90%的变量进行删除。剩余的变量,通过人工观察和业务逻辑分析,对不同情形的缺失值采用不同的特定值填充。这里不做展开。
删除后剩余变量154个。


需要说明的是,删除缺失值占比较高的变量这一动作不是必须的,甚至某些时候是不推荐的。因为任何形式的变量删除都一定会导致信息的减少,理论上可能会削弱模型的最终效果。只有在删除变量的成本较低而收益较高的时候才是合适的选择。
(二)同质化处理
每个输入变量都可以看做是区分预测目标事件的一个特征,因此如果某一变量大部分观测都有同样的特征,或者说一个输入变量大部分的值都是相同的,那么这种特征或者说这个输入变量就不能很好的用来区分目标事件,称之为同质性较高。一般临界点定在90%。
变量同质化处理的逻辑和缺失值是类似的,高同质性的变量对于区分目标时间的贡献通常较小,为了简化模型复杂度、减轻计算负担,可以考虑删除高同质性的变量。临界值的选择可以人为定义,一般的经验值为90%,这里我选择90%作为临界值进行删除。


删除后剩余变量133个。
同样的,同质化处理不是必须的,需综合考虑决定。
(三)特征筛选
完成数据预处理之后,数据已经基本符合建模的需求,理论上说已经可以开始进行建模工作。但通常在建模之前还有一步工作要做,即特征筛选。特征筛选的方法有很多,总体来说可以分为三类:过滤式、包裹式和嵌入式。(《机器学习》 周志华)
在本例中由于变量数量较多,一般不推荐直接采用逐步回归(包裹式)的方法进行变量筛选,所以此处我们重点讨论过滤式(Filter)特征筛选方法,常见的手段有:基于方差的特征筛选、基于IV值的特征筛选、基于相关系数的特征筛选等。本例中主要使用了基于IV值和基于皮尔森相关系数的特征筛选方法。
- 基于IV值的特征筛选
IV值的全称是information value,中文的就是信息量或信息值,其主要作用就是当我们在用决策树或逻辑回归构建分类模型时对变量进行筛选。IV值就是衡量自变量的预测能力的大小,与其相似的还有信息增益、基尼系数等。
由于各个变量的量纲和取值区间存在很大的差别,通常会对变量的取值进行分箱并计算 证据权重 WOE值(weight of evidence) ,从而降低变量属性的个数,并且平滑的变量的变化趋势。接下来,在此基础上计算 信息价值IV(information value) , 一般我们选择 IV值大于0.02的那些变量进入模型。
IV值的计算公式:
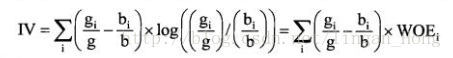

其中证据权重WOE是用来衡量变量某个熟悉的风险的指标,WOE的计算公式:
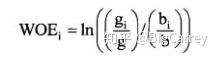

IV值越大表示好坏客户在该变量上的分布差异就越大,也就是该变量的区分能力就越好。
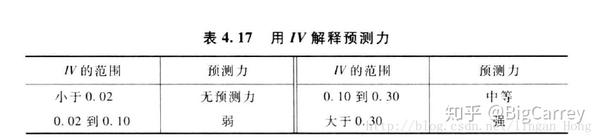
对于IV值的解释预测力

- 数据分箱
在计算IV值的时候,有一个前序步骤,就是数据分箱。分箱的主要目的是平滑变量的变化趋势,使之对异常值不敏感,同时也消除各个变量量纲之间的差异,并使取值区间尽量一致。对于逻辑回归或者基于决策树的算法来说,数据分箱都是十分必要的,也往往能够给模型带来正向影响。
变量的分箱也有多种数学方法:等宽分箱、等深分箱、卡方分箱、最优分箱(并非真正意义上的最优,仅是一个名称)等。等宽分箱通常要求变量近似于均匀分布,在实践中很少用到。
在进行分箱、IV值计算操作时,R语言作为统计语言的优势就非常明显,smbinning包能非常方便的实现最优分箱并计算IV值。我先使用该包计算出各变量的IV值,然后进行筛选。
sumivt=smbinning.sumiv(df,y="y")
sumivt # Display table with IV by characteristic
par(mfrow=c(1,1))
smbinning.sumiv.plot(sumivt,cex=1) # Plot IV summary table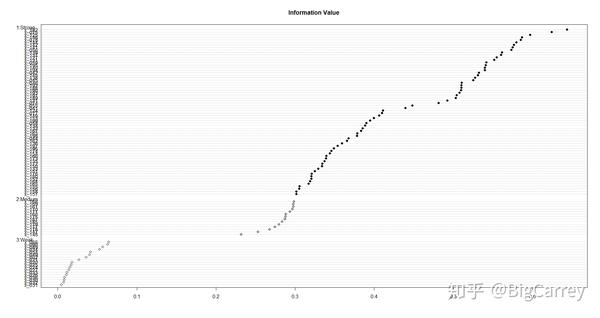

可以看到,smbining包已经帮我们对变量的IV值进行排序和分组,我们把对应weak这一组的变量删除,其他变量保留。删除后剩余变量115个。

需要注意的是,smbinning理论基础是构造条件推断树ctree(conditional inference trees),并把ctree树节点当成bin的分割点。此函数对于连续变量的分bin效果比较好,而对于离散变量分bin就不尽人意了,往往会出现“No Bins”或者只分两三bin的情况。在本例中,许多变量其实不是连续变量,而是多值离散变量,这种情况应用smbining分箱不是特别合适。因此,在完成第一步特征筛选之后,我们转用卡方分箱对剩余的变量进行分箱操作。这在后面进行介绍。
- 基于皮尔森相关系数的特征筛选
在理想状态下,我们希望输入到模型的数据都是相互独立的,但实际中往往多个变量之间并不是完全独立,而是存在一定的相关性。自变量的高相关性(或者叫共线性)会引起一系列问题,最明显的是会导致预测结果不佳,尤其对于线性回归类的算法。对基于决策树的算法来说,自变量相关性的影响没那么大,但高度相关的变量对学习器效果的贡献基本是一样的,因此剔除高相关变量也能够简化计算。本例中,我使用皮尔森相关系数作为计算指标:
###绘出皮尔森相关系数图谱
def plot_pearson(data):
通过皮尔森相关性图谱找出冗余特征并将其剔除;
同时,可以通过相关性图谱进一步引导我们选择特征的方向。
小于0.4显著弱相关,0.4-0.75中等相关,大于0.75强相关
colormap = plt.cm.viridis
plt.figure(figsize=(70,70))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
pearson_coef = data.corr()
sns.heatmap(pearson_coef,linewidths=0.1,vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True)
return pearson_coef
pc = plot_pearson(df_Gi_order)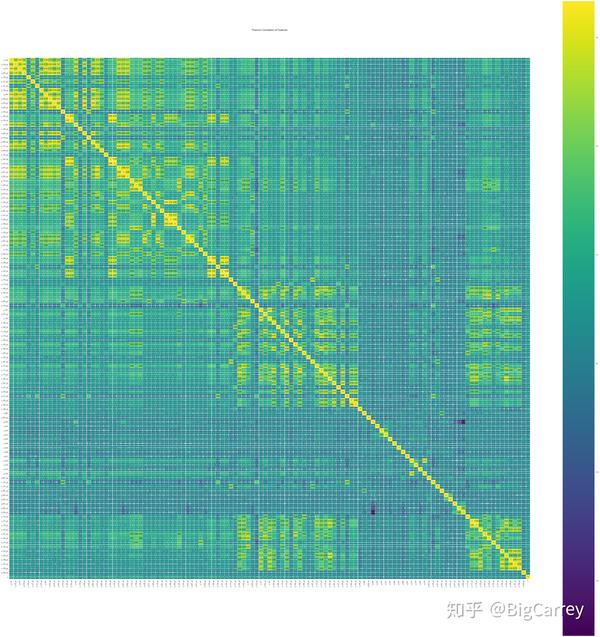

这里选择0.75作为阈值,在相关系数高于0.75的变量组合中,我们保留IV值最大的变量,其余变量删除。删除后剩余变量67个。
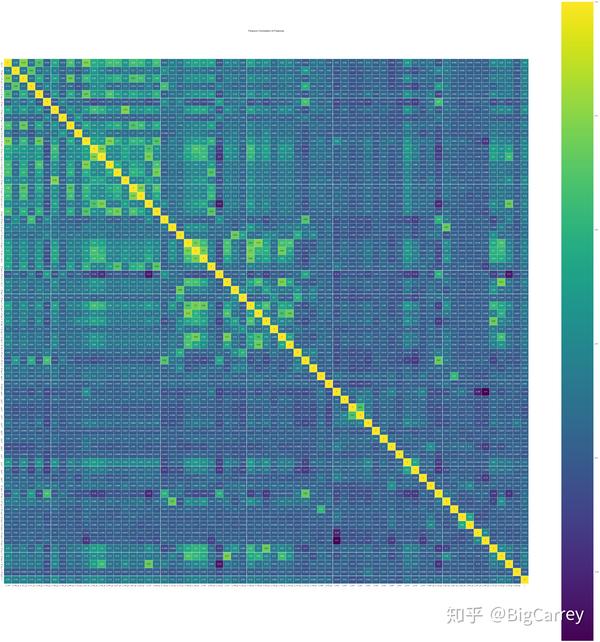

- 卡方分箱
前面计算IV值的时候提到,smbinning分箱的算法对于非连续型变量的效果不是特别好。因此,对于剩余的变量,我们使用ChiMerge(卡方分箱)方法分箱,并用分箱后的序号替代变量原有的取值。对于取值数量较少的离散型变量,可以当做类别变量处理,不进行分箱操作。Python中关于数据分箱并没有成熟的工具可供使用,这里我使用了知友 @Ricky翘 实现的卡方分箱代码,并做了一定的改动,增加了最小样本数量的配置功能。有需要的同学可以私信我获取代码。
五、建模调参
完成以上所有特征工程的工作后,即可正式进入建模的环节了。首先要考虑的第一个问题是算法选择。在本例中,因为项目不要求建立评分卡模型,而是追求更好的预测效果。因此我选择GBM算法来构建模型。
Gradient Tree Boosting (别名 GBM, GBRT, GBDT, MART)是一类很常用的集成学习算法,在KDD Cup, Kaggle组织的很多数据挖掘竞赛中多次表现出在分类和回归任务上面最好的performance。同时在2010年Yahoo Learning to Rank Challenge中, 夺得冠军的LambdaMART算法也属于这一类算法。因此Tree Boosting算法和深度学习算法DNN/CNN/RNN等等一样在工业界和学术界中得到了非常广泛的应用。
GBM算法的主要优点如下:
- 对缺失值、异常值不敏感;
- 对自变量共线性不敏感;
- 基于决策树的分类算法,不要求自变量和因变量之间存在线性关系,因此很多情况下效果比逻辑回归要好;
- 作为集成学习算法,在大部分情况下预测效果优于单一学习器的效果;
Python的Sklearn包中的GradientBoostingClassifier分类器就是GBM算法的良好实现,因此,我使用Sklearn来完成建模工作。
# 导入机器学习包
import sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import f1_score
from sklearn.cross_validation import train_test_split
df_final = df_left
x = df_final.drop(['y'], axis = 1)
y = df_final.y
# 数据集分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)完成数据集的分割后,即可开始进行模型训练和参数调优。实际上,建模的大部分工作就是在进行参数调优(也叫超参数调优)。GMB算法的各参数含义可参见这篇文章: GBM参数 - CSDN博客
就目前来看, 大部分集成算法的参数调优工作还没有成熟的工程方法可以使用,更多是依赖经验来进行, 这是另一个比较复杂的话题,这里不展开。对于GBM算法的参数调优,前人有一些经验可供参考: Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
总结其大致顺序如下:
- 选择一个相对来说 稍微高一点的learning rate( 一般默认的值是0.1),决定 当前learning rate下最优的决定树数量;
- 接着 调节树参数 来控制过拟合;
- 降低learning rate ,同时会增加相应的决定树数量使得模型更加稳健;
下面开始进行建模,首先设定learning_rate ,然后使用格搜索的方式找到最优的n_estimators 参数(决策树数量)。这里提一句,在进行参数优化时,必须指定一个评价函数,所有的参数优化都是朝着评价函数结果更优的方向进行。本例属于二分类作业,最常用也比较科学的评价函数主要是AUC和Gini系数,这里选择AUC作为评价函数:
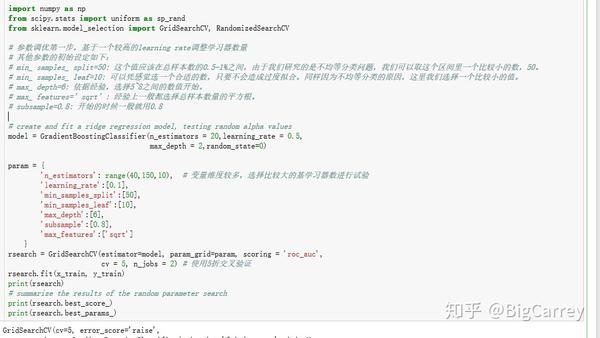

输出结果如下:
GridSearchCV(cv=5, error_score='raise',
estimator=GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
presort='auto', random_state=0, subsample=1.0, verbose=0,
warm_start=False),
fit_params=None, iid=True, n_jobs=2,
param_grid={'n_estimators': range(40, 150, 10), 'learning_rate': [0.1], 'min_samples_split': [50], 'min_samples_leaf': [10], 'max_depth': [6], 'subsample': [0.8], 'max_features': ['sqrt']},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring='roc_auc', verbose=0)
0.7841173853520281
{'learning_rate': 0.1, 'max_depth': 6, 'max_features': 'sqrt', 'min_samples_leaf': 10, 'min_samples_split': 50, 'n_estimators': 60, 'subsample': 0.8}考虑到结果的稳定性,这里配置了CV参数为5,即五折交叉验证。得到最终AUC结果为:0.78412,对应的n_estimators参数值为60。
接下来,固定n_estimators参数为60,然后调节min_samples_split参数(用于控制过拟合):


输出如下:
GridSearchCV(cv=5, error_score='raise',
estimator=GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
presort='auto', random_state=0, subsample=1.0, verbose=0,
warm_start=False),
fit_params=None, iid=True, n_jobs=2,
param_grid={'n_estimators': [60], 'learning_rate': [0.1], 'min_samples_split': range(20, 401, 10), 'min_samples_leaf': [10], 'max_depth': [6], 'subsample': [0.8], 'max_features': ['sqrt']},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring='roc_auc', verbose=0)
0.7870443837906562
{'learning_rate': 0.1, 'max_depth': 6, 'max_features': 'sqrt', 'min_samples_leaf': 10, 'min_samples_split': 360, 'n_estimators': 60, 'subsample': 0.8}可以看到AUC值有明显的提升,具体数值达到了0.78704,此时对应的最佳min_samples_split参数应为360。
继续,固定上述参数调节min_samples_leaf参数:
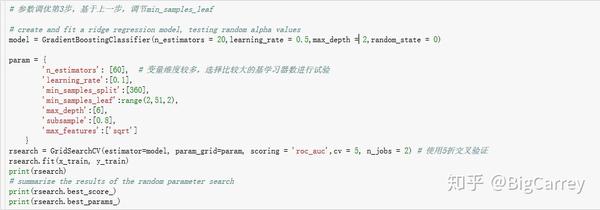

输出结果:
GridSearchCV(cv=5, error_score='raise',
estimator=GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
presort='auto', random_state=0, subsample=1.0, verbose=0,
warm_start=False),
fit_params=None, iid=True, n_jobs=2,
param_grid={'n_estimators': [60], 'learning_rate': [0.1], 'min_samples_split': [360], 'min_samples_leaf': range(2, 51, 2), 'max_depth': [6], 'subsample': [0.8], 'max_features': ['sqrt']},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring='roc_auc', verbose=0)
0.7870443837906562
{'learning_rate': 0.1, 'max_depth': 6, 'max_features': 'sqrt', 'min_samples_leaf': 10, 'min_samples_split': 360, 'n_estimators': 60, 'subsample': 0.8}看到在本例中min_samples_leaf我们保持最初根据经验值设定的10即可,对应的就是最优的结果。
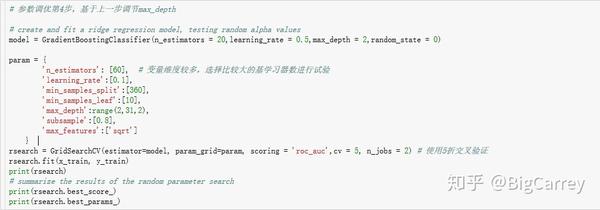
继续,调节max_depth参数:

输出如下:
GridSearchCV(cv=5, error_score='raise',
estimator=GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
presort='auto', random_state=0, subsample=1.0, verbose=0,
warm_start=False),
fit_params=None, iid=True, n_jobs=2,
param_grid={'n_estimators': [60], 'learning_rate': [0.1], 'min_samples_split': [360], 'min_samples_leaf': [10], 'max_depth': range(2, 31, 2), 'subsample': [0.8], 'max_features': ['sqrt']},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring='roc_auc', verbose=0)
0.7870443837906562
{'learning_rate': 0.1, 'max_depth': 6, 'max_features': 'sqrt', 'min_samples_leaf': 10, 'min_samples_split': 360, 'n_estimators': 60, 'subsample': 0.8}同样的,最初设定的max_depth参数即为当前情况的最优参数,保持其值为6。
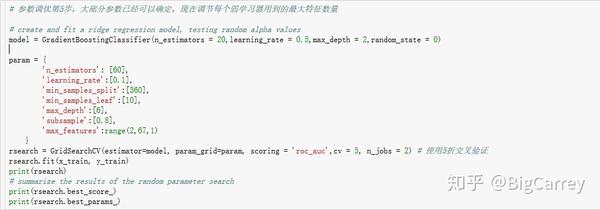
再然后,保持上述参数不变,调节max_features参数:

GridSearchCV(cv=5, error_score='raise',
estimator=GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
presort='auto', random_state=0, subsample=1.0, verbose=0,
warm_start=False),
fit_params=None, iid=True, n_jobs=2,
param_grid={'n_estimators': [60], 'learning_rate': [0.1], 'min_samples_split': [360], 'min_samples_leaf': [10], 'max_depth': [6], 'subsample': [0.8], 'max_features': range(2, 15)},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring='roc_auc', verbose=0)
0.7870443837906562
{'learning_rate': 0.1, 'max_depth': 6, 'max_features': 8, 'min_samples_leaf': 10, 'min_samples_split': 360, 'n_estimators': 60, 'subsample': 0.8}对于max_features这个参数来说,通常按照经验值设定的“sqrt”(总特征数量的平方根取整)即为最优参数,在本例中也是如此。剩余总特征数量为67,对应的平方根取整后为8,该值即为最优值。
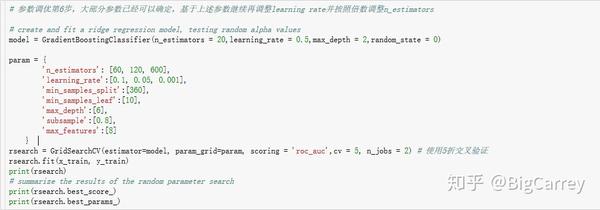
最后一步,保持上述所有参数,回过头调节learning_rate参数,并按倍数调整n_estimators,找到最佳组合:

GridSearchCV(cv=5, error_score='raise',
estimator=GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
presort='auto', random_state=0, subsample=1.0, verbose=0,
warm_start=False),