


为什么GeoPandas 在处理大数据(百万级别)速度很慢

首先声明内容不是原创,个人整理用于处理日常地理数据。我用geopandas的原因是其可以很方便的将python读取的csv,geojson和txt文件中含有xy地理坐标的信息转换成shapely的geometry对象,可以很方便的转换成常用的gis软件支持的shp格式,以便与后续空间分析和可视化操作。另外,geopandas本身具有和pandas相同的plot功能,可以对你的data 进行实时preview,另外支持pyproj 包的坐标转换。我的任务是对超过100 million 的building locations 提取其vertices 和 中心点。你会发现GeoPandas对于处理超过 5 million的数据时速度很慢,not feasible at all! 于是查阅相关资料后试图找到原因和解决方式。
Joris Van den Bossche 在EuroSciPy 2017中的演讲中对比了GeoPandas和Cython以及PostGIS的速度表现并且给出了本文中题目的原因。
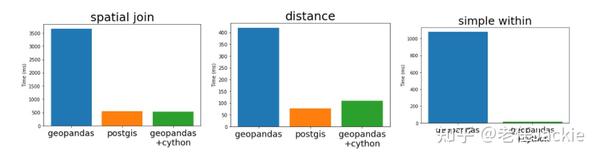

GeoPandas速度慢的原因在于其空间分析机制:
(1) GeoPandas 用Arrays存储特定的Python Objects (Shapely Geometry Objects), Python Objects 比起GEOS objects 占用更多内存
(2) 对于空间查询操作,GeoPandas 简单地循环每一个对象,若对象太多,则耗时自然增加, 且Python的iterate比起C速度慢很多。
例如一个计算一个点到所有储存在GeoSeries中的geometry的距离:
geoseries = GeoSeries(...)
point = Point (...)
geoseries.distance(point)
#list-comprehension under the hood
[geom.distance(d) for geom in geoseries]
从提高运算效率,降低内存占用和平行计算方面,实现成倍提高GeoPandas的运算速度方式:
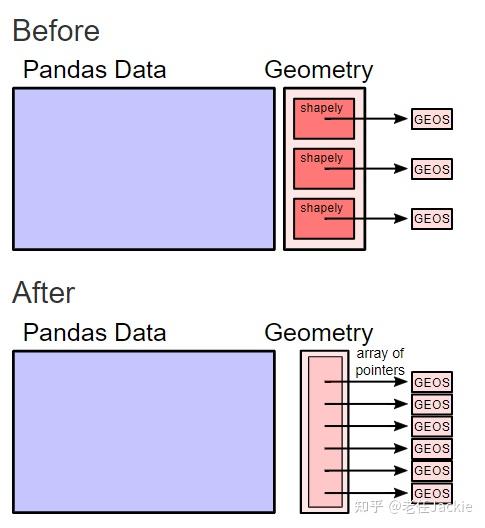
(1)利用Cython将原有shapely objects 替换为利用NumPy array 储存GEOS objects 指针。
Joris et al. 利用GeometryArray存储geometry对象,利用Cython、C,只循环指针而非Shapely对象。
结果进行同样的within操作,速度提升70倍。

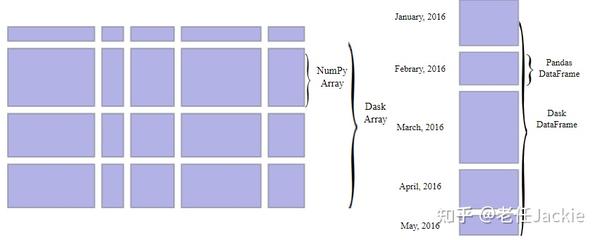
(2)利用Dask 进行平行计算,对数据进行分块处理,并利用Python的平行计算分析工具DASK,进一步提高运行效率4-8倍左右。具体方式可参考其Github网站 mrocklin/dask-geopandas: Parallelized GeoPandas with Dask (github.com) ,该项目目前处于原型阶段,本人正在用该团队已有成果进行千万级地理数据聚类分析,结果下个月呈上。本人研究兴趣为地理大数据分析及新方式方法进行地理建模( Zheng Ren | ResearchGate )。

References:
GeoPandas developments: redesign and improved performance using Cython | Joris Van den Bossche
Fast GeoSpatial Analysis in Python (dask.org)
Geospatial Operations at Scale with Dask and Geopandas | by Ravi Shekhar | Towards Data Science