机器学习
中缺失值
处理
当我们拿到一批数据的时候,往往都是“不干净”的,而缺失值是最常见也是最容易发现的。不同的缺失值
处理
方式对接下来的特征提取,建模等都有巨大影响。那么缺失值的
处理
是有一套流程的,我在这里总结总结:
发现缺失值
统计每个特征在所有个体中缺失的个数 / 缺失率
这一点是查找缺失的特征
公众号:尤而小屋作者:Peter编辑:Peter本文记录的是Pandas中缺失值填充的5大技巧:填充具体数值,通常是0填充某个统计值,比如均值、中位数、众数等填充前后项的值基于SimpleImputer类的填充基于KNN算法的填充数据importpandasaspd
importnumpyasnpdf=pd.DataFrame({
"A":list...
圣人曾说过:数据和特征决定了
机器学习
的上限,而模型和算法只是逼近这个上限而已。
再好的模型,如果没有好的数据和特征质量,那训练出来的效果也不会有所提高。数据质量对于数据分析而言是至关重要的,有时候它的意义会在某种程度上会胜过模型算法。
本篇开始分享如何使用Python进行数据分析,主要侧重介绍一些分析的方法和技巧,而对于pandas和numpy等Py...
在FreeMarker中,有几种
处理
空值
的方法。首先,可以使用判断标签来判断变量是否存在,并根据情况输出或不输出相应的内容。例如,可以使用`${user.name?if_exists}`来判断`user.name`是否存在,如果存在则输出,反之则不输出。另外,可以使用`${user.name!default("默认值")}`或`${name!"默认值"}`来判断存在与否,并根据情况输出相应的值或默认值。此外,还可以使用`${datename?string('yyyy-MM-dd')}`来格式化日期。\[1\]
另一种
处理
空值
的方法是使用`escape`和`noescape`标签。通过这两个标签,可以对所有的变量进行
空值
处理
。可以设置默认值,将
空值
替换为默认值,或者不进行
处理
。例如,使用`<#escape x as x!"默认值"><span>账号</span>${user.id}<span>姓名</span>${user.name}</#escape>`来设置默认值,或者使用`<#noescape><span>账号</span>${user.id}<span>姓名</span>${user.name}</#noescape>`来对
空值
不进行
处理
。\[2\]
此外,还可以通过属性配置的方法来
处理
空值
。可以在类路径下添加`freemarker.properties`文件,并在其中配置`classic_compatible=true`。或者通过`freemarker.template.Configuration`的`config.setClassicCompatible(true)`方法来设置。另外,在ftl文件内引入`<!--#setting classic_compatible=true-->`也可以实现相同的效果。\[3\]
综上所述,FreeMarker中
处理
空值
的方法有多种,可以根据具体情况选择适合的方法来
处理
空值
。
#### 引用[.reference_title]
- *1* *2* [freemarker之
空值
处理
解决方案](https://blog.csdn.net/wdehxiang/article/details/77772356)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^control_2,239^v3^insert_chatgpt"}} ] [.reference_item]
- *3* [四种
处理
freemarker
空值
的方法](https://blog.csdn.net/weixin_33790053/article/details/92931783)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^control_2,239^v3^insert_chatgpt"}} ] [.reference_item]
[ .reference_list ]


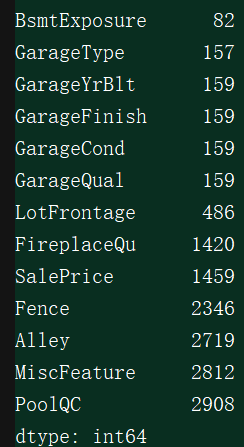
 统计每列的空值:
统计每列的空值:
 打印出的结果如下(截图为部分结果):
打印出的结果如下(截图为部分结果):


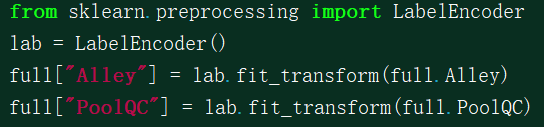
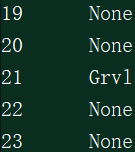
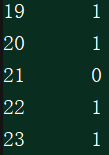
 上面使用“None”来填充空值,也可以使用其他方法填充字符型空值,如众数:
上面使用“None”来填充空值,也可以使用其他方法填充字符型空值,如众数:


 到这里,数据处理已经基本完成,接下来就需要在原特征上进行特征选择,将在下一篇中介绍。
到这里,数据处理已经基本完成,接下来就需要在原特征上进行特征选择,将在下一篇中介绍。