


python爬虫——xpath

XPath非python标准库,是lxml库里的一个支持模块,需安装: pip install lxml
lxml python 官方文档: http:// lxml.de/index.html
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索.
XPath的功能非常强大,几乎所有想要定位的节点都可以用 XPath 来选择。
官方文档: https://www. w3.org/TR/xpath/
中文文档: https://www. w3school.com.cn/xpath/i ndex.asp
1. XPath常用规则
| 表 达 式 | 描 述 |
| nodename | 选取此节点的所有子节点 |
| / | 绝对路径,从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,代表全部,如//*代表选取当前节点的所有子孙节点 |
| [] | 方括号内指定属性值或索引,如://div[@class='ul'] 表示选择当前节点下所有class='ul'的子孙div节点 |
最好在浏览器中安装一个插件:Xpath helper,就是下图上导航栏下面那个深色半透明框框:
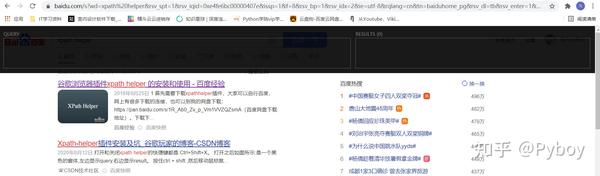

谷歌浏览器直接科学上网去谷歌插件商店下载安装。
有了这个插件,可以直接在网页上操作Xpath表达式,准确的选择需要的数据。
如下图例:
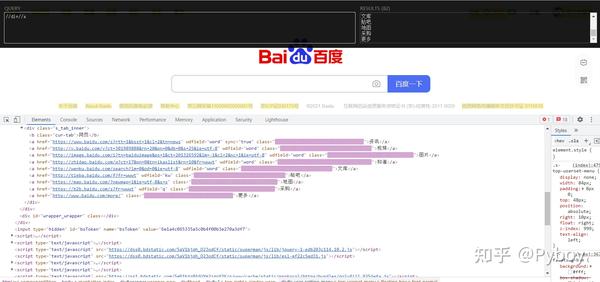
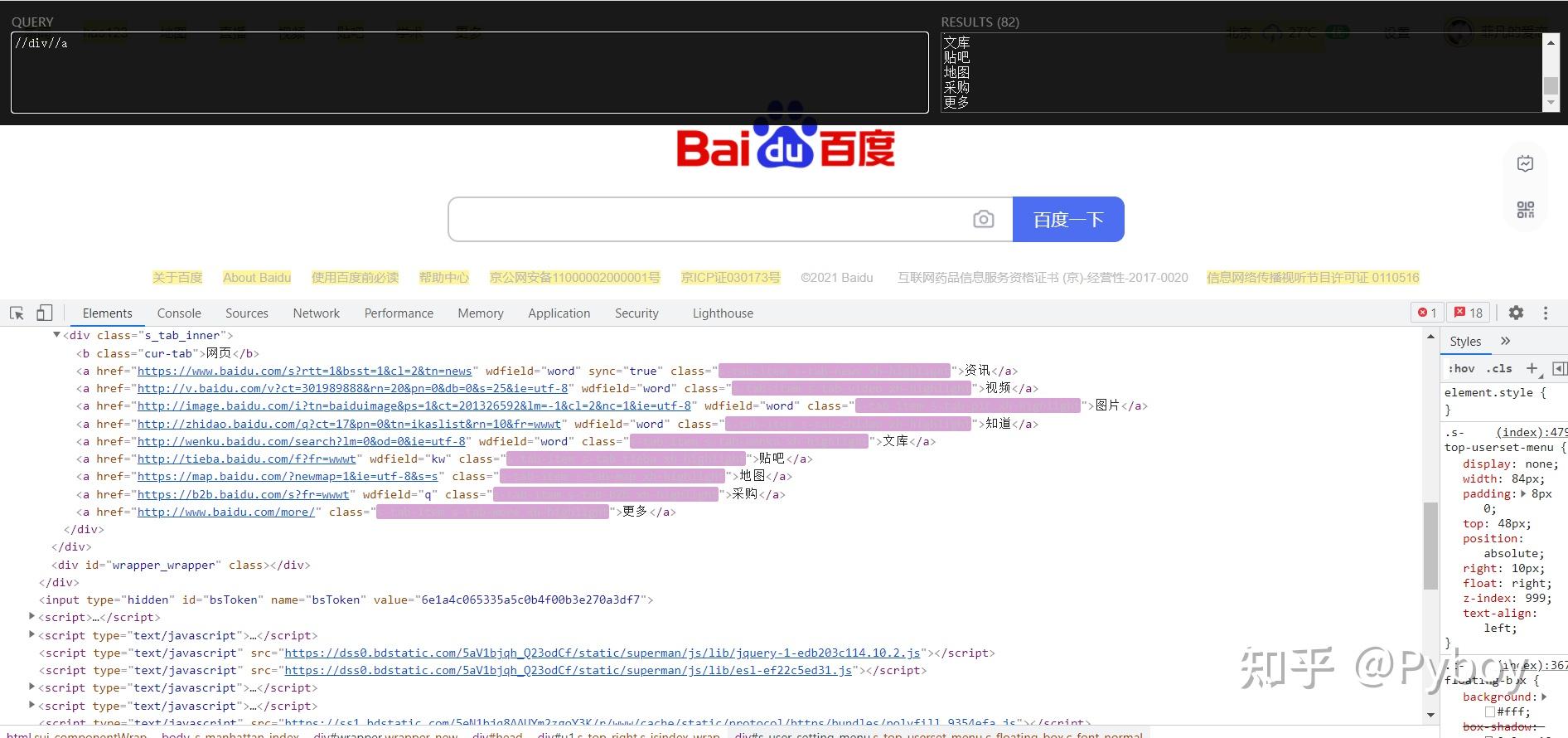
2. 数据解析
2.1 Xpath基本概念
在 XPath 中,有 七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点 。XML和HTML文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
<html lang="en">#根节点
<meta charset="UTF-8">#charset="UTF-8"是元素
<title>Title</title>#Title是文本
</head>#一对标签之间是命名空间2.2 数据导入
2.2.1 HTML文件导入——etree.parse()
首先准备一个html文件:练习.html
<!DOCTYPE html>
<html lang="en">
<meta charset="UTF-8">
<title>Title</title>
</head>
<div id="cont">
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class=
"bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
</div>
</body>
</html>然后导入,解析, tostring 转换成字符串(), 默认parse()解析结果中的中文是Unicode编码 ,所以需要 声明文件类型也就是解码模式method=“html”,并重新编码 encoding='unicode '(按理说应该编码'utf-8',但是实际操作不行,原理不明。。。):
from lxml import etree
html = etree.parse('练习.html',etree.HTMLParser())
#result = etree.tostring(html)
#默认显示中文是Unicode编码过的,所以需要声明文件类型也就是解码模式=“html”,并重新编码。
result = etree.tostring(html,encoding='unicode', method = "html")
#或者用下面这种方式,先转码再解码:
#result = etree.tostring(html,encoding='utf-8',method='html').decode('utf-8')
print(result)运行结果:
<!DOCTYPE html>
<html lang="en">
<meta charset="UTF-8">
<title>Title</title>
</head>
<div id="cont">
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
</div>
</body>
</html>2.2.2 字符串导入——etree.HTML()
etree.HTML()会将部分缺失的节点可以自动修复,并加上<html><body></body></html>节点,比如下例中,div标签有缺失:
text = '''
<div id="cont">
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
from lxml import etree
html = etree.HTML(text)
result = etree.tostring(html,encoding='unicode')
#result = etree.tostring(html,encoding='utf-8',method='html').decode('utf-8')
print(result)运行结果(自动补全了div标签):
<html><body><div id="cont">
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
</div></body></html>
3. 节点操作——xpath()
语法:xpath('xpath规则')
返回一个 由<class 'lxml.etree._Element'>对象元素组成的 列表 。如需解读每个对象的内容, 先for循环遍历,再tostring()。
3.1 提取子节点
3.1.1 提取所有子节点
语法:xpath('父节点/子节点')
或 :xpath('父节点/子节点/.')
from lxml import etree
html = etree.HTML(text)
result = html.xpath('//li/a')
print(type(result[0]),result)
for r in result:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))运行结果:
<class 'lxml.etree._Element'> [<Element a at 0x1db8a781b08>, <Element a at 0x1db9b1fe6c8>, <Element a at 0x1db9b1fefc8>, <Element a at 0x1db9b1fe888>]
<a href="link2.html">爬虫开发</a>
<a href="link3.html"><span class="bold">数据分析</span></a>
<a href="link4.html">深度学习</a>
<a href="link5.html">机器学习</a>3.1.2 按索引指定提取子节点
语法:xpath('父节点/子节点')[索引]
或 :xpath('父节点/子节点[索引] ')
因为xpath返回的是一个列表,所以可以进行索引取值
from lxml import etree
html = etree.
HTML(text)
result = html.xpath('//a')[2]
print(type(result),result)
print(etree.tostring(result,encoding='utf-8',method='html').decode('utf-8'))运行结果:
<class 'lxml.etree._Element'> <Element a at 0x21d2541d8c8>
<a href="link4.html">深度学习</a>3.1.3 其他指定提取方法
| xpath规则 | 说明 |
| node[position()<n] | 提取第n个前的node节点 |
| node[position()>n] | 提取第n个后的node节点 |
| node[last()] | 提取最后一个node节点 |
| node[last()-n] | 提取倒数第n个node节点 |
from lxml import etree
html = etree.HTML(text)
#获取第一个li标签
result1 = html.xpath('//li[1]')
for r in result1:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))
#获取前两个li标签下的a标签(第一个li标签下没有a标签)
result2 = html.xpath('//li[position()<3]/a')
for r in result2:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))
#获取最后一个li标签下的a标签
result3 = html.xpath('//li[last()]/a')
for r in result3:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))
#获取倒数第二个li标签下的a标签
result4 = html.xpath('//li[last()-1]/a')
for r in result4:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8运行结果:
<li class="item-0">web开发</li>
<a href="link2.html">爬虫开发</a>
<a href="link5.html">机器学习</a>
<a href="link4.html">深度学习</a>3.2 提取所有节点
语法:xpath('//*')
//前没有指定节点,即从根节点(文档开头)算起,查找所有子孙节点,*是通配符,指代所有节点。
from lxml import etree
html = etree.HTML(text)
result = html.xpath('//*')
print(type(result[0]),result)
for r in result:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))3.3 提取某个子节点的父节点
语法:xpath('子节点/..')
from lxml import etree
html = etree.HTML(text)
#获取第一个li标签
result1 = html.xpath('//span/..')
for r in result1:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))运行结果:
<a href="link3.html"><span class="bold">数据分析</span></a>3.4 提取文本数据
语法:xpath('路径/text()')
路径可以像3.1中那样,加索引,加函数,去指定到更具体的节点。
from lxml import etree
html = etree.HTML(text)
result = html.xpath('//li/a/text()')
print(type(result[0]),result)运行结果:
<class 'lxml.etree._ElementUnicodeResult'> ['爬虫开发', '深度学习', '机器学习']3.5 提取属性值
语法:xpath('路径//@属性名')
路径可以像3.1中那样,加索引,加函数,去指定到更具体的节点。
注意: @前面是可以是双斜杠,查找当前节点下(包含子孙节点)的这个属性的属性值;
也可以是单斜杠:只查找子节点
from lxml import etree
html = etree.HTML(text)
result = html.xpath('//li/a//@href')
print(type(result[0]),result)运行结果:
<class 'lxml.etree._ElementUnicodeResult'> ['link2.html', 'link3.html', 'link4.html', 'link5.html']3.6 指定具体属性
3.6.1 指定具体属性值
xpath('节点[@属性名="属性值"]')
from lxml import etree
html = etree.HTML(text)
result = html.xpath('//li/a[@href="link4.html"]')
print(result)
#[<Element a at 0x1e16c981b08>]3.6.2 指定某个属性多个值中的某一个或多个
xpath('路径[contains(@属性名,"属性值")]')
某些节点的某个属性可能有多个值,这里 匹配它其中的某一个值和多个值 :
from lxml import etree
html = etree.HTML(text)
#匹配其中某一个值
result1 = html.xpath('//li[contains(@class,"active")]')
for r in result1:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))
#匹配其中多个值
result2 = html.xpath('//li[contains(@class,"item-1 active")]')
for r in result2:
print(etree.tostring(r,encoding='utf-8',method='html').decode('utf-8'))运行结果:
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li3.6.3 匹配多个属性
xpath('路径[@属性1 = "属性值1" and @属性2 = "属性值2"]')
text1 = """
<li class="zxc asd wer" name="222"><a href="https://s2.bdstatic.com/">1 item</a></li>
<li class="ddd zxc eee" name="111"><a href="https://s3.bdstatic.com/">2 item</a></li>
from lxml import etree
html = etree.HTML(text1)
result = html.xpath('//li[@class = "ddd zxc eee" and @name = "111"]')
for r in result:
print(etree.tostring(r, encoding='utf-8', method='html').decode('utf-8'))