with open("config.yml",encoding="utf-8") as f:
conf = yaml.load(f)
pprint.pprint(conf)
执行结果如下:

这里报了个warnning: calling yaml.load() without Loader=… is deprecated, as the default Loader is unsafe.意思是说默认的加载器是不安全的。我们进入load方法的源码看看:
def load(stream, Loader=None):
Parse the first YAML document in a stream
and produce the corresponding Python object.
if Loader is None:
load_warning('load')
Loader = FullLoader
loader = Loader(stream)
try:
return loader.get_single_data()
finally:
loader.dispose()
这里可以看出,如果不指定loader,会抛出个警告,并使用FullLoader作为默认的loader。这里我们最好指定一个loader,如:SafeLoader:
import yaml
import pprint
with open("config.yml",encoding="utf-8") as f:
conf = yaml.load(f,Loader=yaml.SafeLoader)
pprint.pprint(conf)
执行结果如下,可看到警告信息没了:
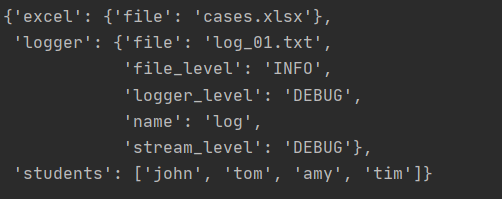
import yaml
def read_yaml(file):
"""读取 yaml 文件"""
with open(file, encoding='utf8') as f:
conf = yaml.load(f, Loader=yaml.SafeLoader)
return conf
def write_yaml(file, data):
with open(file, 'w', encoding='utf8') as f:
yaml.dump(data, f)
1、数据层、用例层、逻辑层分离,逻辑层包含(公用的方法的封装:l例如实现打开浏览器,访问url,输入用户名这些实现测试步骤的经常用到的方法封装)和(数据提取)
element_A.yaml文件(数据层)
host:
url: http://slw.shengyj.com/slw/login/index
login:
username: xpath>//*[@id="loginindex"]/div[2]/div[2]/div/div[3]/div[4]/form...
在设计自动化测试框架的时候,我们会经常将测试数据保存在外部的文件(如Excel、YAML、CSV),或者数据库中,实现脚本与数据解耦,方便后期维护。目前非常多的自动化测试框架采用通过Excel或者YAML文件直接编写测试用例,通过脚本读取出来驱动自动化测试代码执行。至于采用Excel还是YAML格式各位小伙伴都有不同见解,比如用Excel维护直观、修改数据方便,劣势是通过Git这样的版本控制工具不太好比较历史版本差异(因为是二进制格式);
一个yaml 文件中可以写多个用例,yaml 文件相当于py模块,每个用例相当于模块里面定义 pytest 的一个函数,
用例名称最好是test开头,如果不是test开头,也会帮你自动拼接成test开头的
这里是清安,前段时间停更了很久,主要是在是自动化框架,也就是本文所述的这些东西。框架已经写完了,剩下的就是慢慢分解,写成文章的形式呈现出来。本章还是说上一章所没有讲到的内容。读取yaml文件。我们是以yaml文件作为自动化用例的基础的。所以读取它必不可少。即使是excel也是一样的。
此处有一定注释,简单的理解就是传入了一个yaml文件路径,做了一系列的判断,最后获取其中的内容,并返回结果值。其他的代码都是做的校验这么一个操作,处理异常情况的。这里为了后面调用不打(),所以这里加了一个装饰器,将getDat
官方网址: http://www.yaml.de/
它是一个开源的模块化的CSS框架,完全支持当前主流的浏览器,能很好的实现跨浏览器页面设计。主要分为三个模块:布局模块(Layout)、表单模块(Form)、基本元素模块(Typography)。当前版本4.0.1,可在这里下载。
主要特征:
1、灵活实用的布局设计(ym-wrapper, ym-grid)
在设计自动化测试框架的时候,我们会经常将测试数据保存在外部的文件(如Excel、YAML、CSV)或者数据库中,实现脚本与数据解耦,方便后期维护。目前非常多的自动化测试框架采用通过Excel或者YAML文件直接编写测试用例,通过脚本读取出来驱动自动化测试代码执行。
''1、每条用例前置sql,请求参数sql,断言sql2、requests二次封装,自动获取ip和header信息3、allure动态方法封装(标题、描述、步骤)4、钉钉机器人发生allure报告公司局域网内可以访问5、log日志记录每个重要参数6、多接口参数依赖(接口返回提取,请求使用)7、token信息全局前置写入配置文件8、用例文件支持多目录多文件运行,支持排除目录或者文件9、定位运行的用例属于哪个文件10、支持随机几位数字或者字符串11、提供mock接口。......
基于 httprunner 框架的用例结构,我自己开发了一个pytest + yaml 的框架,那么是不是重复造轮子呢?
不可否认 httprunner 框架设计非常优秀,但是也有缺点,httprunner3.x的版本虽然也是基于pytest框架设计,结合yaml执行用例,但是会生成一个py文件去执行。
在辅助函数的引用也很局限,只能获取函数的返回值,不能在yaml中对返回值重新二次取值。
那么我的这个框架,就是为了解决这些痛点。。。。
1 YAML简介
YAML,即YAML Ain’t Markup Language的缩写,YAML 是一种简洁的非标记语言。YAML以数据为中心,使用空白,缩进,分行组织数据,从而使得表示更加简洁易读。
YAML的在线Demo这个YAML转化JSON网页中进行上手练习
2 YAML语法
大小写敏感
使用缩进表示层级关系
禁止使用tab缩进,只能使用空格键
写了好多关于selenium的文章,今天换个口味,推荐一个文件格式 – yaml,以及对应的Python库 – PyYaml。可以用之作为你自动化测试框架的配置文件或者用例文件。yaml是一种比xml和json更轻的文件格式,也更简单更强大,它可以通过缩进来表示结构,听着就和Python很配对不对?yaml的介绍不在这里赘述,感兴趣可以自行百度下,先说下它的基本语法,还是配合着PyYaml来:1.
理念与同“UI自动化测试框架”中的“测试步骤的数据驱动”相同,接口中的测试步骤的数据驱动就是将接口的参数(比如 method、url、param等)封装到 yaml 文件中管理。当测试步骤发生改变,只需要修改 yaml 文件中的配置即可。
数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。简单来说,就是参数化的应用。数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况下建议使用一种结构化的文件(例如yaml,json等)来对数据..
YAML介绍
YAML是”YAML Ain’t a Markup Language”(YAML不是一种置标语言)的递归缩写,早先YAML的意思其实是:”Yet Another Markup Language”(另外一种置标语言)
YAML语法
YAML使用可打印的Unicode字符,可使用UTF-8或UTF-16
使用空白字符(不能使用Tab)分层,同层元素左侧对齐
单行注解由井字号(...




