RNN结构:
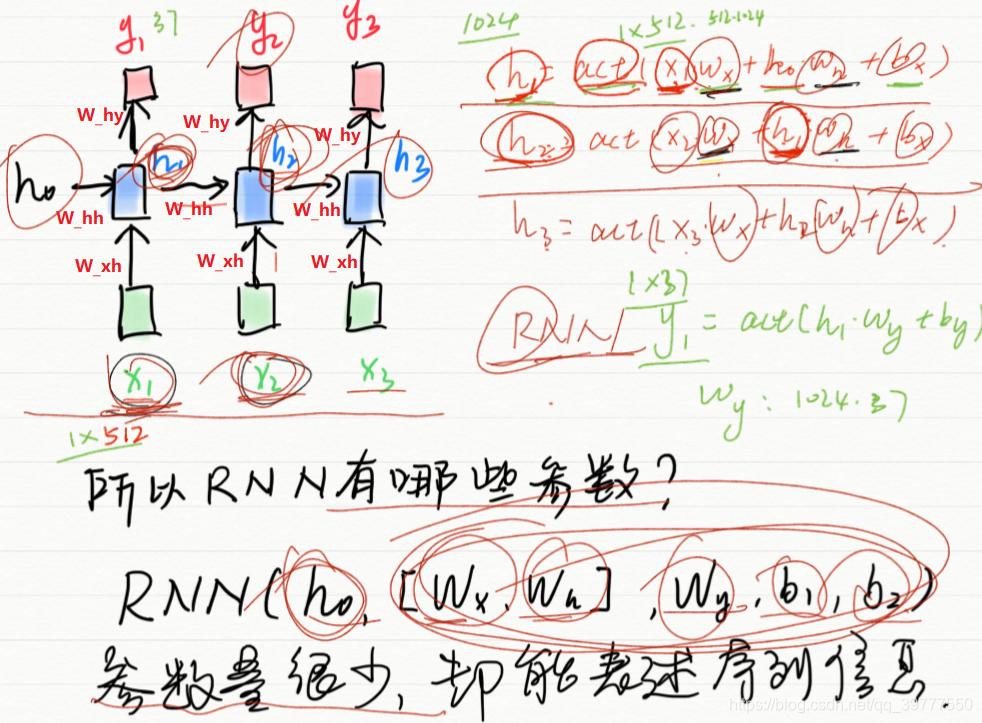
对应的代码为:(代码中没写偏置)

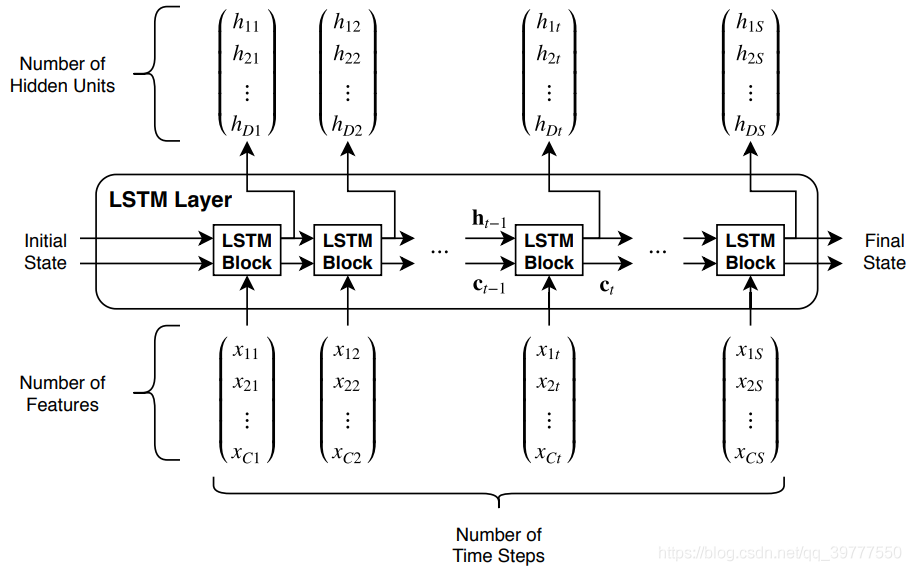
上图是单层LSTM的输入输出结构图。其实它是由一个LSTM单元的一个展开,如下图所示:
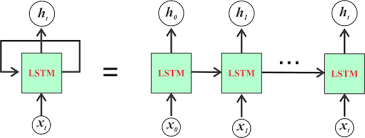
所以从左到右的每个LSTM Block只是对应一个时序中的不同的步。
在第一个图中,输入的时序特征有S个,长度记作:seq_len,每个特征是一个C维的向量,长度记作:input_size。而Initial State是LSTM的隐藏状态和内部状态的一个输入的初始化。分别记作:h0和c0。
输出可以通过设置,来决定是输出所有时序步的输出,还是只输出最后一个时序步的输出。Final_State是隐藏状态和内部状态的输出,记作:hn和cn.
那么对于在pytorch中的函数LSTM的参数的输入情况如下:
-
X的格式:(seq_len,batch,input_size)
#batch是批次数,可以在LSTM()中设置batch_first,使得X的输入格式要求变为(batch,seq_len,input_size)
-
h0的格式:(1,batch,hidden_size)
-
c0的格式:(1,batch,hidden_size)
因为不管输入的数据X是多少个特征的,h0和c0的都只需要一个输入就行。
对于输出,输出的hidden_size的大小是由门控中的隐藏的神经元的个数来确定的。
-
H的格式:(seq_len,batch,hidden_size)
#如果按照(seq_len,batch,hidden_size) 的格式输出,需要在LSTM()中设置return_sequences=True,否则默认只输出最后一个时间步的输出结果(1,batch,hidden_size).
-
hn的格式:(1,batch,hidden_size)
-
cn的格式:(1,batch,hidden_size)
这只是LSTM单元的输入输出格式,真实的其后还要跟一个全连接层,用于把LSTM的输出结果映射到自己想要的结果上,如分类:
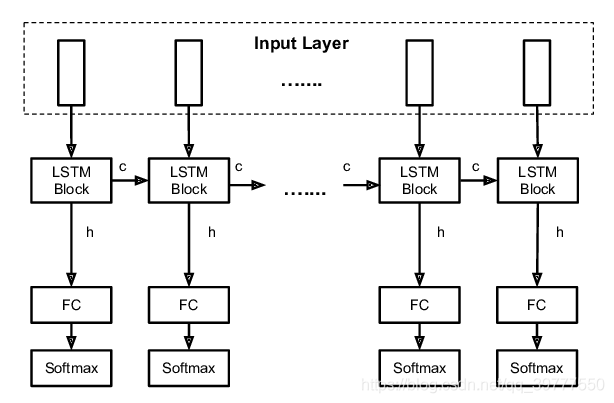
如果只想要研究最后一个时间步的输出结果,只需在最后一个时间步添加全连接即可。
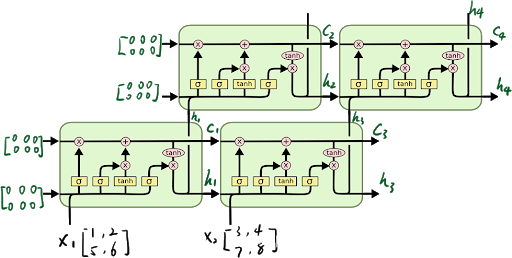
对于多层的LSTM,需要把第一层的每个时间步的输出作为第二层的时间步的输入,如上图所示。
对于num_layers层LSTM:
-
X的格式:(seq_len,batch,input_size)
-
h0的格式:(num_layers,batch,hidden_size)
-
c0的格式:(num_layers,batch,hidden_size)
-
H的格式:(seq_len,batch,hidden_size)
-
hn的格式:(num_layers,batch,hidden_size)
-
cn的格式:(num_layers,batch,hidden_size)
如果是双向的,即在LSTM()函数中,添加关键字bidirectional=True,则:
单向则num_direction=1,双向则num_direction=2
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
补充细节,下面是转载的:
版权声明:本文为CSDN博主「ssswill」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/ssswill/article/details/88429794
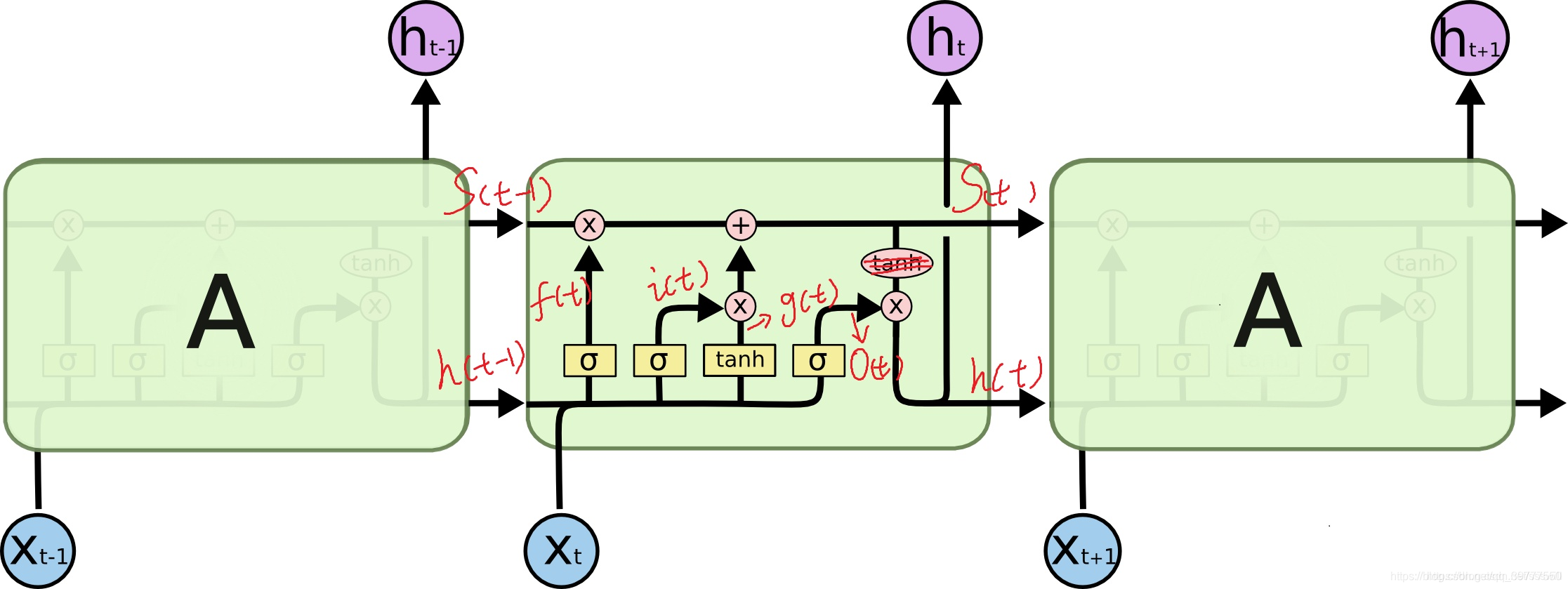
输出的y=act(h_t*W_y)+b_y(图中未显示!)
可以看到中间的 cell 里面有四个黄色小框,你如果理解了那个代表的含义一切就明白了,每一个小黄框代表一个前馈网络层,对,就是经典的神经网络的结构,num_units就是这个层的隐藏神经元个数,就这么简单。其中1、2、4的激活函数是 sigmoid,第三个的激活函数是 tanh。
另外几个需要注意的地方:
1、 cell 的状态是一个向量,是有多个值的。
2、 上一次的状态 h(t-1)是怎么和下一次的输入 x(t) 结合(concat)起来的,这也是很多资料没有明白讲的地方,也很简单,concat, 直白的说就是把二者直接拼起来,比如 x是28位的向量,h(t-1)是128位的,那么拼起来就是156位的向量。
3、 cell 的权重是共享的,这是什么意思呢?这是指这张图片上有三个绿色的大框,代表三个 cell 对吧,但是实际上,它只是代表了一个 cell 在不同时序时候的状态,所有的数据只会通过一个 cell,然后不断更新它的权重。
4、那么一层的 LSTM 的参数有多少个?根据第 3 点的说明,我们知道参数的数量是由 cell 的数量决定的,这里只有一个 cell,所以参数的数量就是这个 cell 里面用到的参数个数。假设 num_units 是128,输入是28位的,那么根据上面的第 2 点,可以得到,四个小黄框的参数一共有 (128+28)*(128*4),也就是156 * 512,可以看看 TensorFlow 的最简单的 LSTM 的案例,中间层的参数就是这样,不过还要加上输出的时候的激活函数的参数,假设是10个类的话,就是128*10的 W 参数和10个bias 参数
5、cell 最上面的一条线的状态即 s(t) 代表了长时记忆,而下面的 h(t)则代表了工作记忆或短时记忆。
LSTM的训练过程:


说明:上面画红框的地方,如想输出如上的三维矩阵,需要指明参数:return_sequences=True

再附一张图:

白色框框中,第一行是实现细节,第二行是第一行输出结果的维度。
对于双向的Bi-LSTM网络:
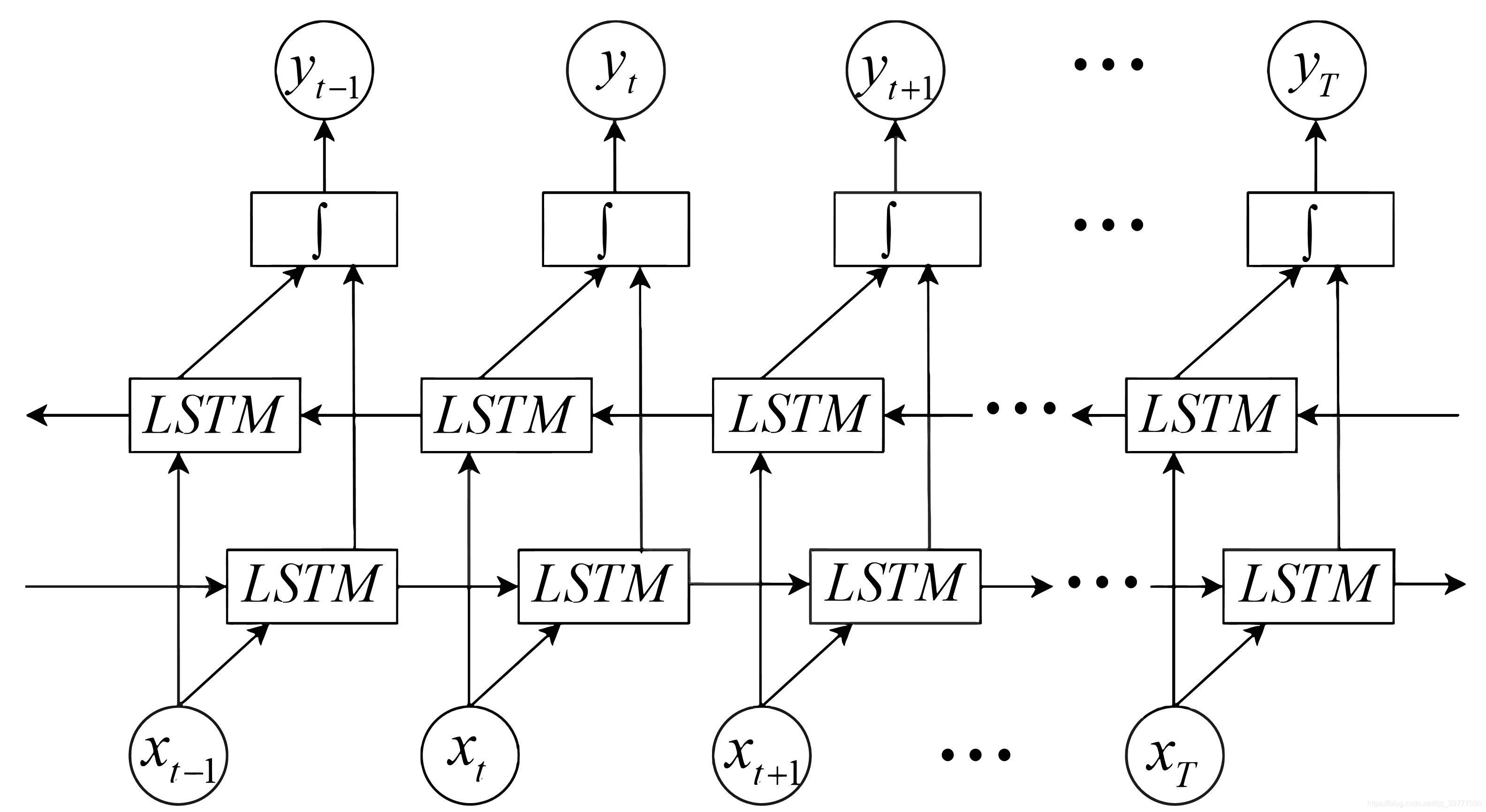
正向求得的第一个正h_1和反向求得的最后一个反h_-1,生成的结果进行对应位置相加,然后再经过act(W_y*h)+b_y得到对应的y.
如何堆叠
多层
LSTM
网络——长短期记忆(
LSTM
)系列_
LSTM
的建模方法(2)发布时间:2018-12-07 15:15,浏览次数:1362, 标签:
LSTM
导读:堆叠式
LSTM
属于深度学习,通过添加网络的深度,提高训练的效率,获得更高的准确性。文中介绍了堆叠式
LSTM
的架构和实现方法在堆叠式
LSTM
中,层与层的输数出通过return_sequences = True参数修改成3D数据,以便供下...
4.batch_first:默认为False,在制作数据集和数据集载入的时候,有个参数叫batch_size,也就是一次
输入
几个数据,
lstm
的
输入
默认将batch_size放在第二维,当为True的时候,则将batch_size放在第一维。1.input_size:
输入
的特征维度,一般来说就是字向量的维度,比如如果用bert(base)的话,那么
输入
的维度input_size=768。3.num_layers:很好理解,就是
LSTM
堆叠的层数,默认值为1,设置为2的时候,第一层的
输出
是第二层的
输入
。
首先明确一点,
RNN
单元的
输入
输出
的维度,点击参考keras.layers.
RNN
()文档
输入
尺寸
3D 张量,尺寸为 (batch_size, timesteps, input_dim)。
输出
尺寸
如果 return_state:返回张量列表。 第一个张量为
输出
。剩余的张量为最后的状态, 每个张量的尺寸为 (batch_size, units)。
如果 return_sequences:返回 3D 张量, 尺寸为 (batch_size, timesteps, units)。
否则,返回尺寸为 (b
读这篇文章的时候,默认你已经对
LSTM
神经网络有了一个初步的认识,当你深入理解时,可能会对
多层
LSTM
内部的隐藏节点数,有关cell的定义或者每一层的
输入
输出
是什么样子的特别好奇,虽然神经网络就像是一个黑箱子一样,但是我们仍然试图去理解他们。 我们所说的
LSTM
的cell就是这样子的一个结构:(图中标识的A就是一个cell,图中一共是三个cell) 其中的X.t代表t时刻的
输入
,h.t代...
RNN
会受到短时记忆的影响。如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步。 因此,如果你正在尝试处理一段文本进行预测,
RNN
可能从一开始就会遗漏重要信息。
在反向传播期间,
RNN
会面临梯度消失的问题。 梯度是用于更新神经网络的权重值,消失的梯度问题是当梯度随着时间的推移传播时梯度下降,如果梯度值变得非常小,就不会继续学习。
欢迎转载,但请务必注明原文出处及作者信息。@author: huangyongye
@creat_date: 2017-03-09 前言: 根据我本人学习 TensorFlow 实现
LSTM
的经历,发现网上虽然也有不少教程,其中很多都是根据官方给出的例子,用
多层
LSTM
来实现 PTBModel 语言模型,比如:
tensorflow笔记:
多层
LSTM
代码分析
但是感觉这些例子还
LSTM
总共有7个参数:前面3个是必须
输入
的
1:input_size:
输入
特征维数,即每一行
输入
元素的个数。
输入
是一维向量。如:[1,2,3,4,5,6,7,8,9],input_size 就是9
2:hidden_size: 隐藏层状态的维数,即隐藏层节点的个数,这个和
单层
感知器的结构是类似的。这个维数值是自定义的,根据具体业务需要决定,如下图:
input_...
input_size
输入
特征维数:(特征向量的长度,如2048)
hidden_size 隐层状态的维数:(每个
LSTM
单元或者时间步的
输出
的ht的维度,单元内部有权重与偏差计算)
num_layers
RNN
层的个数:(在竖直...
对于
输入
文本序列,在
LSTM
的每个时间步
输入
序列中一个单词的嵌入表示,计算当前时间步的隐藏状态,用于当前时间步的
输出
以及传递给下一个时间步和下一 个单词的词向量一起作为
LSTM
单元
输入
,然后再计算下一个时间步的
LSTM
隐藏状态,以此重复...
堆叠
LSTM
使模型深度更深,提取的特征更深层次,从而使预测更准确。堆叠
LSTM
在大范围的预测问题上取得了不错的效果。
The success of deep neural networks is commonly attributed to the h
from 博客 在
rnn
中存在梯度消失和梯度爆炸的问题。 梯度爆炸解决办法: 上图 梯度爆炸解决办法:引入
lstm
一、
LSTM
(Long-Short Term memory)的结构 二、计算值说明 ft:forget gate it: input gate ...

