


Pandas如何读取和导出 Excel、CSV、JSON 数据?

导入pandas等包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt修改pandas的行和列可以一次性显示多少出来。这个不要设置太多了,在IPython里面打印很大的表格速度会非常慢。
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)一、导入数据
(一)读取csv文件
pd.read_csv(file_name, index_col=0,sep=';',encoding='utf_8_sig',\
names=['customer','restaurant'], low_memory=False, parse_dates = ['date'])
# index_col=0表示把csv中的第一列作为dataframe的index
# encoding 指定了用什么编码格式读取,主要解决中文字符识别的问题
# sep表示csv里面用什么作为分隔符,默认是英文逗号,这里改成了英文分号
# names表示手动指定每一列的名字
# low_memory=False表示让pandas可以处理同一列里面有多种数据类型的情况
# parse_dates指定了某一列为datetime格式关于 encoding 这个参数特别说明一下。
有时候我们在读取 csv 的时候会遇到下面的报错信息,错误类型是 UnicodeDecodeError。
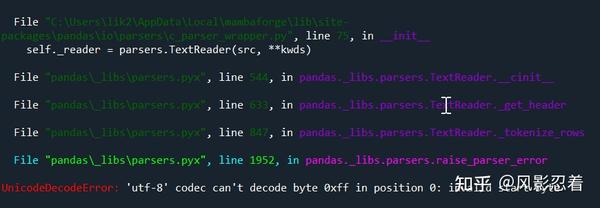

十六进制的0xFF就是二进制的11111111,换算成十进制就是255。UTF8 中编码一个字符的第一个字节(start byte)只可能是 0xxxxxxx、110xxxxx、1110xxx、11110xxx……而后面的字节只可能是 10xxxxxx。也就是说 0xFF 不能出现在第一个字节的位置。
出现这种问题绝大部分情况是因为文件不是 UTF8 编码的(例如,可能是 GBK 编码的),而系统默认采用 UTF8 解码。解决方法是改为对应的解码方式。
极少数情况是因为文件损坏了或者和一部分非 UTF8 编码混在一起,可以修复文件或采用 replace 等方式解码。
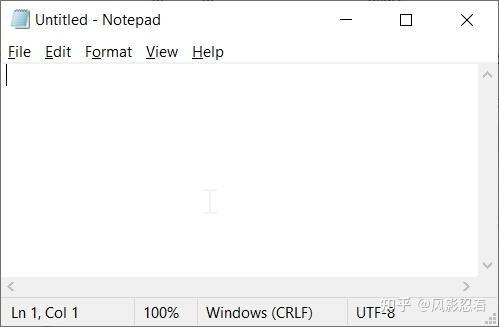
如果是编码不匹配,我们要获取 csv 文件具体是什么编码格式,可以用记事本打开这个 csv,看它的右下角。例如,下图的编码格式是 UTF-8。

(二)读取Excel文件
pd.read_excel('JuiceBlending_Data(1).xlsx',sheet_name='Specs of historical orders',\
usecols='A,DA', nrows=11,header=2,index_col=0, engine='openpyxl')
# sheet_name指定了读取excel里面的哪一个sheet
# usecols指定了读取哪些列
# nrows指定了总共读取多少行
# header指定了列名在第几行,并且只读取这一行往下的数据
# index_col指定了index在第几列
# engine='openpyxl' 指定了使用什么引擎来读取excel文件(三)读取json文件:
data = pd.read_json('all_50_schemas.json',lines=True)
# 其中lines=True表示一个文件里面有多个字典设置最多显示100行100列:
pd.set_option('display.max_columns',100)
pd.set_option('display.max_rows',100)二、导出数据
(一)保存成csv
data_new.to_csv(filename,sep=':',header=False, encoding='utf_8_sig', index=False)
# index: 是否保存行的名字
# header:是否保存列的名字(二)保存成excel文件
data.to_excel(r'output_list1.xls', index=False, sheet_name='Data', float_format="%.0f", freeze_panes=(1,4))
# index表示是否保存dataframe的index
# sheet_name表示worksheet的名字
# float_format表示整个Excel Worksheet中的数字保留几位小数
# freeze_panes表示从第几行、第几列开始冻结单元格,从1开始计数。(三)保存到一个excel文件的多个工作表
1.方法一
使用 pd.ExcelWriter(file_name, mode='a', engine="openpyxl")。我们在这里可以调用的 engine 有两个,一个是xlsxwriter,另一个是openpyxl。在这里是通过设置 mode='a' 来实现工作表的追加的(append),默认状态下,这个参数是 'w',即write。注意,只有 openpyxl 引擎支持这个模式,xlsxwriter 不支持。
data = pd.DataFrame(
{"col1":[1, 2, 3],
"col2":[4, 5, 6],
"col3":[7, 8, 9]
with pd.ExcelWriter("excel 样例.xlsx", mode='a', engine='openpyxl') as writer:
data.to_excel(writer, sheet_name="这是追加的第1个sheet")
data.to_excel(writer, sheet_name="这是追加的第2个sheet")2.方法二
with pd.ExcelWriter('衍生数据.xlsx') as writer:
for group in out_df_group:
print()
# 提取worksheets的名字,以及万得指标编码
sheet_name = group[0]
# 存储到excel
group[1].to_excel(excel_writer=writer,sheet_name=sheet_name,index=True)
print('Finished')(四)保存成数据库文件
from sqlalchemy import create_engine
engine= create_engine('sqlite:///foo.db')
df.to_sql('df', engine)三、Bonus:从内存中读取数据到 DataFrame 中
我们不一定要从文件中读取数据到 pandas 中,还可以直接从内存中读取数据,例如:
import io
data="""
CAT|DATE|VALUE