|
|
|


深度学习做股票预测靠谱吗?
用LSTM做过很多sequencial data的预测发现效果惊人的好,不知道是否有人尝试过在股票预测方面的应用。
关注者
10,150
被浏览
2,808,870
1,125 个回答

修行中 | 多层次研究 | 静默 | 冥想 | 感恩 |
给你讲个段子!真实的!
我去一家量化交易公司实习,一次meeting中,我和老总还有一个资深大佬谈机器学习在股票和期货里面的应用。
我:LSTM在时间序列上应用的效果比较好,我们可以尝试把LSTM应用在股票预测上。
此时,大佬在阴笑,老总默不作声...
我:你为啥笑
大佬: 不work啊!
我:为什么不work?!
这时老总也在旁边强掩笑容,大佬终于忍不住说了,有两个原因,第一个是你如何保证你的因子有效?
老总就补充到:对啊,你的模型很可能garbage in garbage out.
我说:那你们提供因子来训练模型啊
大佬阴笑....
然后大佬又继续说:第二个就是,你非常可能过拟合!
我说:那我们可以加regularization啊。
接着他们俩忽略我的话了,老总接着说:其实我们是想要一个模型能根据每天的数据进行反馈,自动更新。
我一想,这TM的不就是reinforcement learning嘛,我说:可以用reinforcement learning试试。
大佬又开始笑了,我很纳闷。
大佬说: 我就是知道他们有些人在用reinforcement learning,我才能赚钱!!!

最后实习结束之后,在大佬的带领下,我才明白了交易的三重境界
归纳
演绎
博弈
所谓的深度学习不过是基于历史数据进行拟合的 归纳法 罢了,如果把深度学习用来做股票预测,长期的是expected亏钱的,因为市场在变,规律在变,历史可能重演,但是又不尽相同。
深度学习肯定是可以用在股票市场的,比如针对某只股票的新闻情感分析等。但是不能用来预测市场走向!!!
想在市场上赚钱,就得 博弈, 你得知道其他人在干什么,因为市场是有所有的参与者共同决定的。
举个简单的博弈方法:
中国的期货市场之前很长一段时间,很多人,包括一些机构,都在用趋势策略,不同人和机构之间不外乎就是趋势的策略参数不同,让策略性能稍有不同,入市出市点不同,但是大体是类似的。所以这个时候,你应该知道市场上有一部分资金是在用这种趋势策略在跑的,那么在未来的某一个时间点,这些策略会相继的发出信号,然后人们去执行买入卖出的操作。
所以有趣的地方来了,既然你已经知道有一部分人在干嘛了,你是不是就可以设计策略来巧妙的利用其他的人的策略呢?你是不是可以设计一个类似的趋势策略,来告知你别人在这个时候可能会干嘛,而你来选择做更有意义的事情,而不是是不断去改进所谓的趋势策略呢?
所以,回到深度学习的问题上,如果深度学习用来归纳过去的数据,然后来预测股票走势,我觉得是不靠谱的。但是如果能想办法把深度学习用在博弈问题上,那么我觉得有可能靠谱。
-----------------------------------------------------------------------------------------------------------------------
更新:我在另一个回答里举了一个应用深度学习和博弈思想的例子,有兴趣的可以了解下。
MilKY:机器学习(非传统统计方法如回归)在量化金融方面有哪些应用?
我再在这里总结一下我自己对博弈在交易里的理解。我真心就是一个只实习了很短时间的新手,以前也没接触过金融或者量化这一块(只是个码农而已....),理解上肯定有很多偏差和不足。大佬们,如果你们觉得回答里面有什么不妥,本屌非常欢迎赐教啊!
核心思想:
无论你用不用深度学习,除了价值投资,你要赚钱,那么就得有人亏钱,所以说你的交易逻辑本身得是正确的才行,也就是说你设计好一个策略后, 你要知道你赚的钱是从哪来的 。很多人赚钱的时候稀里糊涂的,我们不妨称之为运气好。但是你如果明白你是运气好,并且不断探索原因的话,你很有可能未来还会赚钱。而事实是大多数人明明是运气好但是却觉得是自己聪明,从而未来大亏甚至倾家荡产。
如何应用深度学习呢,假设你已经明白了你得赚钱逻辑,但是这个逻辑里有些事情你一个人做不完,用计算机帮你做,用深度学习帮你做效率更好更快,那么深度学习不是就派上用场了。
我个人认为深度学习不过是个复杂的函数映射逼近算法,你的逻辑就是你的函数,逻辑都不正确,逼近得再好又如何?
----------------------------------------------------------------------------------------------------------------------- 4/19/2021 更新
个人自从2017年暑期在上海某私募基金实习之后,又在2017年圣诞节前后在湾区一家bitcoin fund实习了,然后自己私下做了一段时间交易,有一些新的理解分享给大家。
高频的东西不太懂,对于中低频的而言,个人感觉,市场的宏观分析,包括大国博弈,对世界进程有影响的大机构的发展,左右资源分配的局部战争,各个国家指定的政策,新兴事物的崛起等等,都会一定程度上影响到你关注的市场,这些才是决定市场走向的根本原因。
然后在你把握好大局之后,才是对具体标的的筛选,符合大趋势的标的,也有会做的好和做的不好区别,这个时候你可能要更进一步的阅读财报等更细节的信息。在筛选出标的之后,才是用技术分析对具体的某个标的的行情进行分析,选择对自己有利的入场点。
举个简单的例子,3/12/2020美股,币市等都因为COVID-19暴跌,虽然由疫情带来暴跌的黑天鹅事件很难预测,但是这暴跌之后,央行放水的行为却是可以某种程度上预测的。那么这个时候需要选择在疫情中可能会崛起更快的标的比如Zoom,Amaozn的股票,同时高风险一点的,可以选择一些对抗央行放水的标的,比如BTC。
个人的PhD方向是做深度学习在医学影像领域的应用,个人感觉目前深度学习的局限性还很大(连一个病灶分割的问题也没有办法彻底解决,而这对医生来说是很容易的事情)。虽然深度学习可以一定程度帮你分析问题,但是要依靠深度学习从市场中寻找规律预测涨跌,无异于大海捞针。现在对大佬的话理解更深刻了,garbage in garbage out是常态,即便gold in garbage out也是常态,毕竟给深度学习一张图,让它分割一下,都搞不定,你还指望它给你提取变幻万千的金融市场的特征?高频交易有可能,但我不了解,中低频,靠深度学习预测,你就是进来送钱的。

Kitano

典型INFP-t
背景
趁着完成了本周assignments来佛系更新一下。其实本文模型的原型是ALSTM(Attentive LSTM), 是机器学习选股常见的,也是微软qlib自带的一个baseline,只不过本文作者为了降低模型的过拟合并提高泛化能力,在每一次Iteration里面增添了对抗样本 e_{adv} 以及对应的损失函数部分。我对网络的完整架构和单次BP的过程做了手动复现。由于未参考源代码,或存在部分不妥之处欢迎交流指正。
原论文:《 Enhancing Stock Movement Prediction with Adversarial Training》
作者将该问题抽象成一个经典的低频机器学习预测涨跌的分类模型(可参考我往期的若干篇文章),对于股票 s ,给定时间戳 t 的特征矩阵 X_s \in \mathbb{R}^{T\times D} ,希望训练模型预测该股票在下个持仓期的涨跌标签:
\hat{y_s} = f(X_s,\Theta) \in \{-1,1\}
由于股票市场高随机波动特性,传统的机器学习模型通常会表现出较差的泛化能力,尽管会添加如L2正则化这样的方法,还是会难以避免出现模型过拟合的情况。比如,现在很多模型所喂入的都是短期价量数据(可见此前我的文章AlphaNet因子挖掘网络),学习短期价量特征和收益率的关系,但是这种price-based features是随时间演化的高度随机变量,可以认为是从时变联合分布中不停采样的一组样本,为了适应这种随机性,作者在ALSTM的基础上引入了对抗学习,提升了模型在不同股票数据集上的表现。因此我的复现也基于两大部分:ALSTM的架构和对抗学习部分。
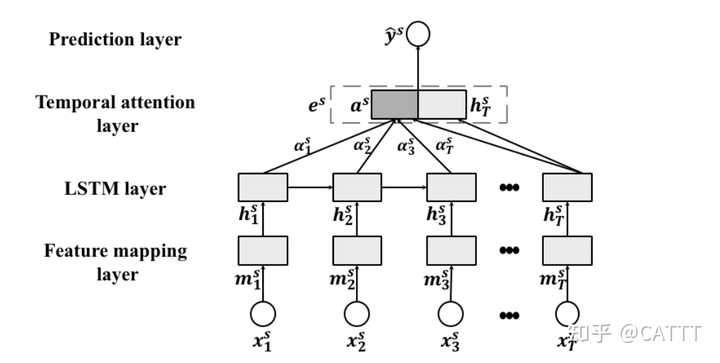
ALSTM模型的整体架构如下:

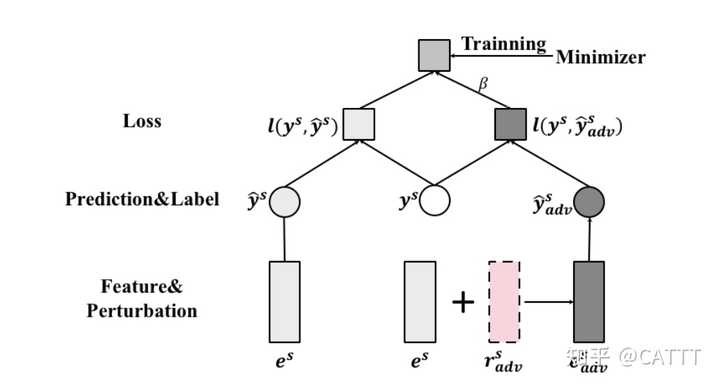
最后的损失函数架构:

首先是定义一些参数:
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch import optim
import torch.nn.functional as F
batch_size = 100
D = 40 #原始的单日的特征维度数
T = 30 #单个样本用于预测所使用的数据的天数
E = 30 #映射后的特征维度数
U = 10 #LSTM网络中的隐藏维度数
Q = 10
num_lstmlayer = 1#LSTM的层数
beta = 1#对抗学习损失函数部分的权重
#模拟一个batch的数据输入
origin_input = torch.randn(batch_size,T,D)
y_label = torch.ones(batch_size)Attentive LSTM
整个模型被拆分成四个主要部分:
- Feature Mapping Layer : 对于一个Batch的原始输入,通过一个fc层映映射成laten space里的特征表示:
m_t^s = tanh(W_mx_t^s+b_m) \in \mathbb{R}^{T \times E}
mapping_layer = nn.Linear(D,E,bias = True)
origin_input = origin_input.flatten(start_dim = 0,end_dim = 1)
tanh = nn.Tanh()
mapping_feature = tanh(mapping_layer(origin_input)
mapping_feature = mapping_feature.reshape(batch_size,T,-1)
mapping_feature = mapping_feature.transpose(0,1)- LSTM Layer: 捕捉时序上的依赖关系,这可以表示成:
h_t^s = LSTM(m_t^s,h_{t-1}^s),\quad [h_1^s,...h_T^s] \in \mathbb{R}^{T \times U}
LSTM_layer = nn.LSTM(E,U,num_lstmlayer)
#初始化参数
h_0 = torch.randn(num_lstmlayer,batch_size,U)
c_0 = torch.randn(num_lstmlayer,batch_size,U)
output, (hn, cn) = LSTM_layer(mapping_feature, (h_0, c_0))
#output: T*batch*U
output = output.transpose(0,1)
hn = hn.squeeze(0) #now turn to batchsize * U
hn.shape
output.shape #100*30*10注意PyTorch里的LSTM层的输入参数,batch_size是在中间的,RNN也是这样。
- Temporal Attention Layer: 老生常谈的话题了,通过一个注意力层聚合同一个股票不同timesteps的特征信息得到该只股票的最终向量表示。这里直接放出公式:
\mathbf{a}^s = \sum_{i =1}^T a_t^s \mathbf{h}_t^s, \\ a_t^s = \frac{e^{\hat{a}_t^s}}{\sum_{i=1}^T e^{\hat{a}_t^s}},\\ \hat{a}_t^s = u_a^Ttanh(W_a \mathbf{h}_t^s+b_a)
对应的代码:
#Temporal attention layer
h_s = output.flatten(start_dim = 0,end_dim = 1)
layer = nn.Linear(U,Q,bias = True)
x = layer(h_s)
tanh = nn.Tanh()
x = tanh(x)
layer_2 = nn.Linear(Q,1,bias = False)
x = layer_2(x).squeeze(1)
x = x.reshape(batch_size,T)
weighted_vector = torch.exp(x)/torch.sum(torch.exp(x),dim = 1).unsqueeze(1)#weight of each time stamp
out = output.transpose(1,2)
weighted_vector = weighted_vector.unsqueeze(2)
a_s = torch.bmm(out,weighted_vector).squeeze(2)- Prediction Layer :注意,个股最终的向量表示是 a^s 和LSTM层最后一个timestamp输出cat的结果:
\mathbf{e}^s = [\mathbf{a}^s,\mathbf{h}_T^s]^T \in \mathbb{R}^{2U}
最终的涨跌标签预测:
\hat{y}^s = sign(W_P \mathbf{e}^s+b_P) \in\{-1,1\}
h_T = output[:,-1,:]
e_s = torch.cat([a_s,h_T],dim=1)
final_map = nn.Linear(e_s.shape[-1],1,bias = True)
y_s = torch.sign(final_map(e_s))#classification result完整的模型实现(代码有模糊处理)
class ALSTM(nn.Module):
def __init__(self,T,D,E,U,Q,num_lstmlayer):
super(ALSTM,self).__init__()
self.D = D
self.T = T
self.E = E
self.U = U
self.Q = Q
self.num_lstmlayer = num_lstmlayer
self.mapping_layer = nn.Linear(D,E,bias = True)
self.LSTM_layer = nn.LSTM(E,U,num_lstmlayer)
self.layer = nn.Linear(U,Q,bias = True)
self.layer_2 = nn.Linear(Q,1,bias = False)
self.tanh = nn.tanh()
def forward(self,origin_input):
batch_size = origin_input.shape[0]
origin_input = origin_input.flatten(start_dim = 0,end_dim = 1)
mapping_feature = self.tanh(mapping_layer(origin_input))
mapping_feature = mapping_feature.reshape(batch_size,T,-1)
mapping_feature = mapping_feature.transpose(0,1)
#LSTM Embedding
h_0 = torch.rand(self.num_lstmlayer,batch_size,self.U)
c_0 = torch.randn(self.num_lstmlayer,batch_size,self.U)
output, (hn, cn) = self.LSTM_layer(mapping_feature, (h_0, c_0))
output = output.transpose(0,1)
hn = hn.squeeze(0) #now turn to batchsize * U
#Temporal attention layer
h_s = output.flatten(start_dim = 0,end_dim = 1)
x = self.layer(h_s)
x = self.tanh(x)
x = self.layer_2(x).squeeze(1)
x = x.reshape(batch_size,self.T)
weighted_vector = torch.exp(x)/torch.sum(torch.exp(x),dim = 1).unsqueeze(1)#weight of each time stamp
#feature aggreagation and final output
out = output.transpose(1,2)
weighted_vector = weight_vector.unsqueeze(2)
a_s = torch.bmm(out,weighted_vector).squeeze(2)
h_T = output[:,-1,:]#last output of the hidden layers of the LSTM block
es = torch.cat([a_s,h_T],dim=1)
return esAdversarial Training
针对分类问题,本文的损失函数主要基于Hinge Loss:
l(y^s,\hat{y}^s) = max(0,1-y^s*\hat{y}^s)
因此我先实现了一个类:
class HingeLoss(nn.Module):
def __init__(self):
super(HingeLoss,self).__init__()
def forward(self,y_label,y_predict):
#y_label,y_predict都是长度为batch_size的一维tensor
if y_label.shape == y_predict.shape:
loss = torch.sum(torch.max(torch.zeros_like(y_label),torch.ones_like(y_label)-y_label * y_predict))
return loss
else:
raise Exception("The size of label and predicted value is not equal !")所谓对抗学习,即在每次迭代训练的时候,给一个batch内的数据添加一个自适应的perturbation,相应的仍然计算这些攻击样本的输出并纳入损失函数,从而提高模型的泛化能力。基于前文给出的最终向量表示 e^s , 先计算一次hinge loss,并计算loss对于 e^s 的梯度,从而构造对抗样本:
e_{adv}^s = e^s + \epsilon \frac{g^s}{||g^s||}, \quad g^s = \frac{\partial l(y^s,\hat{y}^s)}{\partial e^s}
#构造对抗样本函数
def get_adv(origin_input,y_label,final_map,model,epsilon,criterion):
origin_input: batch_size * T * feature_dim
y_label: batch_size
final_map: final mapping layer
model: Attentive lSTM
epsilon: learning rate to control the adv examples
criterion: loss function
e_s = model(origin_input)
e_s.retain_grad()
y_s = torch.sign(final_map(e_s)).squeeze(1)
loss_1 = criterion(y_s,y_label)
g_s = torch.autograd.grad(outputs = loss_1,inputs=e_s,grad_outputs=None)[0]
g_snorm = torch.sqrt(torch.norm(g_s,p = 2))
if g_snorm == 0:
return 0
else:
r_adv = epsilon(g_s/g_snorm)
return r_adv.detach()从而得到对抗样本的输出 \hat{y_{adv}}^s 。最终的损失函数可以表示为:
\Gamma_{adv} = \sum_{s = 1}^S l(y^s,\hat{y}^s) + \beta\sum_{s = 1}^S l(y^s,\hat{y}_{adv}^s) + \frac{\alpha}{2} ||\Theta||_F^2
最后一项是模型复杂度的L2正则化,单次BP的过程如下(代码经过模糊处理):
#input batch data
origin_input = torch.randn(batch_size,T,D)
y_label = torch.ones(batch_size)
#hyper parameters
batch_size = 100
D = 40 #原始的单日的特征维度数
T = 30 #单个样本用于预测所使用的数据的天数
E = 30 #映射后的特征维度数
U = 10 #LSTM网络中的隐藏维度数
Q = 10
num_lstmlayer = 1
beta = 1
#building model
model = ALSTM(T,D,E,U,Q,num_lstmlayer)
final_map = nn.Linear(2*U,1,bias = True)
criterion = HingeLoss()
#L2 normalization
weight_list,bias_list = [],[]
for name,p in model.named_parameters():
if 'bias' in name:
bias_list += [p]
else:
weight_list += [p]
optimizer = optim.SGD([{'params': weight_list, 'weight_decay':1e-5},
{'params': bias_list, 'weight_decay':0}],
lr = 1e-3,
momentum = 0.9)
#初始化:Xavier Initialization
for n in model.modules():
if isinstance(n,nn.Linear): #线性全连接层初始化
n.weight = nn.init.xavier_normal_(n.weight, gain=1.)
#forward propogation
#得到e_s
e_s = model(origin_input)
y_s = torch.sign(final_map(e_s)).unsqueeze(1)
r_adv = get_adv(origin_input,y_label,final_map,model,1e-2,criterion)
e_adv = e_s + r_adv
y_adv = torch.sign(final_map(e_adv)).squeeze(1)
#计算loss