|
|
|


怎么确定LDA的topic个数?
面试时,由于之前用过LDA做推荐,面试官就问怎么确定LDA的topic个数,我就实话实说是自己拍的,面试官就一个劲问“你觉得合理吗?你难道就这么草率吗…
关注者
557
被浏览
291,420
20 个回答

使用gensim包的童鞋注意了,千万不要用log_perplexity()计算的perplexity指标来比较topic数量的好坏!因为这个函数没有对主题数目做归一化,因此不同的topic数目不能直接比较!
( https:// groups.google.com/forum /#!searchin/gensim/topic $20coherence|sort:relevance/gensim/krs1Uytq5bY/ePZXIKfwGwAJ )

<以下是原回答>
我最近也遇到了这个问题。
刚开始我用的Blei论文里推荐的perplexity指标来评价模型的效果,但是我的结果是topic数目越多,perplexity越大,这跟大多数的论文和前人实践得到的结果相反。。。网上google了一下竟发现有不少人跟我有一样的问题,我到现在也不知道是什么原因~
后来我在gensim包的google group里发现有人提出了相同的疑问,gensim包的作者Radim现身回答说perplexity不是一个好的评价topic质量的指标,这个学术界也有论文阐述了这一点,我看到过。( https:// groups.google.com/forum /#!searchin/gensim/perplexity%7Csort:relevance/gensim/TpuYRxhyIOc/98kCvxcpDLcJ )

group里面另外一位大神推荐使用一个新的指标叫topic coherence来评价模型的好坏,具体可见这里 America’s Next Topic Model 。



2018-5-21 补充: Select number of topics for LDA model
R中有个新包(ldatuning)可以直接使用四种方法确定最有的主题数,详情见上面的连接,这个包要和 “topicmodels”包配合使用
1、基于经验 主观判断、不断调试、操作性强、最为常用
2、基于困惑度 (主要是比较两个模型之间的好坏) Blei 2003年原论文


该方法需要测测试集!
参考文献:Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation [J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
3、贝叶斯统计标准方法
参考文献:Griffiths T L, Steyvers M. Finding Scientific Topics [J]. Proceedings of the National Academy of Sciences of the United States of America, 2004, 101(S1): 5228-5235.
使用Log-边际似然函数的方法,这种方法也挺常用的
4、非参数方法:Teh提出的基于狄利克雷过程的HDP法
参考文献:Teh Y, Jordan M, Beal M, et al. Hierarchical Dirichlet Processes [J]. Journal of the American Statistical Association, 2007, 101(476): 1566-1581.
在《机器学习系统设计》的第4章主题模型的4.3节:选择主题个数 中,提到:“有一个能够自动确定主题个数的方法叫做层次狄利克雷过程(HDP)“在该方法中,主题本身是由数据生成的,而不是预先将主体固定,然后通过对数据的反向工程把它们恢复出来。
在论文《 Hierarchical Dirichlet Process 》第6章中,如下图所示,HDP模型和LDA模型的Perplexity-topic number曲线:
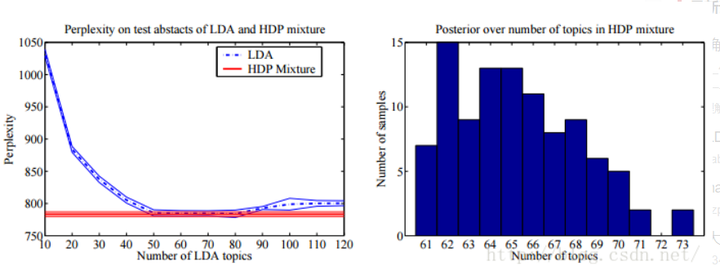
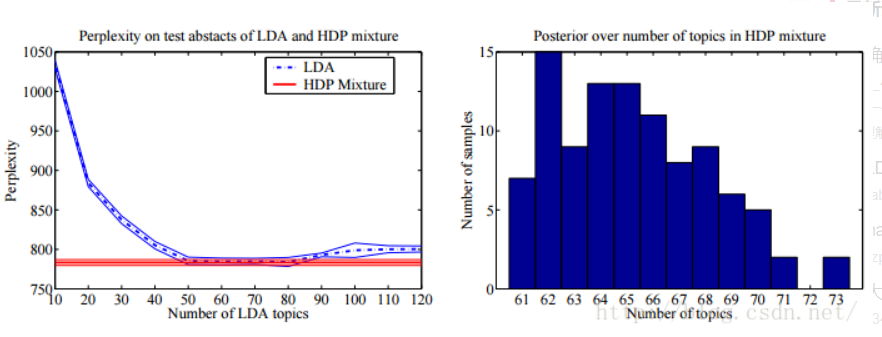
通过分析该HDP中混合成分抽样直方图发现,最佳的混合成分数正好与LDA的最优主题数一致,从而解决LDA中最优topic个数的选择问题。
( 这个方法说实话我看不懂 )
5、基于主题之间的相似度: 计算主题向量之间的余弦距离,KL距离等
参考文献:曹娟, 张勇东, 李锦涛, 等. 一种基于密度的自适应最优LDA 模型选择方法 [J]. 计算机学报, 2008, 31(10): 1780-1787. (Cao Juan, Zhang Yongdong, Li Jintao, et al. A Method of Adaptively Selecting Best LDA Model Based on Density [J]. Chinese Journal of Computers, 2008, 31 (10): 1780-1787.)
这篇文章提到一个定理:当主题结构的平均相似度最小时,对应的模型最优。
(我用自己的语料库试过这个方法,当语料库比较小,主题向量非常稀疏的时候感觉是有问题的)
关鹏, 王曰芬. 科技情报分析中LDA 主题模型最优主题数 确定方法研究[J]. 现代图书情报技术, 2016(9): 42-49. (Guan Peng, Wang Yuefen. Research on the Method of Determining the Optimum Topic Number of LDA Topic Model in Scientific and Technical Information Analysis [J]. New Technology of Library and Information Service, 2016(9): 42-49.)
这篇文章的核心方法如下:
主题方差用来度量主 题和其均值之间的偏离程度, 可以衡量潜在主题空间 的整体差异性和稳定性。主题方差的计算方法如下:


其中, T 表示LDA 抽取的主题, K 表示主题数目,DJS 表示JS 散度。Var(T)衡量了主题之间的稳定性和差异性, 当Var(T)越大时, 主题之间的差异性越大, 主题之间的区分性就越好, 这样的主题结构就越稳定。困惑度反映了模型的预测能力, 但一味追求模型的预测能力则必然导致抽取的主题数过大的问题, 所以二者相结合可以有效解决主题辨识度不高的问题。


其中, Dtest 为实验文本集中的测试数据集,Perplexity(Dtest ) 为测试数据集的困惑度, Var(Ttest )是测试数据集的主题方差。
Perplexity-Var 指标含义: 首先, 考虑到模型的泛化能力, 当Perplexity 越小时, LDA 的泛化能力越好。其次, 考虑到LDA 的主题抽取效果, 当主题结构的平均相似度最小时, 对应的LDA 主题模型最优[21], 而主题结构的平均相似度越小, 则主题之间的差异就越大,此时主题结构的方差越大。所以当主题方差越大时,LDA主题抽取的效果越佳, 同时Perplexity-Var 指标就越小。综合以上分析, 当Perplexity-Var指标最小时, 对应的LDA 主题模型最优。
我们希望方差越大(主题之间有区分度)越好,同时也希望困惑度越小越好,因此perplexity-var指标越小越好!
用测试集来进行测试,一般来说方差不断降低,困惑度先降低后上升,perplexity-var指标先下降后上升,取最小的点即为最优的主题数目。