


【R机器学习:mlr3verse技术手册】V 超参数调参


5 超参数调参
机器学习的 模型参数 是模型的一阶(直接)参数,是训练模型时用梯度下降法寻优的参数,比如正则化回归模型的回归系数;而 超参数 是模型的二阶参数,需要事先设定为某值,才能开始训练一阶模型参数,比如正则化回归模型的惩罚参数、KNN的邻居数等。
超参数会对所训练模型的性能产生重大影响,所以不能是随便或凭经验随便指定,而是需要设定很多种备选配置,从中选出让模型性能最优的超参数配置,这就是 超参数调参 。
超参数调参是用
mlr3tuning
包实现,其一般过程如下:
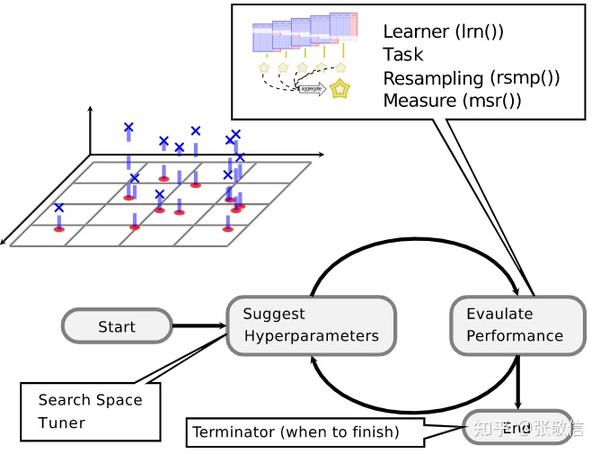

超参数调参是一项多方联动的系统工作,需要设定: 搜索空间、学习器、任务、重抽样策略、模型性能度量指标、终止条件 。
首先要知道学习器包含哪些超参数:
library(mlr3verse)
learner = lrn("classif.svm") # 支持向量机分类
learner$param_set # 查看学习器的超参数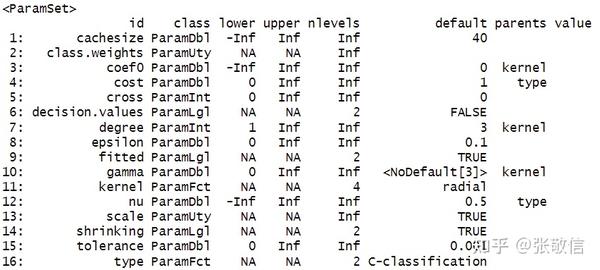

id
列就是超参数的名字,
default
列是默认值。
5.1 独立调参
适合传统的机器学习套路:将数据集按留出法重抽样划分为训练集和测试集,在训练集上做内层重抽样,多次“训练集拟合模型+验证集评估性能”,根据平均性能选出最优超参数。
下面用一个简单案例来演示独立调参的基本过程。
(1) 选取任务,划分数据集,将测试集索引设置为留出
task = tsk("iris")
split = partition(task, ratio = 0.8)
task$set_row_roles(split$test, "holdout")
(2) 选择学习器,同时指定部分超参数,需要调参的超参数用
to_tune()
设定搜索范围:
learner = lrn("classif.svm", type = "C-classification", kernel = "radial",
cost = to_tune(0.1, 10),
gamma = to_tune(0, 5))
注:
to_tune()
支持多种方式的输入,可参阅帮助。
(3) 用
tune()
对学习器做超参数调参,需要设定(有些是可选):
-
method:调参方法,支持"grid_search"(网格搜索)、"random_search"(随机搜索)、gensa(广义模拟退火)、"nloptr"(非线性优化); -
task:任务; -
learner:带调参的学习器或普通学习器; -
resampling:重抽样策略; -
measures:模型性能评估指标,可以是多个; -
search_space:普通学习器,需要设置搜索空间; -
term_evals/term_time/terminator:终止条件,允许评估次数/允许调参时间(秒)/终止器对象; -
store_models:是否保存每次的模型; -
allow_hotstart:是否允许热启动预拟合模型; -
resolution:网格分辨率,网格搜索法的配套参数; -
batch_size:批量大小,每批放几组超参数配置,以并行加速。
对
cost, gamma
执行
5 × 5
网格调参,性能指标选择分类错误率,采用 5 折交叉验证:
instance = tune(
method = "grid_search",
task = task,
learner = learner,
resampling = rsmp("cv", folds = 5),
measure = msr("classif.ce"),
resolution = 5) # 调参过程(部分)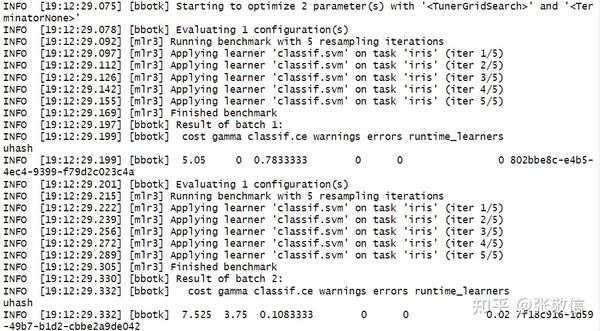
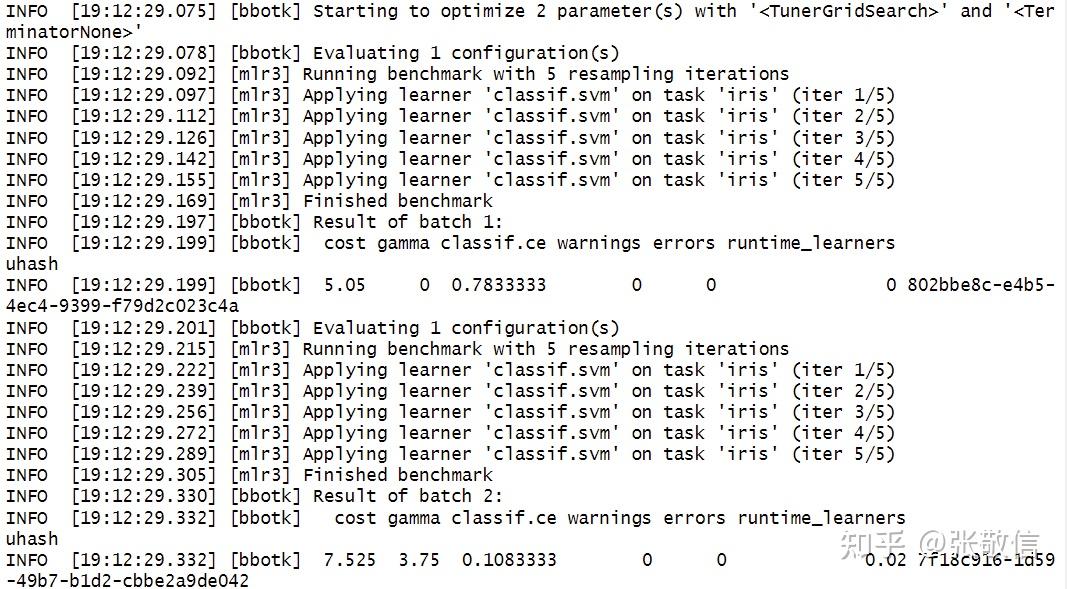
(4) 提取超参数调参结果
instance$result # 调参结果

instance$archive # 调参档案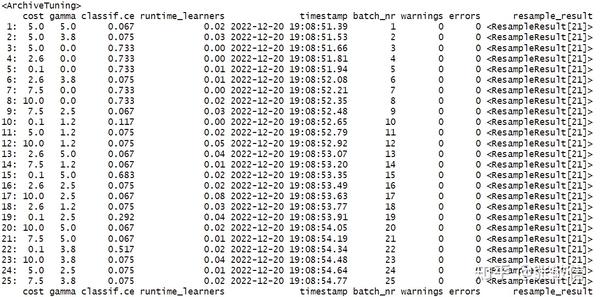
# 可视化调参结果
autoplot(instance, type = "surface", cols_x = c("cost", "gamma")) 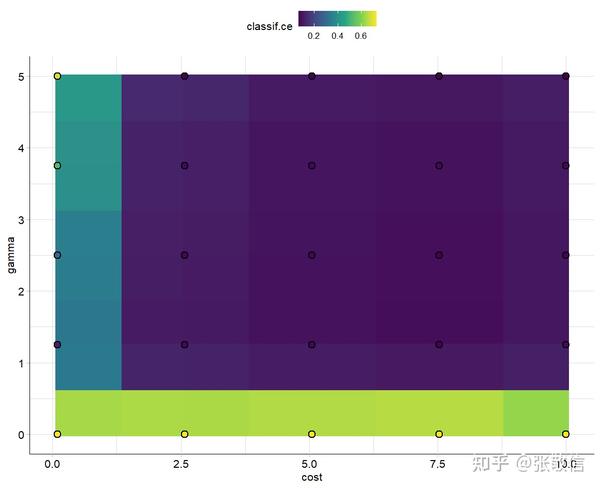
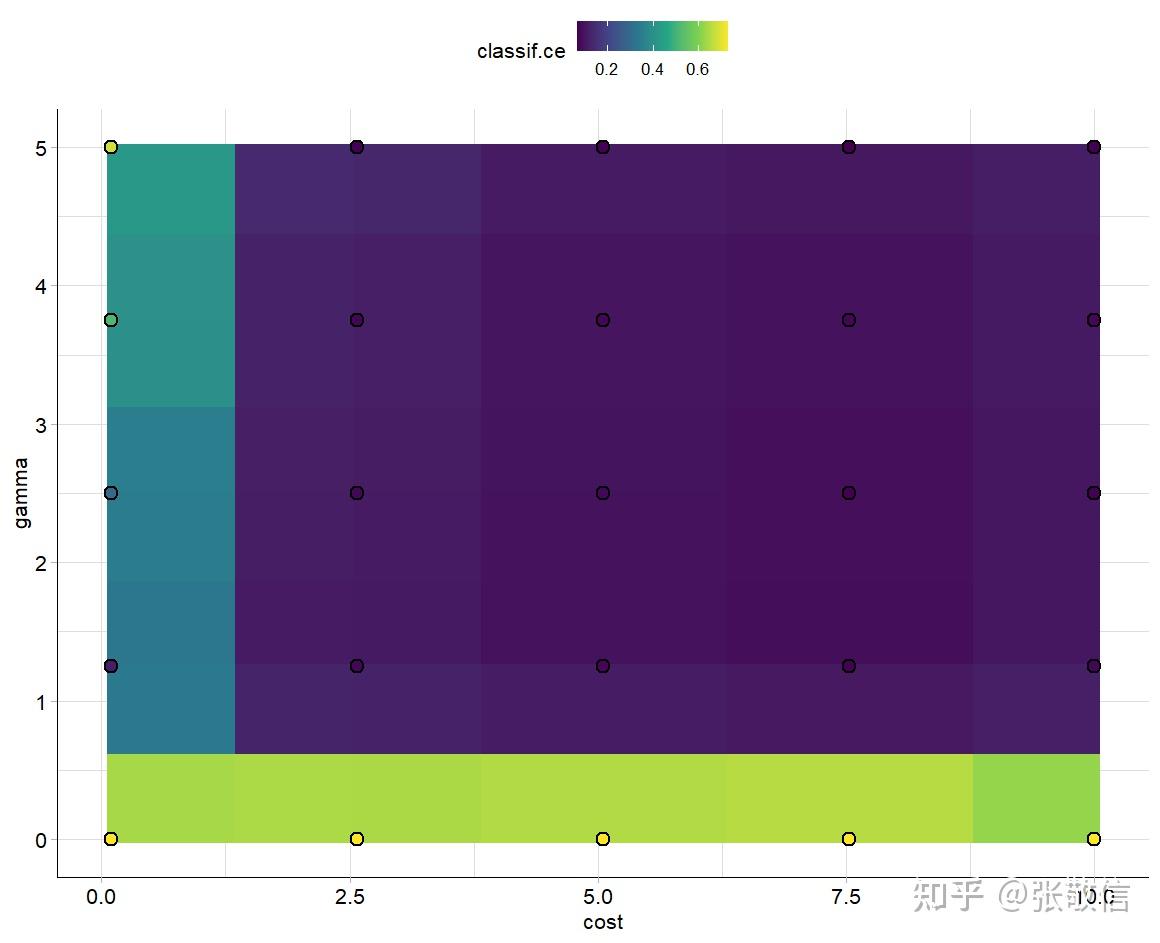
(5) 用最优超参数更新学习器参数,在训练集上训练模型,在测试集上做预测
learner$param_set$values = instance$result_learner_param_vals
learner$train(task)
predictions = learner$predict(task, row_ids = split$test)
predictions

5.2 自动调参器
上述独立调参有两个不足:
- 调参得到的最优超参数需要手动更新到学习器;
- 不方便实现嵌套重抽样。
自动调参器可以弥补上述不足,
AutoTuner
是将超参数调参与学习器封装到一起,能实现自动调参的过程,并且可以像其他学习器一样使用。
下面用同样的简单案例,来演示自动调参的一般过程,同时改用 嵌套重抽样 。
(1) 创建任务、选择学习器
task = tsk("iris")
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
(2) 用
ps()
生成搜索空间,用
auto_tuner()
创建自动调参器,注意:不需要提供任务,其它参数与独立调参的
tune()
基本一样:
search_space = ps(cost = p_dbl(0.1, 10), gamma = p_int(0, 5))
at = auto_tuner(
method = "grid_search",
learner = learner,
search_space = search_space,
resampling = rsmp("cv", folds = 5),
measure = msr("classif.ce"),
resolution = 5)
(3) 外层采用 4 折交叉验证重抽样,设置
store_models = TRUE
保存每次的模型:
rr = resample(task, at, rsmp("cv", folds = 4), store_models = TRUE) # 自动调参过程(部分)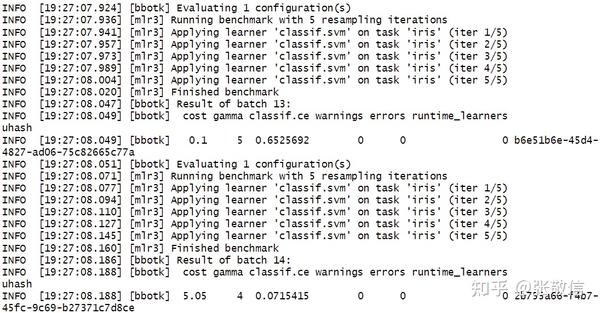
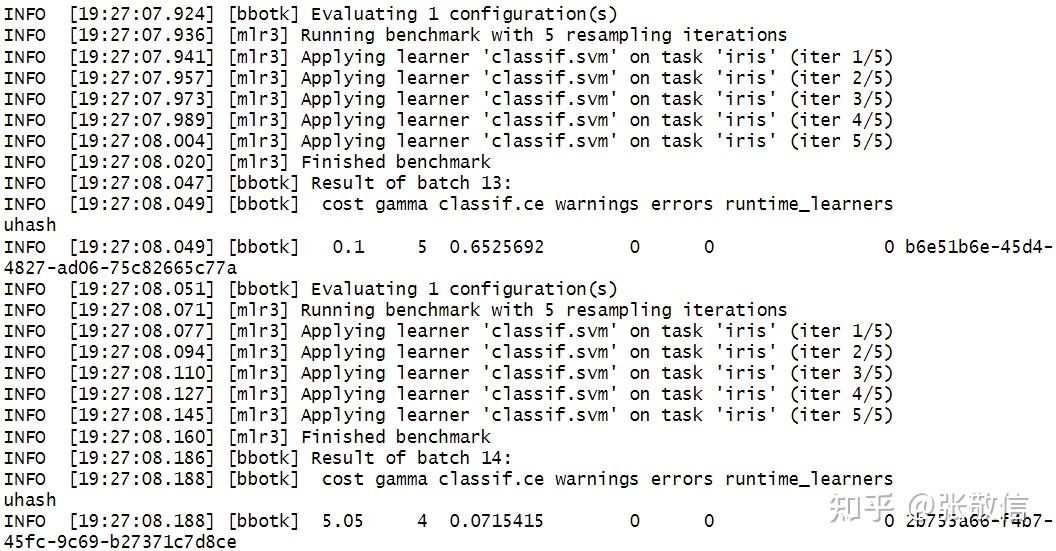
这就是执行嵌套重抽样,外层(整体拟合模型+评估)循环 4 次,每次内层(超参数调参)循环 5 次。查看结果:
rr$aggregate() # 总的平均模型性能, 也可以提供其它度量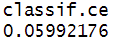
rr$score() # 外层4次迭代的每次结果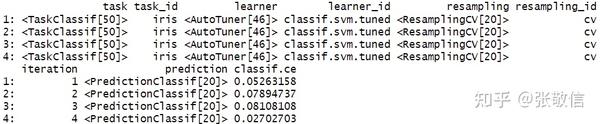
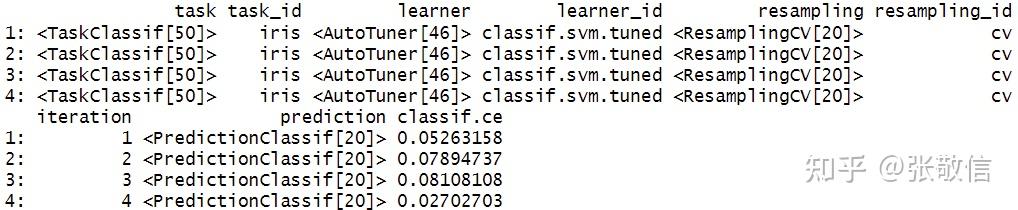
extract_inner_tuning_results
(rr) # 内层每次的调参结果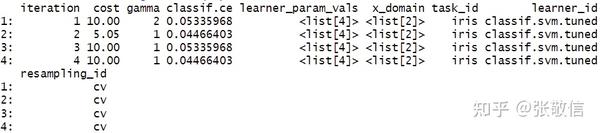
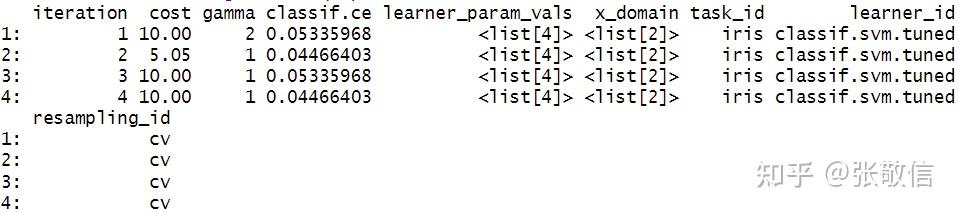
xtract_inner_tuning_archives(rr) # 内层调参档案(部分)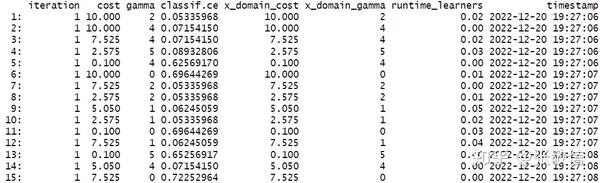


(4) 在全部数据上自动调参,预测新数据
at$train(task) # 部分
dat = task$data()[1:5,-1]
at$predict_newdata(dat)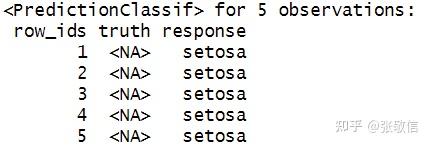
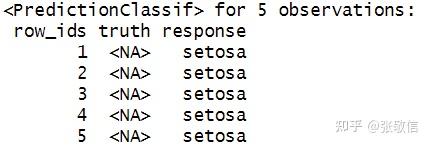
注: 调参结束后,也可以取出最优超参数,更新学习器参数:
learner$param_set$values = at$tuning_result$learner_param_vals[[1]]或者按最优超参数重新创建学习器。
另外,上述的“自动调参+外层重抽样”,若改用嵌套调参
tune_nested()
实现,代码会更加简洁:
rr = tune_nested(
method = "grid_search",
task = task,
learner = learner,
search_space = search_space,
inner_resampling = rsmp ("cv", folds = 5),
outer_resampling = rsmp("cv", folds = 4),
measure = msr("classif.ce"),
resolution = 5)5.3 定制搜索空间
用
ps()
创建搜索空间,它支持 5 种超参数类型构建:


其主要参数有:
-
lower, upper:数值型参数(p_dbl和p_int)的下限和上限; -
levels:p_fct参数允许的类别值; -
trafo:变换函数; -
depends:依赖关系。
示例:
search_space = ps(cost = p_dbl(0.1, 10),
kernel = p_fct(c("polynomial", "radial")))5.3.1 变换
对于数值型超参数,在调参时经常希望前期的点比后期的点更密集一些。这可以通过对数-指数变换来实现,这也适用于大范围搜索空间。
道理如下图所示:
library(tidyverse)
tibble(x = 1:20,
y = exp(seq(log(3), log(50), length.out=20))) %>%
ggplot(aes(x, y)) +
geom_point()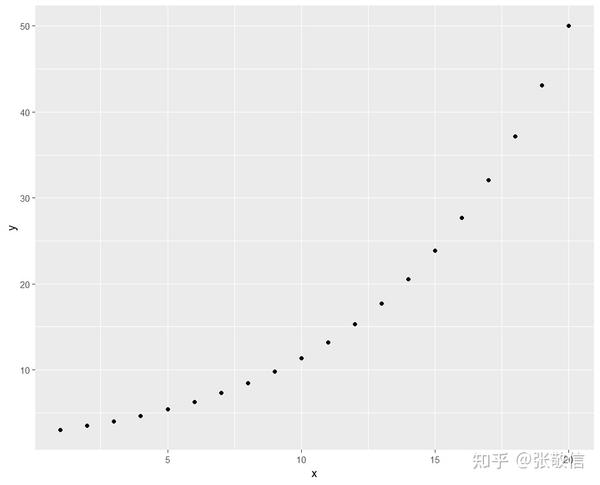

就是希望当 x 均匀变化时,变换后作为超参数能前密后疏。
search_space = ps(
cost = p_dbl(log(0.1), log(10),
trafo = function(x) exp(x)),
kernel = p_fct(c("polynomial", "radial")))
查看调参网格(取分辨率
=5
):
params = generate_design_grid(search_space, resolution = 5)
params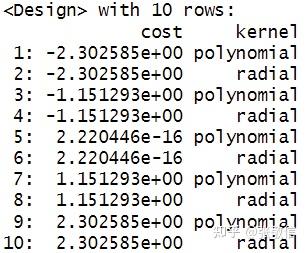
cost
值是等差网格结果同
seq(log(0.1), log(10), length.out = 5)
, 将作为超参数值使用的是
exp(cost)
:
params$transpose() |> data.table::rbindlist()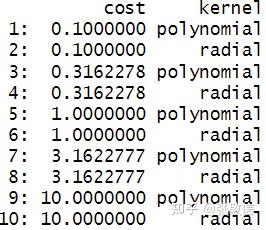
注:
若为
cost
自定义若干数值,用
p_fct()
, 例如
cost = p_fct(c(0.1, 3, 10))
。
5.3.2 依赖关系
有些超参数只有在另一个参数取某些值时才有意义。
例如,支持向量机有一个
degree
参数,只有在
kernel
为
"polynomial"
时才有效。这可以用
depends
参数来指定:
search_space = ps(
cost = p_dbl(log(0.1), log(10), trafo = function(x) exp(x)),
kernel = p_fct(c("polynomial", "radial")),
degree = p_int(1, 3, depends = kernel == "polynomial"))5.4 图学习器调参
图学习器一旦成功创建,就可以像普通学习器一样使用,超参数调参时,原算法的超参数名字都自动带了学习器名字前缀,另外还可以对管道参数调参。
下面是一个复杂的图学习器超参数调参实例:
task = tsk("pima")该任务包含缺失值,还有若干因子特征,都需要做预处理:插补和特征工程。
prep = gunion(list(
po("imputehist"),
po("missind", affect_columns = selector_type(c("numeric","integer"))))) %>>%
po("featureunion") %>>%
po("encode") %>>%
po("removeconstants")
选择三个学习器:
KNN、SVM、Ranger
作为三分支分别拟合模型,再合并分支保证是一个输出结果:
learners = list(
knn = lrn("classif.kknn", id = "kknn"),
svm = lrn("classif.svm", id = "svm", type = "C-classification"),
rf = lrn("classif.ranger", id = "ranger"))
graph = ppl("branch", learners)将预处理图和算法图连接得到整个图,并可视化图:
graph = prep %>>% graph
graph$plot()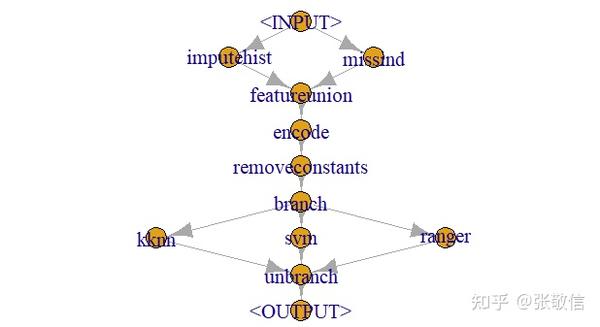

转化为图学习器,查看其超参数:
glearner = as_learner(graph)
glearner$param_set 



可见,所有超参数都多了学习器或管道名字前缀,比如
kknn.k
是
KNN
学习器的邻居数参数
k
。
嵌套重抽样超参数调参,与前文语法一样,为了加速计算,启动并行:
# future::plan("multicore") # win系统不支持多核
future::plan("multisession") # 只支持多线程(异步)
设置搜索空间,用
tune_nested()
做嵌套调参:
search_space = ps(
branch.selection = p_fct(c("kknn", "svm", "ranger")),
kknn.k = p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"),
svm.cost = p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"),
ranger.mtry = p_int(1, 8, depends = branch.selection == "ranger"))
rr = tune_nested(
method = "random_search",