data
=
[
[
10
,
100
]
,
[
14
,
120
]
,
[
16
,
180
]
]
df
=
pd
.
DataFrame
(
data
,
columns
=
[
'feature1'
,
'feature2'
]
,
index
=
[
1
,
2
,
3
]
,
dtype
=
float
)
-
运行结果如下:
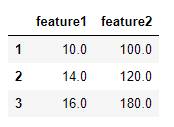
-
dataframe存储为mat。注意这里我把df的索引和列名都转换成了
列表
,否则生成的mat文件中这俩都会变成struct类型,不显示具体数值。
PATH = "C:\\Users\\WIN\\Desktop"
Ind = list(df.index)
Col = list(df.columns)
mat = scio.savemat(PATH+'\\'+'sample.mat',{'data':df.values,'index':Ind,'cols':Col})
至此已成功转化为mat文件。导入到matlab,工作区显示如下:
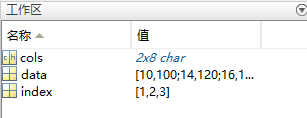
data变量
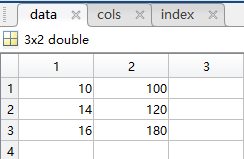
另外,原dataframe的列名现在是char型变量cols(‘feature1’,‘feature2’),原dataframe的索引值现在是变量index。
当然,如果不需要索引和列名,可以在savemat时只保留’data’的键值对~
前言:需要预先安装好 scipy.io 和 pandas 模块具体步骤先创建一个dataframe数据import scipy.io as scioimport pandas as pddata = [[10,100],[14,120],[16,180]]df = pd.DataFrame(data,columns = ['feature1','feature2'],index = [1,2,3],dtype = float)df运行结果如下:dataframe存储为..
def SaveMat(sorted_data):
# transfer the data type
sorted_data['pre'] = sorted_data['pre'].astype(int)
# save the prediction ...
Python中操作.mat文件的方法。有时在python得到一些数据,需要作出曲线数据图,但是使用python中的matplotlib库作图比较单一,不能很好的展示图像。那么就需要把数据保存,然后在matlab中作图。代码如下
# -*- coding: utf-8 -*-
@author: Life696
仅供学习、交流使用
import scipy.io as scio...
构建dataframe
data = {'year': [2000,2000,2000, 2001,2001,2001, 2002,2002,2002, 2003, 2003, 2003],
'month': [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3,],
'ws':np.random.randint(7, size=12)}
frame = pd.Dat
在做科研工作时,我们不仅从理论角度分析所提 idea 的种种优势,还需要进行大量的实验,得到的实验效果可以进一步地支撑 idea 的优越性,这样更具有说服力。实验所使用的数据集作为实验的重要组成部分,我们往往需要对拿来的数据集进行数据预处理工作,因为通常使用的数据集往往都是来自各行各业的数据,而一个数据集往往具有多个属性,每个属性的值是否使用的同一量纲,这往往是个问题,如果不是采用同一个量纲进行评价,得到的值放在一起进行运算,是否公正合理?
因此,归一化处理工作尤为重要,我们要将不同量纲的表达式变为无量纲,
python保存数据为.mat文件:
import scipy.io
scipy.io.savemat('SF0.mat', mdict={'label_test': label_test, 'predlabel': predlabel,})
#SF0.mat为保存的自定义文件名,label_test、predlabel为需要保存的数据
读取.mat文件:
import scipy.io
data = scipy.io.loadmat('SF0.mat')
此时读取的数据为字典格式
data.keys(
test是一个5行3列的dataFframe
# dataframe存进文件中
test.to_csv("test.csv",index=None,header=None) #方法一
test.to_csv("test.txt",index=None,header=None,sep='\t')#方法二
# dataframe转为array
test_values = test.values #方法一
test.as_matr
python中
DataFrame格式
文件保存为excel时不保留索引和列名的方法
只需要将index设置为False,将header设置为None即可!
start_end_point.to_excel(r'D:\我的论文\基于复杂网络的长三角主要城市协同性研究\2021-04-10数据\熵权Critic法起终点城市经纬度.xlsx',index=False,header=None)
index表示设置是否保存索引(就是行号),header表示设置是否保存表头(就是列名)!
问题描述:处理多个文件,每个文件出一个结果,综合这些结果,然后存成.mat文件方便matlab读取。注:三个部分,读取文件夹中多个文件;python中list操作,将数据从python中存到matlab,每个在网上都有各自的解决方案,这里做个总结。1. 读取文件夹中多个文件。import os
path = ''
files = []
for file in os.walk(path):
fi...
将
python程序中的数据保存为.
mat格式数据,方便后续导入到
matlab中进行处理分析。
可调用已有接口:scipy.io.save
mat(file_name, mdict)
file_name为保存的
文件名
mdict为一个字典,其中包含了要保存的变量名和对应的值。
实例代码如下:分别保存int, string, list, dict, array类型数据到一个.
mat文件。看一下效果如何。
from scipy.io import save
mat
import numpy as
首先我们谈谈MarkDown编辑器,我感觉些倒是挺方便的,因为用惯了LaTeX,对于MarkDown还是比较容易上手的,但是我发现,MarkDown中有这样几个问题一直没能找到具体的解决方法:
图片大小的问题。在LaTeX中我们可以调整图片的大小,以适应整个文本;字体,字号大小的设置。在MarkDown里面标题倒是挺大的,但是正文却显得太小,不是很喜欢里面的字体。
主要发现上面两个

