


深度学习模型的流式部署

这篇文章意在与大家分享一些模型部署方面的工作,在之前的项目落地过程中,既野蛮粗暴过,也精耕细作过,当然最终都是追求正确和高效。
- 先看看几种可行的 终端部署方式 :
1、C代码部署;2、Tensorflow-lite部署;3、定制化的模型部署(如MNN、ncnn)。
- 着重音视频领域 流式处理 (逐帧输入逐帧输出),本帧输出需利用历史帧信息。
1.C代码部署
此方式部署难度最大,需要对每个算子 运算方式 有深入的理解和对 内存空间 有十足的把控能力。
例如:
①卷积(padding/dilation_rate/bias…)、LSTM、LayerNorm算子的运算细节。
②算子权重的存储方式(提高cache命中率)、中间状态的变量存储和计算(对历史信息的索引、指令优化)。
优点:算子细节调整灵活,精致的优化可以实现最小的开销。
缺点:落地周期长、工作量大,内存、开销优化效率参差不齐。
这种方式对小且简单的模型实现尚可承受,但是对于复杂的大模型来说,建议先准备几口好碗,时刻准备随时可能喷出的“老血”,O(∩_∩)O哈哈~。这种事情没有人会想做第二次的,光是结果对齐这件事情。。。自行体会。
2.Tensorflow-lite部署
先看看官方主页的介绍:
TensorFlow Lite is a mobile library for deploying models on mobile, microcontrollers and other edge devices .
TensorFlow inference APIs are provided for most common mobile/embedded platforms such as Android, IOS and Linux.
TensorFlow Lite interpreter and perform an inference using C++, Java, and Python 。
这个边界线完全没有拒绝的理由,所以这也是一些中小公司常用的部署方式(有别于一些大公司会自己开发推理框架进行部署)。
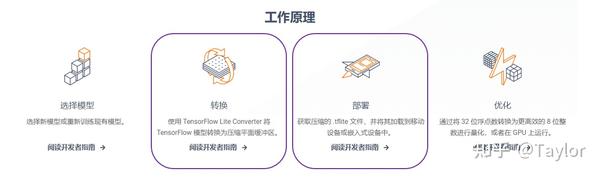
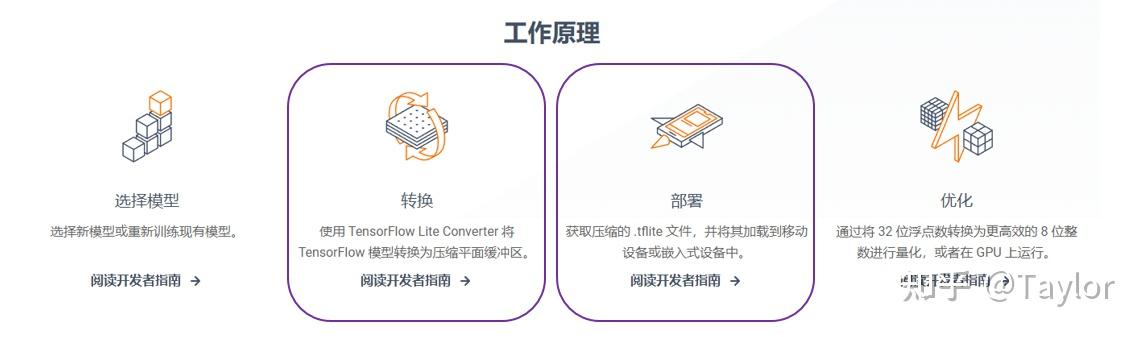
相信看到这里的同学对模型训练已经非常熟悉了,本文的重点就放在模型转换和模型部署。
模型转换
TensorFlow Lite 是一种用于设备端推断的开源深度学习框架。可帮助开发者在移动设备、嵌入式设备和IoT设备上运行 TensorFlow 模型。
那就从tensorflow/keras说起,可以保存的模型后缀.pb和.hdf5,都可以方便地转换为tenforflowlite模型,后缀.tflite。
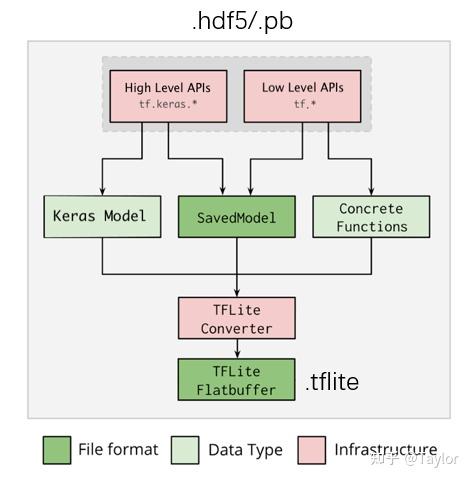
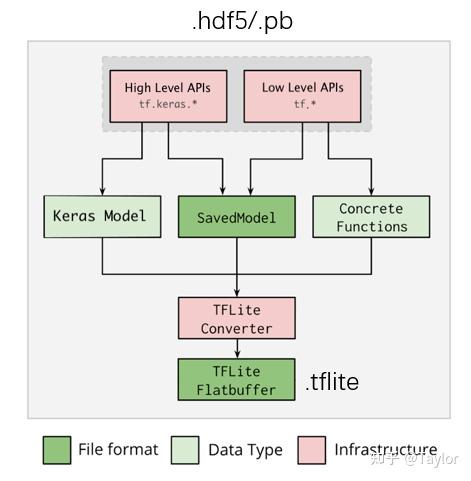
具体有两种实现方式:
- PYTHON API 转换(推荐)
import tensorflow as tf
# Convert the model
# 转换 Keras (hdf5)
converter = tf.lite.TFLiteConverter.from_keras_model(saved_model_dir)
# 转换 SavedModel (pb)
# converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# Save the model.
with open('model.tflite', 'wb') as f:
f.write(tflite_model)常见错误:Some ops are not supported by the native TFLite runtime, you can enable TF kernels fallback using TF Select. See instructions: <ahref=" https://www. tensorflow.org/lite/gui de/ops_select ">
https://www. tensorflow.org/lite/gui de/ops_select </a> TF Select ops:
原因:模型包含缺少对应的 TFLite 实现的 TF OPs,例如fft/ifft的复数运算。
方案:将这些算子移到模型外实现,如果模型中间有此类算子,那就只能将原模型拆成两个甚至多个子模型。
- 命令行 转换
# 转换 Keras (hdf5)
tflite_convert \
--keras_model_file=/tmp/mobilenet_keras_model.h5 \
--output_file=/tmp/mobilenet.tflite
# 转换 SavedModel (pb)
tflite_convert \
--saved_model_dir=/tmp/mobilenet_saved_model \
--output_file=/tmp/mobilenet.tflite流式模型改造
先捋一下三个模型之间的关系:
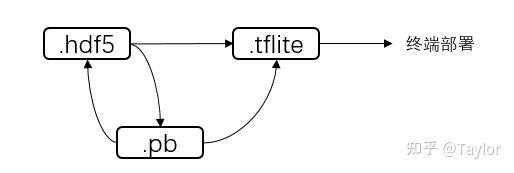
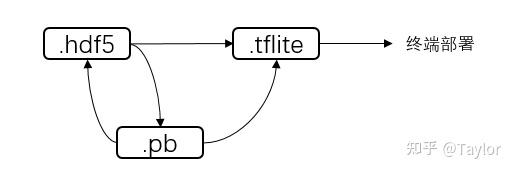
其中,.hdf5/.pb和.tflite都可以用于 流式模型正确性验证 ,最后.tflite用于 流式模型部署 。
- 那流式模型和训练模型之间为什么会有差异?有什么样的差异呢 ?
这就要从二者的功能实现谈谈:训练过程为了提高训练效率,数据是并行处理的;流式推理过程,逐帧输入逐帧输出,数据是串行处理的,缺少历史信息缓存。
- 模型改造过程(重要) :
①如果模型中只使用当帧输入信息,转换时需要修正两点:
a.指定确切的单帧输入维度,每一个维度都要确定,一般比训练模型少一维batchsize。
b.将不支持的算子移到模型外,如fft。
②如果需要处理历史信息(数据、状态等),需要额外修正两点:
a.对于模型中存在RNN结构的模块(LSTM\GRU),需要将状态信息输出保存,作为下一帧的状态输入。
如 y = LSTM(self.numUnits, return_sequences=True)(x)
-> y, h_state, c_state = LSTM(self.numUnits, return_sequences=True,
return_state=True)(x, initial_state= [h_state, c_state] )
b.对于模型中需要使用历史信息的模块(空洞卷积\attention),需要在模型输入/输出加入缓存buff。
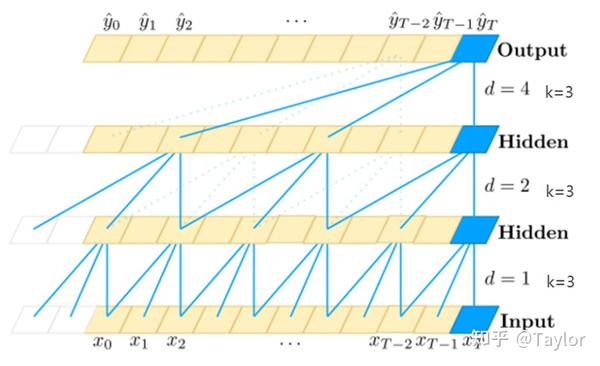
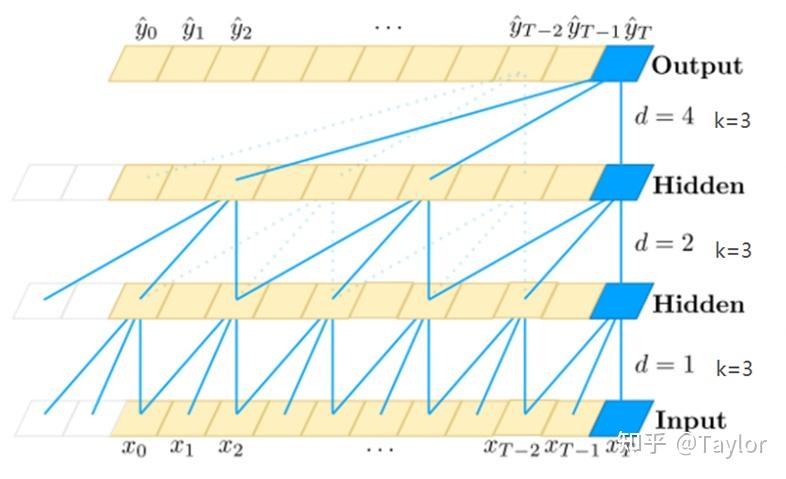
模型推理
- Load and run a model in Python,更多的作用是验证tflite模型的正确性(也可以用流式pb模型验证)
import numpy as np
import tensorflow as tf
# Load the TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="converted_model.tflite")
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Test the model on random input data.
input_shape = input_details[0]['shape']
input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
# The function `get_tensor()` returns a copy of the tensor data.
# Use `tensor()` in order to get a pointer to the tensor.
output_data = interpreter.get_tensor(output_details[0]['index'])
print(output_data)- Load and run a model in C++ ,用于端侧落地
Platforms: Android, iOS, and Linux
Note: C++ API on iOS is only available when using bazel.
class FlatBufferModel {
// Build a model based on a file. Return a nullptr in case of failure.
static std::unique_ptr<FlatBufferModel> BuildFromFile(
const char* filename,
ErrorReporter* error_reporter);
// Build a model based on a pre-loaded flatbuffer. The caller retains
// ownership of the buffer and should keep it alive until the returned object
// is destroyed. Return a nullptr in case of failure.
static std::unique_ptr<FlatBufferModel> BuildFromBuffer(
const char* buffer,
size_t buffer_size,
ErrorReporter* error_reporter);
模型加载和推理:
// Load the model
std::unique_ptr<tflite::FlatBufferModel> model =
tflite::FlatBufferModel::BuildFromFile(filename);
// Build the interpreter
tflite::ops::builtin::BuiltinOpResolver resolver;
std::unique_ptr<tflite::Interpreter> interpreter;
tflite::InterpreterBuilder(*model, resolver)(&interpreter);
// Resize input tensors, if desired.
interpreter->AllocateTensors();
// Fill `input`.