|
|
|


如何系统地学习Python 中 matplotlib, numpy, scipy, pandas?
关注者
15,447
被浏览
2,380,749
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

系统性总结了 Numpy/Pandas 所有知识点
原文链接:
1.0. 引入Numpy库
#引入numpy库
import numpy as np
1.1. 使用np.array创建数组
# 1. 使用np.array创建数组
a = np.array([1,2,
3,4])
#打印数组
print(a)
#查看类型
print(type(a))
1.2. 使用np.arange创建数组
#2. 使用np.arange创建数组
#创建0-10步数为2的数组 结果为[0,2,4,6,8]
b = np.arange(0,10,2)
1.3. np.random.random创建数组
#3. np.random.random创建一个N行N列的数组
# 其中里面的值是0-1之间的随机数
# 创建2行2列的数组
c = np.random.random((2,2))
1.4. np.random.randint创建数组
#4. np.random.randint创建一个N行N列的数组
# 其中值的范围可以通过前面2个参数来指定
# 创建值的范围为[0,9)的4行4列数组
d = np.random.randint(0,9,size=(4,4))
1.5. 特殊函数
#5. 特殊函数
#5.1 zeros
## N行N列的全零数组
### 例如:3行3列全零数组
array_zeros = np.zeros((3,3))
#5.2 ones
## N行N列的全一数组
### 例如:4行4列全一数组
array_ones = np.ones((4,4))
#5.3 full
## 全部为指定值的N行N列数组
### 例如:值为0的2行3列数组
array_full = np.full((2,3),9)
#5.4 eye
## 生成一个在斜方形上元素为1,其他元素都为0的N行N列矩阵
### 例如:4行4列矩阵
array_eye = np.eye(4)
1.6. 注意
数组中的数据类型必须一致,要么全部为整型,要么全部为浮点类型,要么全部为字符串类型
不能同时出现多种数据类型
2. 数组数据类型
2.1 数据类型
| 数据类型 | 描述 | 唯一标识符 |
|---|---|---|
| bool | 用一个字节存储的布尔类型(True或False) | b |
| int8 | 一个字节大小,-128 至 127 | i1 |
| int16 | 整数,16 位整数(-32768 ~ 32767) | i2 |
| int32 | 整数,32 位整数(-2147483648 ~ 2147483647) | i4 |
| int64 | 整数,64 位整数(-9223372036854775808 ~ 9223372036854775807) | i8 |
| uint8 | 无符号整数,0 至 255 | u1 |
| uint16 | 无符号整数,0 至 65535 | u2 |
| uint32 | 无符号整数,0 至 2 ** 32 - 1 | u4 |
| uint64 | 无符号整数,0 至 2 ** 64 - 1 | u8 |
| float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | f2 |
| float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | f4 |
| float64 | 单精度浮点数:64位,正负号1位,指数11位,精度52位 | f8 |
| complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | c8 |
| complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | c16 |
| object_ | python对象 | O |
| string_ | 字符串 | S |
| unicode_ | unicode类型 | U |
2.2 创建数组指定数据类型
import numpy as np
a = np.array([1,2,3,4,5],dtype='i1')
a = np.array([1,2,3,4,5],dtype=int32)
2.3 查询数据类型
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
d = np.array([Person('test1',18),Person('test2',20)])
print(d)
print(d.dtype)
2.4 修改数据类型
f = a.astype('f2')
2.5 总结
(1) Numpy是基于C语言编写,引用了C语言的数据类型,所以Numpy的数组中数据类型多样
(2) 不同的数据类型有利于处理海量数据,针对不同数据赋予不同数据类型,从而节省内存空间
3. 多维数组
3.1 数组维度查询
import numpy as np
# 数组维度
## 维度为1
a1 = np.array([1,2,3])
print(a1.ndim)
## 维度为2
a2 = np.array([[1,2,3],[4,5
,6]])
print(a2.ndim)
## 维度为3
a3 = np.array([
[1,2,3],
[4,5,6]
[7,8,9],
[10,11,12]
print(a3.ndim)
3.2 数组形状查询
a1 = np.array([1,2,3])
# 结果为(3,)
print(a1.shape)
a2 = np.array([[1,2,3],[4,5,6]])
# 结果为(2,3)
print(a2.shape)
a3 = np.array([
[1,2,3],
[4,5,6]
[7,8,9],
[10,11,12]
# 结果为(2,2,3)
print(a3.shape)
3.3 修改数组形状
a1 = np.array([
[1,2,3],
[4,5,6]
[7,8,9],
[10,11,12]
a2 = a1.reshape((2,6))
print(a2)
#结果为(2, 6)
print(a2.shape)
# 扁平化 (多维数组转化为一维数组)
a3 = a2.flatten()
print(a3)
print(a3.ndim)
3.4 数组元素个数与所占内存
a1 = np.array([
[1,2,3],
[4,5,6]
[7,8,9],
[10,11,12]
#数组的元素个数
count = a1.size
print(count)
#各元素所占内存
print(a1.itemsize)
#各元素数据类型
print(a1.dtype)
#数组所占内存
print(a1.itemsize * a1.size)
3.5 总结
(1)一般情况下,数组维度最大到三维,一般会把三维以上的数组转化为二维数组来计算
(2)ndarray.ndmin查询数组的维度
(3)ndarray.shape可以看到数组的形状(几行几列),shape是一个元组,里面有几个元素代表是几维数组
(4) ndarray.reshape可以修改数组的形状。条件只有一个,就是修改后的形状的元素个数必须和原来的个数一致。比如原来是(2,6),那么修改完成后可以变成(3,4),但是不能变成(1,4)。reshape不会修改原来数组的形状,只会将修改后的结果返回。
(5)ndarray.size查询数组元素个数
(6) ndarray.itemsize可以看到数组中每个元素所占内存的大小,单位是字节。(1个字节=8位)
4. 数组索引和切片
4.1 一维数组
import numpy as np
# 1. 一维数组的索引和切片
a1 = np.arange(10)
## 结果为:[0 1 2 3 4 5 6 7 8 9]
print(a1)
# 1.1 进行索引操作
## 结果为:4
print(a1[4])
# 1.2 进行切片操作
## 结果为:[4 5]
print(a1[4:6])
# 1.3 使用步长
## 结果为:[0 2 4 6 8]
print(a1[::2])
# 1.4 使用负数作为索引
## 结果为:9
print(a1[-1])
4.2 二维数组
# 2. 多维数组
# 通过中括号来索引和切片,在中括号中使用逗号进行分割
#逗号前面的是行,逗号后面的是列,如果多维数组中只有一个值,那么这个值就是行
a2 = np.random.randint(0,10,size=(4,6))
print(a2)
#获取第0行数据
print(a2[0])
#获取第1,2行数据
print(a2[1:3])
#获取多行数据 例0,2,3行数据
print(a2[[0,2,3]])
#获取第二行第一列数据
print(a2[2,1])
#获取多个数据 例:第一行第四列、第二行第五列数据
print(a2[[1,2],[4,5]])
#获取多个数据 例:第一、二行的第四、五列的数据
print(a2[1:3,4:6])
#获取某一列数据 例:第一列的全部数据
print(a2[:,1])
#获取多列数据 例:第一、三列的全部数据
print(a2[:,[1,3]])
4.3 总结
1. 如果数组是一维的,那么索引和切片就是和python的列表是一样的
2. 如果是多维的(这里以二维为例),那么在中括号中,给两个值,两个值是通过逗号分隔的,逗号前面的是行,逗号后面的是列。如果中括号中只有一个值,那么就是代表行。
3. 如果是多维数组(以二维为例),那么行的部分和列的部分,都是遵循一维数组的方式,可以使用整型、切片,还可以使用中括号的形式代表不连续的。比如a[[1,2],[3,4]],那么返回的就是第一行第三列、第二行第四列的两个值。
5. 布尔索引
#生成1-24的4行6列的二维数组
a2 = np.arange(24).reshape((4,6))
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
a2[a2<10]
#array([ 0, 1, 2, 3, 4, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,23])
a2[(a2<5) | (a2>10)]
5.1总结
(1) 布尔索引是通过相同数据上的True还是False来进行提取的。
(2) 提取条件可以为一个或多个,当提取条件为多个时使用&代表且,使用|代表或
(3) 当提取条件为多个时,每个条件要使用圆括号括起来
6. 数组元素值的替换
6.1 方式一:索引
#利用索引可以做值的替换,把满足条件的位置的值替换成其他值
#创建数组元素值为[0,10)随机数的3行5列数组
a3 = np.random.randint(0
,10,size=(3,5))
print(a3)
#将a3数组第一行数据全部更换为0
a3[1] = 0
print(a3)
#将a3数组第一行数据更换为[1,2,3,4,5] -- 数据个数要对应
a3[1] = np.array([1,2,3,4,5])
print(a3)
6.2 方式二:条件索引
#数组中值小于3的元素全部替换为1
a3[a3 < 3] = 1
print(a3)
6.3 方式三:函数
#将a3数组中小于5的值替换为0,剩余值替换为1
result = np.where(a3<5,0,1)
result
6.4 总结
(1)使用索引或者切片来替换值
(2)使用条件索引来替换值
(3)使用where函数来实现替换值
7. 数组的广播机制
7.0. 数组的广播原则
如果两个数组的后缘维度(即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在全是和(或)长度为1的维度上进行。
案例分析:
- shape为(3,8,2)的数组能和(8,3)的数组进行运算吗?分析: 不能 ,因为安装广播原则,从后面网前面数,(3,8,2)和(8,3)中的2和3不相等,所以不能进行运算
- shape为(3,8,2)的数组能和(8,1)的数组进行运算吗?分析: 能 ,因为按照广播原则,从后面往前面数,(3,8,2)和(8,1)中的2和1虽然不相等,但因为有一方的长度为1,所以能参加运算
- shape为(3,1,8)的数组能和(8,1)的数组进行运算吗?分析: 能 ,因为按照广播原则,从后面往前面数,(3,1,8)和(8,1)中的4和1虽然不相等且1和8不相等,但是因为这两项中有一方的长度为1,所以能参加运算
7.1. 数组与数字运算
import numpy as np
#生成3行5列 值为0-5随机整数的数组
a1 = np.random.randint(0,5,size=(3,5))
#数组中的所有元素都乘2
print(a1*2)
#数组中所有的元素只保留2位小数
print(a1.round(2))
7.2. 数组与数组运算
#数组形状一致时 各个元素相加减(满足数组广播机制)
a2 = np.random.randint(0,5,size=(3,5))
a1+a2
#形状不一致的数组不能相加减(不满足数组广播机制)
a3 = np.random.randint(0,5,size=(3,4))
# a1+a3 报错
#两个数组行数相同 ,其中一个数组列数为1(满足数组广播机制)
a4 = np.random.randint(0,5,size=(3,1))
a1+a4
#两个数组列数相同 ,其中一个数组行数为1(满足数组广播机制)
a5 = np.random.randint(0,5,size=(1,5))
a1+a5
7.3总结
(1) 数组和数字直接进行运算是没有问题的
(2) 两个shape想要的数组是可以进行运算的
(3) 如果两个shape不同的数组,想要进行运算,那么需要看他们是否满足广播原则
8. 数组形状的操作
8.1. 数组形状的改变
8.1.1 reshape与resize
import numpy as np
# reshape与resize都是用来修改数组形状的,但是存在不同
a1 = np.random.randint(0,10,size=(3,4))
# reshape是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的
a2 = a1.reshape((2,6))
# resize是将数组转换成指定的形状,会直接修改数组本身,并且不会返回任何值
a1.resize((4,3))
print(a1)
8.1.2 flatten与ravel
# faltten与ravel都是将多维数组转换为一维数组,但是存在不同
a3 = np.random.randint(0,10,size=(3,4))
# flatten是将数组转换为一维数组后,然后将这个拷贝返回回去,然后后续对这个返回值进行修改不会影响之前的数组
a4 = a3.flatten()
a4[0] = 100
# 结果为:2
print(a3[0,0])
# 结果为:100
print(a4[0])
# ravel是将数组转换为一维数组后,将这个视图(引用)返回回去,后续对这个返回值进行修改会影响之前的数组
a5 = a3.ravel()
a5[0] = 100
# 结果为:100
print(a3[0,0])
# 结果为:100
print(a5[0])
8.2 数组的叠加
#vstack代表在垂直方向叠加,如果想要叠加成功,那么列数必须一致
#hstack代表在水平方向叠加,如果想要叠加成功,那么行数必须一致
#concatenate可以手动的指定axis参数具体在哪个方向叠加
##(1)如果axis=0,代表在水平方向叠加
##(2)如果axis=1,代表在垂直方向叠加
##(3)如果axis=None,会先进行叠加,再转化为1维数组
vstack1 = np.random.randint(0,10,size=(3,4))
print(vstack1)
vstack2 = np.random.randint(0,10,size=(2,4))
print(vstack2)
#垂直方向叠加的两种方式
vstack3 = np.vstack([vstack1,vstack2])
print(vstack3)
vstack4 = np.concatenate([vstack1,vstack2],axis=0)
print(vstack4)
h1 = np.random.randint(0,10,size=(3,4))
print(h1)
h2 = np.random.randint(0,10,size=(3,1))
print(h2)
#水平方向叠加的两种方式
h3 = np.hstack([h2,h1])
print(h3)
h4 = np.concatenate([h2,h1
],axis=1)
print(h4)
#先识别垂直叠加或水平叠加 后转换为一维数组
h5 = np.concatenate([h2,h1],axis=None)
print(h5)
8.3. 数组的切割
#hsplit代表在水平方向切割,按列进行切割。
#hsplit切割方式两种,第一种直接指定平均切割成多少列,第二种是指定切割的下标值
#vsplit代表在垂直方向切割,按行进行切割。切割方式与hsplit相同
#split/array_split是手动的指定axis参数,axis=0代表按行进行切割,axis=1代表按列进行切割
hs1 = np.random.randint(0,10,size=(3,4))
print(hs1)
#水平方向平均分为2份 (要求列数可被此数整除)
np.hsplit(hs1,2)
#水平方向分为1,1,2列(在下标为1,2处切割)
np.hsplit(hs1,(1,2))
vs1 = np.random.randint(0,10,size=(4,5))
print(vs1)
#垂直方向平均分为4份
np.vsplit(vs1,4)
#垂直方向分为1,2,1
np.vsplit(vs1,(1,3))
#split/array_split(array,indicate_or_section,axis):用于指定切割方式,在切割的时候需要指定按照行还是列,axis=1代表按照列,axis=0代表按照行
#按列平均切割
np.split(hs1,4,axis=1)
#按行平均切割
np.split(vs1,4,axis=0)
8.4. 矩阵转置
#通过ndarray.T的形式进行转置
t1 = np.random.randint(0,10,size=(3,4))
print(t1)
#数组t1转置
t1.T
#矩阵相乘
t1.dot(t1.T)
#通过ndarray.transpose()进行转置
#transpose返回的是一个View,所以对返回值上进行修改会影响到原来的数组。
t2 = t1.transpose()
8.5 总结
1. 数据的形状改变
(1)reshape和resize都是重新定义形状的,但是reshape不会修改数组本身,而是将修改后的结果返回回去,而resize是直接修改数组本身的
(2)flatten和ravel都是用来将数组变成一维数组的,并且他们都不会对原数组造成修改,但是flatten返回的是一个拷贝,所以对flatten的返回值的修改不会影响到原来数组,而ravel返回的是一个View,那么对返回值的修改会影响到原来数组的值
2. 数据的叠加
(1)hstack代表在水平方向叠加,如果想要叠加成功,那么他们的行必须一致
(2)vastack代表在垂直方向叠加,如果想要叠加成功,那么他们的列必须一致
(3)concatenate可以手动指定axis参数具体在哪个方向叠加,如果axis=0,代表在水平方向叠加,如果axis=1,代表在垂直方向叠加,如果axis=None,那么会先进行叠加,再转化成一维数组
3. 数组的切割
(1)hsplit代表在水平方向切割,按列进行切割。切割方式有两种,第一种就是直接指定平均切割成多少列,第二种就是指定切割的下标值
(2)vsplit代表在垂直方向切割,按行进行切割。切割方式与hsplit一致。
(3)split/array_split是手动的指定axis参数,axis=0代表按行进行切割,axis=1代表按列进行切割
4. 矩阵转置
(1)可以通过ndarray.T的形式进行转置
(2)也可以通过ndarray.transpose()进行转置,这个方法返回的是一个View,所以对返回值上进行修改,会影响到原来的数组
9. View或者浅拷贝
9.1 不拷贝
如果只是简单的赋值,那么就不会进行拷贝
import numpy as np
a = np.arange(12)
#这种情况不会进行拷贝
b = a
#返回True,说明b和a是相同的
print(b is a)
9.2 浅拷贝
有些情况,会进行变量的拷贝,但是他们所指向的内存空间都是一样的,那么这种情况叫做浅拷贝,或者叫做View(视图)
c = a.view()
#返回false,说明c与a在栈区空间不同,但是所指向的内存空间是一样的
print(c is a)
#对c的值修改 同时也会对a进行修改
c[0] = 100
#array([100,1,2,3,4,5,6,7,8,9,10,11])
print(a)
9.3 深拷贝
将之前数据完完整整的拷贝一份放到另外一块内存空间中,这样就是两个完全不同的值了
d = a.copy()
#返回False 说明在不同栈区
print(d is a)
#数组d值被修改,数组a值不会被修改 说明内存空间不同
d[1]=200
9.4 总结
在数组操作中分成三种拷贝:
(1)不拷贝:直接赋值,那么栈区没有拷贝,只是用同一个栈区定义了不同的名称
(2)浅拷贝:只拷贝栈区,栈区指定的堆区并没有拷贝
(3)深拷贝:栈区和堆区都拷贝
10. 文件操作
10.1 操作CSV文件
10.1.1 文件保存
np.savetxt(frame,array,fmt="%.18e",delimiter=None)
函数功能
:将数组保存到文件中
参数说明
:
· frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
· array:存入文件的数组
· fmt:写入文件的格式,例如:%d %.2f %.18e
· delimter:分割字符串,默认是空格
import numpy as np
scores = np.random.randint(0,100,size=(10,2))
#保存csv文件
np.savetxt("score.csv",scores,fmt="%d",delimiter=",",header="英语,数学",comments="")
10.1.2 读取文件
np.loadtxt(frame,dtype=np.float,delimiter=None,unpack=False)
函数功能
:将数组保存到文件中
参数说明
:
· frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
· dtype:数据类型,可选
· delimiter:分割字符串,默认是任何空格
· skiprows:跳过前面x行
· usecols:读取指定的列,用元组组合
· unpack:如果True,读取出来的数组是转置后的
#读取csv文件 跳过第一行的表头
b = np.loadtxt("score.csv",dtype=np.int,delimiter=",",skiprows=
1)
10.2 np独有的存储解决方案
numpy中还有一种独有的存储解决方案。文件名是以.npy或者npz结尾的。以下是存储和加载的函数:
1. 存储
np.save(fname,a rray)
或
np.savez(fname,array)
其中,前者函数的扩展名是.npy,后者的扩展名是.npz,后者是经过压缩的。
2.加载
np.load(fname)
c = np.random.randint(0,10,size=(2,3))
np.save("c",c)
c1 = np.load("c.npy")
10.3 总结
1. np.savetxt和np.loadtxt一般用来操作CSV文件,可以设置header,但是不能存储3维以上的数组。
2. np.save和np.load一般用来存储非文本类型的文件,不可以设置header,但是可以存储3维以上的数组
3. 如果想专门的操作csv文件,还存在另一个模块叫做csv,这个模块是python内置的,不需要安装
11. NAN和INF值处理
11.1 介绍
NAN :Not A number,不是一个数字的意思,但是他是浮点类型的,所以想要进行数据操作的时候需要注意他的类型
import numpy as np
data = np.random.randint(0,10,size=(3,5))
data = data.astype(np.float)
#将数组中某个位置的值设置为NAN
data[0,1]=np.NAN
INF :Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为0的时候为无穷大。比如2/0
11.2 NAN特点
- NAN和NAN不相等。比如 np.NAN != np.NAN 这个条件是成立的
- NAN和任何值做运算,结果都是NAN
11.3 处理缺失值的方式
11.3.1 删除缺失值
有时候,我们想要将数组中的NAN删掉,那么我们可以换一种思路,就是 只提取不为NAN的值
#第一种方式: 删除所有NAN的值,因为删除了值后数组将不知道该怎么变化,所以会被变成一维数组
data[~np.isnan(data)]
#第二种方式: 删除NAN所在行
## 获取哪些行有NAN
lines = np.where(np.isnan(data))[0]
## 使用delete方法删除指定的行,lines表示删除的行号,axis=0表示删除行
np.delete(data,lines,axis=0)
11.3.2 用其他值进行替代
#从文件中读取数据
scores = np.loadtxt("scores.csv",delimiter=",",skiprows=1,dtype=np.str)
#将空数据转换成NAN
scores[scores == ""] = np.NAN
#转化成float类型
scores1 = scores.astype(np.float)
#将NAN替换为0
scores1[np.isnan(scores1)]=0
#除了delete用axis=0表示行以外,其他的大部分函数都是axis=1来表示行
#对指定轴求和 axis=1按行
scores1.sum(axis=1)
#将空值替换为均值
#对scores进行深拷贝
scores2 = scores.astype()
#循环遍历每一列
for x in range(score2.shape[1]):
col = scores2[:,x]
#去除该列中值为NAN
non_nan_col = col[~np.isnan(col)]
#求平均值
mean = non_nan_col.mean()
#将该列中值为NAN的数值替换为平均值
col[np.isnan(col)] = mean
scores2
11.4 总结
(1)NAN:Not A Number的简写,不是一个数字,但是是属于浮点类型
(2)INF:无穷大,在除数为0的情况下会出现INF
(3)NAN和所有的值进行计算结果都是等于NAN
(4)NAN != NAN
(5)可以通过np.isnan来判断某个值是不是NAN
(6)处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换进行处理
(7)np.delete比较特殊,通过axis=0来代表行,而其他大部分函数通过axis=1来代表行
12. random模块
12.1 np.random.seed
用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed()值,则每次生成的随机数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异不同。一般没有特殊要求不用设置。
np.random.seed(1)
#打印0.417022004702574
np.random.rand()
#打印其他的值,因为随机数种子支队下一次随机数的产生会有影响
np.random.rand()
12.2 np.random.rand
生成一个值为 [0,1) 之间的数组,形状由参数指定,如果没有参数,那么将返回一个随机值
#产生随机数
np.random.rand()
#产生随机数组 两行三列
np.random.rand(2,3)
12.3 np.random.randn
生成均值(μ)为0,标准差(σ)为1的标准正态分布的值
#生成一个2行3列的数组,数组中的值都满足标准正态分布
data = np.random.randn(2,3)
12.4 np.random.randint
生成指定范围内的随机数,并且可以通过size参数指定维度
#生成值在0-10之间,3行5列的数组
data1 = np.random.randint(10,size=(3,5))
#生成值在1-20之间,3行6列的数组
data2 = np.random.randint(1,20,size=(3,6))
12.5 np.random.choice
从一个列表或者数组中,随机进行采样。或者是从指定的区间中进行采样,采样个数可以通过参数
#从数组中随机选择三个值
np.random.choice(data,3)
#从数组中获取值组成新的数组
np.random.choice(data,size=(3,4))
#从指定值随机取值 (示例:从0-10之间随机取3个值)
np.random.choice(10,3)
12.6 np.random.shuffle
把原来数组的元素的 位置打乱
a = np.arange(10)
#将数组a的元素的位置都会进行随机更换
#shuffle没有返回值,直接打乱原数组位置
np.random.shuffle(a)
13. Axis理解
13.1 Axis
简单来说, 最外面的括号代表着axis=0,依次往里的括号对应的axis的计数就依次加1
如下图,最外面的括号就是axis=0,里面两个子括号axis=1
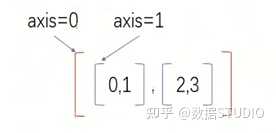
操作方式:如果指定轴进行相关的操作,那么他会使用轴下的每一个直接子元素的第0个,第1个,第2个…分别进行相关的操作
示例:
x = np.array([[0,1],[2,3]])
1.求 x 数组在axis = 0 和 axis=1 两种情况下的和
#结果为[2,4]
x.sum(axis=0)
分析:按照axis=0的方式相加,那么就会把 最外面轴下的所有直接子元素的第0个位置进行相加,第1个位置进行相加…依次类推 ,得到的就是 0+2 以及 2+3 ,然后进行相加,得到的结果就是 [2,4]
2.用np.max求 axis=0 和 axis=1 两种情况下的最大值
np.random.seed(100)
x = np.random.randint(1,10,size=(3,5))
#输出结果为:
#[[9 9 4 8 8]
# [1 5 3 6 3]
# [3 3 2 1 9]]
print(x)
#结果为[9, 9, 4, 8, 9]
x.max(axis=0)
#结果为[9, 6, 9]
x.max(axis=1)
分析:按照axis=0进行求最大值,那么就会在最外面轴里面找直接子元素,然后将每个子元素的第0个值放在一起求最大值,将第1个值放在一起求最大值,以此类推。而如果axis=1,那么就是拿到每个直接子元素,然后求每个子元素中的最大值
3.用 np.delete 在 axis=0 和 axis=1 两种情况下删除元素
np.random.seed(100)
x = np.random.randint(1,10,size=(3,5))
#输出结果为:
#[[9 9 4 8 8]
# [1 5 3 6 3]
# [3 3 2 1 9]]
print(x)
#删除第0行
#结果为:
#[[1, 5, 3, 6, 3],
# [3, 3, 2, 1, 9]]
np.delete(x,0,axis=0)
分析: np.delete是个例外 ,按照 axis=0 的方式进行删除,那么会首先找到最外面的括号下的直接子元素的第0个,然后直接删掉,剩下最后一行的数据。同理,如果我们按照 axis=1 进行删除,那么会把第一列的数据删掉
13.2 三维数组及多维数组
#生成一个三维数组
#[[[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11]],
# [[12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]]]
y = np.arange(24).reshape(2,2,6)
#取最大值
#结果为:
#[[12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]]
y.max(axis=0)
13.3 总结
(1)最外面的括号代表着 axis=0,依次往里的括号对应的 axis 的计数就依次加1
(2)操作方式:如果指定轴进行相关的操作,那么他会使用轴下面的每个直接子元素的第0个,第1个,第2个...分别进行相关的操作
(3)np.delete是直接删除指定轴下的第几个直接子元素
14. 通用函数
14.1 一元函数
| 函数 | 描述 |
|---|---|
| np.abs | 绝对值 |
| np.sqrt | 开方(负数开方结果为NAN) |
| np.square | 平方 |
| np.exp | 计算指数(e^x) |
| np.log,np.log10,np.log2,np.log1p | 求以e为底,以10为底,以2为底,以(1+x为底的对数 |
| np.sign | 将数组中的值标签化,大于0的变成1,等于0的变成0,小于0的变成-1 |
| np.ceil | 朝着无穷大的方向取整,比如5.1会变成6,-6.3会变成-6 |
| np.floor | 朝着负无穷大的方向取整,比如5.1会变成5,-6.3会变成-7 |
| np.rint,np.round | 返回四舍五入后的值 |
| np.modf | 将整数和小数分割开来形成两个数组 |
| np.isnan | 判断是否是nan |
| np.isinf | 判断是否是inf |
| np.cos,np.cosh,np.sinh,np.tan,np.tanh | 三角函数 |
| np.arccos,np.arcsin,np.arctan | 反三角函数 |
14.2 二元函数
| 函数 | 描述 |
|---|---|
| np.add | 加法运算(即1+1=2),相当于+ |
| np.subtract | 减法运算(即3-2=1),相当于- |
| np.negative | 复数运算(即-2)。相当于加个负号 |
| np.multiply | 乘法运算(即2_3=6),相当于_ |
| np.divide | 除法运算(即3/2=1.5),相当于/ |
| np.floor_divide | 取整运算,相当于// |
| np.mod | 取余运算,相当于% |
| greater,greater_equal,less,less_equal,equal,not_equal | >,>=,<,<=,=,!=的函数表达式 |
| logical_and | 且运算符函数表达式 |
| logical_or | 或运算符函数表达式 |
14.3 聚合函数
| 函数名称 | NAN安全版本 | 描述 |
|---|---|---|
| np.sum | np.nansum | 计算元素的和 |
| np.prod | np.nanprod | 计算元素的积 |
| np.mean | np.nanmean | 计算元素的平均值 |
| np.std | np.nanstd | 计算元素的标准差 |
| np.var | np.nanvar | 计算元素的方差 |
| np.min | np.nanmin | 计算元素的最小值 |
| np.max | np.nanmax | 计算元素的最大值 |
| np.argmin | np.nanargmin | 找出最小值的索引 |
| np.argmax | np.nanargmax | 找出最大值的索引 |
| np.median | np.nanmedian | 计算元素的中位数 |
补充 :使用np.sum或者是a.sum即可实现。并且在使用的时候, 可以指定具体哪个轴 。同样python中也内置了sum函数,但是python内置的sum函数执行效率没有np.sum那么高。
14.4 布尔数组的函数
| 函数名称 | 描述 |
|---|---|
| np.any | 验证任何一个元素是否为真 |
| np.all | 验证所有元素是否为真 |
#查看数组中是不是所有元素都为0
np.all(a==0)
(a==0).all()
#查看数组中是否有等于0的数
np.any(a==0)
(a==0).any()
14.5 排序
14.5.1 np.sort
函数说明: 指定轴进行排序。默认是使用数组的最后一个轴进行排序 。
还有ndarray.sort(),这个方法会直接影响到原来的数组,而不是返回一个新的排序后的数组
#生成数组
a = np.random.randint(0,10,size=(5,5))
#按照行进行排序,因为最后一个轴是1,那么就是将最里面的元素进行排序
np.sort(a)
#按照列进行排序,因为指定了axis=0
np.sort(a,axis=0)
#该方法进行排序会影响原数组
a.sort()
14.5.2 np.argsort
函数说明: 返回排序后的下标值 。
#返回排序后的下标值
np.argsort(a)
14.5.3 np.sort(降序)
np.sort()默认会采用升序排序,用一下方案来实现降序排序
#方式一:使用负号
-np.sort(-a)
#方式二:使用sort和argsort以及take
#排序后的结果就是降序的
indexes = np.argsort(-a)
#从a中根据下标提取相应的元素
np.take(a,indexes)
14.6 其他函数
14.6.1 np.apply_along_axis
函数说明: 沿着某个轴执行指定的函数
#求数组a按行求平均值,并且要去掉最大值和最小值
def get_mean(x):
#排除最大值和最小值后求平均值
y=x[np.logical_and(x!=x.max,x!=x.min)].mean()
return y
#方式一:调用函数
np.apply_along_axis(get_mean,axis=1,arr=c)
#方式二:lambda表达式
np.apply_along_axis(lambda x:x[np.logical_and(x!=x.max,x!=x.min)].mean(),axis=1,arr=c)
14.6.2 np.linspace
函数说明: 用来将指定区间内的值平均分成多少份
#将0-10分成12份,生成一个数组
np.linspace(0,10,12)
14.6.3 np.unique
函数说明: 返回数组中的唯一值
#返回数组a中的唯一值
np.unique(d)
#返回数组a中的唯一值,并且会返回每个唯一值出现的次数
np.unique(d,return_counts=True)
系统性总结了Pandas所有知识点
1、Pandas数据结构

- 2008年WesMcKinney开发出的库
- 专门用于数据挖掘的开源python库
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
1.1 为什么使用Pandas
Numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢?
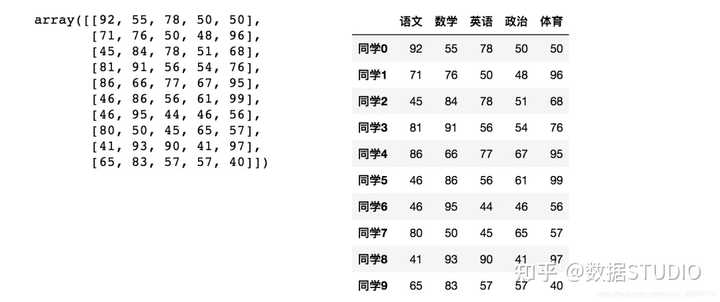
(1)增强图表可读性
- 在numpy当中创建学生成绩表样式:
- 返回结果:
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
如果数据展示为这样,可读性就会更友好:

(2)便捷的数据处理能力

(3)读取文件方便
(4)封装了Matplotlib、Numpy的画图和计算
1.2 Pandas数据结构
Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex(老版本中叫Panel )。
其中Series是一维数据结构,DataFrame是二维的表格型数据结构,MultiIndex是三维的数据结构。
1.2.1 Series
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。
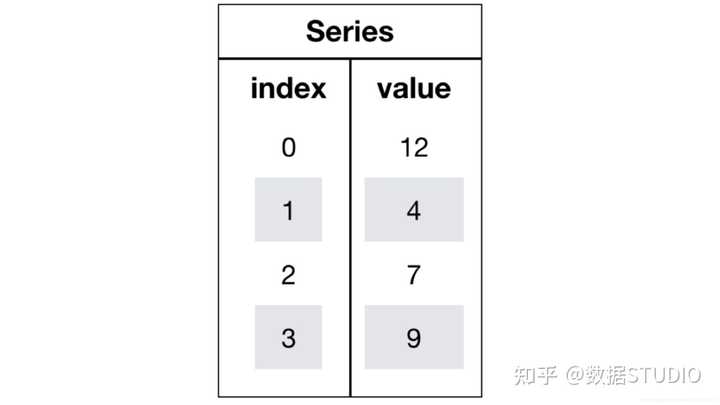

1、Series的创建
# 导入pandas
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
参数:
- data:传入的数据,可以是ndarray、list等
- index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
- dtype:数据的类型
通过已有数据创建:
(1)指定内容,默认索引:
pd.Series(np.arange(10))
# 运行结果
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
(2)指定索引:
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
# 运行结果
1 6.7
2 5.6
3 3.0
4 10.0
5 2.0
dtype: float64
(3)通过字典数据创建
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count
# 运行结果
blue 200
green 500
red 100
yellow 1000
dtype: int64
2、Series的属性
为了更方便地操作Series对象中的索引和数据,Series中提供了两个属性index和values:
- index:
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count.index
Index(['blue', 'green', 'red', 'yellow'], dtype='object')
- values:
color_count.values
array([ 200, 500, 100, 1000])
也可以使用索引来获取数据:
color_count[2]
1.2.2 DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引:
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
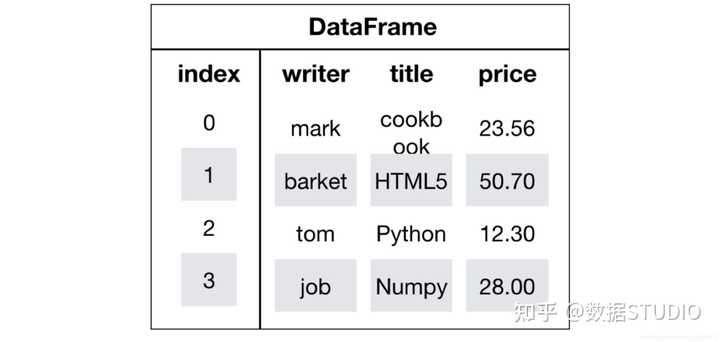

1、DataFrame的创建
# 导入pandas
import pandas as pd
pd.DataFrame(data=None, index=None, columns=None)
参数:
- index:行标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
- columns:列标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
举例一:通过已有数据创建
pd.DataFrame(np.random.randn(2,3))
结果:
举例二:创建学生成绩表
使用np创建的数组显示方式,比较两者的区别。
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))#均匀分布
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
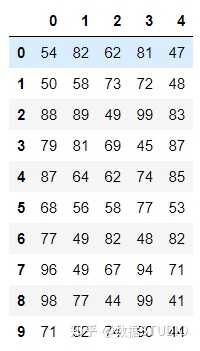
但是这样的数据形式很难看到存储的是什么的样的数据,可读性比较差!!
问题:如何让数据更有意义的显示?
# 使用Pandas中的数据结构
score_df = pd.DataFrame(score)
结果:
给分数数据增加行列索引,显示效果更佳:
- 增加行、列索引:
# 构造行索引序列
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列索引序列
stu = ['同学' + str(i) for i in range(score_df.shape[0])]
# 添加行索引
data = pd.DataFrame(score, columns=subjects, index=stu)
结果:
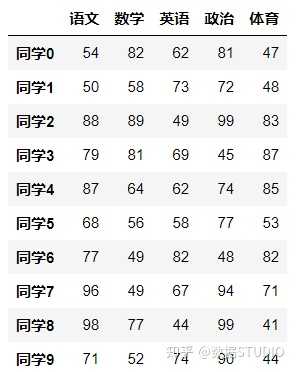
2、DataFrame的属性
(1)shape
data.shape
(10, 5)
(2)index
DataFrame的行索引列表
data.index
Index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object')
(3)columns
DataFrame的列索引列表
data.columns
Index(['语文', '数学', '英语', '政治', '体育'], dtype='object')
(4)values
直接获取其中array的值
array([[54, 82, 62, 81, 47],
[50, 58, 73, 72, 48],
[88, 89, 49, 99, 83],
[79, 81, 69, 45, 87],
[87, 64, 62, 74, 85],
[68, 56, 58, 77, 53],
[77, 49, 82, 48, 82],
[96, 49, 67, 94, 71],
[98, 77, 44, 99, 41],
[71, 52, 74, 90, 44]])
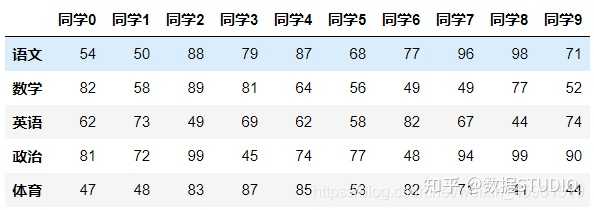
(5)T
转置
data.T
结果:

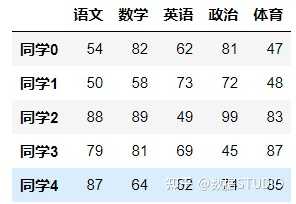
(6)head(5):显示前5行内容
如果不补充参数,默认5行。填入参数N则显示前N行
data.head(5)
结果:
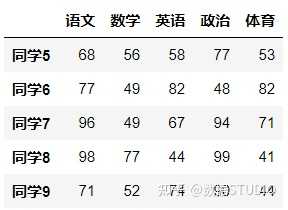
(7)tail(5):显示后5行内容
如果不补充参数,默认5行。填入参数N则显示后N行
data.tail(5)
结果:
3、DatatFrame索引的设置
现在要将下图的行索引改变,变成下下图所示样子,怎么做呢?
(1)修改行列索引值
stu = ["学同学_" + str(i) for i in range(score_df.shape[0])]
# 必须整体全部修改
data.index = stu
注意:以下修改方式是错误的,说明不能单独修改
# 错误修改方式,不能单个修改
data.index[3] = '学生_3'
(2)重设索引
设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
- reset_index(drop=False)
# 重置索引,drop=False
data.reset_index()
结果:
# 重置索引,drop=True
data.reset_index()
结果:
(3)以某列值设置为新的索引
set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
设置新索引案例:
1、创建
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
month sale year
0 1 55 2012
1 4 40 2014
2 7 84 2013
3 10 31 2014
2、以月份设置新的索引
df.set_index('month')
sale year
month
1 55 2012
4 40 2014
7 84 2013
10 31 2014
3、设置多个索引,以年和月份
df = df.set_index(['year', 'month'])
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
注:通过刚才的设置,这样DataFrame就变成了一个具有MultiIndex的DataFrame。
1.2.3 MultiIndex与Panel
1、MultiIndex
MultiIndex是三维的数据结构;
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
(1)multiIndex的特性
打印刚才的df的行索引结果
df
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
df.index
MultiIndex(levels=[[2012, 2013, 2014], [1, 4, 7, 10]],
labels=[[0, 2, 1, 2], [0, 1, 2, 3]],
names=['year', 'month'])
多级或分层索引对象。
index属性
- names:levels的名称
- levels:每个level的元组值
df.index.names
# FrozenList(['year', 'month'])
df.index.levels
# FrozenList([[2012, 2013, 2014], [1, 4, 7, 10]])
(2)multiIndex的创建
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']]
pd.MultiIndex.from_arrays(arrays, names=('number', 'color'))
MultiIndex(levels=[[1, 2], ['blue', 'red']],
codes=[[0, 0, 1, 1], [1, 0, 1, 0]],
names=['number', 'color'])
2、Panel
(1)panel的创建
作用:存储3维数组的Panel结构
参数:
- data : ndarray或者dataframe
- items : 索引或类似数组的对象,axis=0
- major_axis : 索引或类似数组的对象,axis=1
- minor_axis : 索引或类似数组的对象,axis=2
- class pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None)
p = pd.Panel(data=np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 3 (major_axis) x 2 (minor_axis)
Items axis: A to D
Major_axis axis: 2013-01-01 00:00:00 to 2013-01-03 00:00:00
Minor_axis axis: first to second
(2)查看panel数据
p[:,:,"first"]
p["B",:,:]
注:Pandas从版本0.20.0开始弃用:推荐的用于表示3D数据的方法是通过DataFrame上的MultiIndex方法。
2、基本数据操作
为了更好的理解这些基本操作,我们将读取一个真实的股票数据。关于文件操作,后面在介绍,这里只先用一下API。
# 读取文件
data = pd.read_csv("./data/stock_day.csv")
# 删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
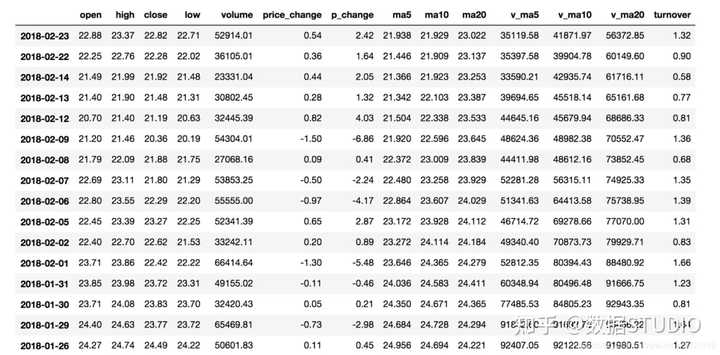

2.1 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
2.2.1 直接使用行列索引(先列后行)
获取’2018-02-27’这天的’open’的结果:
# 直接使用行列索引名字的方式(先列后行)
data['open']['2018-02-27']
23.53
# 不支持的操作
data['2018-02-27']['open']
data[:1, :2]
2.2.2 结合loc或者iloc使用索引
获取从’2018-02-27’到’2018-02-22’,'open’的结果:
# 使用loc:只能指定行列索引的名字
data.loc['2018-02-27':'2018-02-22', 'open']
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
Name: open, dtype: float64
# 使用iloc可以通过索引的下标去获取
# 获取前3天数据,前5列的结果
data.iloc[:3, :5]
open high close low
2018-02-27 23.53 25.88 24.16 23.53
2018-02-26 22.80 23.78 23.53 22.80
2018-02-23 22.88 23.37 22.82 22.71
2.2.3 使用ix组合索引(混合索引:下标和名称)
获取行第1天到第4天,[‘open’, ‘close’, ‘high’, ‘low’]这个四个指标的结果:
# 使用ix进行下表和名称组合做引
data.ix[0:4, ['open', 'close', 'high', 'low']]
# 推荐使用loc和iloc来获取的方式
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
open close high low
2018-02-27 23.53 24.16 25.88 23.53
2018-02-26 22.80 23.53 23.78 22.80
2018-02-23 22.88 22.82 23.37 22.71
2018-02-22 22.25 22.28 22.76 22.02
2.2 赋值操作
对DataFrame当中的close列进行重新赋值为1。
# 直接修改原来的值
data['close'] = 1 # 这一列都变成1
data.close = 1
2.3 排序
排序有两种形式,一种对于索引进行排序,一种对于内容进行排序:
2.3.1 DataFrame排序
(1)使用
df.sort_values(by=, ascending=)
参数:
-
by:指定排序参考的键
-
单个键或者多个键进行排序
- ascending:默认升序
- ascending=False:降序
- ascending=True:升序
如下:
例一:
# 按照开盘价大小进行排序 , 使用ascending指定按照大小排序
data.sort_values(by="open", ascending=True).head()
结果:


例二:
# 按照多个键进行排序
data.sort_values(by=['open', 'high'])
结果:
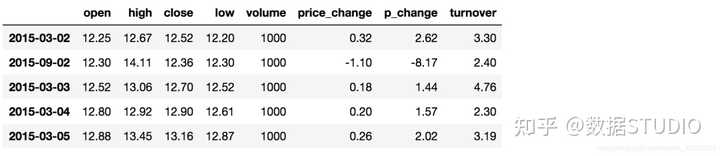

(2)使用
df.sort_index(ascending=)
给索引进行排序
这个股票的日期索引原来是从大到小,现在重新排序,从小到大:
# 对索引进行排序
data.sort_index()
结果:
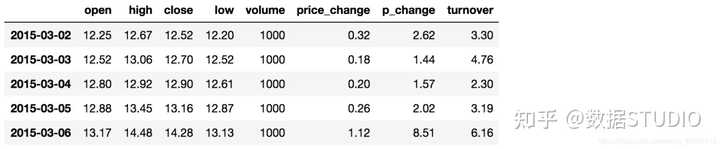

2.3.2 Series排序
(1)使用
series.sort_values(ascending=True)
进行排序
series排序时,只有一列,不需要参数
data['p_change'].sort_values(ascending=True).head()
2015-09-01 -10.03
2015-09-14 -10.02
2016-01-11 -10.02
2015-07-15 -10.02
2015-08-26 -10.01
Name: p_change, dtype: float64
(2)使用
series.sort_index()
进行排序
与df一致
# 对索引进行排序
data['p_change'].sort_index().head()
2015-03-02 2.62
2015-03-03 1.44
2015-03-04 1.57
2015-03-05 2.02
2015-03-06 8.51
Name: p_change, dtype: float64
2.4 总结


3、DataFrame运算
3.1 算术运算
(1)
add(other)
比如进行数学运算加上具体的一个数字
data['open'].head().add(1)
2018-02-27 24.53
2018-02-26 23.80
2018-02-23 23.88
2018-02-22 23.25
2018-02-14 22.49
Name: open, dtype: float64
(2)
sub(other)
整个列减一个数
data.open.head().sub(2)
2018-02-27 21.53
2018-02-26 20.80
2018-02-23 20.88
2018-02-22 20.25
2018-02-14 19.49
Name: open, dtype: float64
3.2 逻辑运算
3.2.1 逻辑运算符号
例如筛选data[“open”] > 23的日期数据
- data[“open”] > 23返回逻辑结果
data["open"] > 23
2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
# 逻辑判断的结果可以作为筛选的依据
data[data["open"] > 23].head()
结果:
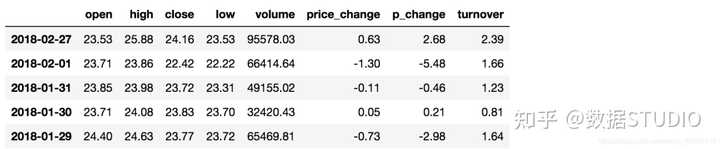

- 完成多个逻辑判断:
data[(data["open"] > 23) & (data["open"] < 24)].head()
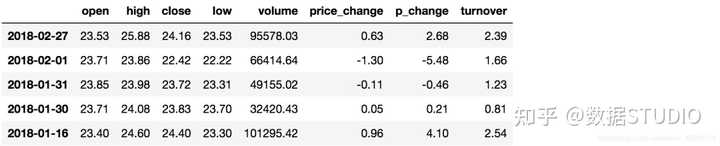

3.2.2 逻辑运算函数
(1)
query(expr)
- expr:查询字符串
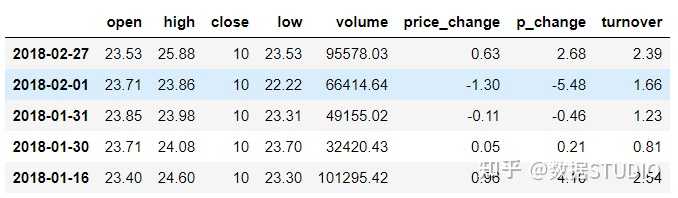
通过query使得刚才的过程更加方便简单,下面是使用的例子:
data.query("open<24 & open>23").head()
结果:

(2)
isin(values)
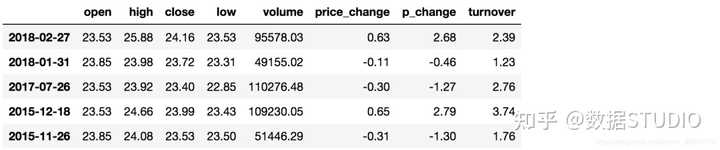
例如判断’open’是否为23.53和23.85:
# 可以指定值进行一个判断,从而进行筛选操作
data[data["open"].isin([23.53, 23.85])]

3.2.3 统计运算
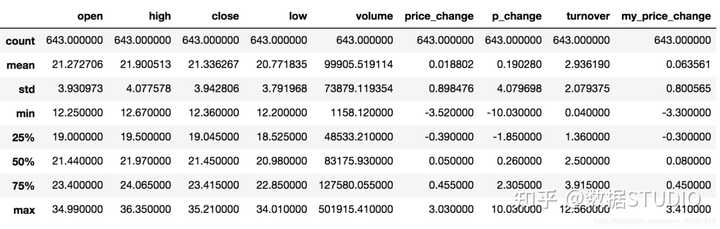
1、escribe
综合分析: 能够直接得出很多统计结果,count, mean, std, min, max 等
# 计算平均值、标准差、最大值、最小值
data.describe()

2、统计函数
看一下
min(最小值)
,
max(最大值)
,
mean(平均值)
,
median(中位数)
,
var(方差)
,
std(标准差)
,
mode(众数)
是怎么操作的:
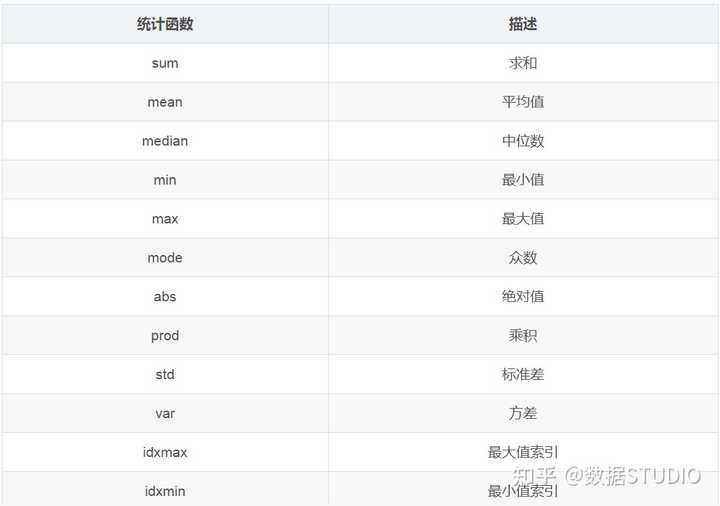

对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)。
(1)
max()、min()
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果
data.max(axis=0) # 最大值
open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
my_price_change 3.41
dtype: float64
(2)
std()、var()
# 方差
data.var(axis=0)
open 1.545255e+01
high 1.662665e+01
close 1.554572e+01
low 1.437902e+01
volume 5.458124e+09
price_change 8.072595e-01
p_change 1.664394e+01
turnover 4.323800e+00
my_price_change 6.409037e-01
dtype: float64
# 标准差
data.std(axis=0)
open 3.930973
high 4.077578
close 3.942806
low 3.791968
volume 73879.119354
price_change 0.898476
p_change 4.079698
turnover 2.079375
my_price_change 0.800565
dtype: float64
(3)
median()
:中位数
中位数为将数据从小到大排列,在最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
data.median(axis=0)
open 21.44
high 21.97
close 10.00
low 20.98
volume 83175.93
price_change 0.05
p_change 0.26
turnover 2.50
dtype: float64
(4)
idxmax()、idxmin()
# 求出最大值的位置
data.idxmax(axis=0)
open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
my_price_change 2015-07-10
dtype: object
# 求出最小值的位置
data.idxmin(axis=0)
open 2015-03-02
high 2015-03-02
close 2015-09-02
low 2015-03-02
volume 2016-07-06
price_change 2015-06-15
p_change 2015-09-01
turnover 2016-07-06
my_price_change 2015-06-15
dtype: object
3、累计统计函数
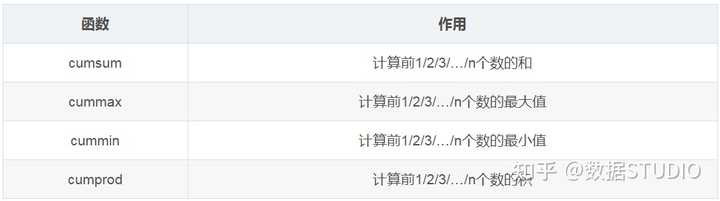

那么这些累计统计函数怎么用?
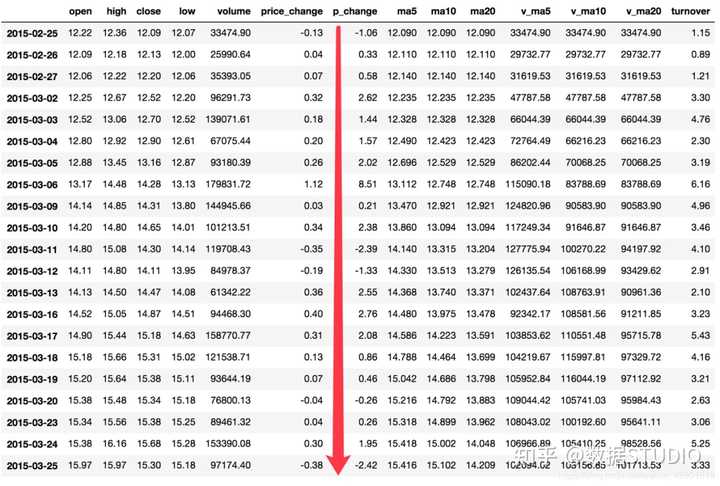

以上这些函数可以对series和dataframe操作,这里我们按照时间的从前往后来进行累计
- 排序
# 排序之后,进行累计求和
data = data.sort_index()
- 对p_change进行求和
stock_rise = data['p_change']
stock_rise.cumsum()
2015-03-02 2.62
2015-03-03 4.06
2015-03-04 5.63
2015-03-05 7.65
2015-03-06 16.16
2015-03-09 16.37
2015-03-10 18.75
2015-03-11 16.36
2015-03-12 15.03
2015-03-13 17.58
2015-03-16 20.34
2015-03-17 22.42
2015-03-18 23.28
2015-03-19 23.74
2015-03-20 23.48
2015-03-23 23.74
那么如何让这个连续求和的结果更好的显示呢?
如果要使用plot函数,需要导入matplotlib.下面是绘图代码:
import matplotlib.pyplot as plt
# plot显示图形, plot方法集成了直方图、条形图、饼图、折线图
stock_rise.cumsum().plot()
# 需要调用show,才能显示出结果
plt.show()
结果:
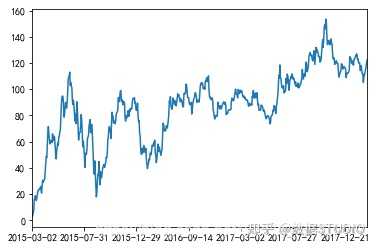
关于plot,稍后会介绍API的选择。
4、自定义运算
apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
定义一个对列,最大值-最小值的函数
下面看个例子:
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0)
open 22.74
close 22.85
dtype: float64
特定需求需要用这个。
4、Pandas画图
4.1 pandas.DataFrame.plot
DataFrame.plot(kind='line')
- ‘line’ : 折线图
- ‘bar’ : 条形图
- ‘barh’ : 横放的条形图
- ‘hist’ : 直方图
- ‘pie’ : 饼图
- ‘scatter’ : 散点图
- kind : str,需要绘制图形的种类
关于“barh”的解释: http:// pandas.pydata.org/panda s-docs/stable/reference/api/pandas.DataFrame.plot.barh.html
看个例子:
import matplotlib.pyplot as plt
# plot显示图形, plot方法集成了直方图、条形图、饼图、折线图
stock_rise.cumsum().plot(kind="line")
# 需要调用show,才能显示出结果
plt.show()
结果:
4.2 pandas.Series.plot
注:使用的时候查看。
5、文件读取与存储
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
注:最常用的HDF5和CSV文件
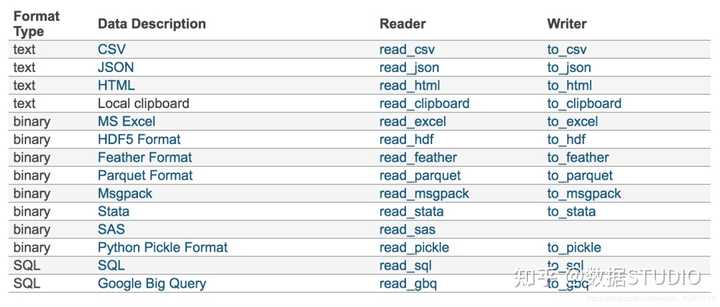

接下来重点看一下,应用CSV方式、HDF方式和json方式实现文件的读取和存储。
5.1 CSV
5.1.1 read_csv
pandas.read_csv(filepath_or_buffer, sep =',', usecols )
- filepath_or_buffer:文件路径
- sep :分隔符,默认用","隔开
- usecols:指定读取的列名,列表形式
举例:读取之前的股票的数据:
# 读取文件,并且指定只获取'open', 'close'指标
data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close'])
open close
2018-02-27 23.53 24.16
2018-02-26 22.80 23.53
2018-02-23 22.88 22.82
2018-02-22 22.25 22.28
2018-02-14 21.49 21.92
5.1.2 to_csv
DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None)
- path_or_buf :文件路径
- sep :分隔符,默认用","隔开
- columns :选择需要的列索引
- header :boolean or list of string, default True,是否写进列索引值
- index:是否写进行索引
- mode:‘w’:重写, ‘a’ 追加
举例:保存读取出来的股票数据 保存’open’列的数据,然后读取查看结果:
# 选取10行数据保存,便于观察数据
data[:10].to_csv("./data/test.csv", columns=['open'])
# 读取,查看结果
pd.read_csv("./data/test.csv")
Unnamed: 0 open
0 2018-02-27 23.53
1 2018-02-26 22.80
2 2018-02-23 22.88
3 2018-02-22 22.25
4 2018-02-14 21.49
5 2018-02-13 21.40
6 2018-02-12 20.70
7 2018-02-09 21.20
8 2018-02-08 21.79
9 2018-02-07 22.69
会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。
下面例子把index指定为False,那么保存的时候就不会保存行索引了:
# index:存储不会将索引值变成一列数据
data[:10].to_csv("./data/test.csv", columns=['open'], index=False)
当然我们也可以这么做,就是把索引保存到文件中,读取的时候变成了一列,那么可以把这个列再变成索引,如下:
# 把Unnamed: 0这一列,变成行索引
open.set_index(["Unnamed: 0"])
# 把索引名字变成index
open.index.name = "index"
5.2 HDF5
5.2.1 read_hdf与to_hdf
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
(1)
pandas.read_hdf(path_or_buf,key =None,** kwargs)
- path_or_buffer:文件路径
- key:读取的键
- return:Theselected object
(2)
DataFrame.to_hdf(path_or_buf, key, **kwargs)
5.2.2 案例
读取文件
day_close = pd.read_hdf("./data/day_close.h5")
如果读取的时候出现以下错误
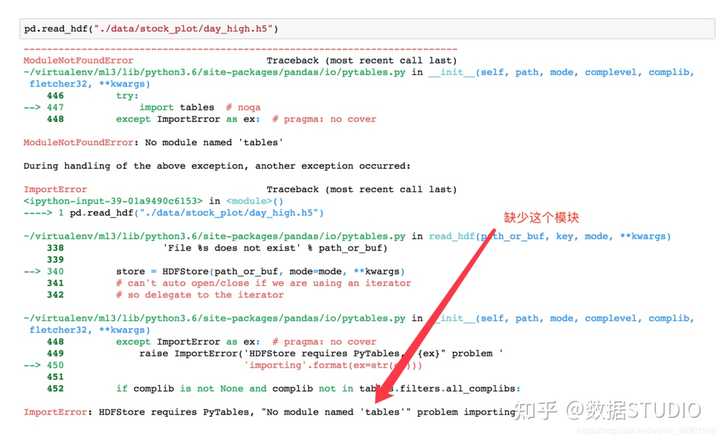

需要安装安装tables模块避免不能读取HDF5文件
pip install tables


存储文件
day_close.to_hdf("./data/test.h5", key="day_close")
再次读取的时候, 需要指定键的名字
new_close = pd.read_hdf("./data/test.h5", key="day_close")
注意:优先选择使用HDF5文件存储
- HDF5在存储的时候支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面
5.3 JSON
JSON是我们常用的一种数据交换格式,在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
5.3.1 read_json
pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False)
-
按照每行读取json对象
- (1)‘split’ : dict like {index -> [index], columns -> [columns], data -> [values]} split 将索引总结到索引,列名到列名,数据到数据。将三部分都分开了
- (2)‘records’ : list like [{column -> value}, … , {column -> value}] records 以columns:values的形式输出
- (3)‘index’ : dict like {index -> {column -> value}} index 以index:{columns:values}…的形式输出
- (4)‘columns’ : dict like {column -> {index -> value}},默认该格式。colums 以columns:{index:values}的形式输出
- (5)‘values’ : just the values array。values 直接输出值
-
path_or_buf: 路径 -
orient: string,以什么样的格式显示.下面是5种格式: -
lines: boolean, default False -
typ: default ‘frame’, 指定转换成的对象类型series或者dataframe
*案例:*
数据介绍:
这里使用一个新闻标题讽刺数据集,格式为json。is_sarcastic:1讽刺的,否则为0;headline:新闻报道的标题;article_link:链接到原始新闻文章。存储格式为:
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0}
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0}
读取
orient指定存储的json格式,lines指定按照行去变成一个样本:
json_read = pd.read_json("./data/Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
结果为:


5.3.2 to_json
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- 将Pandas 对象存储为json格式
- path_or_buf=None:文件地址
- orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}
- lines:一个对象存储为一行
*案例:*
存储文件
# 不指定lines=Treu,则保存成一行
json_read.to_json("./data/test.json", orient='records')
结果:
[{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0},{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1},{"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/advancing-the-worlds-women_b_6810038.html","headline":"advancing the world's women","is_sarcastic":0},....]
修改
lines
参数为True
# 指定lines=True,则多行存储
json_read.to_json("./data/test.json", orient='records', lines=True)
结果:
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0}
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0}
{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1}
{"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1}
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0}...
6、高级处理-缺失值处理
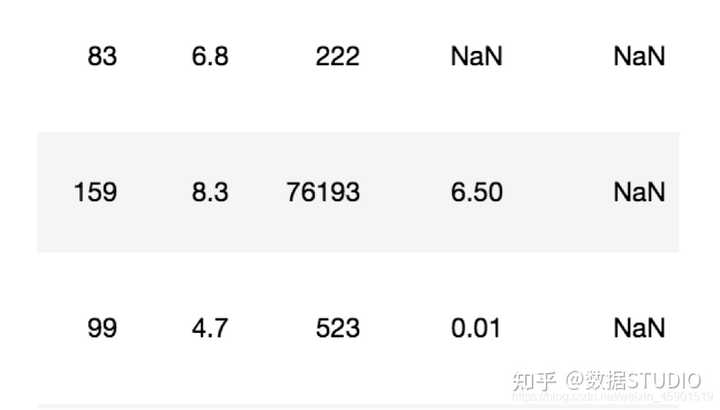
在pandas中,缺失值使用NaN来标记,如下图所示:

6.1 如何处理nan
按如下步骤进行:
(1)获取缺失值的标记方式(NaN或者其他标记方式)
(2)如果缺失值的标记方式是NaN
1、删除存在缺失值的:
dropna(axis='rows')
注:不会修改原数据,需要接受返回值 2、替换缺失值:
fillna(value, inplace=True)
- value:替换成的值
- inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
-
pd.isnull(df), -
pd.notnull(df) - 判断数据中是否包含NaN:
- 存在缺失值nan:
(3)如果缺失值没有使用NaN标记,比如使用"?"
- 先替换‘?’为np.nan,然后继续处理
步骤就是上面的这样,下面通过例子来看看怎么使用pandas处理的:
6.2 电影数据的缺失值处理
电影数据文件获取
# 读取电影数据
movie = pd.read_csv("./data/IMDB-Movie-Data.csv")


6.2.1 判断缺失值是否存在
(1)
pd.notnull()
# 判断是否是缺失值,是则返回False
pd.notnull(movie)
# 结果:
Rank Title Genre Description Director Actors Year Runtime (Minutes) Rating Votes Revenue (Millions) Metascore
0 True True True True True True True True True True True True
1 True True True True True True True True True True True True
2 True True True True True True True True True True True True
3 True True True True True True True True True True True True
4 True True True True True True True True True True True True
5 True True True True True True True True True True True True
6 True True True True True True True True True True True True
7 True True True True True True True True True True False True
但是上面这样显然不好观察,我们可以借助
np.all()
来返回是否有缺失值。
np.all()
只要有一个就返回False,下面看例子:
np.all(pd.notnull(movie))
False
(2)
pd.isnull()
这个和上面的正好相反,判断是否是缺失值,是则返回True。
# 判断是否是缺失值,是则返回True
pd.isnull(movie).head()
# 结果:
Rank Title Genre Description Director Actors Year Runtime (Minutes) Rating Votes Revenue (Millions) Metascore
0 False False False False False False False False False False False False
1 False False False False False False False False False False False False
2 False False False False False False False False False False False False
3 False False False False False False False False False False False False
4 False False False False False False False False False False False False
这个也不好观察,我们利用
np.any()
来判断是否有缺失值,若有则返回True,下面看例子:
np.any(pd.isnull(movie))
6.2.2 存在缺失值nan,并且是np.nan
1、删除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
# 不修改原数据
movie.dropna()
# 可以定义新的变量接受或者用原来的变量名
data = movie.dropna()
2、替换缺失值
# 替换存在缺失值的样本的两列
# 替换填充平均值,中位数
movie['Revenue (Millions)'].fillna(movie['Revenue (Millions)'].mean(), inplace=True)
替换所有缺失值:
# 这个循环,每次取出一列数据,然后用均值来填充
for i in movie.columns:
if np.all(pd.notnull(movie[i])) == False:
print(i)
movie[i].fillna(movie[i].mean(), inplace=True)
6.2.3 不是缺失值nan,有默认标记的
直接看例子:
数据是这样的:
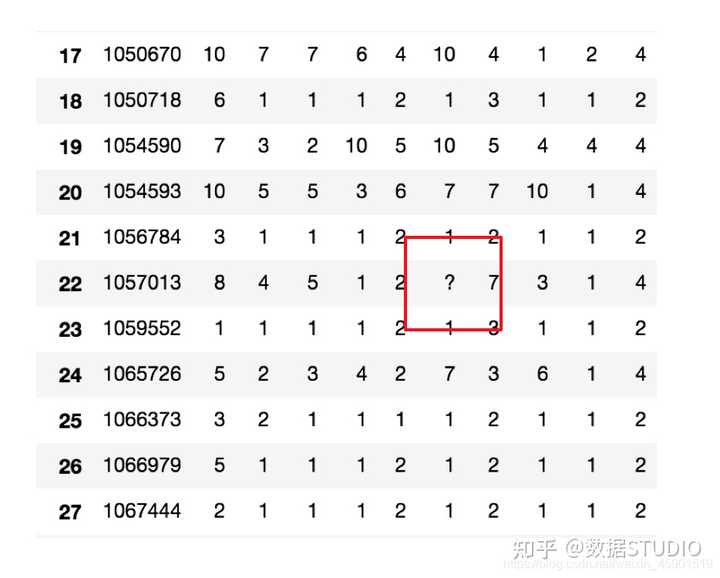

# 读入数据
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
以上数据在读取时,可能会报如下错误:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)>
解决办法:
# 全局取消证书验证
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
处理思路分析:
1、先替换‘?’为np.nan
- to_replace:替换前的值
- value:替换后的值
-
df.replace(to_replace=, value=)
# 把一些其它值标记的缺失值,替换成np.nan
wis = wis.replace(to_replace='?', value=np.nan)
2、再进行缺失值的处理
# 删除
wis = wis.dropna()
3、验证:
np.all(pd.notnull(wis))
# 返回True,说明没有了缺失值
np.any(pd.isnull(wis))
# 返回False,说明没有了缺失值
7、高级处理-数据离散化
7.1 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
7.2 什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
离散化有很多种方法,这里使用一种最简单的方式去操作:
- 原始人的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:150~165, 165~180,180~195
这样我们将数据分到了三个区间段,对应的标记为矮、中、高三个类别,最终要处理成一个"哑变量"矩阵。
下面通过股票数据的例子来看看,具体是怎么操作的。
7.3 股票的涨跌幅离散化
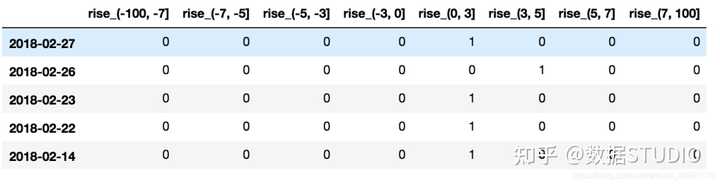
我们对股票每日的"p_change"这一列进行离散化,下图便是离散化后的结果,当前数据存在哪个区间,则这个区间标记为1,否则为0。

那具体怎么做的呢?接着看:
7.3.1 读取股票的数据
先读取股票的数据,筛选出p_change数据。
data = pd.read_csv("./data/stock_day.csv")
p_change= data['p_change']
7.3.2 将股票涨跌幅数据进行分组
下面是所在区间的个数。


使用的工具:
pd.qcut(data, q)
:
-
对数据进行分组,将数据分成q组,一般会与
value_counts搭配使用,统计每组的个数
series.value_counts()
:统计每个分组中有多少数据。
# 自行分组
qcut = pd.qcut(p_change, 10)
# 计算分到每个组数据个数
qcut.value_counts()
# 运行结果:
(5.27, 10.03] 65
(0.26, 0.94] 65
(-0.462, 0.26] 65
(-10.030999999999999, -4.836] 65
(2.938, 5.27] 64
(1.738, 2.938] 64
(-1.352, -0.462] 64
(-2.444, -1.352] 64
(-4.836, -2.444] 64
(0.94, 1.738] 63
Name: p_change, dtype: int64
自定义区间分组:
pd.cut(data, bins)
# 自己指定分组区间
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)
p_counts.value_counts()
# 运行结果:
(0, 3] 215
(-3, 0] 188
(3, 5] 57
(-5, -3] 51
(7, 100] 35
(5, 7] 35
(-100, -7] 34
(-7, -5] 28
Name: p_change, dtype: int64
7.3.3 股票涨跌幅分组数据变成one-hot编码
什么是one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码。
把下图中左边的表格转化为使用右边形式进行表示:
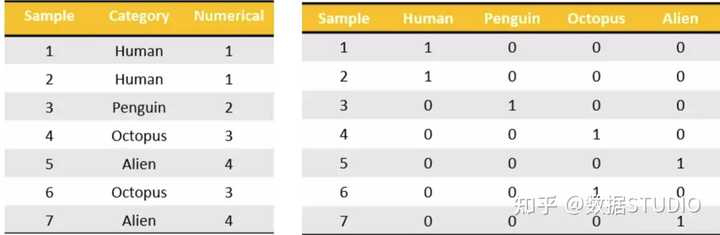

下面看看pandas中是怎么实现的:
pandas.get_dummies(data, prefix=None)
- data:array-like, Series, or DataFrame
- prefix:分组名字
下面是例子:
# 得出one-hot编码矩阵
dummies = pd.get_dummies(p_counts, prefix="rise")
运行结果:

8、高级处理-合并
如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析
8.1 pd.concat实现数据合并
pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引
比如我们将刚才处理好的one-hot编码与原数据合并:
# 按照行索引进行
pd.concat([data, dummies], axis=1)
结果:


8.2 pd.merge
pd.merge(left, right, how='inner', on=None)
-
可以指定按照两组数据的共同键值对合并或者左右各自
-
left: DataFrame -
right: 另一个DataFrame -
on: 指定的共同键 -
how:按照什么方式连接,下面的表格是说明
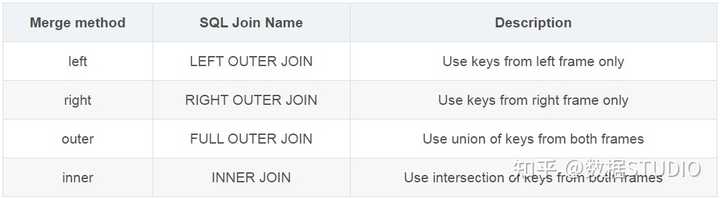

例子:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
内连接:健相同的取上,不同的删掉
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])
结果:
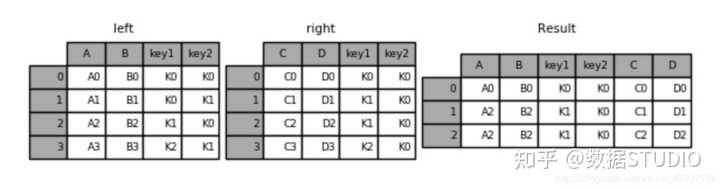

左连接:按左边的数据进行合并
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
结果:
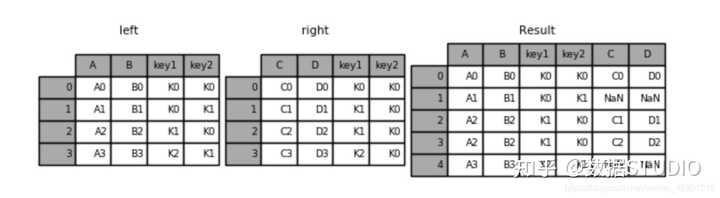

右连接:按右边的数据进行合并
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
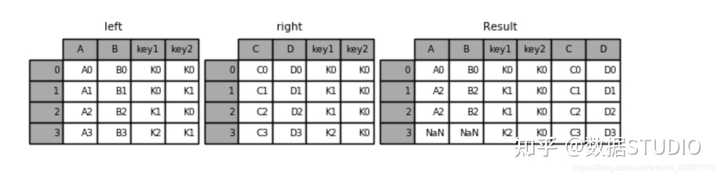

外链接:无论健是否相同都取上,对应不上的使用NaN填充。
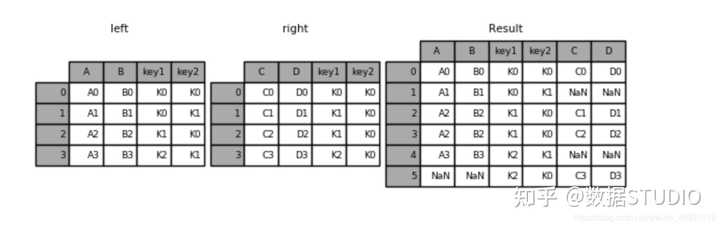
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
结果:

9、高级处理-交叉表与透视表
9.1 交叉表与透视表什么作用
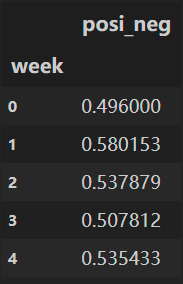
探究股票的涨跌与星期几有关?
以下图当中表示,week代表星期几,1,0代表这一天股票的涨跌幅是好还是坏,里面的数据代表比例
可以理解为所有时间为星期一等等的数据当中涨跌幅好坏的比例
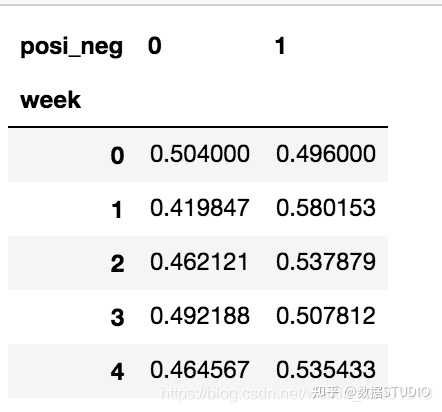

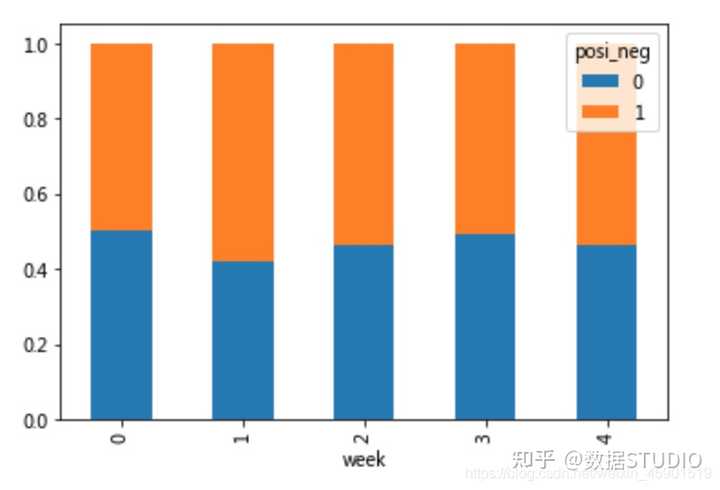

交叉表:交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
-
pd.crosstab(value1, value2)
透视表:透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数
-
data.pivot_table() -
DataFrame.pivot_table([], index=[])
9.2 案例分析
9.2.1 数据准备
- 准备两列数据,星期数据以及涨跌幅是好是坏数据
- 进行交叉表计算
# 寻找星期几跟股票张得的关系
# 1、先把对应的日期找到星期几
date = pd.to_datetime(data.index).weekday
data['week'] = date # 增加一列
# 2、假如把p_change按照大小去分个类0为界限
data['posi_neg'] = np.where(data['p_change'] > 0, 1, 0)
# 通过交叉表找寻两列数据的关系
count = pd.crosstab(data['week'], data['posi_neg'])
结果:
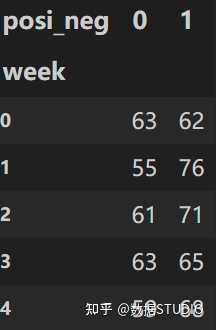
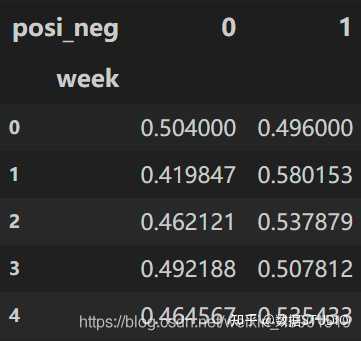
但是我们看到count只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
对于每个星期一等的总天数求和,运用除法运算求出比例
# 算数运算,先求和
sum = count.sum(axis=1).astype(np.float32)
# 进行相除操作,得出比例
pro = count.div(sum, axis=0)
结果:
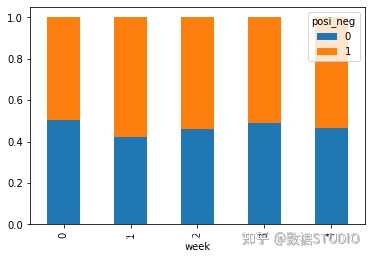
9.2.2 查看效果
使用plot画出这个比例,使用stacked的柱状图
pro.plot(kind='bar', stacked=True)
plt.show()
9.2.3 使用pivot_table(透视表)实现
使用透视表,刚才的过程更加简单
# 通过透视表,将整个过程变成更简单一些
data.pivot_table(['posi_neg'], index='week')
结果:
10、高级处理-分组与聚合
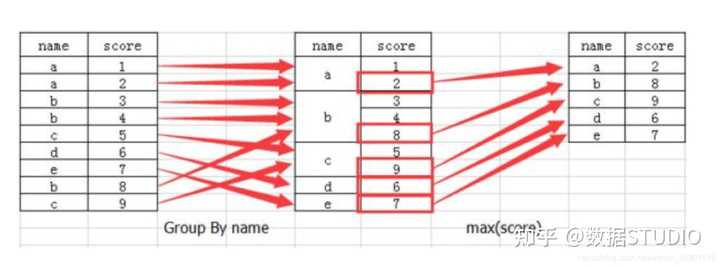
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
10.1 什么分组与聚合
下图展示了分组与聚合的概念:

10.2 分组API
DataFrame.groupby(key, as_index=False)
- key: 分组的列数据,可以多个
案例: 不同颜色的不同笔的价格数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
# 结果:
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
进行分组,对颜色分组,price进行聚合:
# 按color分组,再取出price1列求平均值
col.groupby(['color'])['price1'].mean()
# 和上述一个功能
col['price1'].groupby(col['color']).mean()
# 结果:
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
# 分组,数据的结构不变
col.groupby(['color'], as_index=False)['price1'].mean()
# 结果:
color price1
0 green 2.025
1 red 2.380
2 white 5.560
10.3 星巴克零售店铺数据
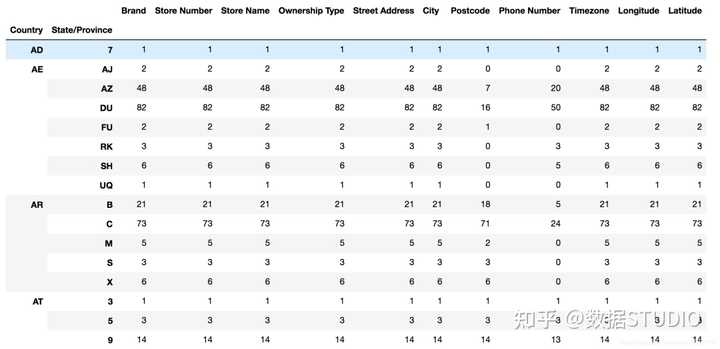
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
数据来源: https://www. kaggle.com/starbucks/st ore-locations/data

10.3.1 数据获取
从文件中读取星巴克店铺数据
# 导入星巴克店的数据
starbucks = pd.read_csv("./data/starbucks/directory.csv")
10.3.2 进行分组聚合
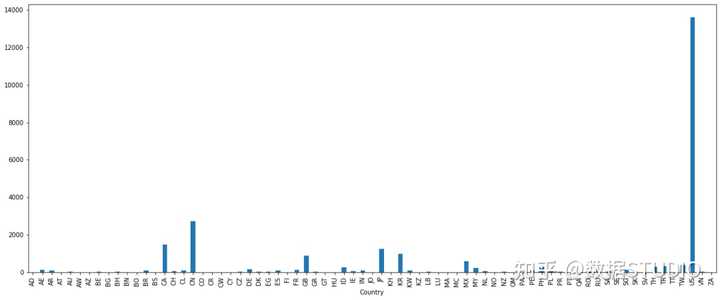
# 按照国家分组,求出每个国家的星巴克零售店数量
count = starbucks.groupby(['Country']).count()
画图显示结果:
count['Brand'].plot(kind='bar', figsize=(20, 8))
plt.show()

假设我们加入省市一起进行分组:
# 设置多个索引,set_index()
starbucks.groupby(['Country', 'State/Province']).count()
结果:

11、电影案例分析
11.1 需求
现在我们有一组从2006年到2016年1000部最流行的电影数据
数据来源: https://www. kaggle.com/damianpanek/ sunday-eda/data
- 问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
- 问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
11.2 实现
首先获取导入包,获取数据:
%matplotlib inline
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#文件的路径
path = "./data/IMDB-Movie-Data.csv"
#读取文件
df = pd.read_csv(path)
11.2.1 问题一:
我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 得出评分的平均分
使用mean函数
df["Rating"].mean()
# 结果:
6.723200000000003
- 得出导演人数信息
求出唯一值,然后进行形状获取
## 导演的人数
# df["Director"].unique().shape[0] # 方法一
np.unique(df["Director"]).shape[0] # 方法二
11.2.2 问题二:
对于这一组电影数据,如果我们想Rating的分布情况,应该如何呈现数据?
- 直接呈现,以直方图的形式
选择分数列数据,进行plot
df["Rating"].plot(kind='hist',figsize=(20,8))
plt.show()
效果:
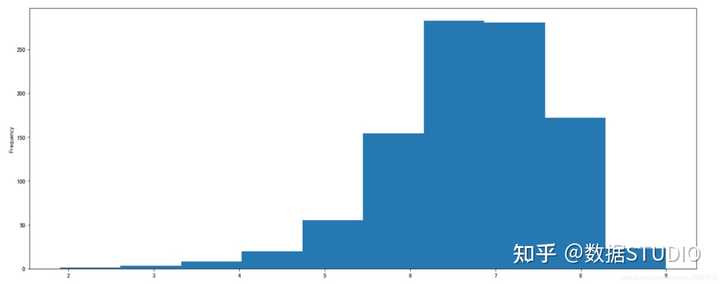

发现直接通过pandas的plot画图,显示的下标不合适,这个时候我们需要借助matplotlib来改变。
- Rating进行分布展示
进行绘制直方图
# 1.添加画布
plt.figure(figsize=(20,8),dpi=100)
# 2.画图
plt.hist(df["Rating"].values,bins=20)
# 2.1 添加刻度线
max_ = df["Rating"].max()
min_ = df["Rating"].min()
x_ticks = np.linspace(min_, max_, num=21)
plt.xticks(x_ticks)
# 2.2添加网格线
plt.grid()
# 3.显示
plt.show()
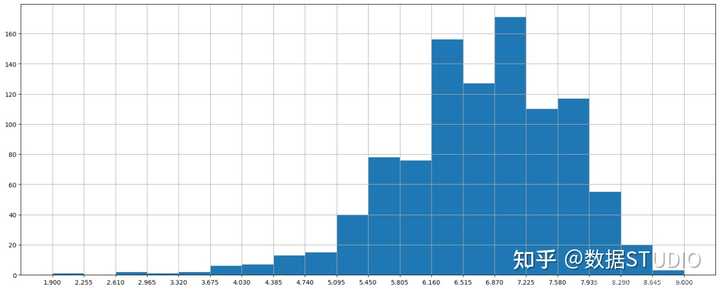

数据分析:从上图中就可以发现,评分主要分布在5~8分之间
11.2.3 问题三:
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路分析
- 1、创建一个全为0的dataframe,列索引置为电影的分类,temp_df
- 2、遍历每一部电影,temp_df中把分类出现的列的值置为1- 3、求和
- 思路
下面接着看:
1、创建一个全为0的dataframe,列索引置为电影的分类,temp_df
# 进行字符串分割
temp_list = [i.split(",") for i in df["Genre"]]
# 获取电影的分类
genre_list = np.unique([i for j in temp_list for i in j])
# 增加新的列,创建全为0的dataframe
temp_df = pd.DataFrame(np.zeros([df.shape[0],genre_list.shape[0]]),columns=genre_list)
2、遍历每一部电影,temp_df中把分类出现的列的值置为1
for i in range(1000):
#temp_list[i] 就是['Action','Adventure','Animation']等