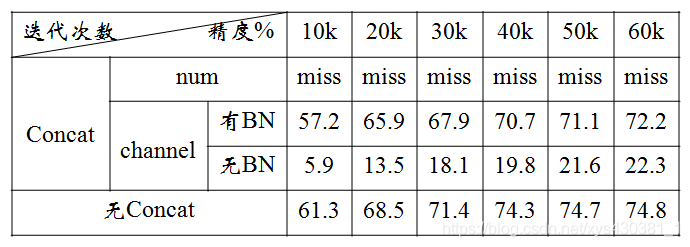
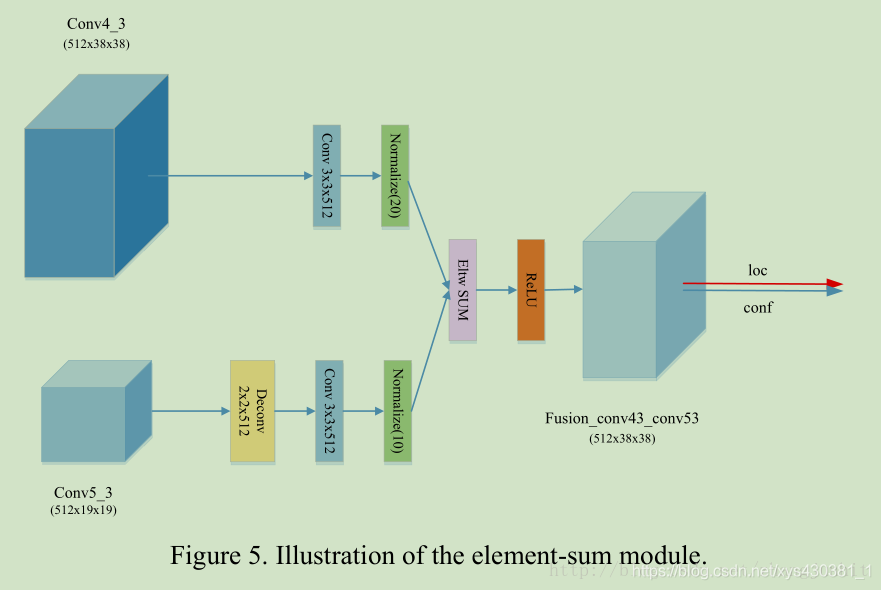
在各个网络模型中,
ResNet,FPN等采用的element-wise add来融合特征,而DenseNet等则采用concat来融合特征
。那add与concat形式有什么不同呢?事实上两者都可以理解为整合特征图信息。只不过concat比较直观,而add理解起来比较生涩。
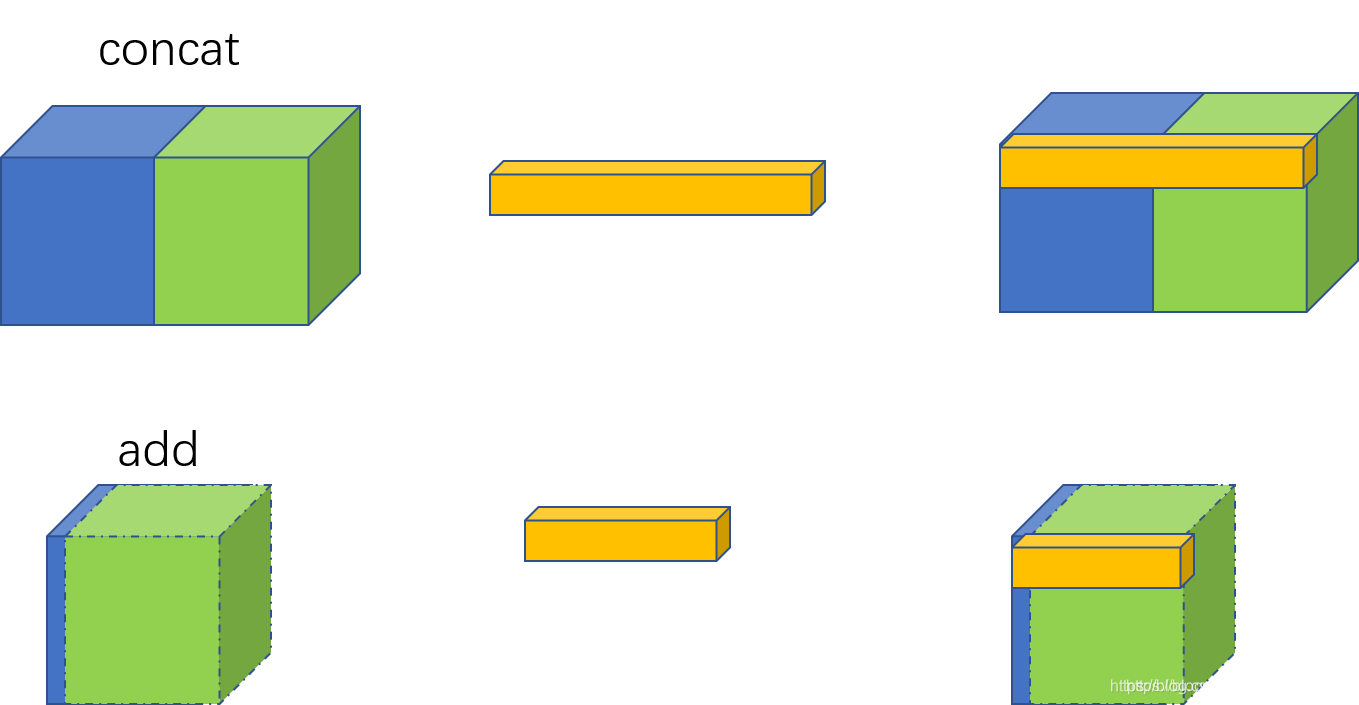
从图中可以发现,
-
concat是通道数的增加
;
-
add是特征图相加,通道数不变
你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征数(通道数)增加了,而每一特征下的信息是没有增加。
concat每个通道对应着对应的卷积核。 而add形式则将对应的特征图相加,再进行下一步卷积操作,相当于加了一个先验:对应通道的特征图语义类似,从而对应的特征图共享一个卷积核(对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核)。
因此add可以认为是特殊的concat形式。但是add的计算量要比concat的计算量小得多。
另解释:
对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核。下面具体用式子解释一下。由于每个输出通道的卷积核是独立的,我们可以只看单个通道的输出。假设两路输入的通道分别为X1, X2, …, Xc和Y1, Y2, …, Yc。那么concat的单个输出通道为(*表示卷积):
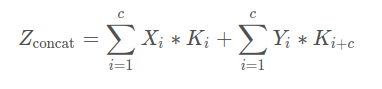
而add的单个输出通道为:
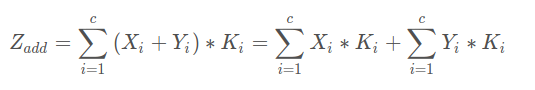
因此add相当于加了一种prior,当两路输入可以具有“对应通道的特征图语义类似”(可能不太严谨)的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。FPN[1]里的金字塔,是希望把分辨率最小但语义最强的特征图增加分辨率,从性质上是可以用add的。如果用concat,因为分辨率小的特征通道数更多,计算量是一笔不少的开销
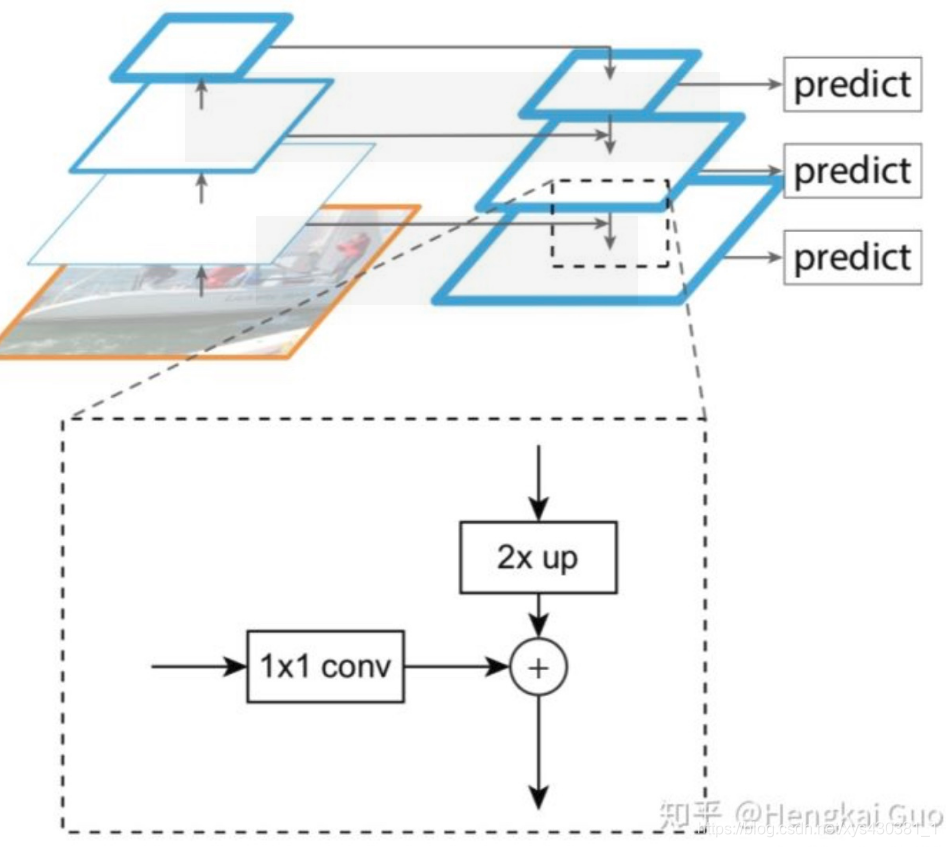
Resnet是做值的叠加,通道数是不变的,DenseNet是做通道的合并。你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
参考文章:https://blog.csdn.net/u012193416/article/details/79479935
通过keras代码,观察了add对参数的影响,以及concat操作数组的结果。
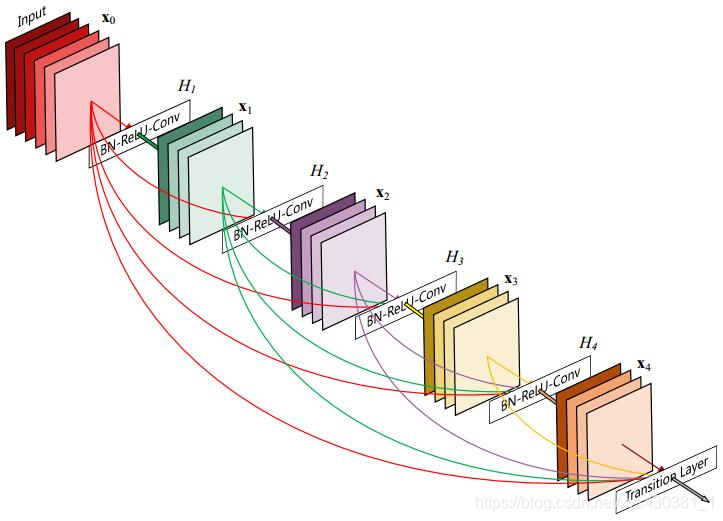
highway的稠密连接方式具有诸多的优势,增加了梯度的传递,特征得到了重用,甚至减少了在小样本数据上的过拟合。但是随之产生2个缺点:
(1)
DenseBlock靠后面的层的输入channel过大—每层开始的时候引入Bottleneck
:
这里假设第L层输出K个feature map,即网络增长率为K,那么第L层的输入为K0+K*(L-1),其中K0为输入层的维度。也就是说,对于Dense Block模块中每一层layer的输入feature map时随着层数递增的,每次递增为K,即网络增长率。那么这样随着Dense Block模块深度的加深,后面的层的输入feature map的维度是很大的。
为了解决这个问题,在DenseNet-B网络中,在Dense Block
每一层开始的时候加入了Bottleneck 单元
,即1x1卷积进行降维,被降到4K维(K为增长率)。
(2)
DenseBlock模块的输出维度很大—transition layer模块中加入1*1卷积降维
每一个DenseBlock模块的输出维度是很大的,假设一个L层的Dense Block模块,假设其中已经加入了Bottleneck 单元,那么输出的维度为,第1层的维度+第2层的维度+第3层的维度+****
第L层的维度,加了Bottleneck单元后每层的输出维度为4K,那么最终Dense Block模块的输出维度为4K
L。随着层数L的增加,最终输出的feature map的维度也是一个很大的数。
为了解决这个问题,在transition layer模块中加入了1
1卷积做降维。
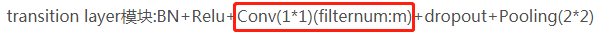
其中,DenseNet-B在原始DenseNet的基础上,在Dense Block模块的每一层都加入了1*1卷积,使得将每一个layer输入的feature map都降为到4k的维度,大大的减少了计算量。
DenseNet-BC在DenseNet-B的基础上,在transitionlayer模块中加入了压缩率θ参数,论文中将θ设置为0.5,这样通过1*1卷积,将上一个Dense Block模块的输出feature map维度减少一半。
附:tensorflow下实现DenseNet对数据集cifar-10的图像分类
https://blog.csdn.net/k87974/article/details/80352315
https://blog.csdn.net/u011732139/article/details/69943954
原文链接:https://blog.csdn.net/xys430381_1/article/details/88355956一、如何理解concat和add的方式融合特征在各个网络模型中,ResNet,FPN等采用的element-wise add来融合特征,而DenseNet等则采用concat来融合特征。那add与concat形式有什么不同呢?事实上两者都可以理解为整合特征图信息。只不过concat比较直观,而add理解起来比较生涩。从图中可以发现,concat是通道数的增加;add是特
1、
Concat
:张量拼接,会扩充两个张量的维度,
例如2626256和2626512两个张量拼接,结果是2626768。
2、
add
:张量相加,张量直接相加,不会扩充维度。
例如104104128和104104128相加,结果还是104104128。
add
和cfg文件
中
的shortcut功能一样。
参考:https://zhuanlan.zhihu.com/p/460234735
1. 如何理解
concat
和
add
:
实际上
add
与
concat
都可以理解为用于整合特征图信息,ResNet/FPN等网络结构逐元素做值的叠加而通道数是不变的,采用的
add
方式来融合特征;而DenseNet等网络结构则做通道的合并,采用
concat
方式来融合特征。
concat
方式经常用于将特征联合、多个卷积特征提取框架提取的特征融合或者是将输出层的信息进行融合;而
add
层更像是信息之间的叠加。
可以理解为,
add
方式在...
concat
与
add
直观理解
add
操作经典代表网络是ResNet,
concat
e操作经典代表网络是Inception系统网络
中
的Inception结构和DenseNet。
add
操作相当于加入一种先验知识。我觉得也就是相当于你对原始特征进行人为的特征融合。而你选择的特征处理的操作是element-wise
add
。通过
add
操作,会得到新的特征,这个新的特征可以反映原始特征的一些特性,但是原始特征的一些信息也会在这个过程
中
损失。
但是
concat
e就是将原始特征直接拼接,让网络去学习,应该如何融合特征,
DenseNet和Inception
中
更多采用的是
concat
enate操作,而ResNet更多采用的
add
操作。
concat
enate为横向或纵向空间上的叠加,而
add
为简单的像素叠加。
https://blog.csdn.net/qq_32256033/article/details/89516738
https://blog.csdn.net/weixin_39610043/article/details/87103358
https://blog.csdn.net/u012193416/a
在java
中
,String字符串拼接
concat
方法 和字符串间直接用“+”号拼接的
区别
?
当我查看String类的
concat
函数的源码时,发现字符串连接是这么实现的: Java代码:
public String
concat
(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
int len = value.length;
char buf[] = Arrays
本课程在介绍计算机视觉深度学习基本概念基础上,详尽讲解YOLOV3和YOLOV4的算法模型原理,并基于实际项目
中
的无人零售商品数据集来手把手教大家如何将它训练成YOLOV3和V4模型,最后对训练出来的模型集进行性能评估,从而挑选出最优模型。课程主要分为九大章:1。课程内容介绍、特色及其答疑2。计算机视觉深度学习基本概念及其yolo1,2,3的模型结构讲解3。darknet框架介绍及其安装4。darknet训练和推理代码的梳理5。基于darknet框架训练一个无人零售商品数据集 上半部6。基于darknet框架训练一个无人零售商品数据集 下半部7。模型评估指标(训练过程的loss和iou曲线显示,PR,RECALL,AP以及MAP的计算)8。YOLOV4算法模型原理讲解9。YOLOV4算法模型的训练和测试